 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Using Low-rank Representation of Abundance Maps and Nonnegative Tensor Factorization for Hyperspectral Nonlinear Unmixing
Mar 30, 2021
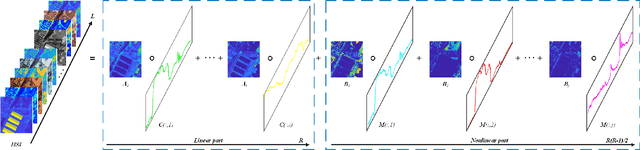

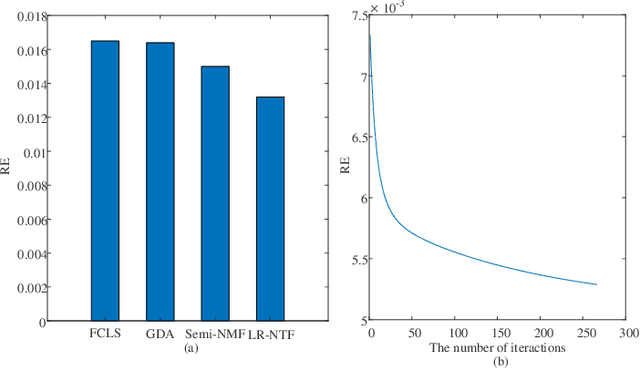
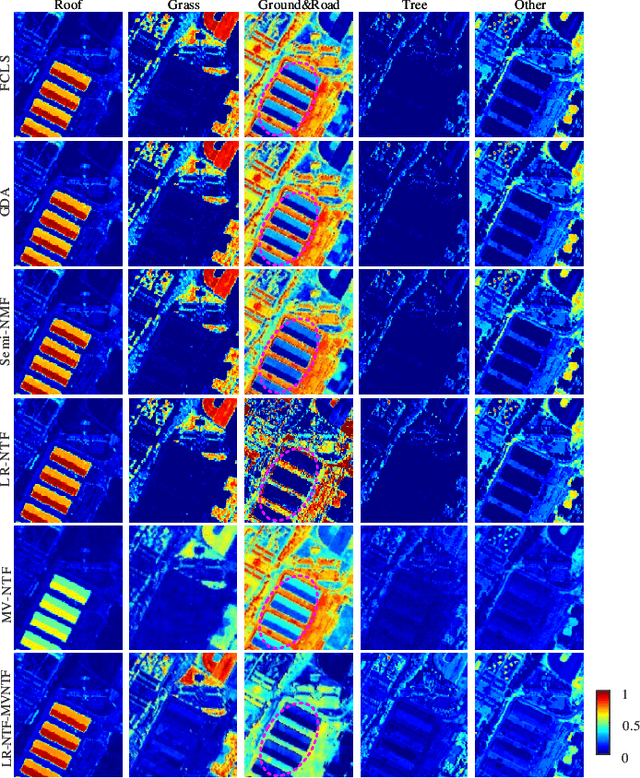
Tensor-based methods have been widely studied to attack inverse problems in hyperspectral imaging since a hyperspectral image (HSI) cube can be naturally represented as a third-order tensor, which can perfectly retain the spatial information in the image. In this article, we extend the linear tensor method to the nonlinear tensor method and propose a nonlinear low-rank tensor unmixing algorithm to solve the generalized bilinear model (GBM). Specifically, the linear and nonlinear parts of the GBM can both be expressed as tensors. Furthermore, the low-rank structures of abundance maps and nonlinear interaction abundance maps are exploited by minimizing their nuclear norm, thus taking full advantage of the high spatial correlation in HSIs. Synthetic and real-data experiments show that the low rank of abundance maps and nonlinear interaction abundance maps exploited in our method can improve the performance of the nonlinear unmixing. A MATLAB demo of this work will be available at https://github.com/LinaZhuang for the sake of reproducibility.
A Parallel Optical Image Security System with Cascaded Phase-only Masks
Feb 21, 2019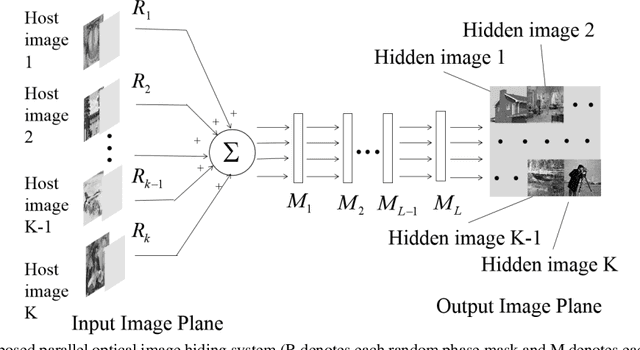

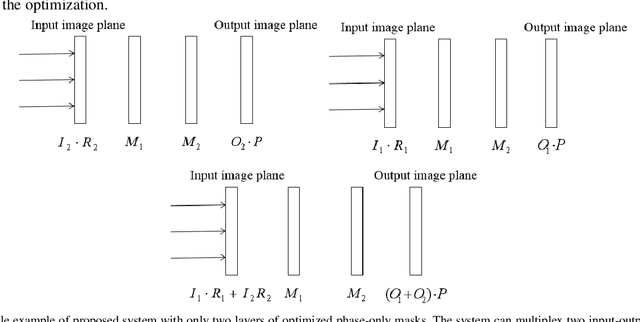
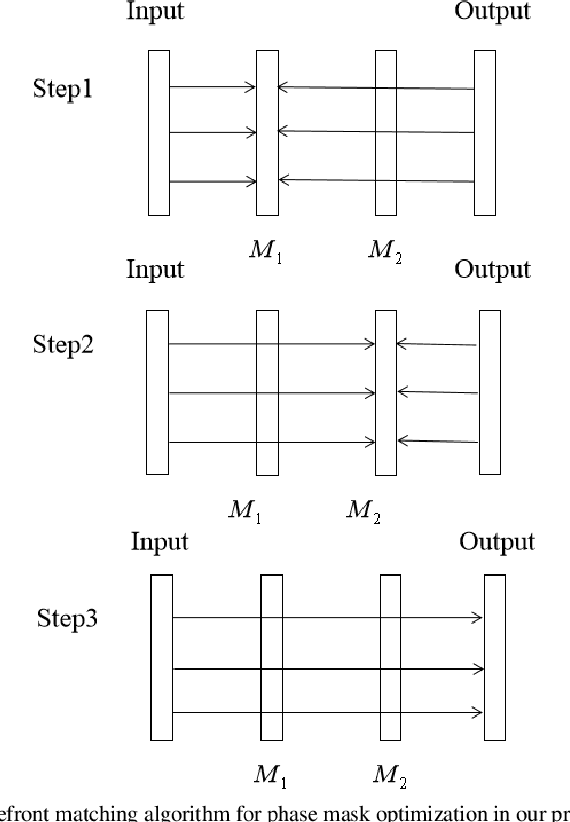
In many previous works, a cascaded phase-only mask (or phase-only hologram) architecture is designed for optical image encryption and watermarking. However, one such system usually cannot process multiple pairs of host images and hidden images in parallel. In our proposed scheme, multiple host images can be simultaneously input to the system and each corresponding output hidden image will be displayed in a non-overlap sub-region in the output imaging plane. Each input host image undergoes a different optical transform in an independent channel within the same system. The multiple cascaded phase masks (up to 25 layers or even more) in the system can be effectively optimized by a wavefront matching algorithm.
Permutation-invariant Feature Restructuring for Correlation-aware Image Set-based Recognition
Aug 03, 2019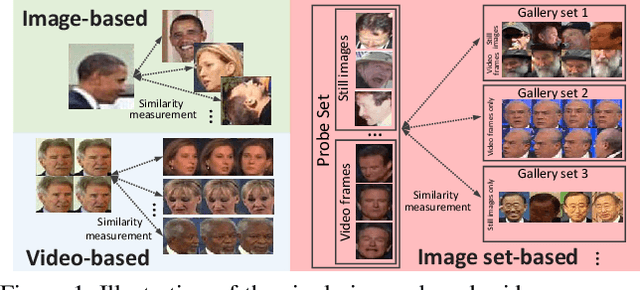
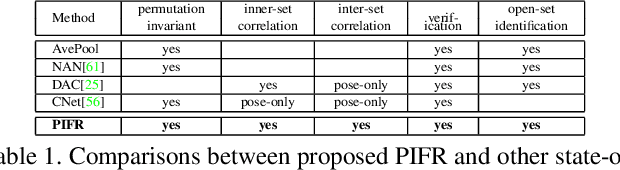


We consider the problem of comparing the similarity of image sets with variable-quantity, quality and un-ordered heterogeneous images. We use feature restructuring to exploit the correlations of both inner$\&$inter-set images. Specifically, the residual self-attention can effectively restructure the features using the other features within a set to emphasize the discriminative images and eliminate the redundancy. Then, a sparse/collaborative learning-based dependency-guided representation scheme reconstructs the probe features conditional to the gallery features in order to adaptively align the two sets. This enables our framework to be compatible with both verification and open-set identification. We show that the parametric self-attention network and non-parametric dictionary learning can be trained end-to-end by a unified alternative optimization scheme, and that the full framework is permutation-invariant. In the numerical experiments we conducted, our method achieves top performance on competitive image set/video-based face recognition and person re-identification benchmarks.
eProduct: A Million-Scale Visual Search Benchmark to Address Product Recognition Challenges
Jul 13, 2021
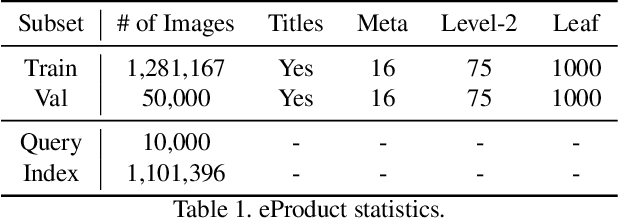
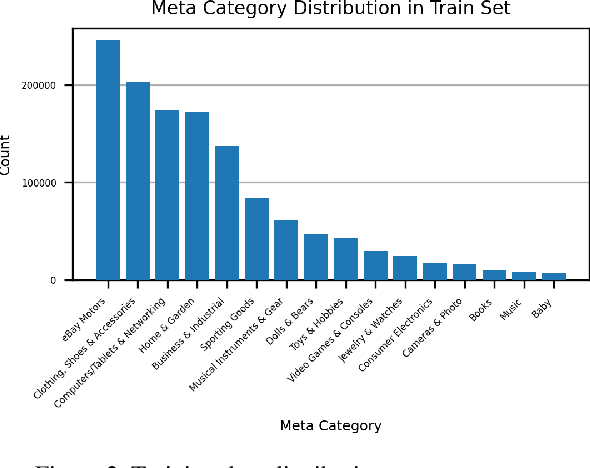
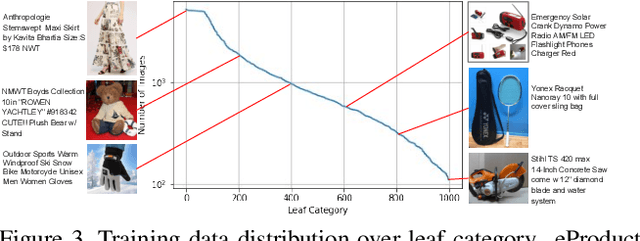
Large-scale product recognition is one of the major applications of computer vision and machine learning in the e-commerce domain. Since the number of products is typically much larger than the number of categories of products, image-based product recognition is often cast as a visual search rather than a classification problem. It is also one of the instances of super fine-grained recognition, where there are many products with slight or subtle visual differences. It has always been a challenge to create a benchmark dataset for training and evaluation on various visual search solutions in a real-world setting. This motivated creation of eProduct, a dataset consisting of 2.5 million product images towards accelerating development in the areas of self-supervised learning, weakly-supervised learning, and multimodal learning, for fine-grained recognition. We present eProduct as a training set and an evaluation set, where the training set contains 1.3M+ listing images with titles and hierarchical category labels, for model development, and the evaluation set includes 10,000 query and 1.1 million index images for visual search evaluation. We will present eProduct's construction steps, provide analysis about its diversity and cover the performance of baseline models trained on it.
Information Maximization Clustering via Multi-View Self-Labelling
Mar 12, 2021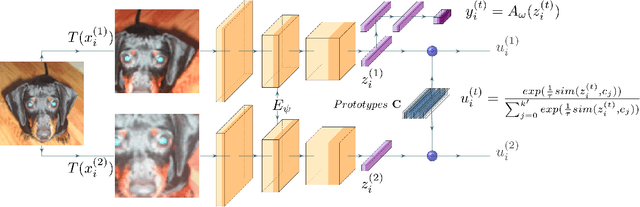
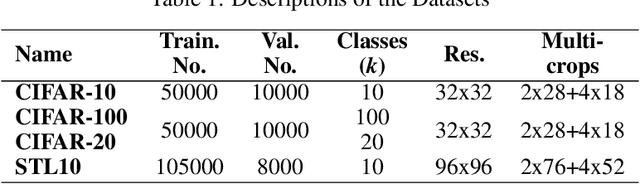
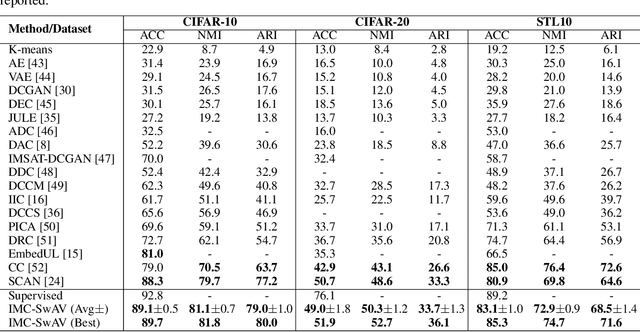
Image clustering is a particularly challenging computer vision task, which aims to generate annotations without human supervision. Recent advances focus on the use of self-supervised learning strategies in image clustering, by first learning valuable semantics and then clustering the image representations. These multiple-phase algorithms, however, increase the computational time and their final performance is reliant on the first stage. By extending the self-supervised approach, we propose a novel single-phase clustering method that simultaneously learns meaningful representations and assigns the corresponding annotations. This is achieved by integrating a discrete representation into the self-supervised paradigm through a classifier net. Specifically, the proposed clustering objective employs mutual information, and maximizes the dependency between the integrated discrete representation and a discrete probability distribution. The discrete probability distribution is derived though the self-supervised process by comparing the learnt latent representation with a set of trainable prototypes. To enhance the learning performance of the classifier, we jointly apply the mutual information across multi-crop views. Our empirical results show that the proposed framework outperforms state-of-the-art techniques with the average accuracy of 89.1% and 49.0%, respectively, on CIFAR-10 and CIFAR-100/20 datasets. Finally, the proposed method also demonstrates attractive robustness to parameter settings, making it ready to be applicable to other datasets.
End-to-end Hand Mesh Recovery from a Monocular RGB Image
Mar 09, 2019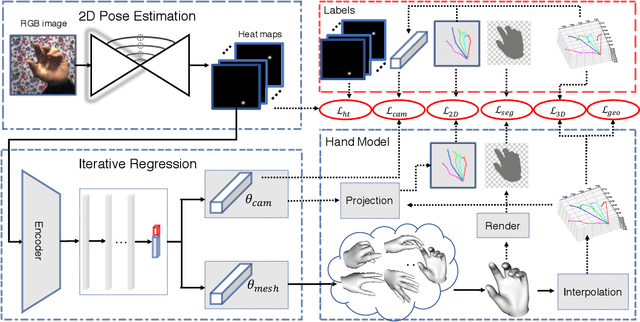
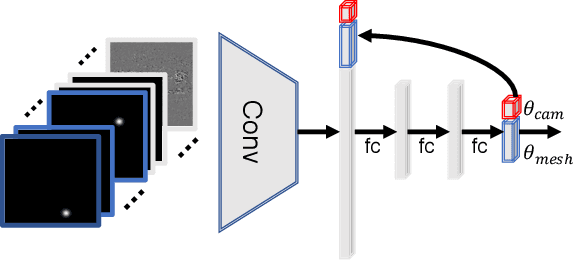
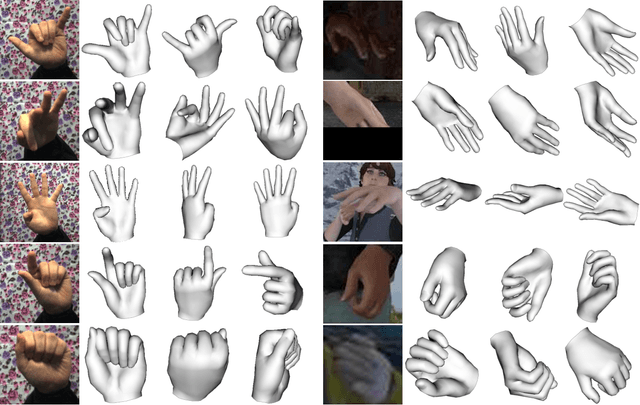

In this paper, we present a HAnd Mesh Recovery (HAMR) framework to tackle the problem of reconstructing the full 3D mesh of a human hand from a single RGB image. In contrast to existing research on 2D or 3D hand pose estimation from RGB or/and depth image data, HAMR can provide a more expressive and useful mesh representation for monocular hand image understanding. In particular, the mesh representation is achieved by parameterizing a generic 3D hand model with shape and relative 3D joint angles. By utilizing this mesh representation, we can easily compute the 3D joint locations via linear interpolations between the vertexes of the mesh, while obtain the 2D joint locations with a projection of the 3D joints.To this end, a differentiable re-projection loss can be defined in terms of the derived representations and the ground-truth labels, thus making our framework end-to-end trainable.Qualitative experiments show that our framework is capable of recovering appealing 3D hand mesh even in the presence of severe occlusions.Quantitatively, our approach also outperforms the state-of-the-art methods for both 2D and 3D hand pose estimation from a monocular RGB image on several benchmark datasets.
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Mar 30, 2021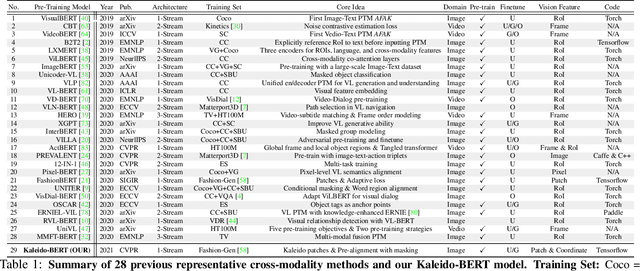
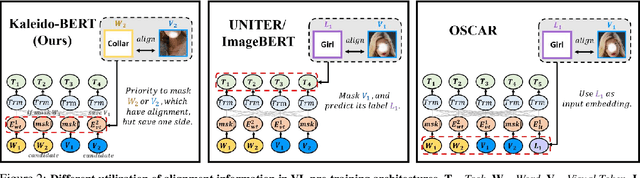
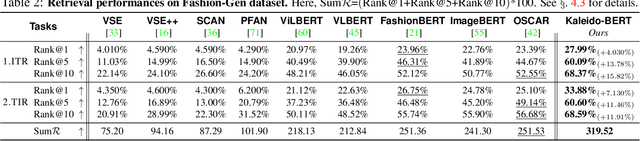
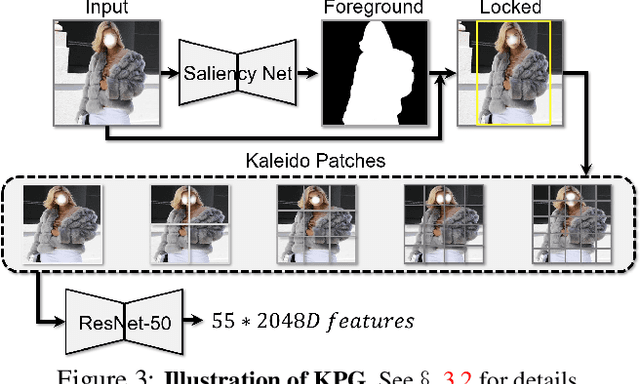
We present a new vision-language (VL) pre-training model dubbed Kaleido-BERT, which introduces a novel kaleido strategy for fashion cross-modality representations from transformers. In contrast to random masking strategy of recent VL models, we design alignment guided masking to jointly focus more on image-text semantic relations. To this end, we carry out five novel tasks, i.e., rotation, jigsaw, camouflage, grey-to-color, and blank-to-color for self-supervised VL pre-training at patches of different scale. Kaleido-BERT is conceptually simple and easy to extend to the existing BERT framework, it attains new state-of-the-art results by large margins on four downstream tasks, including text retrieval (R@1: 4.03% absolute improvement), image retrieval (R@1: 7.13% abs imv.), category recognition (ACC: 3.28% abs imv.), and fashion captioning (Bleu4: 1.2 abs imv.). We validate the efficiency of Kaleido-BERT on a wide range of e-commerical websites, demonstrating its broader potential in real-world applications.
Constrained Contrastive Distribution Learning for Unsupervised Anomaly Detection and Localisation in Medical Images
Mar 05, 2021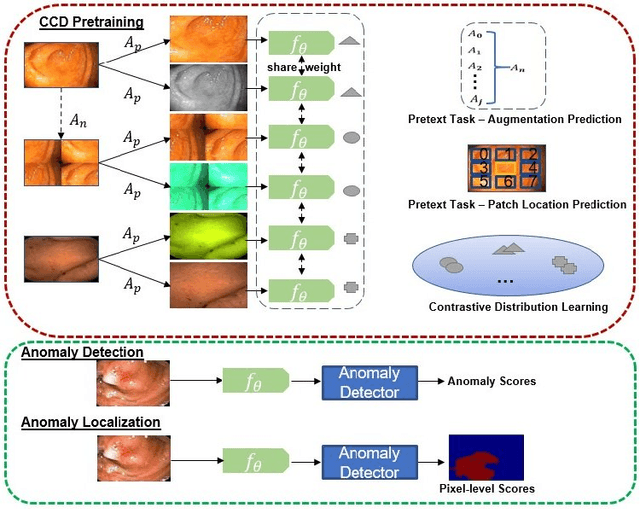
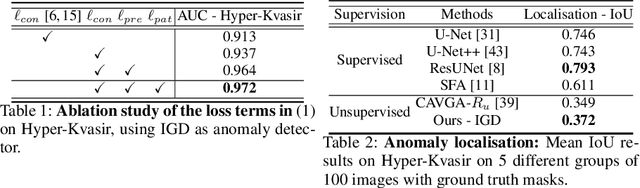
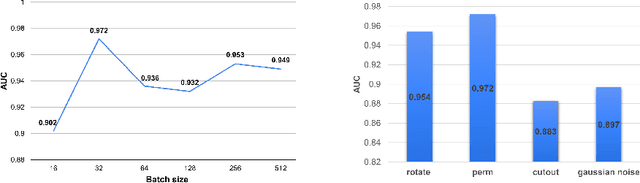
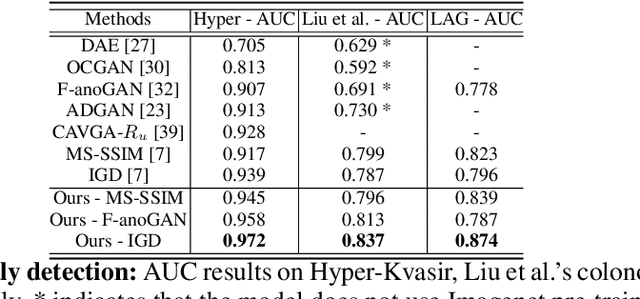
Unsupervised anomaly detection (UAD) learns one-class classifiers exclusively with normal (i.e., healthy) images to detect any abnormal (i.e., unhealthy) samples that do not conform to the expected normal patterns. UAD has two main advantages over its fully supervised counterpart. Firstly, it is able to directly leverage large datasets available from health screening programs that contain mostly normal image samples, avoiding the costly manual labelling of abnormal samples and the subsequent issues involved in training with extremely class-imbalanced data. Further, UAD approaches can potentially detect and localise any type of lesions that deviate from the normal patterns. One significant challenge faced by UAD methods is how to learn effective low-dimensional image representations to detect and localise subtle abnormalities, generally consisting of small lesions. To address this challenge, we propose a novel self-supervised representation learning method, called Constrained Contrastive Distribution learning for anomaly detection (CCD), which learns fine-grained feature representations by simultaneously predicting the distribution of augmented data and image contexts using contrastive learning with pretext constraints. The learned representations can be leveraged to train more anomaly-sensitive detection models. Extensive experiment results show that our method outperforms current state-of-the-art UAD approaches on three different colonoscopy and fundus screening datasets. Our code is available at https://github.com/tianyu0207/CCD.
Heavy Rain Image Restoration: Integrating Physics Model and Conditional Adversarial Learning
Apr 10, 2019



Most deraining works focus on rain streaks removal but they cannot deal adequately with heavy rain images. In heavy rain, streaks are strongly visible, dense rain accumulation or rain veiling effect significantly washes out the image, further scenes are relatively more blurry, etc. In this paper, we propose a novel method to address these problems. We put forth a 2-stage network: a physics-based backbone followed by a depth-guided GAN refinement. The first stage estimates the rain streaks, the transmission, and the atmospheric light governed by the underlying physics. To tease out these components more reliably, a guided filtering framework is used to decompose the image into its low- and high-frequency components. This filtering is guided by a rain-free residue image --- its content is used to set the passbands for the two channels in a spatially-variant manner so that the background details do not get mixed up with the rain-streaks. For the second stage, the refinement stage, we put forth a depth-guided GAN to recover the background details failed to be retrieved by the first stage, as well as correcting artefacts introduced by that stage. We have evaluated our method against the state of the art methods. Extensive experiments show that our method outperforms them on real rain image data, recovering visually clean images with good details.
Domain Adaptive YOLO for One-Stage Cross-Domain Detection
Jun 26, 2021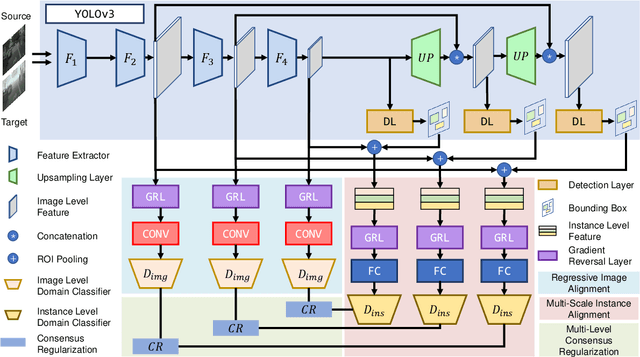
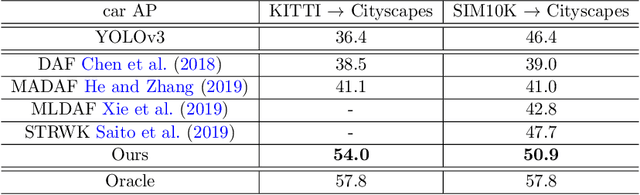


Domain shift is a major challenge for object detectors to generalize well to real world applications. Emerging techniques of domain adaptation for two-stage detectors help to tackle this problem. However, two-stage detectors are not the first choice for industrial applications due to its long time consumption. In this paper, a novel Domain Adaptive YOLO (DA-YOLO) is proposed to improve cross-domain performance for one-stage detectors. Image level features alignment is used to strictly match for local features like texture, and loosely match for global features like illumination. Multi-scale instance level features alignment is presented to reduce instance domain shift effectively , such as variations in object appearance and viewpoint. A consensus regularization to these domain classifiers is employed to help the network generate domain-invariant detections. We evaluate our proposed method on popular datasets like Cityscapes, KITTI, SIM10K and etc.. The results demonstrate significant improvement when tested under different cross-domain scenarios.