 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AOSLO-net: A deep learning-based method for automatic segmentation of retinal microaneurysms from adaptive optics scanning laser ophthalmoscope images
Jun 25, 2021


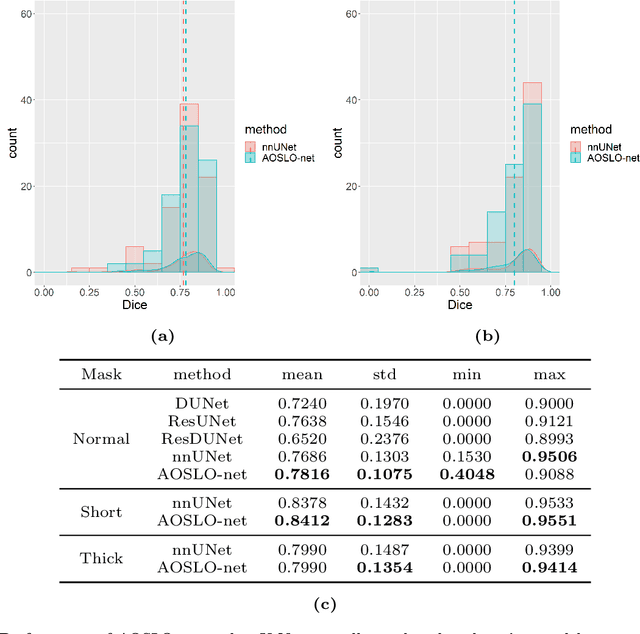
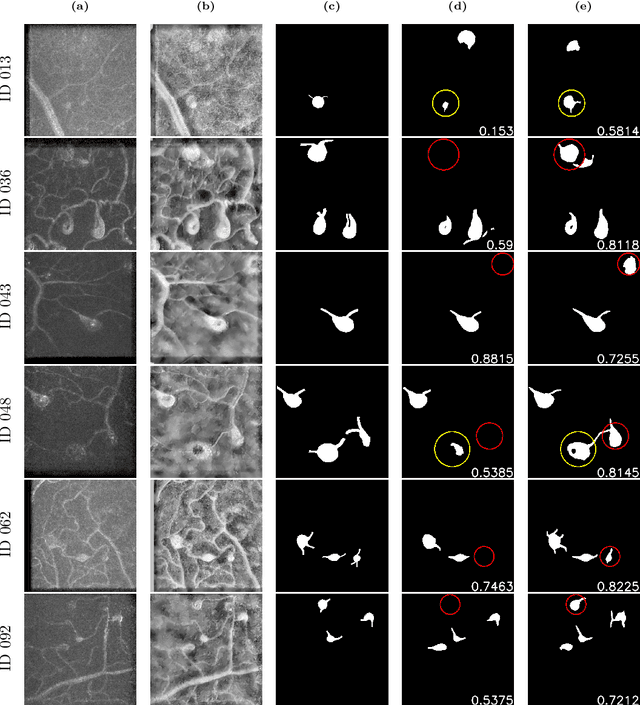
Microaneurysms (MAs) are one of the earliest signs of diabetic retinopathy (DR), a frequent complication of diabetes that can lead to visual impairment and blindness. Adaptive optics scanning laser ophthalmoscopy (AOSLO) provides real-time retinal images with resolution down to 2 $\mu m$ and thus allows detection of the morphologies of individual MAs, a potential marker that might dictate MA pathology and affect the progression of DR. In contrast to the numerous automatic models developed for assessing the number of MAs on fundus photographs, currently there is no high throughput image protocol available for automatic analysis of AOSLO photographs. To address this urgency, we introduce AOSLO-net, a deep neural network framework with customized training policies to automatically segment MAs from AOSLO images. We evaluate the performance of AOSLO-net using 87 DR AOSLO images and our results demonstrate that the proposed model outperforms the state-of-the-art segmentation model both in accuracy and cost and enables correct MA morphological classification.
Protecting Intellectual Property of Generative Adversarial Networks from Ambiguity Attack
Feb 08, 2021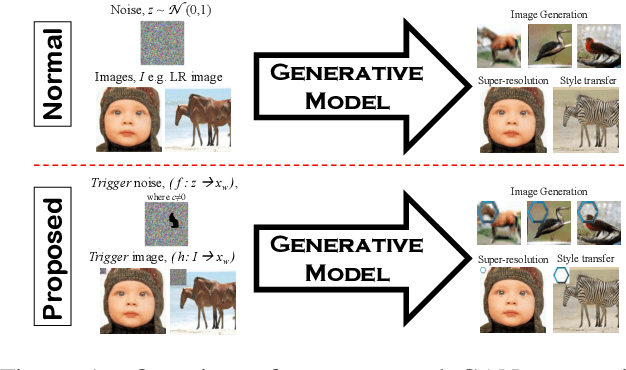



Ever since Machine Learning as a Service (MLaaS) emerges as a viable business that utilizes deep learning models to generate lucrative revenue, Intellectual Property Right (IPR) has become a major concern because these deep learning models can easily be replicated, shared, and re-distributed by any unauthorized third parties. To the best of our knowledge, one of the prominent deep learning models - Generative Adversarial Networks (GANs) which has been widely used to create photorealistic image are totally unprotected despite the existence of pioneering IPR protection methodology for Convolutional Neural Networks (CNNs). This paper therefore presents a complete protection framework in both black-box and white-box settings to enforce IPR protection on GANs. Empirically, we show that the proposed method does not compromise the original GANs performance (i.e. image generation, image super-resolution, style transfer), and at the same time, it is able to withstand both removal and ambiguity attacks against embedded watermarks.
Soccer Event Detection Using Deep Learning
Feb 08, 2021
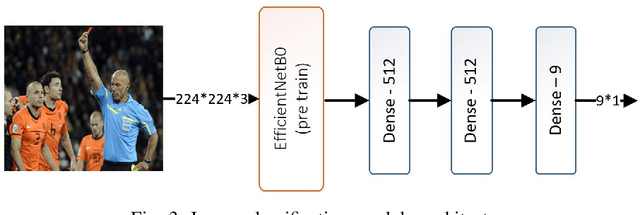
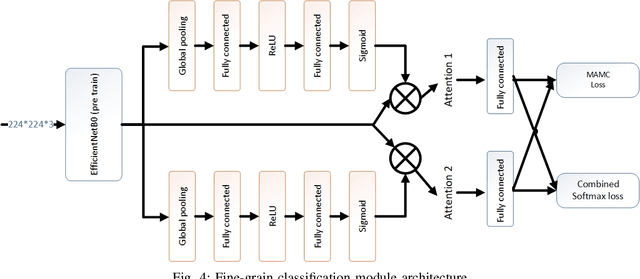
Event detection is an important step in extracting knowledge from the video. In this paper, we propose a deep learning approach to detect events in a soccer match emphasizing the distinction between images of red and yellow cards and the correct detection of the images of selected events from other images. This method includes the following three modules: i) the variational autoencoder (VAE) module to differentiate between soccer images and others image, ii) the image classification module to classify the images of events, and iii) the fine-grain image classification module to classify the images of red and yellow cards. Additionally, a new dataset was introduced for soccer images classification that is employed to train the networks mentioned in the paper. In the final section, 10 UEFA Champions League matches are used to evaluate the networks' performance and precision in detecting the events. The experiments demonstrate that the proposed method achieves better performance than state-of-the-art methods.
External Prior Guided Internal Prior Learning for Real-World Noisy Image Denoising
Oct 15, 2018



Most of existing image denoising methods learn image priors from either external data or the noisy image itself to remove noise. However, priors learned from external data may not be adaptive to the image to be denoised, while priors learned from the given noisy image may not be accurate due to the interference of corrupted noise. Meanwhile, the noise in real-world noisy images is very complex, which is hard to be described by simple distributions such as Gaussian distribution, making real-world noisy image denoising a very challenging problem. We propose to exploit the information in both external data and the given noisy image, and develop an external prior guided internal prior learning method for real-world noisy image denoising. We first learn external priors from an independent set of clean natural images. With the aid of learned external priors, we then learn internal priors from the given noisy image to refine the prior model. The external and internal priors are formulated as a set of orthogonal dictionaries to efficiently reconstruct the desired image. Extensive experiments are performed on several real-world noisy image datasets. The proposed method demonstrates highly competitive denoising performance, outperforming state-of-the-art denoising methods including those designed for real-world noisy images.
Using Low-rank Representation of Abundance Maps and Nonnegative Tensor Factorization for Hyperspectral Nonlinear Unmixing
Mar 30, 2021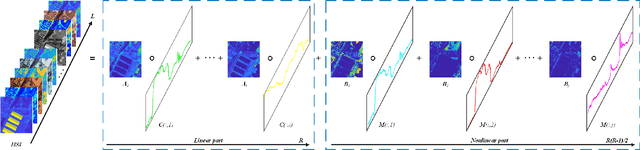

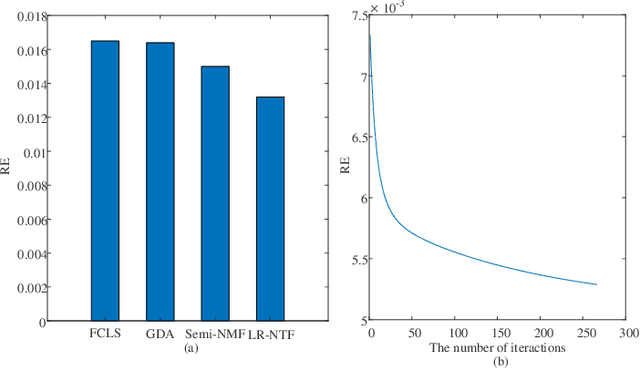
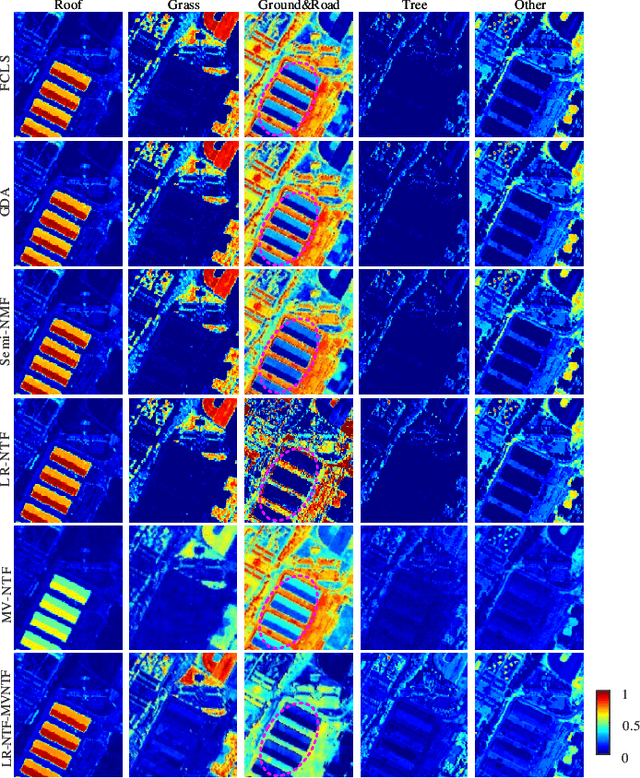
Tensor-based methods have been widely studied to attack inverse problems in hyperspectral imaging since a hyperspectral image (HSI) cube can be naturally represented as a third-order tensor, which can perfectly retain the spatial information in the image. In this article, we extend the linear tensor method to the nonlinear tensor method and propose a nonlinear low-rank tensor unmixing algorithm to solve the generalized bilinear model (GBM). Specifically, the linear and nonlinear parts of the GBM can both be expressed as tensors. Furthermore, the low-rank structures of abundance maps and nonlinear interaction abundance maps are exploited by minimizing their nuclear norm, thus taking full advantage of the high spatial correlation in HSIs. Synthetic and real-data experiments show that the low rank of abundance maps and nonlinear interaction abundance maps exploited in our method can improve the performance of the nonlinear unmixing. A MATLAB demo of this work will be available at https://github.com/LinaZhuang for the sake of reproducibility.
Class Introspection: A Novel Technique for Detecting Unlabeled Subclasses by Leveraging Classifier Explainability Methods
Jul 04, 2021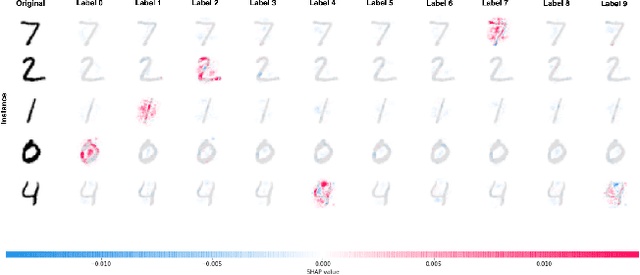
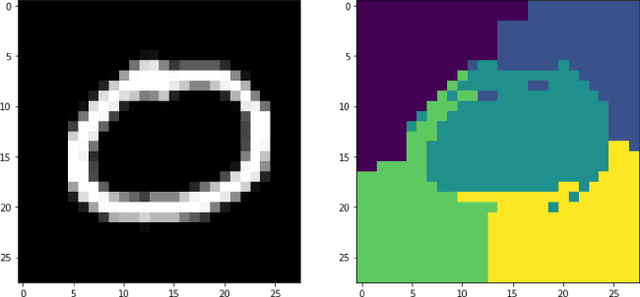
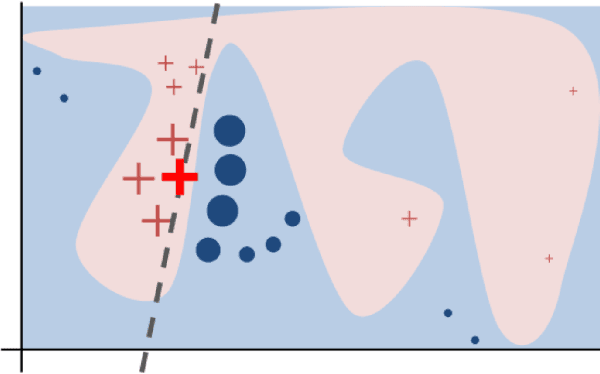

Detecting latent structure within a dataset is a crucial step in performing analysis of a dataset. However, existing state-of-the-art techniques for subclass discovery are limited: either they are limited to detecting very small numbers of outliers or they lack the statistical power to deal with complex data such as image or audio. This paper proposes a solution to this subclass discovery problem: by leveraging instance explanation methods, an existing classifier can be extended to detect latent classes via differences in the classifier's internal decisions about each instance. This works not only with simple classification techniques but also with deep neural networks, allowing for a powerful and flexible approach to detecting latent structure within datasets. Effectively, this represents a projection of the dataset into the classifier's "explanation space," and preliminary results show that this technique outperforms the baseline for the detection of latent classes even with limited processing. This paper also contains a pipeline for analyzing classifiers automatically, and a web application for interactively exploring the results from this technique.
Visual-Tactile Cross-Modal Data Generation using Residue-Fusion GAN with Feature-Matching and Perceptual Losses
Jul 12, 2021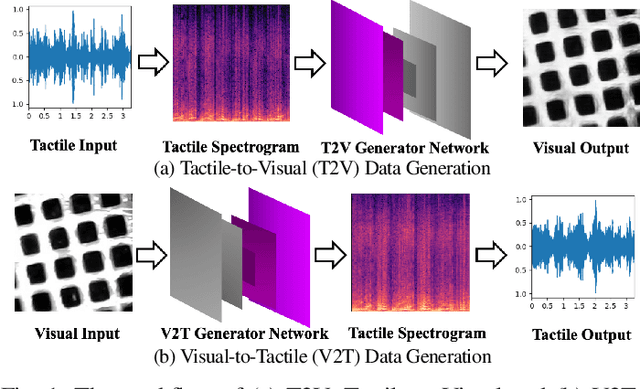
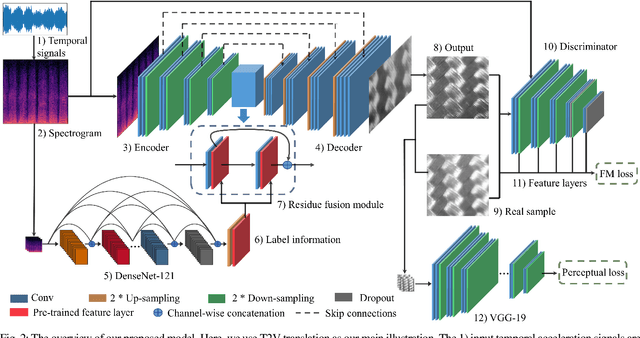
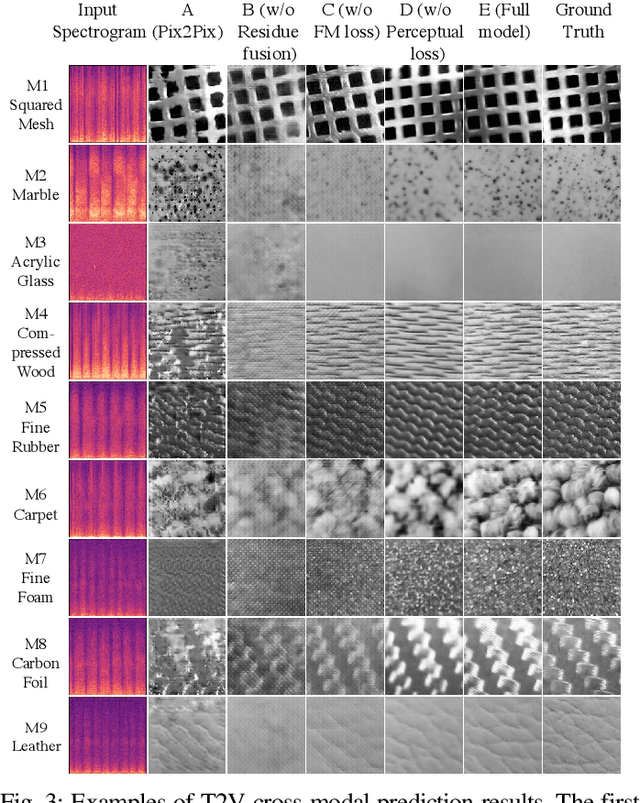
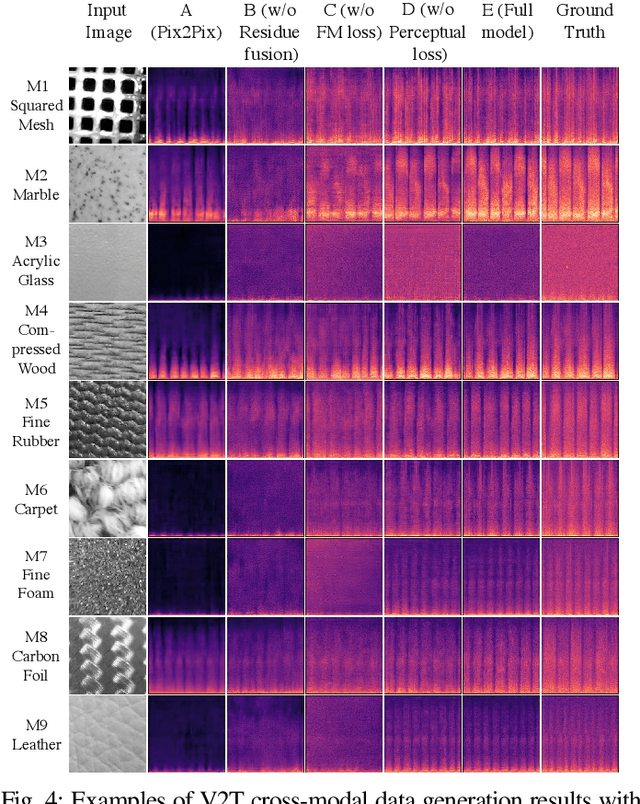
Existing psychophysical studies have revealed that the cross-modal visual-tactile perception is common for humans performing daily activities. However, it is still challenging to build the algorithmic mapping from one modality space to another, namely the cross-modal visual-tactile data translation/generation, which could be potentially important for robotic operation. In this paper, we propose a deep-learning-based approach for cross-modal visual-tactile data generation by leveraging the framework of the generative adversarial networks (GANs). Our approach takes the visual image of a material surface as the visual data, and the accelerometer signal induced by the pen-sliding movement on the surface as the tactile data. We adopt the conditional-GAN (cGAN) structure together with the residue-fusion (RF) module, and train the model with the additional feature-matching (FM) and perceptual losses to achieve the cross-modal data generation. The experimental results show that the inclusion of the RF module, and the FM and the perceptual losses significantly improves cross-modal data generation performance in terms of the classification accuracy upon the generated data and the visual similarity between the ground-truth and the generated data.
Adversarial Examples Make Strong Poisons
Jun 21, 2021

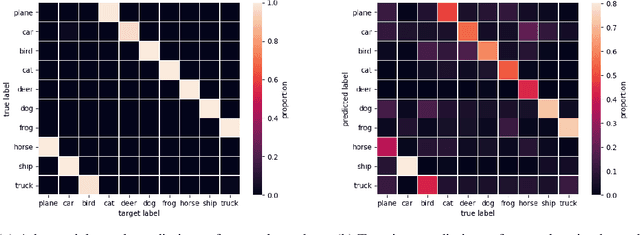

The adversarial machine learning literature is largely partitioned into evasion attacks on testing data and poisoning attacks on training data. In this work, we show that adversarial examples, originally intended for attacking pre-trained models, are even more effective for data poisoning than recent methods designed specifically for poisoning. Our findings indicate that adversarial examples, when assigned the original label of their natural base image, cannot be used to train a classifier for natural images. Furthermore, when adversarial examples are assigned their adversarial class label, they are useful for training. This suggests that adversarial examples contain useful semantic content, just with the ``wrong'' labels (according to a network, but not a human). Our method, adversarial poisoning, is substantially more effective than existing poisoning methods for secure dataset release, and we release a poisoned version of ImageNet, ImageNet-P, to encourage research into the strength of this form of data obfuscation.
Regularized Evolution for Image Classifier Architecture Search
Oct 26, 2018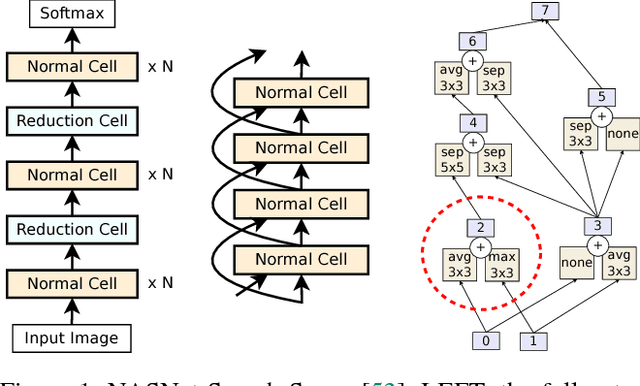
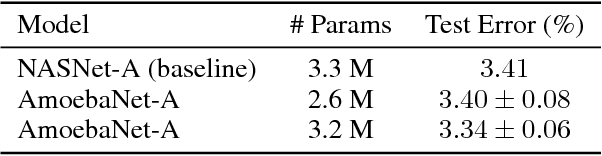
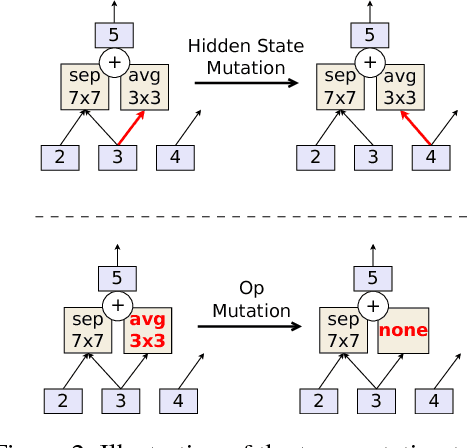
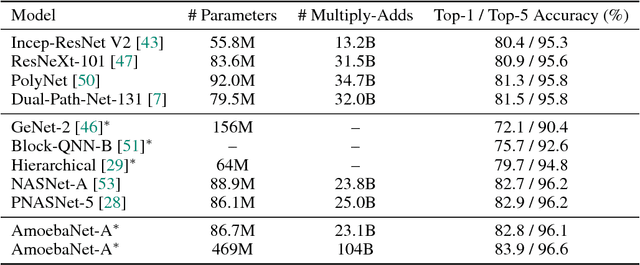
The effort devoted to hand-crafting neural network image classifiers has motivated the use of architecture search to discover them automatically. Although evolutionary algorithms have been repeatedly applied to neural network topologies, the image classifiers thus discovered have remained inferior to human-crafted ones. Here, we evolve an image classifier---AmoebaNet-A---that surpasses hand-designs for the first time. To do this, we modify the tournament selection evolutionary algorithm by introducing an age property to favor the younger genotypes. Matching size, AmoebaNet-A has comparable accuracy to current state-of-the-art ImageNet models discovered with more complex architecture-search methods. Scaled to larger size, AmoebaNet-A sets a new state-of-the-art 83.9% top-1 / 96.6% top-5 ImageNet accuracy. In a controlled comparison against a well known reinforcement learning algorithm, we give evidence that evolution can obtain results faster with the same hardware, especially at the earlier stages of the search. This is relevant when fewer compute resources are available. Evolution is, thus, a simple method to effectively discover high-quality architectures.
Look Twice: A Computational Model of Return Fixations across Tasks and Species
Jan 05, 2021
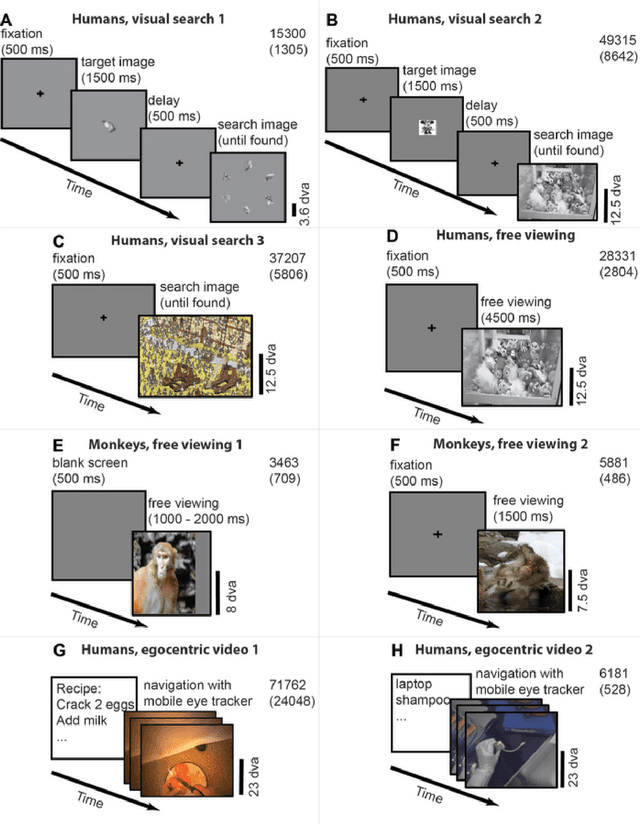
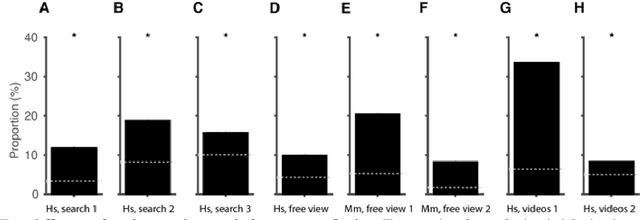
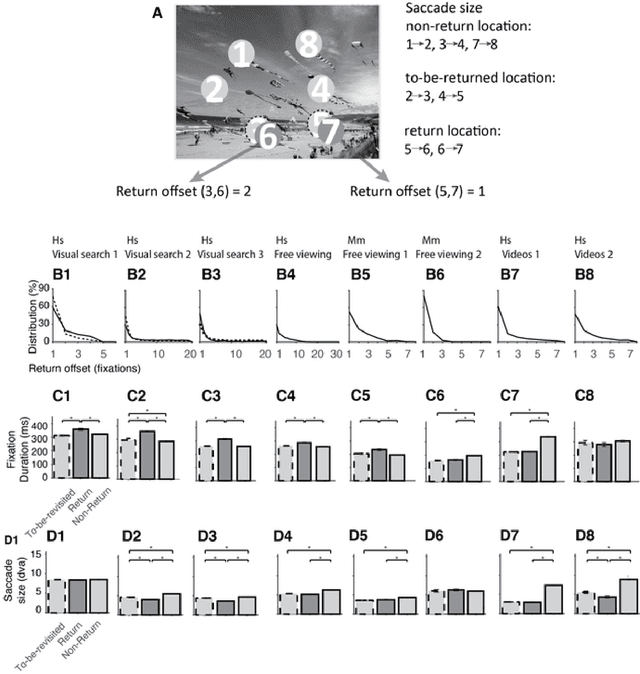
Saccadic eye movements allow animals to bring different parts of an image into high-resolution. During free viewing, inhibition of return incentivizes exploration by discouraging previously visited locations. Despite this inhibition, here we show that subjects make frequent return fixations. We systematically studied a total of 44,328 return fixations out of 217,440 fixations across different tasks, in monkeys and humans, and in static images or egocentric videos. The ubiquitous return fixations were consistent across subjects, tended to occur within short offsets, and were characterized by longer duration than non-return fixations. The locations of return fixations corresponded to image areas of higher saliency and higher similarity to the sought target during visual search tasks. We propose a biologically-inspired computational model that capitalizes on a deep convolutional neural network for object recognition to predict a sequence of fixations. Given an input image, the model computes four maps that constrain the location of the next saccade: a saliency map, a target similarity map, a saccade size map, and a memory map. The model exhibits frequent return fixations and approximates the properties of return fixations across tasks and species. The model provides initial steps towards capturing the trade-off between exploitation of informative image locations combined with exploration of novel image locations during scene viewing.