 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SCNet: Enhancing Few-Shot Semantic Segmentation by Self-Contrastive Background Prototypes
Apr 28, 2021
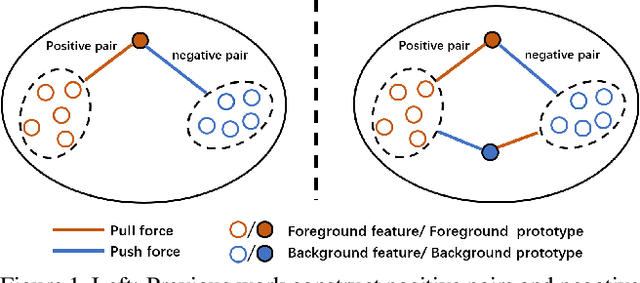
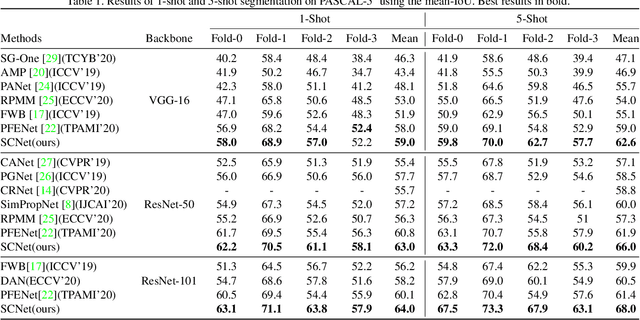
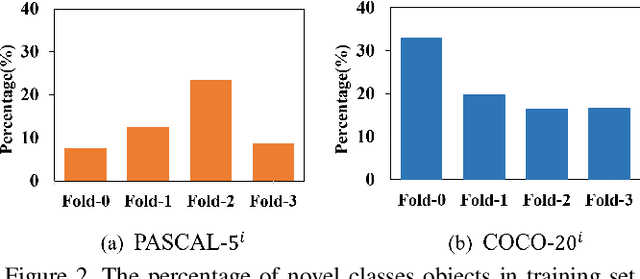
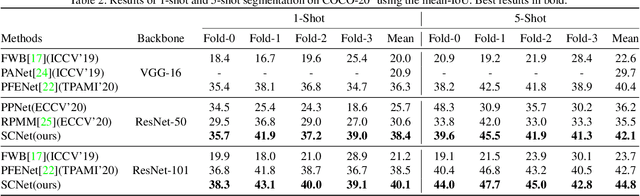
Few-shot semantic segmentation aims to segment novel-class objects in a query image with only a few annotated examples in support images. Most of advanced solutions exploit a metric learning framework that performs segmentation through matching each pixel to a learned foreground prototype. However, this framework suffers from biased classification due to incomplete construction of sample pairs with the foreground prototype only. To address this issue, in this paper, we introduce a complementary self-contrastive task into few-shot semantic segmentation. Our new model is able to associate the pixels in a region with the prototype of this region, no matter they are in the foreground or background. To this end, we generate self-contrastive background prototypes directly from the query image, with which we enable the construction of complete sample pairs and thus a complementary and auxiliary segmentation task to achieve the training of a better segmentation model. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ demonstrate clearly the superiority of our proposal. At no expense of inference efficiency, our model achieves state-of-the results in both 1-shot and 5-shot settings for few-shot semantic segmentation.
Coarse-to-Fine Searching for Efficient Generative Adversarial Networks
Apr 19, 2021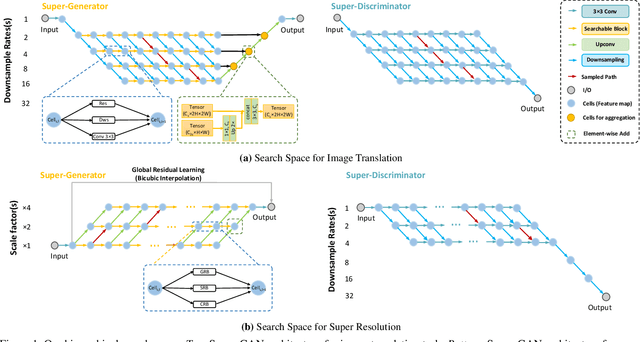
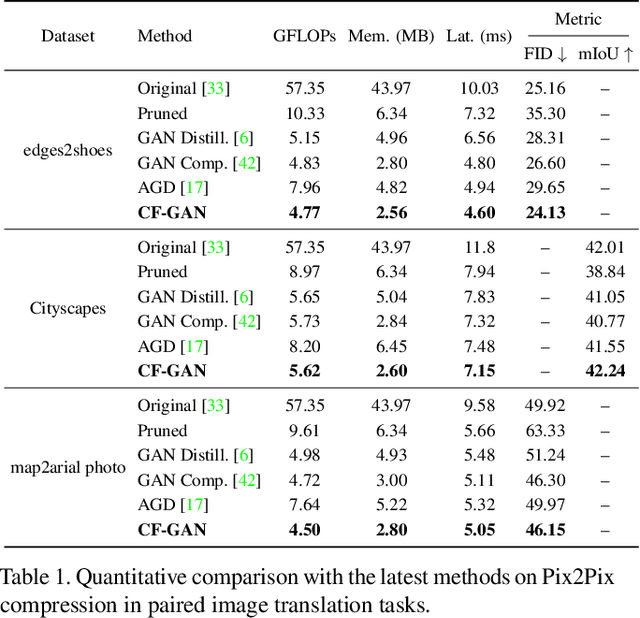
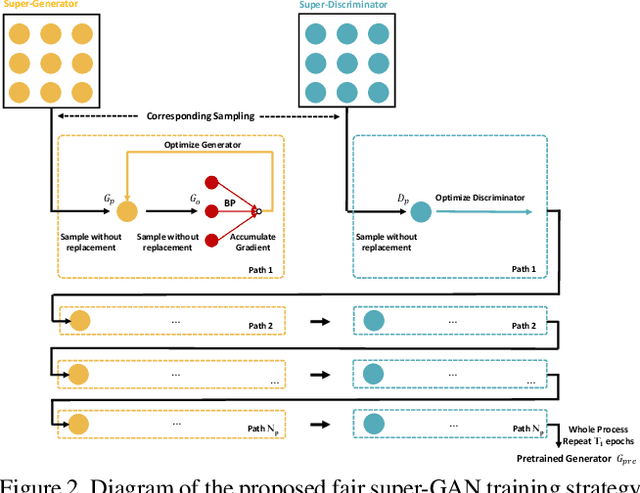
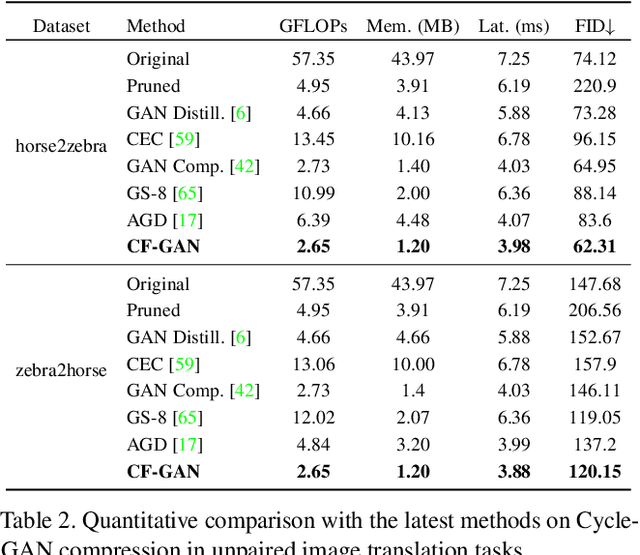
This paper studies the neural architecture search (NAS) problem for developing efficient generator networks. Compared with deep models for visual recognition tasks, generative adversarial network (GAN) are usually designed to conduct various complex image generation. We first discover an intact search space of generator networks including three dimensionalities, i.e., path, operator, channel for fully excavating the network performance. To reduce the huge search cost, we explore a coarse-to-fine search strategy which divides the overall search process into three sub-optimization problems accordingly. In addition, a fair supernet training approach is utilized to ensure that all sub-networks can be updated fairly and stably. Experiments results on benchmarks show that we can provide generator networks with better image quality and lower computational costs over the state-of-the-art methods. For example, with our method, it takes only about 8 GPU hours on the entire edges-to-shoes dataset to get a 2.56 MB model with a 24.13 FID score and 10 GPU hours on the entire Urban100 dataset to get a 1.49 MB model with a 24.94 PSNR score.
Resonant Tunnelling Diode Nano-Optoelectronic Spiking Nodes For Neuromorphic Information Processing
Jul 14, 2021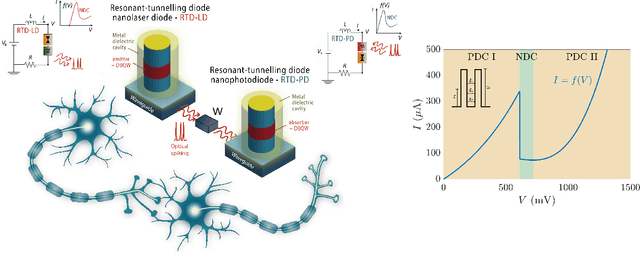
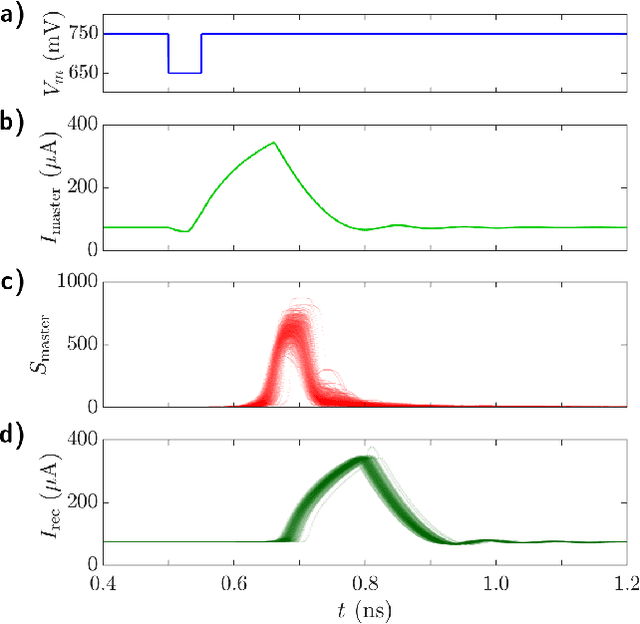
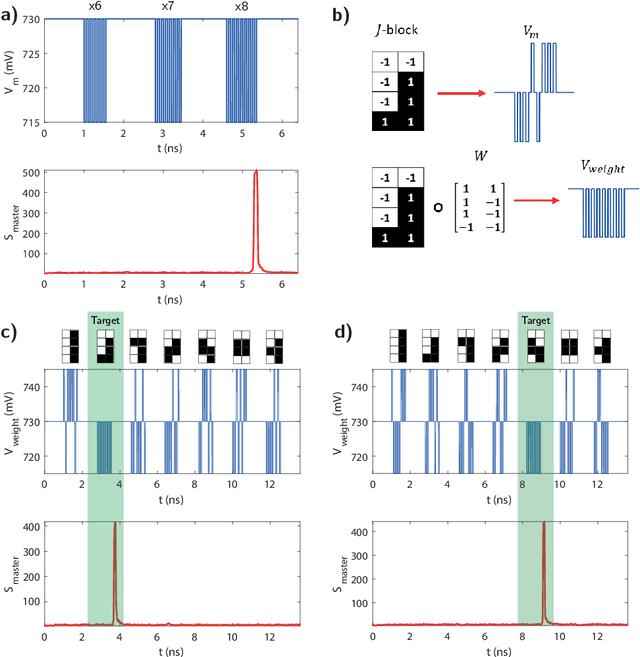
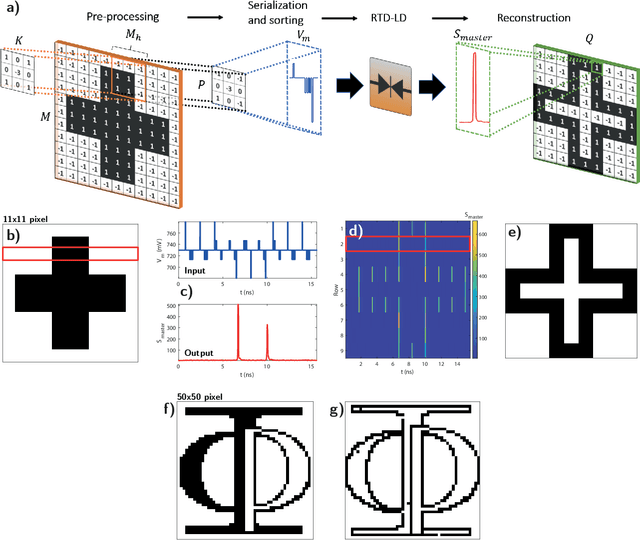
In this work, we introduce an optoelectronic spiking artificial neuron capable of operating at ultrafast rates ($\approx$ 100 ps/optical spike) and with low energy consumption ($<$ pJ/spike). The proposed system combines an excitable resonant tunnelling diode (RTD) element exhibiting negative differential conductance, coupled to a nanoscale light source (forming a master node) or a photodetector (forming a receiver node). We study numerically the spiking dynamical responses and information propagation functionality of an interconnected master-receiver RTD node system. Using the key functionality of pulse thresholding and integration, we utilize a single node to classify sequential pulse patterns and perform convolutional functionality for image feature (edge) recognition. We also demonstrate an optically-interconnected spiking neural network model for processing of spatiotemporal data at over 10 Gbps with high inference accuracy. Finally, we demonstrate an off-chip supervised learning approach utilizing spike-timing dependent plasticity for the RTD-enabled photonic spiking neural network. These results demonstrate the potential and viability of RTD spiking nodes for low footprint, low energy, high-speed optoelectronic realization of neuromorphic hardware.
ADeLA: Automatic Dense Labeling with Attention for Viewpoint Adaptation in Semantic Segmentation
Jul 29, 2021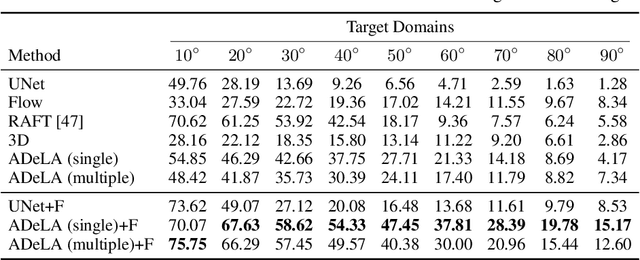

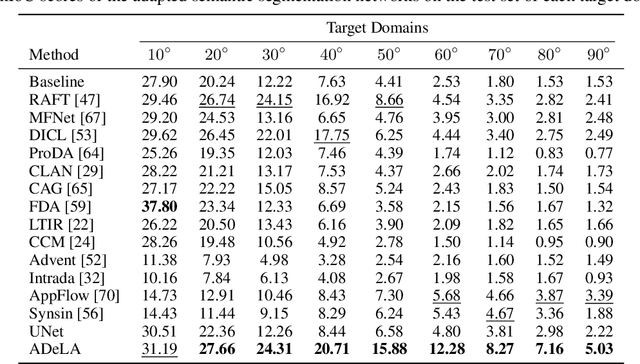

We describe an unsupervised domain adaptation method for image content shift caused by viewpoint changes for a semantic segmentation task. Most existing methods perform domain alignment in a shared space and assume that the mapping from the aligned space to the output is transferable. However, the novel content induced by viewpoint changes may nullify such a space for effective alignments, thus resulting in negative adaptation. Our method works without aligning any statistics of the images between the two domains. Instead, it utilizes a view transformation network trained only on color images to hallucinate the semantic images for the target. Despite the lack of supervision, the view transformation network can still generalize to semantic images thanks to the inductive bias introduced by the attention mechanism. Furthermore, to resolve ambiguities in converting the semantic images to semantic labels, we treat the view transformation network as a functional representation of an unknown mapping implied by the color images and propose functional label hallucination to generate pseudo-labels in the target domain. Our method surpasses baselines built on state-of-the-art correspondence estimation and view synthesis methods. Moreover, it outperforms the state-of-the-art unsupervised domain adaptation methods that utilize self-training and adversarial domain alignment. Our code and dataset will be made publicly available.
Spatio-Temporal Matching for Siamese Visual Tracking
May 06, 2021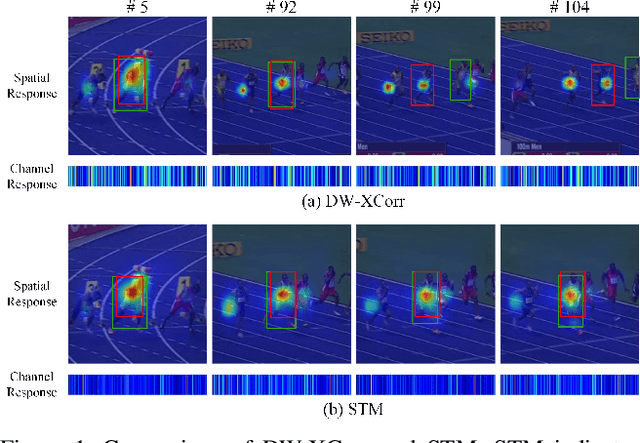
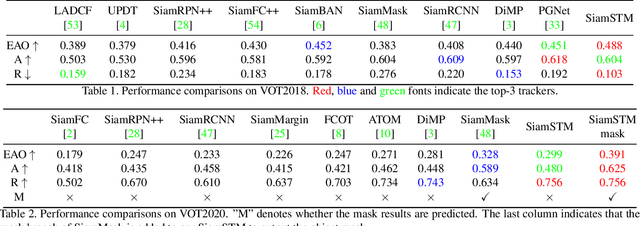
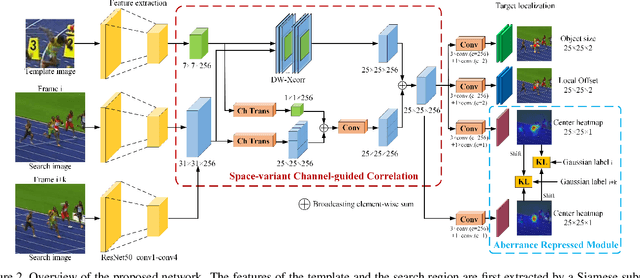
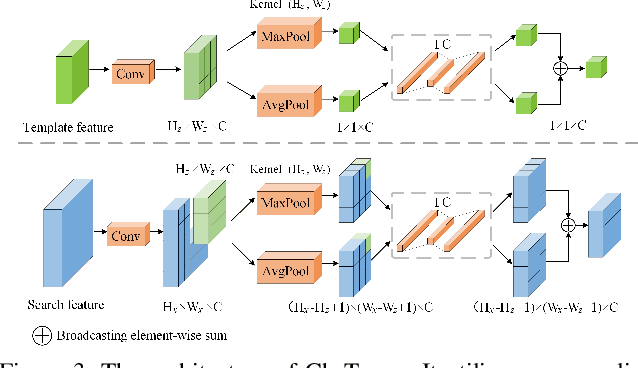
Similarity matching is a core operation in Siamese trackers. Most Siamese trackers carry out similarity learning via cross correlation that originates from the image matching field. However, unlike 2-D image matching, the matching network in object tracking requires 4-D information (height, width, channel and time). Cross correlation neglects the information from channel and time dimensions, and thus produces ambiguous matching. This paper proposes a spatio-temporal matching process to thoroughly explore the capability of 4-D matching in space (height, width and channel) and time. In spatial matching, we introduce a space-variant channel-guided correlation (SVC-Corr) to recalibrate channel-wise feature responses for each spatial location, which can guide the generation of the target-aware matching features. In temporal matching, we investigate the time-domain context relations of the target and the background and develop an aberrance repressed module (ARM). By restricting the abrupt alteration in the interframe response maps, our ARM can clearly suppress aberrances and thus enables more robust and accurate object tracking. Furthermore, a novel anchor-free tracking framework is presented to accommodate these innovations. Experiments on challenging benchmarks including OTB100, VOT2018, VOT2020, GOT-10k, and LaSOT demonstrate the state-of-the-art performance of the proposed method.
Self-Supervised Multi-Modal Alignment for Whole Body Medical Imaging
Jul 14, 2021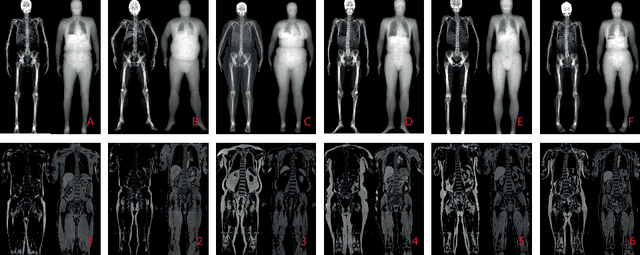
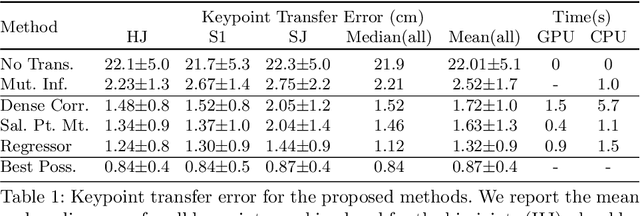
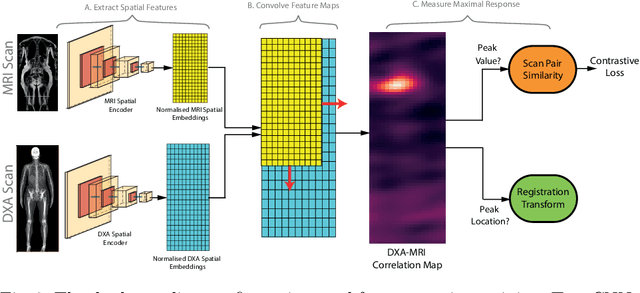
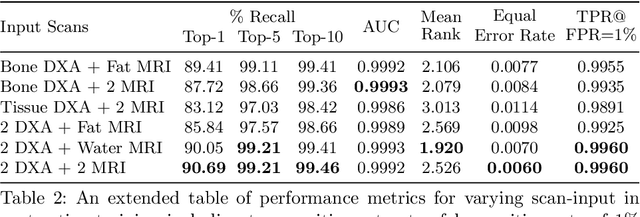
This paper explores the use of self-supervised deep learning in medical imaging in cases where two scan modalities are available for the same subject. Specifically, we use a large publicly-available dataset of over 20,000 subjects from the UK Biobank with both whole body Dixon technique magnetic resonance (MR) scans and also dual-energy x-ray absorptiometry (DXA) scans. We make three contributions: (i) We introduce a multi-modal image-matching contrastive framework, that is able to learn to match different-modality scans of the same subject with high accuracy. (ii) Without any adaption, we show that the correspondences learnt during this contrastive training step can be used to perform automatic cross-modal scan registration in a completely unsupervised manner. (iii) Finally, we use these registrations to transfer segmentation maps from the DXA scans to the MR scans where they are used to train a network to segment anatomical regions without requiring ground-truth MR examples. To aid further research, our code will be made publicly available.
Image Forensics: Detecting duplication of scientific images with manipulation-invariant image similarity
Aug 22, 2018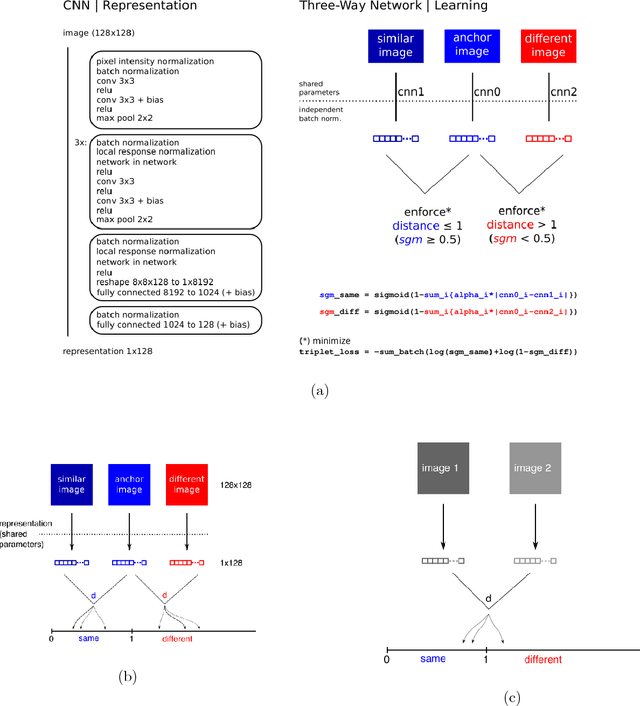
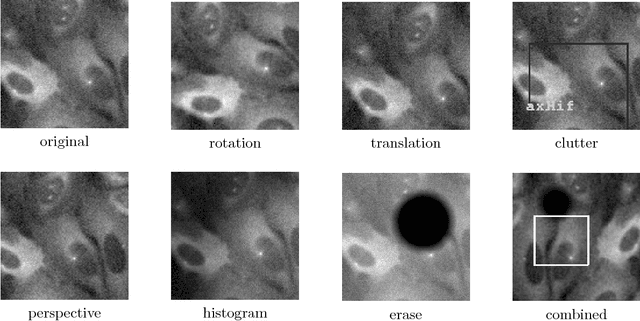
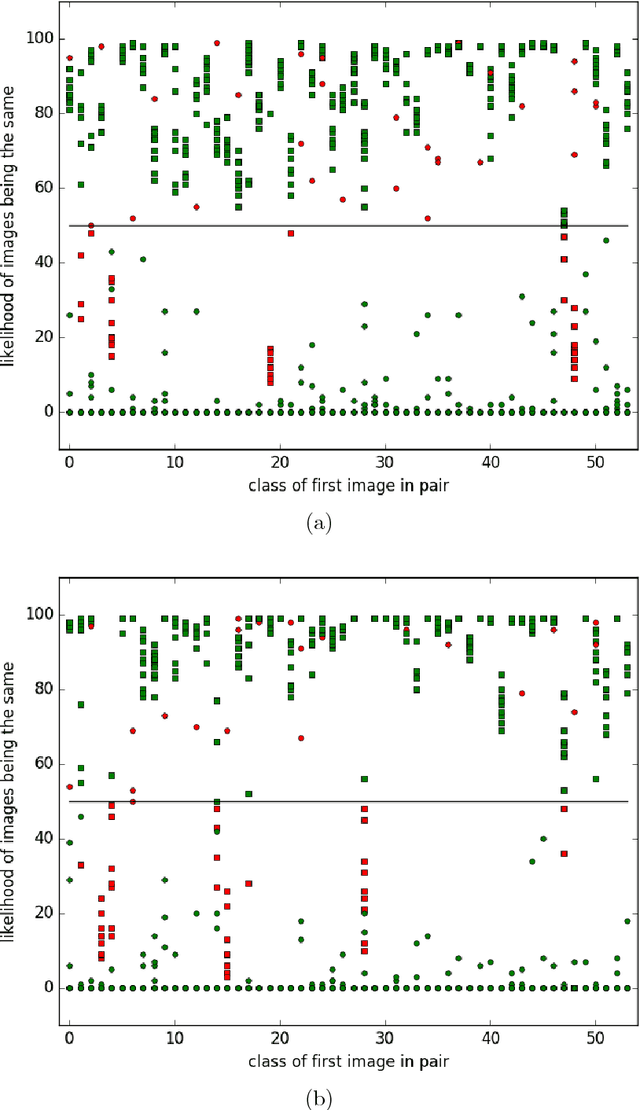
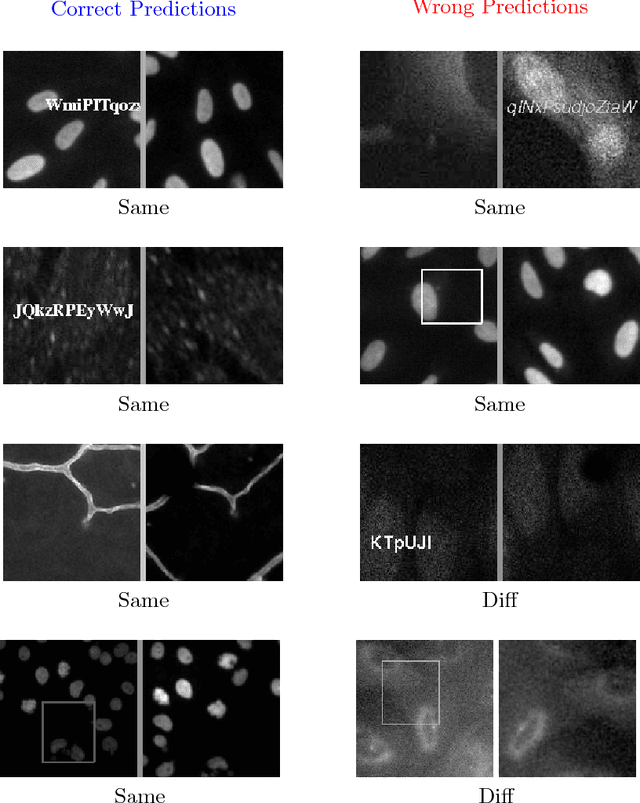
Manipulation and re-use of images in scientific publications is a concerning problem that currently lacks a scalable solution. Current tools for detecting image duplication are mostly manual or semi-automated, despite the availability of an overwhelming target dataset for a learning-based approach. This paper addresses the problem of determining if, given two images, one is a manipulated version of the other by means of copy, rotation, translation, scale, perspective transform, histogram adjustment, or partial erasing. We propose a data-driven solution based on a 3-branch Siamese Convolutional Neural Network. The ConvNet model is trained to map images into a 128-dimensional space, where the Euclidean distance between duplicate images is smaller than or equal to 1, and the distance between unique images is greater than 1. Our results suggest that such an approach has the potential to improve surveillance of the published and in-peer-review literature for image manipulation.
ResizeMix: Mixing Data with Preserved Object Information and True Labels
Dec 21, 2020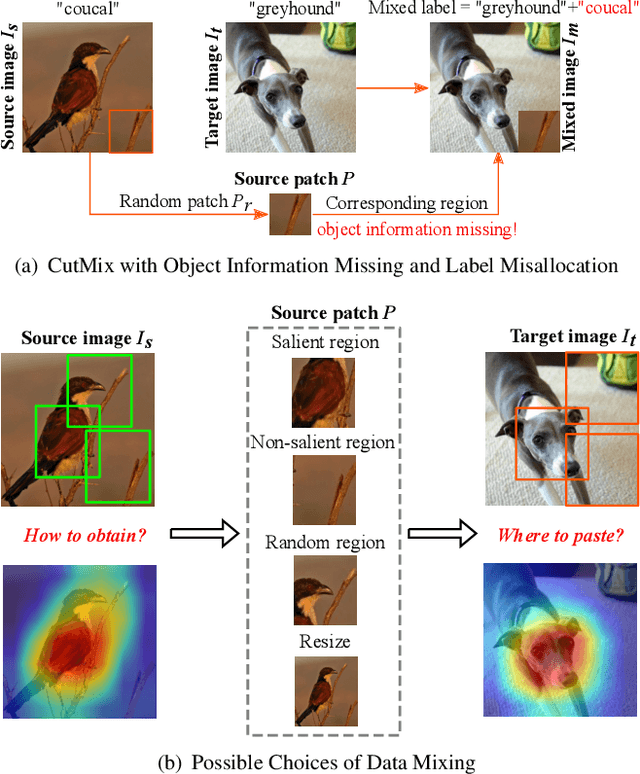
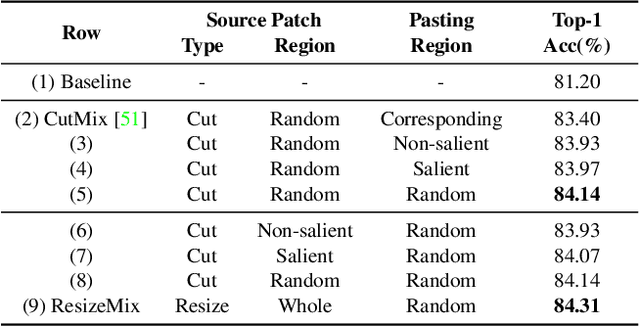
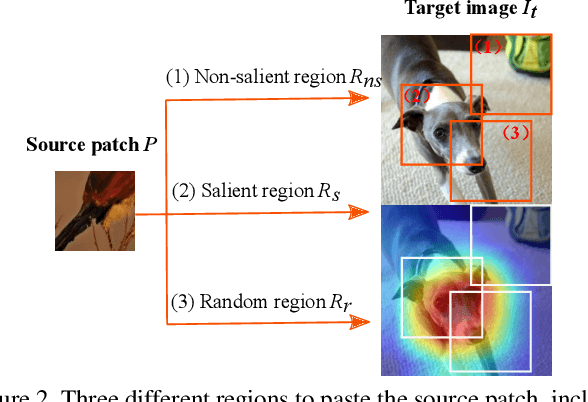
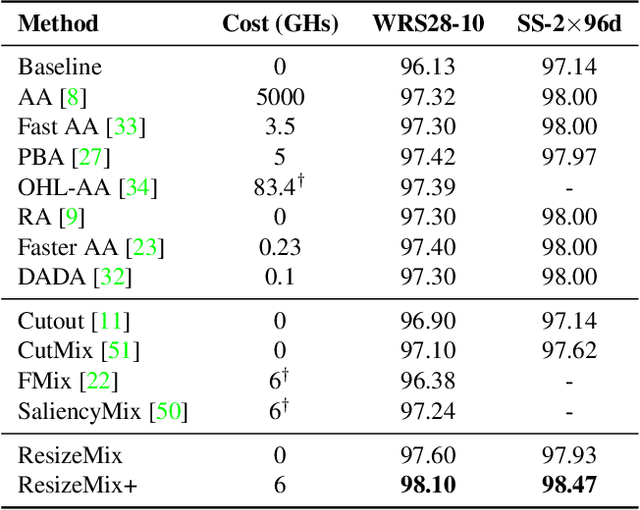
Data augmentation is a powerful technique to increase the diversity of data, which can effectively improve the generalization ability of neural networks in image recognition tasks. Recent data mixing based augmentation strategies have achieved great success. Especially, CutMix uses a simple but effective method to improve the classifiers by randomly cropping a patch from one image and pasting it on another image. To further promote the performance of CutMix, a series of works explore to use the saliency information of the image to guide the mixing. We systematically study the importance of the saliency information for mixing data, and find that the saliency information is not so necessary for promoting the augmentation performance. Furthermore, we find that the cutting based data mixing methods carry two problems of label misallocation and object information missing, which cannot be resolved simultaneously. We propose a more effective but very easily implemented method, namely ResizeMix. We mix the data by directly resizing the source image to a small patch and paste it on another image. The obtained patch preserves more substantial object information compared with conventional cut-based methods. ResizeMix shows evident advantages over CutMix and the saliency-guided methods on both image classification and object detection tasks without additional computation cost, which even outperforms most costly search-based automatic augmentation methods.
CodedStereo: Learned Phase Masks for Large Depth-of-field Stereo
Apr 09, 2021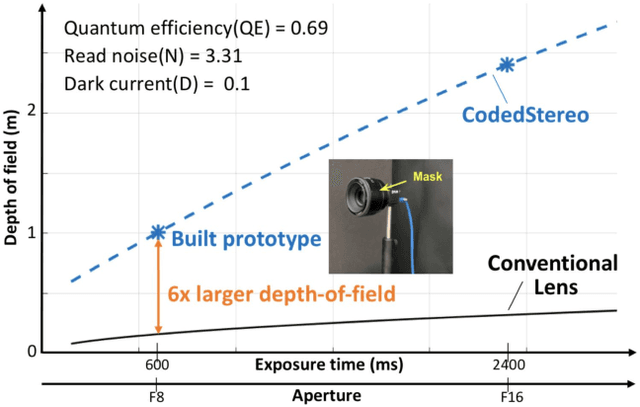
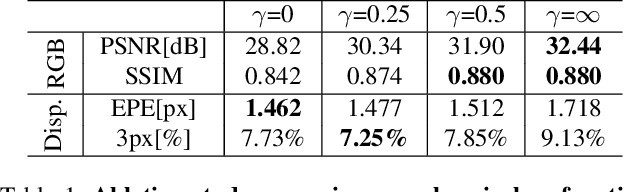
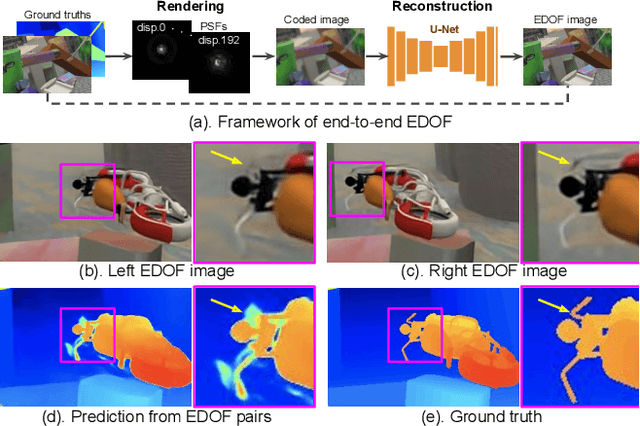
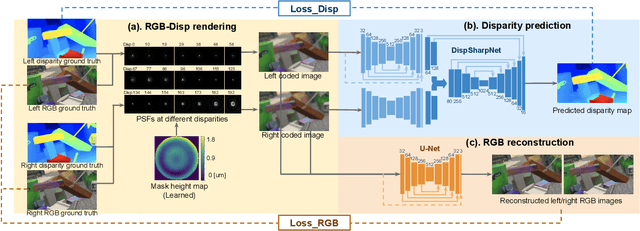
Conventional stereo suffers from a fundamental trade-off between imaging volume and signal-to-noise ratio (SNR) -- due to the conflicting impact of aperture size on both these variables. Inspired by the extended depth of field cameras, we propose a novel end-to-end learning-based technique to overcome this limitation, by introducing a phase mask at the aperture plane of the cameras in a stereo imaging system. The phase mask creates a depth-dependent point spread function, allowing us to recover sharp image texture and stereo correspondence over a significantly extended depth of field (EDOF) than conventional stereo. The phase mask pattern, the EDOF image reconstruction, and the stereo disparity estimation are all trained together using an end-to-end learned deep neural network. We perform theoretical analysis and characterization of the proposed approach and show a 6x increase in volume that can be imaged in simulation. We also build an experimental prototype and validate the approach using real-world results acquired using this prototype system.
Rethinking and Improving Relative Position Encoding for Vision Transformer
Jul 29, 2021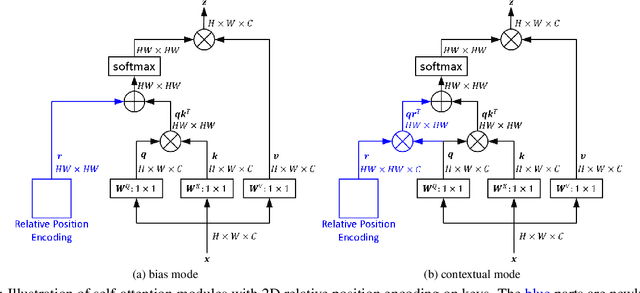
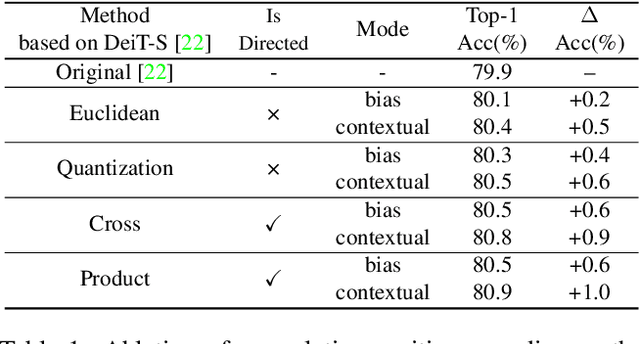
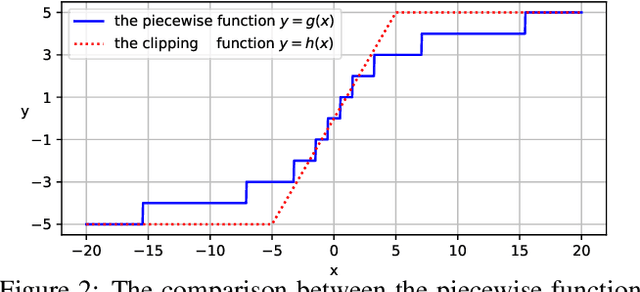
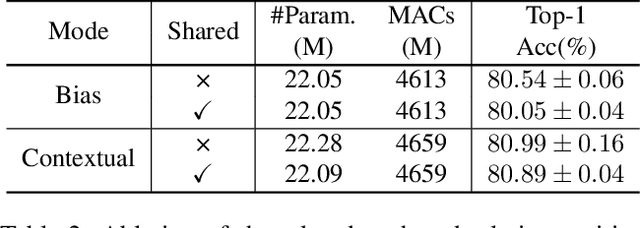
Relative position encoding (RPE) is important for transformer to capture sequence ordering of input tokens. General efficacy has been proven in natural language processing. However, in computer vision, its efficacy is not well studied and even remains controversial, e.g., whether relative position encoding can work equally well as absolute position? In order to clarify this, we first review existing relative position encoding methods and analyze their pros and cons when applied in vision transformers. We then propose new relative position encoding methods dedicated to 2D images, called image RPE (iRPE). Our methods consider directional relative distance modeling as well as the interactions between queries and relative position embeddings in self-attention mechanism. The proposed iRPE methods are simple and lightweight. They can be easily plugged into transformer blocks. Experiments demonstrate that solely due to the proposed encoding methods, DeiT and DETR obtain up to 1.5% (top-1 Acc) and 1.3% (mAP) stable improvements over their original versions on ImageNet and COCO respectively, without tuning any extra hyperparameters such as learning rate and weight decay. Our ablation and analysis also yield interesting findings, some of which run counter to previous understanding. Code and models are open-sourced at https://github.com/microsoft/Cream/tree/main/iRPE.