 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Visual Attention-Based Transfer Clustering
Jul 06, 2021

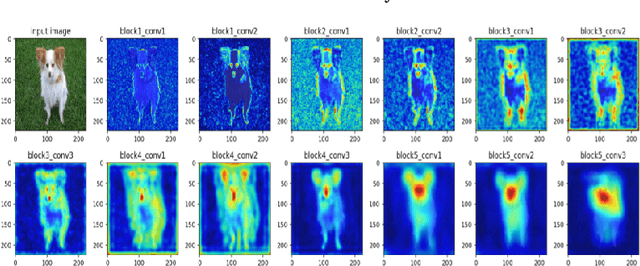
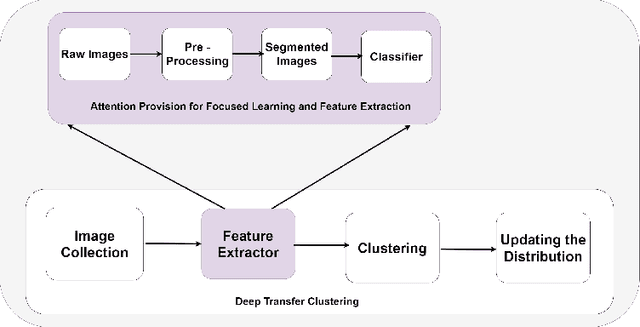
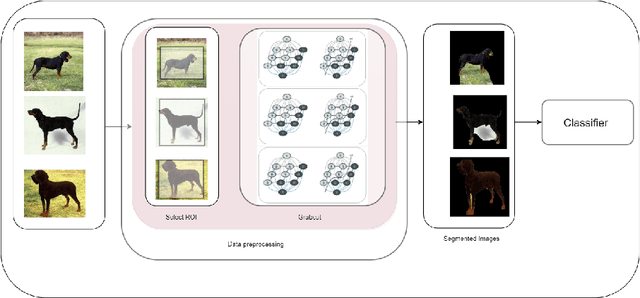
In this paper, we propose a methodology to improvise the technique of deep transfer clustering (DTC) when applied to the less variant data distribution. Clustering can be considered as the most important unsupervised learning problem. A simple definition of clustering can be stated as "the process of organizing objects into groups, whose members are similar in some way". Image clustering is a crucial but challenging task in the domain machine learning and computer vision. We have discussed the clustering of the data collection where the data is less variant. We have discussed the improvement by using attention-based classifiers rather than regular classifiers as the initial feature extractors in the deep transfer clustering. We have enforced the model to learn only the required region of interest in the images to get the differentiable and robust features that do not take into account the background. This paper is the improvement of the existing deep transfer clustering for less variant data distribution.
KVT: k-NN Attention for Boosting Vision Transformers
May 28, 2021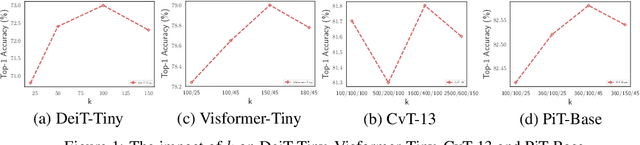
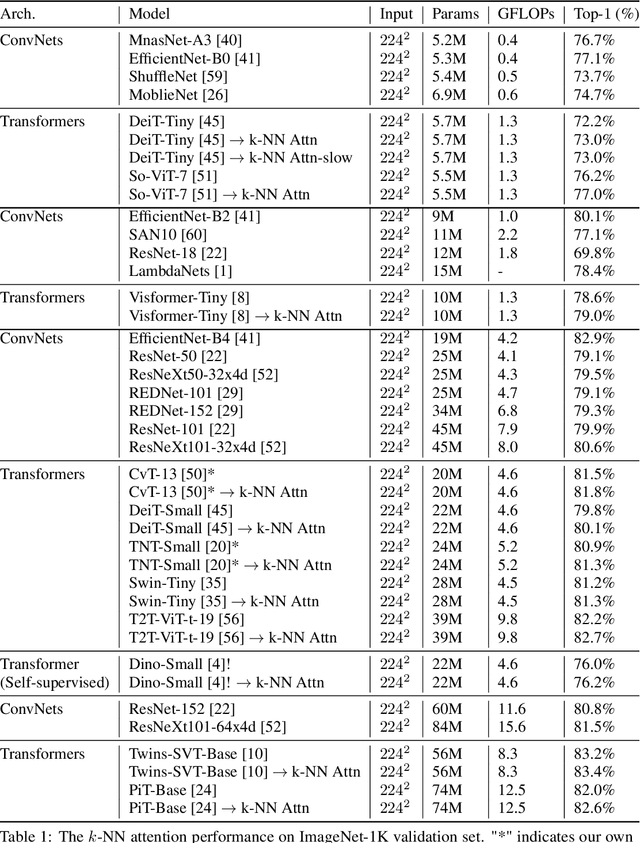
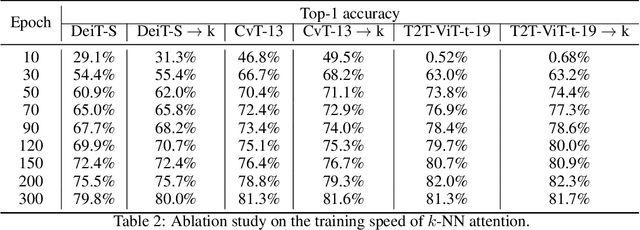
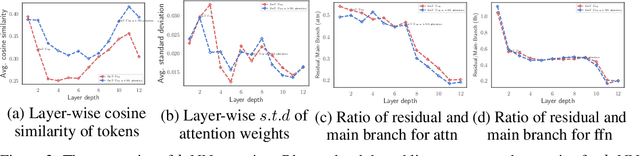
Convolutional Neural Networks (CNNs) have dominated computer vision for years, due to its ability in capturing locality and translation invariance. Recently, many vision transformer architectures have been proposed and they show promising performance. A key component in vision transformers is the fully-connected self-attention which is more powerful than CNNs in modelling long range dependencies. However, since the current dense self-attention uses all image patches (tokens) to compute attention matrix, it may neglect locality of images patches and involve noisy tokens (e.g., clutter background and occlusion), leading to a slow training process and potentially degradation of performance. To address these problems, we propose a sparse attention scheme, dubbed k-NN attention, for boosting vision transformers. Specifically, instead of involving all the tokens for attention matrix calculation, we only select the top-k similar tokens from the keys for each query to compute the attention map. The proposed k-NN attention naturally inherits the local bias of CNNs without introducing convolutional operations, as nearby tokens tend to be more similar than others. In addition, the k-NN attention allows for the exploration of long range correlation and at the same time filter out irrelevant tokens by choosing the most similar tokens from the entire image. Despite its simplicity, we verify, both theoretically and empirically, that $k$-NN attention is powerful in distilling noise from input tokens and in speeding up training. Extensive experiments are conducted by using ten different vision transformer architectures to verify that the proposed k-NN attention can work with any existing transformer architectures to improve its prediction performance.
SESF-Fuse: An Unsupervised Deep Model for Multi-Focus Image Fusion
Aug 05, 2019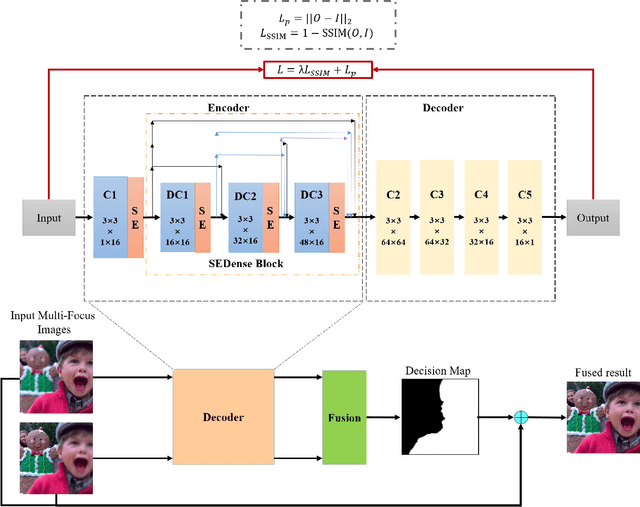
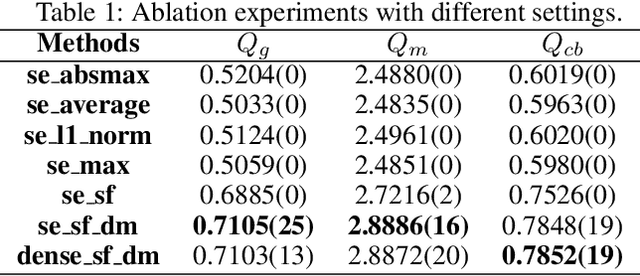
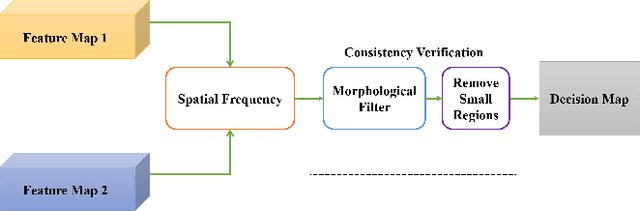
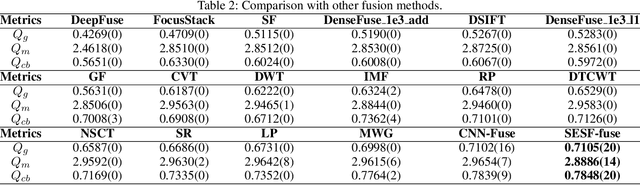
In this work, we propose a novel unsupervised deep learning model to address multi-focus image fusion problem. First, we train an encoder-decoder network in unsupervised manner to acquire deep feature of input images. And then we utilize these features and spatial frequency to measure activity level and decision map. Finally, we apply some consistency verification methods to adjust the decision map and draw out fused result. The key point behind of proposed method is that only the objects within the depth-of-field (DOF) have sharp appearance in the photograph while other objects are likely to be blurred. In contrast to previous works, our method analyzes sharp appearance in deep feature instead of original image. Experimental results demonstrate that the proposed method achieves the state-of-art fusion performance compared to existing 16 fusion methods in objective and subjective assessment.
Self-Supervised Regional and Temporal Auxiliary Tasks for Facial Action Unit Recognition
Jul 30, 2021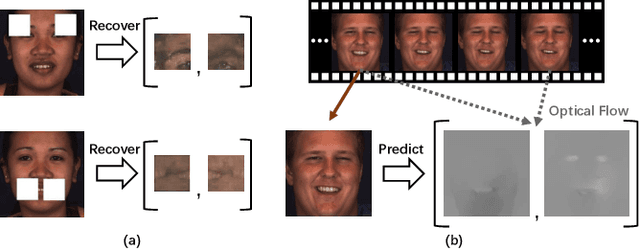
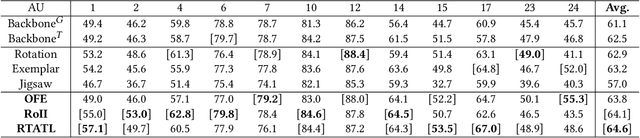
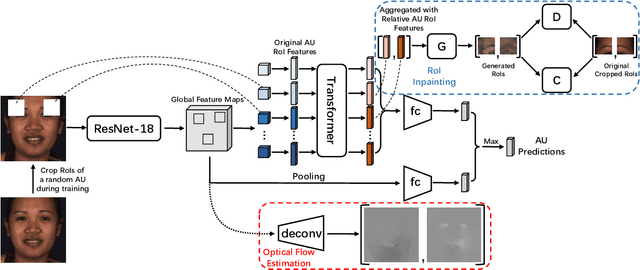
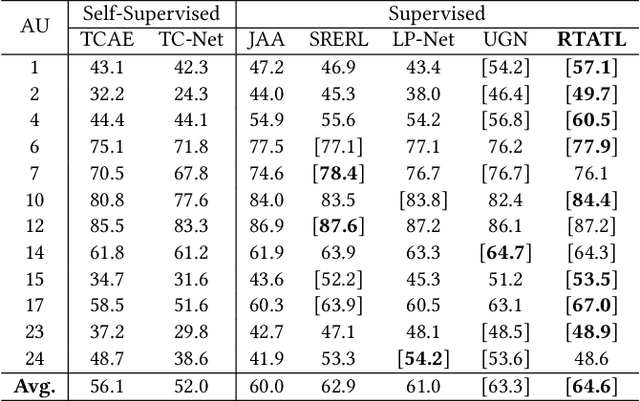
Automatic facial action unit (AU) recognition is a challenging task due to the scarcity of manual annotations. To alleviate this problem, a large amount of efforts has been dedicated to exploiting various methods which leverage numerous unlabeled data. However, many aspects with regard to some unique properties of AUs, such as the regional and relational characteristics, are not sufficiently explored in previous works. Motivated by this, we take the AU properties into consideration and propose two auxiliary AU related tasks to bridge the gap between limited annotations and the model performance in a self-supervised manner via the unlabeled data. Specifically, to enhance the discrimination of regional features with AU relation embedding, we design a task of RoI inpainting to recover the randomly cropped AU patches. Meanwhile, a single image based optical flow estimation task is proposed to leverage the dynamic change of facial muscles and encode the motion information into the global feature representation. Based on these two self-supervised auxiliary tasks, local features, mutual relation and motion cues of AUs are better captured in the backbone network with the proposed regional and temporal based auxiliary task learning (RTATL) framework. Extensive experiments on BP4D and DISFA demonstrate the superiority of our method and new state-of-the-art performances are achieved.
Multi-Modality Generative Adversarial Networks with Tumor Consistency Loss for Brain MR Image Synthesis
May 02, 2020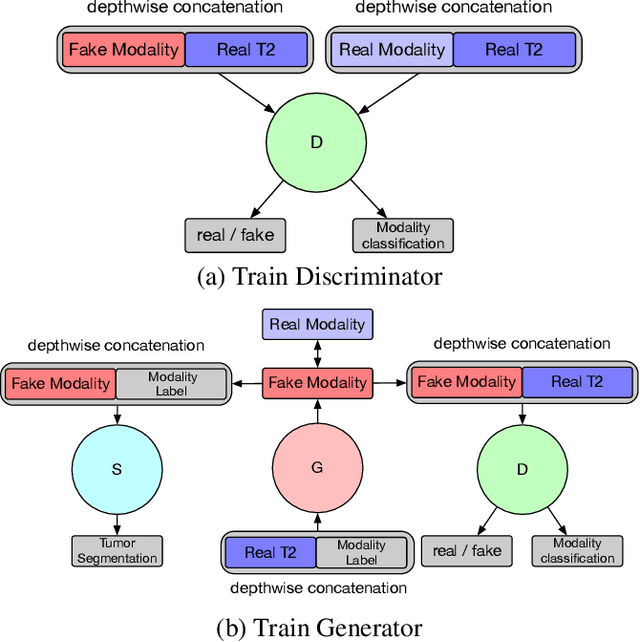
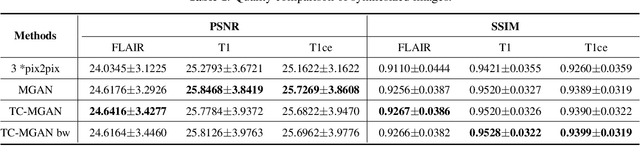
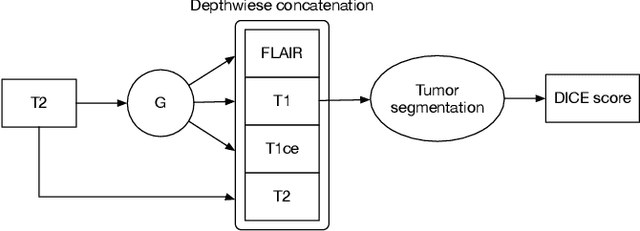
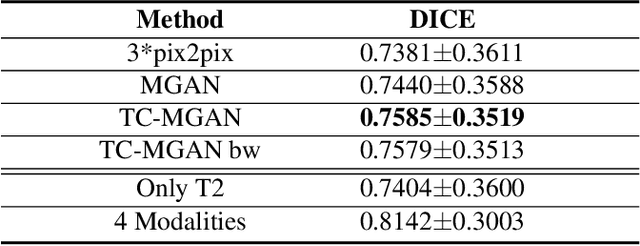
Magnetic Resonance (MR) images of different modalities can provide complementary information for clinical diagnosis, but whole modalities are often costly to access. Most existing methods only focus on synthesizing missing images between two modalities, which limits their robustness and efficiency when multiple modalities are missing. To address this problem, we propose a multi-modality generative adversarial network (MGAN) to synthesize three high-quality MR modalities (FLAIR, T1 and T1ce) from one MR modality T2 simultaneously. The experimental results show that the quality of the synthesized images by our proposed methods is better than the one synthesized by the baseline model, pix2pix. Besides, for MR brain image synthesis, it is important to preserve the critical tumor information in the generated modalities, so we further introduce a multi-modality tumor consistency loss to MGAN, called TC-MGAN. We use the synthesized modalities by TC-MGAN to boost the tumor segmentation accuracy, and the results demonstrate its effectiveness.
Query2Label: A Simple Transformer Way to Multi-Label Classification
Jul 22, 2021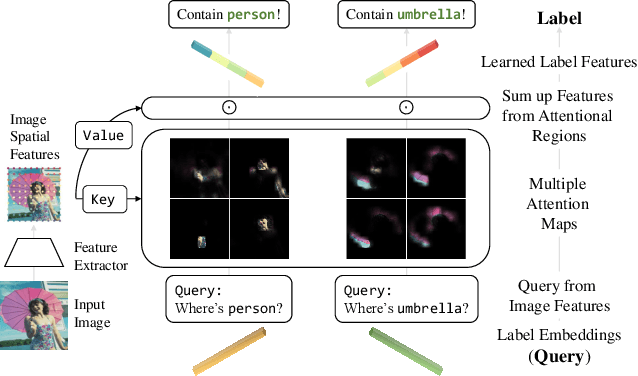
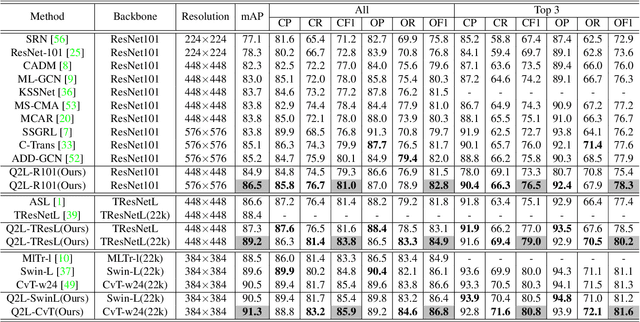
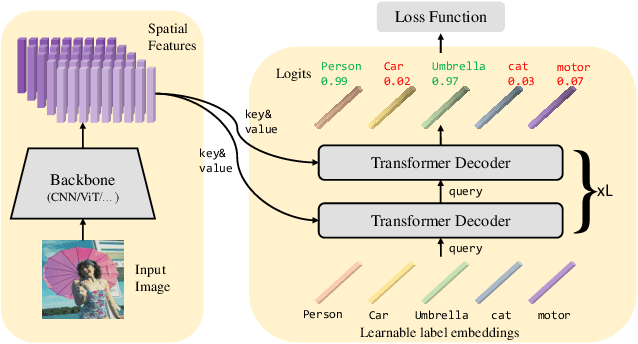
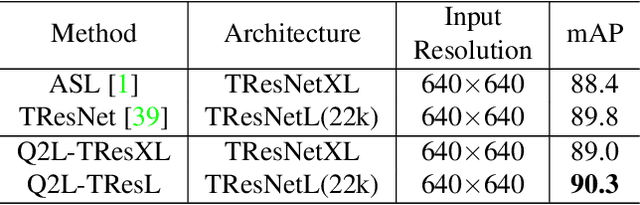
This paper presents a simple and effective approach to solving the multi-label classification problem. The proposed approach leverages Transformer decoders to query the existence of a class label. The use of Transformer is rooted in the need of extracting local discriminative features adaptively for different labels, which is a strongly desired property due to the existence of multiple objects in one image. The built-in cross-attention module in the Transformer decoder offers an effective way to use label embeddings as queries to probe and pool class-related features from a feature map computed by a vision backbone for subsequent binary classifications. Compared with prior works, the new framework is simple, using standard Transformers and vision backbones, and effective, consistently outperforming all previous works on five multi-label classification data sets, including MS-COCO, PASCAL VOC, NUS-WIDE, and Visual Genome. Particularly, we establish $91.3\%$ mAP on MS-COCO. We hope its compact structure, simple implementation, and superior performance serve as a strong baseline for multi-label classification tasks and future studies. The code will be available soon at https://github.com/SlongLiu/query2labels.
Few-Shot Model Adaptation for Customized Facial Landmark Detection, Segmentation, Stylization and Shadow Removal
Apr 19, 2021
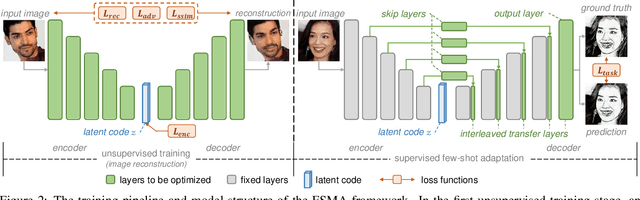
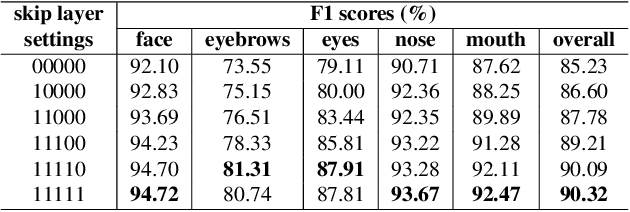
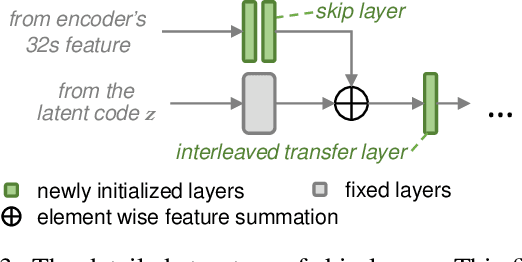
Despite excellent progress has been made, the performance of deep learning based algorithms still heavily rely on specific datasets, which are difficult to extend due to labor-intensive labeling. Moreover, because of the advancement of new applications, initial definition of data annotations might not always meet the requirements of new functionalities. Thus, there is always a great demand in customized data annotations. To address the above issues, we propose the Few-Shot Model Adaptation (FSMA) framework and demonstrate its potential on several important tasks on Faces. The FSMA first acquires robust facial image embeddings by training an adversarial auto-encoder using large-scale unlabeled data. Then the model is equipped with feature adaptation and fusion layers, and adapts to the target task efficiently using a minimal amount of annotated images. The FSMA framework is prominent in its versatility across a wide range of facial image applications. The FSMA achieves state-of-the-art few-shot landmark detection performance and it offers satisfying solutions for few-shot face segmentation, stylization and facial shadow removal tasks for the first time.
Adversarial Robustness Study of Convolutional Neural Network for Lumbar Disk Shape Reconstruction from MR images
Feb 04, 2021
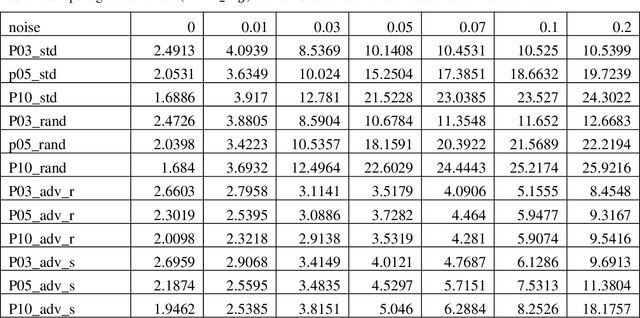
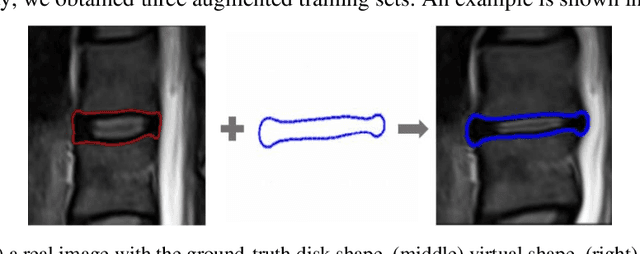
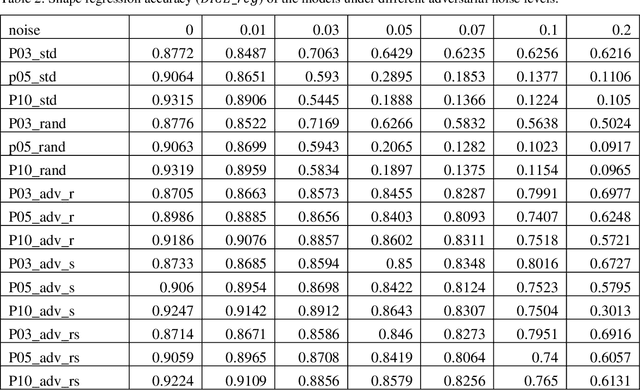
Machine learning technologies using deep neural networks (DNNs), especially convolutional neural networks (CNNs), have made automated, accurate, and fast medical image analysis a reality for many applications, and some DNN-based medical image analysis systems have even been FDA-cleared. Despite the progress, challenges remain to build DNNs as reliable as human expert doctors. It is known that DNN classifiers may not be robust to noises: by adding a small amount of noise to an input image, a DNN classifier may make a wrong classification of the noisy image (i.e., in-distribution adversarial sample), whereas it makes the right classification of the clean image. Another issue is caused by out-of-distribution samples that are not similar to any sample in the training set. Given such a sample as input, the output of a DNN will become meaningless. In this study, we investigated the in-distribution (IND) and out-of-distribution (OOD) adversarial robustness of a representative CNN for lumbar disk shape reconstruction from spine MR images. To study the relationship between dataset size and robustness to IND adversarial attacks, we used a data augmentation method to create training sets with different levels of shape variations. We utilized the PGD-based algorithm for IND adversarial attacks and extended it for OOD adversarial attacks to generate OOD adversarial samples for model testing. The results show that IND adversarial training can improve the CNN robustness to IND adversarial attacks, and larger training datasets may lead to higher IND robustness. However, it is still a challenge to defend against OOD adversarial attacks.
SCNet: Enhancing Few-Shot Semantic Segmentation by Self-Contrastive Background Prototypes
Apr 28, 2021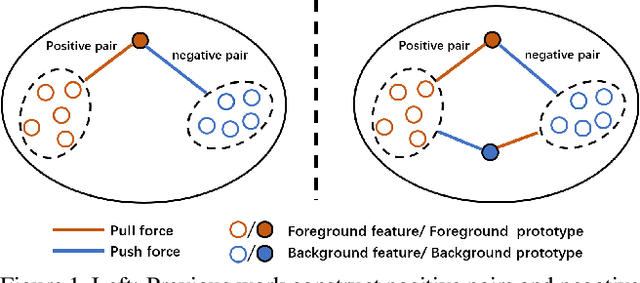
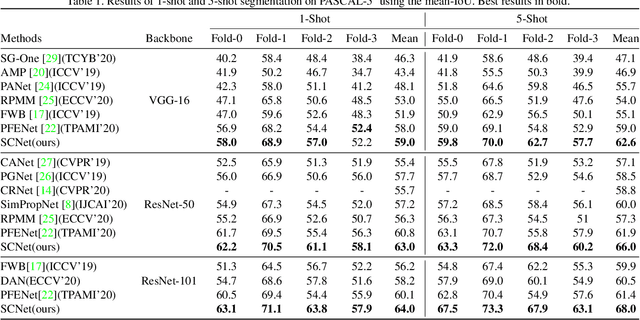
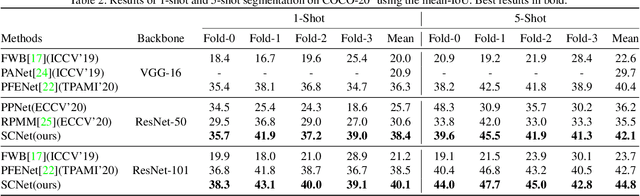
Few-shot semantic segmentation aims to segment novel-class objects in a query image with only a few annotated examples in support images. Most of advanced solutions exploit a metric learning framework that performs segmentation through matching each pixel to a learned foreground prototype. However, this framework suffers from biased classification due to incomplete construction of sample pairs with the foreground prototype only. To address this issue, in this paper, we introduce a complementary self-contrastive task into few-shot semantic segmentation. Our new model is able to associate the pixels in a region with the prototype of this region, no matter they are in the foreground or background. To this end, we generate self-contrastive background prototypes directly from the query image, with which we enable the construction of complete sample pairs and thus a complementary and auxiliary segmentation task to achieve the training of a better segmentation model. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ demonstrate clearly the superiority of our proposal. At no expense of inference efficiency, our model achieves state-of-the results in both 1-shot and 5-shot settings for few-shot semantic segmentation.
Resonant Tunnelling Diode Nano-Optoelectronic Spiking Nodes For Neuromorphic Information Processing
Jul 14, 2021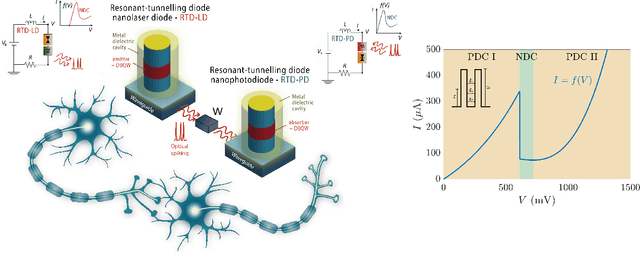
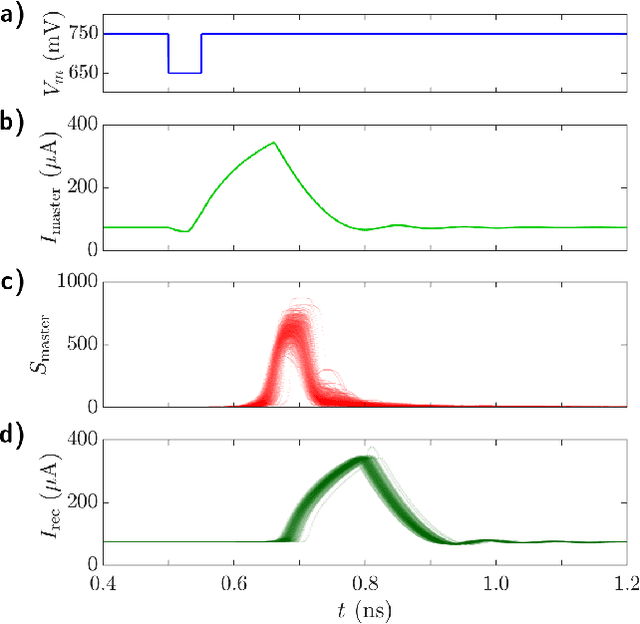
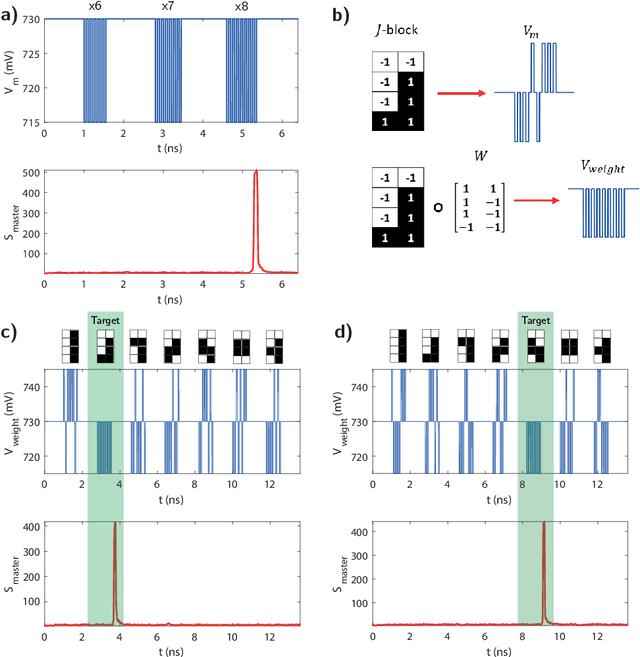
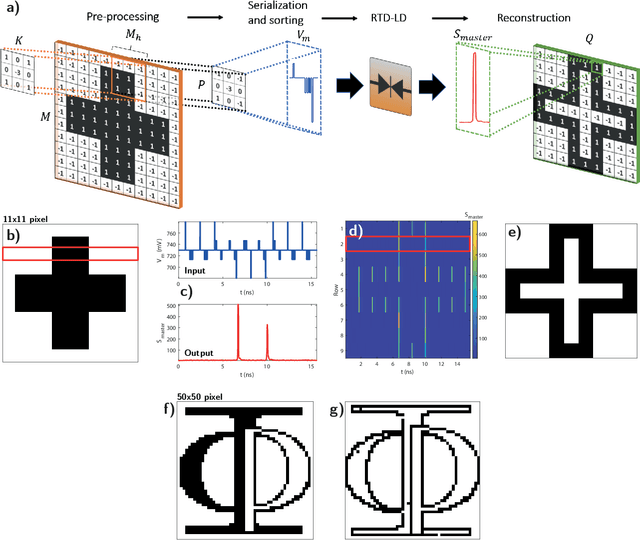
In this work, we introduce an optoelectronic spiking artificial neuron capable of operating at ultrafast rates ($\approx$ 100 ps/optical spike) and with low energy consumption ($<$ pJ/spike). The proposed system combines an excitable resonant tunnelling diode (RTD) element exhibiting negative differential conductance, coupled to a nanoscale light source (forming a master node) or a photodetector (forming a receiver node). We study numerically the spiking dynamical responses and information propagation functionality of an interconnected master-receiver RTD node system. Using the key functionality of pulse thresholding and integration, we utilize a single node to classify sequential pulse patterns and perform convolutional functionality for image feature (edge) recognition. We also demonstrate an optically-interconnected spiking neural network model for processing of spatiotemporal data at over 10 Gbps with high inference accuracy. Finally, we demonstrate an off-chip supervised learning approach utilizing spike-timing dependent plasticity for the RTD-enabled photonic spiking neural network. These results demonstrate the potential and viability of RTD spiking nodes for low footprint, low energy, high-speed optoelectronic realization of neuromorphic hardware.