 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Guided Nonlocal Means Estimation of Polarimetric Covariance for Canopy State Classification
Jun 17, 2021
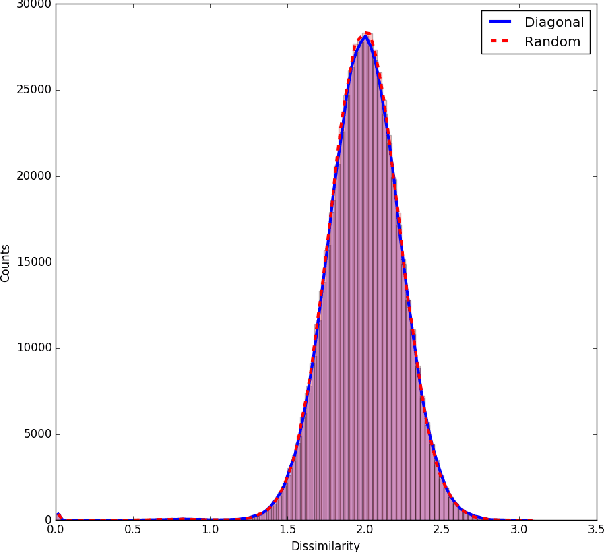

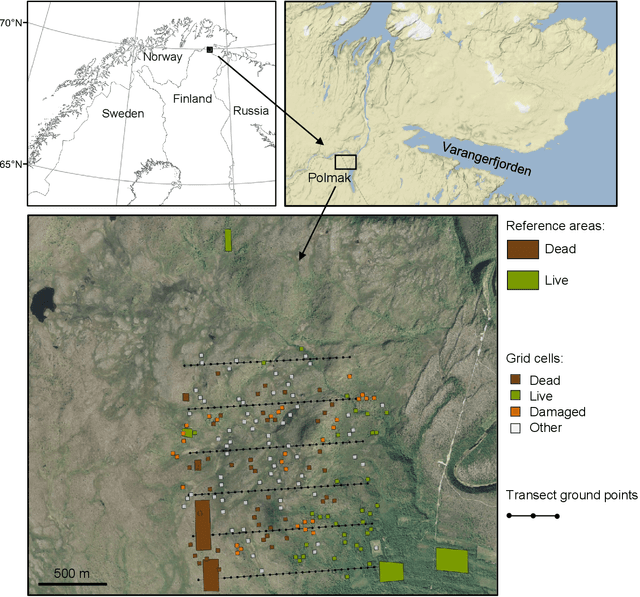

We have developed a nonlocal algorithm for estimating polarimetric synthetic aperture radar (PolSAR) covariance matrices on single-look complex (SLC) format resolution. The algorithm is inspired by recent work with guided nonlocal means (NLM) speckle filtering, where a co-registered optical image is used to aid the filtering. Based on patch-wise dissimilarities in the SAR and optical domains we set the weights used for the nonlocal average of the outer product of the lexicographic target vectors which form the estimate. By use of this method we show that the estimated covariance matrices preserve the local structure better than previous filtering methods and improve the separation of live from defoliated and dead forest. The detail preserving nature of the algorithm also means that it can be applicable in other settings where preserving the SLC format resolution is necessary.
AIRD: Adversarial Learning Framework for Image Repurposing Detection
Apr 09, 2019
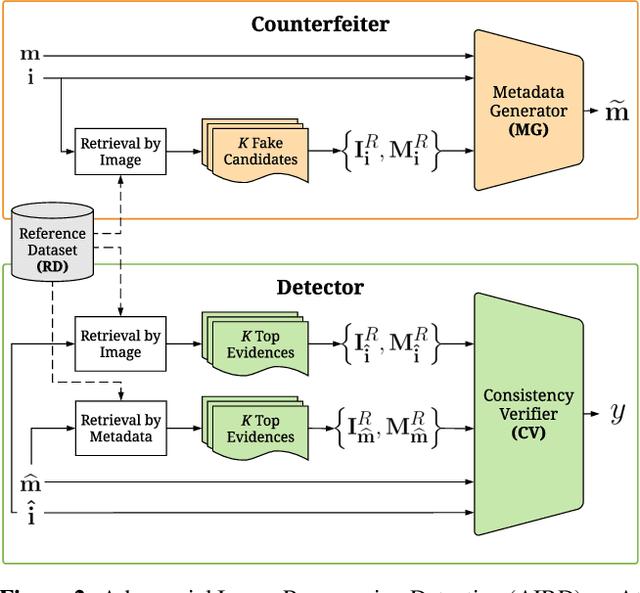
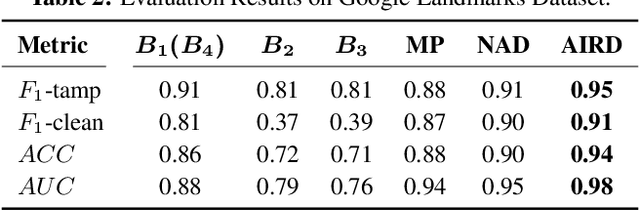
Image repurposing is a commonly used method for spreading misinformation on social media and online forums, which involves publishing untampered images with modified metadata to create rumors and further propaganda. While manual verification is possible, given vast amounts of verified knowledge available on the internet, the increasing prevalence and ease of this form of semantic manipulation call for the development of robust automatic ways of assessing the semantic integrity of multimedia data. In this paper, we present a novel method for image repurposing detection that is based on the real-world adversarial interplay between a bad actor who repurposes images with counterfeit metadata and a watchdog who verifies the semantic consistency between images and their accompanying metadata, where both players have access to a reference dataset of verified content, which they can use to achieve their goals. The proposed method exhibits state-of-the-art performance on location-identity, subject-identity and painting-artist verification, showing its efficacy across a diverse set of scenarios.
MeanShift++: Extremely Fast Mode-Seeking With Applications to Segmentation and Object Tracking
Apr 01, 2021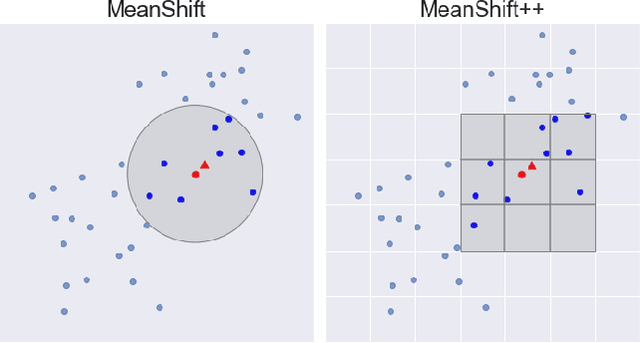
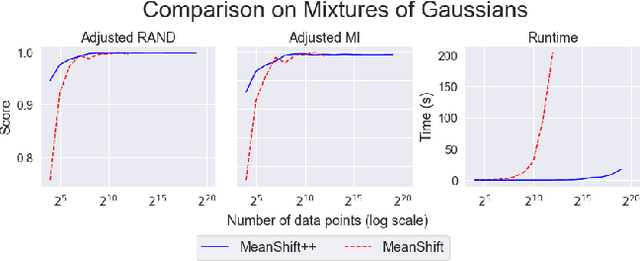
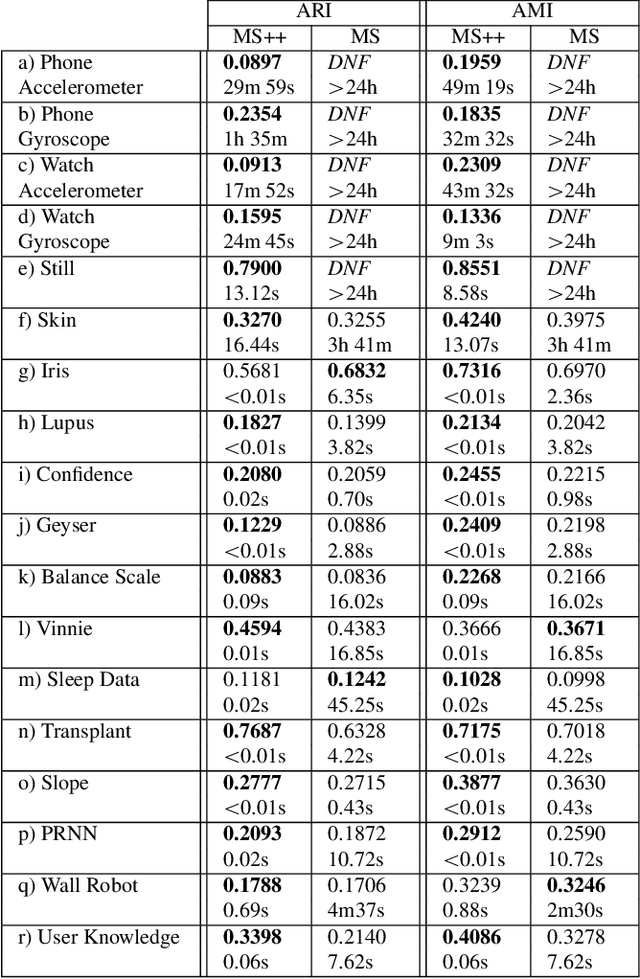
MeanShift is a popular mode-seeking clustering algorithm used in a wide range of applications in machine learning. However, it is known to be prohibitively slow, with quadratic runtime per iteration. We propose MeanShift++, an extremely fast mode-seeking algorithm based on MeanShift that uses a grid-based approach to speed up the mean shift step, replacing the computationally expensive neighbors search with a density-weighted mean of adjacent grid cells. In addition, we show that this grid-based technique for density estimation comes with theoretical guarantees. The runtime is linear in the number of points and exponential in dimension, which makes MeanShift++ ideal on low-dimensional applications such as image segmentation and object tracking. We provide extensive experimental analysis showing that MeanShift++ can be more than 10,000x faster than MeanShift with competitive clustering results on benchmark datasets and nearly identical image segmentations as MeanShift. Finally, we show promising results for object tracking.
TransformerFusion: Monocular RGB Scene Reconstruction using Transformers
Jul 05, 2021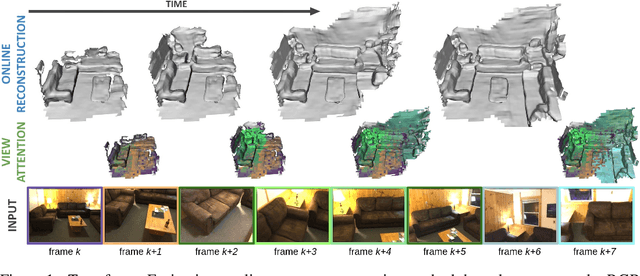
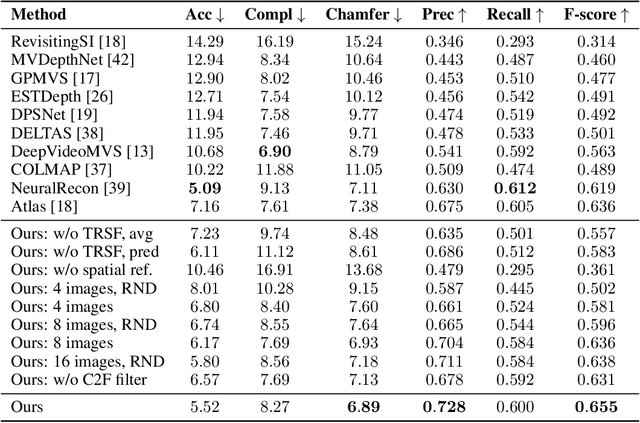
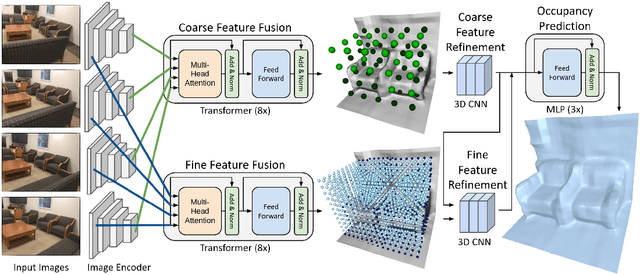

We introduce TransformerFusion, a transformer-based 3D scene reconstruction approach. From an input monocular RGB video, the video frames are processed by a transformer network that fuses the observations into a volumetric feature grid representing the scene; this feature grid is then decoded into an implicit 3D scene representation. Key to our approach is the transformer architecture that enables the network to learn to attend to the most relevant image frames for each 3D location in the scene, supervised only by the scene reconstruction task. Features are fused in a coarse-to-fine fashion, storing fine-level features only where needed, requiring lower memory storage and enabling fusion at interactive rates. The feature grid is then decoded to a higher-resolution scene reconstruction, using an MLP-based surface occupancy prediction from interpolated coarse-to-fine 3D features. Our approach results in an accurate surface reconstruction, outperforming state-of-the-art multi-view stereo depth estimation methods, fully-convolutional 3D reconstruction approaches, and approaches using LSTM- or GRU-based recurrent networks for video sequence fusion.
toon2real: Translating Cartoon Images to Realistic Images
Feb 01, 2021
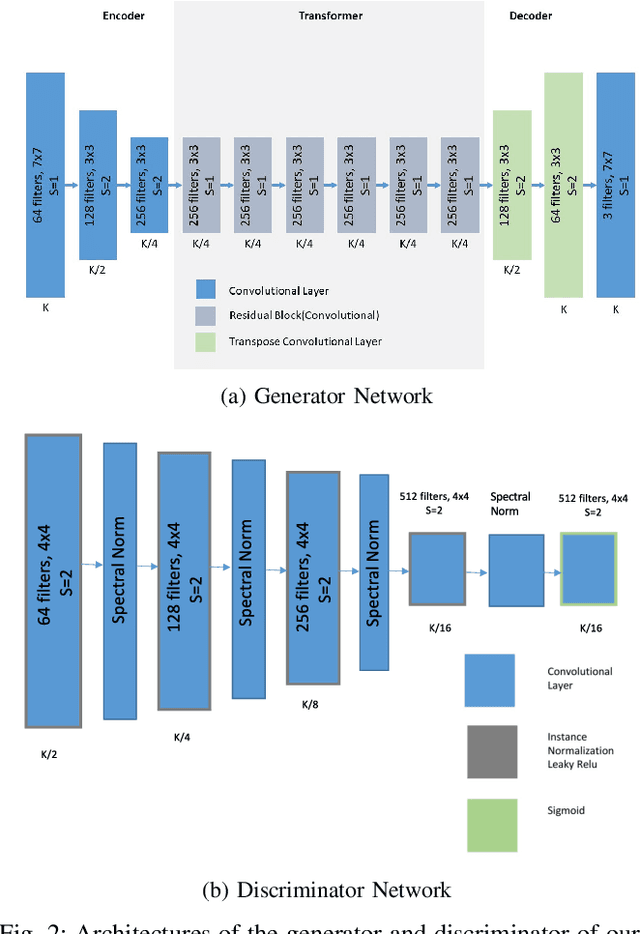

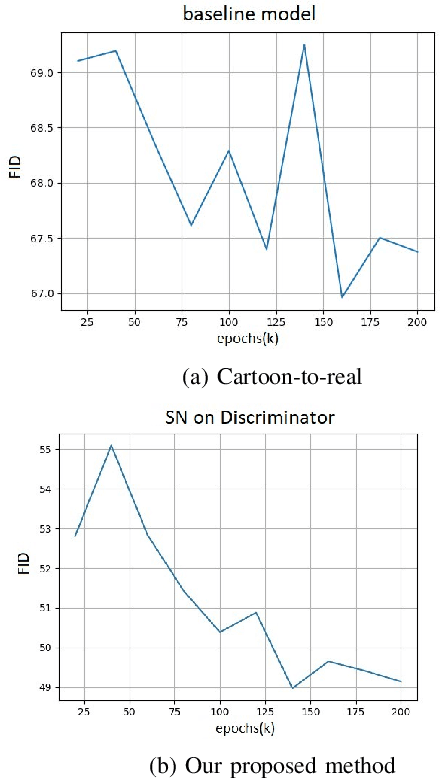
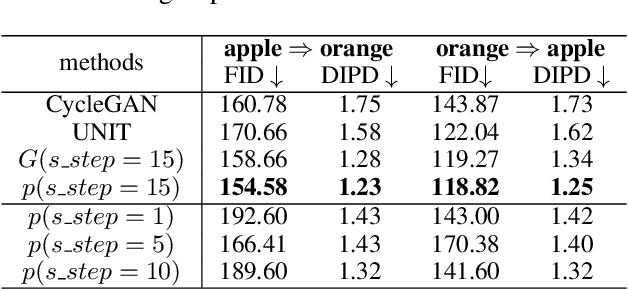
In terms of Image-to-image translation, Generative Adversarial Networks (GANs) has achieved great success even when it is used in the unsupervised dataset. In this work, we aim to translate cartoon images to photo-realistic images using GAN. We apply several state-of-the-art models to perform this task; however, they fail to perform good quality translations. We observe that the shallow difference between these two domains causes this issue. Based on this idea, we propose a method based on CycleGAN model for image translation from cartoon domain to photo-realistic domain. To make our model efficient, we implemented Spectral Normalization which added stability in our model. We demonstrate our experimental results and show that our proposed model has achieved the lowest Frechet Inception Distance score and better results compared to another state-of-the-art technique, UNIT.
Super Resolution in Human Pose Estimation: Pixelated Poses to a Resolution Result?
Jul 05, 2021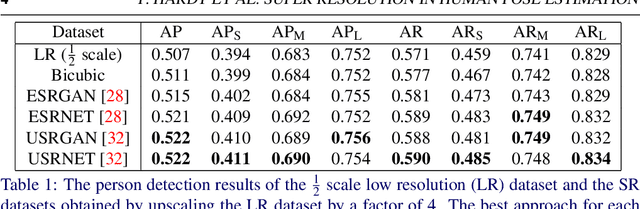
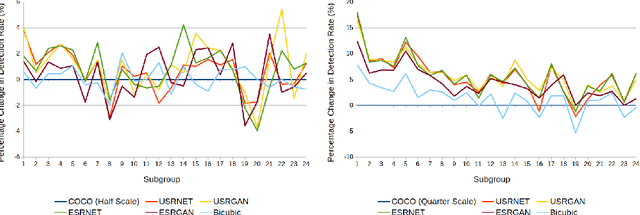
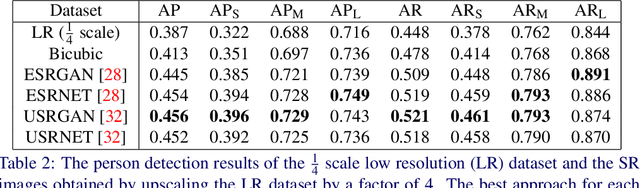
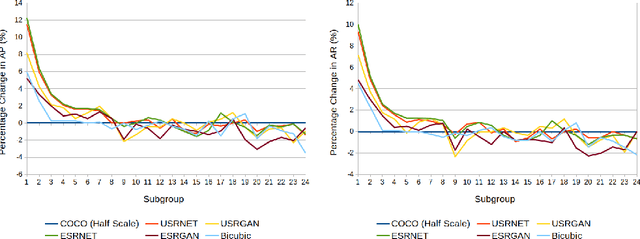
The results obtained from state of the art human pose estimation (HPE) models degrade rapidly when evaluating people of a low resolution, but can super resolution (SR) be used to help mitigate this effect? By using various SR approaches we enhanced two low resolution datasets and evaluated the change in performance of both an object and keypoint detector as well as end-to-end HPE results. We remark the following observations. First we find that for low resolution people their keypoint detection performance improved once SR was applied. Second, the keypoint detection performance gained is dependent on the persons initial resolution (segmentation area in pixels) in the original image; keypoint detection performance was improved when SR was applied to people with a small initial segmentation area, but degrades as this becomes larger. To address this we introduced a novel Mask-RCNN approach, utilising a segmentation area threshold to decide when to use SR during the keypoint detection step. This approach achieved the best results for each of our HPE performance metrics.
Learning Cycle-Consistent Cooperative Networks via Alternating MCMC Teaching for Unsupervised Cross-Domain Translation
Mar 07, 2021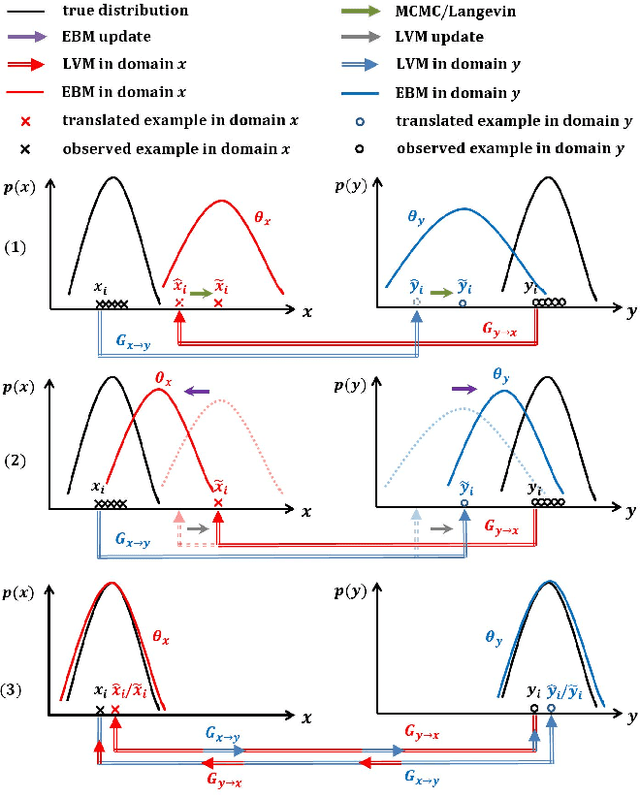

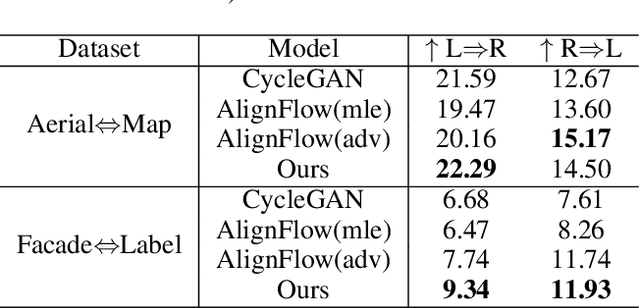
This paper studies the unsupervised cross-domain translation problem by proposing a generative framework, in which the probability distribution of each domain is represented by a generative cooperative network that consists of an energy-based model and a latent variable model. The use of generative cooperative network enables maximum likelihood learning of the domain model by MCMC teaching, where the energy-based model seeks to fit the data distribution of domain and distills its knowledge to the latent variable model via MCMC. Specifically, in the MCMC teaching process, the latent variable model parameterized by an encoder-decoder maps examples from the source domain to the target domain, while the energy-based model further refines the mapped results by Langevin revision such that the revised results match to the examples in the target domain in terms of the statistical properties, which are defined by the learned energy function. For the purpose of building up a correspondence between two unpaired domains, the proposed framework simultaneously learns a pair of cooperative networks with cycle consistency, accounting for a two-way translation between two domains, by alternating MCMC teaching. Experiments show that the proposed framework is useful for unsupervised image-to-image translation and unpaired image sequence translation.
Joining datasets via data augmentation in the label space for neural networks
Jun 17, 2021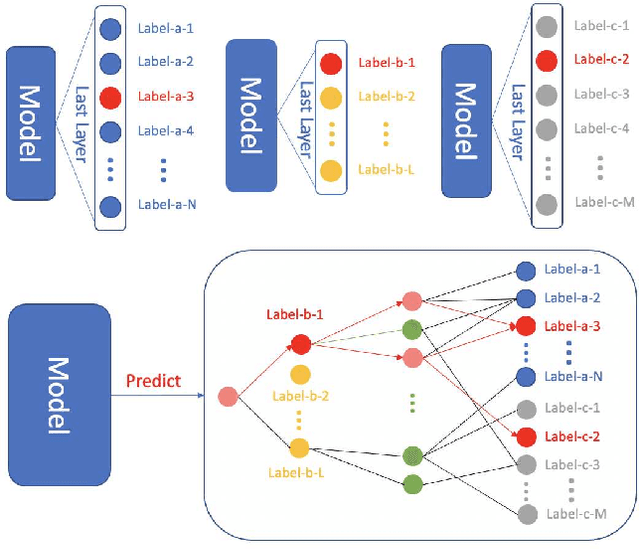
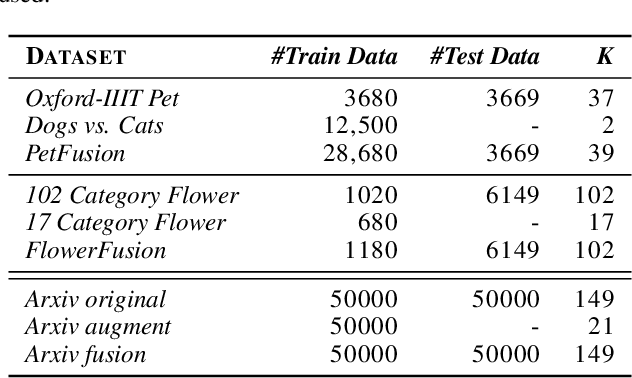
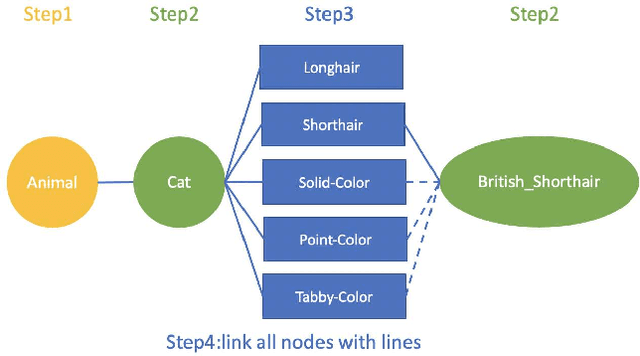
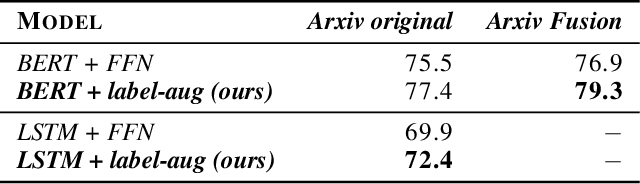
Most, if not all, modern deep learning systems restrict themselves to a single dataset for neural network training and inference. In this article, we are interested in systematic ways to join datasets that are made of similar purposes. Unlike previous published works that ubiquitously conduct the dataset joining in the uninterpretable latent vectorial space, the core to our method is an augmentation procedure in the label space. The primary challenge to address the label space for dataset joining is the discrepancy between labels: non-overlapping label annotation sets, different labeling granularity or hierarchy and etc. Notably we propose a new technique leveraging artificially created knowledge graph, recurrent neural networks and policy gradient that successfully achieve the dataset joining in the label space. Empirical results on both image and text classification justify the validity of our approach.
Detecting race and gender bias in visual representation of AI on web search engines
Jun 26, 2021
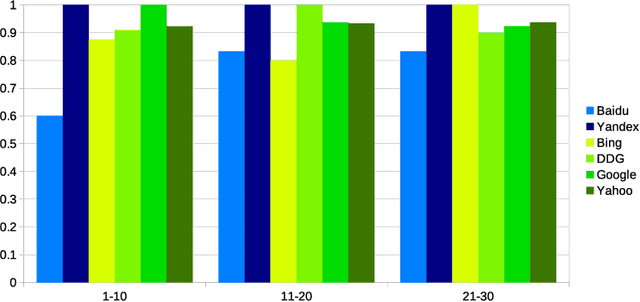
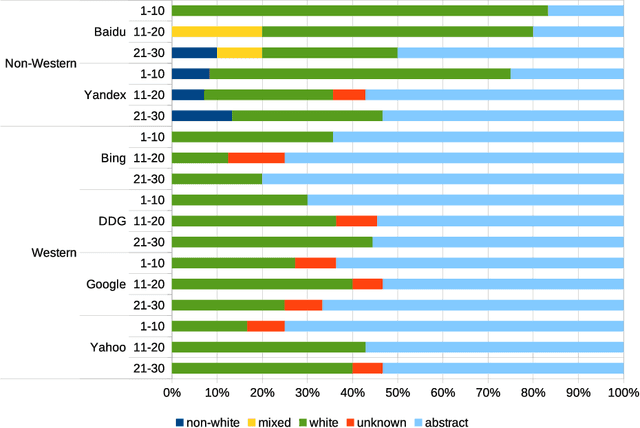
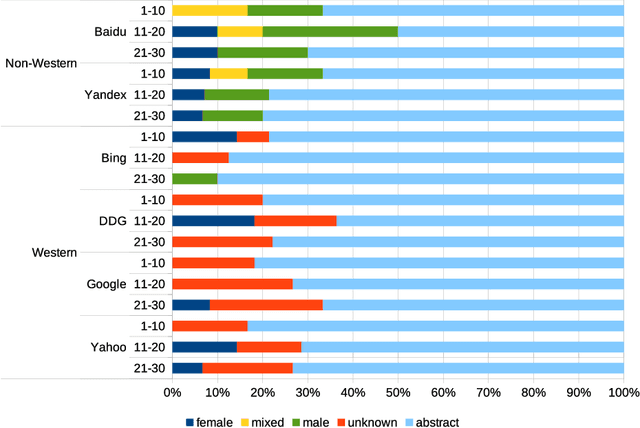
Web search engines influence perception of social reality by filtering and ranking information. However, their outputs are often subjected to bias that can lead to skewed representation of subjects such as professional occupations or gender. In our paper, we use a mixed-method approach to investigate presence of race and gender bias in representation of artificial intelligence (AI) in image search results coming from six different search engines. Our findings show that search engines prioritize anthropomorphic images of AI that portray it as white, whereas non-white images of AI are present only in non-Western search engines. By contrast, gender representation of AI is more diverse and less skewed towards a specific gender that can be attributed to higher awareness about gender bias in search outputs. Our observations indicate both the the need and the possibility for addressing bias in representation of societally relevant subjects, such as technological innovation, and emphasize the importance of designing new approaches for detecting bias in information retrieval systems.
* 16 pages, 3 figures
Training Data Independent Image Registration With GANs Using Transfer Learning And Segmentation Information
Apr 11, 2019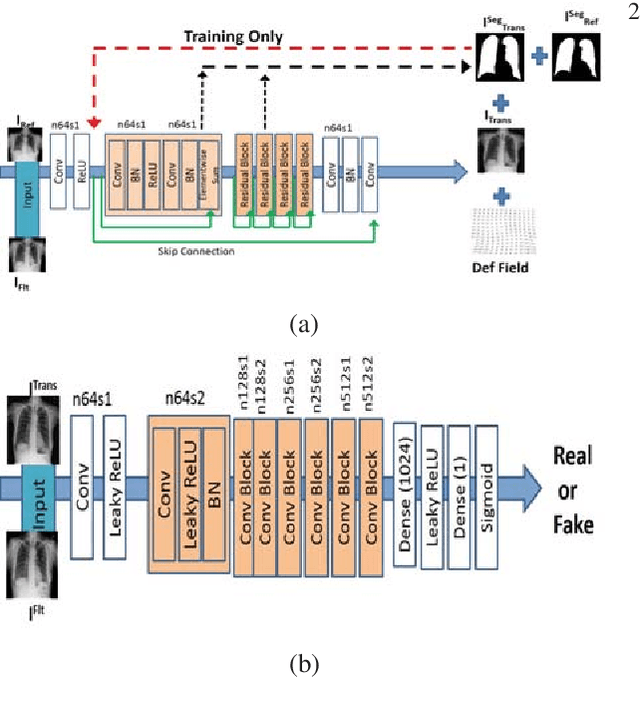
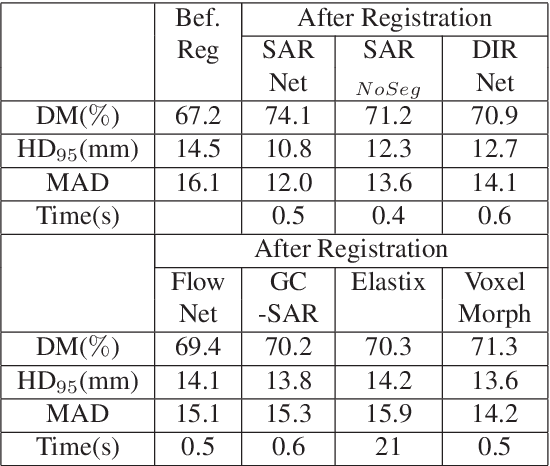
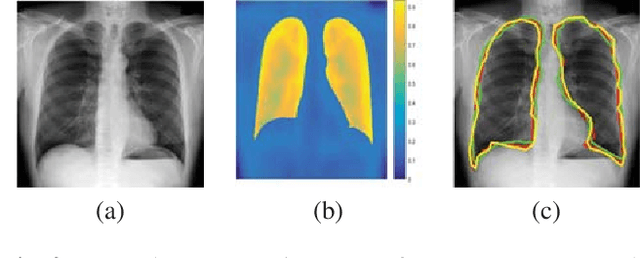
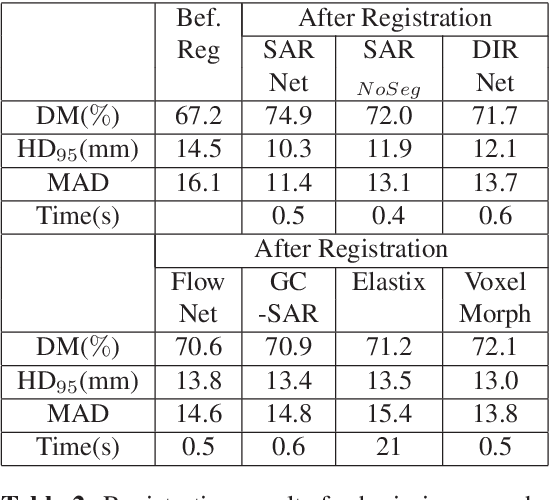
Registration is an important task in automated medical image analysis. Although deep learning (DL) based image registration methods out perform time consuming conventional approaches, they are heavily dependent on training data and do not generalize well for new images types. We present a DL based approach that can register an image pair which is different from the training images. This is achieved by training generative adversarial networks (GANs) in combination with segmentation information and transfer learning. Experiments on chest Xray and brain MR images show that our method gives better registration performance over conventional methods.