 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
toon2real: Translating Cartoon Images to Realistic Images
Feb 01, 2021

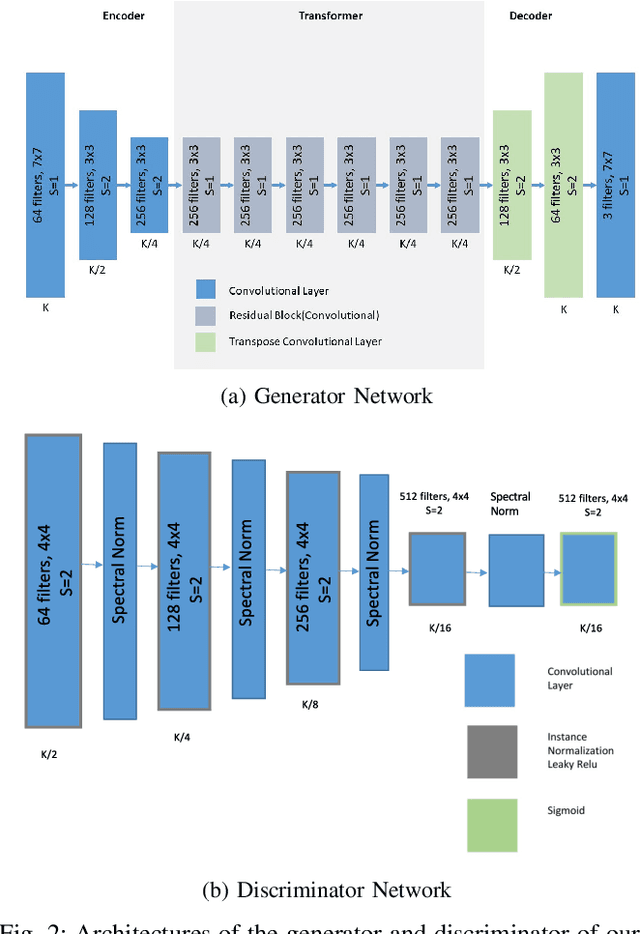

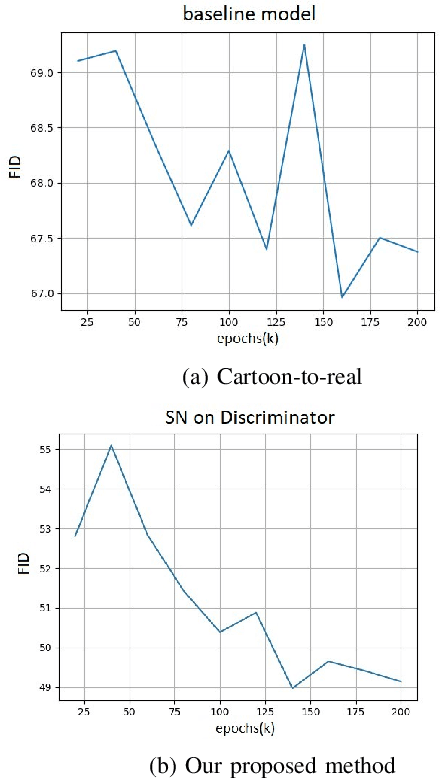
In terms of Image-to-image translation, Generative Adversarial Networks (GANs) has achieved great success even when it is used in the unsupervised dataset. In this work, we aim to translate cartoon images to photo-realistic images using GAN. We apply several state-of-the-art models to perform this task; however, they fail to perform good quality translations. We observe that the shallow difference between these two domains causes this issue. Based on this idea, we propose a method based on CycleGAN model for image translation from cartoon domain to photo-realistic domain. To make our model efficient, we implemented Spectral Normalization which added stability in our model. We demonstrate our experimental results and show that our proposed model has achieved the lowest Frechet Inception Distance score and better results compared to another state-of-the-art technique, UNIT.
Polarization Guided Specular Reflection Separation
Mar 22, 2021
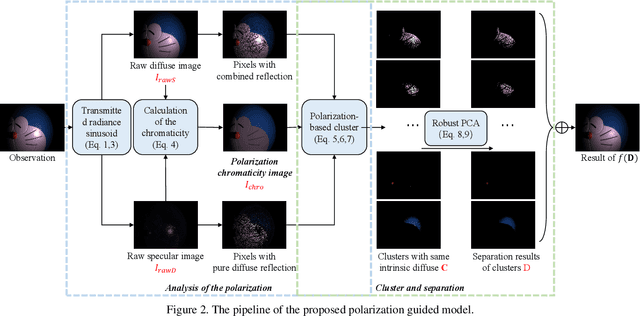
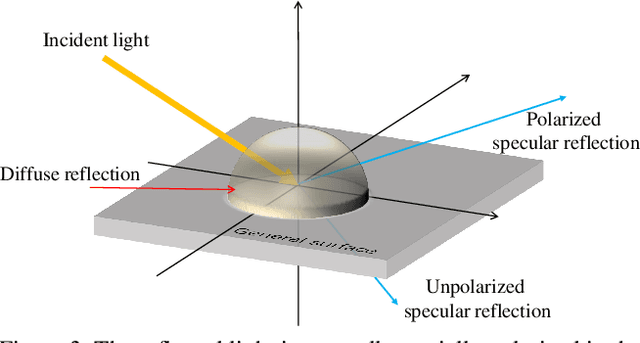
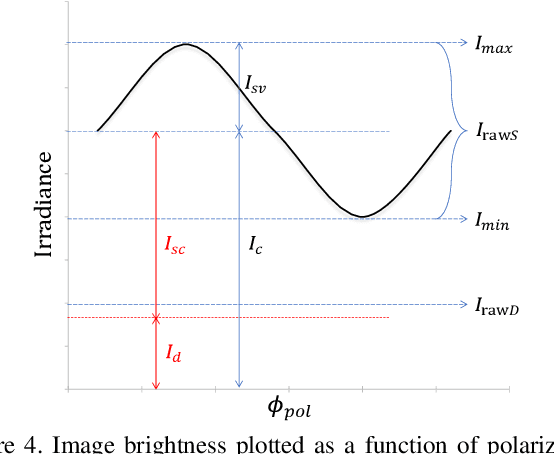
Since specular reflection often exists in the real captured images and causes deviation between the recorded color and intrinsic color, specular reflection separation can bring advantages to multiple applications that require consistent object surface appearance. However, due to the color of an object is significantly influenced by the color of the illumination, the existing researches still suffer from the near-duplicate challenge, that is, the separation becomes unstable when the illumination color is close to the surface color. In this paper, we derive a polarization guided model to incorporate the polarization information into a designed iteration optimization separation strategy to separate the specular reflection. Based on the analysis of polarization, we propose a polarization guided model to generate a polarization chromaticity image, which is able to reveal the geometrical profile of the input image in complex scenarios, such as diversity of illumination. The polarization chromaticity image can accurately cluster the pixels with similar diffuse color. We further use the specular separation of all these clusters as an implicit prior to ensure that the diffuse components will not be mistakenly separated as the specular components. With the polarization guided model, we reformulate the specular reflection separation into a unified optimization function which can be solved by the ADMM strategy. The specular reflection will be detected and separated jointly by RGB and polarimetric information. Both qualitative and quantitative experimental results have shown that our method can faithfully separate the specular reflection, especially in some challenging scenarios.
Multiresolution Graph Variational Autoencoder
Jun 02, 2021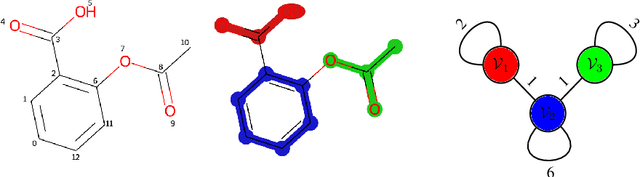
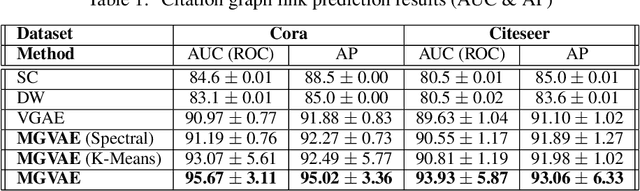
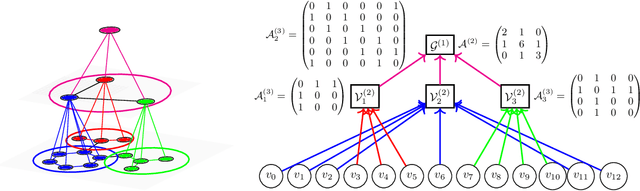
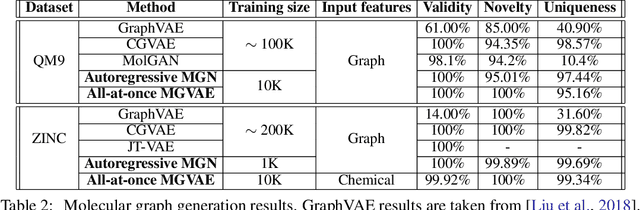
In this paper, we propose Multiresolution Graph Networks (MGN) and Multiresolution Graph Variational Autoencoders (MGVAE) to learn and generate graphs in a multiresolution and equivariant manner. At each resolution level, MGN employs higher order message passing to encode the graph while learning to partition it into mutually exclusive clusters and coarsening into a lower resolution. MGVAE constructs a hierarchical generative model based on MGN to variationally autoencode the hierarchy of coarsened graphs. Our proposed framework is end-to-end permutation equivariant with respect to node ordering. Our methods have been successful with several generative tasks including link prediction on citation graphs, unsupervised molecular representation learning to predict molecular properties, molecular generation, general graph generation and graph-based image generation.
External Prior Guided Internal Prior Learning for Real-World Noisy Image Denoising
Oct 15, 2018



Most of existing image denoising methods learn image priors from either external data or the noisy image itself to remove noise. However, priors learned from external data may not be adaptive to the image to be denoised, while priors learned from the given noisy image may not be accurate due to the interference of corrupted noise. Meanwhile, the noise in real-world noisy images is very complex, which is hard to be described by simple distributions such as Gaussian distribution, making real-world noisy image denoising a very challenging problem. We propose to exploit the information in both external data and the given noisy image, and develop an external prior guided internal prior learning method for real-world noisy image denoising. We first learn external priors from an independent set of clean natural images. With the aid of learned external priors, we then learn internal priors from the given noisy image to refine the prior model. The external and internal priors are formulated as a set of orthogonal dictionaries to efficiently reconstruct the desired image. Extensive experiments are performed on several real-world noisy image datasets. The proposed method demonstrates highly competitive denoising performance, outperforming state-of-the-art denoising methods including those designed for real-world noisy images.
Multi-Task Attention-Based Semi-Supervised Learning for Medical Image Segmentation
Jul 29, 2019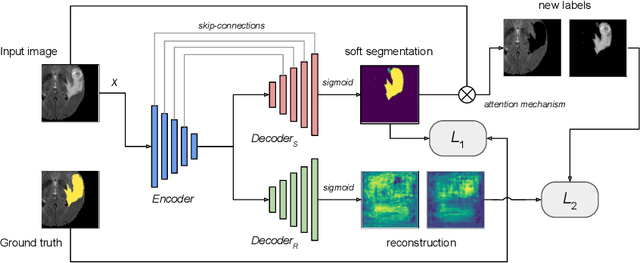
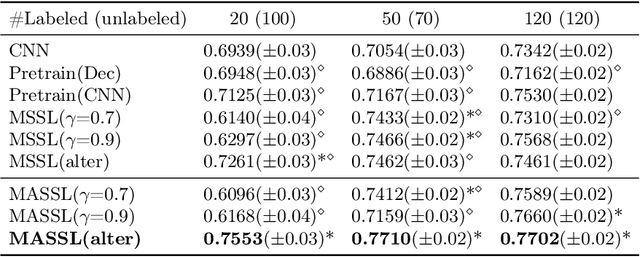
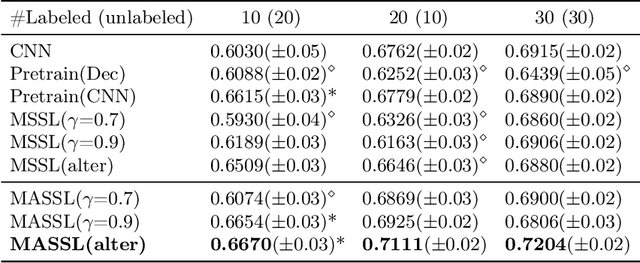
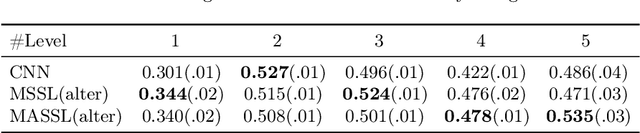
We propose a novel semi-supervised image segmentation method that simultaneously optimizes a supervised segmentation and an unsupervised reconstruction objectives. The reconstruction objective uses an attention mechanism that separates the reconstruction of image areas corresponding to different classes. The proposed approach was evaluated on two applications: brain tumor and white matter hyperintensities segmentation. Our method, trained on unlabeled and a small number of labeled images, outperformed supervised CNNs trained with the same number of images and CNNs pre-trained on unlabeled data. In ablation experiments, we observed that the proposed attention mechanism substantially improves segmentation performance. We explore two multi-task training strategies: joint training and alternating training. Alternating training requires fewer hyperparameters and achieves a better, more stable performance than joint training. Finally, we analyze the features learned by different methods and find that the attention mechanism helps to learn more discriminative features in the deeper layers of encoders.
Towards Robust Image Classification Using Sequential Attention Models
Dec 04, 2019
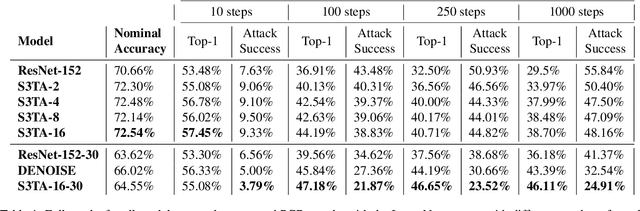
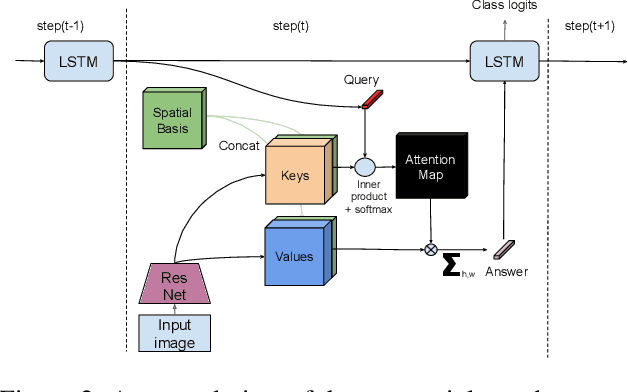

In this paper we propose to augment a modern neural-network architecture with an attention model inspired by human perception. Specifically, we adversarially train and analyze a neural model incorporating a human inspired, visual attention component that is guided by a recurrent top-down sequential process. Our experimental evaluation uncovers several notable findings about the robustness and behavior of this new model. First, introducing attention to the model significantly improves adversarial robustness resulting in state-of-the-art ImageNet accuracies under a wide range of random targeted attack strengths. Second, we show that by varying the number of attention steps (glances/fixations) for which the model is unrolled, we are able to make its defense capabilities stronger, even in light of stronger attacks --- resulting in a "computational race" between the attacker and the defender. Finally, we show that some of the adversarial examples generated by attacking our model are quite different from conventional adversarial examples --- they contain global, salient and spatially coherent structures coming from the target class that would be recognizable even to a human, and work by distracting the attention of the model away from the main object in the original image.
Low-cost Stereovision system (disparity map) for few dollars
Jun 02, 2021


The paper presents an analysis of the latest developments in the field of stereo vision in the low-cost segment, both for prototypes and for industrial designs. We described the theory of stereo vision and presented information about cameras and data transfer protocols and their compatibility with various devices. The theory in the field of image processing for stereo vision processes is considered and the calibration process is described in detail. Ultimately, we presented the developed stereo vision system and provided the main points that need to be considered when developing such systems. The final, we presented software for adjusting stereo vision parameters in real-time in the python language in the Windows operating system.
Regularized Evolution for Image Classifier Architecture Search
Oct 26, 2018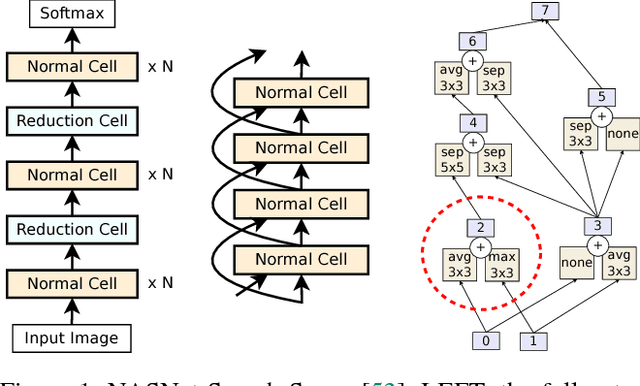
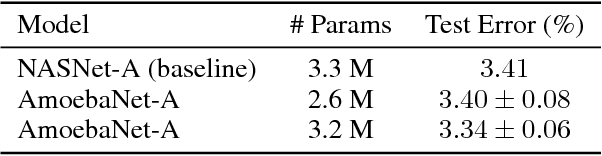
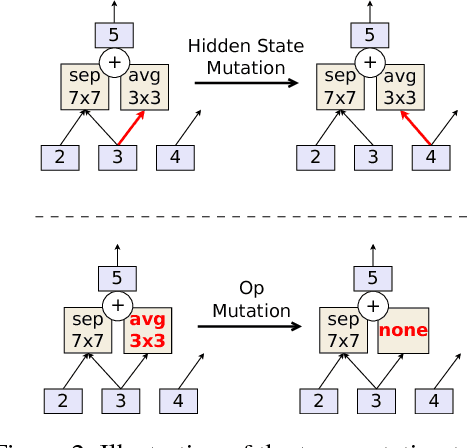
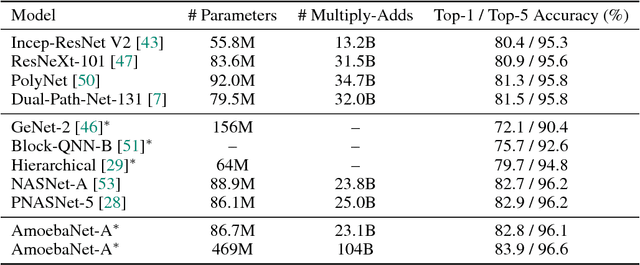
The effort devoted to hand-crafting neural network image classifiers has motivated the use of architecture search to discover them automatically. Although evolutionary algorithms have been repeatedly applied to neural network topologies, the image classifiers thus discovered have remained inferior to human-crafted ones. Here, we evolve an image classifier---AmoebaNet-A---that surpasses hand-designs for the first time. To do this, we modify the tournament selection evolutionary algorithm by introducing an age property to favor the younger genotypes. Matching size, AmoebaNet-A has comparable accuracy to current state-of-the-art ImageNet models discovered with more complex architecture-search methods. Scaled to larger size, AmoebaNet-A sets a new state-of-the-art 83.9% top-1 / 96.6% top-5 ImageNet accuracy. In a controlled comparison against a well known reinforcement learning algorithm, we give evidence that evolution can obtain results faster with the same hardware, especially at the earlier stages of the search. This is relevant when fewer compute resources are available. Evolution is, thus, a simple method to effectively discover high-quality architectures.
Poisoning the Search Space in Neural Architecture Search
Jun 28, 2021
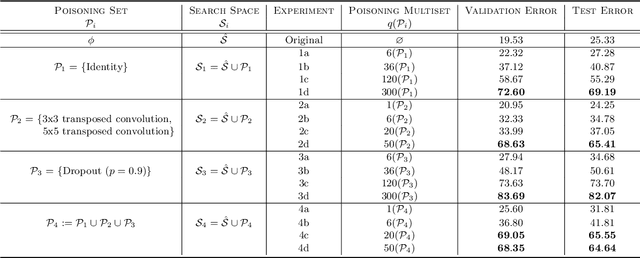

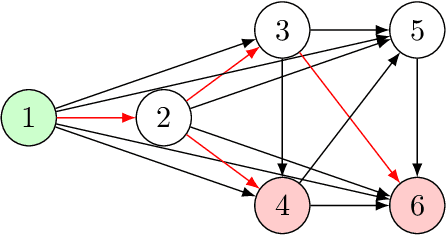
Deep learning has proven to be a highly effective problem-solving tool for object detection and image segmentation across various domains such as healthcare and autonomous driving. At the heart of this performance lies neural architecture design which relies heavily on domain knowledge and prior experience on the researchers' behalf. More recently, this process of finding the most optimal architectures, given an initial search space of possible operations, was automated by Neural Architecture Search (NAS). In this paper, we evaluate the robustness of one such algorithm known as Efficient NAS (ENAS) against data agnostic poisoning attacks on the original search space with carefully designed ineffective operations. By evaluating algorithm performance on the CIFAR-10 dataset, we empirically demonstrate how our novel search space poisoning (SSP) approach and multiple-instance poisoning attacks exploit design flaws in the ENAS controller to result in inflated prediction error rates for child networks. Our results provide insights into the challenges to surmount in using NAS for more adversarially robust architecture search.
NeRD: Neural 3D Reflection Symmetry Detector
Apr 19, 2021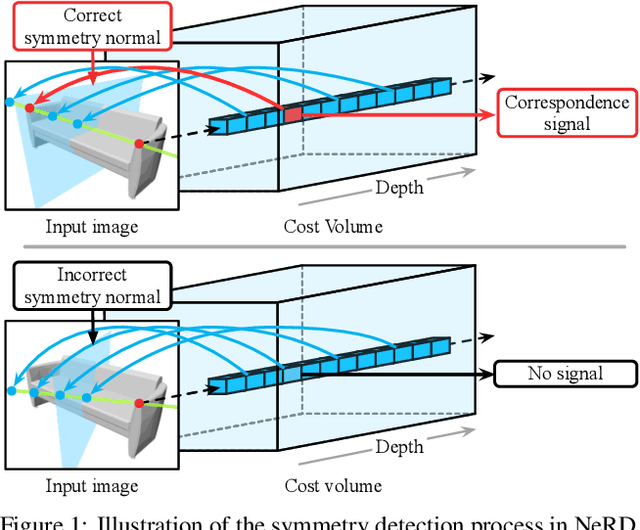
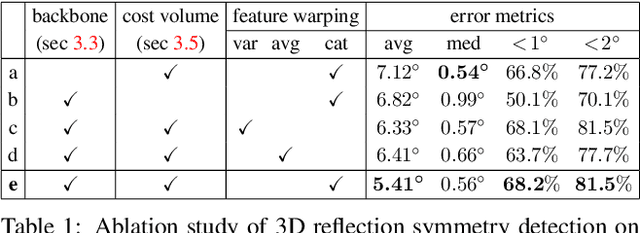
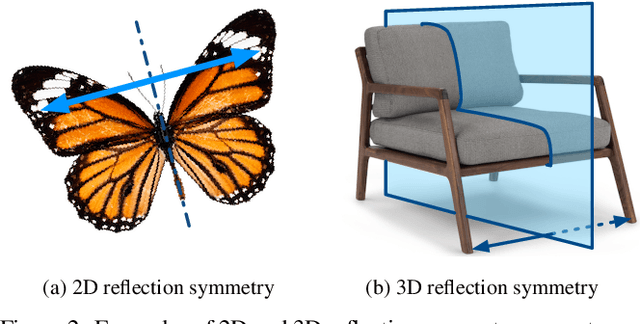
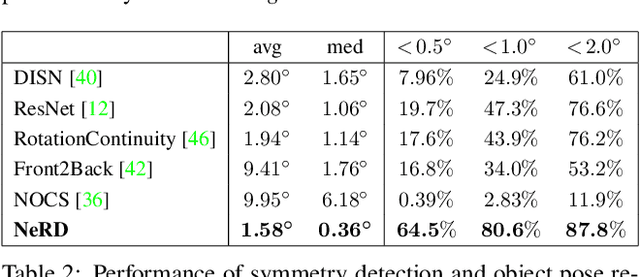
Recent advances have shown that symmetry, a structural prior that most objects exhibit, can support a variety of single-view 3D understanding tasks. However, detecting 3D symmetry from an image remains a challenging task. Previous works either assume that the symmetry is given or detect the symmetry with a heuristic-based method. In this paper, we present NeRD, a Neural 3D Reflection Symmetry Detector, which combines the strength of learning-based recognition and geometry-based reconstruction to accurately recover the normal direction of objects' mirror planes. Specifically, we first enumerate the symmetry planes with a coarse-to-fine strategy and then find the best ones by building 3D cost volumes to examine the intra-image pixel correspondence from the symmetry. Our experiments show that the symmetry planes detected with our method are significantly more accurate than the planes from direct CNN regression on both synthetic and real-world datasets. We also demonstrate that the detected symmetry can be used to improve the performance of downstream tasks such as pose estimation and depth map regression. The code of this paper has been made public at https://github.com/zhou13/nerd.