 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Foreground-Aware Stylization and Consensus Pseudo-Labeling for Domain Adaptation of First-Person Hand Segmentation
Jul 07, 2021
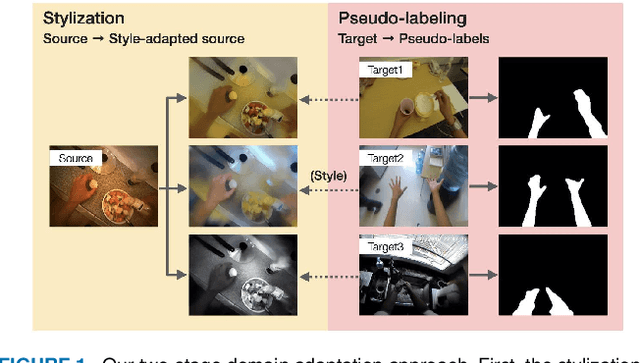
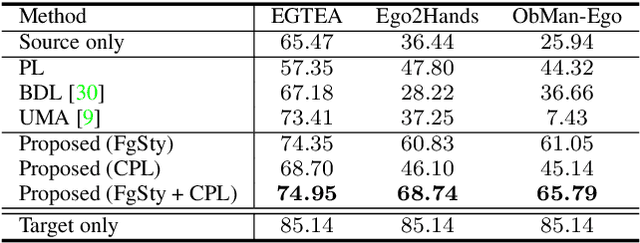


Hand segmentation is a crucial task in first-person vision. Since first-person images exhibit strong bias in appearance among different environments, adapting a pre-trained segmentation model to a new domain is required in hand segmentation. Here, we focus on appearance gaps for hand regions and backgrounds separately. We propose (i) foreground-aware image stylization and (ii) consensus pseudo-labeling for domain adaptation of hand segmentation. We stylize source images independently for the foreground and background using target images as style. To resolve the domain shift that the stylization has not addressed, we apply careful pseudo-labeling by taking a consensus between the models trained on the source and stylized source images. We validated our method on domain adaptation of hand segmentation from real and simulation images. Our method achieved state-of-the-art performance in both settings. We also demonstrated promising results in challenging multi-target domain adaptation and domain generalization settings. Code is available at https://github.com/ut-vision/FgSty-CPL.
A New Semi-supervised Learning Benchmark for Classifying View and Diagnosing Aortic Stenosis from Echocardiograms
Jul 30, 2021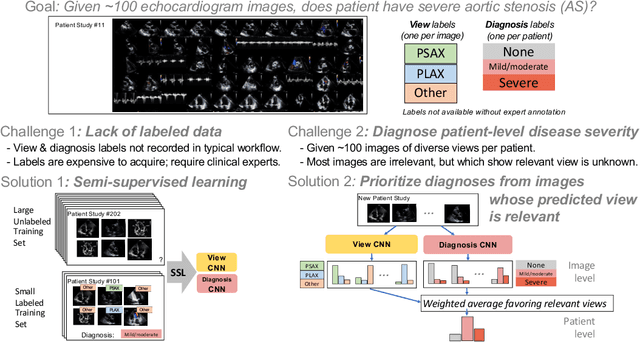
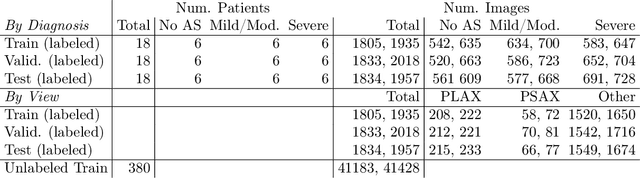
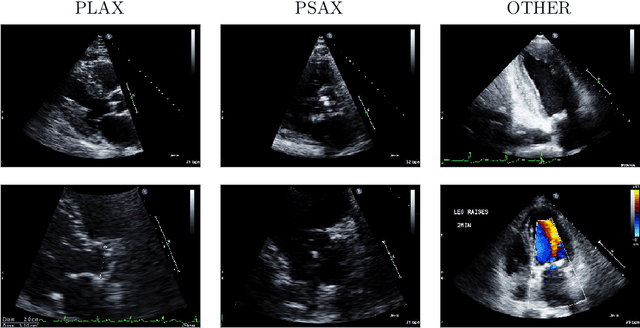
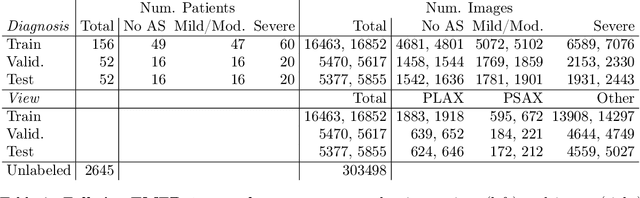
Semi-supervised image classification has shown substantial progress in learning from limited labeled data, but recent advances remain largely untested for clinical applications. Motivated by the urgent need to improve timely diagnosis of life-threatening heart conditions, especially aortic stenosis, we develop a benchmark dataset to assess semi-supervised approaches to two tasks relevant to cardiac ultrasound (echocardiogram) interpretation: view classification and disease severity classification. We find that a state-of-the-art method called MixMatch achieves promising gains in heldout accuracy on both tasks, learning from a large volume of truly unlabeled images as well as a labeled set collected at great expense to achieve better performance than is possible with the labeled set alone. We further pursue patient-level diagnosis prediction, which requires aggregating across hundreds of images of diverse view types, most of which are irrelevant, to make a coherent prediction. The best patient-level performance is achieved by new methods that prioritize diagnosis predictions from images that are predicted to be clinically-relevant views and transfer knowledge from the view task to the diagnosis task. We hope our released Tufts Medical Echocardiogram Dataset and evaluation framework inspire further improvements in multi-task semi-supervised learning for clinical applications.
ELSD: Efficient Line Segment Detector and Descriptor
Apr 29, 2021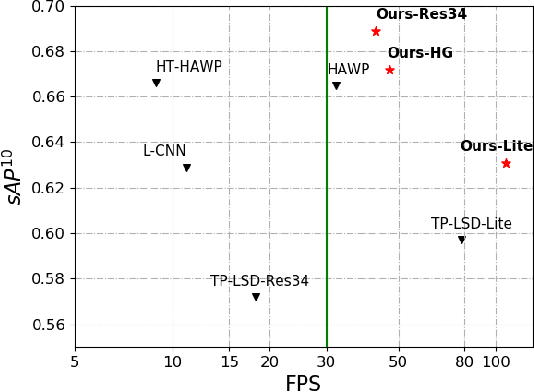
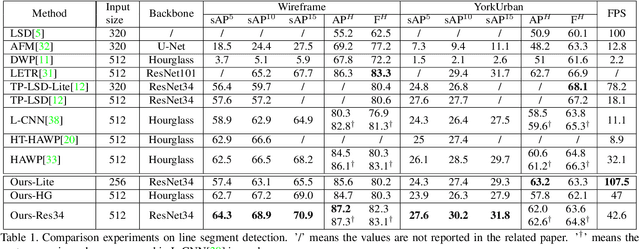
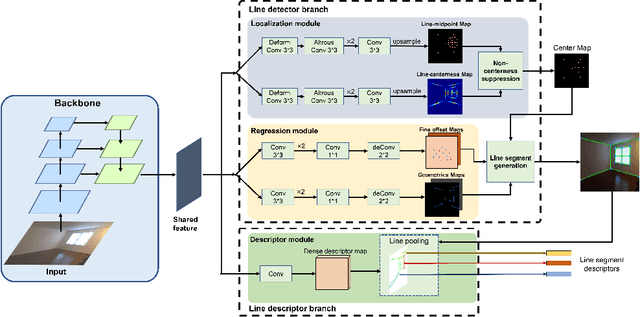
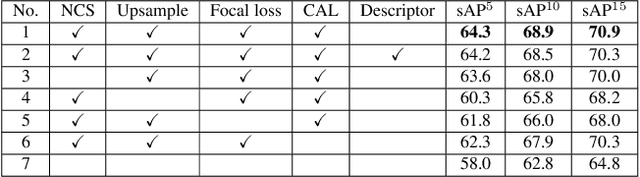
We present the novel Efficient Line Segment Detector and Descriptor (ELSD) to simultaneously detect line segments and extract their descriptors in an image. Unlike the traditional pipelines that conduct detection and description separately, ELSD utilizes a shared feature extractor for both detection and description, to provide the essential line features to the higher-level tasks like SLAM and image matching in real time. First, we design the one-stage compact model, and propose to use the mid-point, angle and length as the minimal representation of line segment, which also guarantees the center-symmetry. The non-centerness suppression is proposed to filter out the fragmented line segments caused by lines' intersections. The fine offset prediction is designed to refine the mid-point localization. Second, the line descriptor branch is integrated with the detector branch, and the two branches are jointly trained in an end-to-end manner. In the experiments, the proposed ELSD achieves the state-of-the-art performance on the Wireframe dataset and YorkUrban dataset, in both accuracy and efficiency. The line description ability of ELSD also outperforms the previous works on the line matching task.
Unsupervised MRI Reconstruction via Zero-Shot Learned Adversarial Transformers
May 15, 2021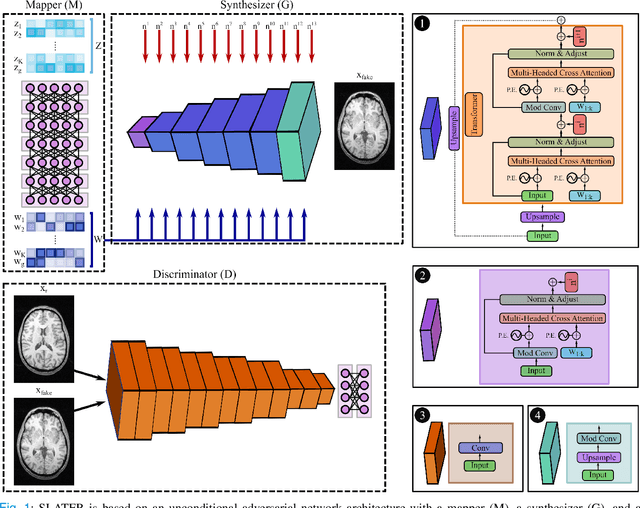
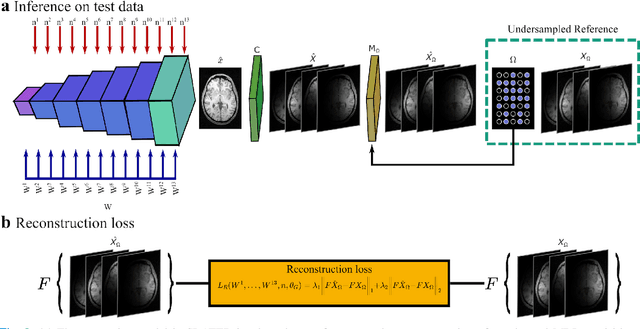
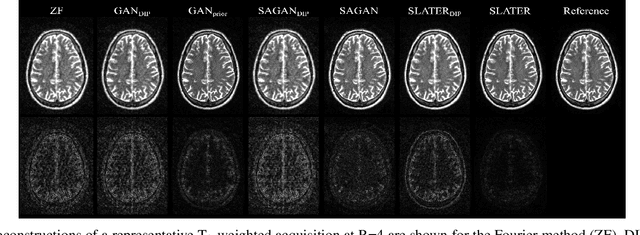
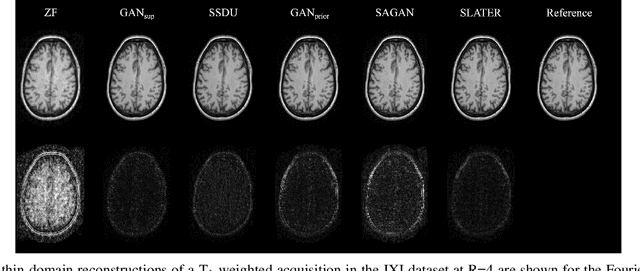
Supervised deep learning has swiftly become a workhorse for accelerated MRI in recent years, offering state-of-the-art performance in image reconstruction from undersampled acquisitions. Training deep supervised models requires large datasets of undersampled and fully-sampled acquisitions typically from a matching set of subjects. Given scarce access to large medical datasets, this limitation has sparked interest in unsupervised methods that reduce reliance on fully-sampled ground-truth data. A common framework is based on the deep image prior, where network-driven regularization is enforced directly during inference on undersampled acquisitions. Yet, canonical convolutional architectures are suboptimal in capturing long-range relationships, and randomly initialized networks may hamper convergence. To address these limitations, here we introduce a novel unsupervised MRI reconstruction method based on zero-Shot Learned Adversarial TransformERs (SLATER). SLATER embodies a deep adversarial network with cross-attention transformer blocks to map noise and latent variables onto MR images. This unconditional network learns a high-quality MRI prior in a self-supervised encoding task. A zero-shot reconstruction is performed on undersampled test data, where inference is performed by optimizing network parameters, latent and noise variables to ensure maximal consistency to multi-coil MRI data. Comprehensive experiments on brain MRI datasets clearly demonstrate the superior performance of SLATER against several state-of-the-art unsupervised methods.
Wavelet Design in a Learning Framework
Jul 23, 2021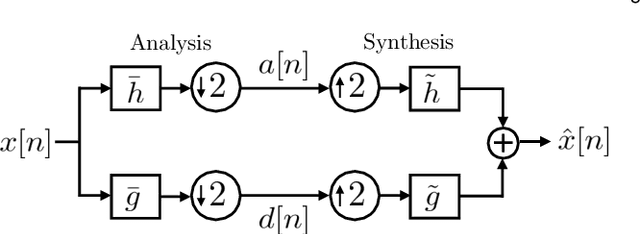
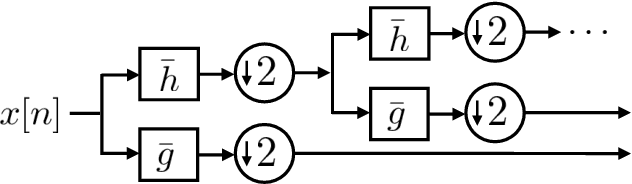
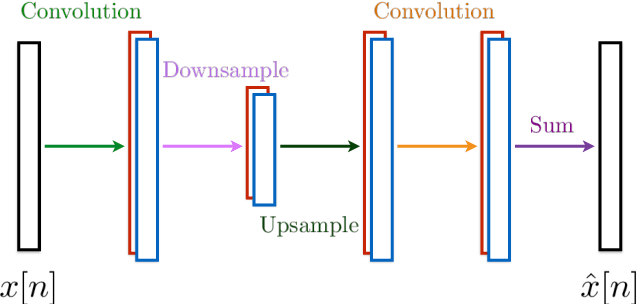
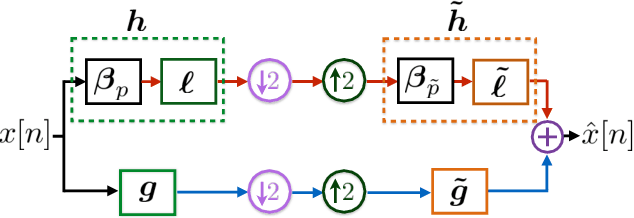
Wavelets have proven to be highly successful in several signal and image processing applications. Wavelet design has been an active field of research for over two decades, with the problem often being approached from an analytical perspective. In this paper, we introduce a learning based approach to wavelet design. We draw a parallel between convolutional autoencoders and wavelet multiresolution approximation, and show how the learning angle provides a coherent computational framework for addressing the design problem. We aim at designing data-independent wavelets by training filterbank autoencoders, which precludes the need for customized datasets. In fact, we use high-dimensional Gaussian vectors for training filterbank autoencoders, and show that a near-zero training loss implies that the learnt filters satisfy the perfect reconstruction property with very high probability. Properties of a wavelet such as orthogonality, compact support, smoothness, symmetry, and vanishing moments can be incorporated by designing the autoencoder architecture appropriately and with a suitable regularization term added to the mean-squared error cost used in the learning process. Our approach not only recovers the well known Daubechies family of orthogonal wavelets and the Cohen-Daubechies-Feauveau family of symmetric biorthogonal wavelets, but also learns wavelets outside these families.
Multi-Modal Pedestrian Detection with Large Misalignment Based on Modal-Wise Regression and Multi-Modal IoU
Jul 23, 2021
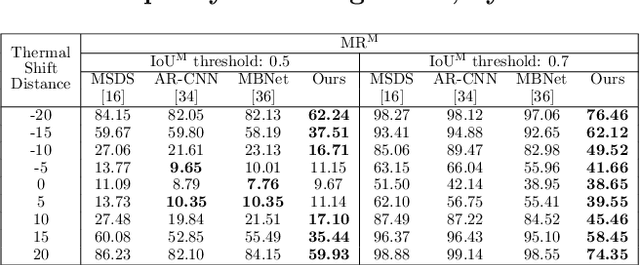
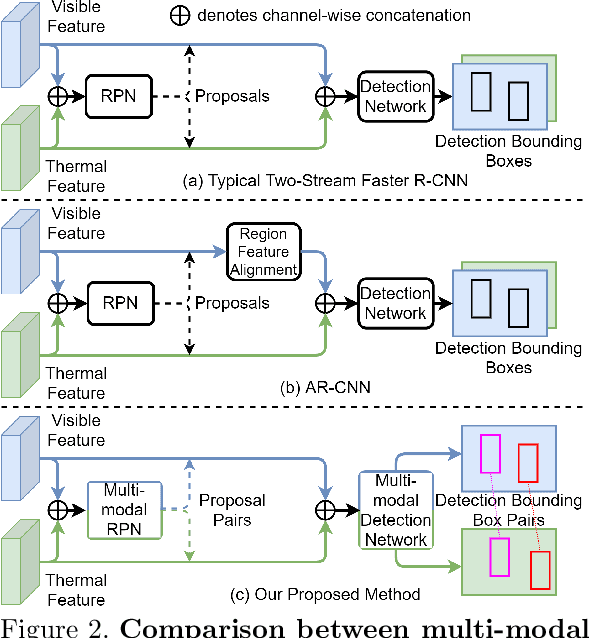
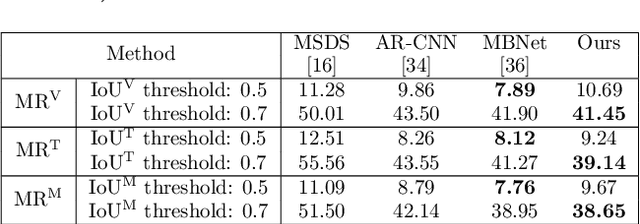
The combined use of multiple modalities enables accurate pedestrian detection under poor lighting conditions by using the high visibility areas from these modalities together. The vital assumption for the combination use is that there is no or only a weak misalignment between the two modalities. In general, however, this assumption often breaks in actual situations. Due to this assumption's breakdown, the position of the bounding boxes does not match between the two modalities, resulting in a significant decrease in detection accuracy, especially in regions where the amount of misalignment is large. In this paper, we propose a multi-modal Faster-RCNN that is robust against large misalignment. The keys are 1) modal-wise regression and 2) multi-modal IoU for mini-batch sampling. To deal with large misalignment, we perform bounding box regression for both the RPN and detection-head with both modalities. We also propose a new sampling strategy called "multi-modal mini-batch sampling" that integrates the IoU for both modalities. We demonstrate that the proposed method's performance is much better than that of the state-of-the-art methods for data with large misalignment through actual image experiments.
Pay attention to the activations: a modular attention mechanism for fine-grained image recognition
Jul 30, 2019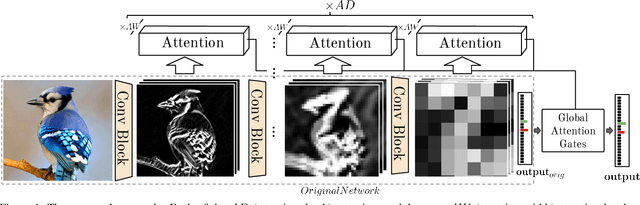
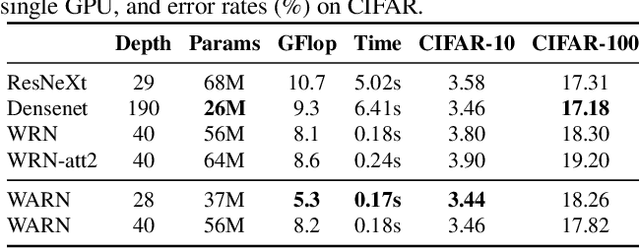
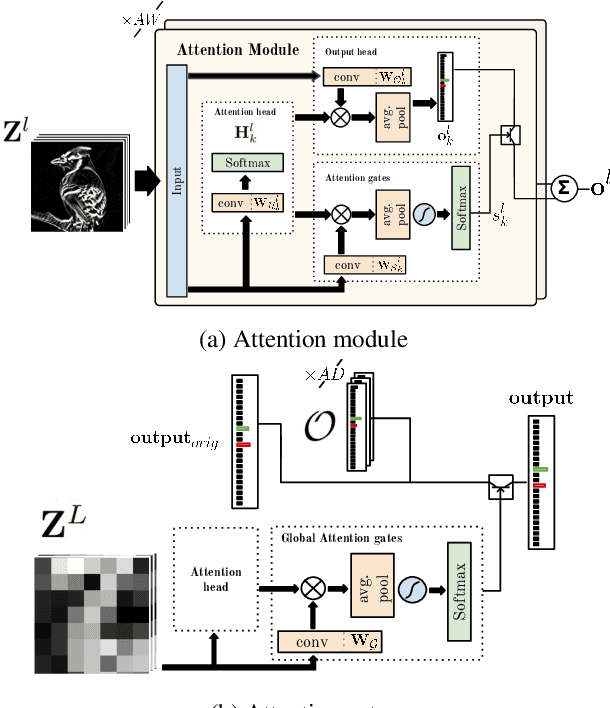
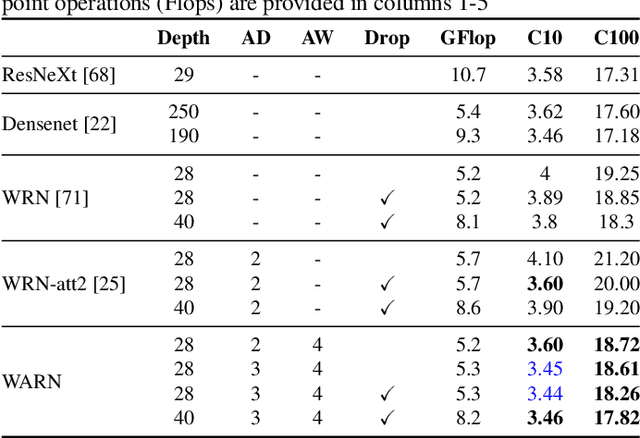
Fine-grained image recognition is central to many multimedia tasks such as search, retrieval and captioning. Unfortunately, these tasks are still challenging since the appearance of samples of the same class can be more different than those from different classes. Attention has been typically implemented in neural networks by selecting the most informative regions of the image that improve classification. In contrast, in this paper, attention is not applied at the image level but to the convolutional feature activations. In essence, with our approach, the neural model learns to attend to lower-level feature activations without requiring part annotations and uses those activations to update and rectify the output likelihood distribution. The proposed mechanism is modular, architecture-independent and efficient in terms of both parameters and computation required. Experiments demonstrate that well-known networks such as Wide Residual Networks and ResNeXt, when augmented with our approach, systematically improve their classification accuracy and become more robust to changes in deformation and pose and to the presence of clutter. As a result, our proposal reaches state-of-the-art classification accuracies in CIFAR-10, the Adience gender recognition task, Stanford Dogs, and UEC-Food100 while obtaining competitive performance in ImageNet, CIFAR-100, CUB200 Birds, and Stanford Cars. In addition, we analyze the different components of our model, showing that the proposed attention modules succeed in finding the most discriminative regions of the image. Finally, as a proof of concept, we demonstrate that with only local predictions, an augmented neural network can successfully classify an image before reaching any fully connected layer, thus reducing the computational amount up to 10%.
Robust Guided Image Filtering
Mar 28, 2017


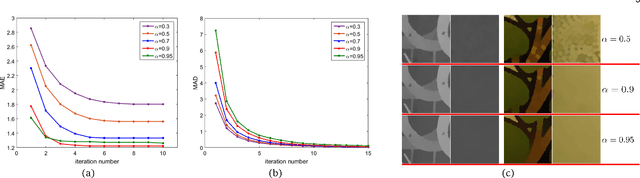
The process of using one image to guide the filtering process of another one is called Guided Image Filtering (GIF). The main challenge of GIF is the structure inconsistency between the guidance image and the target image. Besides, noise in the target image is also a challenging issue especially when it is heavy. In this paper, we propose a general framework for Robust Guided Image Filtering (RGIF), which contains a data term and a smoothness term, to solve the two issues mentioned above. The data term makes our model simultaneously denoise the target image and perform GIF which is robust against the heavy noise. The smoothness term is able to make use of the property of both the guidance image and the target image which is robust against the structure inconsistency. While the resulting model is highly non-convex, it can be solved through the proposed Iteratively Re-weighted Least Squares (IRLS) in an efficient manner. For challenging applications such as guided depth map upsampling, we further develop a data-driven parameter optimization scheme to properly determine the parameter in our model. This optimization scheme can help to preserve small structures and sharp depth edges even for a large upsampling factor (8x for example). Moreover, the specially designed structure of the data term and the smoothness term makes our model perform well in edge-preserving smoothing for single-image tasks (i.e., the guidance image is the target image itself). This paper is an extension of our previous work [1], [2].
Generative adversarial networks in time series: A survey and taxonomy
Jul 23, 2021
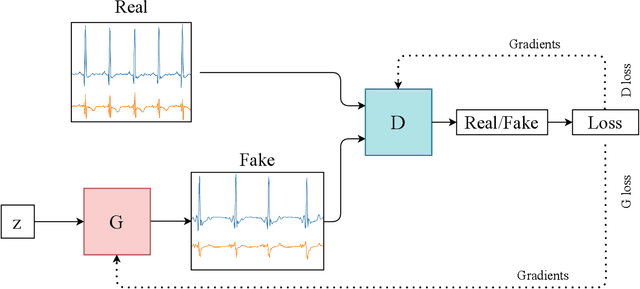
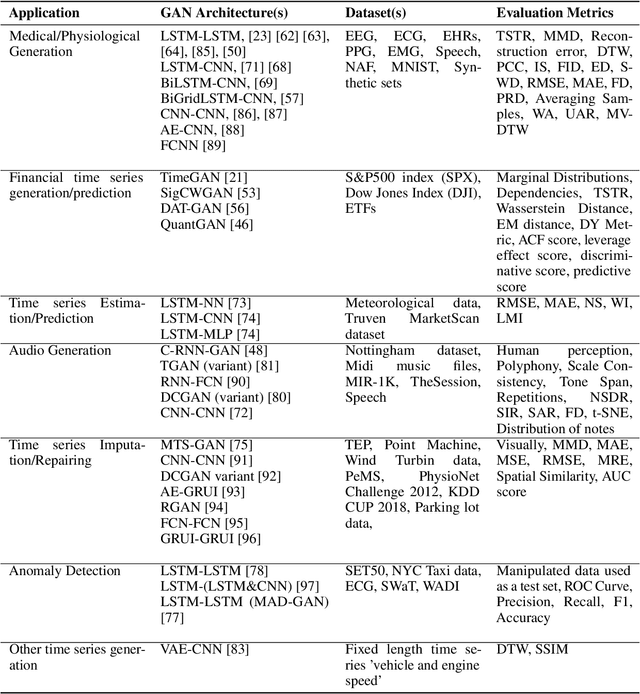
Generative adversarial networks (GANs) studies have grown exponentially in the past few years. Their impact has been seen mainly in the computer vision field with realistic image and video manipulation, especially generation, making significant advancements. While these computer vision advances have garnered much attention, GAN applications have diversified across disciplines such as time series and sequence generation. As a relatively new niche for GANs, fieldwork is ongoing to develop high quality, diverse and private time series data. In this paper, we review GAN variants designed for time series related applications. We propose a taxonomy of discrete-variant GANs and continuous-variant GANs, in which GANs deal with discrete time series and continuous time series data. Here we showcase the latest and most popular literature in this field; their architectures, results, and applications. We also provide a list of the most popular evaluation metrics and their suitability across applications. Also presented is a discussion of privacy measures for these GANs and further protections and directions for dealing with sensitive data. We aim to frame clearly and concisely the latest and state-of-the-art research in this area and their applications to real-world technologies.
Custom Video-Oculography Device and Its Application to Fourth Purkinje Image Detection during Saccades
Apr 15, 2019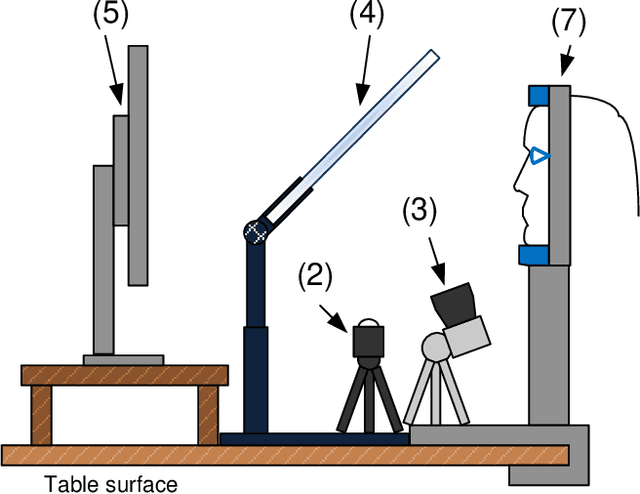
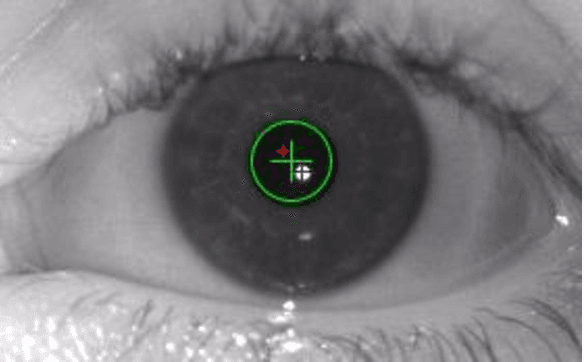
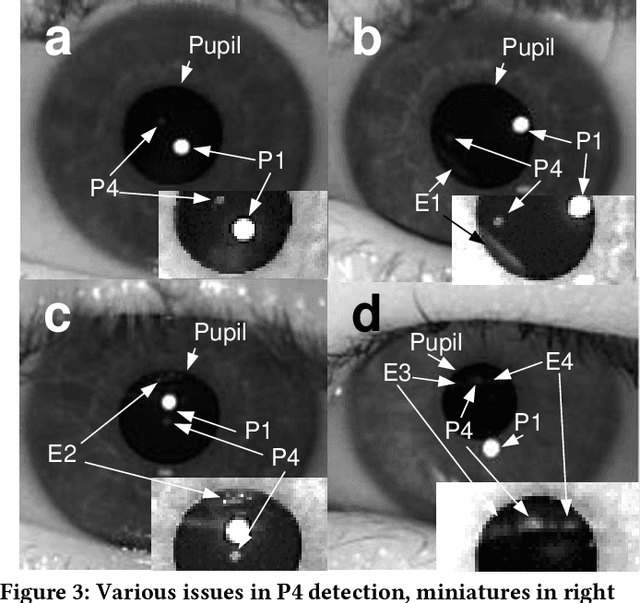
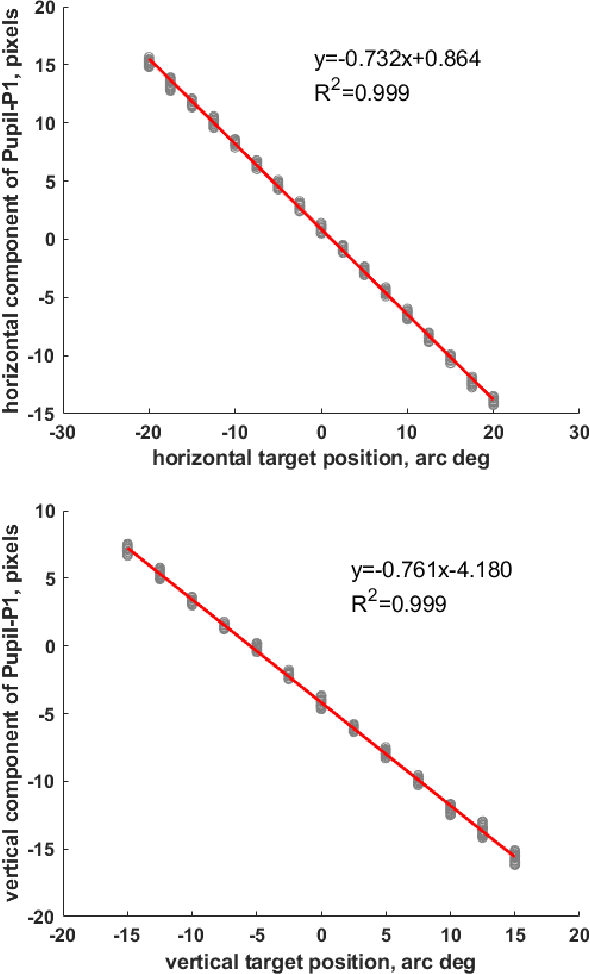
We built a custom video-based eye-tracker that saves every video frame as a full resolution image (MJPEG). Images can be processed offline for the detection of ocular features, including the pupil and corneal reflection (First Purkinje Image, P1) position. A comparison of multiple algorithms for detection of pupil and corneal reflection can be performed. The system provides for highly flexible stimulus creation, with mixing of graphic, image, and video stimuli. We can change cameras and infrared illuminators depending on the image qualities and frame rate desired. Using this system, we have detected the position of the Fourth Purkinje image (P4) in the frames. We show that when we estimate gaze by calculating P1-P4, signal compares well with gaze estimated with a DPI eye-tracker, which natively detects and tracks the P1 and P4.