 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Geometry Uncertainty Projection Network for Monocular 3D Object Detection
Aug 13, 2021
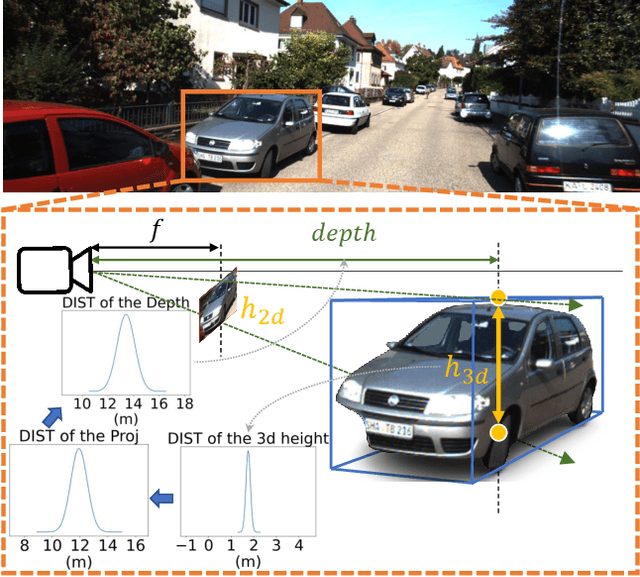
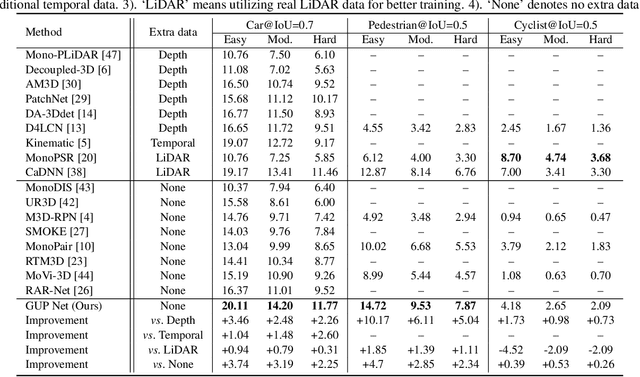
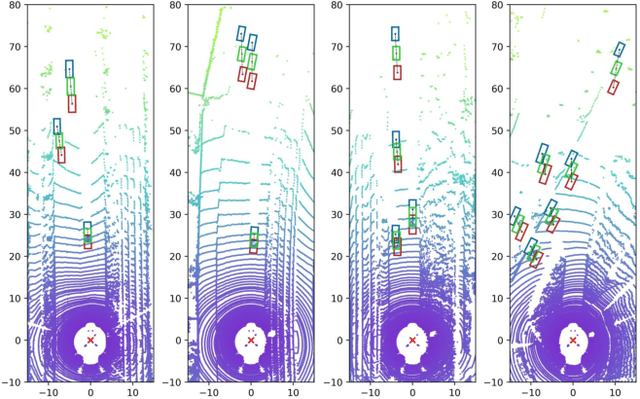
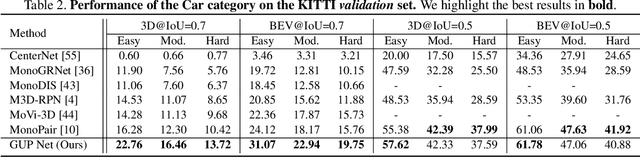
Geometry Projection is a powerful depth estimation method in monocular 3D object detection. It estimates depth dependent on heights, which introduces mathematical priors into the deep model. But projection process also introduces the error amplification problem, in which the error of the estimated height will be amplified and reflected greatly at the output depth. This property leads to uncontrollable depth inferences and also damages the training efficiency. In this paper, we propose a Geometry Uncertainty Projection Network (GUP Net) to tackle the error amplification problem at both inference and training stages. Specifically, a GUP module is proposed to obtains the geometry-guided uncertainty of the inferred depth, which not only provides high reliable confidence for each depth but also benefits depth learning. Furthermore, at the training stage, we propose a Hierarchical Task Learning strategy to reduce the instability caused by error amplification. This learning algorithm monitors the learning situation of each task by a proposed indicator and adaptively assigns the proper loss weights for different tasks according to their pre-tasks situation. Based on that, each task starts learning only when its pre-tasks are learned well, which can significantly improve the stability and efficiency of the training process. Extensive experiments demonstrate the effectiveness of the proposed method. The overall model can infer more reliable object depth than existing methods and outperforms the state-of-the-art image-based monocular 3D detectors by 3.74% and 4.7% AP40 of the car and pedestrian categories on the KITTI benchmark.
Uniformity in Heterogeneity:Diving Deep into Count Interval Partition for Crowd Counting
Aug 07, 2021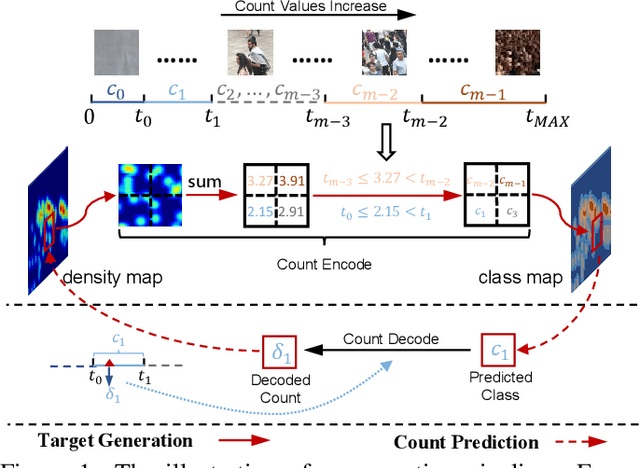
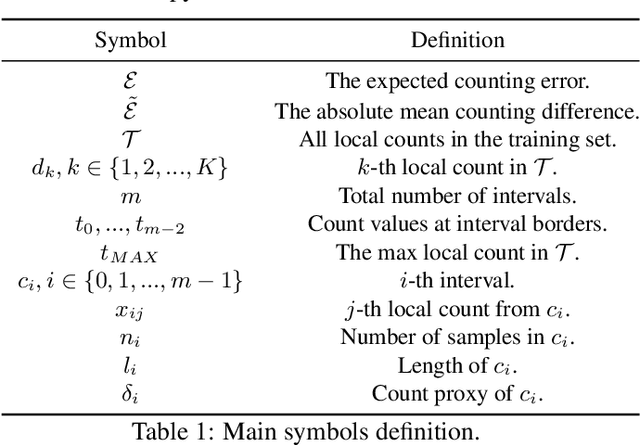
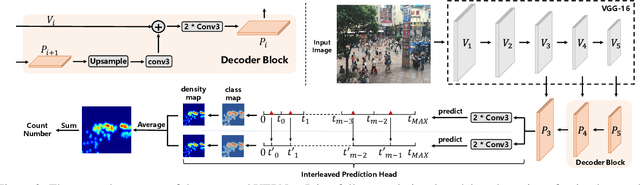
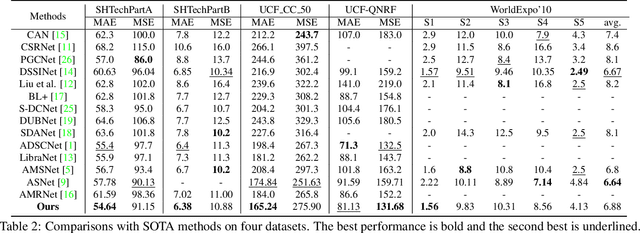
Recently, the problem of inaccurate learning targets in crowd counting draws increasing attention. Inspired by a few pioneering work, we solve this problem by trying to predict the indices of pre-defined interval bins of counts instead of the count values themselves. However, an inappropriate interval setting might make the count error contributions from different intervals extremely imbalanced, leading to inferior counting performance. Therefore, we propose a novel count interval partition criterion called Uniform Error Partition (UEP), which always keeps the expected counting error contributions equal for all intervals to minimize the prediction risk. Then to mitigate the inevitably introduced discretization errors in the count quantization process, we propose another criterion called Mean Count Proxies (MCP). The MCP criterion selects the best count proxy for each interval to represent its count value during inference, making the overall expected discretization error of an image nearly negligible. As far as we are aware, this work is the first to delve into such a classification task and ends up with a promising solution for count interval partition. Following the above two theoretically demonstrated criterions, we propose a simple yet effective model termed Uniform Error Partition Network (UEPNet), which achieves state-of-the-art performance on several challenging datasets. The codes will be available at: https://github.com/TencentYoutuResearch/CrowdCounting-UEPNet.
Unsupervised Natural Image Patch Learning
Jun 28, 2018
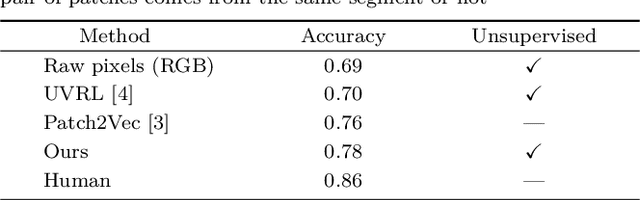

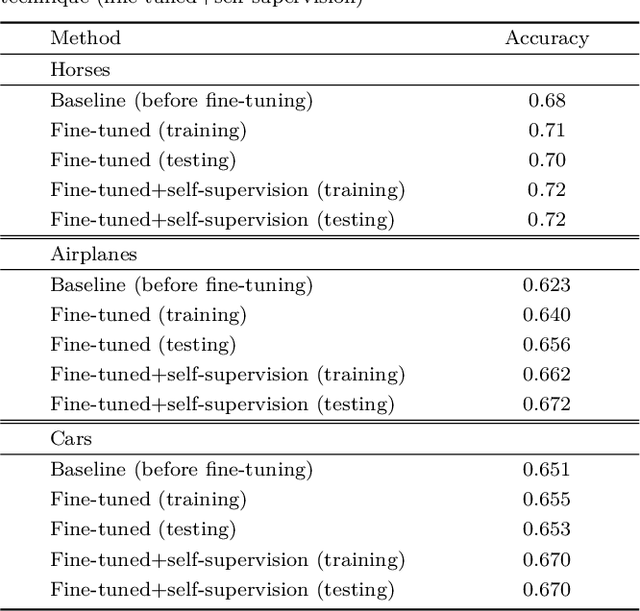
Learning a metric of natural image patches is an important tool for analyzing images. An efficient means is to train a deep network to map an image patch to a vector space, in which the Euclidean distance reflects patch similarity. Previous attempts learned such an embedding in a supervised manner, requiring the availability of many annotated images. In this paper, we present an unsupervised embedding of natural image patches, avoiding the need for annotated images. The key idea is that the similarity of two patches can be learned from the prevalence of their spatial proximity in natural images. Clearly, relying on this simple principle, many spatially nearby pairs are outliers, however, as we show, the outliers do not harm the convergence of the metric learning. We show that our unsupervised embedding approach is more effective than a supervised one or one that uses deep patch representations. Moreover, we show that it naturally leads itself to an efficient self-supervised domain adaptation technique onto a target domain that contains a common foreground object.
A System for Automated Image Editing from Natural Language Commands
Dec 03, 2018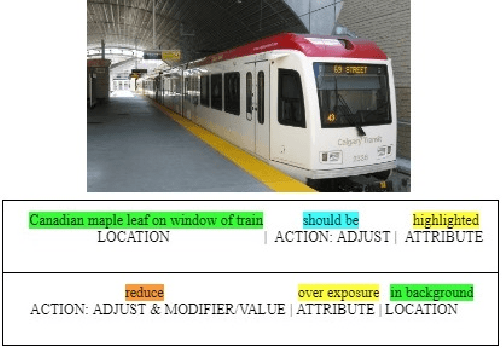
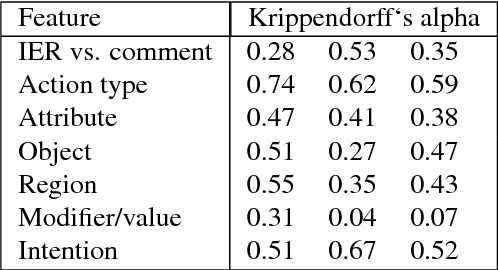
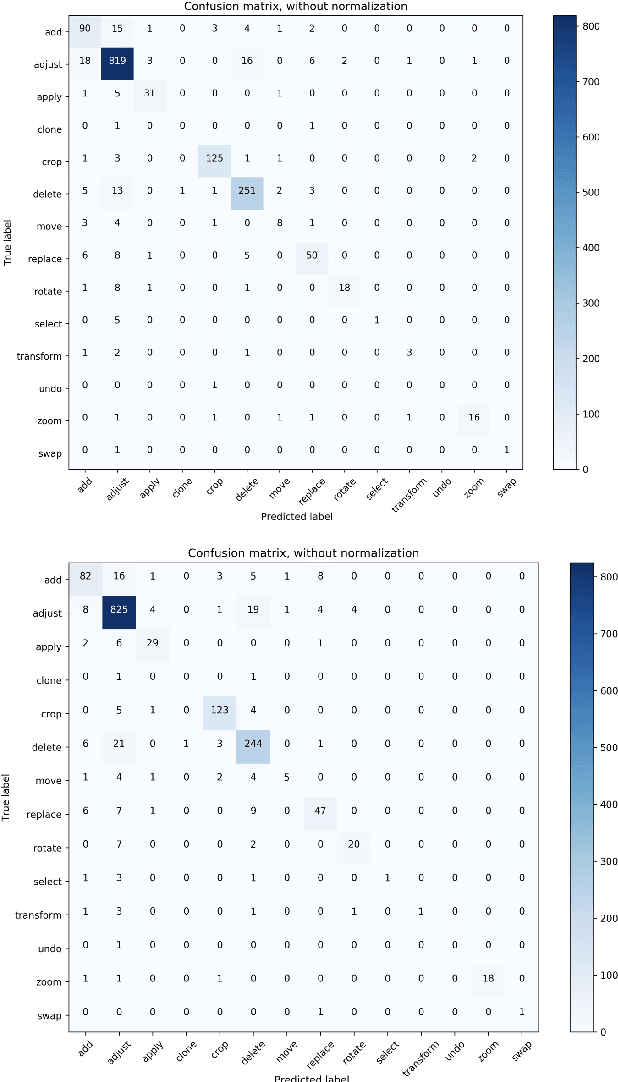
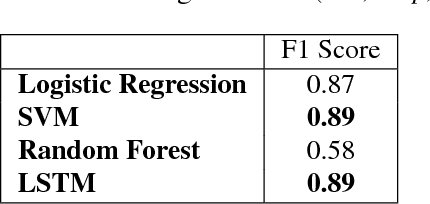
This work presents the task of modifying images in an image editing program using natural language written commands. We utilize a corpus of over 6000 image edit text requests to alter real world images collected via crowdsourcing. A novel framework composed of actions and entities to map a user's natural language request to executable commands in an image editing program is described. We resolve previously labeled annotator disagreement through a voting process and complete annotation of the corpus. We experimented with different machine learning models and found that the LSTM, the SVM, and the bidirectional LSTM-CRF joint models are the best to detect image editing actions and associated entities in a given utterance.
Describing and Localizing Multiple Changes with Transformers
Mar 25, 2021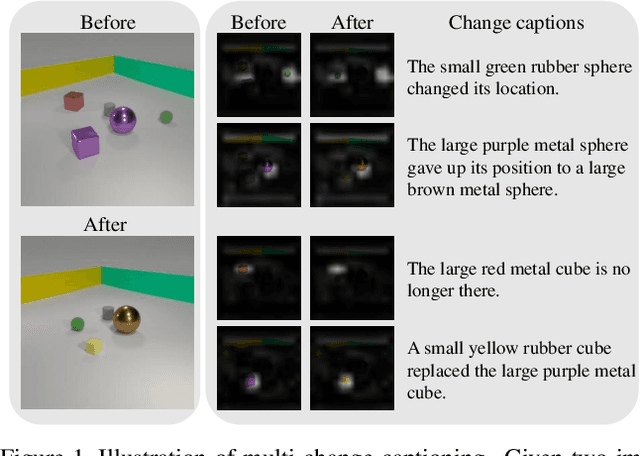
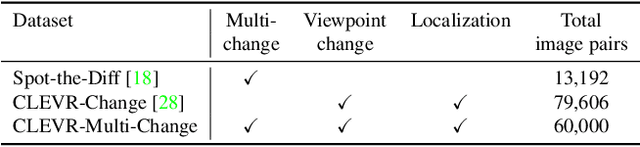


Change captioning tasks aim to detect changes in image pairs observed before and after a scene change and generate a natural language description of the changes. Existing change captioning studies have mainly focused on scenes with a single change. However, detecting and describing multiple changed parts in image pairs is essential for enhancing adaptability to complex scenarios. We solve the above issues from three aspects: (i) We propose a CG-based multi-change captioning dataset; (ii) We benchmark existing state-of-the-art methods of single change captioning on multi-change captioning; (iii) We further propose Multi-Change Captioning transformers (MCCFormers) that identify change regions by densely correlating different regions in image pairs and dynamically determines the related change regions with words in sentences. The proposed method obtained the highest scores on four conventional change captioning evaluation metrics for multi-change captioning. In addition, existing methods generate a single attention map for multiple changes and lack the ability to distinguish change regions. In contrast, our proposed method can separate attention maps for each change and performs well with respect to change localization. Moreover, the proposed framework outperformed the previous state-of-the-art methods on an existing change captioning benchmark, CLEVR-Change, by a large margin (+6.1 on BLEU-4 and +9.7 on CIDEr scores), indicating its general ability in change captioning tasks.
Incorporating Label Uncertainty in Understanding Adversarial Robustness
Jul 07, 2021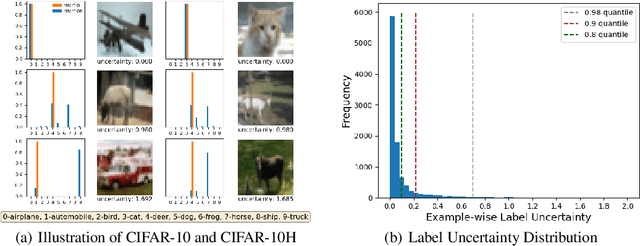
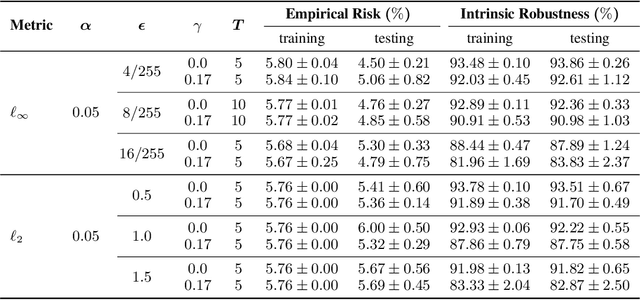
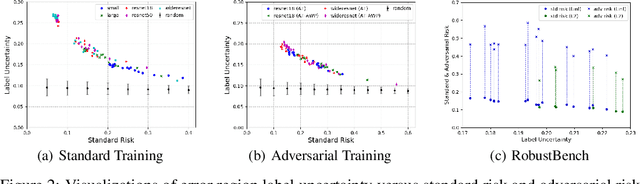
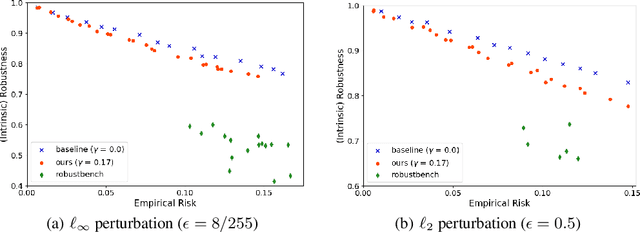
A fundamental question in adversarial machine learning is whether a robust classifier exists for a given task. A line of research has made progress towards this goal by studying concentration of measure, but without considering data labels. We argue that the standard concentration fails to fully characterize the intrinsic robustness of a classification problem, since it ignores data labels which are essential to any classification task. Building on a novel definition of label uncertainty, we empirically demonstrate that error regions induced by state-of-the-art models tend to have much higher label uncertainty compared with randomly-selected subsets. This observation motivates us to adapt a concentration estimation algorithm to account for label uncertainty, resulting in more accurate intrinsic robustness measures for benchmark image classification problems. We further provide empirical evidence showing that adding an abstain option for classifiers based on label uncertainty can help improve both the clean and robust accuracies of models.
Removing Blocking Artifacts in Video Streams Using Event Cameras
May 12, 2021
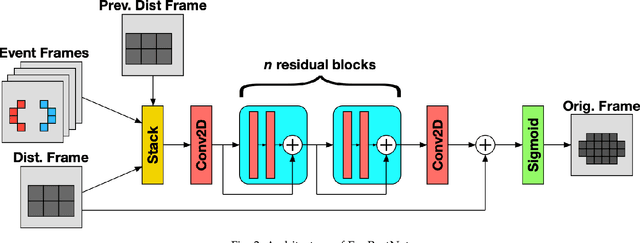
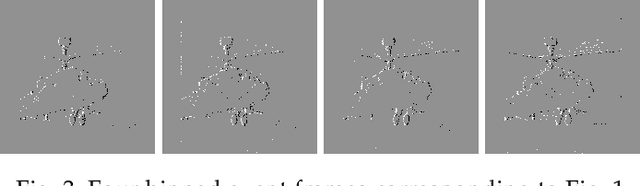

In this paper, we propose EveRestNet, a convolutional neural network designed to remove blocking artifacts in videostreams using events from neuromorphic sensors. We first degrade the video frame using a quadtree structure to produce the blocking artifacts to simulate transmitting a video under a heavily constrained bandwidth. Events from the neuromorphic sensor are also simulated, but are transmitted in full. Using the distorted frames and the event stream, EveRestNet is able to improve the image quality.
Fuzzy Semantic Segmentation of Breast Ultrasound Image with Breast Anatomy Constraints
Oct 23, 2019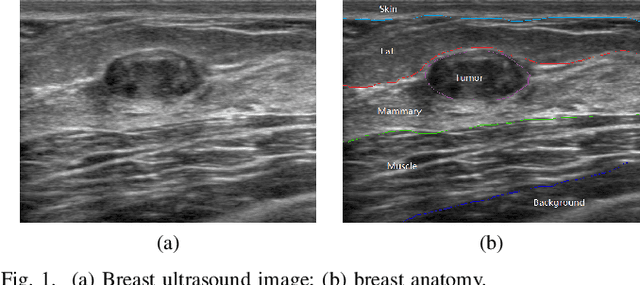


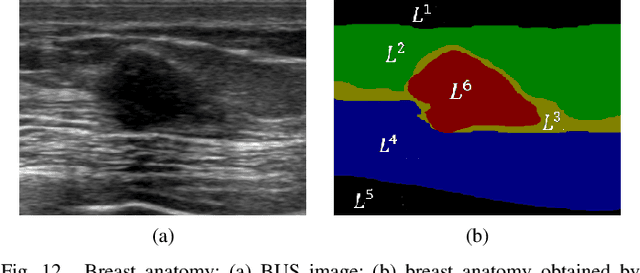
Breast cancer is one of the most serious disease affecting women's health. Due to low cost, portable, no radiation, and high efficiency, breast ultrasound (BUS) imaging is the most popular approach for diagnosing early breast cancer. However, ultrasound images are low resolution and poor quality. Thus, developing accurate detection system is a challenging task. In this paper, we propose a fully automatic segmentation algorithm consisting of two parts: fuzzy fully convolutional network and accurately fine-tuning post-processing based on breast anatomy constraints. In the first part, the image is preprocessed by contrast enhancement, and wavelet features are employed for image augmentation. A fuzzy membership function transforms the augmented BUS images into fuzzy domain. The features from convolutional layers are processed using fuzzy logic as well. The conditional random fields (CRFs) post-process the segmentation result. The location relation among the breast anatomy layers is utilized to improve the performance. The proposed method is applied to the dataset with 325 BUS images, and achieves state-of-art performance compared with that of existing methods with true positive rate 90.33%, false positive rate 9.00%, and intersection over union (IoU) 81.29% on tumor category, and overall intersection over union (mIoU) 80.47% over five categories: fat layer, mammary layer, muscle layer, background, and tumor.
Graph Convolutional Subspace Clustering: A Robust Subspace Clustering Framework for Hyperspectral Image
Apr 22, 2020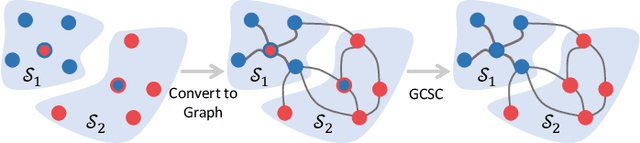
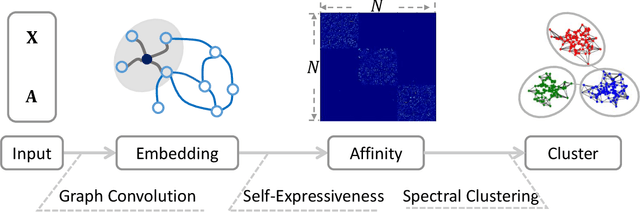
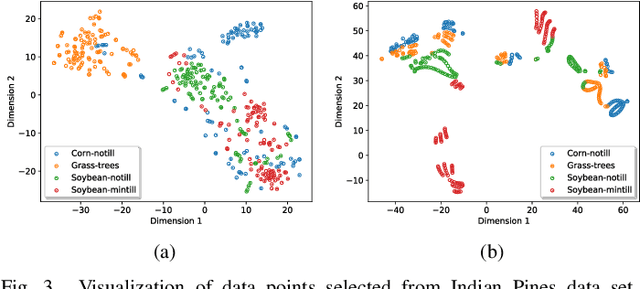

Hyperspectral image (HSI) clustering is a challenging task due to the high complexity of HSI data. Subspace clustering has been proven to be powerful for exploiting the intrinsic relationship between data points. Despite the impressive performance in the HSI clustering, traditional subspace clustering methods often ignore the inherent structural information among data. In this paper, we revisit the subspace clustering with graph convolution and present a novel subspace clustering framework called Graph Convolutional Subspace Clustering (GCSC) for robust HSI clustering. Specifically, the framework recasts the self-expressiveness property of the data into the non-Euclidean domain, which results in a more robust graph embedding dictionary. We show that traditional subspace clustering models are the special forms of our framework with the Euclidean data. Basing on the framework, we further propose two novel subspace clustering models by using the Frobenius norm, namely Efficient GCSC (EGCSC) and Efficient Kernel GCSC (EKGCSC). Both models have a globally optimal closed-form solution, which makes them easier to implement, train, and apply in practice. Extensive experiments on three popular HSI datasets demonstrate that EGCSC and EKGCSC can achieve state-of-the-art clustering performance and dramatically outperforms many existing methods with significant margins.
H-GAN: the power of GANs in your Hands
Mar 27, 2021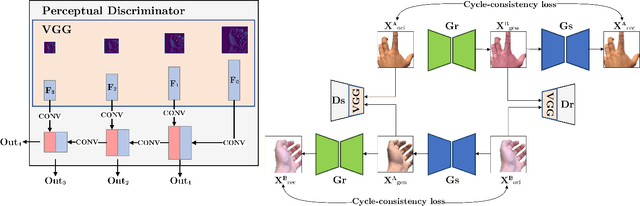
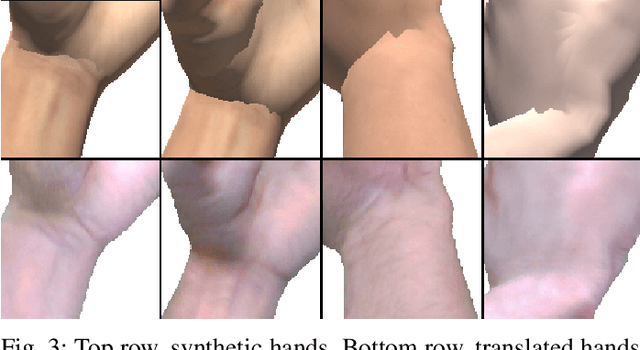
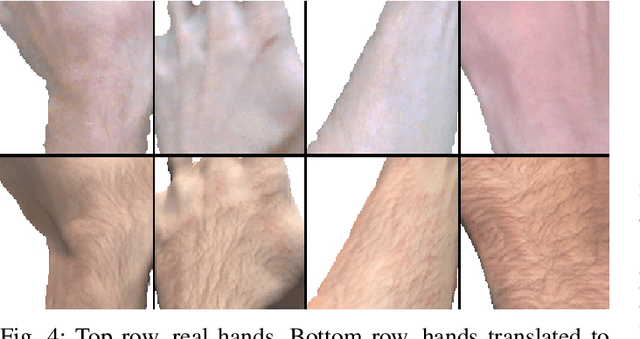
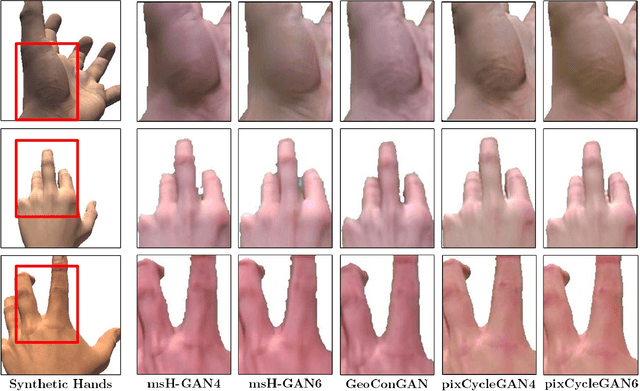
We present HandGAN (H-GAN), a cycle-consistent adversarial learning approach implementing multi-scale perceptual discriminators. It is designed to translate synthetic images of hands to the real domain. Synthetic hands provide complete ground-truth annotations, yet they are not representative of the target distribution of real-world data. We strive to provide the perfect blend of a realistic hand appearance with synthetic annotations. Relying on image-to-image translation, we improve the appearance of synthetic hands to approximate the statistical distribution underlying a collection of real images of hands. H-GAN tackles not only cross-domain tone mapping but also structural differences in localized areas such as shading discontinuities. Results are evaluated on a qualitative and quantitative basis improving previous works. Furthermore, we successfully apply the generated images to the hand classification task.