 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Transfer learning approach to Classify the X-ray image that corresponds to corona disease Using ResNet50 pretrained by ChexNet
May 18, 2021
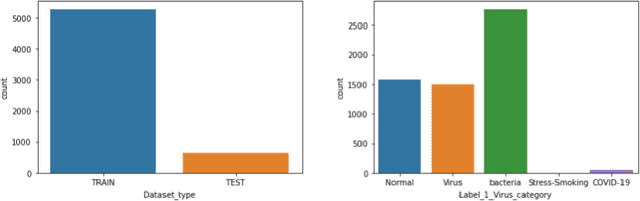

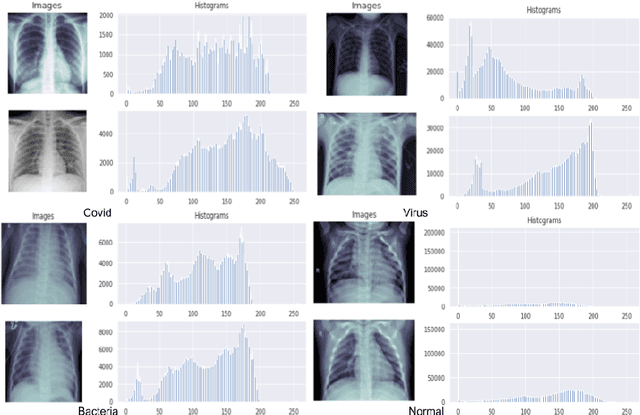
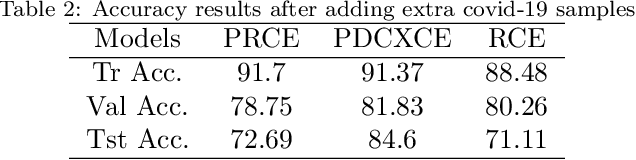
Coronavirus adversely has affected people worldwide. There are common symptoms between the Covid19 virus disease and other respiratory diseases like pneumonia or Influenza. Therefore, diagnosing it fast is crucial not only to save patients but also to prevent it from spreading. One of the most reliant methods of diagnosis is through X-ray images of a lung. With the help of deep learning approaches, we can teach the deep model to learn the condition of an affected lung. Therefore, it can classify the new sample as if it is a Covid19 infected patient or not. In this project, we train a deep model based on ResNet50 pretrained by ImageNet dataset and CheXNet dataset. Based on the imbalanced CoronaHack Chest X-Ray dataset introducing by Kaggle we applied both binary and multi-class classification. Also, we compare the results when using Focal loss and Cross entropy loss.
Learning event representations in image sequences by dynamic graph embedding
Oct 08, 2019
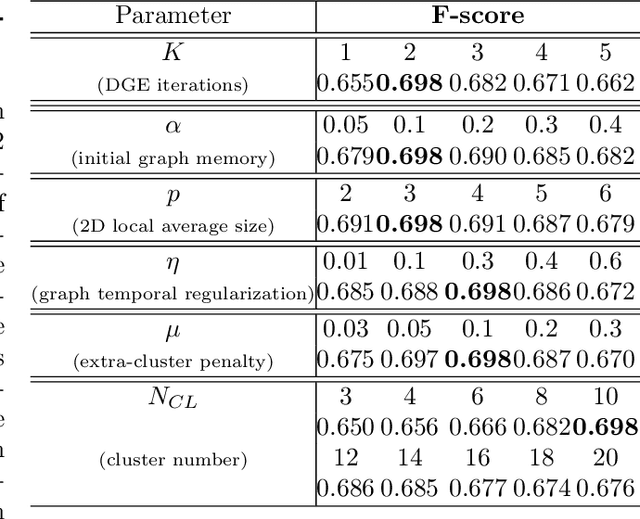
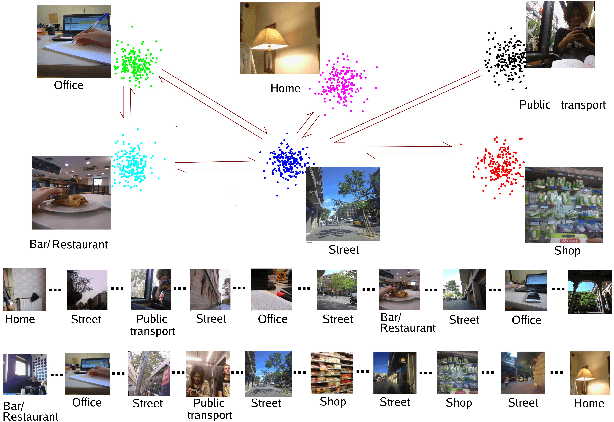
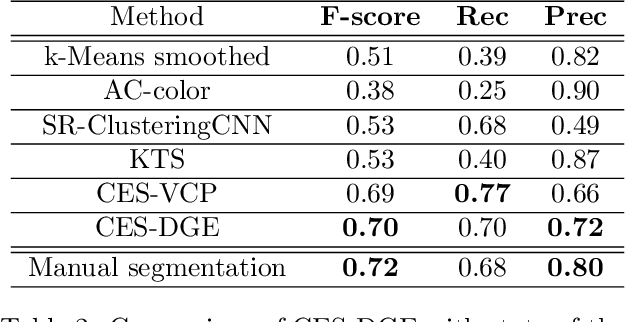
Recently, self-supervised learning has proved to be effective to learn representations of events in image sequences, where events are understood as sets of temporally adjacent images that are semantically perceived as a whole. However, although this approach does not require expensive manual annotations, it is data hungry and suffers from domain adaptation problems. As an alternative, in this work, we propose a novel approach for learning event representations named Dynamic Graph Embedding (DGE). The assumption underlying our model is that a sequence of images can be represented by a graph that encodes both semantic and temporal similarity. The key novelty of DGE is to learn jointly the graph and its graph embedding. At its core, DGE works by iterating over two steps: 1) updating the graph representing the semantic and temporal structure of the data based on the current data representation, and 2) updating the data representation to take into account the current data graph structure. The main advantage of DGE over state-of-the-art self-supervised approaches is that it does not require any training set, but instead learns iteratively from the data itself a low-dimensional embedding that reflects their temporal and semantic structure. Experimental results on two benchmark datasets of real image sequences captured at regular intervals demonstrate that the proposed DGE leads to effective event representations. In particular, it achieves robust temporal segmentation on the EDUBSeg and EDUBSeg-Desc benchmark datasets, outperforming the state of the art.
SynthRef: Generation of Synthetic Referring Expressions for Object Segmentation
Jun 08, 2021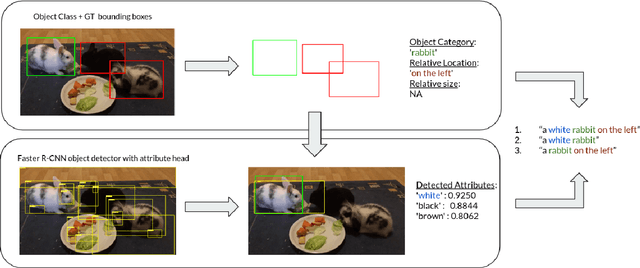



Recent advances in deep learning have brought significant progress in visual grounding tasks such as language-guided video object segmentation. However, collecting large datasets for these tasks is expensive in terms of annotation time, which represents a bottleneck. To this end, we propose a novel method, namely SynthRef, for generating synthetic referring expressions for target objects in an image (or video frame), and we also present and disseminate the first large-scale dataset with synthetic referring expressions for video object segmentation. Our experiments demonstrate that by training with our synthetic referring expressions one can improve the ability of a model to generalize across different datasets, without any additional annotation cost. Moreover, our formulation allows its application to any object detection or segmentation dataset.
GPLA-12: An Acoustic Signal Dataset of Gas Pipeline Leakage
Jun 19, 2021

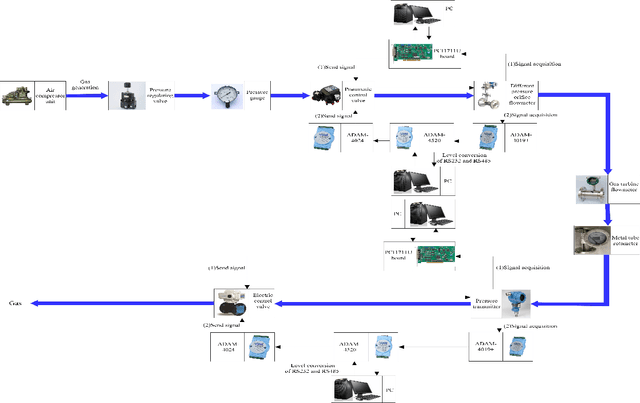

In this paper, we introduce a new acoustic leakage dataset of gas pipelines, called as GPLA-12, which has 12 categories over 684 training/testing acoustic signals. Unlike massive image and voice datasets, there have relatively few acoustic signal datasets, especially for engineering fault detection. In order to enhance the development of fault diagnosis, we collect acoustic leakage signals on the basis of an intact gas pipe system with external artificial leakages, and then preprocess the collected data with structured tailoring which are turned into GPLA-12. GPLA-12 dedicates to serve as a feature learning dataset for time-series tasks and classifications. To further understand the dataset, we train both shadow and deep learning algorithms to observe the performance. The dataset as well as the pretrained models have been released at both www.daip.club and github.com/Deep-AI-Application-DAIP
Unsupervised Deep Features for Remote Sensing Image Matching via Discriminator Network
Oct 15, 2018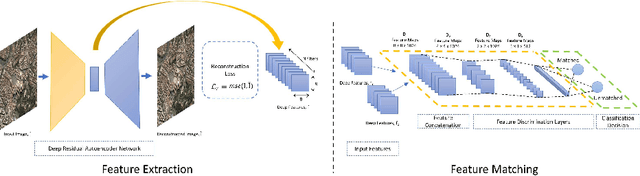

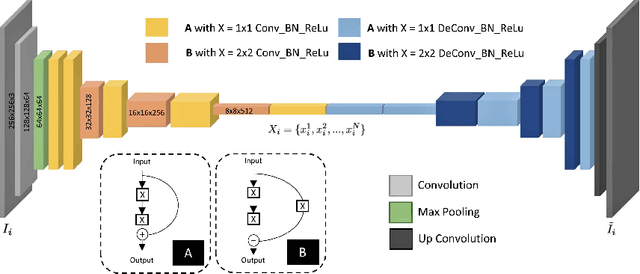
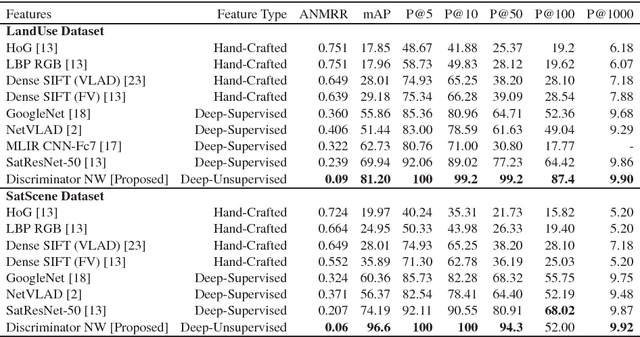
The advent of deep perceptual networks brought about a paradigm shift in machine vision and image perception. Image apprehension lately carried out by hand-crafted features in the latent space have been replaced by deep features acquired from supervised networks for improved understanding. However, such deep networks require strict supervision with a substantial amount of the labeled data for authentic training process. These methods perform poorly in domains lacking labeled data especially in case of remote sensing image retrieval. Resolving this, we propose an unsupervised encoder-decoder feature for remote sensing image matching (RSIM). Moreover, we replace the conventional distance metrics with a deep discriminator network to identify the similarity of the image pairs. To the best of our knowledge, discriminator network has never been used before for solving RSIM problem. Results have been validated with two publicly available benchmark remote sensing image datasets. The technique has also been investigated for content-based remote sensing image retrieval (CBRSIR); one of the widely used applications of RSIM. Results demonstrate that our technique supersedes the state-of-the-art methods used for unsupervised image matching with mean average precision (mAP) of 81%, and image retrieval with an overall improvement in mAP score of about 12%.
Helsinki Deblur Challenge 2021: description of photographic data
May 21, 2021

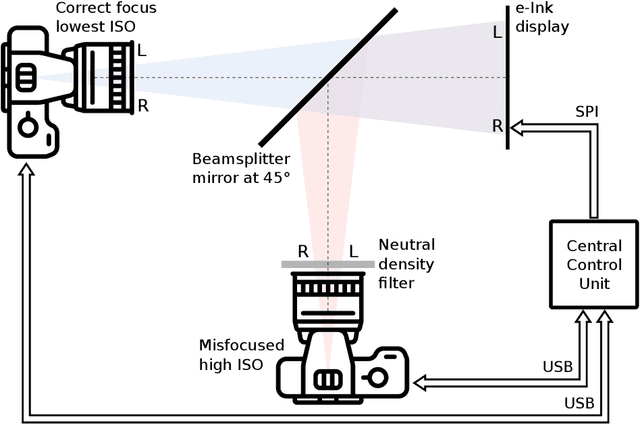
The photographic dataset collected for the Helsinki Deblur Challenge 2021 (HDC2021) contains pairs of images taken by two identical cameras of the same target but with different conditions. One camera is always in focus and produces sharp and low-noise images the other camera produces blurred and noisy images as it is gradually more and more out of focus and has a higher ISO setting. Even though the dataset was designed and captured with the HDC2021 in mind it can be used for any testing and benchmarking of image deblurring algorithms. The data is available here: https://doi.org/10.5281/zenodo.477228
Multi-Temporal High Resolution Aerial Image Registration Using Semantic Features
Aug 30, 2019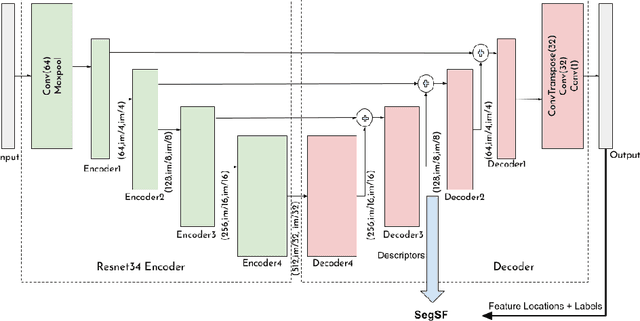


A new type of segmentation-based semantic feature (SegSF) for multi-temporal aerial image registration is proposed in this paper. These features encode information about temporally invariant objects such as roads which help deal with the issues such as changing foliage that classical handcrafted features are unable to address. These features are extracted from a semantic segmentation network and show good accuracy in registering aerial images across years and seasons.
Multi-Instance Learning by Utilizing Structural Relationship among Instances
Feb 03, 2021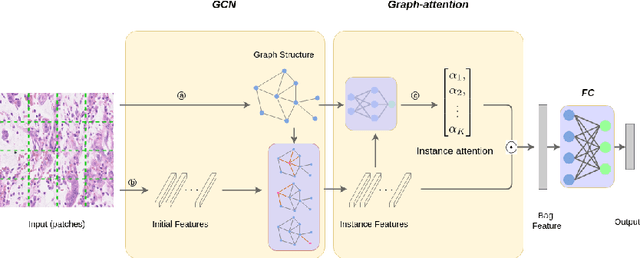
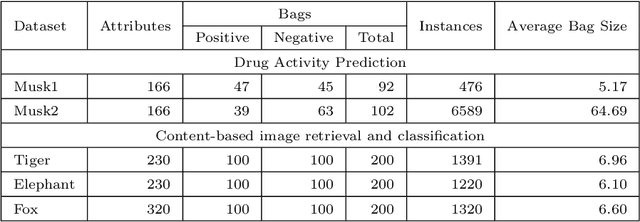
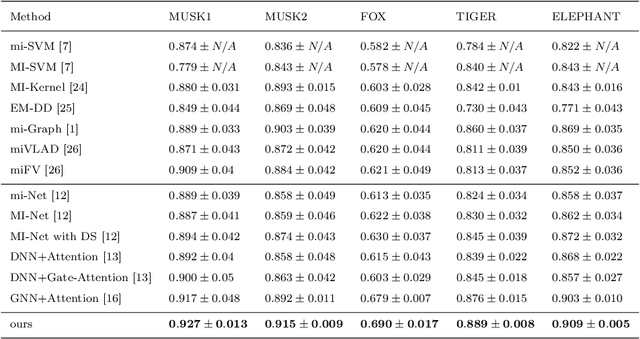

Multi-Instance Learning(MIL) aims to learn the mapping between a bag of instances and the bag-level label. Therefore, the relationships among instances are very important for learning the mapping. In this paper, we propose an MIL algorithm based on a graph built by structural relationship among instances within a bag. Then, Graph Convolutional Network(GCN) and the graph-attention mechanism are used to learn bag-embedding. In the task of medical image classification, our GCN-based MIL algorithm makes full use of the structural relationships among patches(instances) in an original image space domain, and experimental results verify that our method is more suitable for handling medical high-resolution images. We also verify experimentally that the proposed method achieves better results than previous methods on five bechmark MIL datasets and four medical image datasets.
Towards multi-sequence MR image recovery from undersampled k-space data
Aug 16, 2019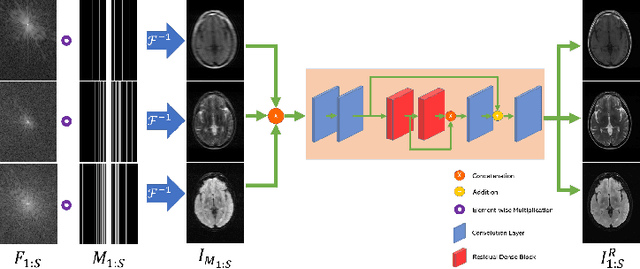
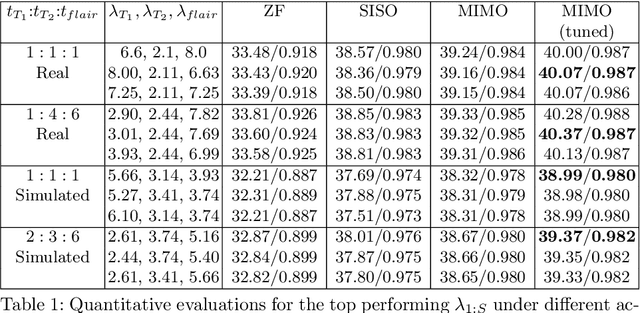
Undersampled MR image recovery has been widely studied for accelerated MR acquisition. However, it has been mostly studied under a single sequence scenario, despite the fact that multi-sequence MR scan is common in practice. In this paper, we aim to optimize multi-sequence MR image recovery from undersampled k-space data under an overall time constraint while considering the difference in acquisition time for various sequences. We first formulate it as a constrained optimization problem and then show that finding the optimal sampling strategy for all sequences and the best recovery model at the same time is combinatorial and hence computationally prohibitive. To solve this problem, we propose a blind recovery model that simultaneously recovers multiple sequences, and an efficient approach to find proper combination of sampling strategy and recovery model. Our experiments demonstrate that the proposed method outperforms sequence-wise recovery, and sheds light on how to decide the undersampling strategy for sequences within an overall time budget.
LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference
Apr 02, 2021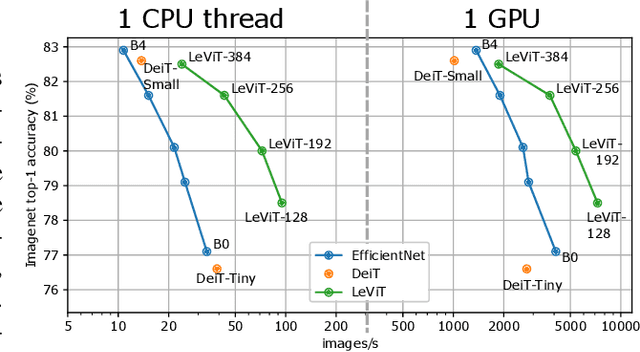
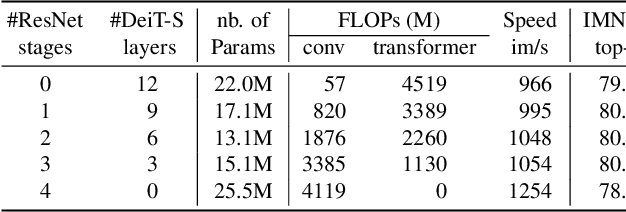

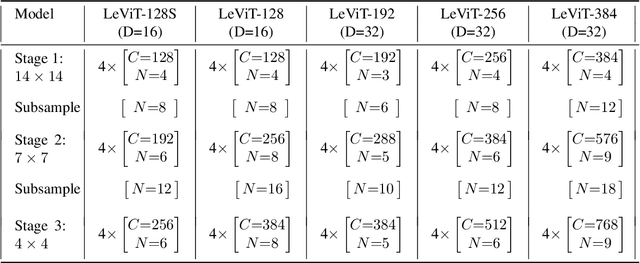
We design a family of image classification architectures that optimize the trade-off between accuracy and efficiency in a high-speed regime. Our work exploits recent findings in attention-based architectures, which are competitive on highly parallel processing hardware. We re-evaluated principles from the extensive literature on convolutional neural networks to apply them to transformers, in particular activation maps with decreasing resolutions. We also introduce the attention bias, a new way to integrate positional information in vision transformers. As a result, we propose LeVIT: a hybrid neural network for fast inference image classification. We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect to the speed/accuracy tradeoff. For example, at 80\% ImageNet top-1 accuracy, LeViT is 3.3 times faster than EfficientNet on the CPU.