 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spline Positional Encoding for Learning 3D Implicit Signed Distance Fields
Jun 03, 2021
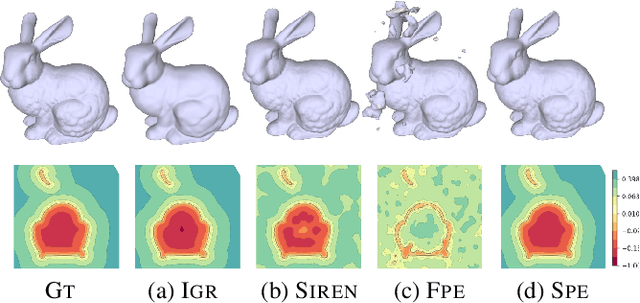

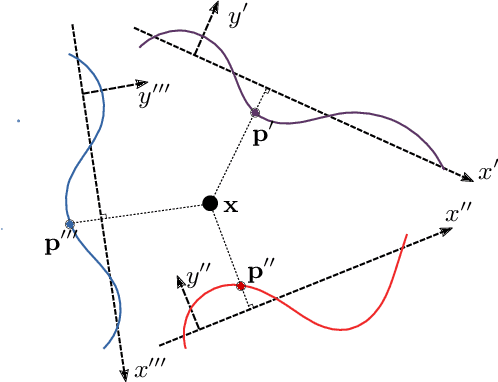
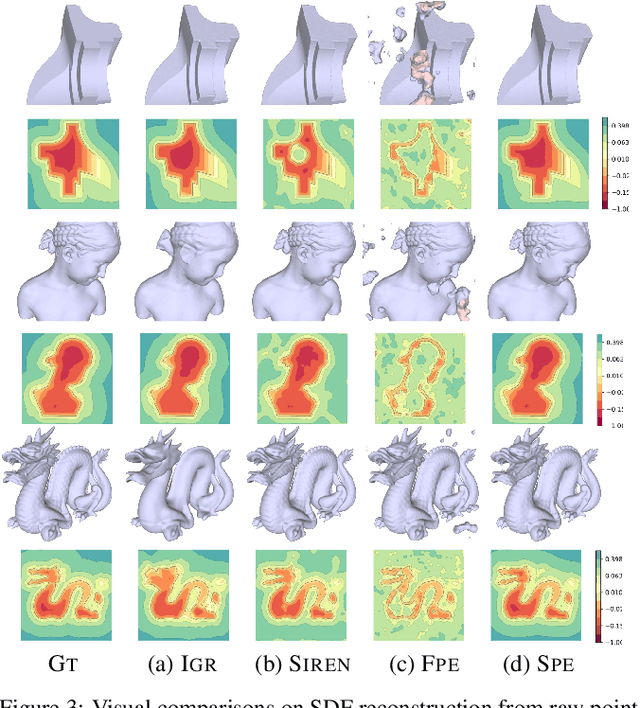
Multilayer perceptrons (MLPs) have been successfully used to represent 3D shapes implicitly and compactly, by mapping 3D coordinates to the corresponding signed distance values or occupancy values. In this paper, we propose a novel positional encoding scheme, called Spline Positional Encoding, to map the input coordinates to a high dimensional space before passing them to MLPs, for helping to recover 3D signed distance fields with fine-scale geometric details from unorganized 3D point clouds. We verified the superiority of our approach over other positional encoding schemes on tasks of 3D shape reconstruction from input point clouds and shape space learning. The efficacy of our approach extended to image reconstruction is also demonstrated and evaluated.
Multi-Instance Multi-Scale CNN for Medical Image Classification
Jul 31, 2019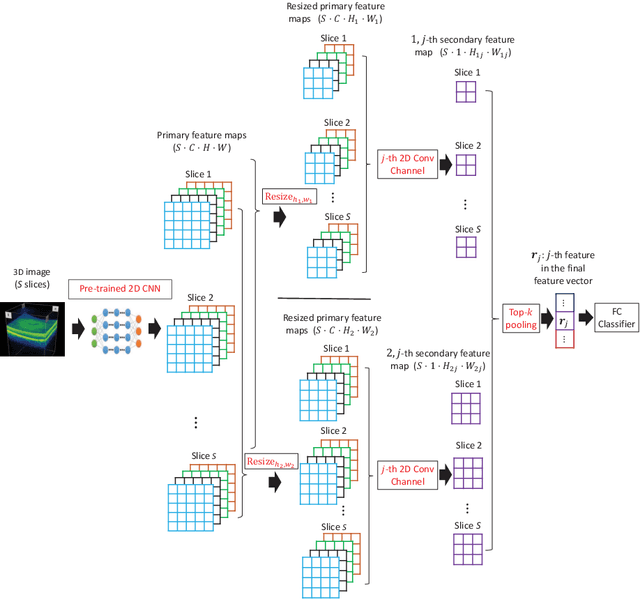
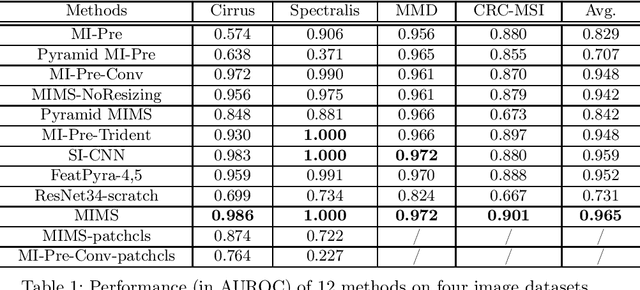
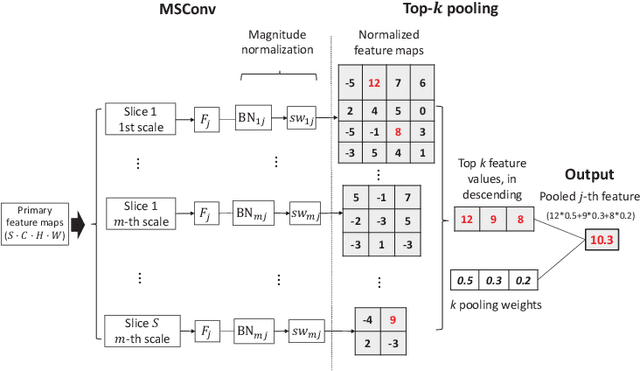

Deep learning for medical image classification faces three major challenges: 1) the number of annotated medical images for training are usually small; 2) regions of interest (ROIs) are relatively small with unclear boundaries in the whole medical images, and may appear in arbitrary positions across the x,y (and also z in 3D images) dimensions. However often only labels of the whole images are annotated, and localized ROIs are unavailable; and 3) ROIs in medical images often appear in varying sizes (scales). We approach these three challenges with a Multi-Instance Multi-Scale (MIMS) CNN: 1) We propose a multi-scale convolutional layer, which extracts patterns of different receptive fields with a shared set of convolutional kernels, so that scale-invariant patterns are captured by this compact set of kernels. As this layer contains only a small number of parameters, training on small datasets becomes feasible; 2) We propose a "top-k pooling" to aggregate the feature maps in varying scales from multiple spatial dimensions, allowing the model to be trained using weak annotations within the multiple instance learning (MIL) framework. Our method is shown to perform well on three classification tasks involving two 3D and two 2D medical image datasets.
Cross-modality Discrepant Interaction Network for RGB-D Salient Object Detection
Aug 04, 2021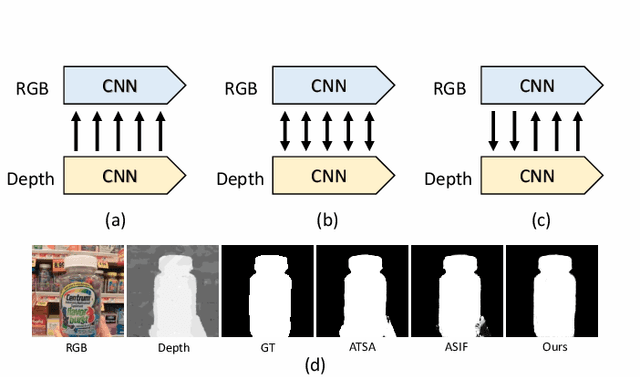
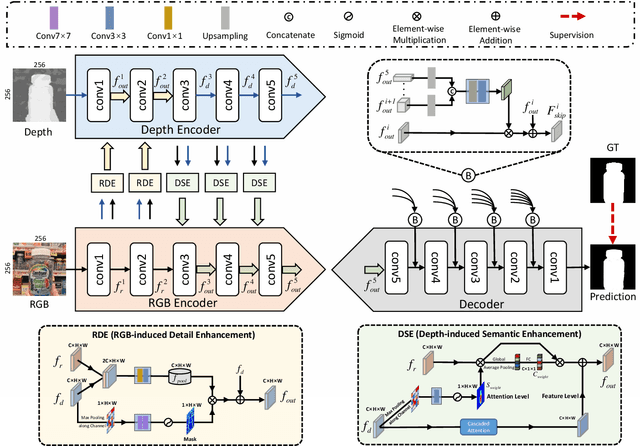
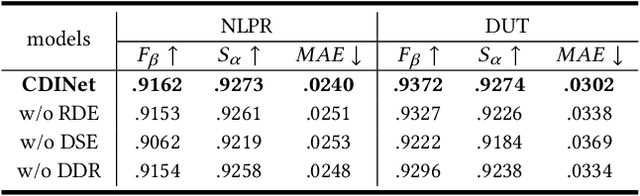
The popularity and promotion of depth maps have brought new vigor and vitality into salient object detection (SOD), and a mass of RGB-D SOD algorithms have been proposed, mainly concentrating on how to better integrate cross-modality features from RGB image and depth map. For the cross-modality interaction in feature encoder, existing methods either indiscriminately treat RGB and depth modalities, or only habitually utilize depth cues as auxiliary information of the RGB branch. Different from them, we reconsider the status of two modalities and propose a novel Cross-modality Discrepant Interaction Network (CDINet) for RGB-D SOD, which differentially models the dependence of two modalities according to the feature representations of different layers. To this end, two components are designed to implement the effective cross-modality interaction: 1) the RGB-induced Detail Enhancement (RDE) module leverages RGB modality to enhance the details of the depth features in low-level encoder stage. 2) the Depth-induced Semantic Enhancement (DSE) module transfers the object positioning and internal consistency of depth features to the RGB branch in high-level encoder stage. Furthermore, we also design a Dense Decoding Reconstruction (DDR) structure, which constructs a semantic block by combining multi-level encoder features to upgrade the skip connection in the feature decoding. Extensive experiments on five benchmark datasets demonstrate that our network outperforms $15$ state-of-the-art methods both quantitatively and qualitatively. Our code is publicly available at: https://rmcong.github.io/proj_CDINet.html.
GPLA-12: An Acoustic Signal Dataset of Gas Pipeline Leakage
Jun 19, 2021

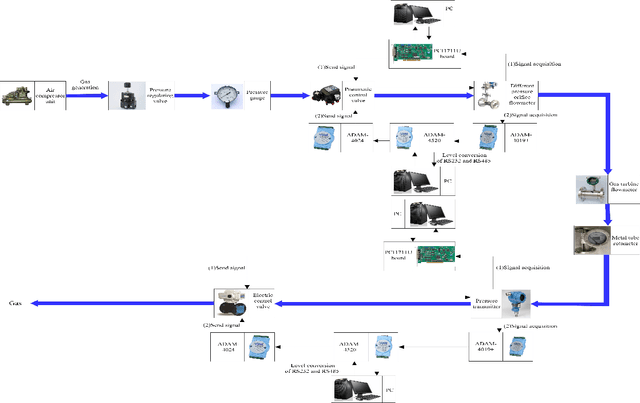

In this paper, we introduce a new acoustic leakage dataset of gas pipelines, called as GPLA-12, which has 12 categories over 684 training/testing acoustic signals. Unlike massive image and voice datasets, there have relatively few acoustic signal datasets, especially for engineering fault detection. In order to enhance the development of fault diagnosis, we collect acoustic leakage signals on the basis of an intact gas pipe system with external artificial leakages, and then preprocess the collected data with structured tailoring which are turned into GPLA-12. GPLA-12 dedicates to serve as a feature learning dataset for time-series tasks and classifications. To further understand the dataset, we train both shadow and deep learning algorithms to observe the performance. The dataset as well as the pretrained models have been released at both www.daip.club and github.com/Deep-AI-Application-DAIP
Deep Aggregation of Regional Convolutional Activations for Content Based Image Retrieval
Sep 24, 2019



One of the key challenges of deep learning based image retrieval remains in aggregating convolutional activations into one highly representative feature vector. Ideally, this descriptor should encode semantic, spatial and low level information. Even though off-the-shelf pre-trained neural networks can already produce good representations in combination with aggregation methods, appropriate fine tuning for the task of image retrieval has shown to significantly boost retrieval performance. In this paper, we present a simple yet effective supervised aggregation method built on top of existing regional pooling approaches. In addition to the maximum activation of a given region, we calculate regional average activations of extracted feature maps. Subsequently, weights for each of the pooled feature vectors are learned to perform a weighted aggregation to a single feature vector. Furthermore, we apply our newly proposed NRA loss function for deep metric learning to fine tune the backbone neural network and to learn the aggregation weights. Our method achieves state-of-the-art results for the INRIA Holidays data set and competitive results for the Oxford Buildings and Paris data sets while reducing the training time significantly.
SparseMask: Differentiable Connectivity Learning for Dense Image Prediction
Apr 16, 2019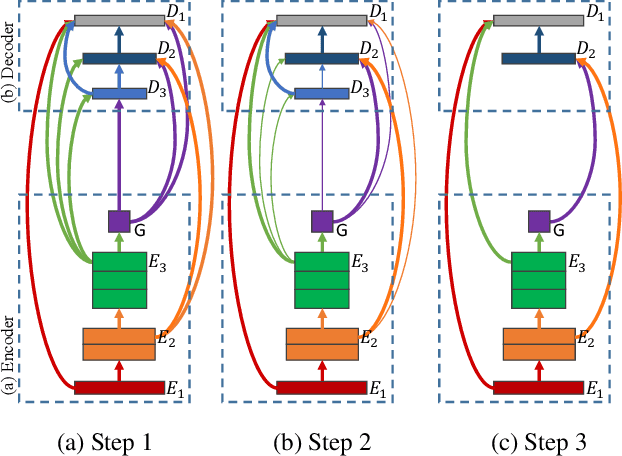
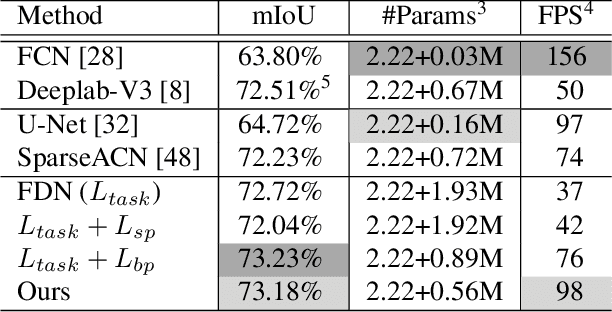
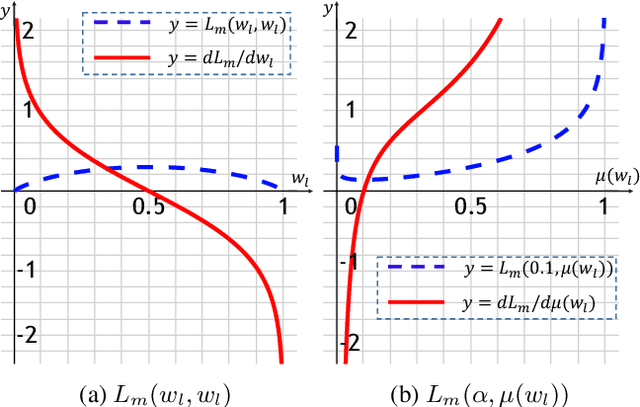
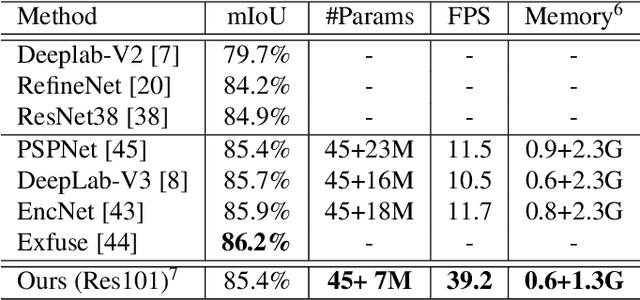
In this paper, we aim at automatically searching an efficient network architecture for dense image prediction. Particularly, we follow the encoder-decoder style and focus on automatically designing a connectivity structure for the decoder. To achieve that, we first design a densely connected network with learnable connections named Fully Dense Network, which contains a large set of possible final connectivity structures. We then employ gradient descent to search the optimal connectivity from the dense connections. The search process is guided by a novel loss function, which pushes the weight of each connection to be binary and the connections to be sparse. The discovered connectivity achieves competitive results on two segmentation datasets, while runs more than three times faster and requires less than half parameters compared to state-of-the-art methods. An extensive experiment shows that the discovered connectivity is compatible with various backbones and generalizes well to other dense image prediction tasks.
Extraction of physically meaningful endmembers from STEM spectrum-images combining geometrical and statistical approaches
May 21, 2021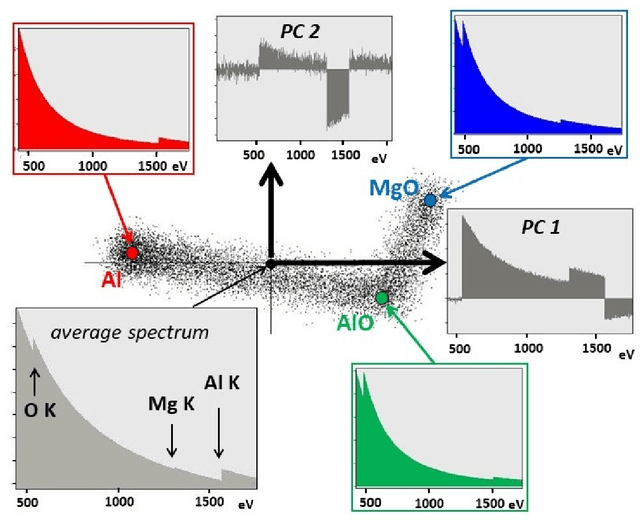
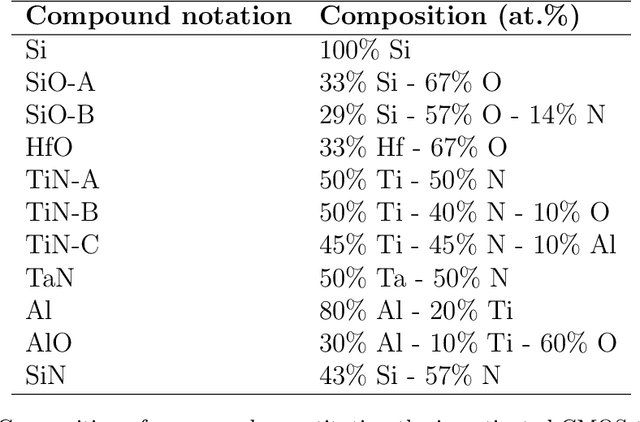
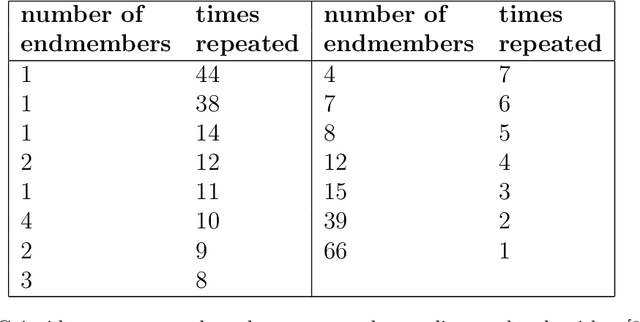

This article addresses extraction of physically meaningful information from STEM EELS and EDX spectrum-images using methods of Multivariate Statistical Analysis. The problem is interpreted in terms of data distribution in a multi-dimensional factor space, which allows for a straightforward and intuitively clear comparison of various approaches. A new computationally efficient and robust method for finding physically meaningful endmembers in spectrum-image datasets is presented. The method combines the geometrical approach of Vertex Component Analysis with the statistical approach of Bayesian inference. The algorithm is described in detail at an example of EELS spectrum-imaging of a multi-compound CMOS transistor.
SynthRef: Generation of Synthetic Referring Expressions for Object Segmentation
Jun 08, 2021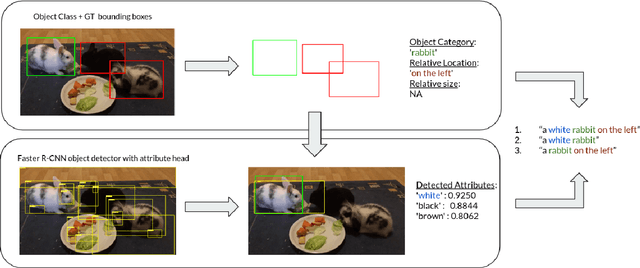



Recent advances in deep learning have brought significant progress in visual grounding tasks such as language-guided video object segmentation. However, collecting large datasets for these tasks is expensive in terms of annotation time, which represents a bottleneck. To this end, we propose a novel method, namely SynthRef, for generating synthetic referring expressions for target objects in an image (or video frame), and we also present and disseminate the first large-scale dataset with synthetic referring expressions for video object segmentation. Our experiments demonstrate that by training with our synthetic referring expressions one can improve the ability of a model to generalize across different datasets, without any additional annotation cost. Moreover, our formulation allows its application to any object detection or segmentation dataset.
Generic Neural Architecture Search via Regression
Aug 04, 2021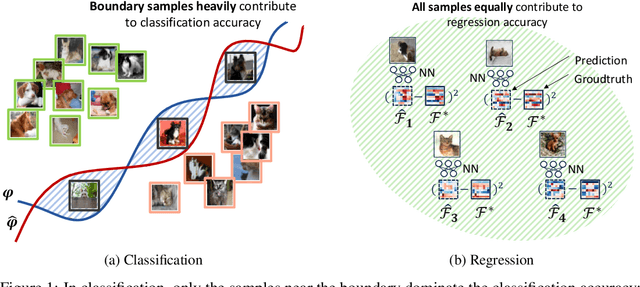
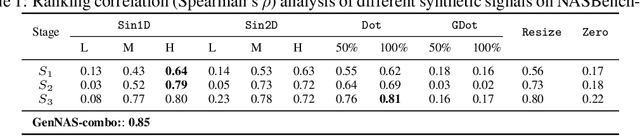
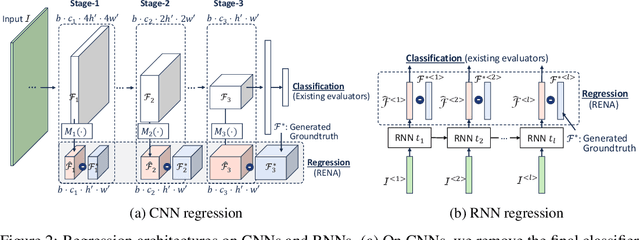
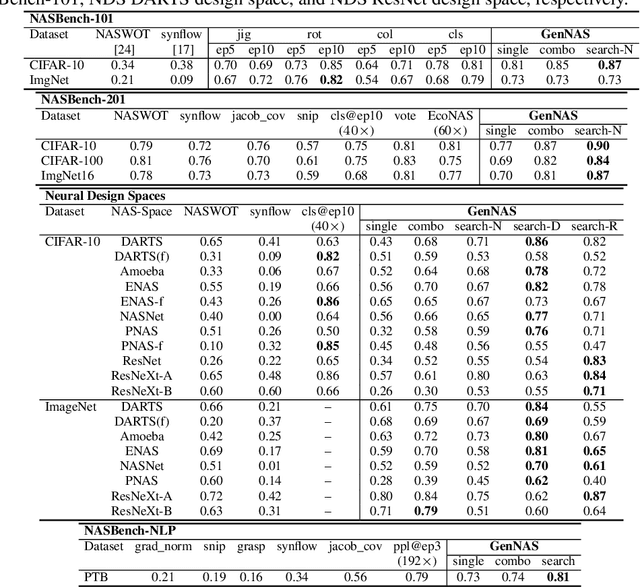
Most existing neural architecture search (NAS) algorithms are dedicated to the downstream tasks, e.g., image classification in computer vision. However, extensive experiments have shown that, prominent neural architectures, such as ResNet in computer vision and LSTM in natural language processing, are generally good at extracting patterns from the input data and perform well on different downstream tasks. These observations inspire us to ask: Is it necessary to use the performance of specific downstream tasks to evaluate and search for good neural architectures? Can we perform NAS effectively and efficiently while being agnostic to the downstream task? In this work, we attempt to affirmatively answer the above two questions and improve the state-of-the-art NAS solution by proposing a novel and generic NAS framework, termed Generic NAS (GenNAS). GenNAS does not use task-specific labels but instead adopts \textit{regression} on a set of manually designed synthetic signal bases for architecture evaluation. Such a self-supervised regression task can effectively evaluate the intrinsic power of an architecture to capture and transform the input signal patterns, and allow more sufficient usage of training samples. We then propose an automatic task search to optimize the combination of synthetic signals using limited downstream-task-specific labels, further improving the performance of GenNAS. We also thoroughly evaluate GenNAS's generality and end-to-end NAS performance on all search spaces, which outperforms almost all existing works with significant speedup.
Multi-Plane Program Induction with 3D Box Priors
Nov 22, 2020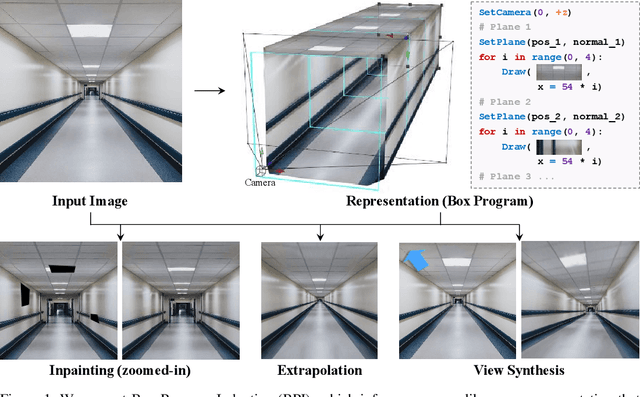


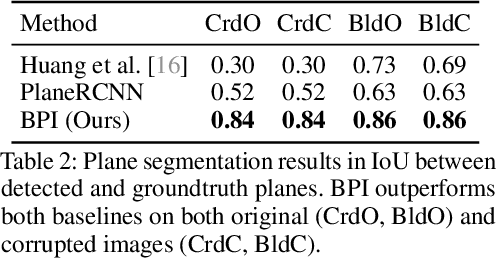
We consider two important aspects in understanding and editing images: modeling regular, program-like texture or patterns in 2D planes, and 3D posing of these planes in the scene. Unlike prior work on image-based program synthesis, which assumes the image contains a single visible 2D plane, we present Box Program Induction (BPI), which infers a program-like scene representation that simultaneously models repeated structure on multiple 2D planes, the 3D position and orientation of the planes, and camera parameters, all from a single image. Our model assumes a box prior, i.e., that the image captures either an inner view or an outer view of a box in 3D. It uses neural networks to infer visual cues such as vanishing points, wireframe lines to guide a search-based algorithm to find the program that best explains the image. Such a holistic, structured scene representation enables 3D-aware interactive image editing operations such as inpainting missing pixels, changing camera parameters, and extrapolate the image contents.