 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Survey of Modern Deep Learning based Object Detection Models
May 12, 2021
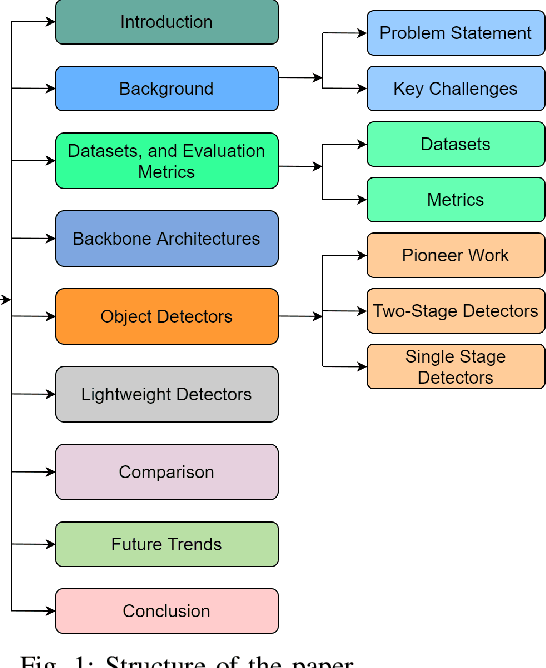


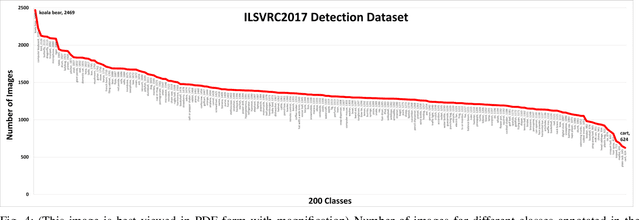
Object Detection is the task of classification and localization of objects in an image or video. It has gained prominence in recent years due to its widespread applications. This article surveys recent developments in deep learning based object detectors. Concise overview of benchmark datasets and evaluation metrics used in detection is also provided along with some of the prominent backbone architectures used in recognition tasks. It also covers contemporary lightweight classification models used on edge devices. Lastly, we compare the performances of these architectures on multiple metrics.
Learning Representational Invariances for Data-Efficient Action Recognition
Mar 30, 2021

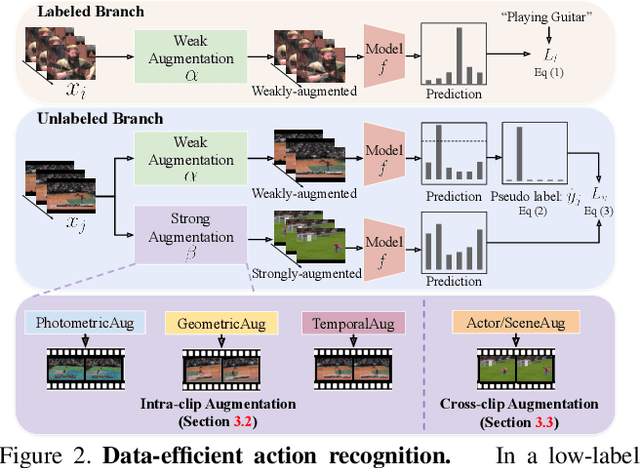
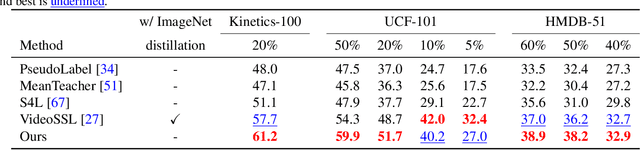
Data augmentation is a ubiquitous technique for improving image classification when labeled data is scarce. Constraining the model predictions to be invariant to diverse data augmentations effectively injects the desired representational invariances to the model (e.g., invariance to photometric variations), leading to improved accuracy. Compared to image data, the appearance variations in videos are far more complex due to the additional temporal dimension. Yet, data augmentation methods for videos remain under-explored. In this paper, we investigate various data augmentation strategies that capture different video invariances, including photometric, geometric, temporal, and actor/scene augmentations. When integrated with existing consistency-based semi-supervised learning frameworks, we show that our data augmentation strategy leads to promising performance on the Kinetics-100, UCF-101, and HMDB-51 datasets in the low-label regime. We also validate our data augmentation strategy in the fully supervised setting and demonstrate improved performance.
ID-Unet: Iterative Soft and Hard Deformation for View Synthesis
Mar 18, 2021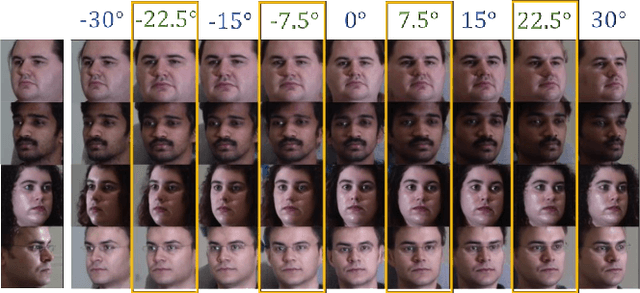
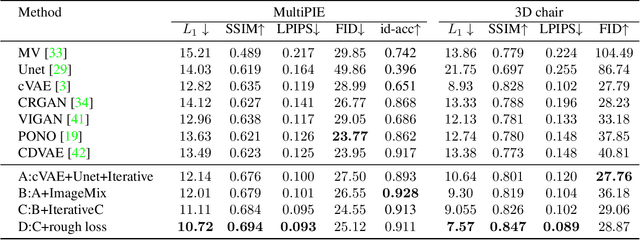
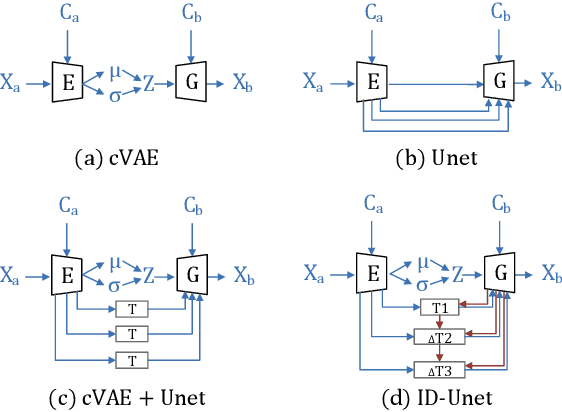
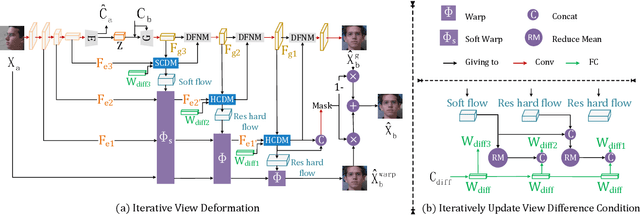
View synthesis is usually done by an autoencoder, in which the encoder maps a source view image into a latent content code, and the decoder transforms it into a target view image according to the condition. However, the source contents are often not well kept in this setting, which leads to unnecessary changes during the view translation. Although adding skipped connections, like Unet, alleviates the problem, but it often causes the failure on the view conformity. This paper proposes a new architecture by performing the source-to-target deformation in an iterative way. Instead of simply incorporating the features from multiple layers of the encoder, we design soft and hard deformation modules, which warp the encoder features to the target view at different resolutions, and give results to the decoder to complement the details. Particularly, the current warping flow is not only used to align the feature of the same resolution, but also as an approximation to coarsely deform the high resolution feature. Then the residual flow is estimated and applied in the high resolution, so that the deformation is built up in the coarse-to-fine fashion. To better constrain the model, we synthesize a rough target view image based on the intermediate flows and their warped features. The extensive ablation studies and the final results on two different data sets show the effectiveness of the proposed model.
Night-to-Day Image Translation for Retrieval-based Localization
Sep 26, 2018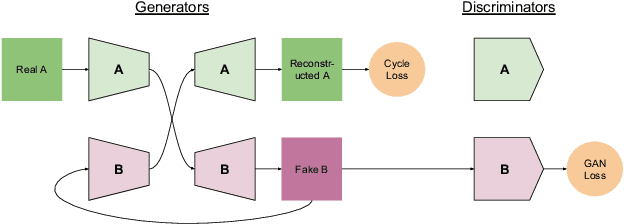


Visual localization is a key step in many robotics pipelines, allowing the robot to approximately determine its position and orientation in the world. An efficient and scalable approach to visual localization is to use image retrieval techniques. These approaches identify the image most similar to a query photo in a database of geo-tagged images and approximate the query's pose via the pose of the retrieved database image. However, image retrieval across drastically different illumination conditions, e.g. day and night, is still a problem with unsatisfactory results, even in this age of powerful neural models. This is due to a lack of a suitably diverse dataset with true correspondences to perform end-to-end learning. A recent class of neural models allows for realistic translation of images among visual domains with relatively little training data and, most importantly, without ground-truth pairings. In this paper, we explore the task of accurately localizing images captured from two traversals of the same area in both day and night. We propose ToDayGAN - a modified image-translation model to alter nighttime driving images to a more-useful daytime representation. We then compare the daytime and translated-night images to obtain a pose estimate for the night image using the known 6-DOF position of the closest day image. Our approach improves localization performance by over 250% compared the current state-of-the-art, in the context of standard metrics in multiple categories.
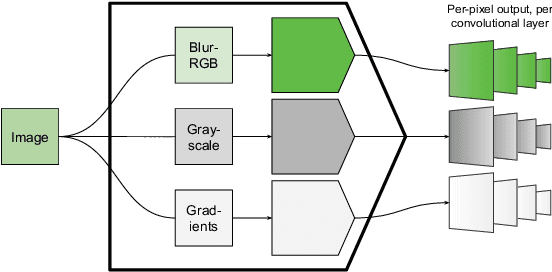
Advantages and Bottlenecks of Quantum Machine Learning for Remote Sensing
Jan 26, 2021
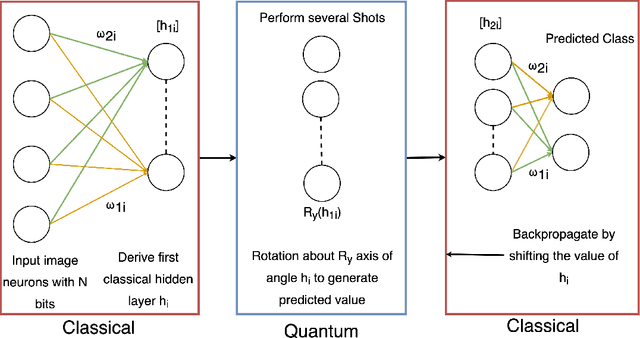

This concept paper aims to provide a brief outline of quantum computers, explore existing methods of quantum image classification techniques, so focusing on remote sensing applications, and discuss the bottlenecks of performing these algorithms on currently available open source platforms. Initial results demonstrate feasibility. Next steps include expanding the size of the quantum hidden layer and increasing the variety of output image options.
Generative Modeling for Multi-task Visual Learning
Jun 25, 2021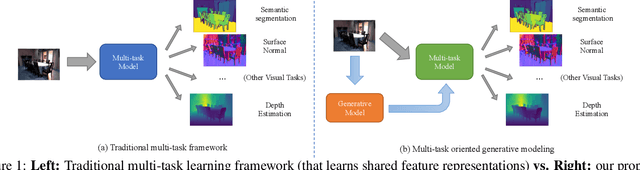
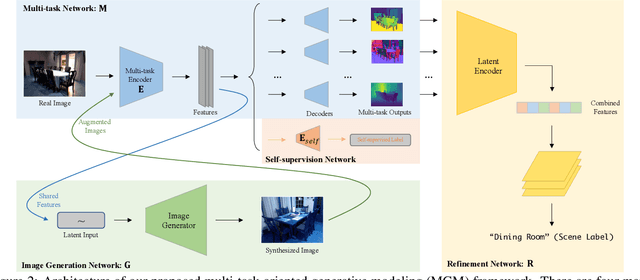
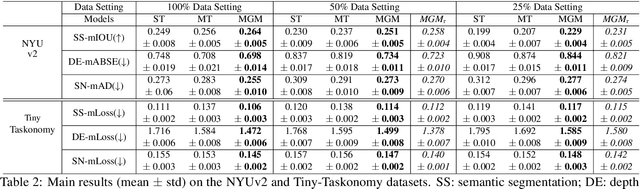
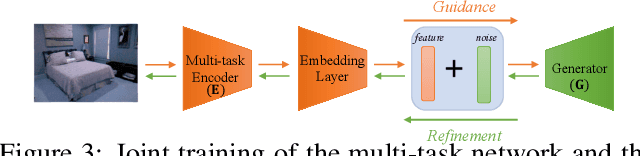
Generative modeling has recently shown great promise in computer vision, but it has mostly focused on synthesizing visually realistic images. In this paper, motivated by multi-task learning of shareable feature representations, we consider a novel problem of learning a shared generative model that is useful across various visual perception tasks. Correspondingly, we propose a general multi-task oriented generative modeling (MGM) framework, by coupling a discriminative multi-task network with a generative network. While it is challenging to synthesize both RGB images and pixel-level annotations in multi-task scenarios, our framework enables us to use synthesized images paired with only weak annotations (i.e., image-level scene labels) to facilitate multiple visual tasks. Experimental evaluation on challenging multi-task benchmarks, including NYUv2 and Taskonomy, demonstrates that our MGM framework improves the performance of all the tasks by large margins, consistently outperforming state-of-the-art multi-task approaches.
TransCT: Dual-path Transformer for Low Dose Computed Tomography
Mar 03, 2021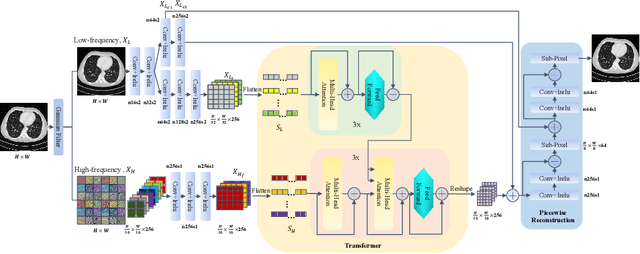

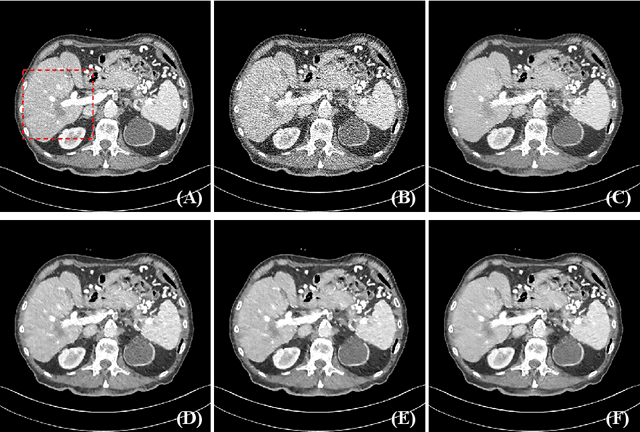
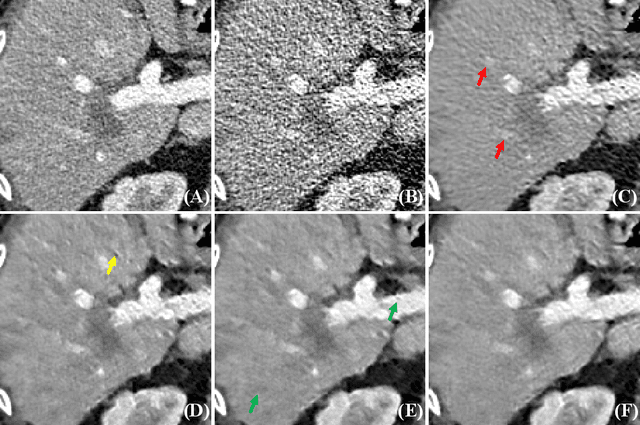
Low dose computed tomography (LDCT) has attracted more and more attention in routine clinical diagnosis assessment, therapy planning, etc., which can reduce the dose of X-ray radiation to patients. However, the noise caused by low X-ray exposure degrades the CT image quality and then affects clinical diagnosis accuracy. In this paper, we train a transformer-based neural network to enhance the final CT image quality. To be specific, we first decompose the noisy LDCT image into two parts: high-frequency (HF) and low-frequency (LF) compositions. Then, we extract content features (X_{L_c}) and latent texture features (X_{L_t}) from the LF part, as well as HF embeddings (X_{H_f}) from the HF part. Further, we feed X_{L_t} and X_{H_f} into a modified transformer with three encoders and decoders to obtain well-refined HF texture features. After that, we combine these well-refined HF texture features with the pre-extracted X_{L_c} to encourage the restoration of high-quality LDCT images with the assistance of piecewise reconstruction. Extensive experiments on Mayo LDCT dataset show that our method produces superior results and outperforms other methods.
Transfer learning approach to Classify the X-ray image that corresponds to corona disease Using ResNet50 pretrained by ChexNet
May 18, 2021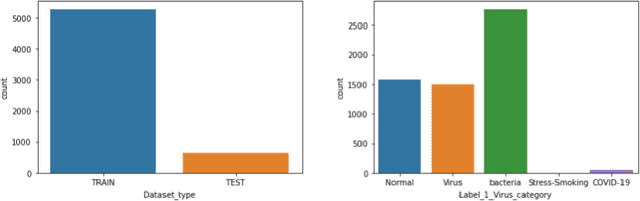

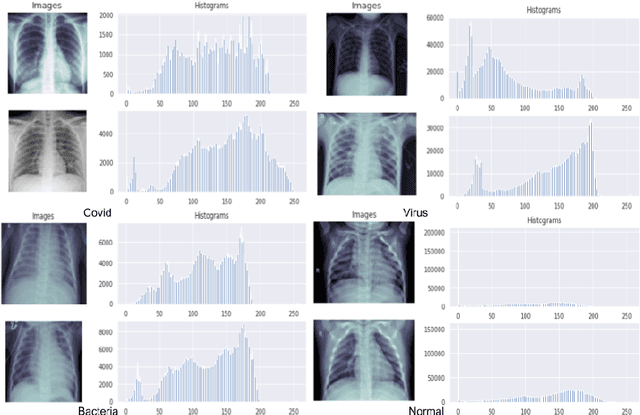
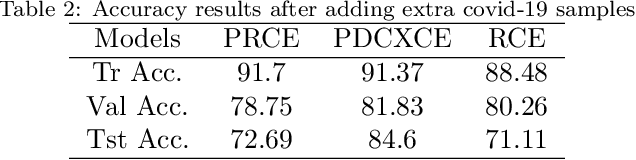
Coronavirus adversely has affected people worldwide. There are common symptoms between the Covid19 virus disease and other respiratory diseases like pneumonia or Influenza. Therefore, diagnosing it fast is crucial not only to save patients but also to prevent it from spreading. One of the most reliant methods of diagnosis is through X-ray images of a lung. With the help of deep learning approaches, we can teach the deep model to learn the condition of an affected lung. Therefore, it can classify the new sample as if it is a Covid19 infected patient or not. In this project, we train a deep model based on ResNet50 pretrained by ImageNet dataset and CheXNet dataset. Based on the imbalanced CoronaHack Chest X-Ray dataset introducing by Kaggle we applied both binary and multi-class classification. Also, we compare the results when using Focal loss and Cross entropy loss.
Effectiveness of random deep feature selection for securing image manipulation detectors against adversarial examples
Oct 25, 2019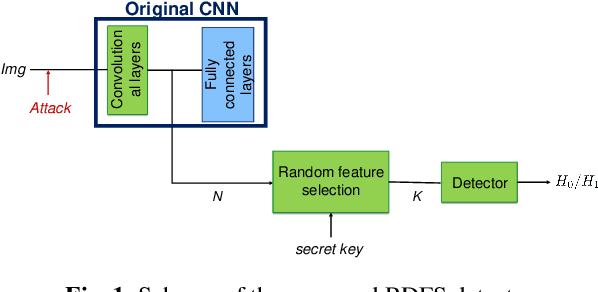
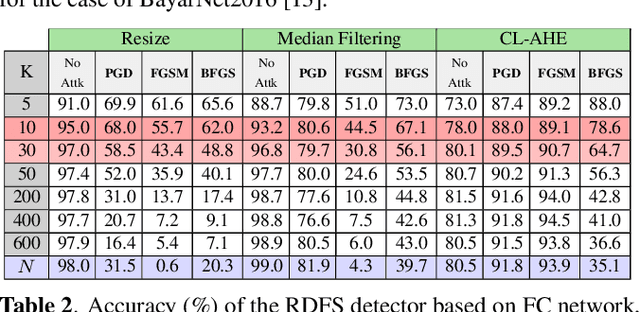
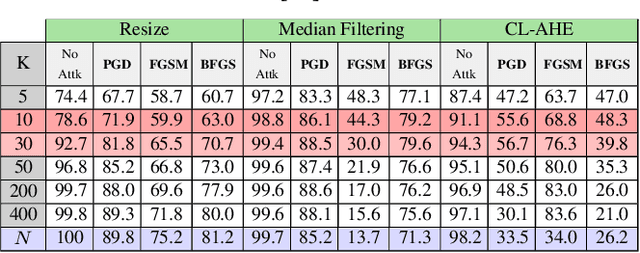
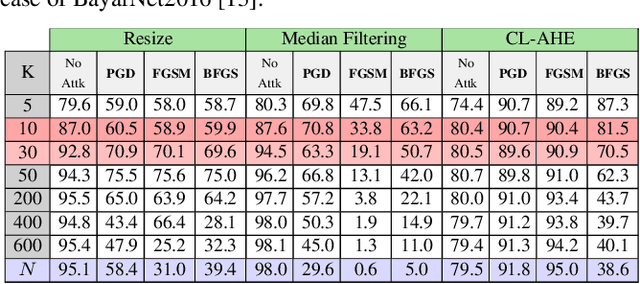
We investigate if the random feature selection approach proposed in [1] to improve the robustness of forensic detectors to targeted attacks, can be extended to detectors based on deep learning features. In particular, we study the transferability of adversarial examples targeting an original CNN image manipulation detector to other detectors (a fully connected neural network and a linear SVM) that rely on a random subset of the features extracted from the flatten layer of the original network. The results we got by considering three image manipulation detection tasks (resizing, median filtering and adaptive histogram equalization), two original network architectures and three classes of attacks, show that feature randomization helps to hinder attack transferability, even if, in some cases, simply changing the architecture of the detector, or even retraining the detector is enough to prevent the transferability of the attacks.
GANs for Medical Image Analysis
Sep 13, 2018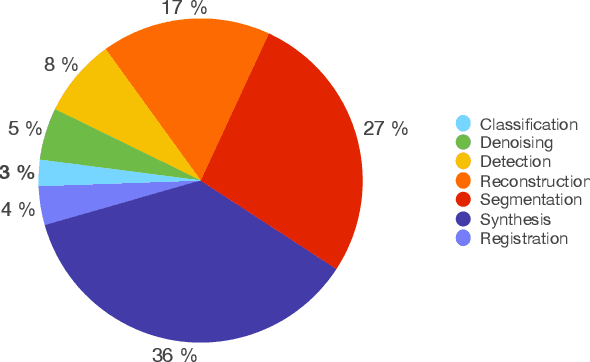

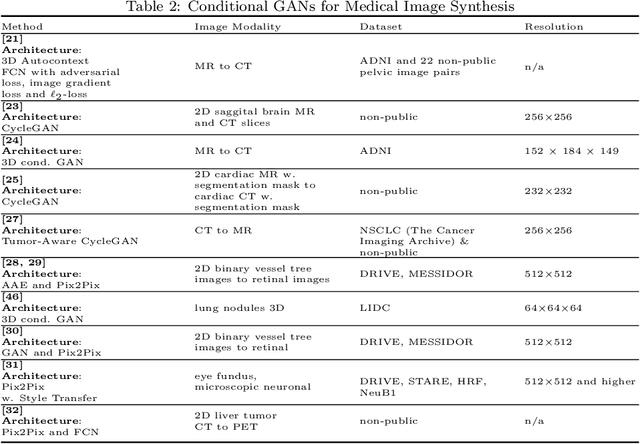
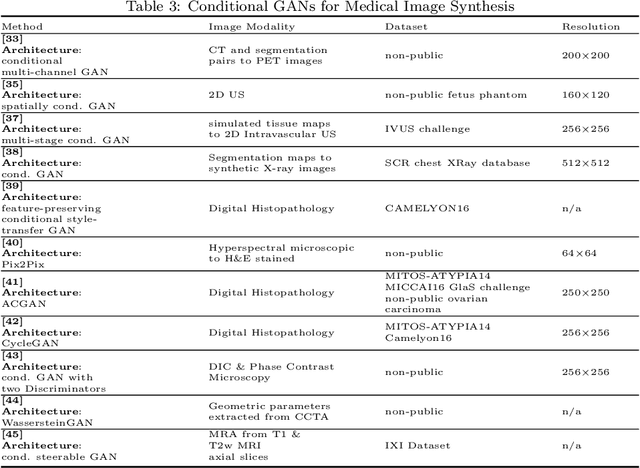
Generative Adversarial Networks (GANs) and their extensions have carved open many exciting ways to tackle well known and challenging medical image analysis problems such as medical image denoising, reconstruction, segmentation, data simulation, detection or classification. Furthermore, their ability to synthesize images at unprecedented levels of realism also gives hope that the chronic scarcity of labeled data in the medical field can be resolved with the help of these generative models. In this review paper, a broad overview of recent literature on GANs for medical applications is given, the shortcomings and opportunities of the proposed methods are thoroughly discussed and potential future work is elaborated. A total of 63 papers published until end of July 2018 are reviewed. For quick access, the papers and important details such as the underlying method, datasets and performance are summarized in tables.