 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Edge Detection for Satellite Images without Deep Networks
May 26, 2021
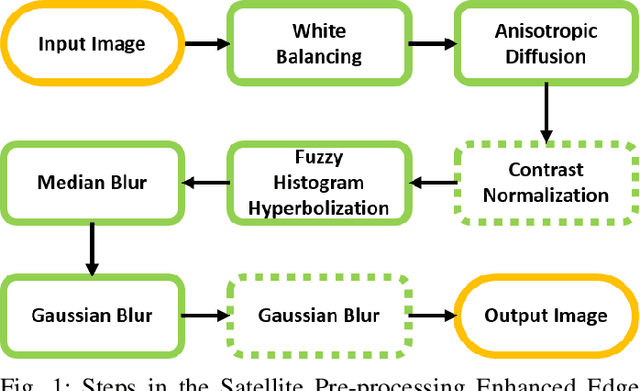
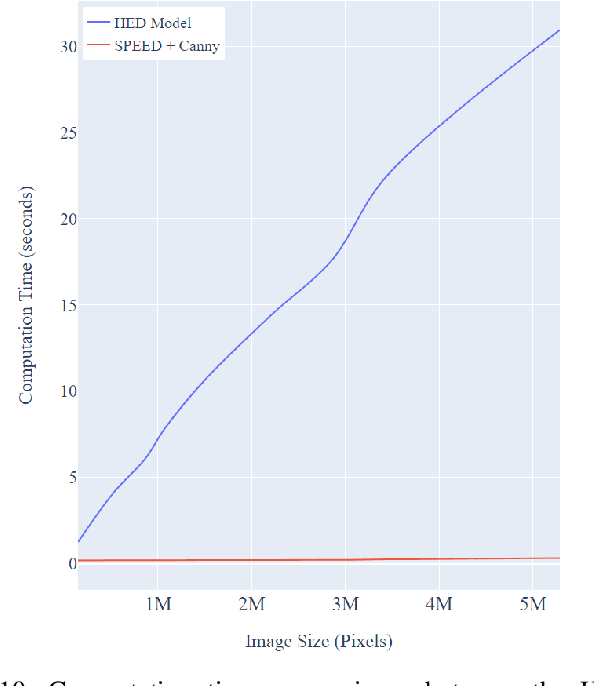
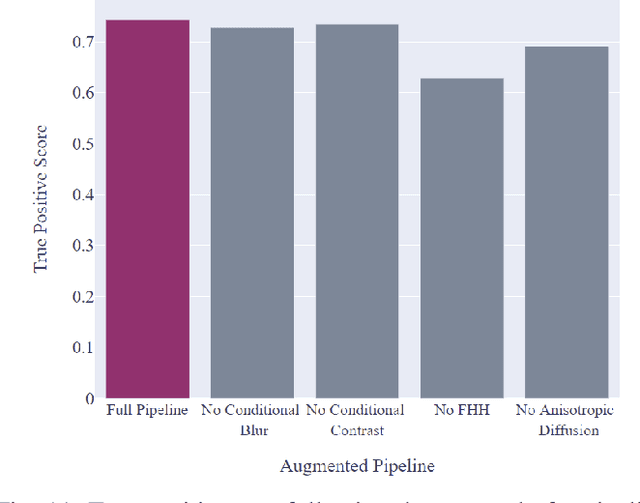
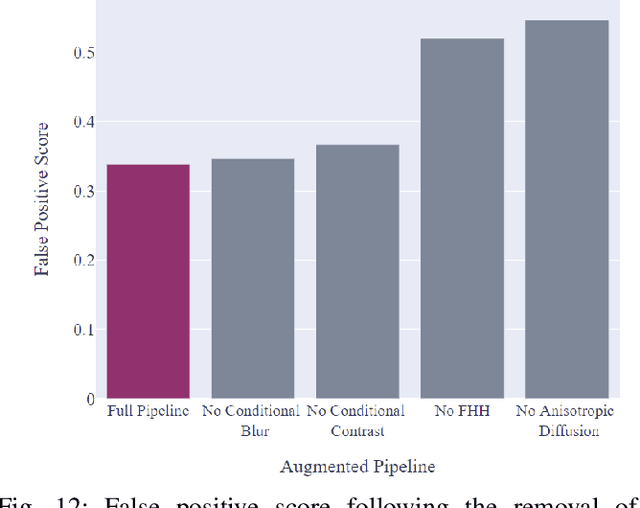
Satellite imagery is widely used in many application sectors, including agriculture, navigation, and urban planning. Frequently, satellite imagery involves both large numbers of images as well as high pixel counts, making satellite datasets computationally expensive to analyze. Recent approaches to satellite image analysis have largely emphasized deep learning methods. Though extremely powerful, deep learning has some drawbacks, including the requirement of specialized computing hardware and a high reliance on training data. When dealing with large satellite datasets, the cost of both computational resources and training data annotation may be prohibitive.
Image similarity using Deep CNN and Curriculum Learning
Jul 13, 2018
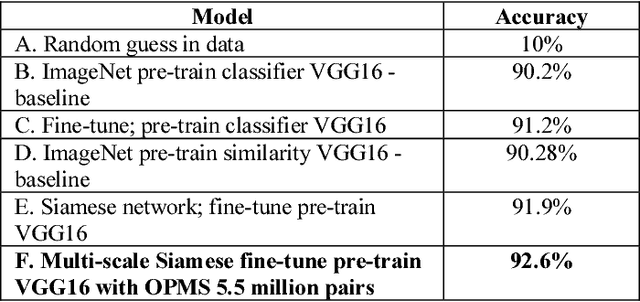
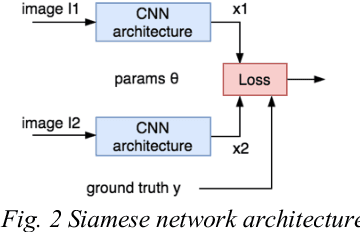
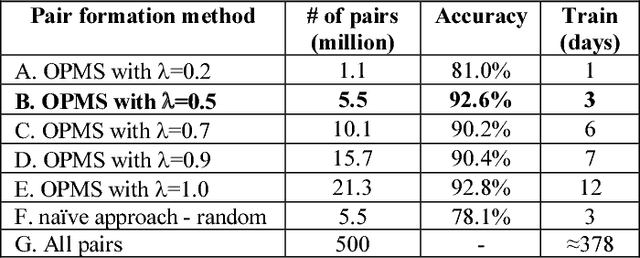
Image similarity involves fetching similar looking images given a reference image. Our solution called SimNet, is a deep siamese network which is trained on pairs of positive and negative images using a novel online pair mining strategy inspired by Curriculum learning. We also created a multi-scale CNN, where the final image embedding is a joint representation of top as well as lower layer embedding's. We go on to show that this multi-scale siamese network is better at capturing fine grained image similarities than traditional CNN's.
Learning from Images: Proactive Caching with Parallel Convolutional Neural Networks
Aug 15, 2021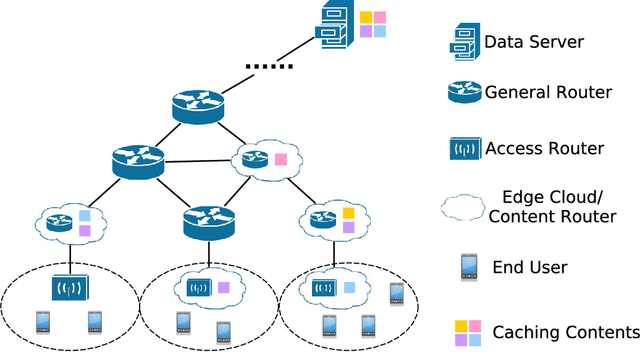
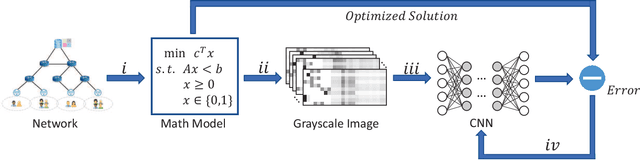
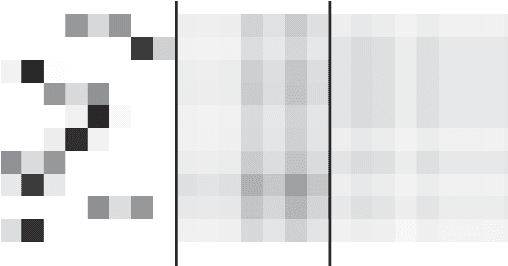
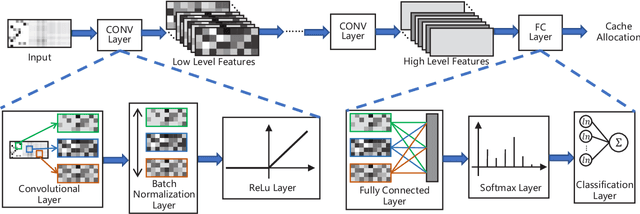
With the continuous trend of data explosion, delivering packets from data servers to end users causes increased stress on both the fronthaul and backhaul traffic of mobile networks. To mitigate this problem, caching popular content closer to the end-users has emerged as an effective method for reducing network congestion and improving user experience. To find the optimal locations for content caching, many conventional approaches construct various mixed integer linear programming (MILP) models. However, such methods may fail to support online decision making due to the inherent curse of dimensionality. In this paper, a novel framework for proactive caching is proposed. This framework merges model-based optimization with data-driven techniques by transforming an optimization problem into a grayscale image. For parallel training and simple design purposes, the proposed MILP model is first decomposed into a number of sub-problems and, then, convolutional neural networks (CNNs) are trained to predict content caching locations of these sub-problems. Furthermore, since the MILP model decomposition neglects the internal effects among sub-problems, the CNNs' outputs have the risk to be infeasible solutions. Therefore, two algorithms are provided: the first uses predictions from CNNs as an extra constraint to reduce the number of decision variables; the second employs CNNs' outputs to accelerate local search. Numerical results show that the proposed scheme can reduce 71.6% computation time with only 0.8% additional performance cost compared to the MILP solution, which provides high quality decision making in real-time.
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Apr 15, 2021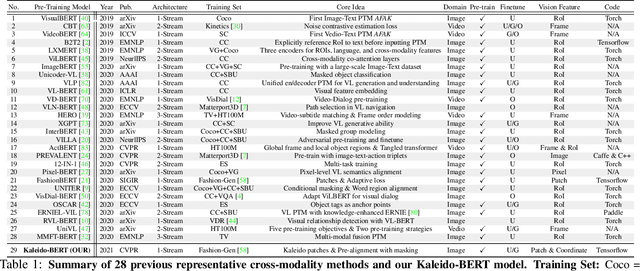
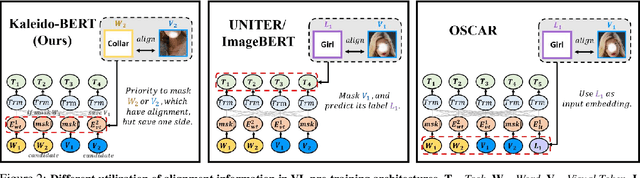
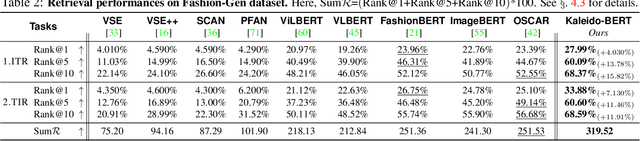
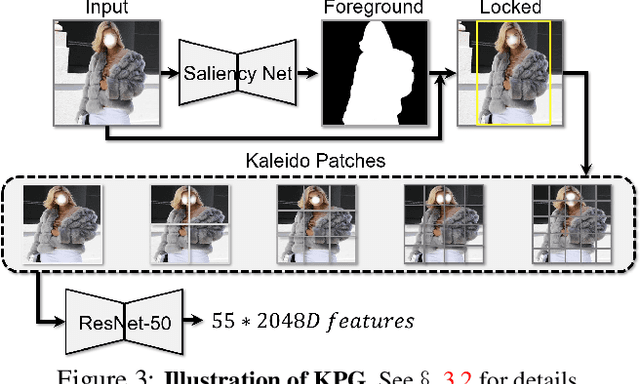
We present a new vision-language (VL) pre-training model dubbed Kaleido-BERT, which introduces a novel kaleido strategy for fashion cross-modality representations from transformers. In contrast to random masking strategy of recent VL models, we design alignment guided masking to jointly focus more on image-text semantic relations. To this end, we carry out five novel tasks, i.e., rotation, jigsaw, camouflage, grey-to-color, and blank-to-color for self-supervised VL pre-training at patches of different scale. Kaleido-BERT is conceptually simple and easy to extend to the existing BERT framework, it attains new state-of-the-art results by large margins on four downstream tasks, including text retrieval (R@1: 4.03% absolute improvement), image retrieval (R@1: 7.13% abs imv.), category recognition (ACC: 3.28% abs imv.), and fashion captioning (Bleu4: 1.2 abs imv.). We validate the efficiency of Kaleido-BERT on a wide range of e-commerical websites, demonstrating its broader potential in real-world applications.
Elastic Architecture Search for Diverse Tasks with Different Resources
Aug 03, 2021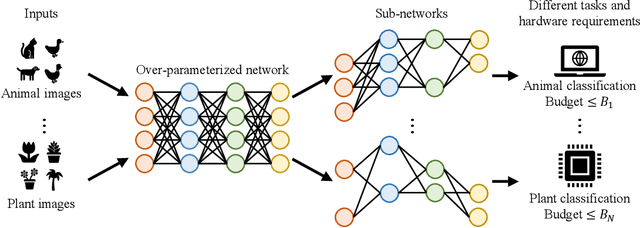
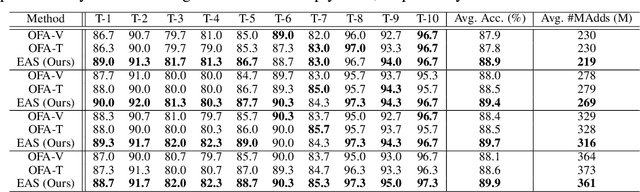
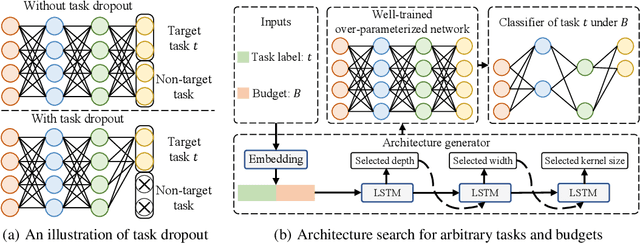
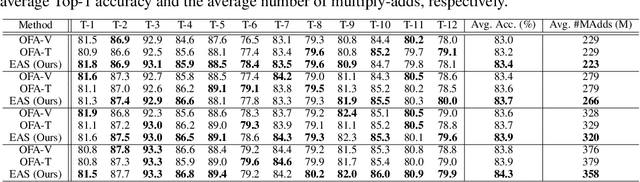
We study a new challenging problem of efficient deployment for diverse tasks with different resources, where the resource constraint and task of interest corresponding to a group of classes are dynamically specified at testing time. Previous NAS approaches seek to design architectures for all classes simultaneously, which may not be optimal for some individual tasks. A straightforward solution is to search an architecture from scratch for each deployment scenario, which however is computation-intensive and impractical. To address this, we present a novel and general framework, called Elastic Architecture Search (EAS), permitting instant specializations at runtime for diverse tasks with various resource constraints. To this end, we first propose to effectively train the over-parameterized network via a task dropout strategy to disentangle the tasks during training. In this way, the resulting model is robust to the subsequent task dropping at inference time. Based on the well-trained over-parameterized network, we then propose an efficient architecture generator to obtain optimal architectures within a single forward pass. Experiments on two image classification datasets show that EAS is able to find more compact networks with better performance while remarkably being orders of magnitude faster than state-of-the-art NAS methods. For example, our proposed EAS finds compact architectures within 0.1 second for 50 deployment scenarios.
An auditory cortex model for sound processing
Mar 08, 2021
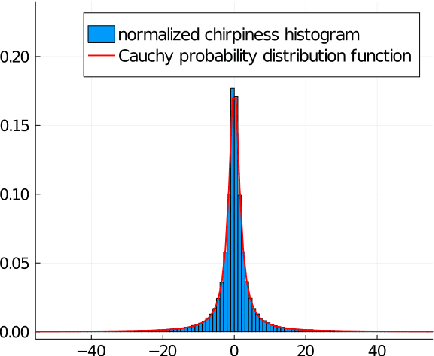
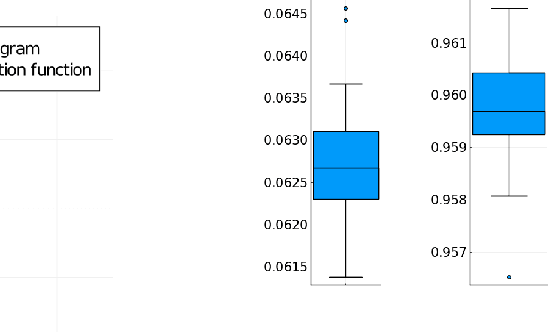
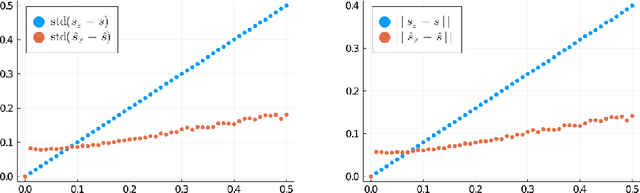
The reconstruction mechanisms built by the human auditory system during sound reconstruction are still a matter of debate. The purpose of this study is to refine the auditory cortex model introduced in [9], and inspired by the geometrical modelling of vision. The algorithm transforms the degraded sound in an 'image' in the time-frequency domain via a short-time Fourier transform. Such an image is then lifted in the Heisenberg group and it is reconstructed via a Wilson-Cowan differo-integral equation. Numerical experiments on a library of speech recordings are provided, showing the good reconstruction properties of the algorithm.
A Novel Solution of an Elastic Net Regularization for Dementia Knowledge Discovery using Deep Learning
Aug 21, 2021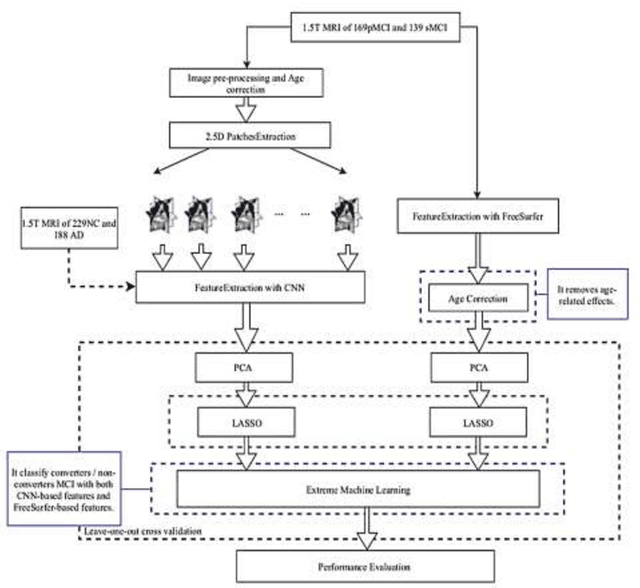
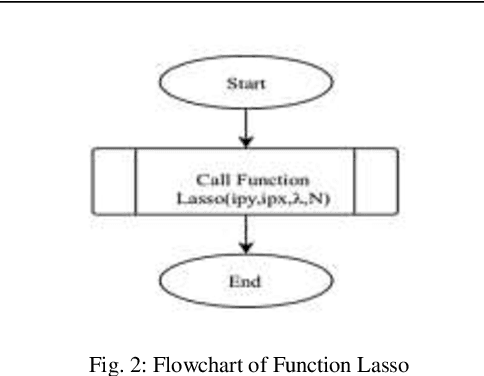

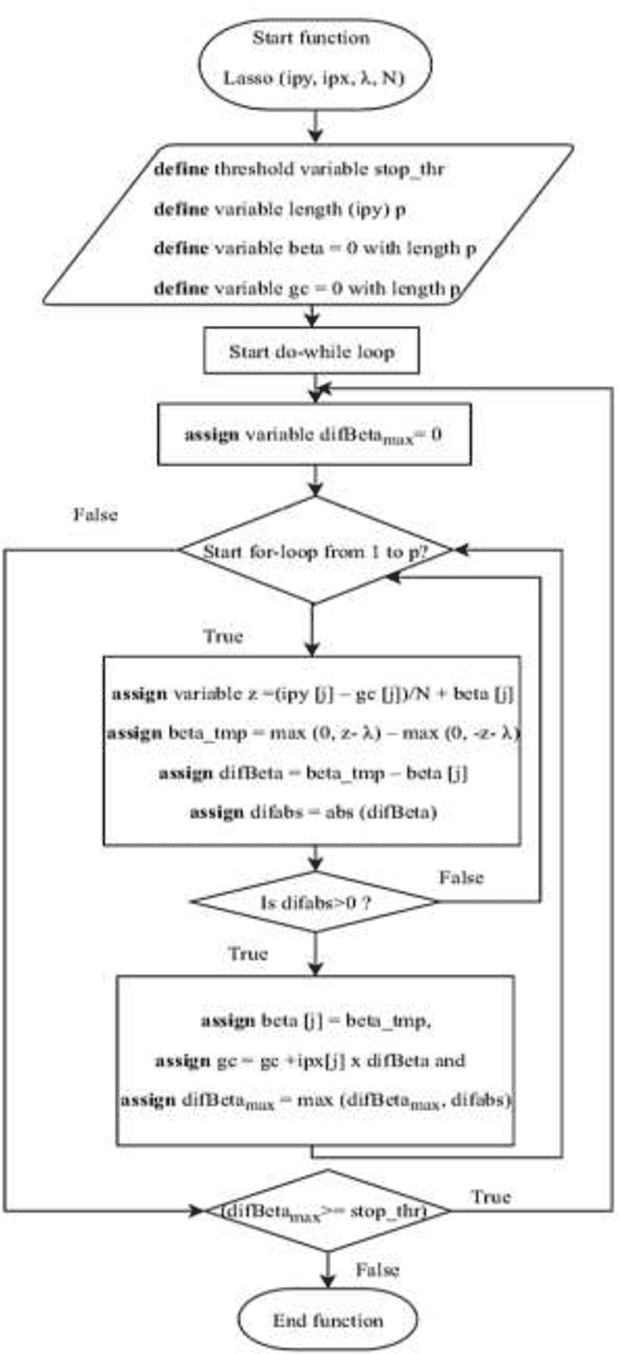
Background and Aim: Accurate classification of Magnetic Resonance Images (MRI) is essential to accurately predict Mild Cognitive Impairment (MCI) to Alzheimer's Disease (AD) conversion. Meanwhile, deep learning has been successfully implemented to classify and predict dementia disease. However, the accuracy of MRI image classification is low. This paper aims to increase the accuracy and reduce the processing time of classification through Deep Learning Architecture by using Elastic Net Regularization in Feature Selection. Methodology: The proposed system consists of Convolutional Neural Network (CNN) to enhance the accuracy of classification and prediction by using Elastic Net Regularization. Initially, the MRI images are fed into CNN for features extraction through convolutional layers alternate with pooling layers, and then through a fully connected layer. After that, the features extracted are subjected to Principle Component Analysis (PCA) and Elastic Net Regularization for feature selection. Finally, the selected features are used as an input to Extreme Machine Learning (EML) for the classification of MRI images. Results: The result shows that the accuracy of the proposed solution is better than the current system. In addition to that, the proposed method has improved the classification accuracy by 5% on average and reduced the processing time by 30 ~ 40 seconds on average. Conclusion: The proposed system is focused on improving the accuracy and processing time of MCI converters/non-converters classification. It consists of features extraction, feature selection, and classification using CNN, FreeSurfer, PCA, Elastic Net, Extreme Machine Learning. Finally, this study enhances the accuracy and the processing time by using Elastic Net Regularization, which provides important selected features for classification.
* 20 pages
Closing the Reality Gap with Unsupervised Sim-to-Real Image Translation for Semantic Segmentation in Robot Soccer
Nov 04, 2019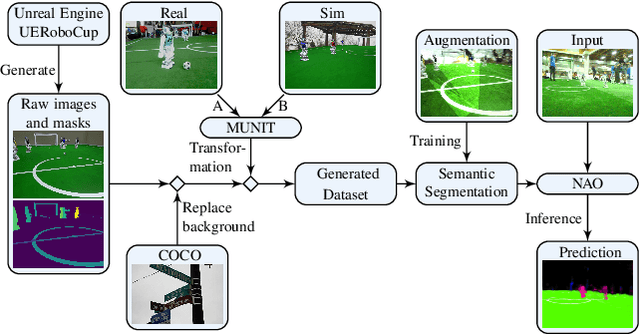

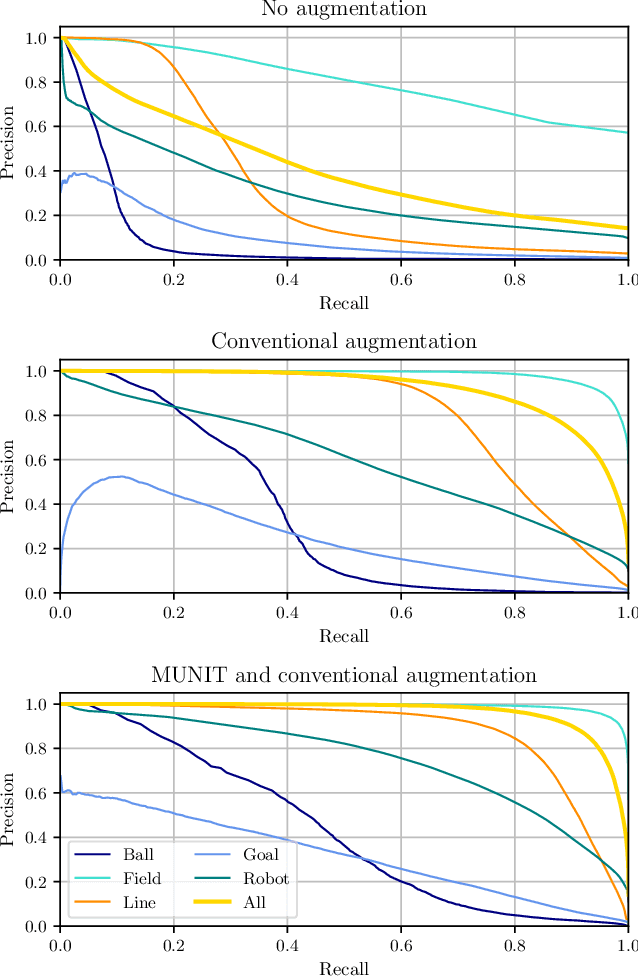

Deep learning approaches have become the standard solution to many problems in computer vision and robotics, but obtaining proper and sufficient training data is often a problem, as human labor is often error prone, time consuming and expensive. Solutions based on simulation have become more popular in recent years, but the gap between simulation and reality is still a major issue. In this paper, we introduce a novel model for augmenting synthetic image data through unsupervised image-to-image translation by applying the style of real world images to simulated images with open source frameworks. This model intends to generate the training data as a separate step and not as part of the training. The generated dataset is combined with conventional augmentation methods and is then applied to a neural network capable of running in real-time on autonomous soccer robots. Our evaluation shows a significant improvement compared to networks trained on simulated images without this kind of augmentation.
Distilling the Knowledge from Normalizing Flows
Jun 25, 2021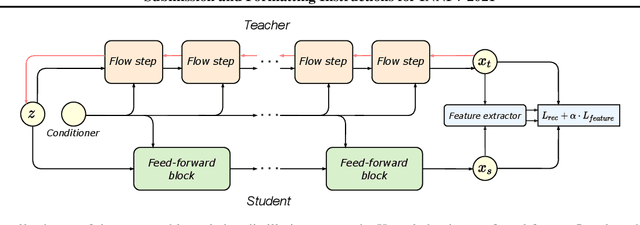
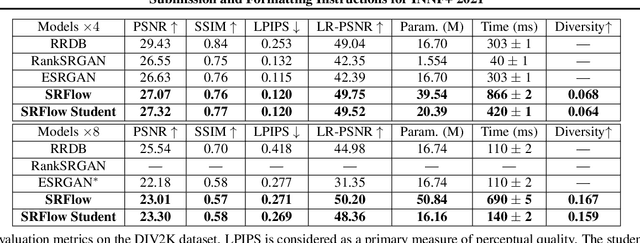
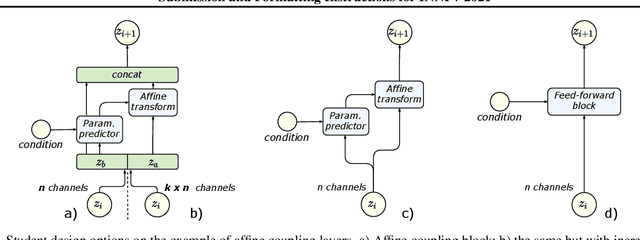
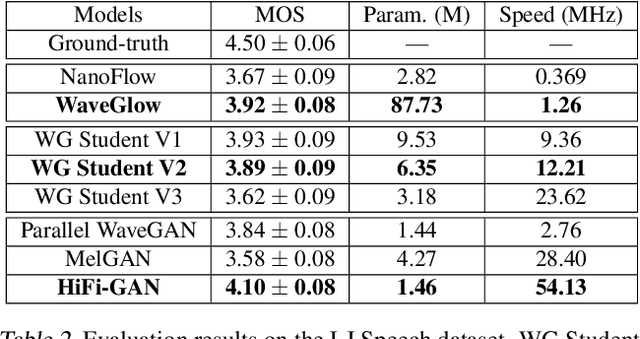
Normalizing flows are a powerful class of generative models demonstrating strong performance in several speech and vision problems. In contrast to other generative models, normalizing flows are latent variable models with tractable likelihoods and allow for stable training. However, they have to be carefully designed to represent invertible functions with efficient Jacobian determinant calculation. In practice, these requirements lead to overparameterized and sophisticated architectures that are inferior to alternative feed-forward models in terms of inference time and memory consumption. In this work, we investigate whether one can distill flow-based models into more efficient alternatives. We provide a positive answer to this question by proposing a simple distillation approach and demonstrating its effectiveness on state-of-the-art conditional flow-based models for image super-resolution and speech synthesis.
Finding Discriminative Filters for Specific Degradations in Blind Super-Resolution
Aug 02, 2021


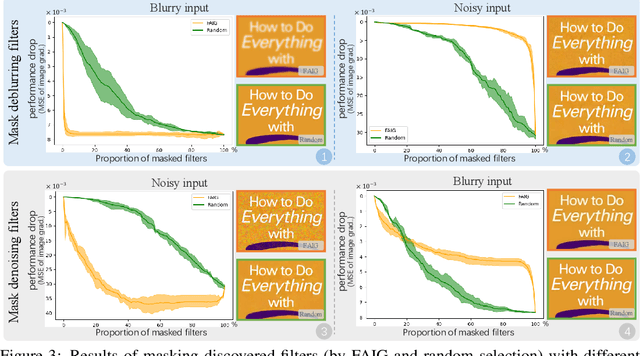
Recent blind super-resolution (SR) methods typically consist of two branches, one for degradation prediction and the other for conditional restoration. However, our experiments show that a one-branch network can achieve comparable performance to the two-branch scheme. Then we wonder: how can one-branch networks automatically learn to distinguish degradations? To find the answer, we propose a new diagnostic tool -- Filter Attribution method based on Integral Gradient (FAIG). Unlike previous integral gradient methods, our FAIG aims at finding the most discriminative filters instead of input pixels/features for degradation removal in blind SR networks. With the discovered filters, we further develop a simple yet effective method to predict the degradation of an input image. Based on FAIG, we show that, in one-branch blind SR networks, 1) we are able to find a very small number of (1%) discriminative filters for each specific degradation; 2) The weights, locations and connections of the discovered filters are all important to determine the specific network function. 3) The task of degradation prediction can be implicitly realized by these discriminative filters without explicit supervised learning. Our findings can not only help us better understand network behaviors inside one-branch blind SR networks, but also provide guidance on designing more efficient architectures and diagnosing networks for blind SR.