 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Saliency Transformer
Apr 25, 2021
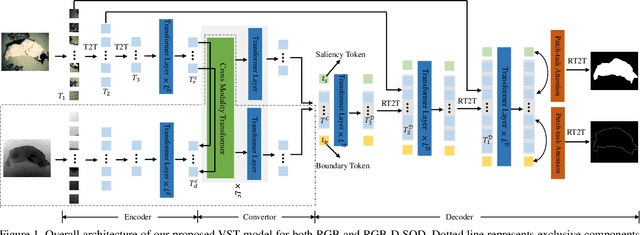
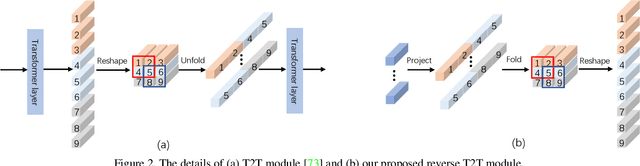
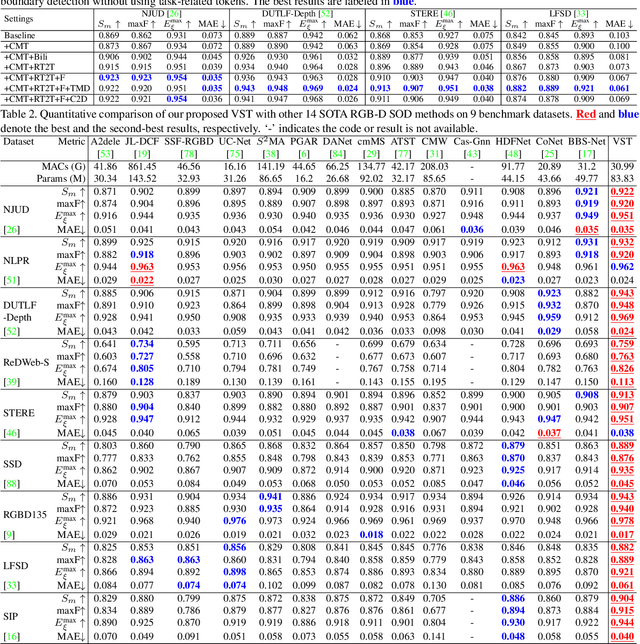
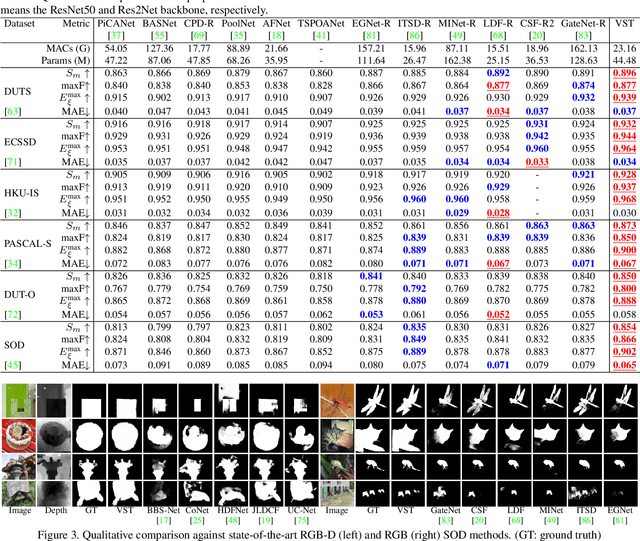
Recently, massive saliency detection methods have achieved promising results by relying on CNN-based architectures. Alternatively, we rethink this task from a convolution-free sequence-to-sequence perspective and predict saliency by modeling long-range dependencies, which can not be achieved by convolution. Specifically, we develop a novel unified model based on a pure transformer, namely, Visual Saliency Transformer (VST), for both RGB and RGB-D salient object detection (SOD). It takes image patches as inputs and leverages the transformer to propagate global contexts among image patches. Apart from the traditional transformer architecture used in Vision Transformer (ViT), we leverage multi-level token fusion and propose a new token upsampling method under the transformer framework to get high-resolution detection results. We also develop a token-based multi-task decoder to simultaneously perform saliency and boundary detection by introducing task-related tokens and a novel patch-task-attention mechanism. Experimental results show that our model outperforms existing state-of-the-art results on both RGB and RGB-D SOD benchmark datasets. Most importantly, our whole framework not only provides a new perspective for the SOD field but also shows a new paradigm for transformer-based dense prediction models.
Unsupervised learning of multimodal image registration using domain adaptation with projected Earth Move's discrepancies
May 28, 2020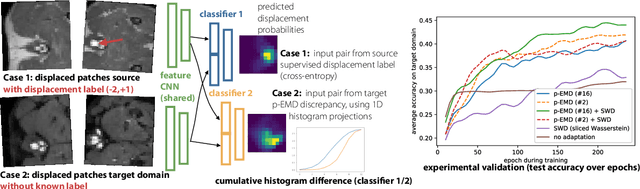
Multimodal image registration is a very challenging problem for deep learning approaches. Most current work focuses on either supervised learning that requires labelled training scans and may yield models that bias towards annotated structures or unsupervised approaches that are based on hand-crafted similarity metrics and may therefore not outperform their classical non-trained counterparts. We believe that unsupervised domain adaptation can be beneficial in overcoming the current limitations for multimodal registration, where good metrics are hard to define. Domain adaptation has so far been mainly limited to classification problems. We propose the first use of unsupervised domain adaptation for discrete multimodal registration. Based on a source domain for which quantised displacement labels are available as supervision, we transfer the output distribution of the network to better resemble the target domain (other modality) using classifier discrepancies. To improve upon the sliced Wasserstein metric for 2D histograms, we present a novel approximation that projects predictions into 1D and computes the L1 distance of their cumulative sums. Our proof-of-concept demonstrates the applicability of domain transfer from mono- to multimodal (multi-contrast) 2D registration of canine MRI scans and improves the registration accuracy from 33% (using sliced Wasserstein) to 44%.
Identifying Water Stress in Chickpea Plant by Analyzing Progressive Changes in Shoot Images using Deep Learning
Apr 16, 2021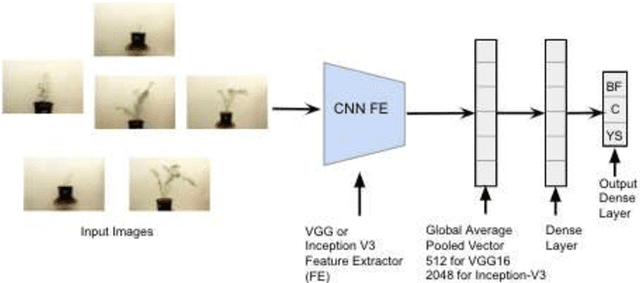
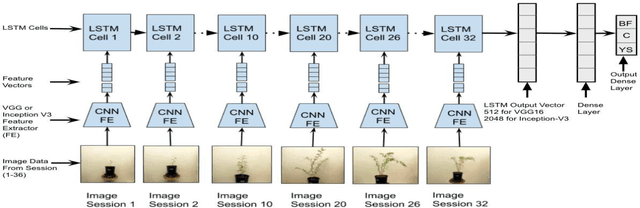

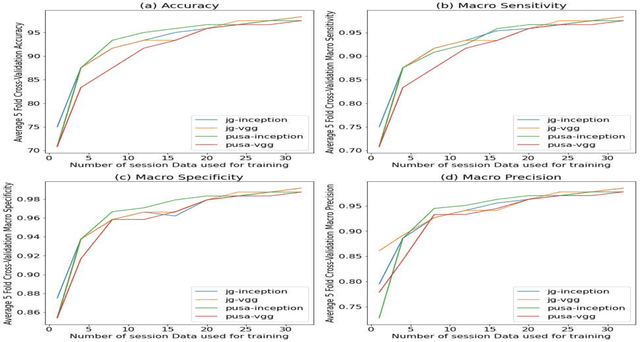
To meet the needs of a growing world population, we need to increase the global agricultural yields by employing modern, precision, and automated farming methods. In the recent decade, high-throughput plant phenotyping techniques, which combine non-invasive image analysis and machine learning, have been successfully applied to identify and quantify plant health and diseases. However, these image-based machine learning usually do not consider plant stress's progressive or temporal nature. This time-invariant approach also requires images showing severe signs of stress to ensure high confidence detections, thereby reducing this approach's feasibility for early detection and recovery of plants under stress. In order to overcome the problem mentioned above, we propose a temporal analysis of the visual changes induced in the plant due to stress and apply it for the specific case of water stress identification in Chickpea plant shoot images. For this, we have considered an image dataset of two chickpea varieties JG-62 and Pusa-372, under three water stress conditions; control, young seedling, and before flowering, captured over five months. We then develop an LSTM-CNN architecture to learn visual-temporal patterns from this dataset and predict the water stress category with high confidence. To establish a baseline context, we also conduct a comparative analysis of the CNN architecture used in the proposed model with the other CNN techniques used for the time-invariant classification of water stress. The results reveal that our proposed LSTM-CNN model has resulted in the ceiling level classification performance of \textbf{98.52\%} on JG-62 and \textbf{97.78\%} on Pusa-372 and the chickpea plant data. Lastly, we perform an ablation study to determine the LSTM-CNN model's performance on decreasing the amount of temporal session data used for training.
Advantages and Bottlenecks of Quantum Machine Learning for Remote Sensing
Jan 28, 2021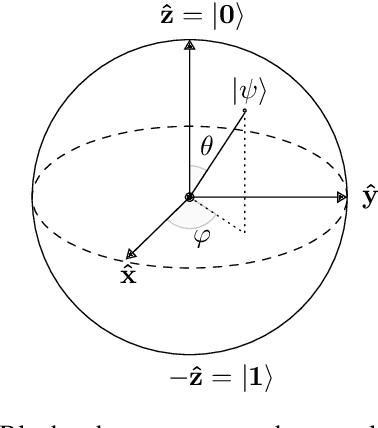
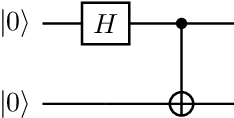
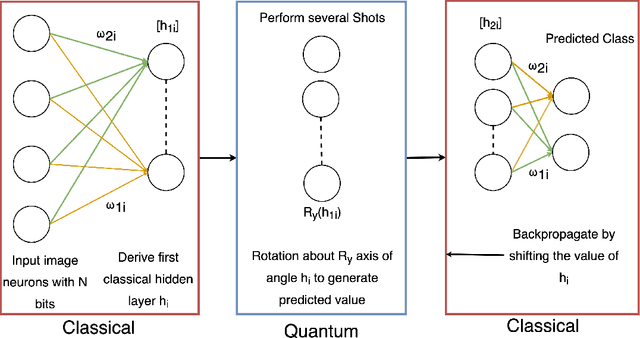

This concept paper aims to provide a brief outline of quantum computers, explore existing methods of quantum image classification techniques, so focusing on remote sensing applications, and discuss the bottlenecks of performing these algorithms on currently available open source platforms. Initial results demonstrate feasibility. Next steps include expanding the size of the quantum hidden layer and increasing the variety of output image options.
Interpolating Points on a Non-Uniform Grid using a Mixture of Gaussians
Dec 24, 2020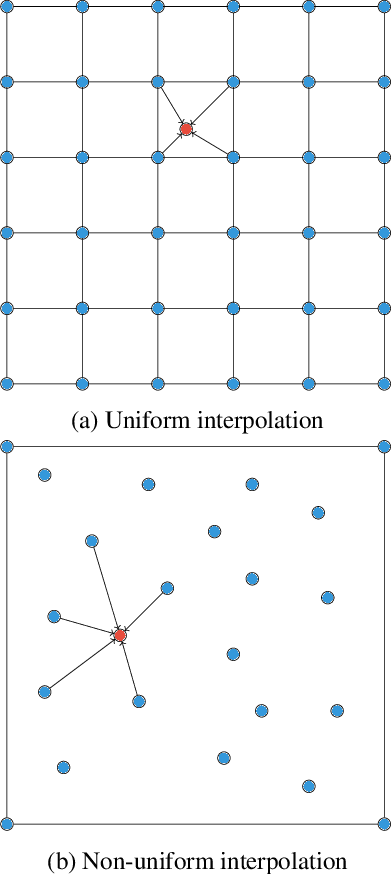
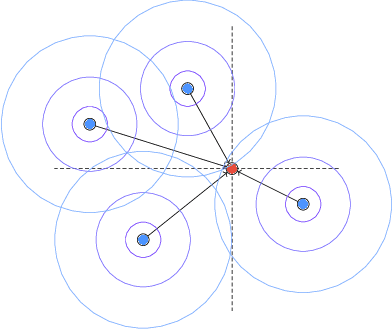
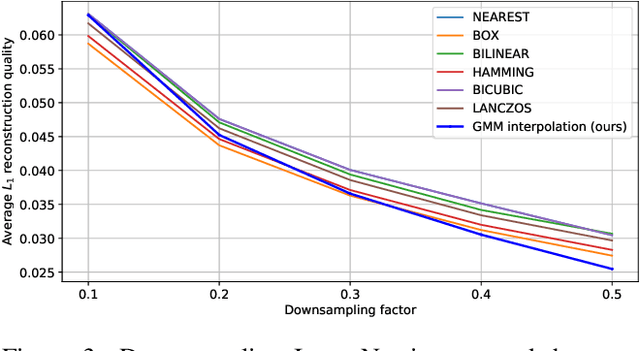
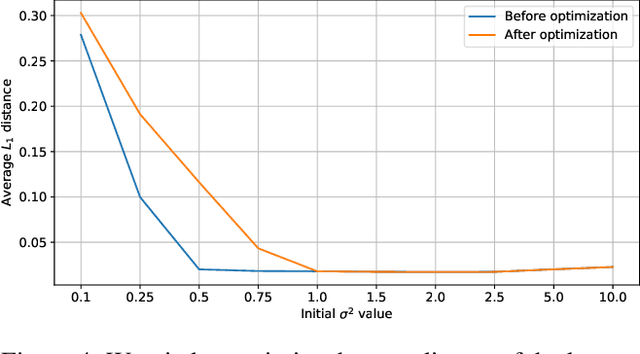
In this work, we propose an approach to perform non-uniform image interpolation based on a Gaussian Mixture Model. Traditional image interpolation methods, like nearest neighbor, bilinear, Hamming, Lanczos, etc. assume that the coordinates you want to interpolate from, are positioned on a uniform grid. However, it is not always the case in practice and we develop an interpolation method that is able to generate an image from arbitrarily positioned pixel values. We do this by representing each known pixel as a 2D normal distribution and considering each output image pixel as a sample from the mixture of all the known ones. Apart from the ability to reconstruct an image from arbitrarily positioned set of pixels, this also allows us to differentiate through the interpolation procedure, which might be helpful for downstream applications. Our optimized CUDA kernel and the source code to reproduce the benchmarks is located at https://github.com/universome/non-uniform-interpolation.
A New Clustering-Based Technique for the Acceleration of Deep Convolutional Networks
Jul 19, 2021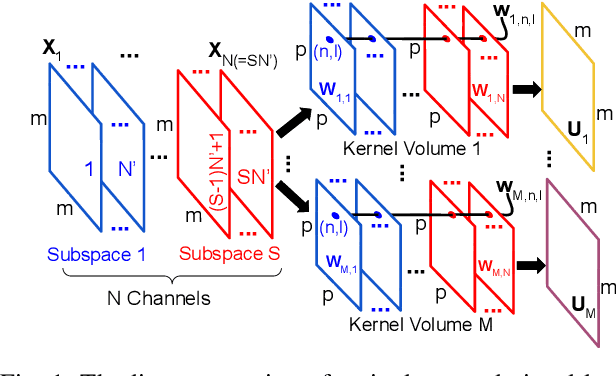
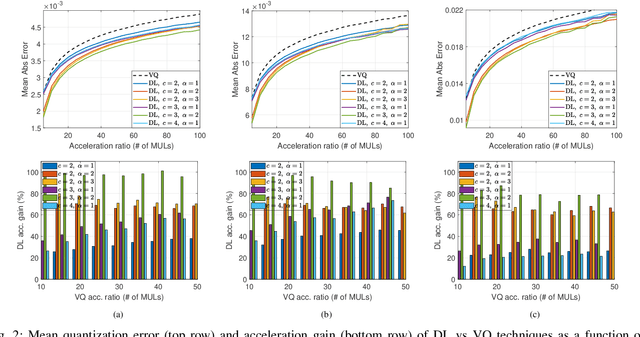
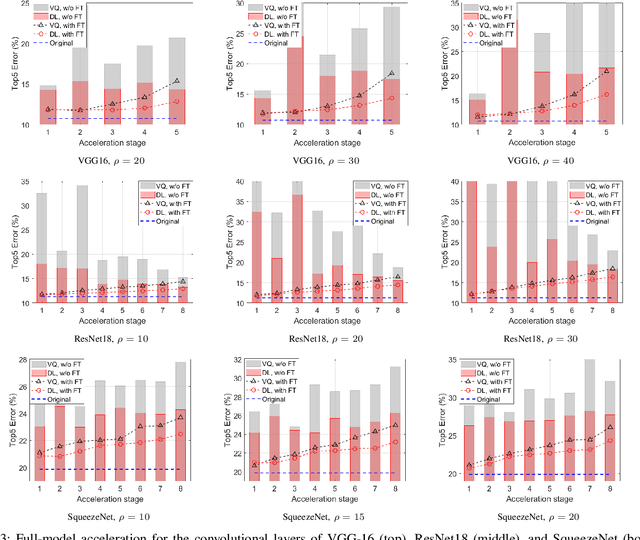

Deep learning and especially the use of Deep Neural Networks (DNNs) provides impressive results in various regression and classification tasks. However, to achieve these results, there is a high demand for computing and storing resources. This becomes problematic when, for instance, real-time, mobile applications are considered, in which the involved (embedded) devices have limited resources. A common way of addressing this problem is to transform the original large pre-trained networks into new smaller models, by utilizing Model Compression and Acceleration (MCA) techniques. Within the MCA framework, we propose a clustering-based approach that is able to increase the number of employed centroids/representatives, while at the same time, have an acceleration gain compared to conventional, $k$-means based approaches. This is achieved by imposing a special structure to the employed representatives, which is enabled by the particularities of the problem at hand. Moreover, the theoretical acceleration gains are presented and the key system hyper-parameters that affect that gain, are identified. Extensive evaluation studies carried out using various state-of-the-art DNN models trained in image classification, validate the superiority of the proposed method as compared for its use in MCA tasks.
Object-driven Text-to-Image Synthesis via Adversarial Training
Feb 27, 2019
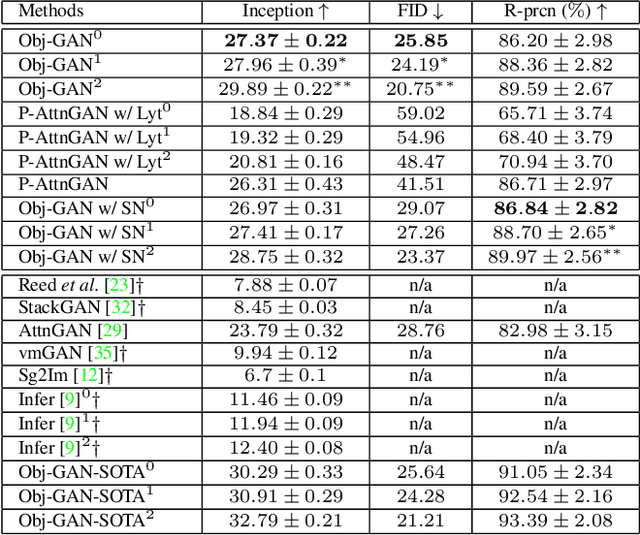
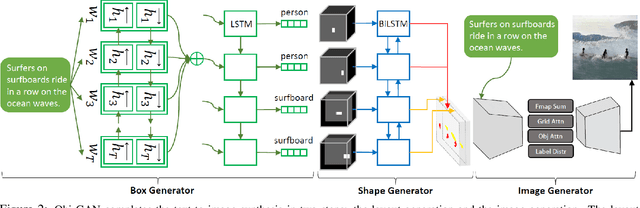

In this paper, we propose Object-driven Attentive Generative Adversarial Newtorks (Obj-GANs) that allow object-centered text-to-image synthesis for complex scenes. Following the two-step (layout-image) generation process, a novel object-driven attentive image generator is proposed to synthesize salient objects by paying attention to the most relevant words in the text description and the pre-generated semantic layout. In addition, a new Fast R-CNN based object-wise discriminator is proposed to provide rich object-wise discrimination signals on whether the synthesized object matches the text description and the pre-generated layout. The proposed Obj-GAN significantly outperforms the previous state of the art in various metrics on the large-scale COCO benchmark, increasing the Inception score by 27% and decreasing the FID score by 11%. A thorough comparison between the traditional grid attention and the new object-driven attention is provided through analyzing their mechanisms and visualizing their attention layers, showing insights of how the proposed model generates complex scenes in high quality.
Unsupervised Learning of Fine Structure Generation for 3D Point Clouds by 2D Projection Matching
Aug 08, 2021



Learning to generate 3D point clouds without 3D supervision is an important but challenging problem. Current solutions leverage various differentiable renderers to project the generated 3D point clouds onto a 2D image plane, and train deep neural networks using the per-pixel difference with 2D ground truth images. However, these solutions are still struggling to fully recover fine structures of 3D shapes, such as thin tubes or planes. To resolve this issue, we propose an unsupervised approach for 3D point cloud generation with fine structures. Specifically, we cast 3D point cloud learning as a 2D projection matching problem. Rather than using entire 2D silhouette images as a regular pixel supervision, we introduce structure adaptive sampling to randomly sample 2D points within the silhouettes as an irregular point supervision, which alleviates the consistency issue of sampling from different view angles. Our method pushes the neural network to generate a 3D point cloud whose 2D projections match the irregular point supervision from different view angles. Our 2D projection matching approach enables the neural network to learn more accurate structure information than using the per-pixel difference, especially for fine and thin 3D structures. Our method can recover fine 3D structures from 2D silhouette images at different resolutions, and is robust to different sampling methods and point number in irregular point supervision. Our method outperforms others under widely used benchmarks. Our code, data and models are available at https://github.com/chenchao15/2D\_projection\_matching.
UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation
Dec 11, 2019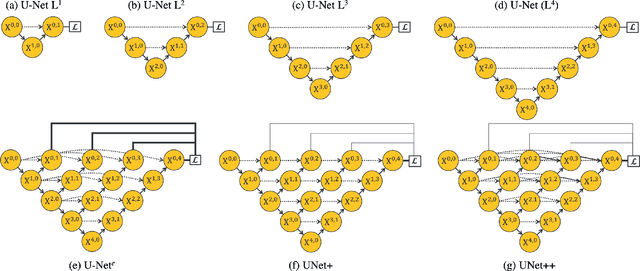

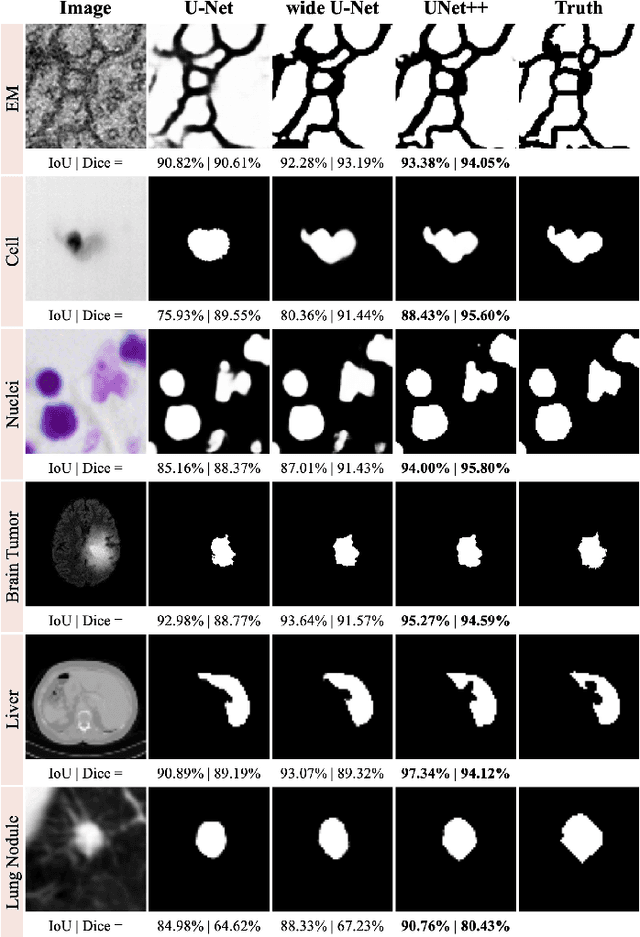
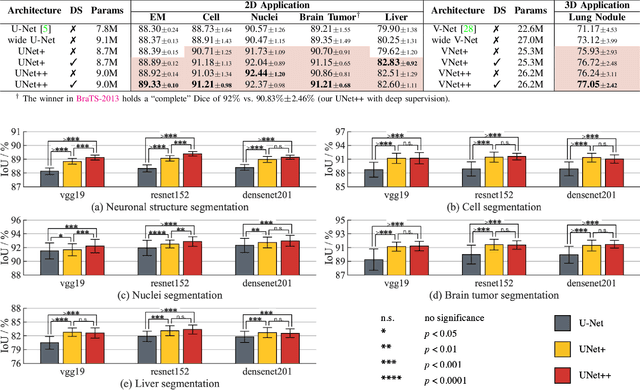
The state-of-the-art models for medical image segmentation are variants of U-Net and fully convolutional networks (FCN). Despite their success, these models have two limitations: (1) their optimal depth is apriori unknown, requiring extensive architecture search or inefficient ensemble of models of varying depths; and (2) their skip connections impose an unnecessarily restrictive fusion scheme, forcing aggregation only at the same-scale feature maps of the encoder and decoder sub-networks. To overcome these two limitations, we propose UNet++, a new neural architecture for semantic and instance segmentation, by (1) alleviating the unknown network depth with an efficient ensemble of U-Nets of varying depths, which partially share an encoder and co-learn simultaneously using deep supervision; (2) redesigning skip connections to aggregate features of varying semantic scales at the decoder sub-networks, leading to a highly flexible feature fusion scheme; and (3) devising a pruning scheme to accelerate the inference speed of UNet++. We have evaluated UNet++ using six different medical image segmentation datasets, covering multiple imaging modalities such as computed tomography (CT), magnetic resonance imaging (MRI), and electron microscopy (EM), and demonstrating that (1) UNet++ consistently outperforms the baseline models for the task of semantic segmentation across different datasets and backbone architectures; (2) UNet++ enhances segmentation quality of varying-size objects -- an improvement over the fixed-depth U-Net; (3) Mask RCNN++ (Mask R-CNN with UNet++ design) outperforms the original Mask R-CNN for the task of instance segmentation; and (4) pruned UNet++ models achieve significant speedup while showing only modest performance degradation. Our implementation and pre-trained models are available at https://github.com/MrGiovanni/UNetPlusPlus.
Machine Learning and Deep Learning Methods for Building Intelligent Systems in Medicine and Drug Discovery: A Comprehensive Survey
Jul 19, 2021

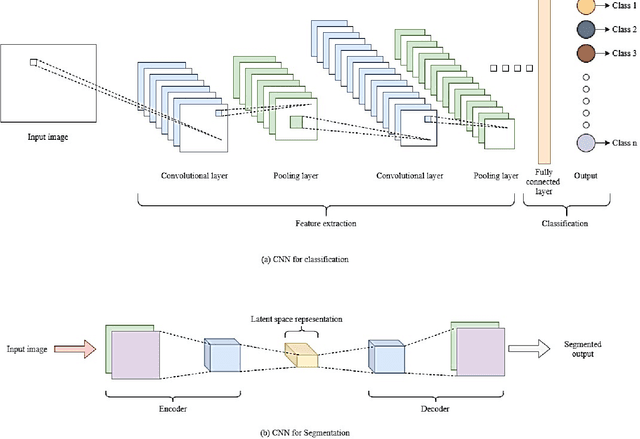
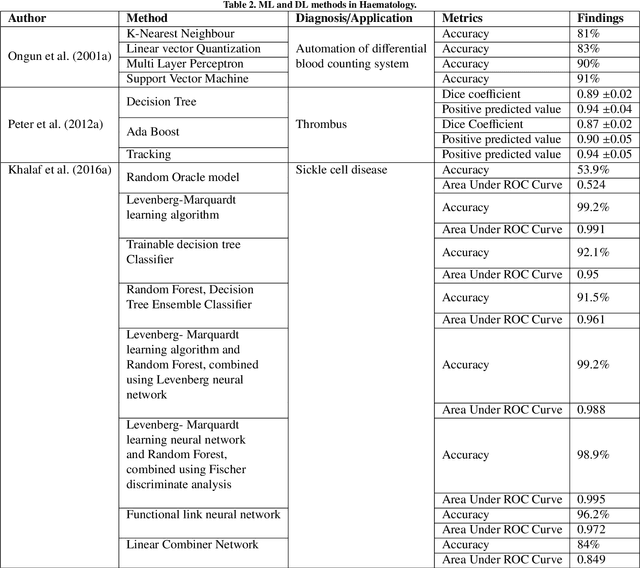
With the advancements in computer technology, there is a rapid development of intelligent systems to understand the complex relationships in data to make predictions and classifications. Artificail Intelligence based framework is rapidly revolutionizing the healthcare industry. These intelligent systems are built with machine learning and deep learning based robust models for early diagnosis of diseases and demonstrates a promising supplementary diagnostic method for frontline clinical doctors and surgeons. Machine Learning and Deep Learning based systems can streamline and simplify the steps involved in diagnosis of diseases from clinical and image-based data, thus providing significant clinician support and workflow optimization. They mimic human cognition and are even capable of diagnosing diseases that cannot be diagnosed with human intelligence. This paper focuses on the survey of machine learning and deep learning applications in across 16 medical specialties, namely Dental medicine, Haematology, Surgery, Cardiology, Pulmonology, Orthopedics, Radiology, Oncology, General medicine, Psychiatry, Endocrinology, Neurology, Dermatology, Hepatology, Nephrology, Ophthalmology, and Drug discovery. In this paper along with the survey, we discuss the advancements of medical practices with these systems and also the impact of these systems on medical professionals.