 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Graph Convolutional Memory for Deep Reinforcement Learning
Jun 27, 2021
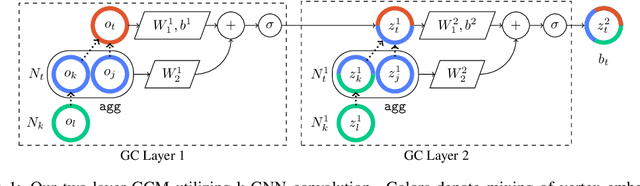
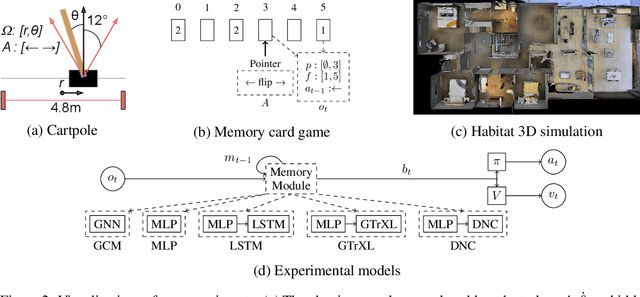
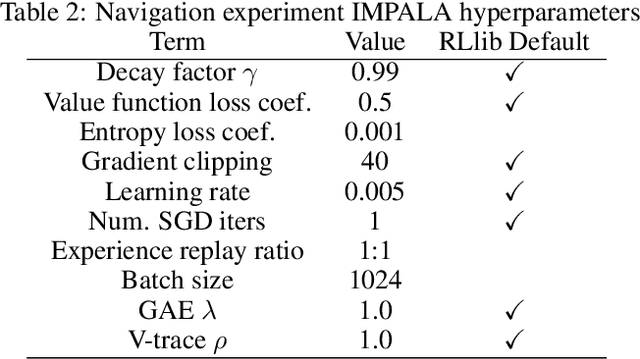
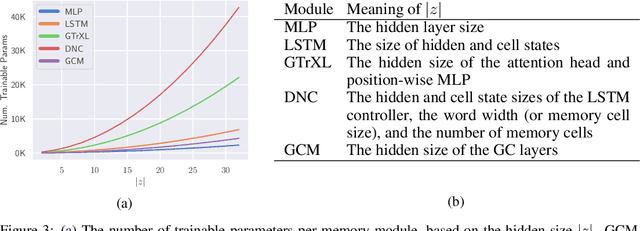
Solving partially-observable Markov decision processes (POMDPs) is critical when applying deep reinforcement learning (DRL) to real-world robotics problems, where agents have an incomplete view of the world. We present graph convolutional memory (GCM) for solving POMDPs using deep reinforcement learning. Unlike recurrent neural networks (RNNs) or transformers, GCM embeds domain-specific priors into the memory recall process via a knowledge graph. By encapsulating priors in the graph, GCM adapts to specific tasks but remains applicable to any DRL task. Using graph convolutions, GCM extracts hierarchical graph features, analogous to image features in a convolutional neural network (CNN). We show GCM outperforms long short-term memory (LSTM), gated transformers for reinforcement learning (GTrXL), and differentiable neural computers (DNCs) on control, long-term non-sequential recall, and 3D navigation tasks while using significantly fewer parameters.
The U-Net based GLOW for Optical-Flow-free Video Interframe Generation
Apr 06, 2021
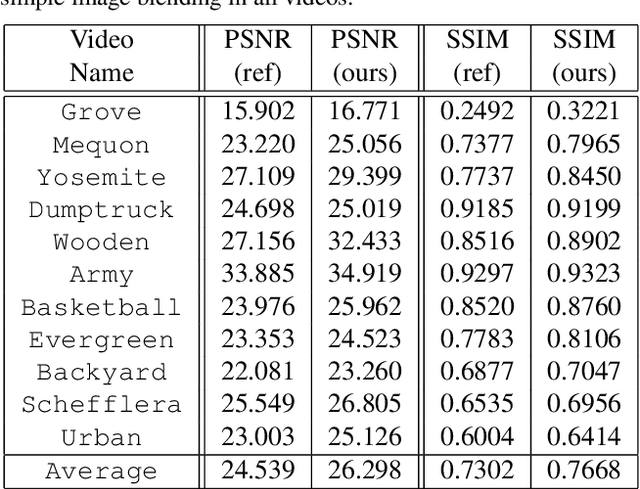
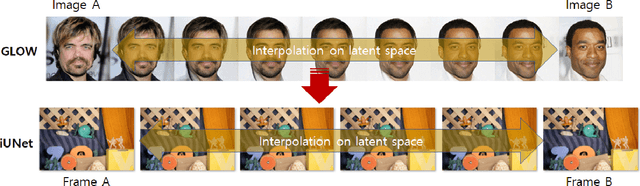
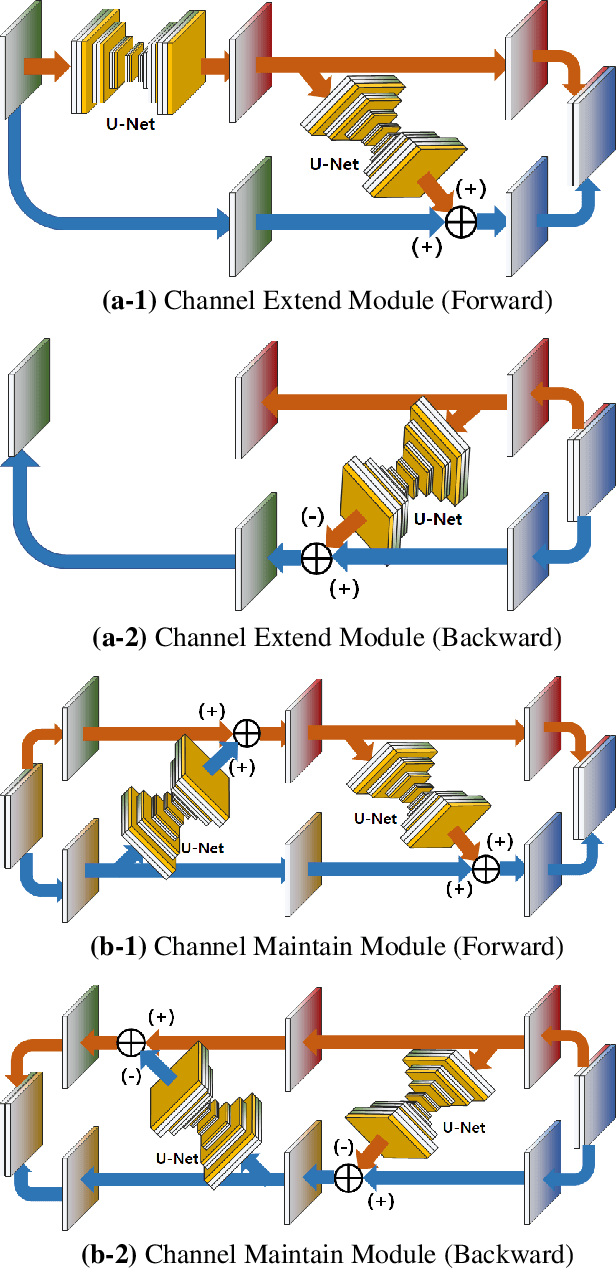
Video frame interpolation is the task of creating an interframe between two adjacent frames along the time axis. So, instead of simply averaging two adjacent frames to create an intermediate image, this operation should maintain semantic continuity with the adjacent frames. Most conventional methods use optical flow, and various tools such as occlusion handling and object smoothing are indispensable. Since the use of these various tools leads to complex problems, we tried to tackle the video interframe generation problem without using problematic optical flow . To enable this , we have tried to use a deep neural network with an invertible structure, and developed an U-Net based Generative Flow which is a modified normalizing flow. In addition, we propose a learning method with a new consistency loss in the latent space to maintain semantic temporal consistency between frames. The resolution of the generated image is guaranteed to be identical to that of the original images by using an invertible network. Furthermore, as it is not a random image like the ones by generative models, our network guarantees stable outputs without flicker. Through experiments, we \sam {confirmed the feasibility of the proposed algorithm and would like to suggest the U-Net based Generative Flow as a new possibility for baseline in video frame interpolation. This paper is meaningful in that it is the world's first attempt to use invertible networks instead of optical flows for video interpolation.
Neural Naturalist: Generating Fine-Grained Image Comparisons
Sep 20, 2019
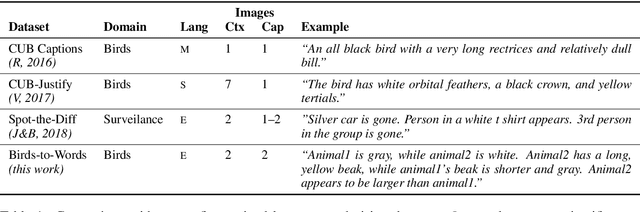
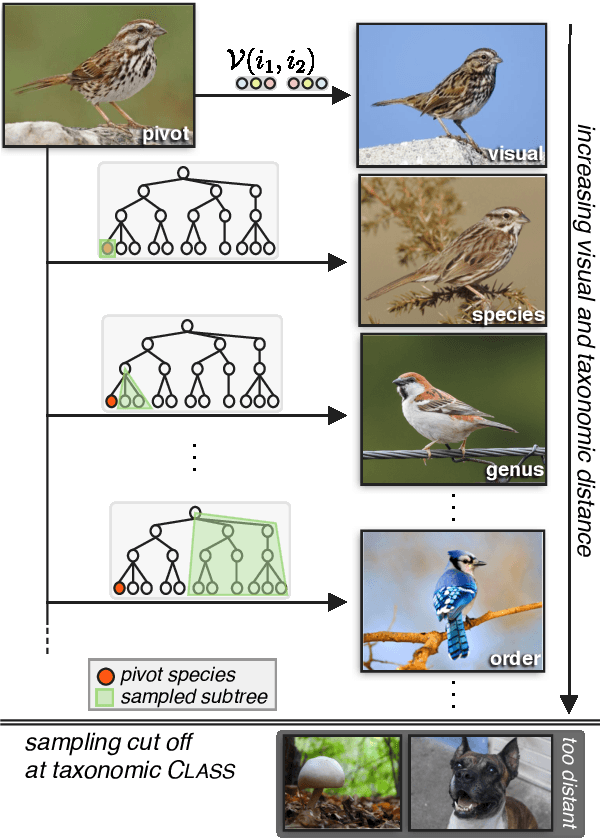
We introduce the new Birds-to-Words dataset of 41k sentences describing fine-grained differences between photographs of birds. The language collected is highly detailed, while remaining understandable to the everyday observer (e.g., "heart-shaped face," "squat body"). Paragraph-length descriptions naturally adapt to varying levels of taxonomic and visual distance---drawn from a novel stratified sampling approach---with the appropriate level of detail. We propose a new model called Neural Naturalist that uses a joint image encoding and comparative module to generate comparative language, and evaluate the results with humans who must use the descriptions to distinguish real images. Our results indicate promising potential for neural models to explain differences in visual embedding space using natural language, as well as a concrete path for machine learning to aid citizen scientists in their effort to preserve biodiversity.
Monocular Visual Analysis for Electronic Line Calling of Tennis Games
Jul 20, 2021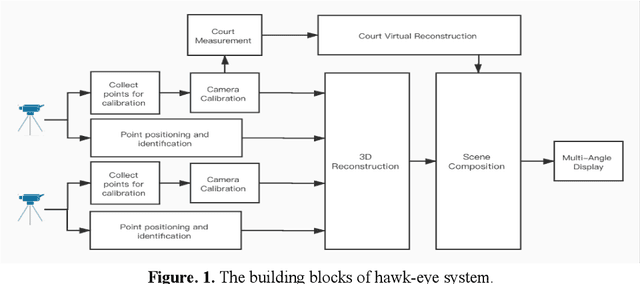
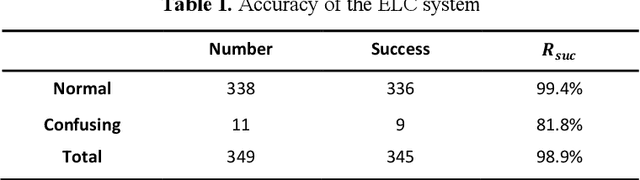

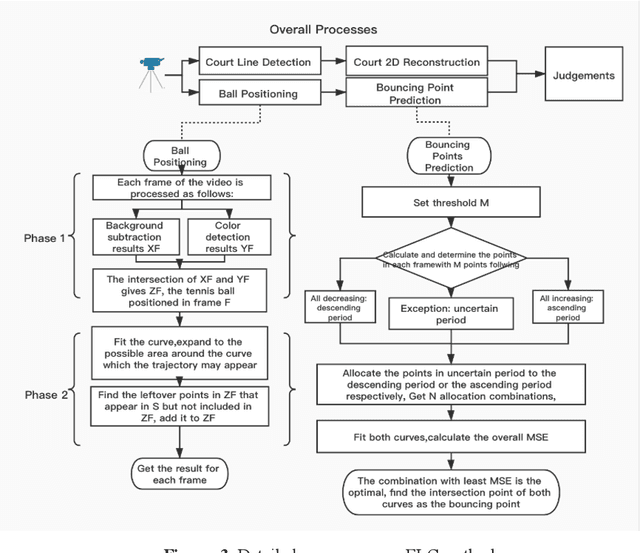
Electronic Line Calling is an auxiliary referee system used for tennis matches based on binocular vision technology. While ELC has been widely used, there are still many problems, such as complex installation and maintenance, high cost and etc. We propose a monocular vision technology based ELC method. The method has the following steps. First, locate the tennis ball's trajectory. We propose a multistage tennis ball positioning approach combining background subtraction and color area filtering. Then we propose a bouncing point prediction method by minimizing the fitting loss of the uncertain point. Finally, we find out whether the bouncing point of the ball is out of bounds or not according to the relative position between the bouncing point and the court side line in the two dimensional image. We collected and tagged 394 samples with an accuracy rate of 99.4%, and 81.8% of the 11 samples with bouncing points.The experimental results show that our method is feasible to judge if a ball is out of the court with monocular vision and significantly reduce complex installation and costs of ELC system with binocular vision.
The QXS-SAROPT Dataset for Deep Learning in SAR-Optical Data Fusion
Mar 15, 2021Deep learning techniques have made an increasing impact on the field of remote sensing. However, deep neural networks based fusion of multimodal data from different remote sensors with heterogenous characteristics has not been fully explored, due to the lack of availability of big amounts of perfectly aligned multi-sensor image data with diverse scenes of high resolution, especially for synthetic aperture radar (SAR) data and optical imagery. In this paper, we publish the QXS-SAROPT dataset to foster deep learning research in SAR-optical data fusion. QXS-SAROPT comprises 20,000 pairs of corresponding image patches, collected from three port cities: San Diego, Shanghai and Qingdao acquired by the SAR satellite GaoFen-3 and optical satellites of Google Earth. Besides a detailed description of the dataset, we show exemplary results for two representative applications, namely SAR-optical image matching and SAR ship detection boosted by cross-modal information from optical images. Since QXS-SAROPT is a large open dataset with multiple scenes of the highest resolution of this kind, we believe it will support further developments in the field of deep learning based SAR-optical data fusion for remote sensing.
ACCL: Adversarial constrained-CNN loss for weakly supervised medical image segmentation
May 01, 2020
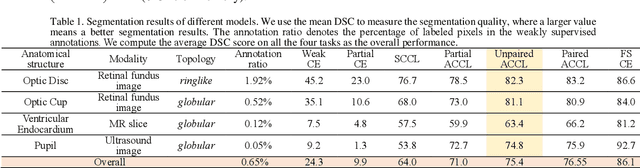
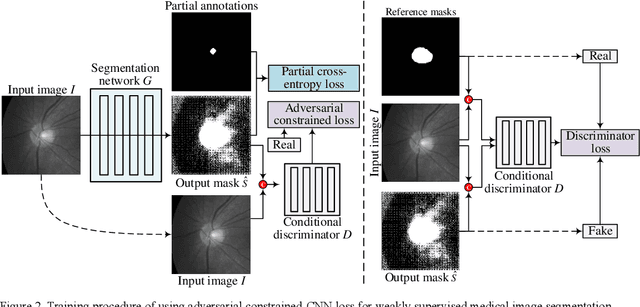
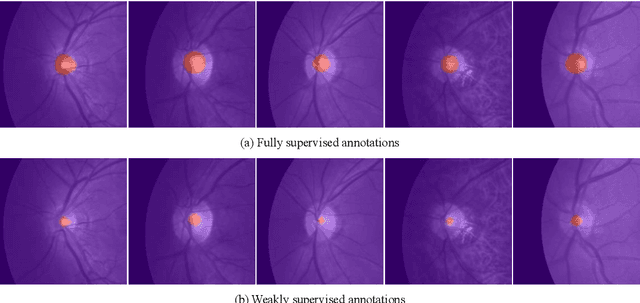
We propose adversarial constrained-CNN loss, a new paradigm of constrained-CNN loss methods, for weakly supervised medical image segmentation. In the new paradigm, prior knowledge is encoded and depicted by reference masks, and is further employed to impose constraints on segmentation outputs through adversarial learning with reference masks. Unlike pseudo label methods for weakly supervised segmentation, such reference masks are used to train a discriminator rather than a segmentation network, and thus are not required to be paired with specific images. Our new paradigm not only greatly facilitates imposing prior knowledge on network's outputs, but also provides stronger and higher-order constraints, i.e., distribution approximation, through adversarial learning. Extensive experiments involving different medical modalities, different anatomical structures, different topologies of the object of interest, different levels of prior knowledge and weakly supervised annotations with different annotation ratios is conducted to evaluate our ACCL method. Consistently superior segmentation results over the size constrained-CNN loss method have been achieved, some of which are close to the results of full supervision, thus fully verifying the effectiveness and generalization of our method. Specifically, we report an average Dice score of 75.4% with an average annotation ratio of 0.65%, surpassing the prior art, i.e., the size constrained-CNN loss method, by a large margin of 11.4%. Our codes are made publicly available at https://github.com/PengyiZhang/ACCL.
A Joint Network for Grasp Detection Conditioned on Natural Language Commands
Apr 01, 2021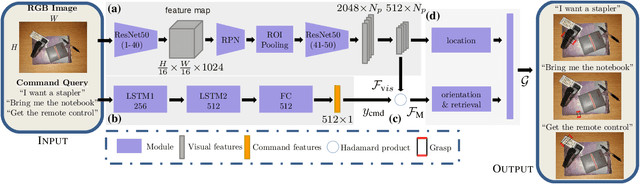

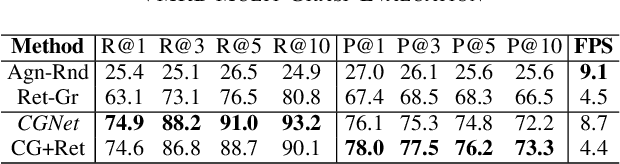
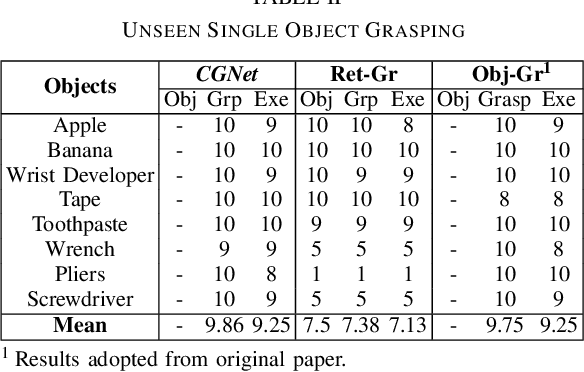
We consider the task of grasping a target object based on a natural language command query. Previous work primarily focused on localizing the object given the query, which requires a separate grasp detection module to grasp it. The cascaded application of two pipelines incurs errors in overlapping multi-object cases due to ambiguity in the individual outputs. This work proposes a model named Command Grasping Network(CGNet) to directly output command satisficing grasps from RGB image and textual command inputs. A dataset with ground truth (image, command, grasps) tuple is generated based on the VMRD dataset to train the proposed network. Experimental results on the generated test set show that CGNet outperforms a cascaded object-retrieval and grasp detection baseline by a large margin. Three physical experiments demonstrate the functionality and performance of CGNet.
Divide-and-Assemble: Learning Block-wise Memory for Unsupervised Anomaly Detection
Jul 28, 2021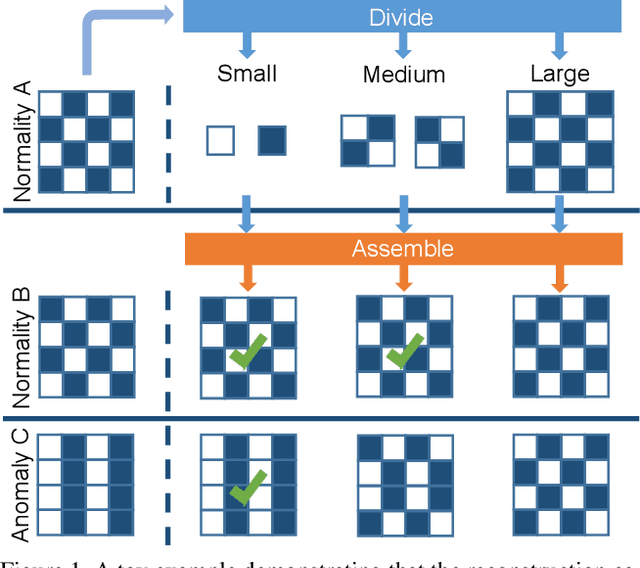

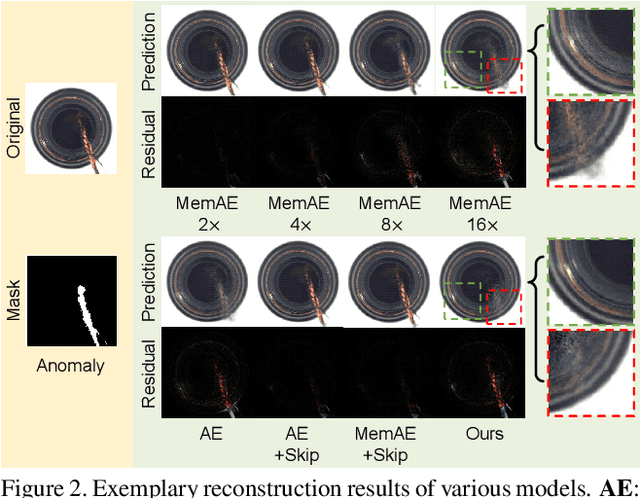
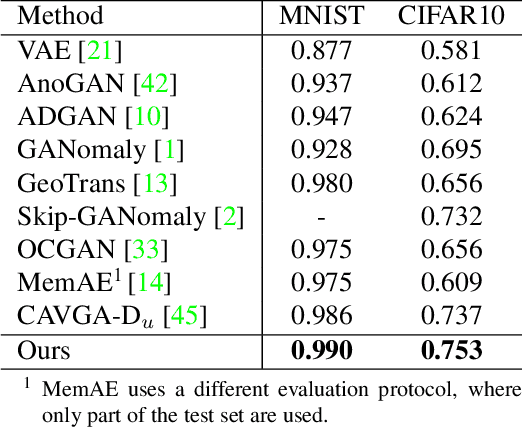
Reconstruction-based methods play an important role in unsupervised anomaly detection in images. Ideally, we expect a perfect reconstruction for normal samples and poor reconstruction for abnormal samples. Since the generalizability of deep neural networks is difficult to control, existing models such as autoencoder do not work well. In this work, we interpret the reconstruction of an image as a divide-and-assemble procedure. Surprisingly, by varying the granularity of division on feature maps, we are able to modulate the reconstruction capability of the model for both normal and abnormal samples. That is, finer granularity leads to better reconstruction, while coarser granularity leads to poorer reconstruction. With proper granularity, the gap between the reconstruction error of normal and abnormal samples can be maximized. The divide-and-assemble framework is implemented by embedding a novel multi-scale block-wise memory module into an autoencoder network. Besides, we introduce adversarial learning and explore the semantic latent representation of the discriminator, which improves the detection of subtle anomaly. We achieve state-of-the-art performance on the challenging MVTec AD dataset. Remarkably, we improve the vanilla autoencoder model by 10.1% in terms of the AUROC score.
Rendu basé image avec contraintes sur les gradients
Dec 29, 2018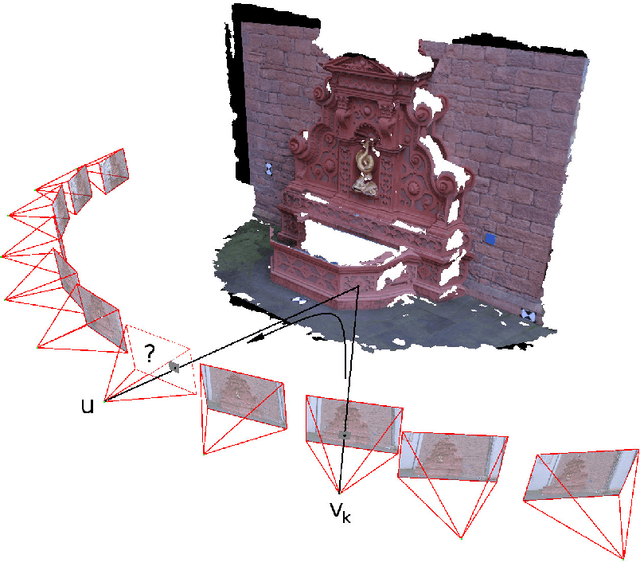
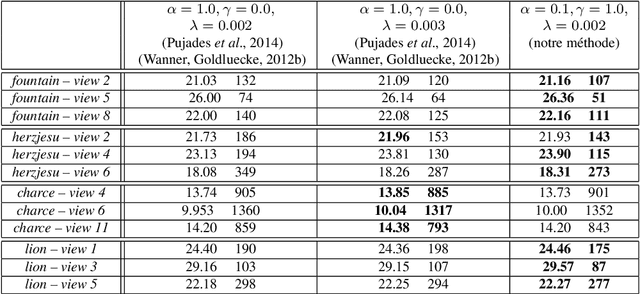
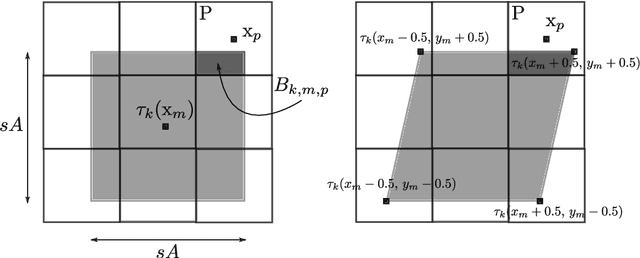

Multi-view image-based rendering consists in generating a novel view of a scene from a set of source views. In general, this works by first doing a coarse 3D reconstruction of the scene, and then using this reconstruction to establish correspondences between source and target views, followed by blending the warped views to get the final image. Unfortunately, discontinuities in the blending weights, due to scene geometry or camera placement, result in artifacts in the target view. In this paper, we show how to avoid these artifacts by imposing additional constraints on the image gradients of the novel view. We propose a variational framework in which an energy functional is derived and optimized by iteratively solving a linear system. We demonstrate this method on several structured and unstructured multi-view datasets, and show that it numerically outperforms state-of-the-art methods, and eliminates artifacts that result from visibility discontinuities
Deep Retinex Network for Estimating Illumination Colors with Self-Supervised Learning
Feb 08, 2021
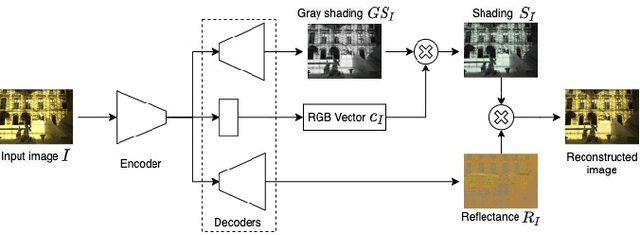

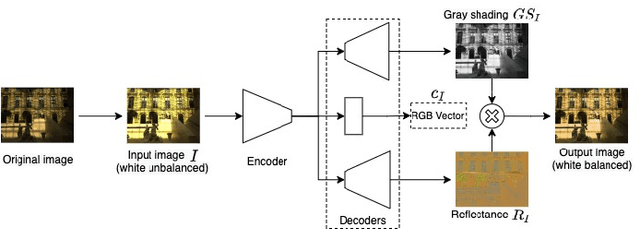
We propose a novel Retinex image-decomposition network that can be trained in a self-supervised manner. The Retinex image-decomposition aims to decompose an image into illumination-invariant and illumination-variant components, referred to as "reflectance" and "shading," respectively. Although there are three consistencies that the reflectance and shading should satisfy, most conventional work considers only one or two of the consistencies. For this reason, the three consistencies are considered in the proposed network. In addition, by using generated pseudo-images for training, the proposed network can be trained with self-supervised learning. Experimental results show that our network can decompose images into reflectance and shading components. Furthermore, it is shown that the proposed network can be used for white-balance adjustment.