 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Misclassification-Aware Gaussian Smoothing improves Robustness against Domain Shifts
Apr 02, 2021

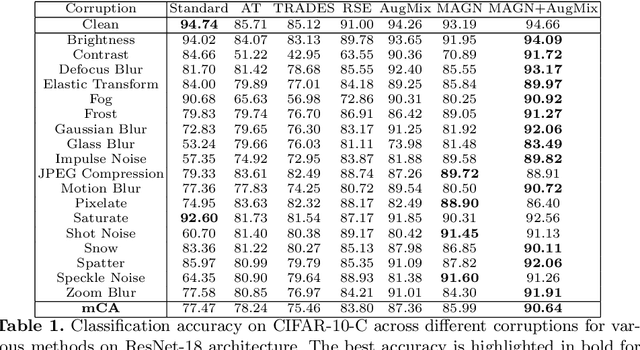
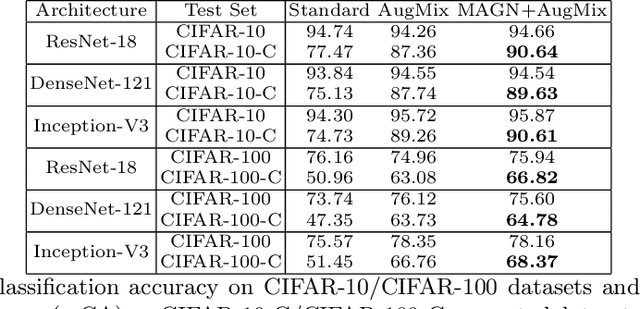
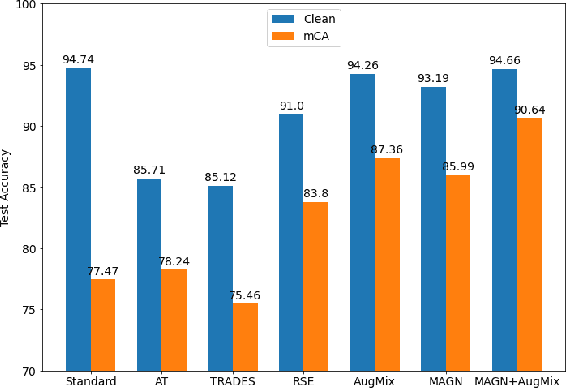
Deep neural networks achieve high prediction accuracy when the train and test distributions coincide. However, in practice various types of corruptions can deviate from this setup and performance can be heavily degraded. There have been only a few methods to address generalization in presence of unexpected domain shifts observed during deployment. In this paper, a misclassification-aware Gaussian smoothing approach is presented to improve the robustness of image classifiers against a variety of corruptions while maintaining clean accuracy. The intuition behind our proposed misclassification-aware objective is revealed through bounds on the local loss deviation in the small-noise regime. When our method is coupled with additional data augmentations, it is empirically shown to improve upon the state-of-the-art in robustness and uncertainty calibration on several image classification tasks.
An image-driven machine learning approach to kinetic modeling of a discontinuous precipitation reaction
Jun 13, 2019

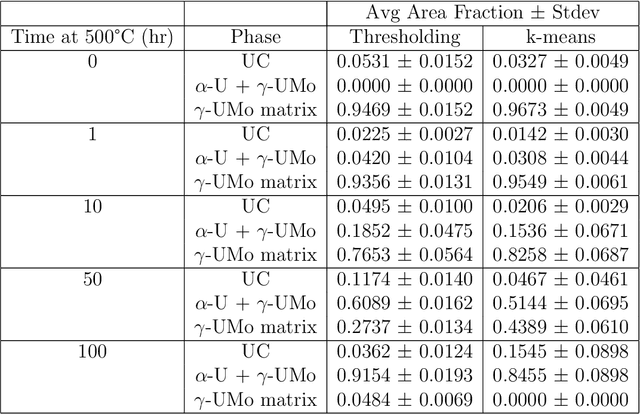
Micrograph quantification is an essential component of several materials science studies. Machine learning methods, in particular convolutional neural networks, have previously demonstrated performance in image recognition tasks across several disciplines (e.g. materials science, medical imaging, facial recognition). Here, we apply these well-established methods to develop an approach to microstructure quantification for kinetic modeling of a discontinuous precipitation reaction in a case study on the uranium-molybdenum system. Prediction of material processing history based on image data (classification), calculation of area fraction of phases present in the micrographs (segmentation), and kinetic modeling from segmentation results were performed. Results indicate that convolutional neural networks represent microstructure image data well, and segmentation using the k-means clustering algorithm yields results that agree well with manually annotated images. Classification accuracies of original and segmented images are both 94\% for a 5-class classification problem. Kinetic modeling results agree well with previously reported data using manual thresholding. The image quantification and kinetic modeling approach developed and presented here aims to reduce researcher bias introduced into the characterization process, and allows for leveraging information in limited image data sets.
Image Generation and Translation with Disentangled Representations
Mar 28, 2018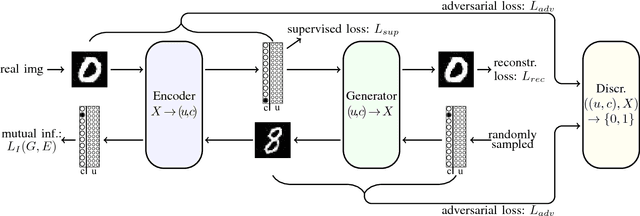



Generative models have made significant progress in the tasks of modeling complex data distributions such as natural images. The introduction of Generative Adversarial Networks (GANs) and auto-encoders lead to the possibility of training on big data sets in an unsupervised manner. However, for many generative models it is not possible to specify what kind of image should be generated and it is not possible to translate existing images into new images of similar domains. Furthermore, models that can perform image-to-image translation often need distinct models for each domain, making it hard to scale these systems to multiple domain image-to-image translation. We introduce a model that can do both, controllable image generation and image-to-image translation between multiple domains. We split our image representation into two parts encoding unstructured and structured information respectively. The latter is designed in a disentangled manner, so that different parts encode different image characteristics. We train an encoder to encode images into these representations and use a small amount of labeled data to specify what kind of information should be encoded in the disentangled part. A generator is trained to generate images from these representations using the characteristics provided by the disentangled part of the representation. Through this we can control what kind of images the generator generates, translate images between different domains, and even learn unknown data-generating factors while only using one single model.
BioFaceNet: Deep Biophysical Face Image Interpretation
Aug 28, 2019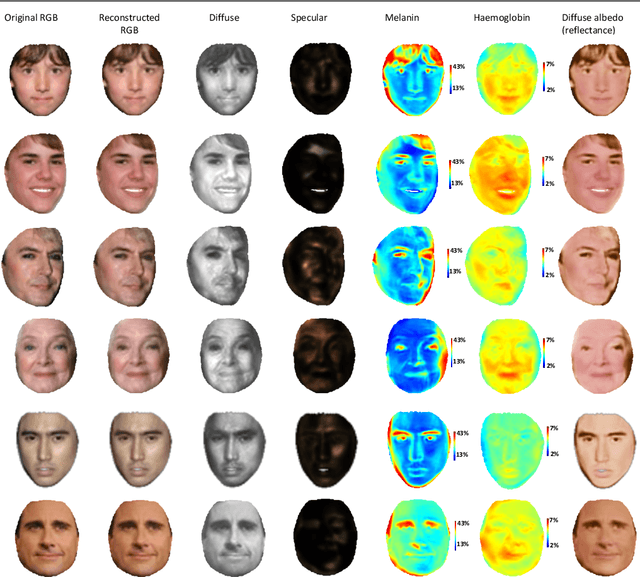

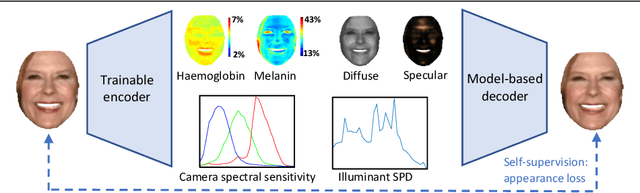
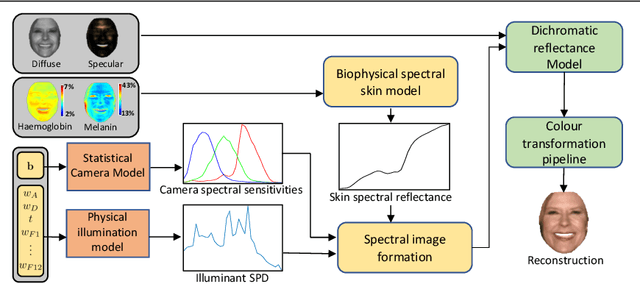
In this paper we present BioFaceNet, a deep CNN that learns to decompose a single face image into biophysical parameters maps, diffuse and specular shading maps as well as estimating the spectral power distribution of the scene illuminant and the spectral sensitivity of the camera. The network comprises a fully convolutional encoder for estimating the spatial maps with a fully connected branch for estimating the vector quantities. The network is trained using a self-supervised appearance loss computed via a model-based decoder. The task is highly underconstrained so we impose a number of model-based priors. Skin spectral reflectance is restricted to a biophysical model, we impose a statistical prior on camera spectral sensitivities, a physical constraint on illumination spectra, a sparsity prior on specular reflections and direct supervision on diffuse shading using a rough shape proxy. We show convincing qualitative results on in-the-wild data and introduce a benchmark for quantitative evaluation on this new task.
Spatially and color consistent environment lighting estimation using deep neural networks for mixed reality
Aug 17, 2021
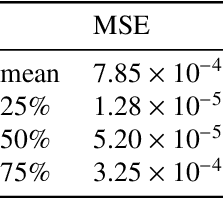
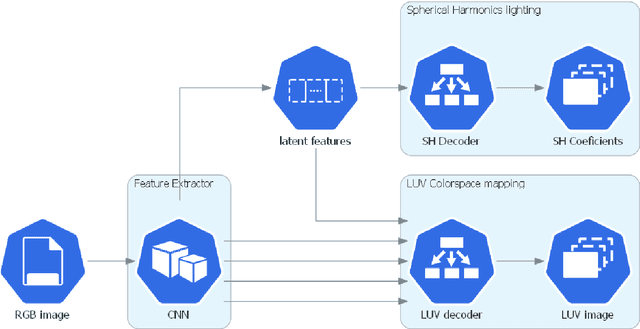

The representation of consistent mixed reality (XR) environments requires adequate real and virtual illumination composition in real-time. Estimating the lighting of a real scenario is still a challenge. Due to the ill-posed nature of the problem, classical inverse-rendering techniques tackle the problem for simple lighting setups. However, those assumptions do not satisfy the current state-of-art in computer graphics and XR applications. While many recent works solve the problem using machine learning techniques to estimate the environment light and scene's materials, most of them are limited to geometry or previous knowledge. This paper presents a CNN-based model to estimate complex lighting for mixed reality environments with no previous information about the scene. We model the environment illumination using a set of spherical harmonics (SH) environment lighting, capable of efficiently represent area lighting. We propose a new CNN architecture that inputs an RGB image and recognizes, in real-time, the environment lighting. Unlike previous CNN-based lighting estimation methods, we propose using a highly optimized deep neural network architecture, with a reduced number of parameters, that can learn high complex lighting scenarios from real-world high-dynamic-range (HDR) environment images. We show in the experiments that the CNN architecture can predict the environment lighting with an average mean squared error (MSE) of \num{7.85e-04} when comparing SH lighting coefficients. We validate our model in a variety of mixed reality scenarios. Furthermore, we present qualitative results comparing relights of real-world scenes.
Age Range Estimation using MTCNN and VGG-Face Model
Apr 17, 2021


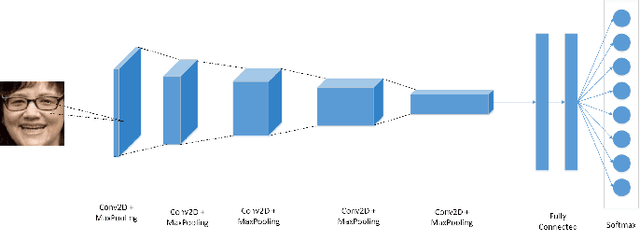
The Convolutional Neural Network has amazed us with its usage on several applications. Age range estimation using CNN is emerging due to its application in myriad of areas which makes it a state-of-the-art area for research and improve the estimation accuracy. A deep CNN model is used for identification of people's age range in our proposed work. At first, we extracted only face images from image dataset using MTCNN to remove unnecessary features other than face from the image. Secondly, we used random crop technique for data augmentation to improve the model performance. We have used the concept of transfer learning in our research. A pretrained face recognition model i.e VGG-Face is used to build our model for identification of age range whose performance is evaluated on Adience Benchmark for confirming the efficacy of our work. The performance in test set outperformed existing state-of-the-art by substantial margins.
* 6 pages, 10 figures
Multimodal Contrastive Training for Visual Representation Learning
Apr 26, 2021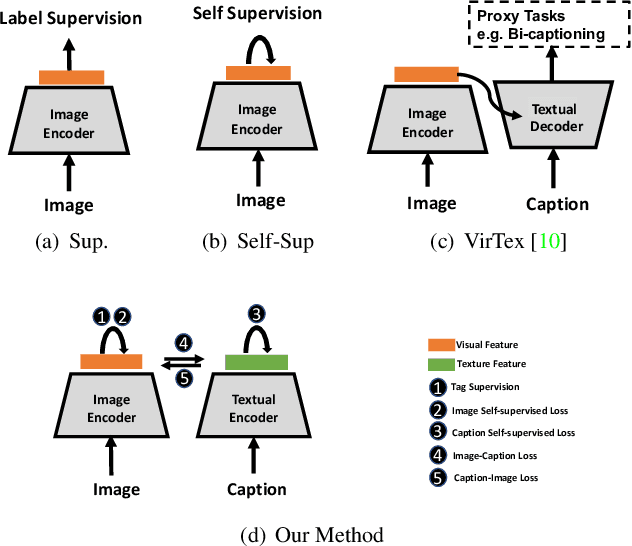
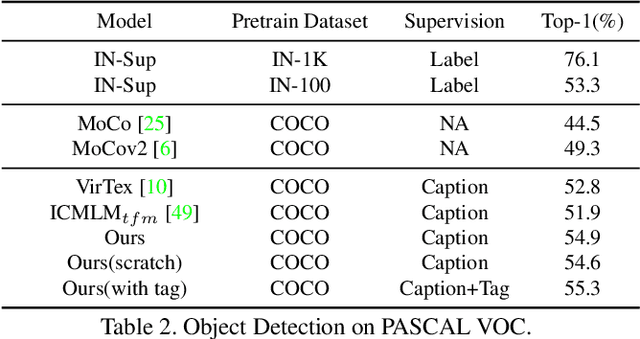
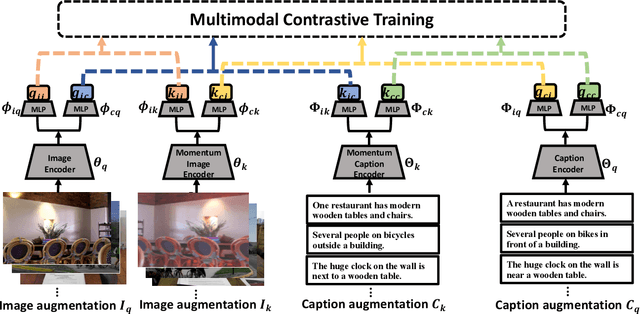
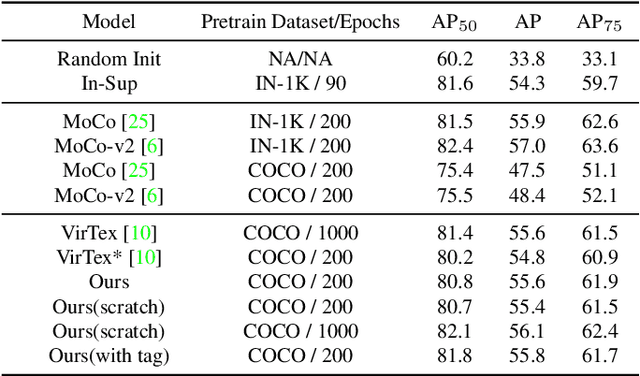
We develop an approach to learning visual representations that embraces multimodal data, driven by a combination of intra- and inter-modal similarity preservation objectives. Unlike existing visual pre-training methods, which solve a proxy prediction task in a single domain, our method exploits intrinsic data properties within each modality and semantic information from cross-modal correlation simultaneously, hence improving the quality of learned visual representations. By including multimodal training in a unified framework with different types of contrastive losses, our method can learn more powerful and generic visual features. We first train our model on COCO and evaluate the learned visual representations on various downstream tasks including image classification, object detection, and instance segmentation. For example, the visual representations pre-trained on COCO by our method achieve state-of-the-art top-1 validation accuracy of $55.3\%$ on ImageNet classification, under the common transfer protocol. We also evaluate our method on the large-scale Stock images dataset and show its effectiveness on multi-label image tagging, and cross-modal retrieval tasks.
AGD-Autoencoder: Attention Gated Deep Convolutional Autoencoder for Brain Tumor Segmentation
Jul 07, 2021Brain tumor segmentation is a challenging problem in medical image analysis. The endpoint is to generate the salient masks that accurately identify brain tumor regions in an fMRI screening. In this paper, we propose a novel attention gate (AG model) for brain tumor segmentation that utilizes both the edge detecting unit and the attention gated network to highlight and segment the salient regions from fMRI images. This feature enables us to eliminate the necessity of having to explicitly point towards the damaged area(external tissue localization) and classify(classification) as per classical computer vision techniques. AGs can easily be integrated within the deep convolutional neural networks(CNNs). Minimal computional overhead is required while the AGs increase the sensitivity scores significantly. We show that the edge detector along with an attention gated mechanism provide a sufficient enough method for brain segmentation reaching an IOU of 0.78
Kanerva++: extending The Kanerva Machine with differentiable, locally block allocated latent memory
Mar 16, 2021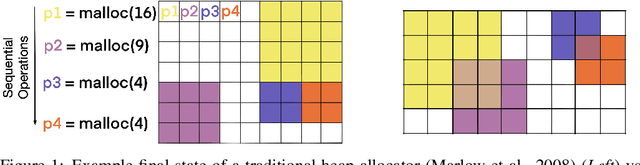
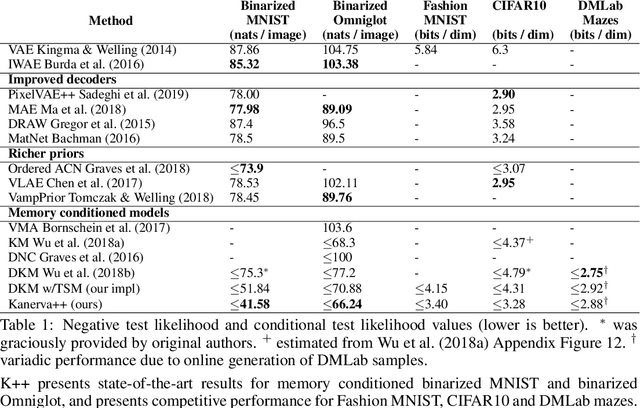
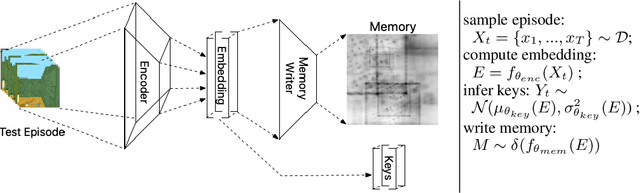
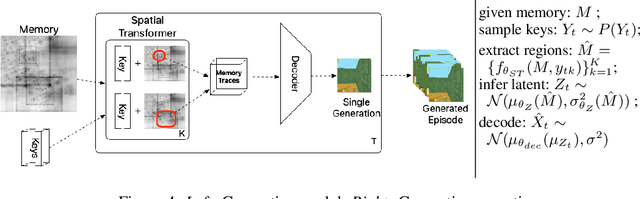
Episodic and semantic memory are critical components of the human memory model. The theory of complementary learning systems (McClelland et al., 1995) suggests that the compressed representation produced by a serial event (episodic memory) is later restructured to build a more generalized form of reusable knowledge (semantic memory). In this work we develop a new principled Bayesian memory allocation scheme that bridges the gap between episodic and semantic memory via a hierarchical latent variable model. We take inspiration from traditional heap allocation and extend the idea of locally contiguous memory to the Kanerva Machine, enabling a novel differentiable block allocated latent memory. In contrast to the Kanerva Machine, we simplify the process of memory writing by treating it as a fully feed forward deterministic process, relying on the stochasticity of the read key distribution to disperse information within the memory. We demonstrate that this allocation scheme improves performance in memory conditional image generation, resulting in new state-of-the-art conditional likelihood values on binarized MNIST (<=41.58 nats/image) , binarized Omniglot (<=66.24 nats/image), as well as presenting competitive performance on CIFAR10, DMLab Mazes, Celeb-A and ImageNet32x32.
System Matrix based Reconstruction for Pulsed Sequences in Magnetic Particle Imaging
Aug 23, 2021
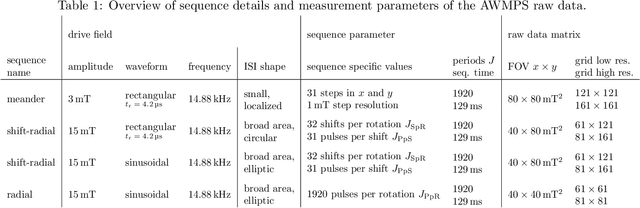
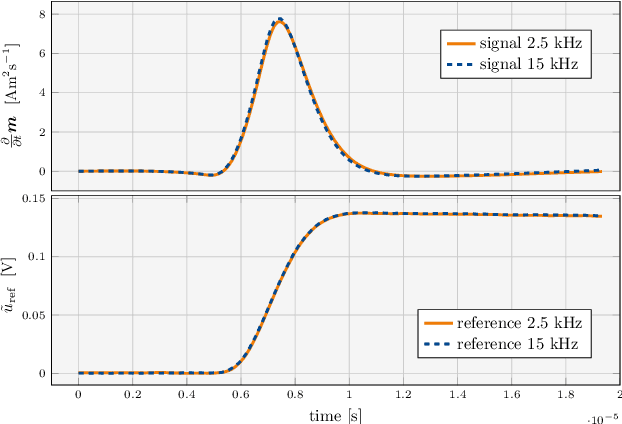
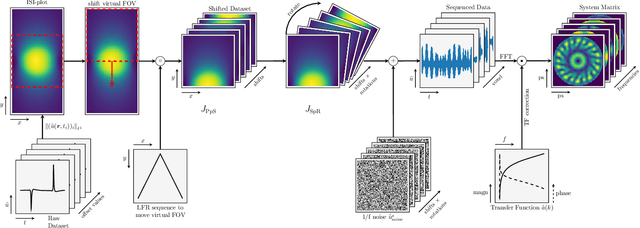
Improving resolution and sensitivity will widen possible medical applications of magnetic particle imaging in its clinical application. Pulsed excitation promises such benefits, at the cost of more complex hardware solutions and restrictions on drive field amplitude and frequency. In this work, a sequence is proposed, that combines high drive-field amplitudes and high frequency rectangular excitation. State of the art systems utilize a sinusoidal excitation to drive superparamagnetic nanoparticles into the non-linear part of their magnetization curve, which creates a spectrum with a clear separation of direct feed-through and higher harmonics caused by the particles response. One challenge for rectangular excitation is the discrimination of particle and excitation signals, both broad-band. Another is the drive-field sequence itself, as particles that are not placed at the same spatial position, may react simultaneously and are not separable by their signals phase or signal shape. This loss of information in spatial encoding is overcome in this work by utilizing a superposition of shifting fields and drive-field rotations. The software framework developed for this work processes measured data from an Arbitrary Waveform Magnetic Particle Spectrometer, which is calibrated to guarantee device independence. Multiple sequence types and waveforms are compared, based on frequency space image reconstruction from emulated signals, that are derived from these measured particle responses. A resolution of 1.0 mT (0.8 mm for a gradient of (-1.25,-1.25,2.5) T/m) in x- and y-direction was achieved and a superior sensitivity was detected on the basis of reference phantoms for the proposed sequence in this work.