 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
You Only Look Bottom-Up for Monocular 3D Object Detection
Jan 27, 2024
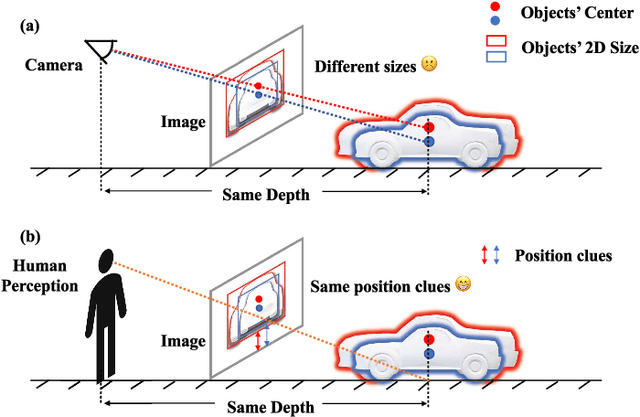
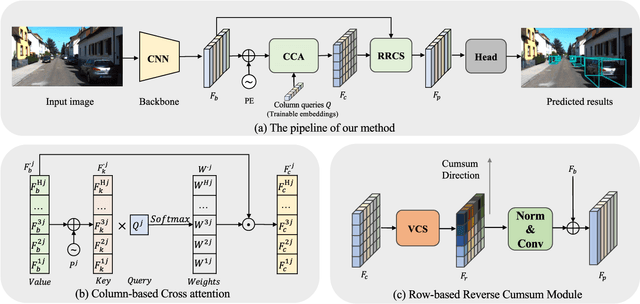
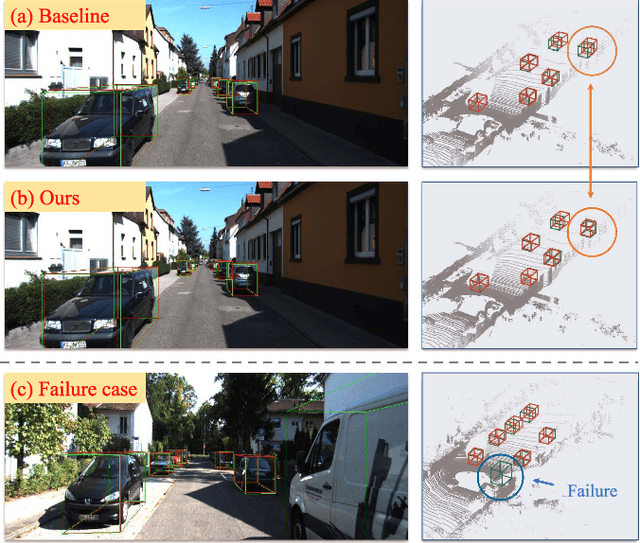
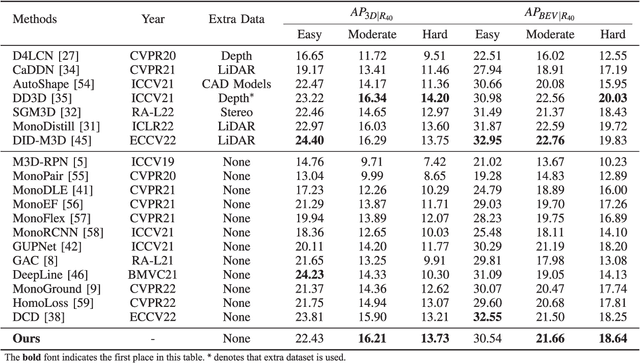
Monocular 3D Object Detection is an essential task for autonomous driving. Meanwhile, accurate 3D object detection from pure images is very challenging due to the loss of depth information. Most existing image-based methods infer objects' location in 3D space based on their 2D sizes on the image plane, which usually ignores the intrinsic position clues from images, leading to unsatisfactory performances. Motivated by the fact that humans could leverage the bottom-up positional clues to locate objects in 3D space from a single image, in this paper, we explore the position modeling from the image feature column and propose a new method named You Only Look Bottum-Up (YOLOBU). Specifically, our YOLOBU leverages Column-based Cross Attention to determine how much a pixel contributes to pixels above it. Next, the Row-based Reverse Cumulative Sum (RRCS) is introduced to build the connections of pixels in the bottom-up direction. Our YOLOBU fully explores the position clues for monocular 3D detection via building the relationship of pixels from the bottom-up way. Extensive experiments on the KITTI dataset demonstrate the effectiveness and superiority of our method.
Memory-Inspired Temporal Prompt Interaction for Text-Image Classification
Jan 26, 2024In recent years, large-scale pre-trained multimodal models (LMM) generally emerge to integrate the vision and language modalities, achieving considerable success in various natural language processing and computer vision tasks. The growing size of LMMs, however, results in a significant computational cost for fine-tuning these models for downstream tasks. Hence, prompt-based interaction strategy is studied to align modalities more efficiently. In this contex, we propose a novel prompt-based multimodal interaction strategy inspired by human memory strategy, namely Memory-Inspired Temporal Prompt Interaction (MITP). Our proposed method involves in two stages as in human memory strategy: the acquiring stage, and the consolidation and activation stage. We utilize temporal prompts on intermediate layers to imitate the acquiring stage, leverage similarity-based prompt interaction to imitate memory consolidation, and employ prompt generation strategy to imitate memory activation. The main strength of our paper is that we interact the prompt vectors on intermediate layers to leverage sufficient information exchange between modalities, with compressed trainable parameters and memory usage. We achieve competitive results on several datasets with relatively small memory usage and 2.0M of trainable parameters (about 1% of the pre-trained foundation model).
Segment Anything Model for Medical Image Segmentation: Current Applications and Future Directions
Jan 07, 2024Due to the inherent flexibility of prompting, foundation models have emerged as the predominant force in the fields of natural language processing and computer vision. The recent introduction of the Segment Anything Model (SAM) signifies a noteworthy expansion of the prompt-driven paradigm into the domain of image segmentation, thereby introducing a plethora of previously unexplored capabilities. However, the viability of its application to medical image segmentation remains uncertain, given the substantial distinctions between natural and medical images. In this work, we provide a comprehensive overview of recent endeavors aimed at extending the efficacy of SAM to medical image segmentation tasks, encompassing both empirical benchmarking and methodological adaptations. Additionally, we explore potential avenues for future research directions in SAM's role within medical image segmentation. While direct application of SAM to medical image segmentation does not yield satisfactory performance on multi-modal and multi-target medical datasets so far, numerous insights gleaned from these efforts serve as valuable guidance for shaping the trajectory of foundational models in the realm of medical image analysis. To support ongoing research endeavors, we maintain an active repository that contains an up-to-date paper list and a succinct summary of open-source projects at https://github.com/YichiZhang98/SAM4MIS.
DiffMorph: Text-less Image Morphing with Diffusion Models
Jan 01, 2024Text-conditioned image generation models are a prevalent use of AI image synthesis, yet intuitively controlling output guided by an artist remains challenging. Current methods require multiple images and textual prompts for each object to specify them as concepts to generate a single customized image. On the other hand, our work, \verb|DiffMorph|, introduces a novel approach that synthesizes images that mix concepts without the use of textual prompts. Our work integrates a sketch-to-image module to incorporate user sketches as input. \verb|DiffMorph| takes an initial image with conditioning artist-drawn sketches to generate a morphed image. We employ a pre-trained text-to-image diffusion model and fine-tune it to reconstruct each image faithfully. We seamlessly merge images and concepts from sketches into a cohesive composition. The image generation capability of our work is demonstrated through our results and a comparison of these with prompt-based image generation.
Rendering Graphs for Graph Reasoning in Multimodal Large Language Models
Feb 03, 2024Large Language Models (LLMs) are increasingly used for various tasks with graph structures, such as robotic planning, knowledge graph completion, and common-sense reasoning. Though LLMs can comprehend graph information in a textual format, they overlook the rich visual modality, which is an intuitive way for humans to comprehend structural information and conduct graph reasoning. The potential benefits and capabilities of representing graph structures as visual images (i.e., visual graph) is still unexplored. In this paper, we take the first step in incorporating visual information into graph reasoning tasks and propose a new benchmark GITQA, where each sample is a tuple (graph, image, textual description). We conduct extensive experiments on the GITQA benchmark using state-of-the-art multimodal LLMs. Results on graph reasoning tasks show that combining textual and visual information together performs better than using one modality alone. Moreover, the LLaVA-7B/13B models finetuned on the training set achieve higher accuracy than the closed-source model GPT-4(V). We also study the effects of augmentations in graph reasoning.
Separable Multi-Concept Erasure from Diffusion Models
Feb 03, 2024Large-scale diffusion models, known for their impressive image generation capabilities, have raised concerns among researchers regarding social impacts, such as the imitation of copyrighted artistic styles. In response, existing approaches turn to machine unlearning techniques to eliminate unsafe concepts from pre-trained models. However, these methods compromise the generative performance and neglect the coupling among multi-concept erasures, as well as the concept restoration problem. To address these issues, we propose a Separable Multi-concept Eraser (SepME), which mainly includes two parts: the generation of concept-irrelevant representations and the weight decoupling. The former aims to avoid unlearning substantial information that is irrelevant to forgotten concepts. The latter separates optimizable model weights, making each weight increment correspond to a specific concept erasure without affecting generative performance on other concepts. Specifically, the weight increment for erasing a specified concept is formulated as a linear combination of solutions calculated based on other known undesirable concepts. Extensive experiments indicate the efficacy of our approach in eliminating concepts, preserving model performance, and offering flexibility in the erasure or recovery of various concepts.
Towards Visual Syntactical Understanding
Jan 30, 2024Syntax is usually studied in the realm of linguistics and refers to the arrangement of words in a sentence. Similarly, an image can be considered as a visual 'sentence', with the semantic parts of the image acting as 'words'. While visual syntactic understanding occurs naturally to humans, it is interesting to explore whether deep neural networks (DNNs) are equipped with such reasoning. To that end, we alter the syntax of natural images (e.g. swapping the eye and nose of a face), referred to as 'incorrect' images, to investigate the sensitivity of DNNs to such syntactic anomaly. Through our experiments, we discover an intriguing property of DNNs where we observe that state-of-the-art convolutional neural networks, as well as vision transformers, fail to discriminate between syntactically correct and incorrect images when trained on only correct ones. To counter this issue and enable visual syntactic understanding with DNNs, we propose a three-stage framework- (i) the 'words' (or the sub-features) in the image are detected, (ii) the detected words are sequentially masked and reconstructed using an autoencoder, (iii) the original and reconstructed parts are compared at each location to determine syntactic correctness. The reconstruction module is trained with BERT-like masked autoencoding for images, with the motivation to leverage language model inspired training to better capture the syntax. Note, our proposed approach is unsupervised in the sense that the incorrect images are only used during testing and the correct versus incorrect labels are never used for training. We perform experiments on CelebA, and AFHQ datasets and obtain classification accuracy of 92.10%, and 90.89%, respectively. Notably, the approach generalizes well to ImageNet samples which share common classes with CelebA and AFHQ without explicitly training on them.
AGG: Amortized Generative 3D Gaussians for Single Image to 3D
Jan 08, 2024Given the growing need for automatic 3D content creation pipelines, various 3D representations have been studied to generate 3D objects from a single image. Due to its superior rendering efficiency, 3D Gaussian splatting-based models have recently excelled in both 3D reconstruction and generation. 3D Gaussian splatting approaches for image to 3D generation are often optimization-based, requiring many computationally expensive score-distillation steps. To overcome these challenges, we introduce an Amortized Generative 3D Gaussian framework (AGG) that instantly produces 3D Gaussians from a single image, eliminating the need for per-instance optimization. Utilizing an intermediate hybrid representation, AGG decomposes the generation of 3D Gaussian locations and other appearance attributes for joint optimization. Moreover, we propose a cascaded pipeline that first generates a coarse representation of the 3D data and later upsamples it with a 3D Gaussian super-resolution module. Our method is evaluated against existing optimization-based 3D Gaussian frameworks and sampling-based pipelines utilizing other 3D representations, where AGG showcases competitive generation abilities both qualitatively and quantitatively while being several orders of magnitude faster. Project page: https://ir1d.github.io/AGG/
Data-Agnostic Face Image Synthesis Detection Using Bayesian CNNs
Jan 08, 2024Face image synthesis detection is considerably gaining attention because of the potential negative impact on society that this type of synthetic data brings. In this paper, we propose a data-agnostic solution to detect the face image synthesis process. Specifically, our solution is based on an anomaly detection framework that requires only real data to learn the inference process. It is therefore data-agnostic in the sense that it requires no synthetic face images. The solution uses the posterior probability with respect to the reference data to determine if new samples are synthetic or not. Our evaluation results using different synthesizers show that our solution is very competitive against the state-of-the-art, which requires synthetic data for training.
UP-CrackNet: Unsupervised Pixel-Wise Road Crack Detection via Adversarial Image Restoration
Jan 28, 2024Over the past decade, automated methods have been developed to detect cracks more efficiently, accurately, and objectively, with the ultimate goal of replacing conventional manual visual inspection techniques. Among these methods, semantic segmentation algorithms have demonstrated promising results in pixel-wise crack detection tasks. However, training such data-driven algorithms requires a large amount of human-annotated datasets with pixel-level annotations, which is a highly labor-intensive and time-consuming process. Moreover, supervised learning-based methods often struggle with poor generalization ability in unseen datasets. Therefore, we propose an unsupervised pixel-wise road crack detection network, known as UP-CrackNet. Our approach first generates multi-scale square masks and randomly selects them to corrupt undamaged road images by removing certain regions. Subsequently, a generative adversarial network is trained to restore the corrupted regions by leveraging the semantic context learned from surrounding uncorrupted regions. During the testing phase, an error map is generated by calculating the difference between the input and restored images, which allows for pixel-wise crack detection. Our comprehensive experimental results demonstrate that UP-CrackNet outperforms other general-purpose unsupervised anomaly detection algorithms, and exhibits comparable performance and superior generalizability when compared with state-of-the-art supervised crack segmentation algorithms. Our source code is publicly available at mias.group/UP-CrackNet.