 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SESF-Fuse: An Unsupervised Deep Model for Multi-Focus Image Fusion
Aug 21, 2019
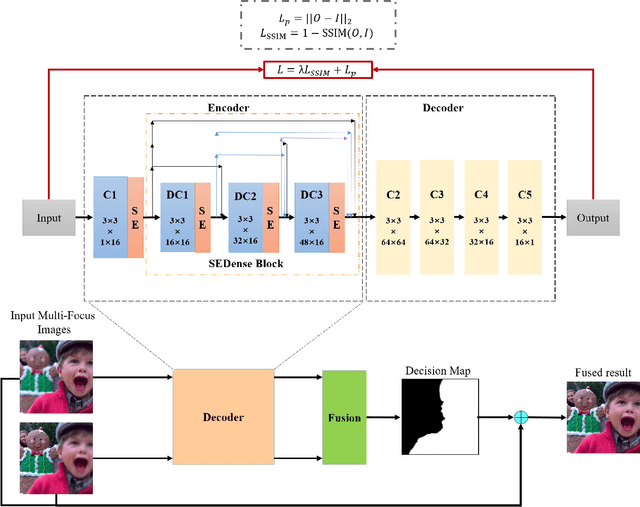
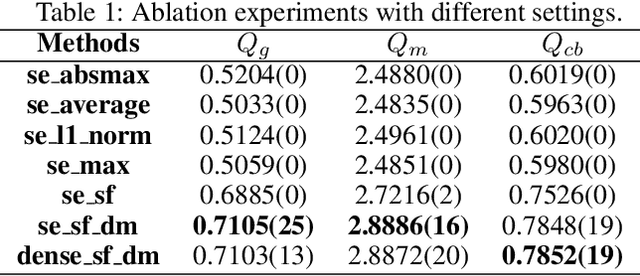
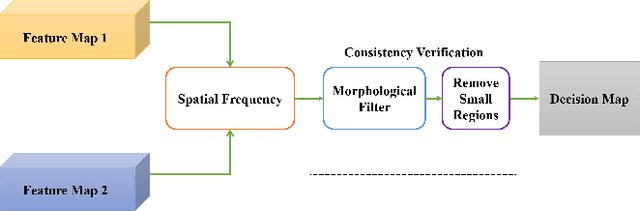
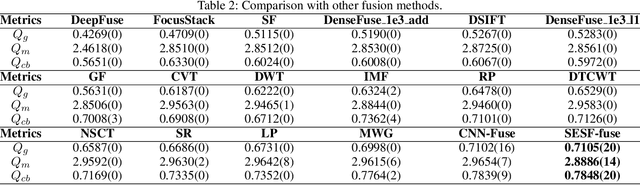
In this work, we propose a novel unsupervised deep learning model to address multi-focus image fusion problem. First, we train an encoder-decoder network in unsupervised manner to acquire deep feature of input images. And then we utilize these features and spatial frequency to measure activity level and decision map. Finally, we apply some consistency verification methods to adjust the decision map and draw out fused result. The key point behind of proposed method is that only the objects within the depth-of-field (DOF) have sharp appearance in the photograph while other objects are likely to be blurred. In contrast to previous works, our method analyzes sharp appearance in deep feature instead of original image. Experimental results demonstrate that the proposed method achieves the state-of-art fusion performance compared to existing 16 fusion methods in objective and subjective assessment.
End-to-End Pseudo-LiDAR for Image-Based 3D Object Detection
Apr 07, 2020
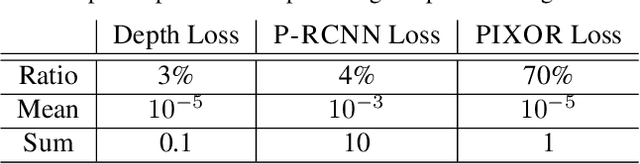
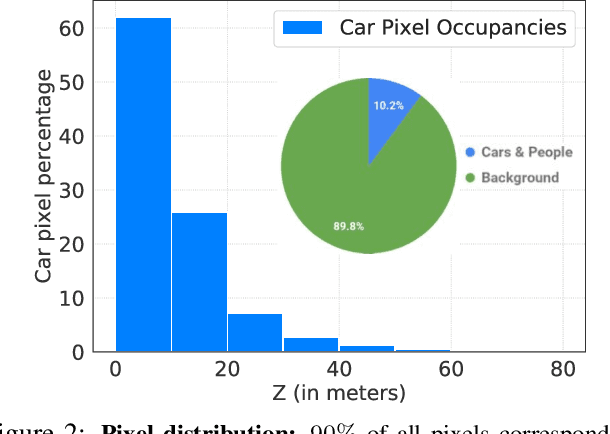
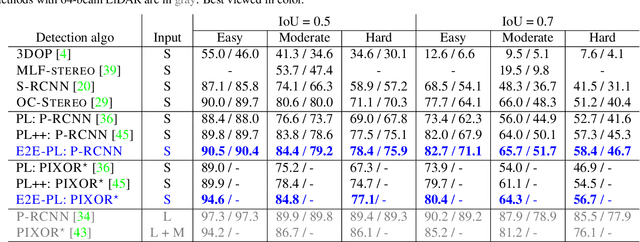
Reliable and accurate 3D object detection is a necessity for safe autonomous driving. Although LiDAR sensors can provide accurate 3D point cloud estimates of the environment, they are also prohibitively expensive for many settings. Recently, the introduction of pseudo-LiDAR (PL) has led to a drastic reduction in the accuracy gap between methods based on LiDAR sensors and those based on cheap stereo cameras. PL combines state-of-the-art deep neural networks for 3D depth estimation with those for 3D object detection by converting 2D depth map outputs to 3D point cloud inputs. However, so far these two networks have to be trained separately. In this paper, we introduce a new framework based on differentiable Change of Representation (CoR) modules that allow the entire PL pipeline to be trained end-to-end. The resulting framework is compatible with most state-of-the-art networks for both tasks and in combination with PointRCNN improves over PL consistently across all benchmarks -- yielding the highest entry on the KITTI image-based 3D object detection leaderboard at the time of submission. Our code will be made available at https://github.com/mileyan/pseudo-LiDAR_e2e.
DiaRet: A browser-based application for the grading of Diabetic Retinopathy with Integrated Gradients
Mar 16, 2021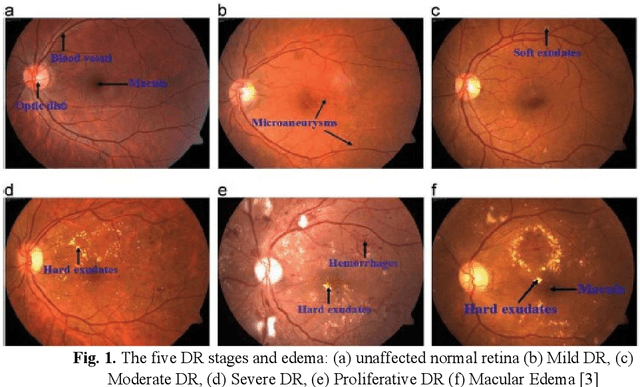



Diabetes is a metabolic disorder that results from defects in autoimmune beta-cell destruction in Type 1, peripheral resistance to insulin action in Type 2 or, most commonly, both. Patients with long-standing diabetes often fall prey to Diabetic Retinopathy (DR) resulting in changes in the retina of the human eye, which may lead to loss of vision in extreme cases. The aim of this study is two-fold: (a) create deep learning models that were trained to grade degraded retinal fundus images and (b) to create a browser-based application that will aid in diagnostic procedures by highlighting the key features of the fundus image. Deep learning has proven to be a success for computer-aided DR diagnosis resulting in early-detection and prevention of blindness. In this research work, we have emulated the images plagued by distortions by degrading the images based on multiple different combinations of Light Transmission Disturbance, Image Blurring and insertion of Retinal Artifacts. These degraded images were used for the training of multiple Deep Learning based Convolutional Neural Networks. We have trained InceptionV3, ResNet-50 and InceptionResNetV2 on multiple datasets. The models were used to classify retinal fundus images based on their severity level and then further used in the creation of a browser-based application, which demonstrates the models prediction and the probability associated with each class. It will also show the Integration Gradient (IG) Attribution Mask superimposed onto the input image. The creation of the browser-based application would aid in the diagnostic procedures performed by ophthalmologists by highlighting the key features of the fundus image based on an educated prediction made by the model.
SPARK: SPAcecraft Recognition leveraging Knowledge of Space Environment
Apr 13, 2021
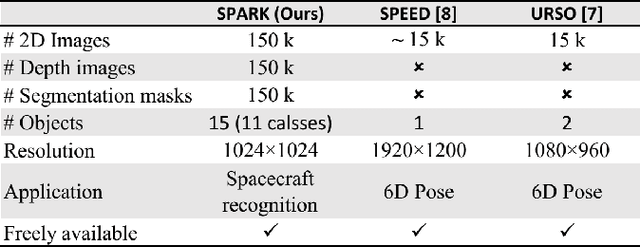
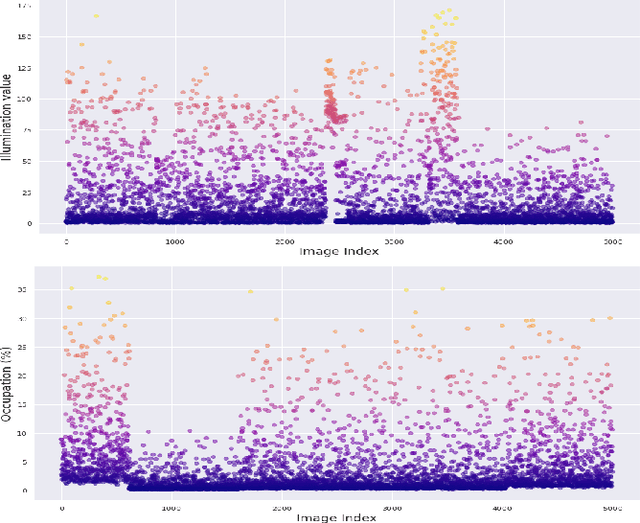
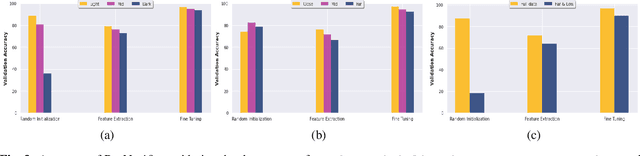
This paper proposes the SPARK dataset as a new unique space object multi-modal image dataset. Image-based object recognition is an important component of Space Situational Awareness, especially for applications such as on-orbit servicing, active debris removal, and satellite formation. However, the lack of sufficient annotated space data has limited research efforts in developing data-driven spacecraft recognition approaches. The SPARK dataset has been generated under a realistic space simulation environment, with a large diversity in sensing conditions for different orbital scenarios. It provides about 150k images per modality, RGB and depth, and 11 classes for spacecrafts and debris. This dataset offers an opportunity to benchmark and further develop object recognition, classification and detection algorithms, as well as multi-modal RGB-Depth approaches under space sensing conditions. Preliminary experimental evaluation validates the relevance of the data, and highlights interesting challenging scenarios specific to the space environment.
Dealing with Missing Modalities in the Visual Question Answer-Difference Prediction Task through Knowledge Distillation
Apr 13, 2021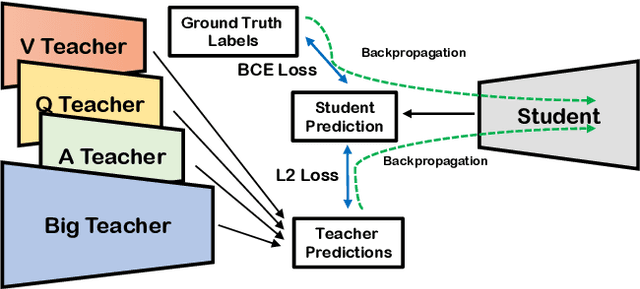

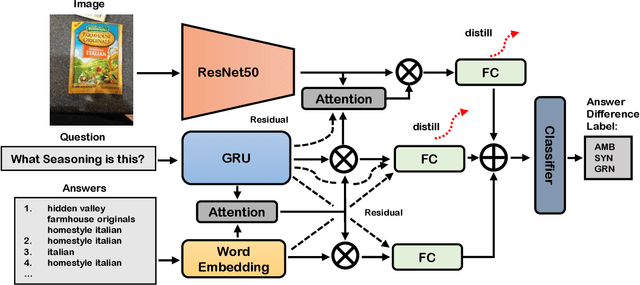
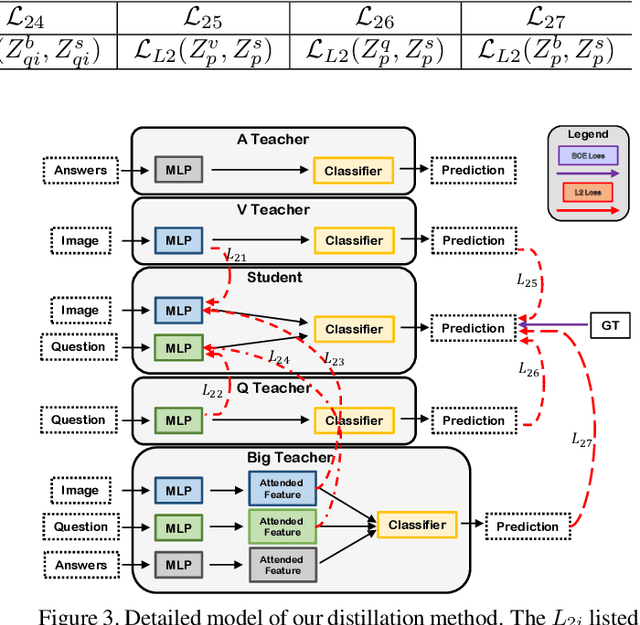
In this work, we address the issues of missing modalities that have arisen from the Visual Question Answer-Difference prediction task and find a novel method to solve the task at hand. We address the missing modality-the ground truth answers-that are not present at test time and use a privileged knowledge distillation scheme to deal with the issue of the missing modality. In order to efficiently do so, we first introduce a model, the "Big" Teacher, that takes the image/question/answer triplet as its input and outperforms the baseline, then use a combination of models to distill knowledge to a target network (student) that only takes the image/question pair as its inputs. We experiment our models on the VizWiz and VQA-V2 Answer Difference datasets and show through extensive experimentation and ablation the performances of our method and a diverse possibility for future research.
Locally Enhanced Self-Attention: Rethinking Self-Attention as Local and Context Terms
Jul 12, 2021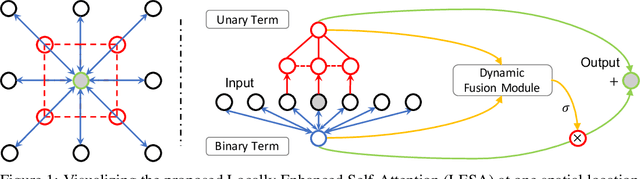

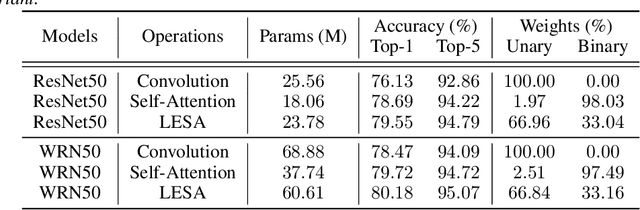

Self-Attention has become prevalent in computer vision models. Inspired by fully connected Conditional Random Fields (CRFs), we decompose it into local and context terms. They correspond to the unary and binary terms in CRF and are implemented by attention mechanisms with projection matrices. We observe that the unary terms only make small contributions to the outputs, and meanwhile standard CNNs that rely solely on the unary terms achieve great performances on a variety of tasks. Therefore, we propose Locally Enhanced Self-Attention (LESA), which enhances the unary term by incorporating it with convolutions, and utilizes a fusion module to dynamically couple the unary and binary operations. In our experiments, we replace the self-attention modules with LESA. The results on ImageNet and COCO show the superiority of LESA over convolution and self-attention baselines for the tasks of image recognition, object detection, and instance segmentation. The code is made publicly available.
Resonant tunnelling diode nano-optoelectronic spiking nodes for neuromorphic information processing
Jul 21, 2021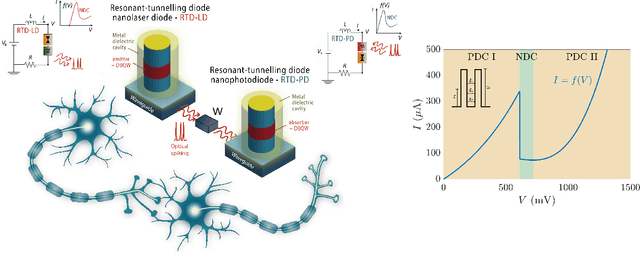
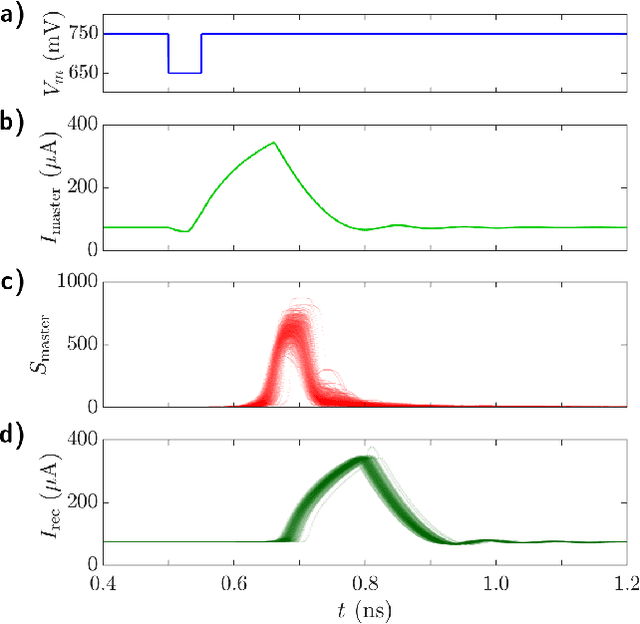
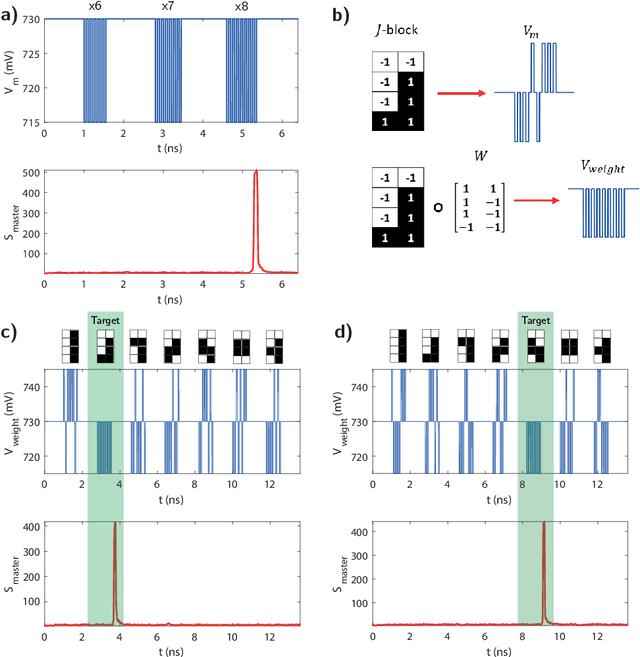
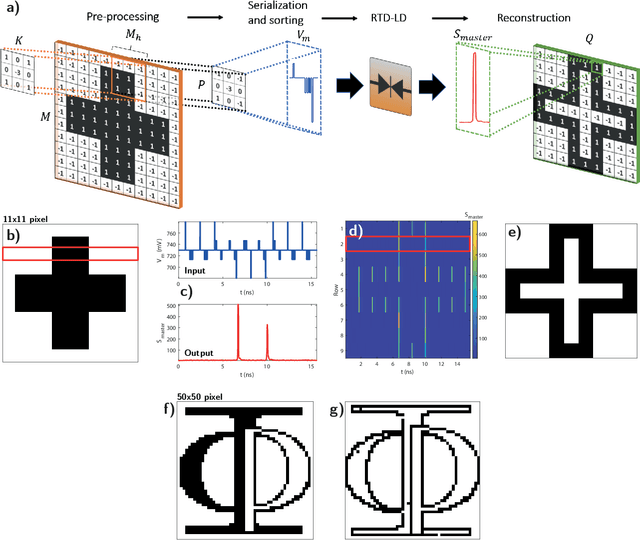
In this work, we introduce an optoelectronic spiking artificial neuron capable of operating at ultrafast rates ($\approx$ 100 ps/optical spike) and with low energy consumption ($<$ pJ/spike). The proposed system combines an excitable resonant tunnelling diode (RTD) element exhibiting negative differential conductance, coupled to a nanoscale light source (forming a master node) or a photodetector (forming a receiver node). We study numerically the spiking dynamical responses and information propagation functionality of an interconnected master-receiver RTD node system. Using the key functionality of pulse thresholding and integration, we utilize a single node to classify sequential pulse patterns and perform convolutional functionality for image feature (edge) recognition. We also demonstrate an optically-interconnected spiking neural network model for processing of spatiotemporal data at over 10 Gbps with high inference accuracy. Finally, we demonstrate an off-chip supervised learning approach utilizing spike-timing dependent plasticity for the RTD-enabled photonic spiking neural network. These results demonstrate the potential and viability of RTD spiking nodes for low footprint, low energy, high-speed optoelectronic realization of neuromorphic hardware.
Photon-Starved Scene Inference using Single Photon Cameras
Jul 29, 2021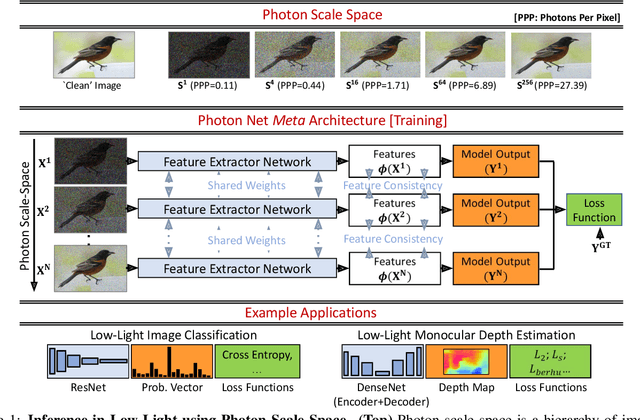



Scene understanding under low-light conditions is a challenging problem. This is due to the small number of photons captured by the camera and the resulting low signal-to-noise ratio (SNR). Single-photon cameras (SPCs) are an emerging sensing modality that are capable of capturing images with high sensitivity. Despite having minimal read-noise, images captured by SPCs in photon-starved conditions still suffer from strong shot noise, preventing reliable scene inference. We propose photon scale-space a collection of high-SNR images spanning a wide range of photons-per-pixel (PPP) levels (but same scene content) as guides to train inference model on low photon flux images. We develop training techniques that push images with different illumination levels closer to each other in feature representation space. The key idea is that having a spectrum of different brightness levels during training enables effective guidance, and increases robustness to shot noise even in extreme noise cases. Based on the proposed approach, we demonstrate, via simulations and real experiments with a SPAD camera, high-performance on various inference tasks such as image classification and monocular depth estimation under ultra low-light, down to < 1 PPP.
Token Shift Transformer for Video Classification
Aug 05, 2021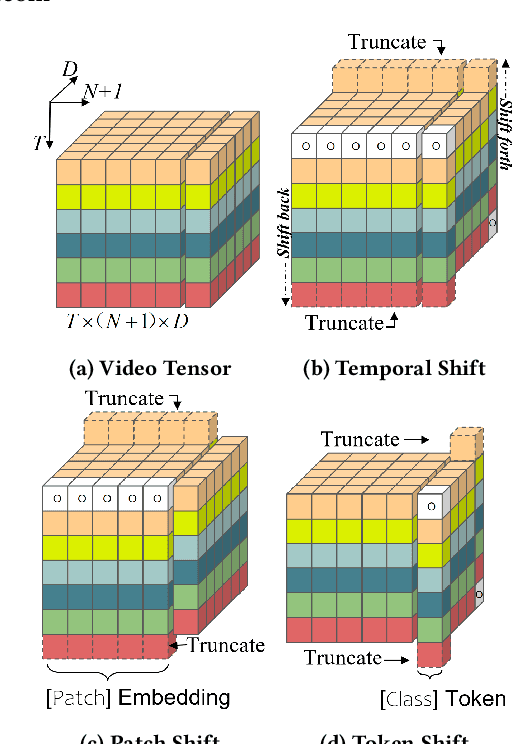
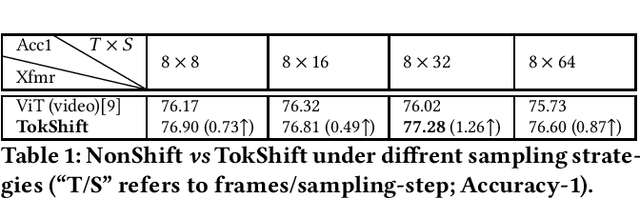
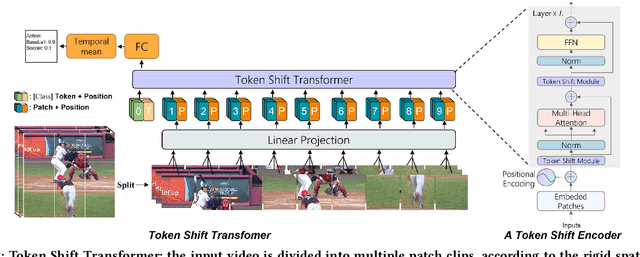
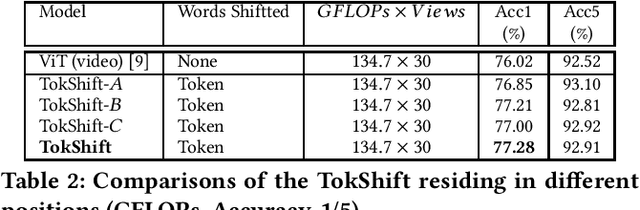
Transformer achieves remarkable successes in understanding 1 and 2-dimensional signals (e.g., NLP and Image Content Understanding). As a potential alternative to convolutional neural networks, it shares merits of strong interpretability, high discriminative power on hyper-scale data, and flexibility in processing varying length inputs. However, its encoders naturally contain computational intensive operations such as pair-wise self-attention, incurring heavy computational burden when being applied on the complex 3-dimensional video signals. This paper presents Token Shift Module (i.e., TokShift), a novel, zero-parameter, zero-FLOPs operator, for modeling temporal relations within each transformer encoder. Specifically, the TokShift barely temporally shifts partial [Class] token features back-and-forth across adjacent frames. Then, we densely plug the module into each encoder of a plain 2D vision transformer for learning 3D video representation. It is worth noticing that our TokShift transformer is a pure convolutional-free video transformer pilot with computational efficiency for video understanding. Experiments on standard benchmarks verify its robustness, effectiveness, and efficiency. Particularly, with input clips of 8/12 frames, the TokShift transformer achieves SOTA precision: 79.83%/80.40% on the Kinetics-400, 66.56% on EGTEA-Gaze+, and 96.80% on UCF-101 datasets, comparable or better than existing SOTA convolutional counterparts. Our code is open-sourced in: https://github.com/VideoNetworks/TokShift-Transformer.
Fed-TGAN: Federated Learning Framework for Synthesizing Tabular Data
Aug 18, 2021
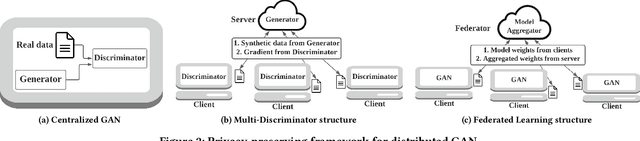
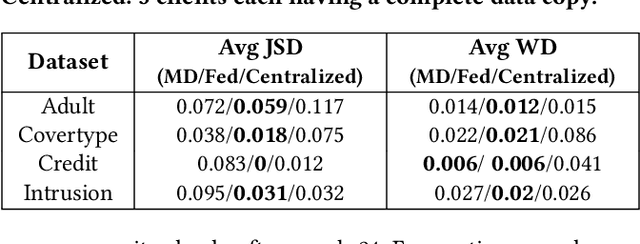
Generative Adversarial Networks (GANs) are typically trained to synthesize data, from images and more recently tabular data, under the assumption of directly accessible training data. Recently, federated learning (FL) is an emerging paradigm that features decentralized learning on client's local data with a privacy-preserving capability. And, while learning GANs to synthesize images on FL systems has just been demonstrated, it is unknown if GANs for tabular data can be learned from decentralized data sources. Moreover, it remains unclear which distributed architecture suits them best. Different from image GANs, state-of-the-art tabular GANs require prior knowledge on the data distribution of each (discrete and continuous) column to agree on a common encoding -- risking privacy guarantees. In this paper, we propose Fed-TGAN, the first Federated learning framework for Tabular GANs. To effectively learn a complex tabular GAN on non-identical participants, Fed-TGAN designs two novel features: (i) a privacy-preserving multi-source feature encoding for model initialization; and (ii) table similarity aware weighting strategies to aggregate local models for countering data skew. We extensively evaluate the proposed Fed-TGAN against variants of decentralized learning architectures on four widely used datasets. Results show that Fed-TGAN accelerates training time per epoch up to 200% compared to the alternative architectures, for both IID and Non-IID data. Overall, Fed-TGAN not only stabilizes the training loss, but also achieves better similarity between generated and original data.