 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Stylish Image Description Generation via Domain Layer Norm
Sep 11, 2018

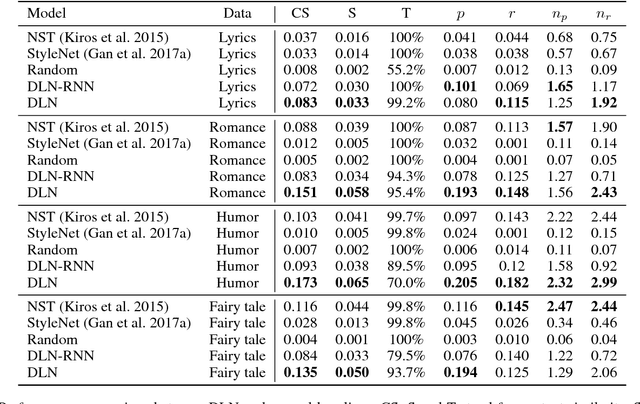
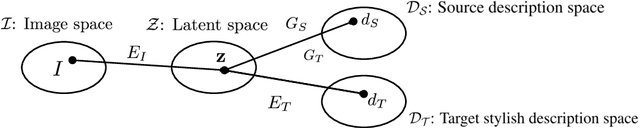
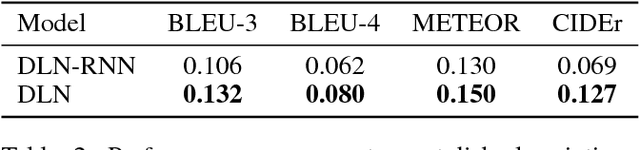
Most of the existing works on image description focus on generating expressive descriptions. The only few works that are dedicated to generating stylish (e.g., romantic, lyric, etc.) descriptions suffer from limited style variation and content digression. To address these limitations, we propose a controllable stylish image description generation model. It can learn to generate stylish image descriptions that are more related to image content and can be trained with the arbitrary monolingual corpus without collecting new paired image and stylish descriptions. Moreover, it enables users to generate various stylish descriptions by plugging in style-specific parameters to include new styles into the existing model. We achieve this capability via a novel layer normalization layer design, which we will refer to as the Domain Layer Norm (DLN). Extensive experimental validation and user study on various stylish image description generation tasks are conducted to show the competitive advantages of the proposed model.
Learning with Average Precision: Training Image Retrieval with a Listwise Loss
Jun 18, 2019
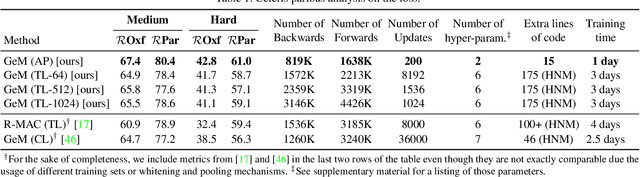
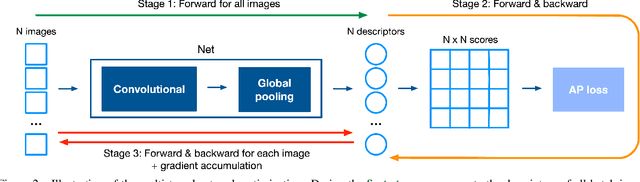
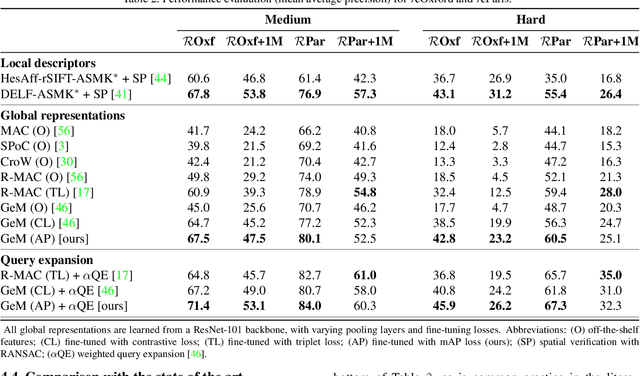
Image retrieval can be formulated as a ranking problem where the goal is to order database images by decreasing similarity to the query. Recent deep models for image retrieval have outperformed traditional methods by leveraging ranking-tailored loss functions, but important theoretical and practical problems remain. First, rather than directly optimizing the global ranking, they minimize an upper-bound on the essential loss, which does not necessarily result in an optimal mean average precision (mAP). Second, these methods require significant engineering efforts to work well, e.g. special pre-training and hard-negative mining. In this paper we propose instead to directly optimize the global mAP by leveraging recent advances in listwise loss formulations. Using a histogram binning approximation, the AP can be differentiated and thus employed to end-to-end learning. Compared to existing losses, the proposed method considers thousands of images simultaneously at each iteration and eliminates the need for ad hoc tricks. It also establishes a new state of the art on many standard retrieval benchmarks. Models and evaluation scripts have been made available at https://europe.naverlabs.com/Deep-Image-Retrieval/
Deep Co-Training for Semi-Supervised Image Segmentation
Mar 27, 2019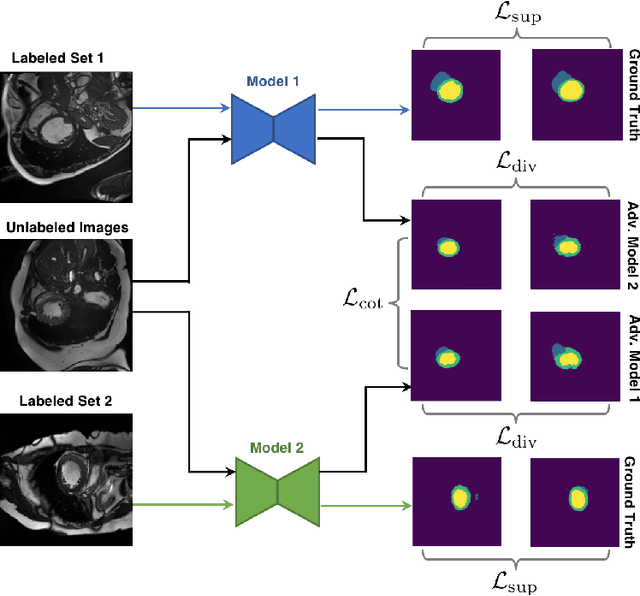
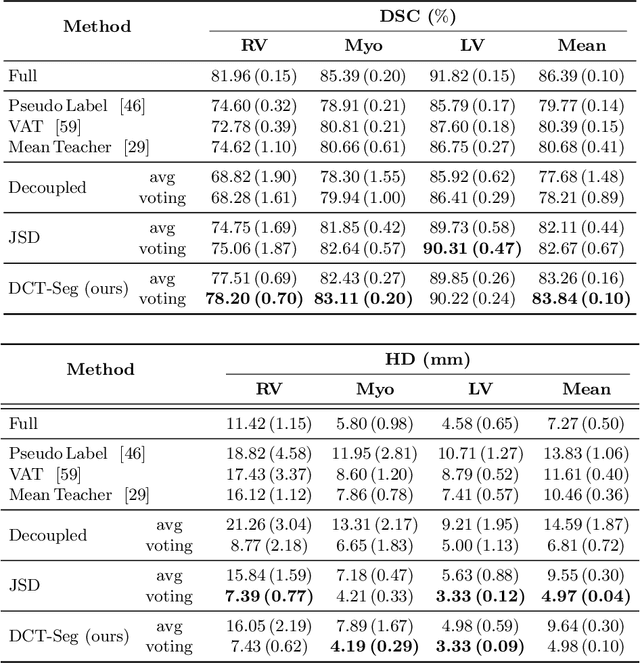

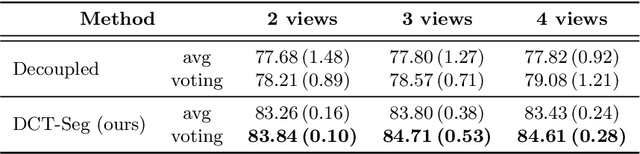
In this paper, we aim to improve the performance of semantic image segmentation in a semi-supervised setting in which training is effectuated with a reduced set of annotated images and additional non-annotated images. We present a method based on an ensemble of deep segmentation models. Each model is trained on a subset of the annotated data, and uses the non-annotated images to exchange information with the other models, similar to co-training. Even if each model learns on the same non-annotated images, diversity is preserved with the use of adversarial samples. Our results show that this ability to simultaneously train models, which exchange knowledge while preserving diversity, leads to state-of-the-art results on two challenging medical image datasets.
Differentiable Feature Selection, a Reparameterization Approach
Jul 21, 2021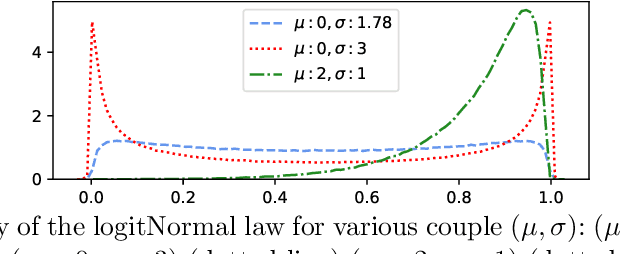
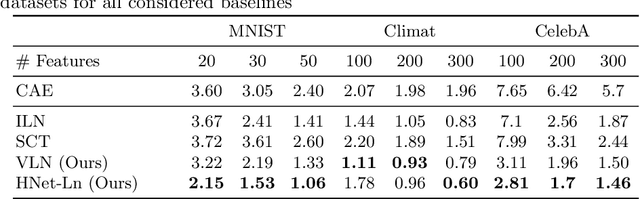
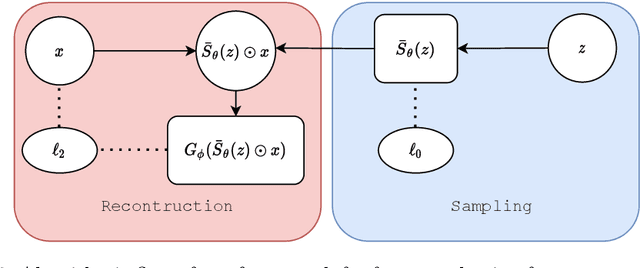
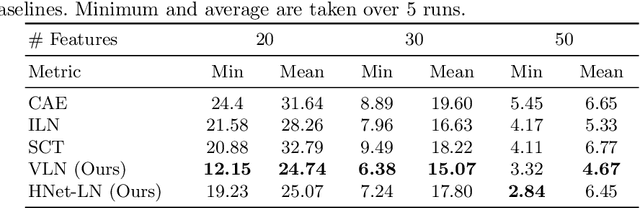
We consider the task of feature selection for reconstruction which consists in choosing a small subset of features from which whole data instances can be reconstructed. This is of particular importance in several contexts involving for example costly physical measurements, sensor placement or information compression. To break the intrinsic combinatorial nature of this problem, we formulate the task as optimizing a binary mask distribution enabling an accurate reconstruction. We then face two main challenges. One concerns differentiability issues due to the binary distribution. The second one corresponds to the elimination of redundant information by selecting variables in a correlated fashion which requires modeling the covariance of the binary distribution. We address both issues by introducing a relaxation of the problem via a novel reparameterization of the logitNormal distribution. We demonstrate that the proposed method provides an effective exploration scheme and leads to efficient feature selection for reconstruction through evaluation on several high dimensional image benchmarks. We show that the method leverages the intrinsic geometry of the data, facilitating reconstruction.
Anatomy-guided Multimodal Registration by Learning Segmentation without Ground Truth: Application to Intraprocedural CBCT/MR Liver Segmentation and Registration
Apr 14, 2021
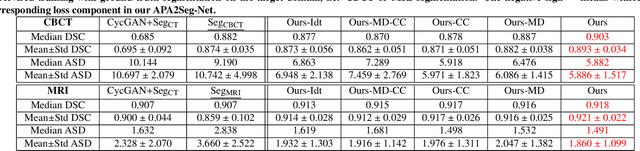
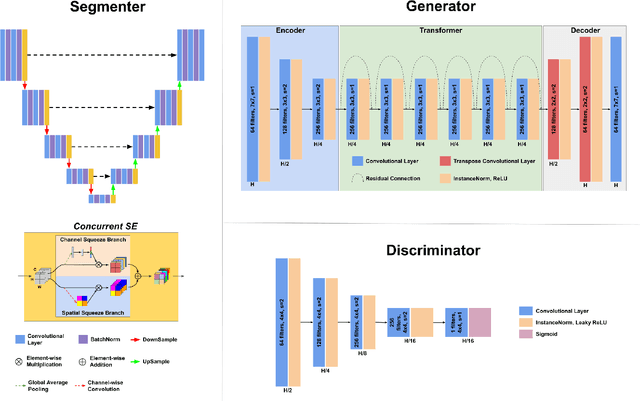
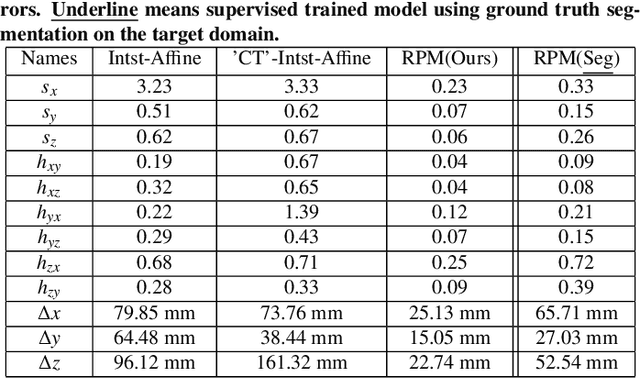
Multimodal image registration has many applications in diagnostic medical imaging and image-guided interventions, such as Transcatheter Arterial Chemoembolization (TACE) of liver cancer guided by intraprocedural CBCT and pre-operative MR. The ability to register peri-procedurally acquired diagnostic images into the intraprocedural environment can potentially improve the intra-procedural tumor targeting, which will significantly improve therapeutic outcomes. However, the intra-procedural CBCT often suffers from suboptimal image quality due to lack of signal calibration for Hounsfield unit, limited FOV, and motion/metal artifacts. These non-ideal conditions make standard intensity-based multimodal registration methods infeasible to generate correct transformation across modalities. While registration based on anatomic structures, such as segmentation or landmarks, provides an efficient alternative, such anatomic structure information is not always available. One can train a deep learning-based anatomy extractor, but it requires large-scale manual annotations on specific modalities, which are often extremely time-consuming to obtain and require expert radiological readers. To tackle these issues, we leverage annotated datasets already existing in a source modality and propose an anatomy-preserving domain adaptation to segmentation network (APA2Seg-Net) for learning segmentation without target modality ground truth. The segmenters are then integrated into our anatomy-guided multimodal registration based on the robust point matching machine. Our experimental results on in-house TACE patient data demonstrated that our APA2Seg-Net can generate robust CBCT and MR liver segmentation, and the anatomy-guided registration framework with these segmenters can provide high-quality multimodal registrations. Our code is available at https://github.com/bbbbbbzhou/APA2Seg-Net.
Commonsense Knowledge Aware Concept Selection For Diverse and Informative Visual Storytelling
Feb 05, 2021
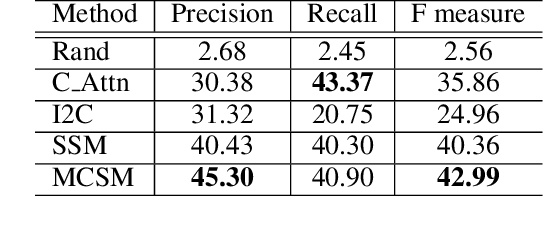
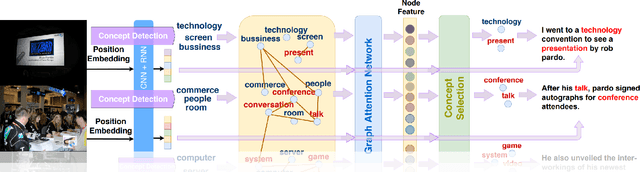
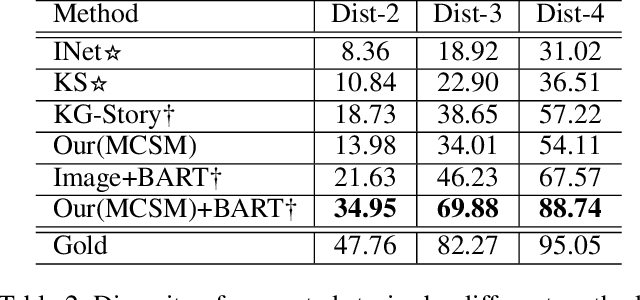
Visual storytelling is a task of generating relevant and interesting stories for given image sequences. In this work we aim at increasing the diversity of the generated stories while preserving the informative content from the images. We propose to foster the diversity and informativeness of a generated story by using a concept selection module that suggests a set of concept candidates. Then, we utilize a large scale pre-trained model to convert concepts and images into full stories. To enrich the candidate concepts, a commonsense knowledge graph is created for each image sequence from which the concept candidates are proposed. To obtain appropriate concepts from the graph, we propose two novel modules that consider the correlation among candidate concepts and the image-concept correlation. Extensive automatic and human evaluation results demonstrate that our model can produce reasonable concepts. This enables our model to outperform the previous models by a large margin on the diversity and informativeness of the story, while retaining the relevance of the story to the image sequence.
Unsupervised MRI Reconstruction via Zero-Shot Learned Adversarial Transformers
May 21, 2021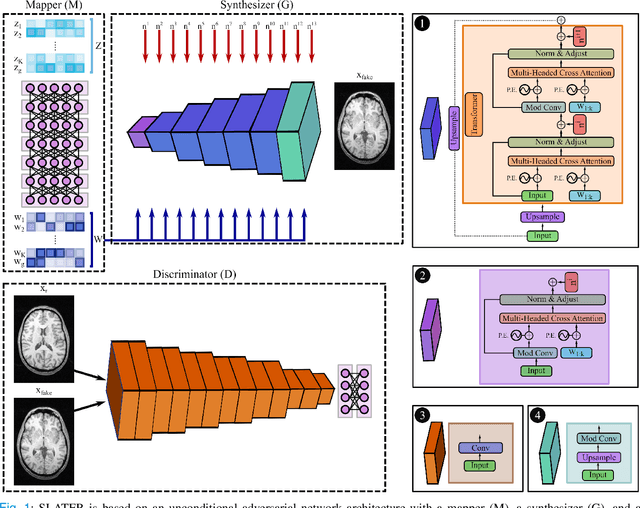
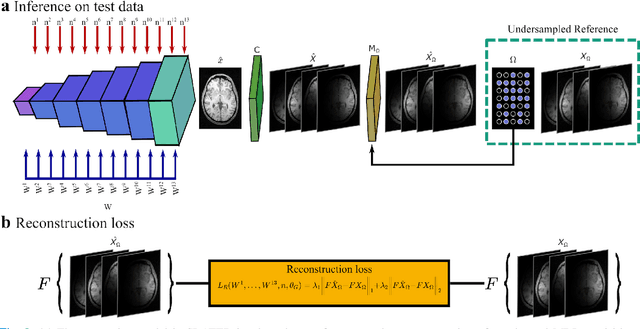
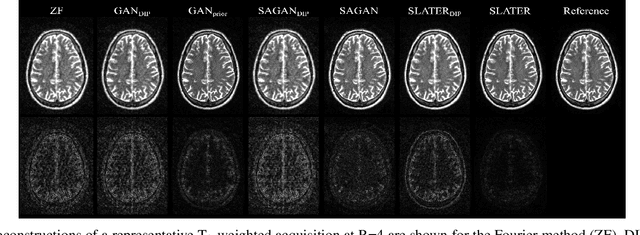
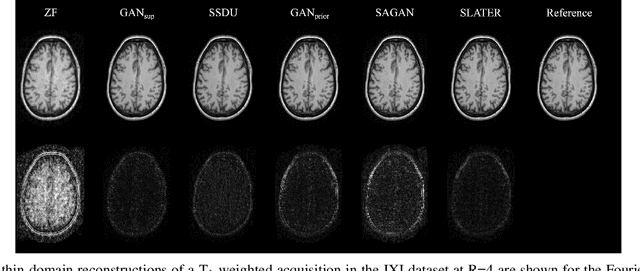
Supervised deep learning has swiftly become a workhorse for accelerated MRI in recent years, offering state-of-the-art performance in image reconstruction from undersampled acquisitions. Training deep supervised models requires large datasets of undersampled and fully-sampled acquisitions typically from a matching set of subjects. Given scarce access to large medical datasets, this limitation has sparked interest in unsupervised methods that reduce reliance on fully-sampled ground-truth data. A common framework is based on the deep image prior, where network-driven regularization is enforced directly during inference on undersampled acquisitions. Yet, canonical convolutional architectures are suboptimal in capturing long-range relationships, and randomly initialized networks may hamper convergence. To address these limitations, here we introduce a novel unsupervised MRI reconstruction method based on zero-Shot Learned Adversarial TransformERs (SLATER). SLATER embodies a deep adversarial network with cross-attention transformer blocks to map noise and latent variables onto MR images. This unconditional network learns a high-quality MRI prior in a self-supervised encoding task. A zero-shot reconstruction is performed on undersampled test data, where inference is performed by optimizing network parameters, latent and noise variables to ensure maximal consistency to multi-coil MRI data. Comprehensive experiments on brain MRI datasets clearly demonstrate the superior performance of SLATER against several state-of-the-art unsupervised methods.
Image Generation from Layout
Nov 29, 2018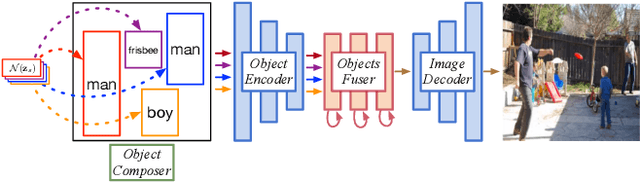
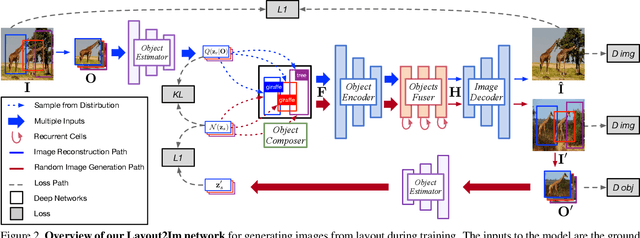

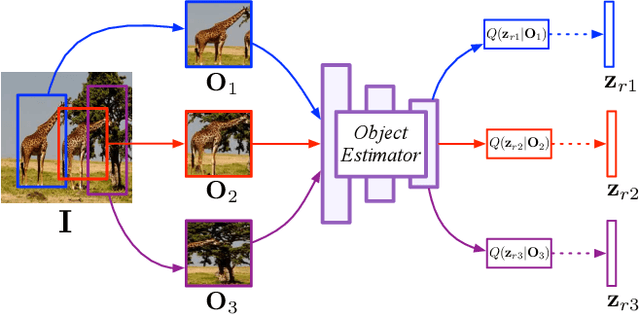
Despite significant recent progress on generative models, controlled generation of images depicting multiple and complex object layouts is still a difficult problem. Among the core challenges are the diversity of appearance a given object may possess and, as a result, exponential set of images consistent with a specified layout. To address these challenges, we propose a novel approach for layout-based image generation; we call it Layout2Im. Given the coarse spatial layout (bounding boxes + object categories), our model can generate a set of realistic images which have the correct objects in the desired locations. The representation of each object is disentangled into a specified/certain part (category) and an unspecified/uncertain part (appearance). The category is encoded using a word embedding and the appearance is distilled into a low-dimensional vector sampled from a normal distribution. Individual object representations are composed together using convolutional LSTM, to obtain an encoding of the complete layout, and then decoded to an image. Several loss terms are introduced to encourage accurate and diverse generation. The proposed Layout2Im model significantly outperforms the previous state of the art, boosting the best reported inception score by 24.66% and 28.57% on the very challenging COCO-Stuff and Visual Genome datasets, respectively. Extensive experiments also demonstrate our method's ability to generate complex and diverse images with multiple objects.
Iterative Shrinking for Referring Expression Grounding Using Deep Reinforcement Learning
Mar 09, 2021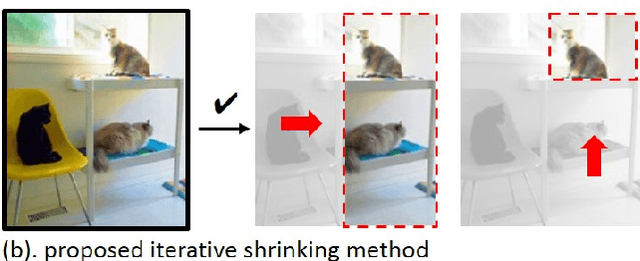
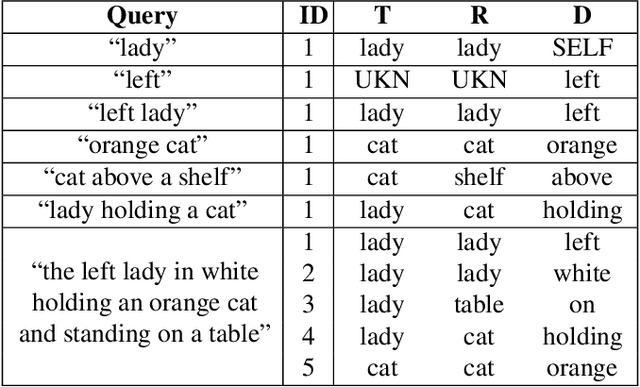
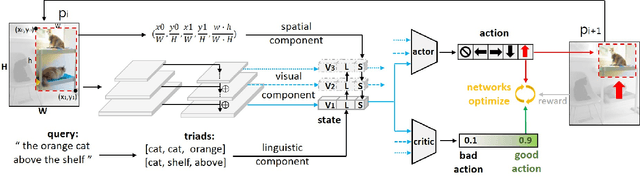
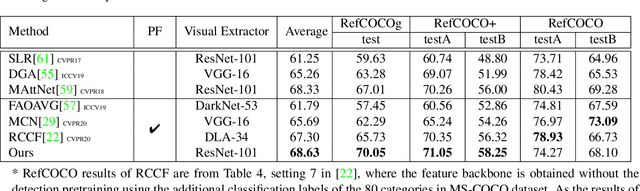
In this paper, we are tackling the proposal-free referring expression grounding task, aiming at localizing the target object according to a query sentence, without relying on off-the-shelf object proposals. Existing proposal-free methods employ a query-image matching branch to select the highest-score point in the image feature map as the target box center, with its width and height predicted by another branch. Such methods, however, fail to utilize the contextual relation between the target and reference objects, and lack interpretability on its reasoning procedure. To solve these problems, we propose an iterative shrinking mechanism to localize the target, where the shrinking direction is decided by a reinforcement learning agent, with all contents within the current image patch comprehensively considered. Beside, the sequential shrinking process enables to demonstrate the reasoning about how to iteratively find the target. Experiments show that the proposed method boosts the accuracy by 4.32% against the previous state-of-the-art (SOTA) method on the RefCOCOg dataset, where query sentences are long and complex, with many targets referred by other reference objects.
Resonant tunnelling diode nano-optoelectronic spiking nodes for neuromorphic information processing
Jul 21, 2021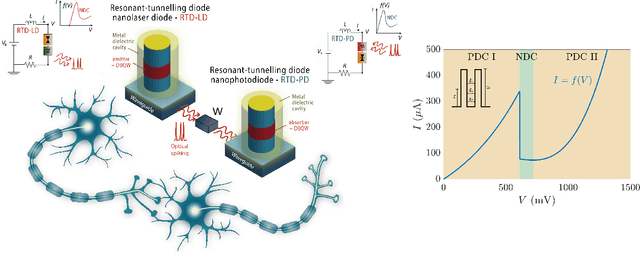
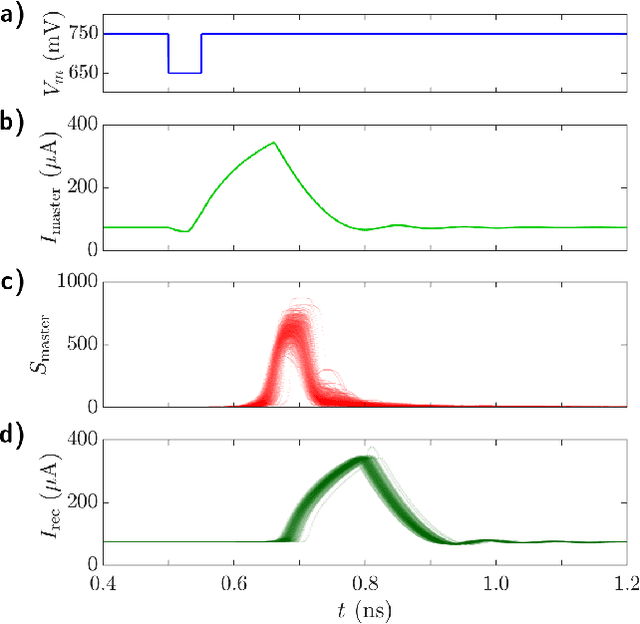
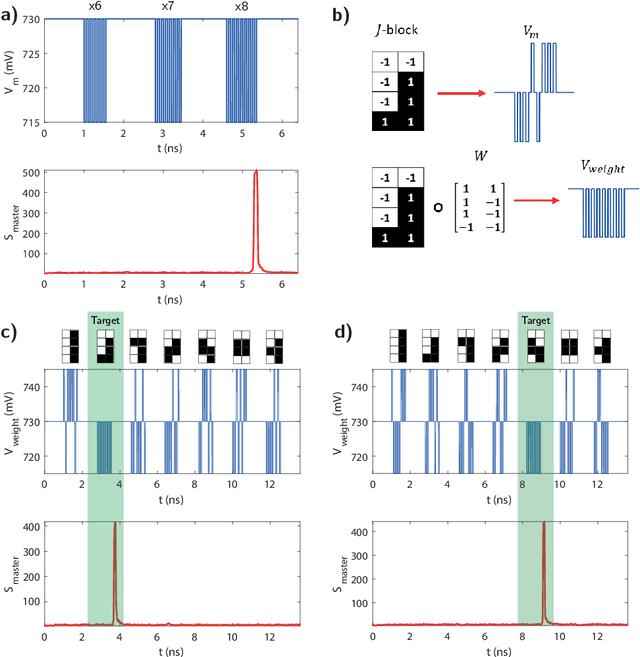
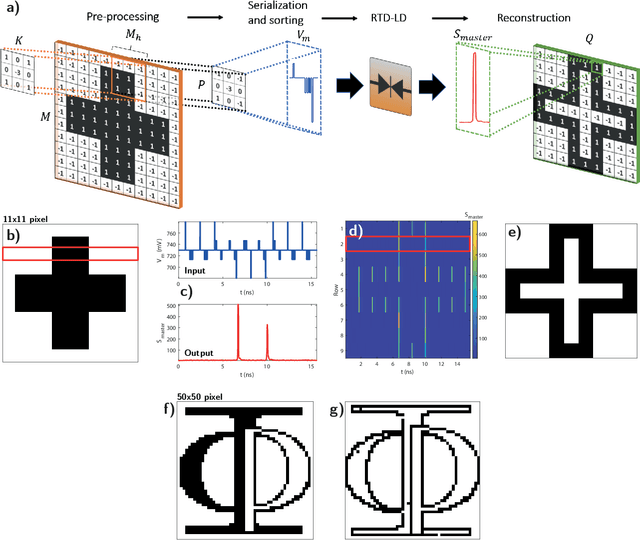
In this work, we introduce an optoelectronic spiking artificial neuron capable of operating at ultrafast rates ($\approx$ 100 ps/optical spike) and with low energy consumption ($<$ pJ/spike). The proposed system combines an excitable resonant tunnelling diode (RTD) element exhibiting negative differential conductance, coupled to a nanoscale light source (forming a master node) or a photodetector (forming a receiver node). We study numerically the spiking dynamical responses and information propagation functionality of an interconnected master-receiver RTD node system. Using the key functionality of pulse thresholding and integration, we utilize a single node to classify sequential pulse patterns and perform convolutional functionality for image feature (edge) recognition. We also demonstrate an optically-interconnected spiking neural network model for processing of spatiotemporal data at over 10 Gbps with high inference accuracy. Finally, we demonstrate an off-chip supervised learning approach utilizing spike-timing dependent plasticity for the RTD-enabled photonic spiking neural network. These results demonstrate the potential and viability of RTD spiking nodes for low footprint, low energy, high-speed optoelectronic realization of neuromorphic hardware.