 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis
Jul 26, 2018
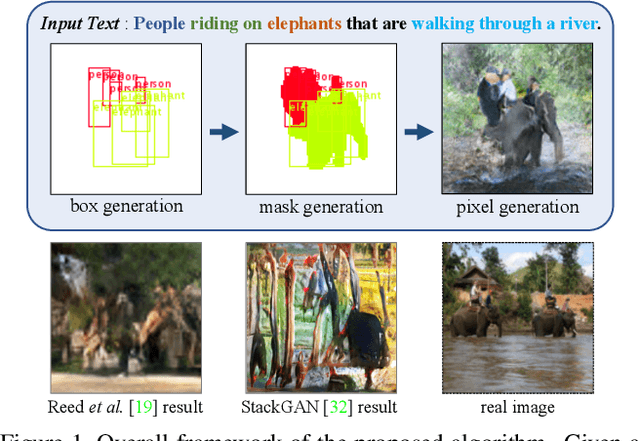
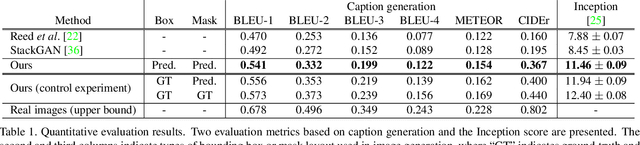
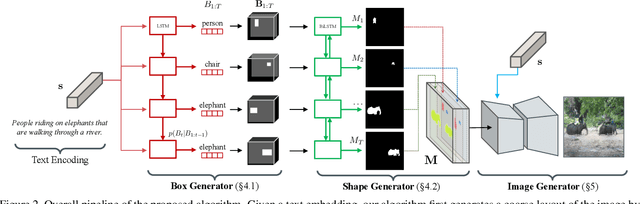
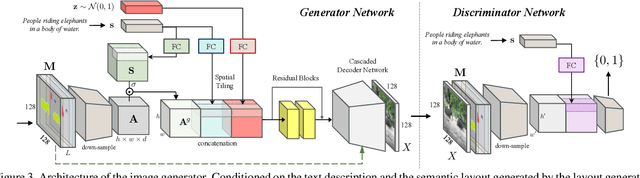
We propose a novel hierarchical approach for text-to-image synthesis by inferring semantic layout. Instead of learning a direct mapping from text to image, our algorithm decomposes the generation process into multiple steps, in which it first constructs a semantic layout from the text by the layout generator and converts the layout to an image by the image generator. The proposed layout generator progressively constructs a semantic layout in a coarse-to-fine manner by generating object bounding boxes and refining each box by estimating object shapes inside the box. The image generator synthesizes an image conditioned on the inferred semantic layout, which provides a useful semantic structure of an image matching with the text description. Our model not only generates semantically more meaningful images, but also allows automatic annotation of generated images and user-controlled generation process by modifying the generated scene layout. We demonstrate the capability of the proposed model on challenging MS-COCO dataset and show that the model can substantially improve the image quality, interpretability of output and semantic alignment to input text over existing approaches.
A Review of the Vision-based Approaches for Dietary Assessment
Jun 29, 2021
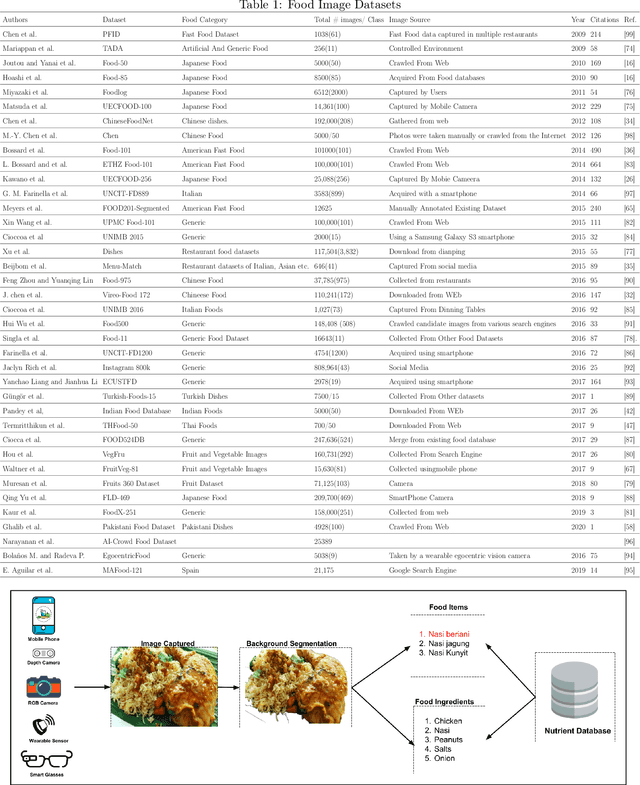
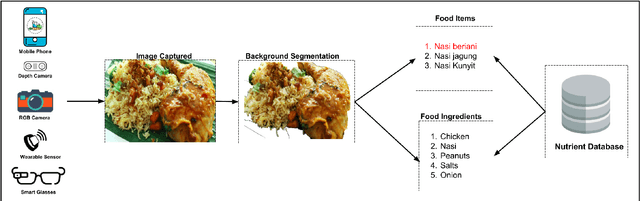
Last ten years have witnessed the growth of many computer vision applications for food recognition. Dietary studies showed that dietary-related problem such as obesity is associated with other chronic diseases like hypertension, irregular blood sugar levels, and increased risk of heart attacks. The primary cause of these problems is poor lifestyle choices and unhealthy dietary habits, which are manageable by using interactive mHealth apps that use automatic visual-based methods to assess dietary intake. This review discusses the most performing methodologies that have been developed so far for automatic food recognition. First, we will present the rationale of visual-based methods for food recognition. The core of the paper is the presentation, discussion and evaluation of these methods on popular food image databases. We also discussed the mobile applications that are implementing these methods. The review ends with a discussion of research gaps and future challenges in this area.
Evaluation of Retinal Image Quality Assessment Networks in Different Color-spaces
Jul 10, 2019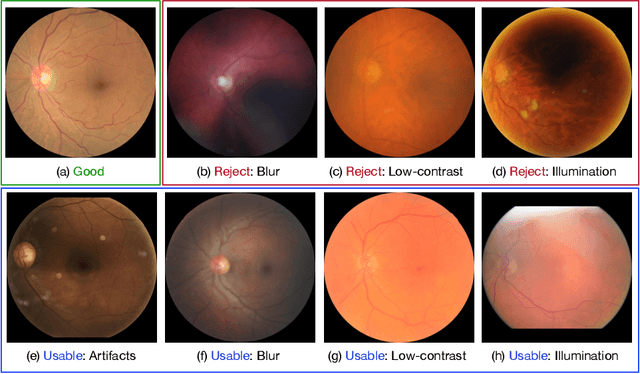
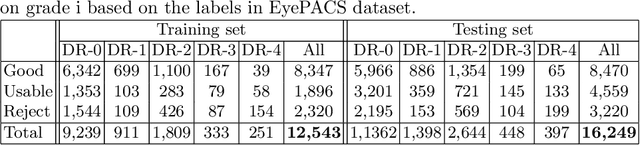
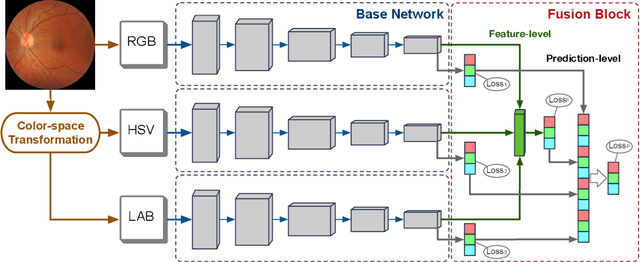
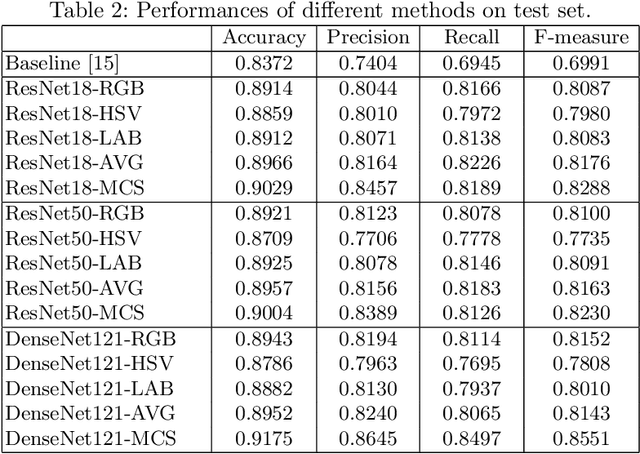
Retinal image quality assessment (RIQA) is essential for controlling the quality of retinal imaging and guaranteeing the reliability of diagnoses by ophthalmologists or automated analysis systems. Existing RIQA methods focus on the RGB color-space and are developed based on small datasets with binary quality labels (i.e., `Accept' and `Reject'). In this paper, we first re-annotate an Eye-Quality (EyeQ) dataset with 28,792 retinal images from the EyePACS dataset, based on a three-level quality grading system (i.e., `Good', `Usable' and `Reject') for evaluating RIQA methods. Our RIQA dataset is characterized by its large-scale size, multi-level grading, and multi-modality. Then, we analyze the influences on RIQA of different color-spaces, and propose a simple yet efficient deep network, named Multiple Color-space Fusion Network (MCF-Net), which integrates the different color-space representations at both a feature-level and prediction-level to predict image quality grades. Experiments on our EyeQ dataset show that our MCF-Net obtains a state-of-the-art performance, outperforming the other deep learning methods. Furthermore, we also evaluate diabetic retinopathy (DR) detection methods on images of different quality, and demonstrate that the performances of automated diagnostic systems are highly dependent on image quality.
A Remote Sensing Image Dataset for Cloud Removal
Jan 03, 2019

Cloud-based overlays are often present in optical remote sensing images, thus limiting the application of acquired data. Removing clouds is an indispensable pre-processing step in remote sensing image analysis. Deep learning has achieved great success in the field of remote sensing in recent years, including scene classification and change detection. However, deep learning is rarely applied in remote sensing image removal clouds. The reason is the lack of data sets for training neural networks. In order to solve this problem, this paper first proposed the Remote sensing Image Cloud rEmoving dataset (RICE). The proposed dataset consists of two parts: RICE1 contains 500 pairs of images, each pair has images with cloud and cloudless size of 512*512; RICE2 contains 450 sets of images, each set contains three 512*512 size images. , respectively, the reference picture without clouds, the picture of the cloud and the mask of its cloud. The dataset is freely available at \url{https://github.com/BUPTLdy/RICE_DATASET}.
A Machine learning approach for rapid disaster response based on multi-modal data. The case of housing & shelter needs
Aug 09, 2021



Along with climate change, more frequent extreme events, such as flooding and tropical cyclones, threaten the livelihoods and wellbeing of poor and vulnerable populations. One of the most immediate needs of people affected by a disaster is finding shelter. While the proliferation of data on disasters is already helping to save lives, identifying damages in buildings, assessing shelter needs, and finding appropriate places to establish emergency shelters or settlements require a wide range of data to be combined rapidly. To address this gap and make a headway in comprehensive assessments, this paper proposes a machine learning workflow that aims to fuse and rapidly analyse multimodal data. This workflow is built around open and online data to ensure scalability and broad accessibility. Based on a database of 19 characteristics for more than 200 disasters worldwide, a fusion approach at the decision level was used. This technique allows the collected multimodal data to share a common semantic space that facilitates the prediction of individual variables. Each fused numerical vector was fed into an unsupervised clustering algorithm called Self-Organizing-Maps (SOM). The trained SOM serves as a predictor for future cases, allowing predicting consequences such as total deaths, total people affected, and total damage, and provides specific recommendations for assessments in the shelter and housing sector. To achieve such prediction, a satellite image from before the disaster and the geographic and demographic conditions are shown to the trained model, which achieved a prediction accuracy of 62 %
Self-Supervised Feature Learning of 1D Convolutional Neural Networks with Contrastive Loss for Eating Detection Using an In-Ear Microphone
Aug 03, 2021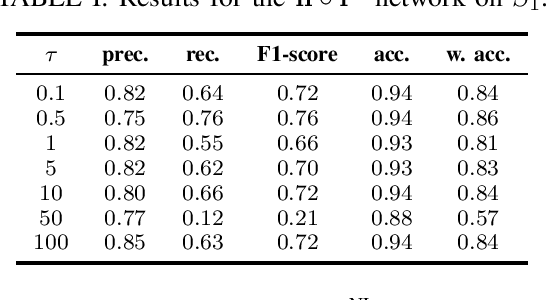
The importance of automated and objective monitoring of dietary behavior is becoming increasingly accepted. The advancements in sensor technology along with recent achievements in machine-learning--based signal-processing algorithms have enabled the development of dietary monitoring solutions that yield highly accurate results. A common bottleneck for developing and training machine learning algorithms is obtaining labeled data for training supervised algorithms, and in particular ground truth annotations. Manual ground truth annotation is laborious, cumbersome, can sometimes introduce errors, and is sometimes impossible in free-living data collection. As a result, there is a need to decrease the labeled data required for training. Additionally, unlabeled data, gathered in-the-wild from existing wearables (such as Bluetooth earbuds) can be used to train and fine-tune eating-detection models. In this work, we focus on training a feature extractor for audio signals captured by an in-ear microphone for the task of eating detection in a self-supervised way. We base our approach on the SimCLR method for image classification, proposed by Chen et al. from the domain of computer vision. Results are promising as our self-supervised method achieves similar results to supervised training alternatives, and its overall effectiveness is comparable to current state-of-the-art methods. Code is available at https://github.com/mug-auth/ssl-chewing .
A security steganography scheme based on hdr image
Feb 28, 2019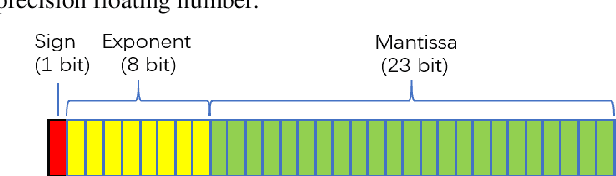



It is widely recognized that the image format is crucial to steganography for that each individual format has its unique properities. Nowadays, the most famous approach of digital image steganography is to combine a well-defined distortion function with efficient practical codes such as STC. And numerous researches are concentrated on spatial domain and jpeg domain. However, whether in spatial domain or jpeg domain, high payload (e.g., 0.5 bit per pixel) is not secure enough. In this paper, we propose a novel adaptive steganography scheme based on 32-bit HDR (High dynamic range) format and Norm IEEE 754. Experiments show that the steganographic method can achieve satisfactory security under payload from 0.3bpp to 0.5bpp.
Domain Adaptive YOLO for One-Stage Cross-Domain Detection
Jul 04, 2021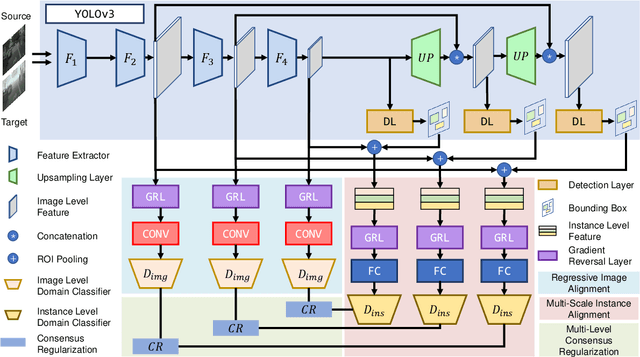
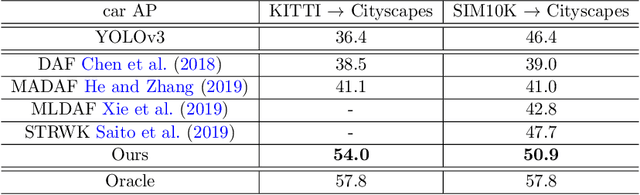


Domain shift is a major challenge for object detectors to generalize well to real world applications. Emerging techniques of domain adaptation for two-stage detectors help to tackle this problem. However, two-stage detectors are not the first choice for industrial applications due to its long time consumption. In this paper, a novel Domain Adaptive YOLO (DA-YOLO) is proposed to improve cross-domain performance for one-stage detectors. Image level features alignment is used to strictly match for local features like texture, and loosely match for global features like illumination. Multi-scale instance level features alignment is presented to reduce instance domain shift effectively , such as variations in object appearance and viewpoint. A consensus regularization to these domain classifiers is employed to help the network generate domain-invariant detections. We evaluate our proposed method on popular datasets like Cityscapes, KITTI, SIM10K and etc.. The results demonstrate significant improvement when tested under different cross-domain scenarios.
SharpGAN: Receptive Field Block Net for Dynamic Scene Deblurring
Dec 31, 2020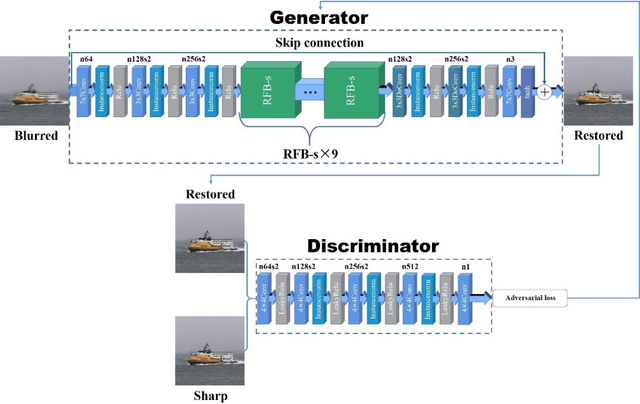

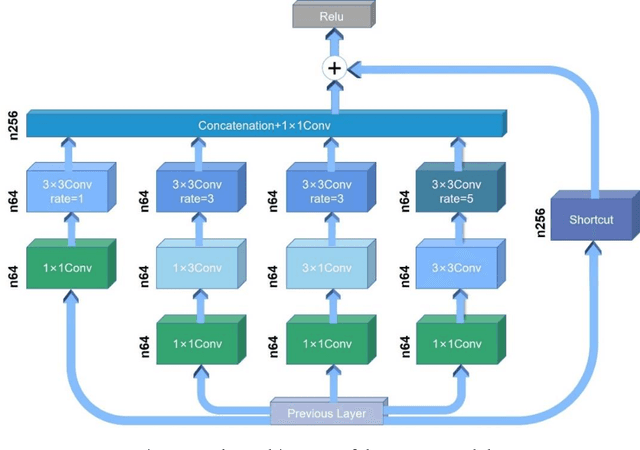
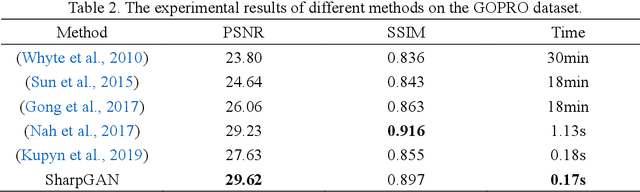
When sailing at sea, the smart ship will inevitably produce swaying motion due to the action of wind, wave and current, which makes the image collected by the visual sensor appear motion blur. This will have an adverse effect on the object detection algorithm based on the vision sensor, thereby affect the navigation safety of the smart ship. In order to remove the motion blur in the images during the navigation of the smart ship, we propose SharpGAN, a new image deblurring method based on the generative adversarial network. First of all, the Receptive Field Block Net (RFBNet) is introduced to the deblurring network to strengthen the network's ability to extract the features of blurred image. Secondly, we propose a feature loss that combines different levels of image features to guide the network to perform higher-quality deblurring and improve the feature similarity between the restored images and the sharp image. Finally, we propose to use the lightweight RFB-s module to improve the real-time performance of deblurring network. Compared with the existing deblurring methods on large-scale real sea image datasets and large-scale deblurring datasets, the proposed method not only has better deblurring performance in visual perception and quantitative criteria, but also has higher deblurring efficiency.
Using a New Nonlinear Gradient Method for Solving Large Scale Convex Optimization Problems with an Application on Arabic Medical Text
Jun 08, 2021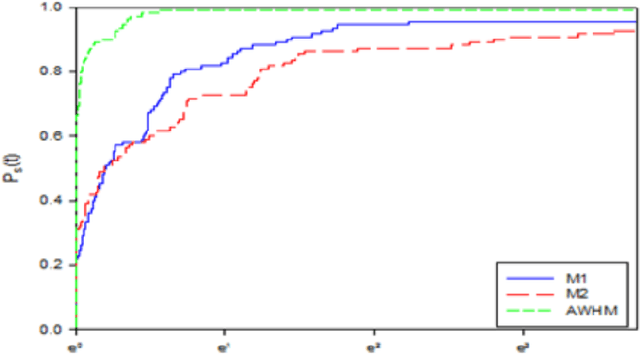

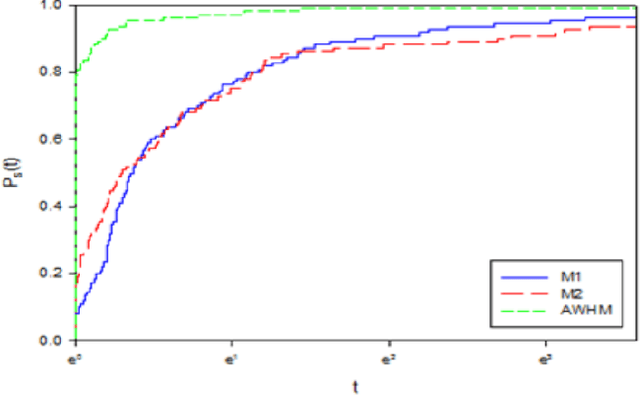

Gradient methods have applications in multiple fields, including signal processing, image processing, and dynamic systems. In this paper, we present a nonlinear gradient method for solving convex supra-quadratic functions by developing the search direction, that done by hybridizing between the two conjugate coefficients HRM [2] and NHS [1]. The numerical results proved the effectiveness of the presented method by applying it to solve standard problems and reaching the exact solution if the objective function is quadratic convex. Also presented in this article, an application to the problem of named entities in the Arabic medical language, as it proved the stability of the proposed method and its efficiency in terms of execution time.