 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Rank Words: Optimizing Ranking Metrics for Word Spotting
Jun 09, 2021
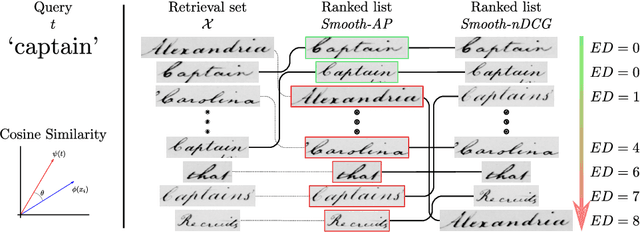
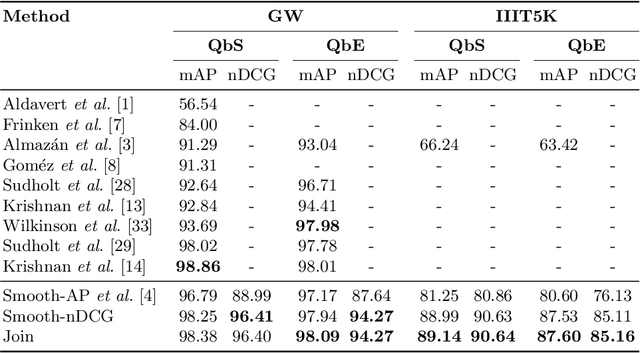
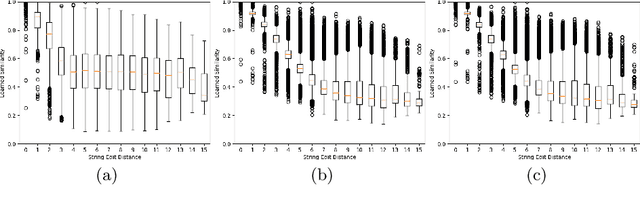
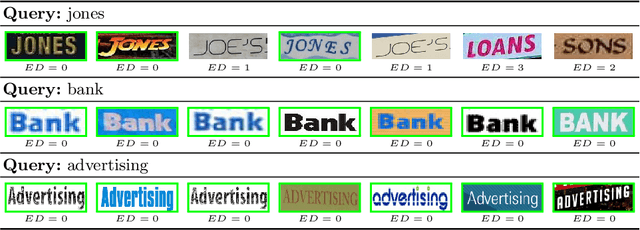
In this paper, we explore and evaluate the use of ranking-based objective functions for learning simultaneously a word string and a word image encoder. We consider retrieval frameworks in which the user expects a retrieval list ranked according to a defined relevance score. In the context of a word spotting problem, the relevance score has been set according to the string edit distance from the query string. We experimentally demonstrate the competitive performance of the proposed model on query-by-string word spotting for both, handwritten and real scene word images. We also provide the results for query-by-example word spotting, although it is not the main focus of this work.
Pretrained Encoders are All You Need
Jun 09, 2021



Data-efficiency and generalization are key challenges in deep learning and deep reinforcement learning as many models are trained on large-scale, domain-specific, and expensive-to-label datasets. Self-supervised models trained on large-scale uncurated datasets have shown successful transfer to diverse settings. We investigate using pretrained image representations and spatio-temporal attention for state representation learning in Atari. We also explore fine-tuning pretrained representations with self-supervised techniques, i.e., contrastive predictive coding, spatio-temporal contrastive learning, and augmentations. Our results show that pretrained representations are at par with state-of-the-art self-supervised methods trained on domain-specific data. Pretrained representations, thus, yield data and compute-efficient state representations. https://github.com/PAL-ML/PEARL_v1
Few Shots Is All You Need: A Progressive Few Shot Learning Approach for Low Resource Handwriting Recognition
Jul 21, 2021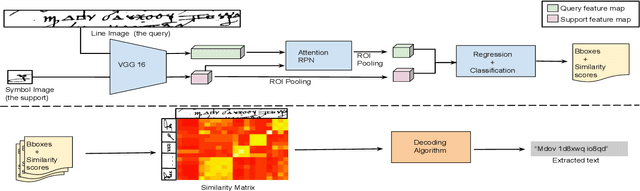
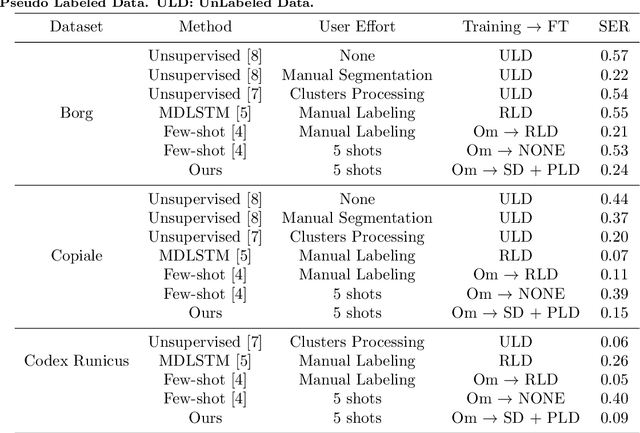
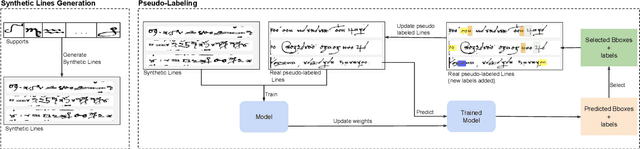
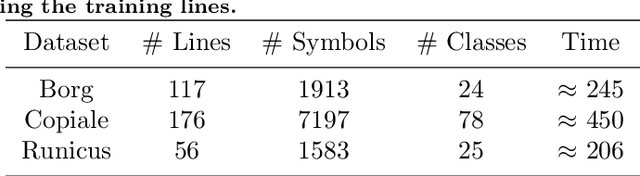
Handwritten text recognition in low resource scenarios, such as manuscripts with rare alphabets, is a challenging problem. The main difficulty comes from the very few annotated data and the limited linguistic information (e.g. dictionaries and language models). Thus, we propose a few-shot learning-based handwriting recognition approach that significantly reduces the human labor annotation process, requiring only few images of each alphabet symbol. First, our model detects all symbols of a given alphabet in a textline image, then a decoding step maps the symbol similarity scores to the final sequence of transcribed symbols. Our model is first pretrained on synthetic line images generated from any alphabet, even though different from the target domain. A second training step is then applied to diminish the gap between the source and target data. Since this retraining would require annotation of thousands of handwritten symbols together with their bounding boxes, we propose to avoid such human effort through an unsupervised progressive learning approach that automatically assigns pseudo-labels to the non-annotated data. The evaluation on different manuscript datasets show that our model can lead to competitive results with a significant reduction in human effort.
Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis
Jul 26, 2018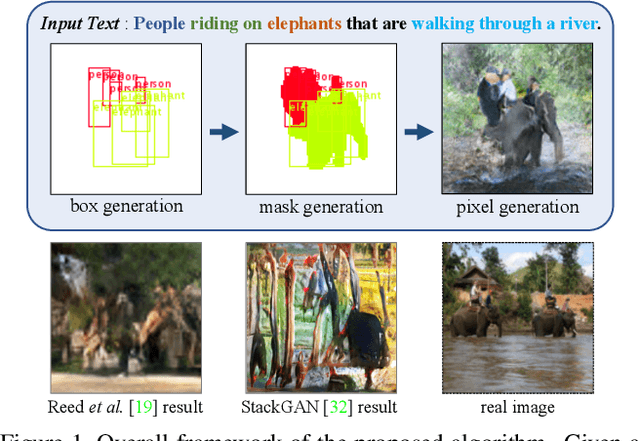
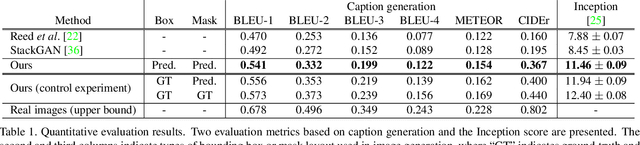
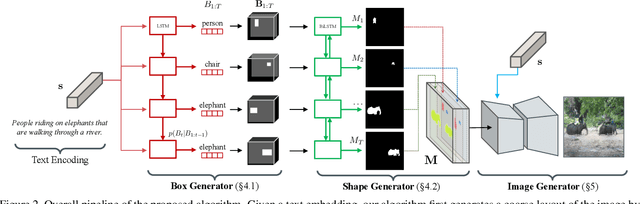
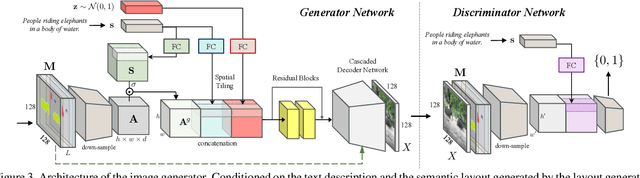
We propose a novel hierarchical approach for text-to-image synthesis by inferring semantic layout. Instead of learning a direct mapping from text to image, our algorithm decomposes the generation process into multiple steps, in which it first constructs a semantic layout from the text by the layout generator and converts the layout to an image by the image generator. The proposed layout generator progressively constructs a semantic layout in a coarse-to-fine manner by generating object bounding boxes and refining each box by estimating object shapes inside the box. The image generator synthesizes an image conditioned on the inferred semantic layout, which provides a useful semantic structure of an image matching with the text description. Our model not only generates semantically more meaningful images, but also allows automatic annotation of generated images and user-controlled generation process by modifying the generated scene layout. We demonstrate the capability of the proposed model on challenging MS-COCO dataset and show that the model can substantially improve the image quality, interpretability of output and semantic alignment to input text over existing approaches.
SCNet: Enhancing Few-Shot Semantic Segmentation by Self-Contrastive Background Prototypes
Apr 28, 2021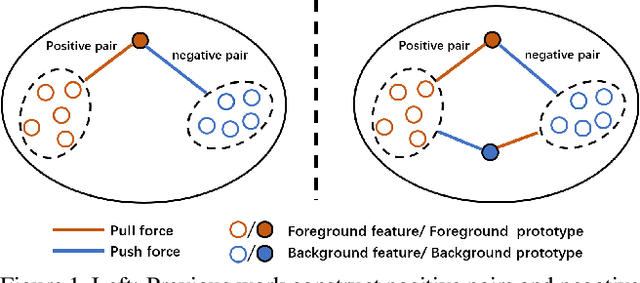
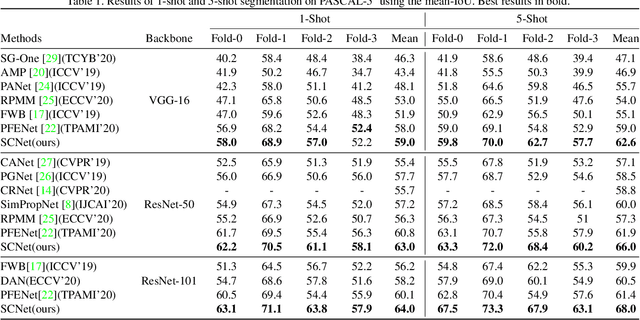
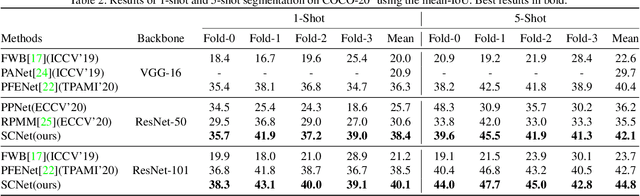
Few-shot semantic segmentation aims to segment novel-class objects in a query image with only a few annotated examples in support images. Most of advanced solutions exploit a metric learning framework that performs segmentation through matching each pixel to a learned foreground prototype. However, this framework suffers from biased classification due to incomplete construction of sample pairs with the foreground prototype only. To address this issue, in this paper, we introduce a complementary self-contrastive task into few-shot semantic segmentation. Our new model is able to associate the pixels in a region with the prototype of this region, no matter they are in the foreground or background. To this end, we generate self-contrastive background prototypes directly from the query image, with which we enable the construction of complete sample pairs and thus a complementary and auxiliary segmentation task to achieve the training of a better segmentation model. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ demonstrate clearly the superiority of our proposal. At no expense of inference efficiency, our model achieves state-of-the results in both 1-shot and 5-shot settings for few-shot semantic segmentation.
Spatio-Temporal Matching for Siamese Visual Tracking
May 06, 2021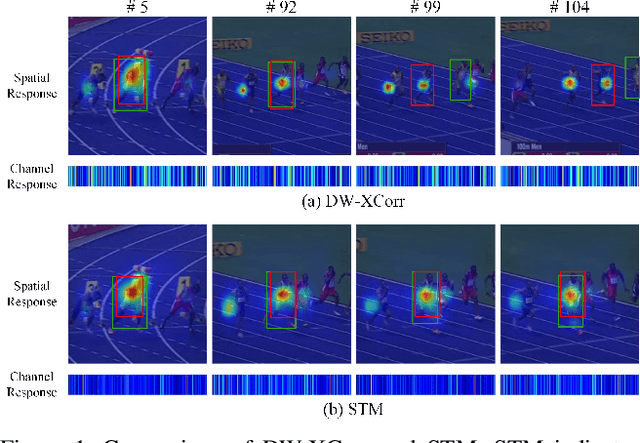
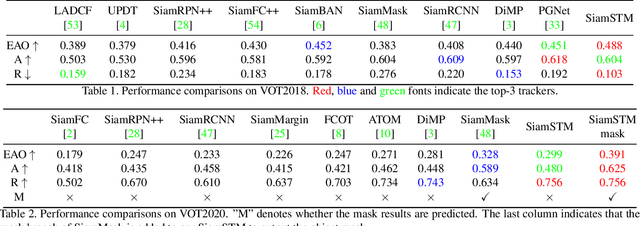
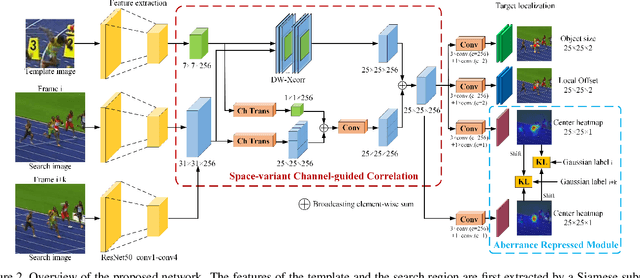
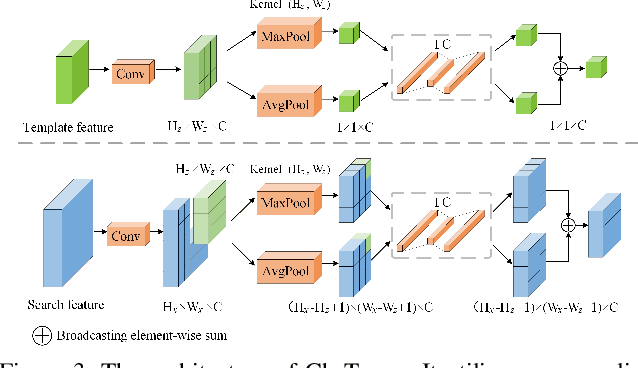
Similarity matching is a core operation in Siamese trackers. Most Siamese trackers carry out similarity learning via cross correlation that originates from the image matching field. However, unlike 2-D image matching, the matching network in object tracking requires 4-D information (height, width, channel and time). Cross correlation neglects the information from channel and time dimensions, and thus produces ambiguous matching. This paper proposes a spatio-temporal matching process to thoroughly explore the capability of 4-D matching in space (height, width and channel) and time. In spatial matching, we introduce a space-variant channel-guided correlation (SVC-Corr) to recalibrate channel-wise feature responses for each spatial location, which can guide the generation of the target-aware matching features. In temporal matching, we investigate the time-domain context relations of the target and the background and develop an aberrance repressed module (ARM). By restricting the abrupt alteration in the interframe response maps, our ARM can clearly suppress aberrances and thus enables more robust and accurate object tracking. Furthermore, a novel anchor-free tracking framework is presented to accommodate these innovations. Experiments on challenging benchmarks including OTB100, VOT2018, VOT2020, GOT-10k, and LaSOT demonstrate the state-of-the-art performance of the proposed method.
Using a New Nonlinear Gradient Method for Solving Large Scale Convex Optimization Problems with an Application on Arabic Medical Text
Jun 09, 2021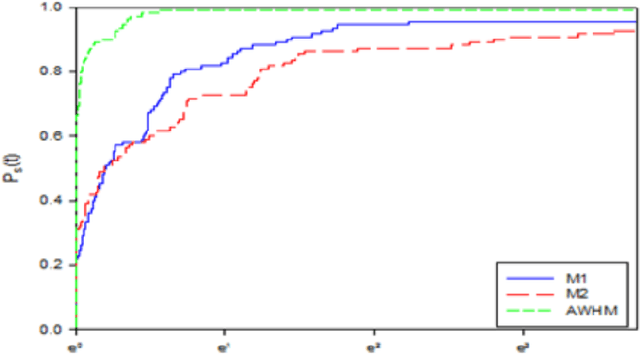

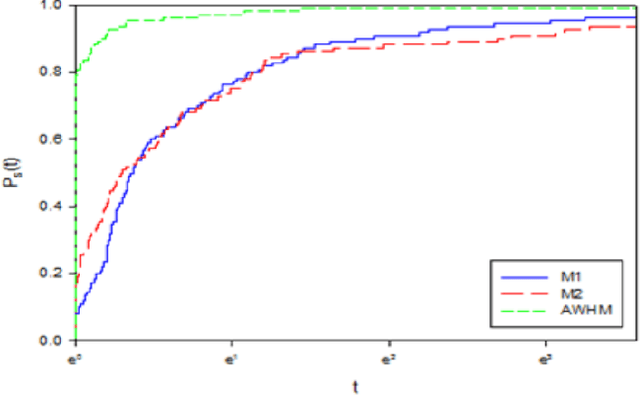

Gradient methods have applications in multiple fields, including signal processing, image processing, and dynamic systems. In this paper, we present a nonlinear gradient method for solving convex supra-quadratic functions by developing the search direction, that done by hybridizing between the two conjugate coefficients HRM [2] and NHS [1]. The numerical results proved the effectiveness of the presented method by applying it to solve standard problems and reaching the exact solution if the objective function is quadratic convex. Also presented in this article, an application to the problem of named entities in the Arabic medical language, as it proved the stability of the proposed method and its efficiency in terms of execution time.
Learning from Synthetic Shadows for Shadow Detection and Removal
Jan 05, 2021


Shadow removal is an essential task in computer vision and computer graphics. Recent shadow removal approaches all train convolutional neural networks (CNN) on real paired shadow/shadow-free or shadow/shadow-free/mask image datasets. However, obtaining a large-scale, diverse, and accurate dataset has been a big challenge, and it limits the performance of the learned models on shadow images with unseen shapes/intensities. To overcome this challenge, we present SynShadow, a novel large-scale synthetic shadow/shadow-free/matte image triplets dataset and a pipeline to synthesize it. We extend a physically-grounded shadow illumination model and synthesize a shadow image given an arbitrary combination of a shadow-free image, a matte image, and shadow attenuation parameters. Owing to the diversity, quantity, and quality of SynShadow, we demonstrate that shadow removal models trained on SynShadow perform well in removing shadows with diverse shapes and intensities on some challenging benchmarks. Furthermore, we show that merely fine-tuning from a SynShadow-pre-trained model improves existing shadow detection and removal models. Codes are publicly available at https://github.com/naoto0804/SynShadow.
Evaluation of Retinal Image Quality Assessment Networks in Different Color-spaces
Jul 10, 2019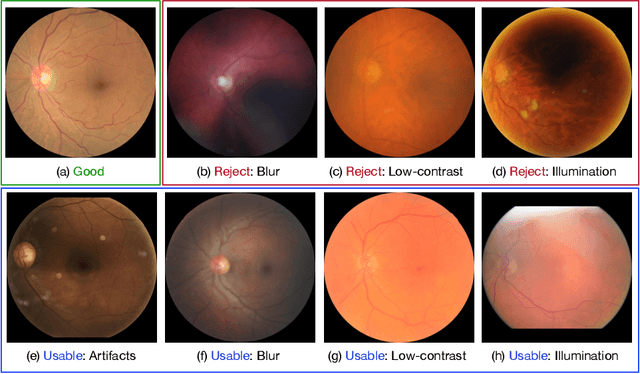
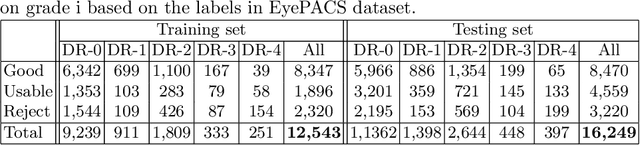
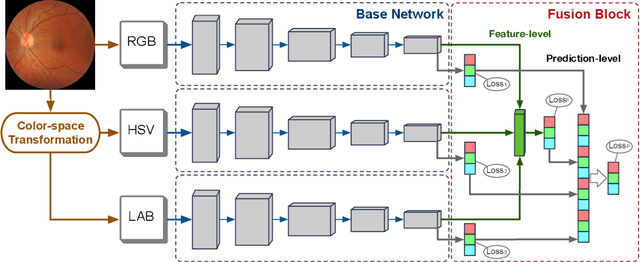
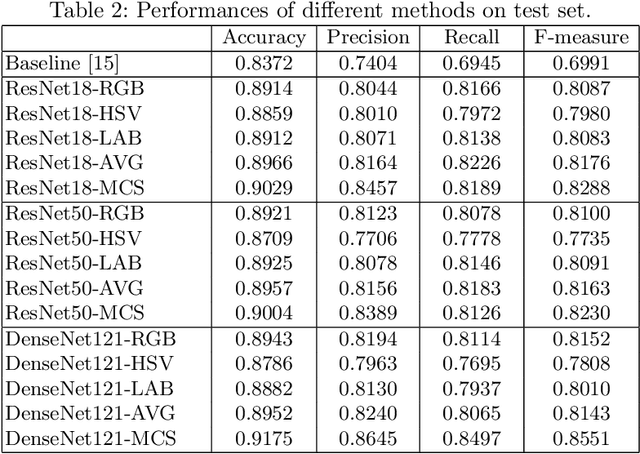
Retinal image quality assessment (RIQA) is essential for controlling the quality of retinal imaging and guaranteeing the reliability of diagnoses by ophthalmologists or automated analysis systems. Existing RIQA methods focus on the RGB color-space and are developed based on small datasets with binary quality labels (i.e., `Accept' and `Reject'). In this paper, we first re-annotate an Eye-Quality (EyeQ) dataset with 28,792 retinal images from the EyePACS dataset, based on a three-level quality grading system (i.e., `Good', `Usable' and `Reject') for evaluating RIQA methods. Our RIQA dataset is characterized by its large-scale size, multi-level grading, and multi-modality. Then, we analyze the influences on RIQA of different color-spaces, and propose a simple yet efficient deep network, named Multiple Color-space Fusion Network (MCF-Net), which integrates the different color-space representations at both a feature-level and prediction-level to predict image quality grades. Experiments on our EyeQ dataset show that our MCF-Net obtains a state-of-the-art performance, outperforming the other deep learning methods. Furthermore, we also evaluate diabetic retinopathy (DR) detection methods on images of different quality, and demonstrate that the performances of automated diagnostic systems are highly dependent on image quality.
Coarse-to-Fine Searching for Efficient Generative Adversarial Networks
Apr 19, 2021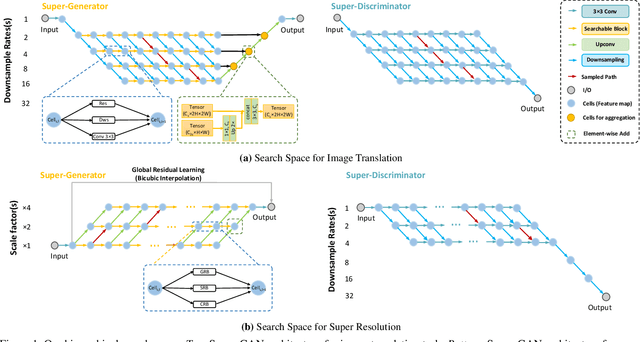
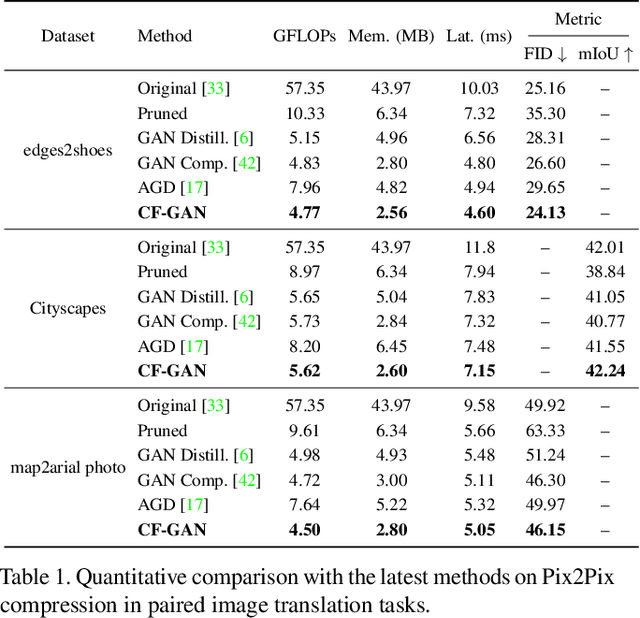
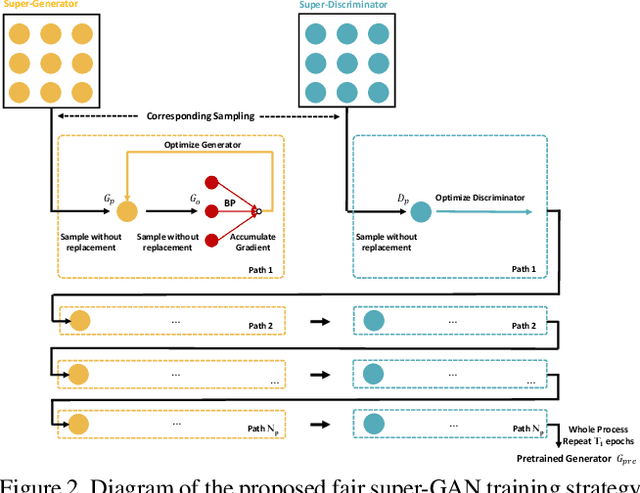
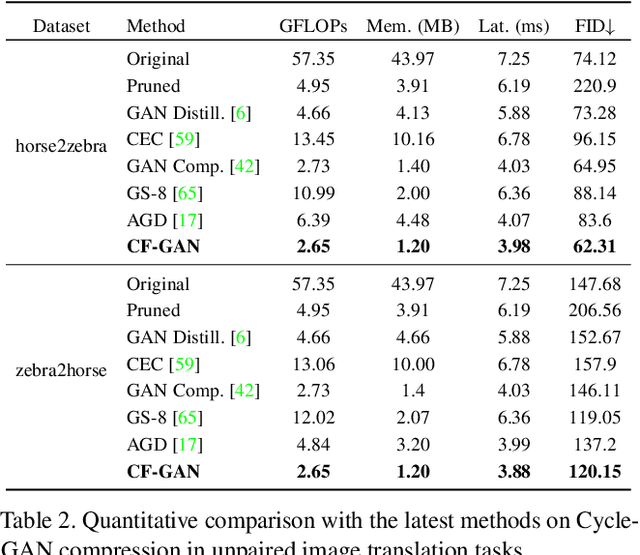
This paper studies the neural architecture search (NAS) problem for developing efficient generator networks. Compared with deep models for visual recognition tasks, generative adversarial network (GAN) are usually designed to conduct various complex image generation. We first discover an intact search space of generator networks including three dimensionalities, i.e., path, operator, channel for fully excavating the network performance. To reduce the huge search cost, we explore a coarse-to-fine search strategy which divides the overall search process into three sub-optimization problems accordingly. In addition, a fair supernet training approach is utilized to ensure that all sub-networks can be updated fairly and stably. Experiments results on benchmarks show that we can provide generator networks with better image quality and lower computational costs over the state-of-the-art methods. For example, with our method, it takes only about 8 GPU hours on the entire edges-to-shoes dataset to get a 2.56 MB model with a 24.13 FID score and 10 GPU hours on the entire Urban100 dataset to get a 1.49 MB model with a 24.94 PSNR score.