 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Using Robust Regression to Find Font Usage Trends
Jul 05, 2021

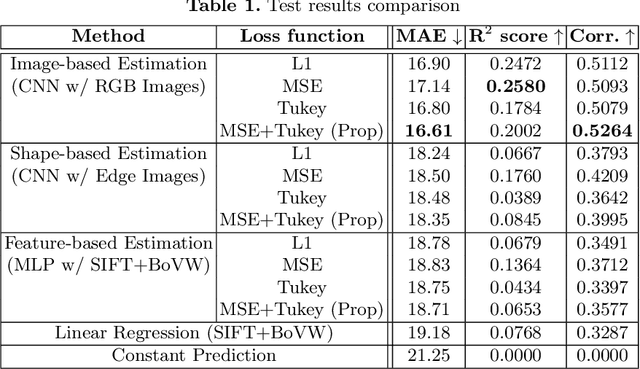

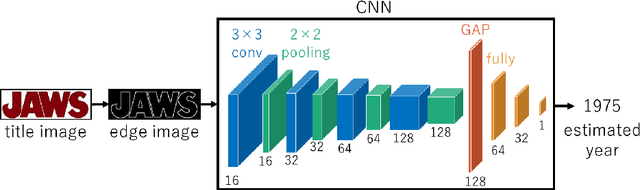
Fonts have had trends throughout their history, not only in when they were invented but also in their usage and popularity. In this paper, we attempt to specifically find the trends in font usage using robust regression on a large collection of text images. We utilize movie posters as the source of fonts for this task because movie posters can represent time periods by using their release date. In addition, movie posters are documents that are carefully designed and represent a wide range of fonts. To understand the relationship between the fonts of movie posters and time, we use a regression Convolutional Neural Network (CNN) to estimate the release year of a movie using an isolated title text image. Due to the difficulty of the task, we propose to use of a hybrid training regimen that uses a combination of Mean Squared Error (MSE) and Tukey's biweight loss. Furthermore, we perform a thorough analysis on the trends of fonts through time.
Multi-Level Feature Fusion Mechanism for Single Image Super-Resolution
Feb 14, 2020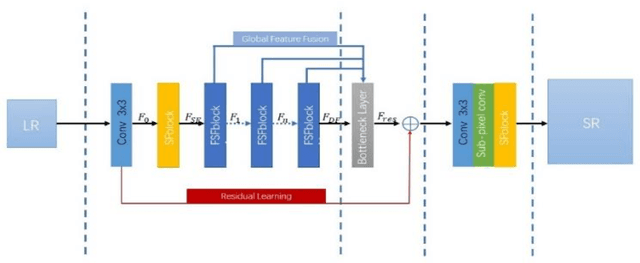
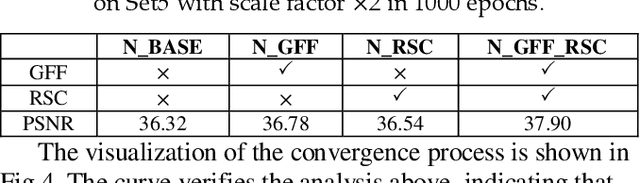

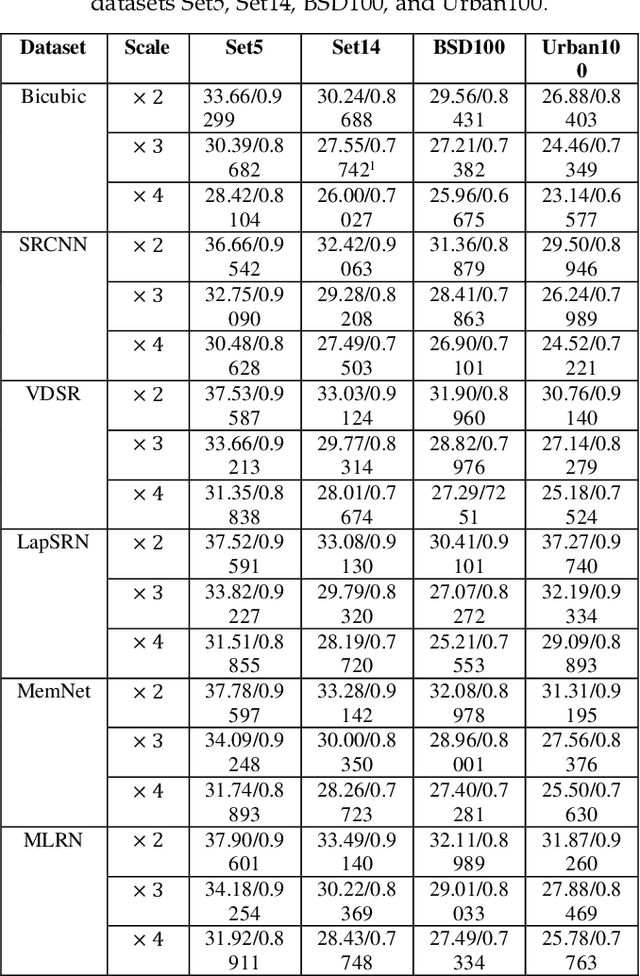
Convolution neural network (CNN) has been widely used in Single Image Super Resolution (SISR) so that SISR has been a great success recently. As the network deepens, the learning ability of network becomes more and more powerful. However, most SISR methods based on CNN do not make full use of hierarchical feature and the learning ability of network. These features cannot be extracted directly by subsequent layers, so the previous layer hierarchical information has little impact on the output and performance of subsequent layers relatively poor. To solve above problem, a novel Multi-Level Feature Fusion network (MLRN) is proposed, which can take full use of global intermediate features. We also introduce Feature Skip Fusion Block (FSFblock) as basic module. Each block can be extracted directly to the raw multiscale feature and fusion multi-level feature, then learn feature spatial correlation. The correlation among the features of the holistic approach leads to a continuous global memory of information mechanism. Extensive experiments on public datasets show that the method proposed by MLRN can be implemented, which is favorable performance for the most advanced methods.
Few-Shot Model Adaptation for Customized Facial Landmark Detection, Segmentation, Stylization and Shadow Removal
Apr 19, 2021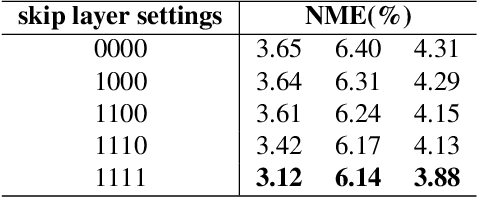
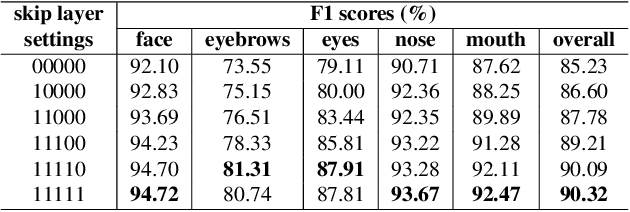
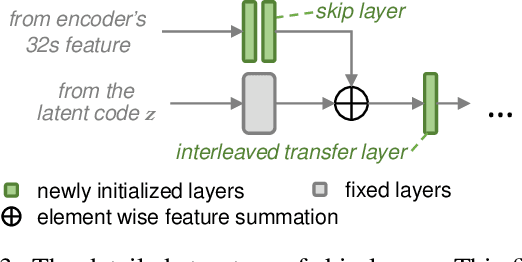
Despite excellent progress has been made, the performance of deep learning based algorithms still heavily rely on specific datasets, which are difficult to extend due to labor-intensive labeling. Moreover, because of the advancement of new applications, initial definition of data annotations might not always meet the requirements of new functionalities. Thus, there is always a great demand in customized data annotations. To address the above issues, we propose the Few-Shot Model Adaptation (FSMA) framework and demonstrate its potential on several important tasks on Faces. The FSMA first acquires robust facial image embeddings by training an adversarial auto-encoder using large-scale unlabeled data. Then the model is equipped with feature adaptation and fusion layers, and adapts to the target task efficiently using a minimal amount of annotated images. The FSMA framework is prominent in its versatility across a wide range of facial image applications. The FSMA achieves state-of-the-art few-shot landmark detection performance and it offers satisfying solutions for few-shot face segmentation, stylization and facial shadow removal tasks for the first time.
Continuous-Time Spatiotemporal Calibration of a Rolling Shutter Camera---IMU System
Aug 16, 2021
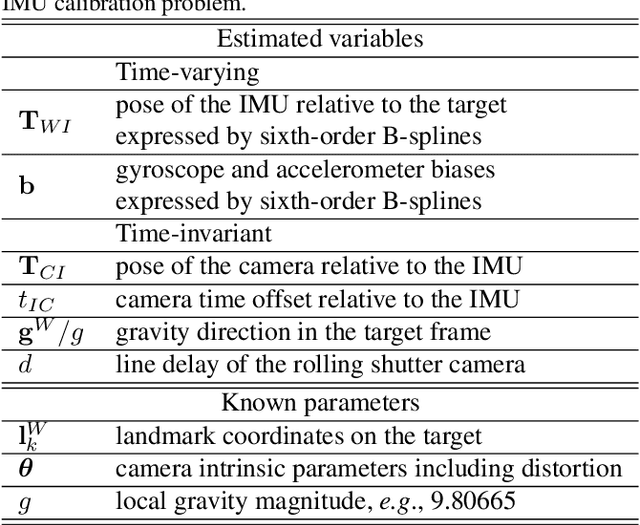
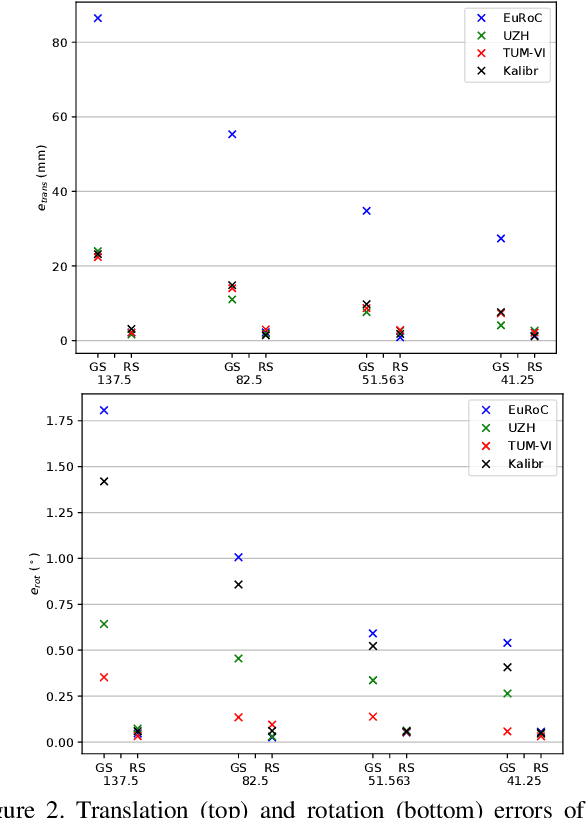
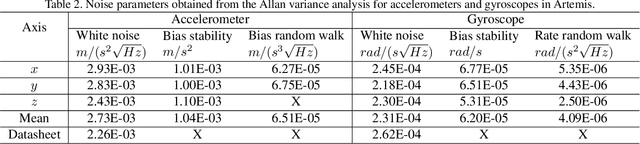
The rolling shutter (RS) mechanism is widely used by consumer-grade cameras, which are essential parts in smartphones and autonomous vehicles. The RS effect leads to image distortion upon relative motion between a camera and the scene. This effect needs to be considered in video stabilization, structure from motion, and vision-aided odometry, for which recent studies have improved earlier global shutter (GS) methods by accounting for the RS effect. However, it is still unclear how the RS affects spatiotemporal calibration of the camera in a sensor assembly, which is crucial to good performance in aforementioned applications. This work takes the camera-IMU system as an example and looks into the RS effect on its spatiotemporal calibration. To this end, we develop a calibration method for a RS-camera-IMU system with continuous-time B-splines by using a calibration target. Unlike in calibrating GS cameras, every observation of a landmark on the target has a unique camera pose fitted by continuous-time B-splines. With simulated data generated from four sets of public calibration data, we show that RS can noticeably affect the extrinsic parameters, causing errors about 1$^\circ$ in orientation and 2 $cm$ in translation with a RS setting as in common smartphone cameras. With real data collected by two industrial camera-IMU systems, we find that considering the RS effect gives more accurate and consistent spatiotemporal calibration. Moreover, our method also accurately calibrates the inter-line delay of the RS. The code for simulation and calibration is publicly available.
Improving Self-supervised Learning with Hardness-aware Dynamic Curriculum Learning: An Application to Digital Pathology
Aug 16, 2021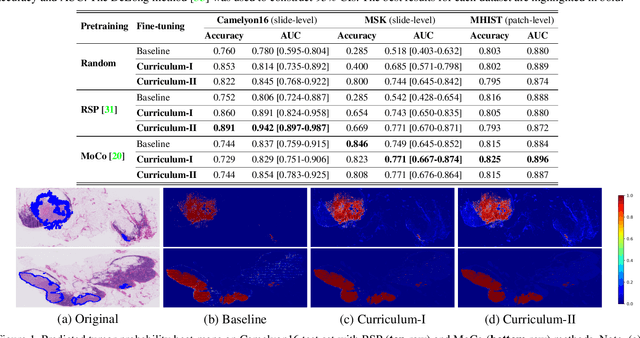
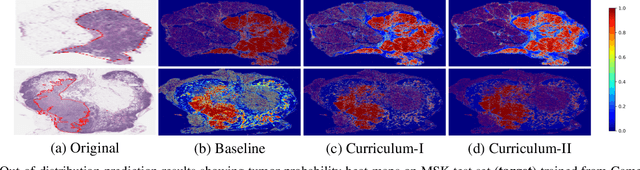
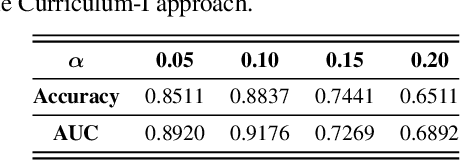
Self-supervised learning (SSL) has recently shown tremendous potential to learn generic visual representations useful for many image analysis tasks. Despite their notable success, the existing SSL methods fail to generalize to downstream tasks when the number of labeled training instances is small or if the domain shift between the transfer domains is significant. In this paper, we attempt to improve self-supervised pretrained representations through the lens of curriculum learning by proposing a hardness-aware dynamic curriculum learning (HaDCL) approach. To improve the robustness and generalizability of SSL, we dynamically leverage progressive harder examples via easy-to-hard and hard-to-very-hard samples during mini-batch downstream fine-tuning. We discover that by progressive stage-wise curriculum learning, the pretrained representations are significantly enhanced and adaptable to both in-domain and out-of-domain distribution data. We performed extensive validation on three histology benchmark datasets on both patch-wise and slide-level classification problems. Our curriculum based fine-tuning yields a significant improvement over standard fine-tuning, with a minimum improvement in area-under-the-curve (AUC) score of 1.7% and 2.2% on in-domain and out-of-domain distribution data, respectively. Further, we empirically show that our approach is more generic and adaptable to any SSL methods and does not impose any additional overhead complexity. Besides, we also outline the role of patch-based versus slide-based curriculum learning in histopathology to provide practical insights into the success of curriculum based fine-tuning of SSL methods. Code will be released at https://github.com/srinidhiPY/ICCVCDPATH2021-ID-8
Assessing the applicability of Deep Learning-based visible-infrared fusion methods for fire imagery
Jan 27, 2021
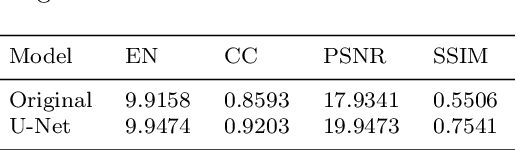
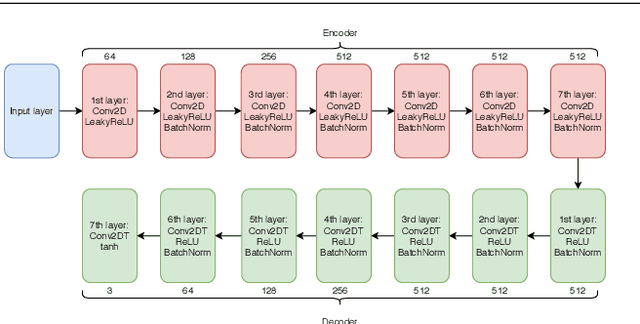
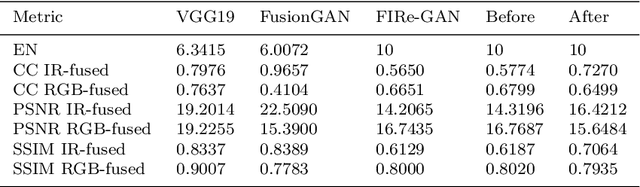
Early wildfire detection is of paramount importance to avoid as much damage as possible to the environment, properties, and lives. Deep Learning (DL) models that can leverage both visible and infrared information have the potential to display state-of-the-art performance, with lower false-positive rates than existing techniques. However, most DL-based image fusion methods have not been evaluated in the domain of fire imagery. Additionally, to the best of our knowledge, no publicly available dataset contains visible-infrared fused fire images. There is a growing interest in DL-based image fusion techniques due to their reduced complexity. Due to the latter, we select three state-of-the-art, DL-based image fusion techniques and evaluate them for the specific task of fire image fusion. We compare the performance of these methods on selected metrics. Finally, we also present an extension to one of the said methods, that we called FIRe-GAN, that improves the generation of artificial infrared images and fused ones on selected metrics.
Revisiting the Calibration of Modern Neural Networks
Jun 15, 2021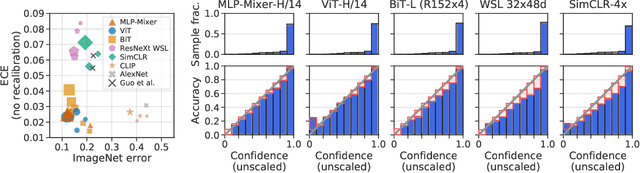

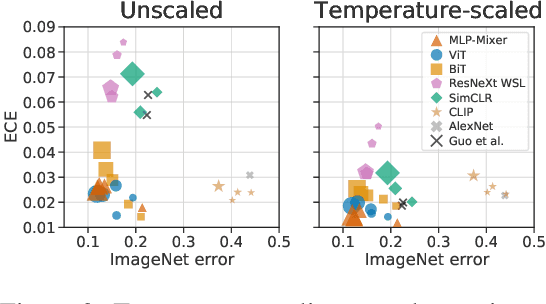
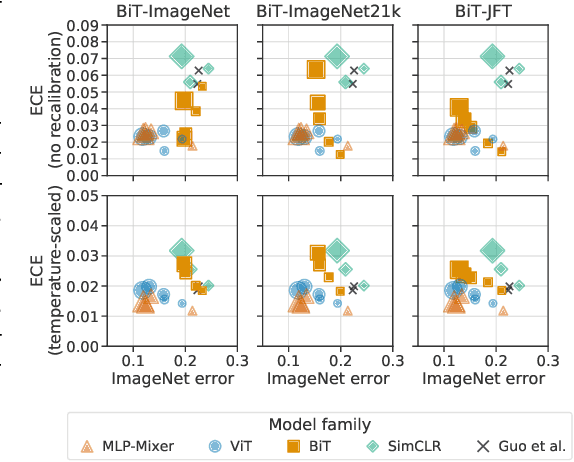
Accurate estimation of predictive uncertainty (model calibration) is essential for the safe application of neural networks. Many instances of miscalibration in modern neural networks have been reported, suggesting a trend that newer, more accurate models produce poorly calibrated predictions. Here, we revisit this question for recent state-of-the-art image classification models. We systematically relate model calibration and accuracy, and find that the most recent models, notably those not using convolutions, are among the best calibrated. Trends observed in prior model generations, such as decay of calibration with distribution shift or model size, are less pronounced in recent architectures. We also show that model size and amount of pretraining do not fully explain these differences, suggesting that architecture is a major determinant of calibration properties.
SCNet: Enhancing Few-Shot Semantic Segmentation by Self-Contrastive Background Prototypes
Apr 28, 2021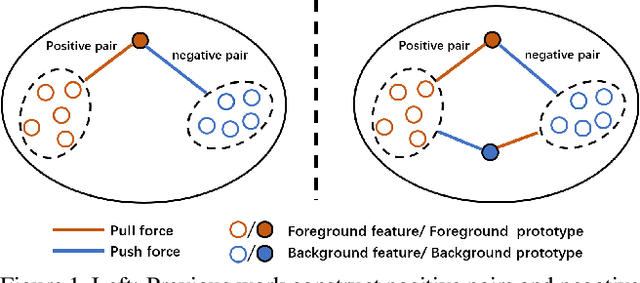
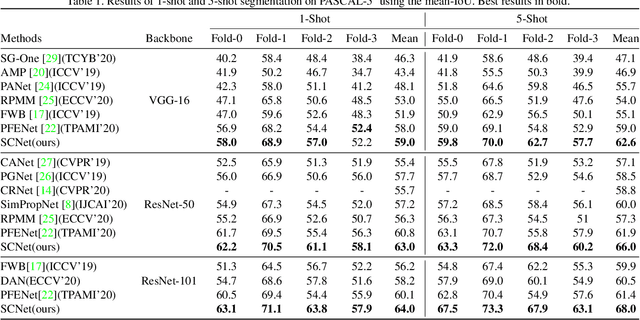
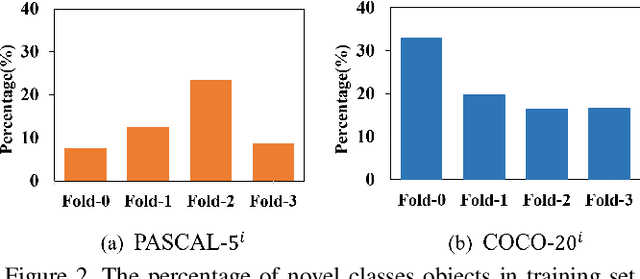
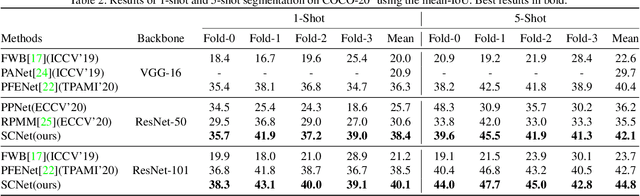
Few-shot semantic segmentation aims to segment novel-class objects in a query image with only a few annotated examples in support images. Most of advanced solutions exploit a metric learning framework that performs segmentation through matching each pixel to a learned foreground prototype. However, this framework suffers from biased classification due to incomplete construction of sample pairs with the foreground prototype only. To address this issue, in this paper, we introduce a complementary self-contrastive task into few-shot semantic segmentation. Our new model is able to associate the pixels in a region with the prototype of this region, no matter they are in the foreground or background. To this end, we generate self-contrastive background prototypes directly from the query image, with which we enable the construction of complete sample pairs and thus a complementary and auxiliary segmentation task to achieve the training of a better segmentation model. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ demonstrate clearly the superiority of our proposal. At no expense of inference efficiency, our model achieves state-of-the results in both 1-shot and 5-shot settings for few-shot semantic segmentation.
Autonomous Navigation of an Ultrasound Probe Towards Standard Scan Planes with Deep Reinforcement Learning
Mar 01, 2021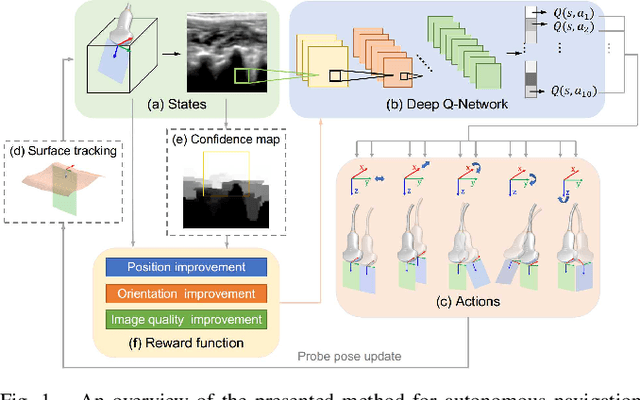

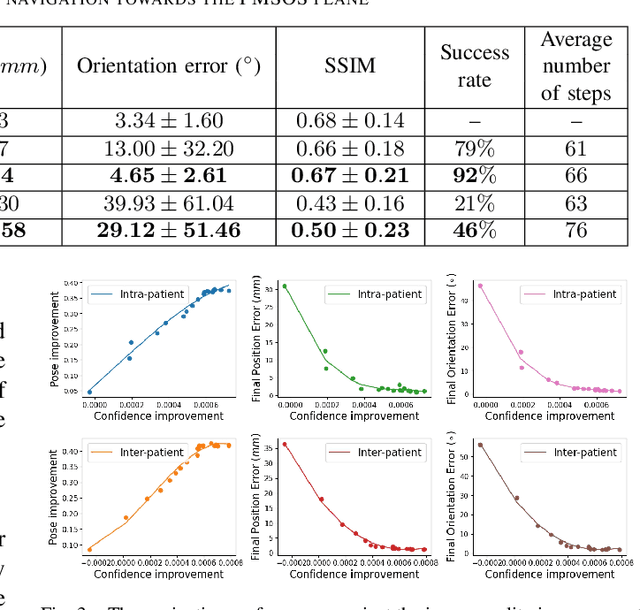

Autonomous ultrasound (US) acquisition is an important yet challenging task, as it involves interpretation of the highly complex and variable images and their spatial relationships. In this work, we propose a deep reinforcement learning framework to autonomously control the 6-D pose of a virtual US probe based on real-time image feedback to navigate towards the standard scan planes under the restrictions in real-world US scans. Furthermore, we propose a confidence-based approach to encode the optimization of image quality in the learning process. We validate our method in a simulation environment built with real-world data collected in the US imaging of the spine. Experimental results demonstrate that our method can perform reproducible US probe navigation towards the standard scan plane with an accuracy of $4.91mm/4.65^\circ$ in the intra-patient setting, and accomplish the task in the intra- and inter-patient settings with a success rate of $92\%$ and $46\%$, respectively. The results also show that the introduction of image quality optimization in our method can effectively improve the navigation performance.
Predictive Image Regression for Longitudinal Studies with Missing Data
Aug 19, 2018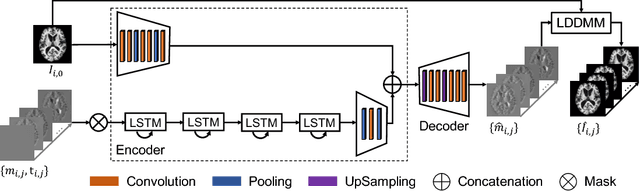
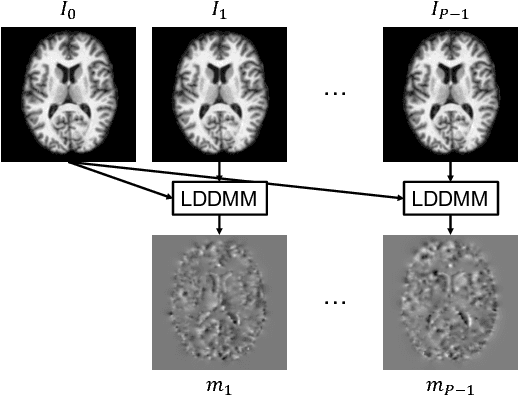
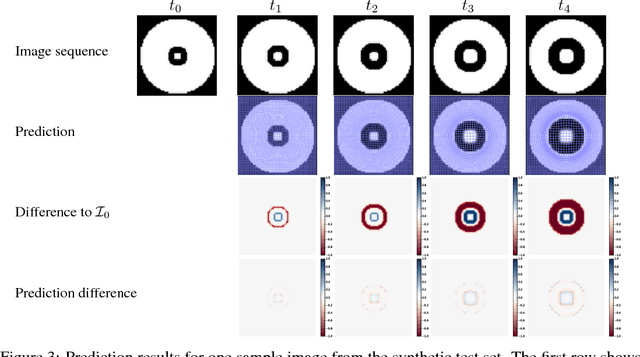
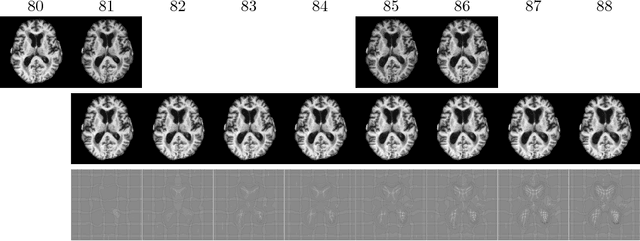
In this paper, we propose a predictive regression model for longitudinal images with missing data based on large deformation diffeomorphic metric mapping (LDDMM) and deep neural networks. Instead of directly predicting image scans, our model predicts a vector momentum sequence associated with a baseline image. This momentum sequence parameterizes the original image sequence in the LDDMM framework and lies in the tangent space of the baseline image, which is Euclidean. A recurrent network with long term-short memory (LSTM) units encodes the time-varying changes in the vector-momentum sequence, and a convolutional neural network (CNN) encodes the baseline image of the vector momenta. Features extracted by the LSTM and CNN are fed into a decoder network to reconstruct the vector momentum sequence, which is used for the image sequence prediction by deforming the baseline image with LDDMM shooting. To handle the missing images at some time points, we adopt a binary mask to ignore their reconstructions in the loss calculation. We evaluate our model on synthetically generated images and the brain MRIs from the OASIS dataset. Experimental results demonstrate the promising predictions of the spatiotemporal changes in both datasets, irrespective of large or subtle changes in longitudinal image sequences.