 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Feature Semi-Supervised Learning for COVID-19 Diagnosis from Chest X-ray Images
Apr 04, 2021
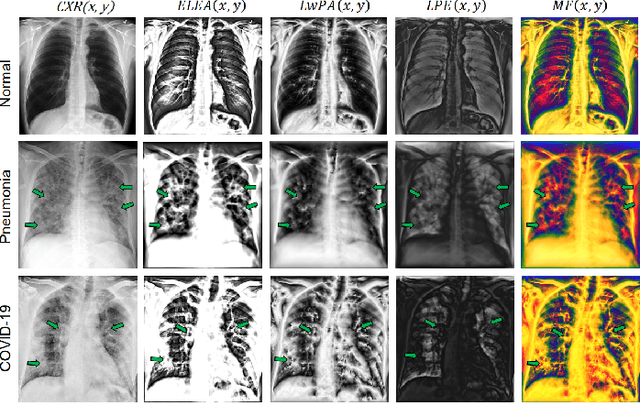

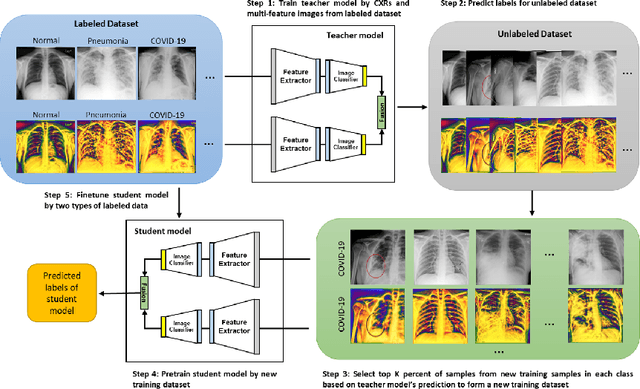
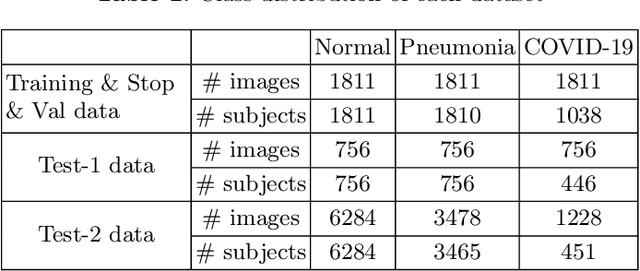
Computed tomography (CT) and chest X-ray (CXR) have been the two dominant imaging modalities deployed for improved management of Coronavirus disease 2019 (COVID-19). Due to faster imaging, less radiation exposure, and being cost-effective CXR is preferred over CT. However, the interpretation of CXR images, compared to CT, is more challenging due to low image resolution and COVID-19 image features being similar to regular pneumonia. Computer-aided diagnosis via deep learning has been investigated to help mitigate these problems and help clinicians during the decision-making process. The requirement for a large amount of labeled data is one of the major problems of deep learning methods when deployed in the medical domain. To provide a solution to this, in this work, we propose a semi-supervised learning (SSL) approach using minimal data for training. We integrate local-phase CXR image features into a multi-feature convolutional neural network architecture where the training of SSL method is obtained with a teacher/student paradigm. Quantitative evaluation is performed on 8,851 normal (healthy), 6,045 pneumonia, and 3,795 COVID-19 CXR scans. By only using 7.06% labeled and 16.48% unlabeled data for training, 5.53% for validation, our method achieves 93.61\% mean accuracy on a large-scale (70.93%) test data. We provide comparison results against fully supervised and SSL methods.
iNNformant: Boundary Samples as Telltale Watermarks
Jun 14, 2021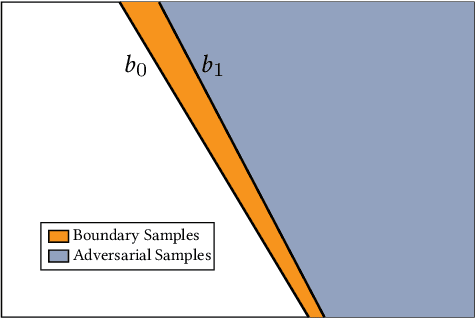

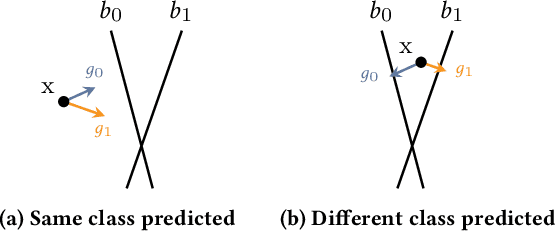
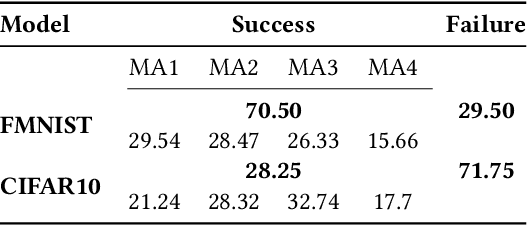
Boundary samples are special inputs to artificial neural networks crafted to identify the execution environment used for inference by the resulting output label. The paper presents and evaluates algorithms to generate transparent boundary samples. Transparency refers to a small perceptual distortion of the host signal (i.e., a natural input sample). For two established image classifiers, ResNet on FMNIST and CIFAR10, we show that it is possible to generate sets of boundary samples which can identify any of four tested microarchitectures. These sets can be built to not contain any sample with a worse peak signal-to-noise ratio than 70dB. We analyze the relationship between search complexity and resulting transparency.
Context-Aware Text-Based Binary Image Stylization and Synthesis
Oct 09, 2018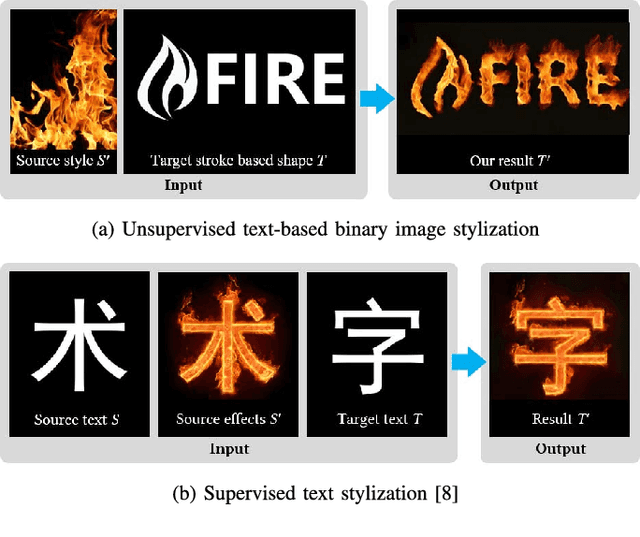



In this work, we present a new framework for the stylization of text-based binary images. First, our method stylizes the stroke-based geometric shape like text, symbols and icons in the target binary image based on an input style image. Second, the composition of the stylized geometric shape and a background image is explored. To accomplish the task, we propose legibility-preserving structure and texture transfer algorithms, which progressively narrow the visual differences between the binary image and the style image. The stylization is then followed by a context-aware layout design algorithm, where cues for both seamlessness and aesthetics are employed to determine the optimal layout of the shape in the background. Given the layout, the binary image is seamlessly embedded into the background by texture synthesis under a context-aware boundary constraint. According to the contents of binary images, our method can be applied to many fields. We show that the proposed method is capable of addressing the unsupervised text stylization problem and is superior to state-of-the-art style transfer methods in automatic artistic typography creation. Besides, extensive experiments on various tasks, such as visual-textual presentation synthesis, icon/symbol rendering and structure-guided image inpainting, demonstrate the effectiveness of the proposed method.
ScreenSeg: On-Device Screenshot Layout Analysis
Apr 21, 2021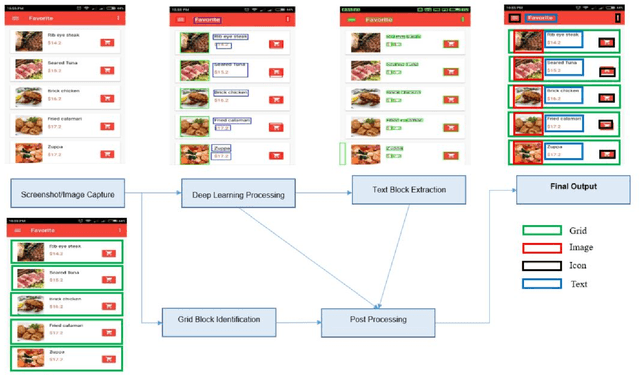
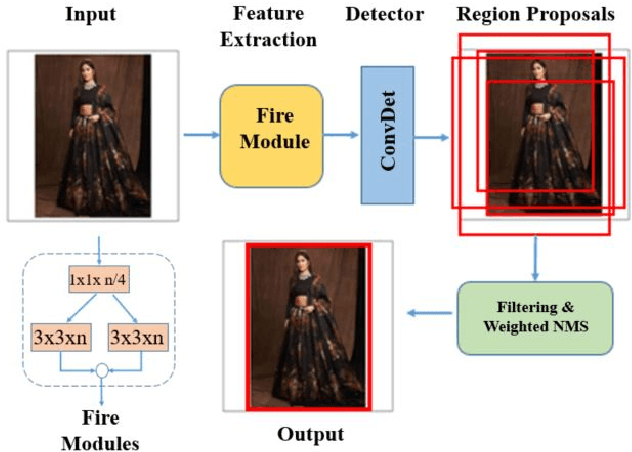
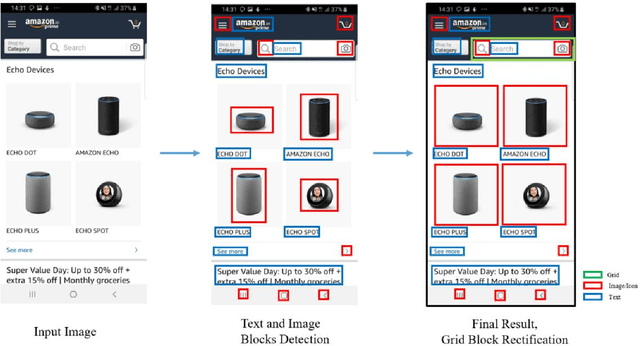
We propose a novel end-to-end solution that performs a Hierarchical Layout Analysis of screenshots and document images on resource constrained devices like mobilephones. Our approach segments entities like Grid, Image, Text and Icon blocks occurring in a screenshot. We provide an option for smart editing by auto highlighting these entities for saving or sharing. Further this multi-level layout analysis of screenshots has many use cases including content extraction, keyword-based image search, style transfer, etc. We have addressed the limitations of known baseline approaches, supported a wide variety of semantically complex screenshots, and developed an approach which is highly optimized for on-device deployment. In addition, we present a novel weighted NMS technique for filtering object proposals. We achieve an average precision of about 0.95 with a latency of around 200ms on Samsung Galaxy S10 Device for a screenshot of 1080p resolution. The solution pipeline is already commercialized in Samsung Device applications i.e. Samsung Capture, Smart Crop, My Filter in Camera Application, Bixby Touch.
Optimal Feature Transport for Cross-View Image Geo-Localization
Jul 12, 2019

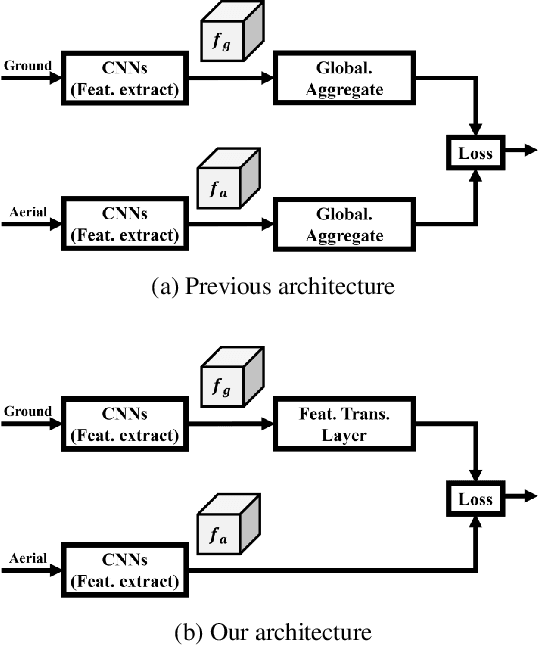

This paper addresses the problem of cross-view image based localization, where the geographic location of a ground-level street-view query image is estimated by matching it against a large scale aerial map (e.g., a high-resolution satellite image). State-of-the-art deep-learning based methods tackle this problem as deep metric learning which aims to learn global feature representations of the scene seen by the two different views. Despite promising results are obtained by such deep metric learning methods, they, however, fail to exploit a crucial cue relevant for localization, namely, the spatial layout of local features. Moreover, little attention is paid to the obvious domain gap (between aerial view and ground view) in the context of cross-view localization. This paper proposes a novel Cross-View Feature Transport (CVFT) technique to explicitly establish cross-view domain transfer that facilitates feature alignment between ground and aerial images. Specifically, we implement the CVFT as a network layer, which transports features from one domain to the other, leading to more meaningful feature similarity comparison. Our model is differentiable and can be learned end-to-end. Experiments on large-scale datasets have demonstrated that our method has remarkably boosted the state-of-the-art cross-view localization performance, e.g., on the CVUSA dataset, with significant improvements for top-1 recall from 40.79% to 61.43%, and for top-10 from 76.36% to 90.49%, compared with the previous state of the art [14]. We expect the key insight of the paper (i.e., explicitly handling domain difference via domain transport) will prove to be useful for other similar problems in computer vision as well.
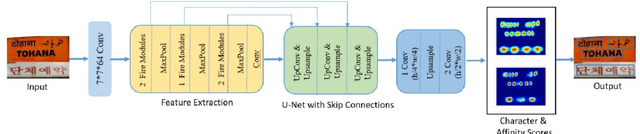
A modular U-Net for automated segmentation of X-ray tomography images in composite materials
Jul 15, 2021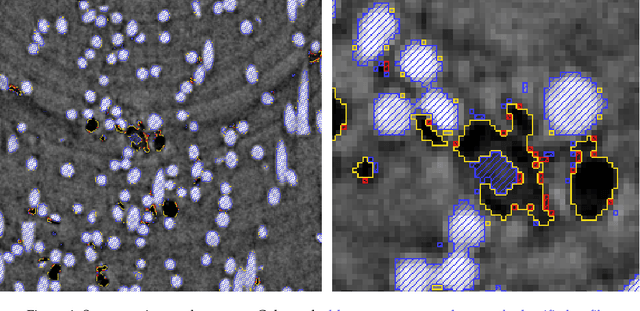
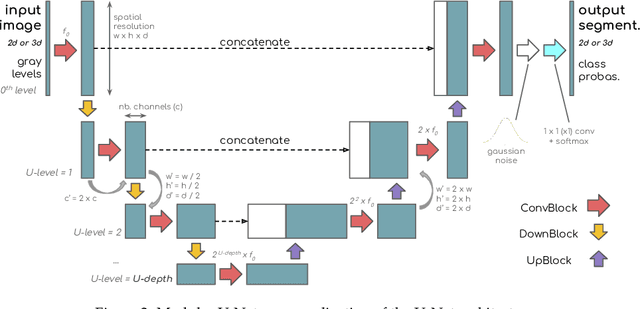
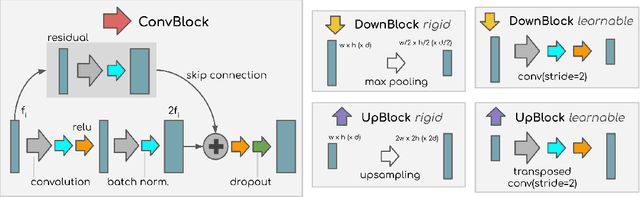

X-ray Computed Tomography (XCT) techniques have evolved to a point that high-resolution data can be acquired so fast that classic segmentation methods are prohibitively cumbersome, demanding automated data pipelines capable of dealing with non-trivial 3D images. Deep learning has demonstrated success in many image processing tasks, including material science applications, showing a promising alternative for a humanfree segmentation pipeline. In this paper a modular interpretation of UNet (Modular U-Net) is proposed and trained to segment 3D tomography images of a three-phased glass fiber-reinforced Polyamide 66. We compare 2D and 3D versions of our model, finding that the former is slightly better than the latter. We observe that human-comparable results can be achievied even with only 10 annotated layers and using a shallow U-Net yields better results than a deeper one. As a consequence, Neural Network (NN) show indeed a promising venue to automate XCT data processing pipelines needing no human, adhoc intervention.
TrTr: Visual Tracking with Transformer
May 09, 2021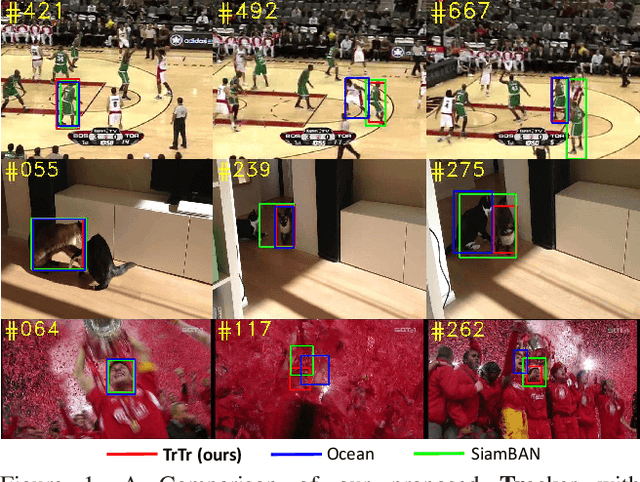
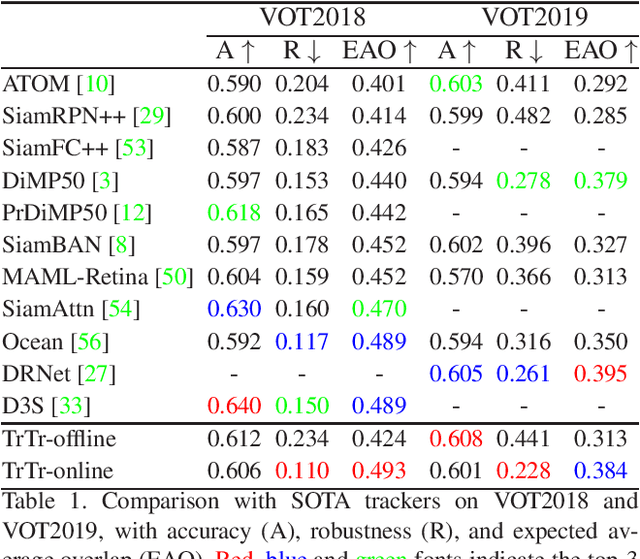
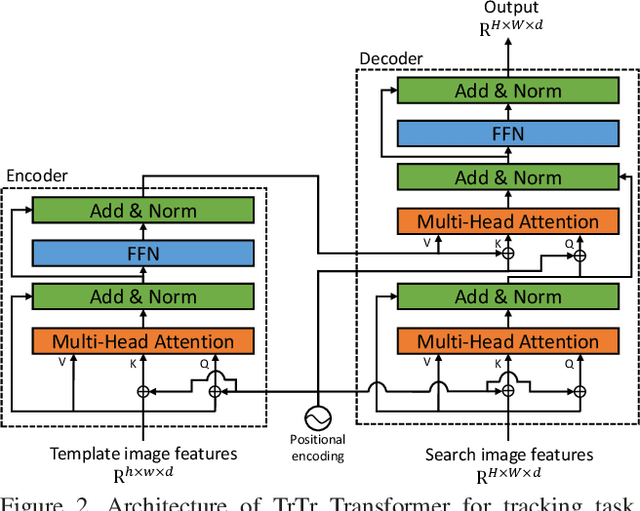
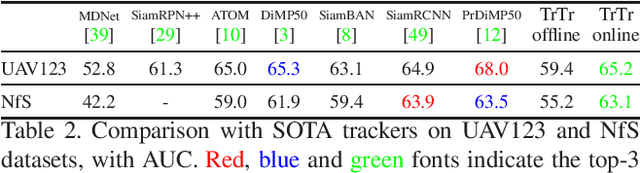
Template-based discriminative trackers are currently the dominant tracking methods due to their robustness and accuracy, and the Siamese-network-based methods that depend on cross-correlation operation between features extracted from template and search images show the state-of-the-art tracking performance. However, general cross-correlation operation can only obtain relationship between local patches in two feature maps. In this paper, we propose a novel tracker network based on a powerful attention mechanism called Transformer encoder-decoder architecture to gain global and rich contextual interdependencies. In this new architecture, features of the template image is processed by a self-attention module in the encoder part to learn strong context information, which is then sent to the decoder part to compute cross-attention with the search image features processed by another self-attention module. In addition, we design the classification and regression heads using the output of Transformer to localize target based on shape-agnostic anchor. We extensively evaluate our tracker TrTr, on VOT2018, VOT2019, OTB-100, UAV, NfS, TrackingNet, and LaSOT benchmarks and our method performs favorably against state-of-the-art algorithms. Training code and pretrained models are available at https://github.com/tongtybj/TrTr.
Some open questions on morphological operators and representations in the deep learning era
May 04, 2021During recent years, the renaissance of neural networks as the major machine learning paradigm and more specifically, the confirmation that deep learning techniques provide state-of-the-art results for most of computer vision tasks has been shaking up traditional research in image processing. The same can be said for research in communities working on applied harmonic analysis, information geometry, variational methods, etc. For many researchers, this is viewed as an existential threat. On the one hand, research funding agencies privilege mainstream approaches especially when these are unquestionably suitable for solving real problems and for making progress on artificial intelligence. On the other hand, successful publishing of research in our communities is becoming almost exclusively based on a quantitative improvement of the accuracy of any benchmark task. As most of my colleagues sharing this research field, I am confronted with the dilemma of continuing to invest my time and intellectual effort on mathematical morphology as my driving force for research, or simply focussing on how to use deep learning and contributing to it. The solution is not obvious to any of us since our research is not fundamental, it is just oriented to solve challenging problems, which can be more or less theoretical. Certainly, it would be foolish for anyone to claim that deep learning is insignificant or to think that one's favourite image processing domain is productive enough to ignore the state-of-the-art. I fully understand that the labs and leading people in image processing communities have been shifting their research to almost exclusively focus on deep learning techniques. My own position is different: I do think there is room for progress on mathematically grounded image processing branches, under the condition that these are rethought in a broader sense from the deep learning paradigm. Indeed, I firmly believe that the convergence between mathematical morphology and the computation methods which gravitate around deep learning (fully connected networks, convolutional neural networks, residual neural networks, recurrent neural networks, etc.) is worthwhile. The goal of this talk is to discuss my personal vision regarding these potential interactions. Without any pretension of being exhaustive, I want to address it with a series of open questions, covering a wide range of specificities of morphological operators and representations, which could be tackled and revisited under the paradigm of deep learning. An expected benefit of such convergence between morphology and deep learning is a cross-fertilization of concepts and techniques between both fields. In addition, I think the future answer to some of these questions can provide some insight on understanding, interpreting and simplifying deep learning networks.
Non-blind Image Restoration Based on Convolutional Neural Network
Sep 11, 2018
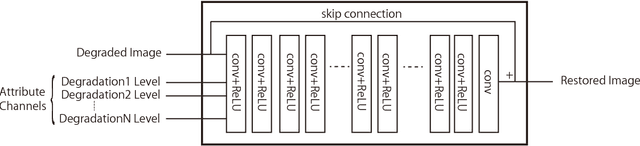

Blind image restoration processors based on convolutional neural network (CNN) are intensively researched because of their high performance. However, they are too sensitive to the perturbation of the degradation model. They easily fail to restore the image whose degradation model is slightly different from the trained degradation model. In this paper, we propose a non-blind CNN-based image restoration processor, aiming to be robust against a perturbation of the degradation model compared to the blind restoration processor. Experimental comparisons demonstrate that the proposed non-blind CNN-based image restoration processor can robustly restore images compared to existing blind CNN-based image restoration processors.
Efficient data-driven encoding of scene motion using Eccentricity
Mar 03, 2021
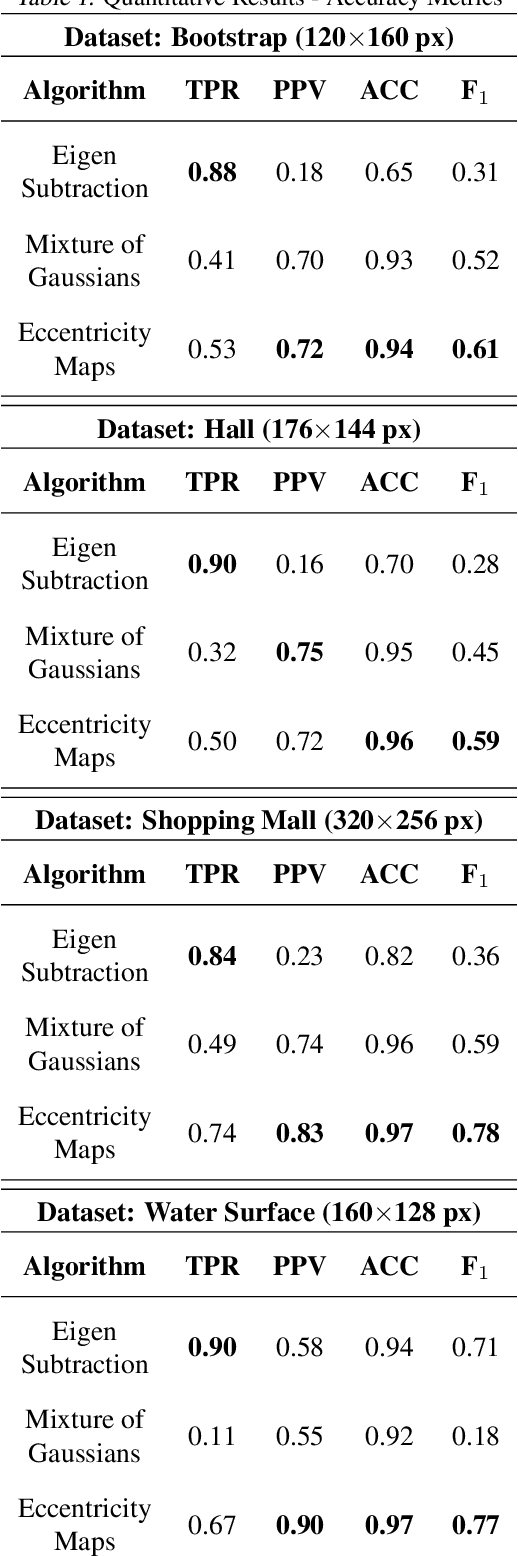

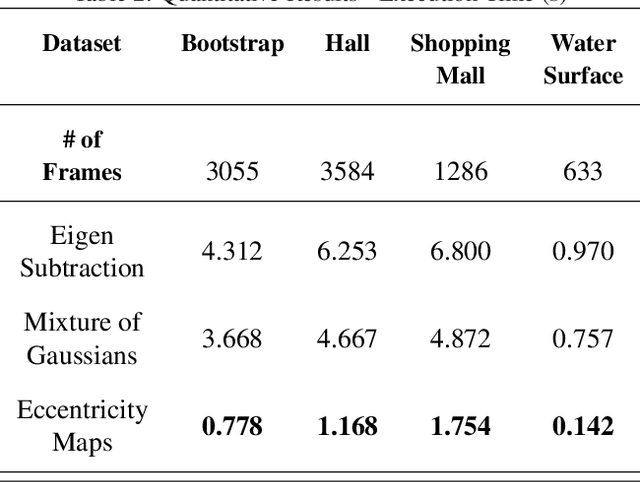
This paper presents a novel approach of representing dynamic visual scenes with static maps generated from video/image streams. Such representation allows easy visual assessment of motion in dynamic environments. These maps are 2D matrices calculated recursively, in a pixel-wise manner, that is based on the recently introduced concept of Eccentricity data analysis. Eccentricity works as a metric of a discrepancy between a particular pixel of an image and its normality model, calculated in terms of mean and variance of past readings of the same spatial region of the image. While Eccentricity maps carry temporal information about the scene, actual images do not need to be stored nor processed in batches. Rather, all the calculations are done recursively, based on a small amount of statistical information stored in memory, thus resulting in a very computationally efficient (processor- and memory-wise) method. The list of potential applications includes video-based activity recognition, intent recognition, object tracking, video description, and so on.