 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Interpretable Algorithm for Uveal Melanoma Subtyping from Whole Slide Cytology Images
Aug 13, 2021
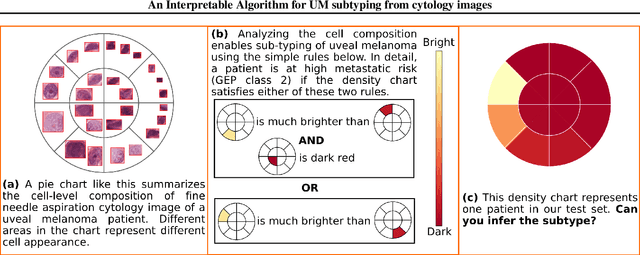

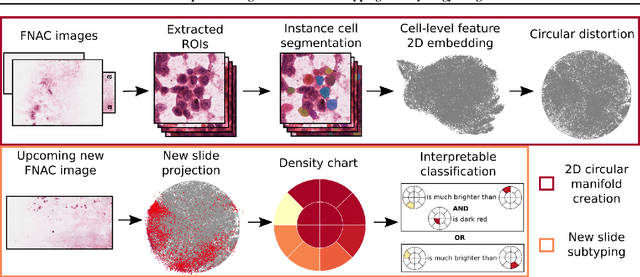
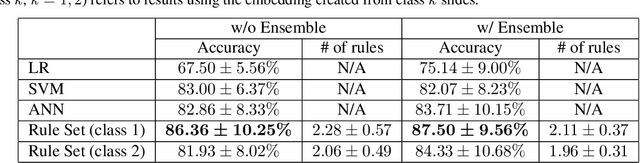
Algorithmic decision support is rapidly becoming a staple of personalized medicine, especially for high-stakes recommendations in which access to certain information can drastically alter the course of treatment, and thus, patient outcome; a prominent example is radiomics for cancer subtyping. Because in these scenarios the stakes are high, it is desirable for decision systems to not only provide recommendations but supply transparent reasoning in support thereof. For learning-based systems, this can be achieved through an interpretable design of the inference pipeline. Herein we describe an automated yet interpretable system for uveal melanoma subtyping with digital cytology images from fine needle aspiration biopsies. Our method embeds every automatically segmented cell of a candidate cytology image as a point in a 2D manifold defined by many representative slides, which enables reasoning about the cell-level composition of the tissue sample, paving the way for interpretable subtyping of the biopsy. Finally, a rule-based slide-level classification algorithm is trained on the partitions of the circularly distorted 2D manifold. This process results in a simple rule set that is evaluated automatically but highly transparent for human verification. On our in house cytology dataset of 88 uveal melanoma patients, the proposed method achieves an accuracy of 87.5% that compares favorably to all competing approaches, including deep "black box" models. The method comes with a user interface to facilitate interaction with cell-level content, which may offer additional insights for pathological assessment.
CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation
Jul 07, 2021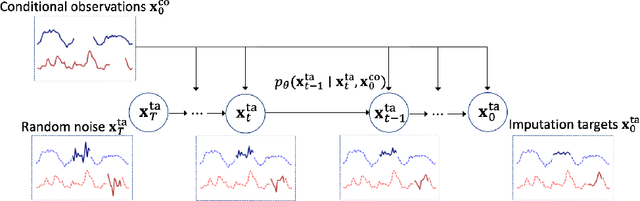

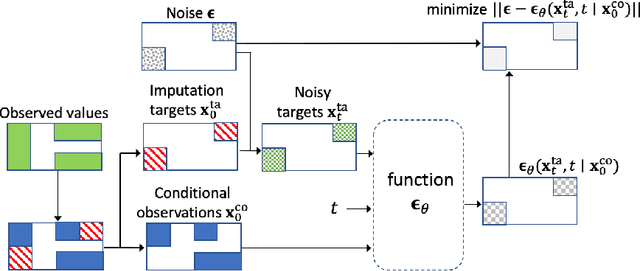
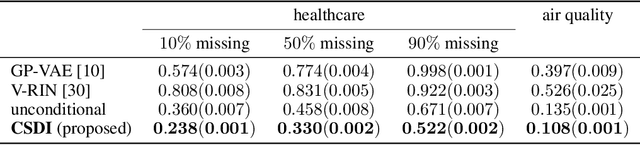
The imputation of missing values in time series has many applications in healthcare and finance. While autoregressive models are natural candidates for time series imputation, score-based diffusion models have recently outperformed existing counterparts including autoregressive models in many tasks such as image generation and audio synthesis, and would be promising for time series imputation. In this paper, we propose Conditional Score-based Diffusion models for Imputation (CSDI), a novel time series imputation method that utilizes score-based diffusion models conditioned on observed data. Unlike existing score-based approaches, the conditional diffusion model is explicitly trained for imputation and can exploit correlations between observed values. On healthcare and environmental data, CSDI improves by 40-70% over existing probabilistic imputation methods on popular performance metrics. In addition, deterministic imputation by CSDI reduces the error by 5-20% compared to the state-of-the-art deterministic imputation methods. Furthermore, CSDI can also be applied to time series interpolation and probabilistic forecasting, and is competitive with existing baselines.
A Diffeomorphic Aging Model for Adult Human Brain from Cross-Sectional Data
Jun 28, 2021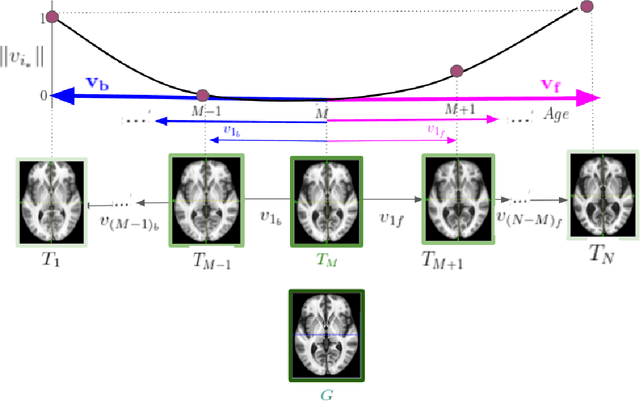
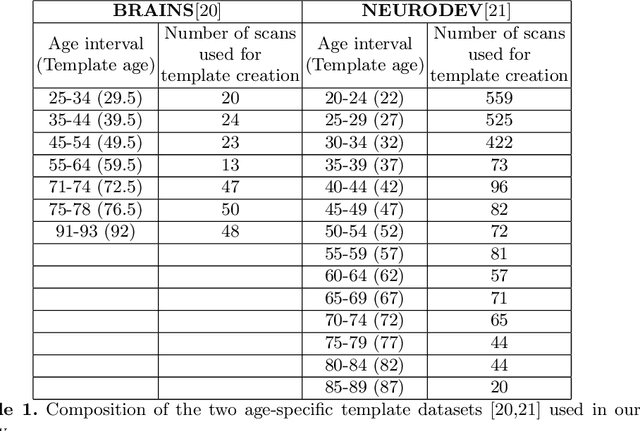
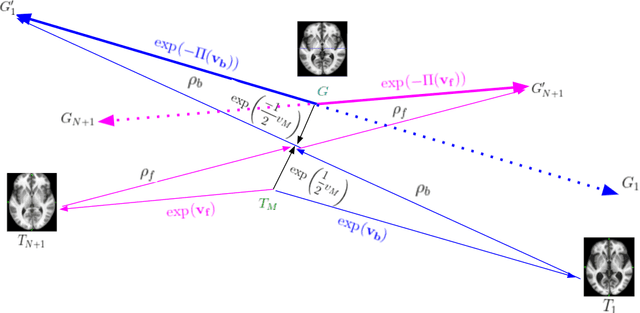
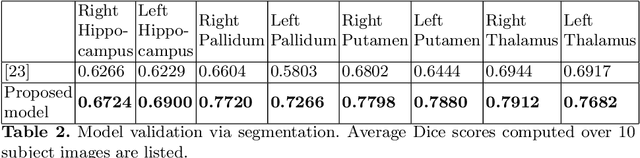
Normative aging trends of the brain can serve as an important reference in the assessment of neurological structural disorders. Such models are typically developed from longitudinal brain image data -- follow-up data of the same subject over different time points. In practice, obtaining such longitudinal data is difficult. We propose a method to develop an aging model for a given population, in the absence of longitudinal data, by using images from different subjects at different time points, the so-called cross-sectional data. We define an aging model as a diffeomorphic deformation on a structural template derived from the data and propose a method that develops topology preserving aging model close to natural aging. The proposed model is successfully validated on two public cross-sectional datasets which provide templates constructed from different sets of subjects at different age points.
A Remote Sensing Image Dataset for Cloud Removal
Jan 03, 2019

Cloud-based overlays are often present in optical remote sensing images, thus limiting the application of acquired data. Removing clouds is an indispensable pre-processing step in remote sensing image analysis. Deep learning has achieved great success in the field of remote sensing in recent years, including scene classification and change detection. However, deep learning is rarely applied in remote sensing image removal clouds. The reason is the lack of data sets for training neural networks. In order to solve this problem, this paper first proposed the Remote sensing Image Cloud rEmoving dataset (RICE). The proposed dataset consists of two parts: RICE1 contains 500 pairs of images, each pair has images with cloud and cloudless size of 512*512; RICE2 contains 450 sets of images, each set contains three 512*512 size images. , respectively, the reference picture without clouds, the picture of the cloud and the mask of its cloud. The dataset is freely available at \url{https://github.com/BUPTLdy/RICE_DATASET}.
CAT: Cross-Attention Transformer for One-Shot Object Detection
Apr 30, 2021
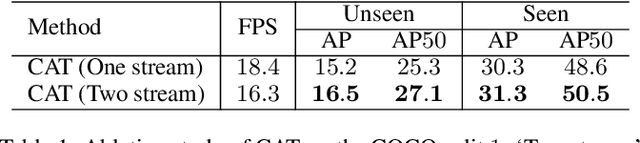
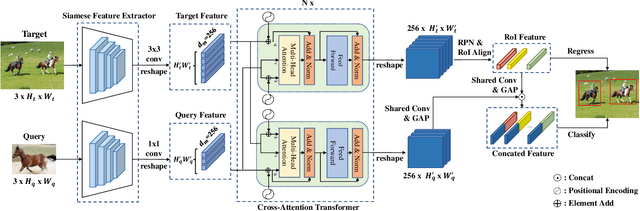
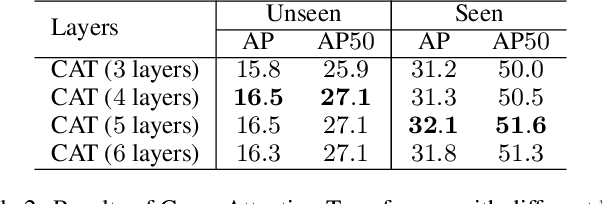
Given a query patch from a novel class, one-shot object detection aims to detect all instances of that class in a target image through the semantic similarity comparison. However, due to the extremely limited guidance in the novel class as well as the unseen appearance difference between query and target instances, it is difficult to appropriately exploit their semantic similarity and generalize well. To mitigate this problem, we present a universal Cross-Attention Transformer (CAT) module for accurate and efficient semantic similarity comparison in one-shot object detection. The proposed CAT utilizes transformer mechanism to comprehensively capture bi-directional correspondence between any paired pixels from the query and the target image, which empowers us to sufficiently exploit their semantic characteristics for accurate similarity comparison. In addition, the proposed CAT enables feature dimensionality compression for inference speedup without performance loss. Extensive experiments on COCO, VOC, and FSOD under one-shot settings demonstrate the effectiveness and efficiency of our method, e.g., it surpasses CoAE, a major baseline in this task by 1.0% in AP on COCO and runs nearly 2.5 times faster. Code will be available in the future.
Geometry Uncertainty Projection Network for Monocular 3D Object Detection
Aug 13, 2021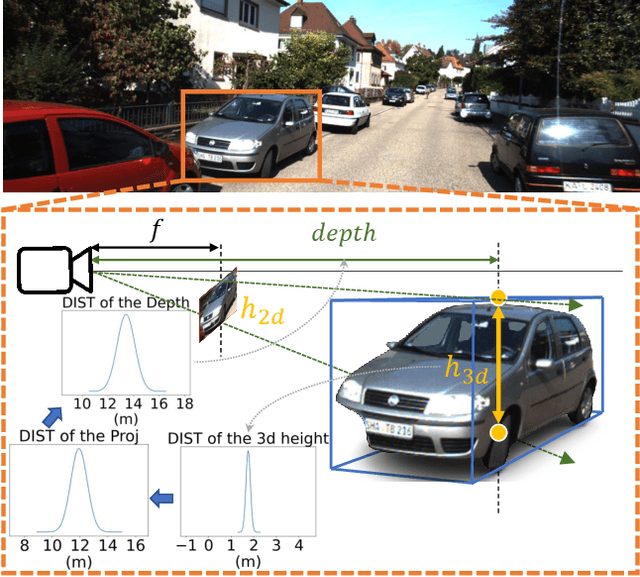
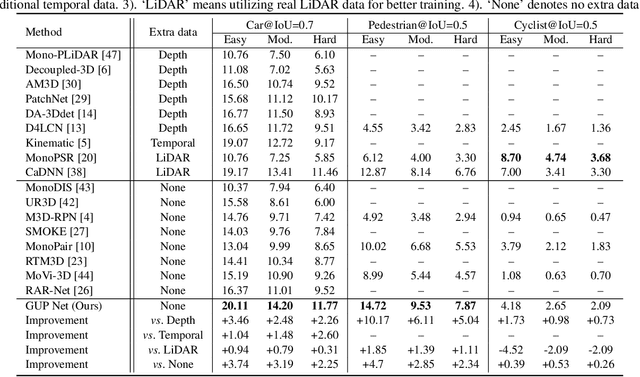
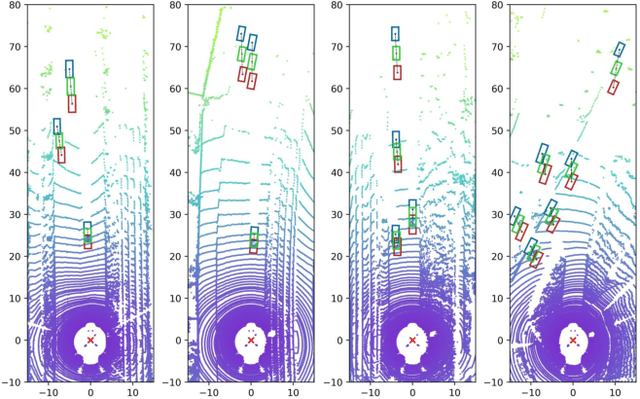
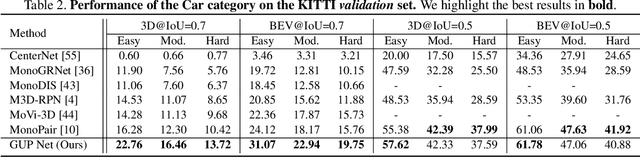
Geometry Projection is a powerful depth estimation method in monocular 3D object detection. It estimates depth dependent on heights, which introduces mathematical priors into the deep model. But projection process also introduces the error amplification problem, in which the error of the estimated height will be amplified and reflected greatly at the output depth. This property leads to uncontrollable depth inferences and also damages the training efficiency. In this paper, we propose a Geometry Uncertainty Projection Network (GUP Net) to tackle the error amplification problem at both inference and training stages. Specifically, a GUP module is proposed to obtains the geometry-guided uncertainty of the inferred depth, which not only provides high reliable confidence for each depth but also benefits depth learning. Furthermore, at the training stage, we propose a Hierarchical Task Learning strategy to reduce the instability caused by error amplification. This learning algorithm monitors the learning situation of each task by a proposed indicator and adaptively assigns the proper loss weights for different tasks according to their pre-tasks situation. Based on that, each task starts learning only when its pre-tasks are learned well, which can significantly improve the stability and efficiency of the training process. Extensive experiments demonstrate the effectiveness of the proposed method. The overall model can infer more reliable object depth than existing methods and outperforms the state-of-the-art image-based monocular 3D detectors by 3.74% and 4.7% AP40 of the car and pedestrian categories on the KITTI benchmark.
A New Ensemble Learning Framework for 3D Biomedical Image Segmentation
Dec 10, 2018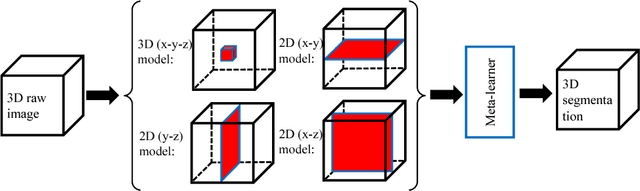
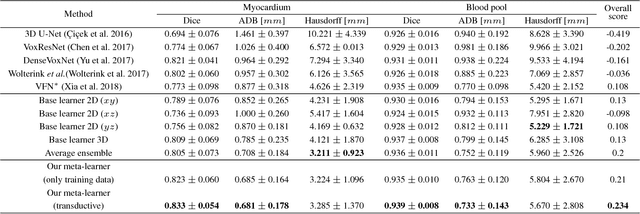
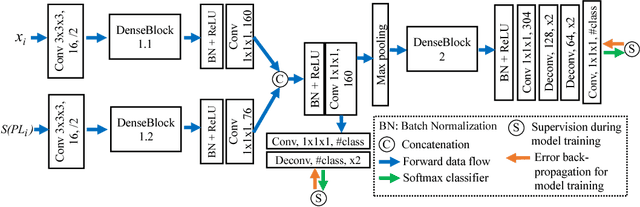
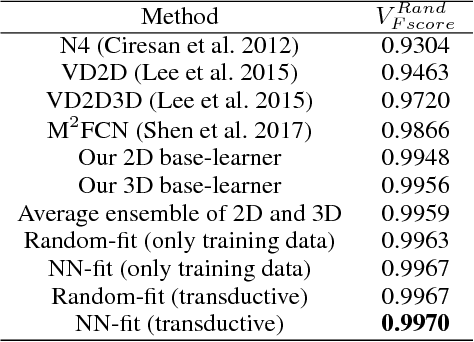
3D image segmentation plays an important role in biomedical image analysis. Many 2D and 3D deep learning models have achieved state-of-the-art segmentation performance on 3D biomedical image datasets. Yet, 2D and 3D models have their own strengths and weaknesses, and by unifying them together, one may be able to achieve more accurate results. In this paper, we propose a new ensemble learning framework for 3D biomedical image segmentation that combines the merits of 2D and 3D models. First, we develop a fully convolutional network based meta-learner to learn how to improve the results from 2D and 3D models (base-learners). Then, to minimize over-fitting for our sophisticated meta-learner, we devise a new training method that uses the results of the base-learners as multiple versions of "ground truths". Furthermore, since our new meta-learner training scheme does not depend on manual annotation, it can utilize abundant unlabeled 3D image data to further improve the model. Extensive experiments on two public datasets (the HVSMR 2016 Challenge dataset and the mouse piriform cortex dataset) show that our approach is effective under fully-supervised, semi-supervised, and transductive settings, and attains superior performance over state-of-the-art image segmentation methods.
Progressive Deep Video Dehazing without Explicit Alignment Estimation
Jul 16, 2021
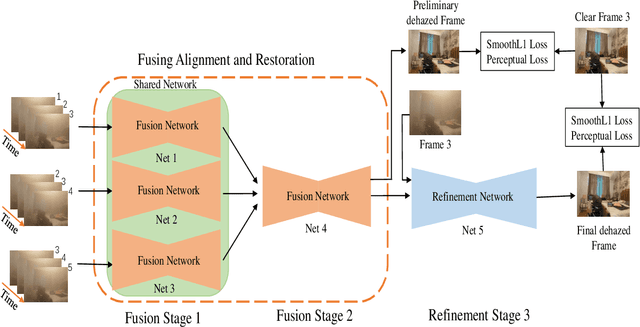
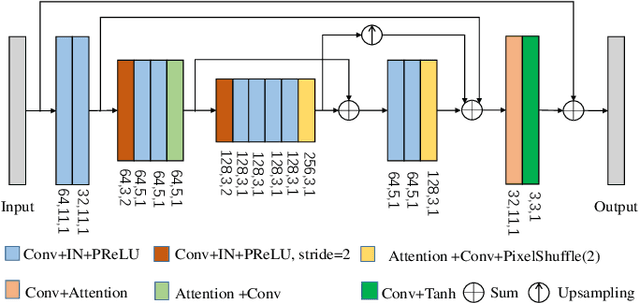
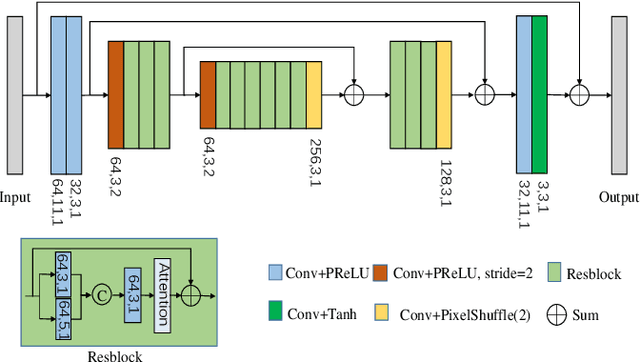
To solve the issue of video dehazing, there are two main tasks to attain: how to align adjacent frames to the reference frame; how to restore the reference frame. Some papers adopt explicit approaches (e.g., the Markov random field, optical flow, deformable convolution, 3D convolution) to align neighboring frames with the reference frame in feature space or image space, they then use various restoration methods to achieve the final dehazing results. In this paper, we propose a progressive alignment and restoration method for video dehazing. The alignment process aligns consecutive neighboring frames stage by stage without using the optical flow estimation. The restoration process is not only implemented under the alignment process but also uses a refinement network to improve the dehazing performance of the whole network. The proposed networks include four fusion networks and one refinement network. To decrease the parameters of networks, three fusion networks in the first fusion stage share the same parameters. Extensive experiments demonstrate that the proposed video dehazing method achieves outstanding performance against the-state-of-art methods.
Uniformity in Heterogeneity:Diving Deep into Count Interval Partition for Crowd Counting
Aug 07, 2021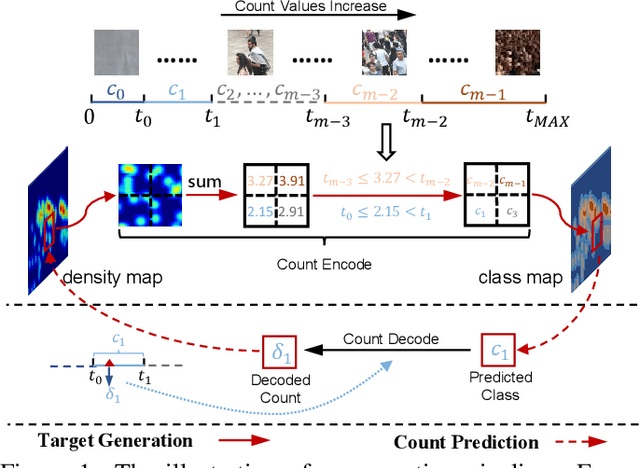
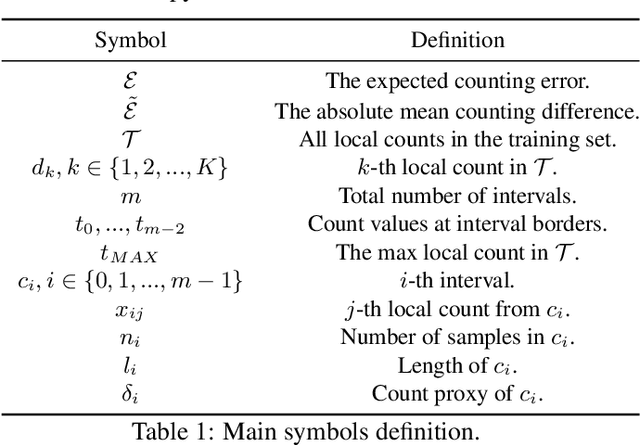
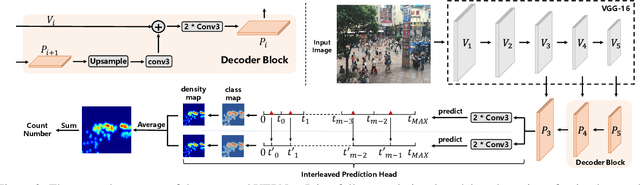
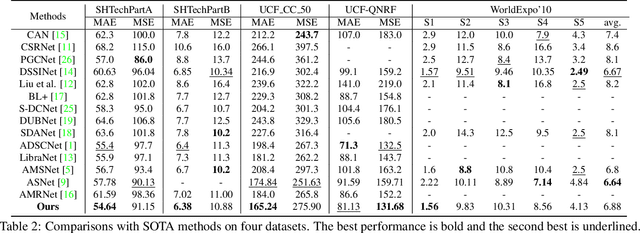
Recently, the problem of inaccurate learning targets in crowd counting draws increasing attention. Inspired by a few pioneering work, we solve this problem by trying to predict the indices of pre-defined interval bins of counts instead of the count values themselves. However, an inappropriate interval setting might make the count error contributions from different intervals extremely imbalanced, leading to inferior counting performance. Therefore, we propose a novel count interval partition criterion called Uniform Error Partition (UEP), which always keeps the expected counting error contributions equal for all intervals to minimize the prediction risk. Then to mitigate the inevitably introduced discretization errors in the count quantization process, we propose another criterion called Mean Count Proxies (MCP). The MCP criterion selects the best count proxy for each interval to represent its count value during inference, making the overall expected discretization error of an image nearly negligible. As far as we are aware, this work is the first to delve into such a classification task and ends up with a promising solution for count interval partition. Following the above two theoretically demonstrated criterions, we propose a simple yet effective model termed Uniform Error Partition Network (UEPNet), which achieves state-of-the-art performance on several challenging datasets. The codes will be available at: https://github.com/TencentYoutuResearch/CrowdCounting-UEPNet.
A-FMI: Learning Attributions from Deep Networks via Feature Map Importance
Apr 12, 2021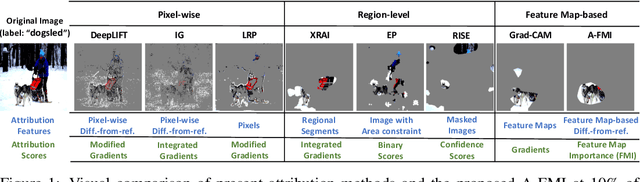

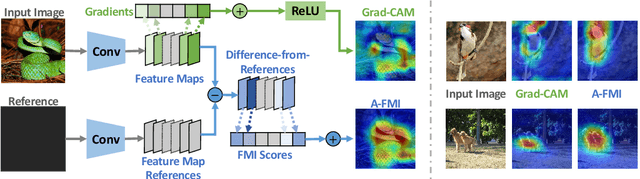
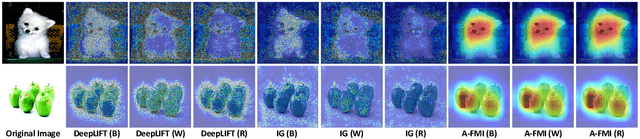
Gradient-based attribution methods can aid in the understanding of convolutional neural networks (CNNs). However, the redundancy of attribution features and the gradient saturation problem, which weaken the ability to identify significant features and cause an explanation focus shift, are challenges that attribution methods still face. In this work, we propose: 1) an essential characteristic, Strong Relevance, when selecting attribution features; 2) a new concept, feature map importance (FMI), to refine the contribution of each feature map, which is faithful to the CNN model; and 3) a novel attribution method via FMI, termed A-FMI, to address the gradient saturation problem, which couples the target image with a reference image, and assigns the FMI to the difference-from-reference at the granularity of feature map. Through visual inspections and qualitative evaluations on the ImageNet dataset, we show the compelling advantages of A-FMI on its faithfulness, insensitivity to the choice of reference, class discriminability, and superior explanation performance compared with popular attribution methods across varying CNN architectures.