 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SPeCiaL: Self-Supervised Pretraining for Continual Learning
Jun 16, 2021
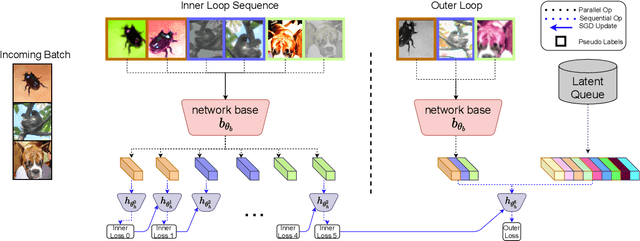
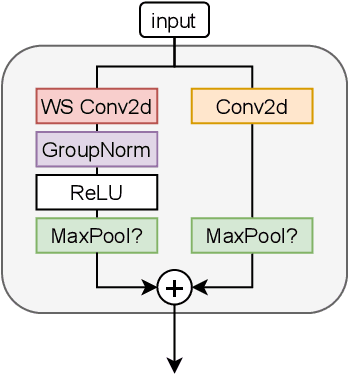
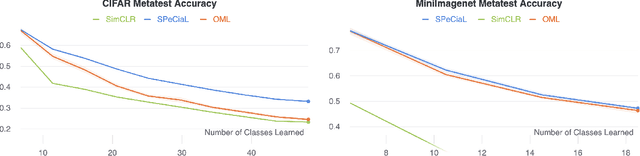
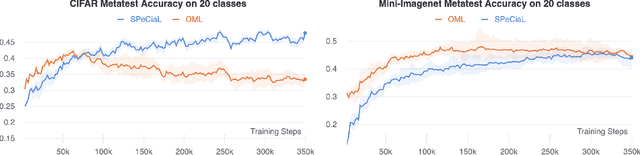
This paper presents SPeCiaL: a method for unsupervised pretraining of representations tailored for continual learning. Our approach devises a meta-learning objective that differentiates through a sequential learning process. Specifically, we train a linear model over the representations to match different augmented views of the same image together, each view presented sequentially. The linear model is then evaluated on both its ability to classify images it just saw, and also on images from previous iterations. This gives rise to representations that favor quick knowledge retention with minimal forgetting. We evaluate SPeCiaL in the Continual Few-Shot Learning setting, and show that it can match or outperform other supervised pretraining approaches.
Multi-scale Dynamic Graph Convolutional Network for Hyperspectral Image Classification
May 14, 2019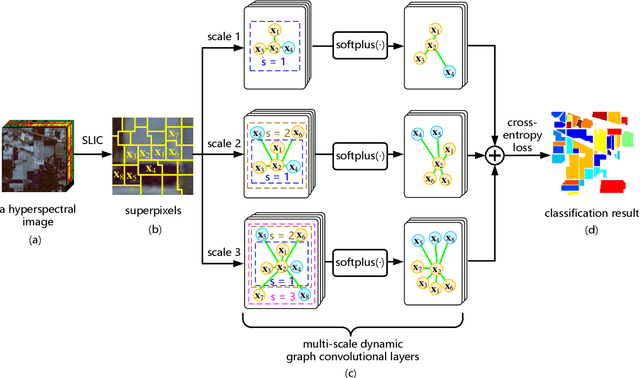
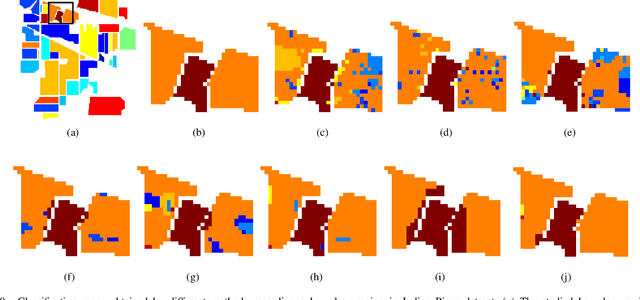
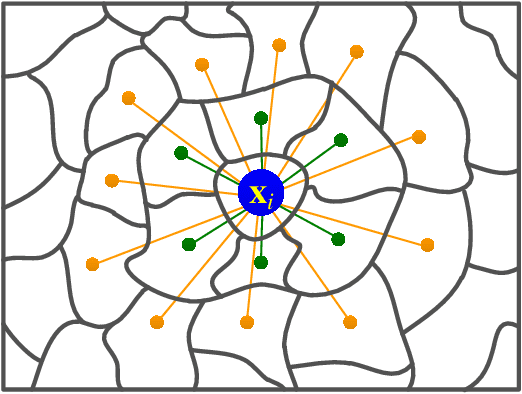
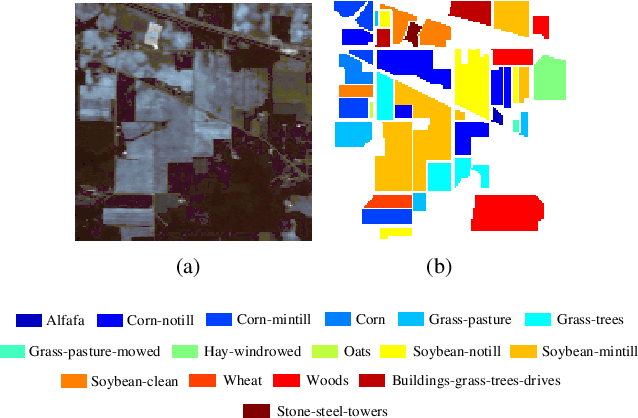
Convolutional Neural Network (CNN) has demonstrated impressive ability to represent hyperspectral images and to achieve promising results in hyperspectral image classification. However, traditional CNN models can only operate convolution on regular square image regions with fixed size and weights, so they cannot universally adapt to the distinct local regions with various object distributions and geometric appearances. Therefore, their classification performances are still to be improved, especially in class boundaries. To alleviate this shortcoming, we consider employing the recently proposed Graph Convolutional Network (GCN) for hyperspectral image classification, as it can conduct the convolution on arbitrarily structured non-Euclidean data and is applicable to the irregular image regions represented by graph topological information. Different from the commonly used GCN models which work on a fixed graph, we enable the graph to be dynamically updated along with the graph convolution process, so that these two steps can be benefited from each other to gradually produce the discriminative embedded features as well as a refined graph. Moreover, to comprehensively deploy the multi-scale information inherited by hyperspectral images, we establish multiple input graphs with different neighborhood scales to extensively exploit the diversified spectral-spatial correlations at multiple scales. Therefore, our method is termed 'Multi-scale Dynamic Graph Convolutional Network' (MDGCN). The experimental results on three typical benchmark datasets firmly demonstrate the superiority of the proposed MDGCN to other state-of-the-art methods in both qualitative and quantitative aspects.
XCycles Backprojection Acoustic Super-Resolution
May 19, 2021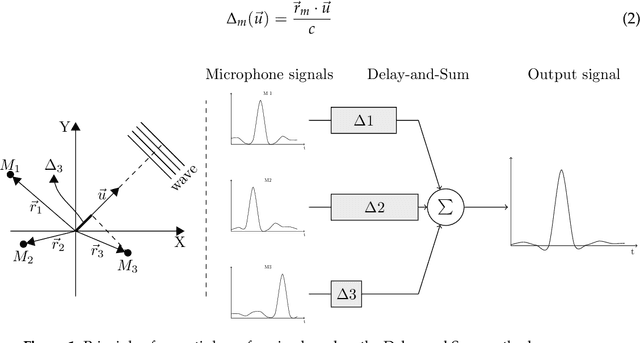
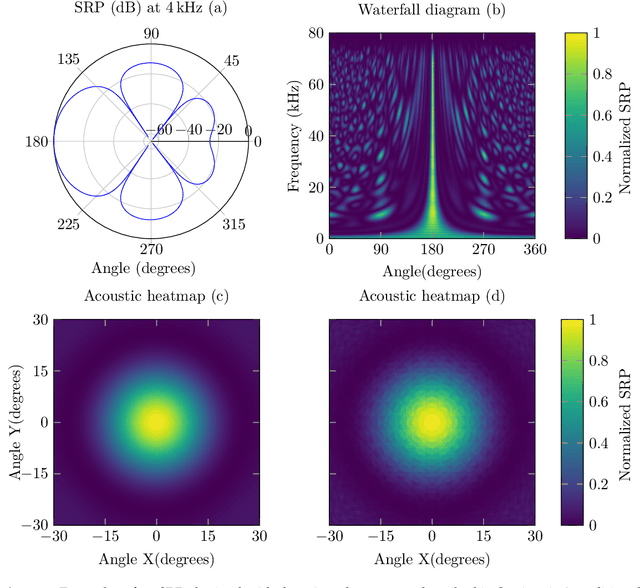
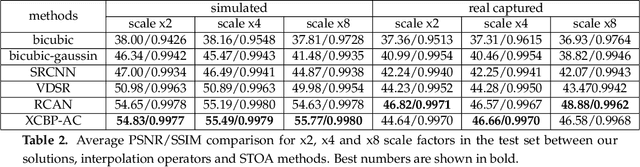
The computer vision community has paid much attention to the development of visible image super-resolution (SR) using deep neural networks (DNNs) and has achieved impressive results. The advancement of non-visible light sensors, such as acoustic imaging sensors, has attracted much attention, as they allow people to visualize the intensity of sound waves beyond the visible spectrum. However, because of the limitations imposed on acquiring acoustic data, new methods for improving the resolution of the acoustic images are necessary. At this time, there is no acoustic imaging dataset designed for the SR problem. This work proposed a novel backprojection model architecture for the acoustic image super-resolution problem, together with Acoustic Map Imaging VUB-ULB Dataset (AMIVU). The dataset provides large simulated and real captured images at different resolutions. The proposed XCycles BackProjection model (XCBP), in contrast to the feedforward model approach, fully uses the iterative correction procedure in each cycle to reconstruct the residual error correction for the encoded features in both low- and high-resolution space. The proposed approach was evaluated on the dataset and showed high outperformance compared to the classical interpolation operators and to the recent feedforward state-of-the-art models. It also contributed to a drastically reduced sub-sampling error produced during the data acquisition.
Patient-specific Conditional Joint Models of Shape, Image Features and Clinical Indicators
Jul 17, 2019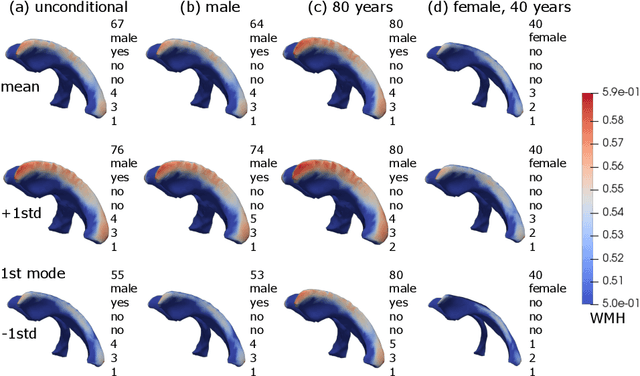


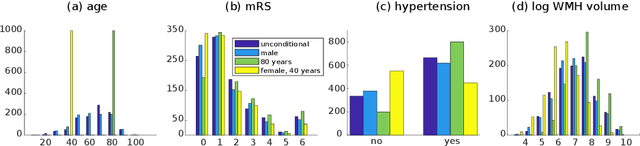
We propose and demonstrate a joint model of anatomical shapes, image features and clinical indicators for statistical shape modeling and medical image analysis. The key idea is to employ a copula model to separate the joint dependency structure from the marginal distributions of variables of interest. This separation provides flexibility on the assumptions made during the modeling process. The proposed method can handle binary, discrete, ordinal and continuous variables. We demonstrate a simple and efficient way to include binary, discrete and ordinal variables into the modeling. We build Bayesian conditional models based on observed partial clinical indicators, features or shape based on Gaussian processes capturing the dependency structure. We apply the proposed method on a stroke dataset to jointly model the shape of the lateral ventricles, the spatial distribution of the white matter hyperintensity associated with periventricular white matter disease, and clinical indicators. The proposed method yields interpretable joint models for data exploration and patient-specific statistical shape models for medical image analysis.
* Supplementary material: https://www.youtube.com/watch?v=gPoHP_iFQIA
MultiScene: A Large-scale Dataset and Benchmark for Multi-scene Recognition in Single Aerial Images
Apr 07, 2021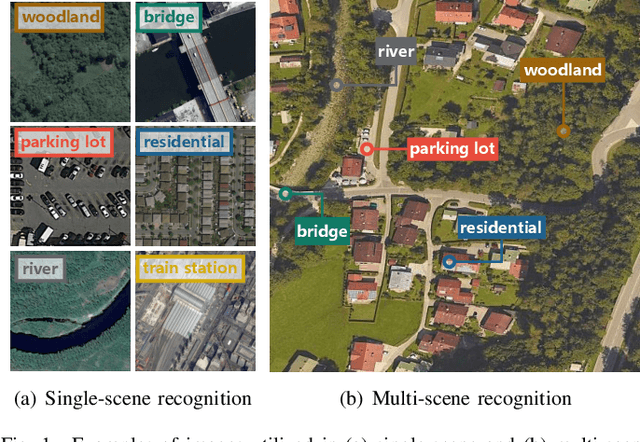

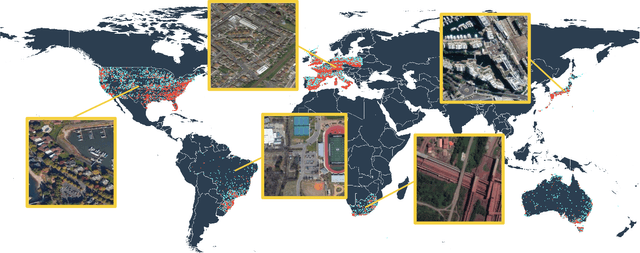
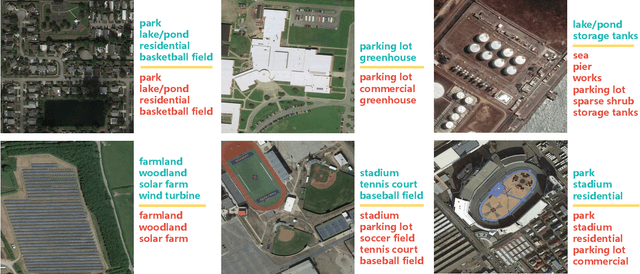
Aerial scene recognition is a fundamental research problem in interpreting high-resolution aerial imagery. Over the past few years, most studies focus on classifying an image into one scene category, while in real-world scenarios, it is more often that a single image contains multiple scenes. Therefore, in this paper, we investigate a more practical yet underexplored task -- multi-scene recognition in single images. To this end, we create a large-scale dataset, called MultiScene, composed of 100,000 unconstrained high-resolution aerial images. Considering that manually labeling such images is extremely arduous, we resort to low-cost annotations from crowdsourcing platforms, e.g., OpenStreetMap (OSM). However, OSM data might suffer from incompleteness and incorrectness, which introduce noise into image labels. To address this issue, we visually inspect 14,000 images and correct their scene labels, yielding a subset of cleanly-annotated images, named MultiScene-Clean. With it, we can develop and evaluate deep networks for multi-scene recognition using clean data. Moreover, we provide crowdsourced annotations of all images for the purpose of studying network learning with noisy labels. We conduct experiments with extensive baseline models on both MultiScene-Clean and MultiScene to offer benchmarks for multi-scene recognition in single images and learning from noisy labels for this task, respectively. To facilitate progress, we will make our dataset and pre-trained models available.
Brain-inspired algorithms for processing of visual data
Mar 02, 2021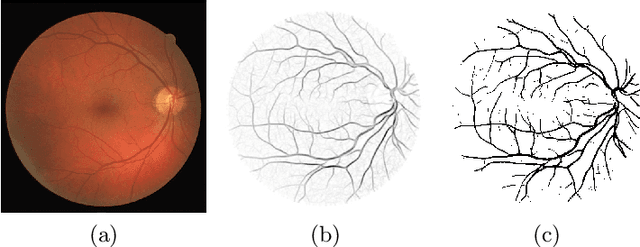


The study of the visual system of the brain has attracted the attention and interest of many neuro-scientists, that derived computational models of some types of neuron that compose it. These findings inspired researchers in image processing and computer vision to deploy such models to solve problems of visual data processing. In this paper, we review approaches for image processing and computer vision, the design of which is based on neuro-scientific findings about the functions of some neurons in the visual cortex. Furthermore, we analyze the connection between the hierarchical organization of the visual system of the brain and the structure of Convolutional Networks (ConvNets). We pay particular attention to the mechanisms of inhibition of the responses of some neurons, which provide the visual system with improved stability to changing input stimuli, and discuss their implementation in image processing operators and in ConvNets.
NeRD: Neural Reflectance Decomposition from Image Collections
Dec 08, 2020
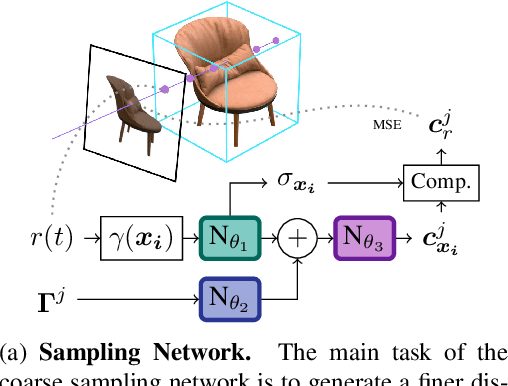

Decomposing a scene into its shape, reflectance, and illumination is a challenging but essential problem in computer vision and graphics. This problem is inherently more challenging when the illumination is not a single light source under laboratory conditions but is instead an unconstrained environmental illumination. Though recent work has shown that implicit representations can be used to model the radiance field of an object, these techniques only enable view synthesis and not relighting. Additionally, evaluating these radiance fields is resource and time-intensive. By decomposing a scene into explicit representations, any rendering framework can be leveraged to generate novel views under any illumination in real-time. NeRD is a method that achieves this decomposition by introducing physically-based rendering to neural radiance fields. Even challenging non-Lambertian reflectances, complex geometry, and unknown illumination can be decomposed to high-quality models. The datasets and code is available at the project page: https://markboss.me/publication/2021-nerd/
Recursive Chaining of Reversible Image-to-image Translators For Face Aging
Aug 06, 2018


This paper addresses the modeling and simulation of progressive changes over time, such as human face aging. By treating the age phases as a sequence of image domains, we construct a chain of transformers that map images from one age domain to the next. Leveraging recent adversarial image translation methods, our approach requires no training samples of the same individual at different ages. Here, the model must be flexible enough to translate a child face to a young adult, and all the way through the adulthood to old age. We find that some transformers in the chain can be recursively applied on their own output to cover multiple phases, compressing the chain. The structure of the chain also unearths information about the underlying physical process. We demonstrate the performance of our method with precise and intuitive metrics, and visually match with the face aging state-of-the-art.
Multi-Frame GAN: Image Enhancement for Stereo Visual Odometry in Low Light
Oct 15, 2019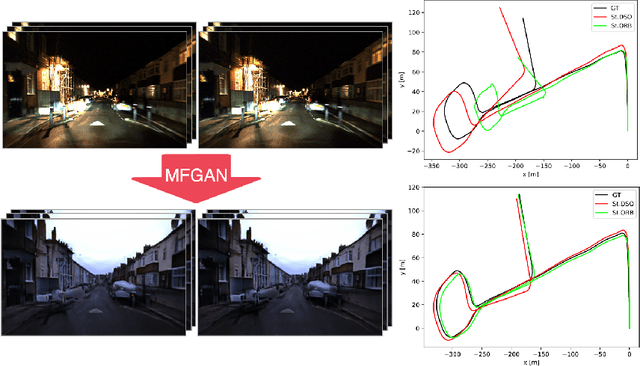
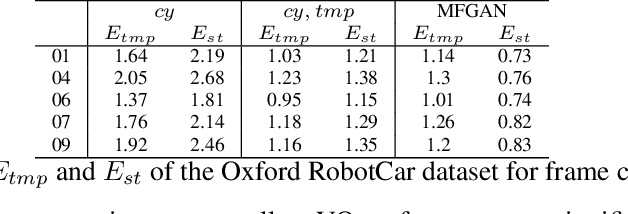
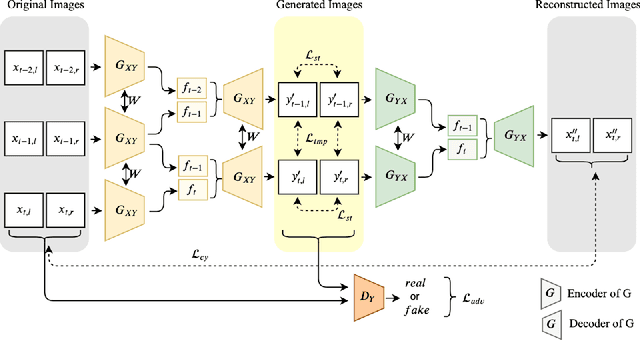
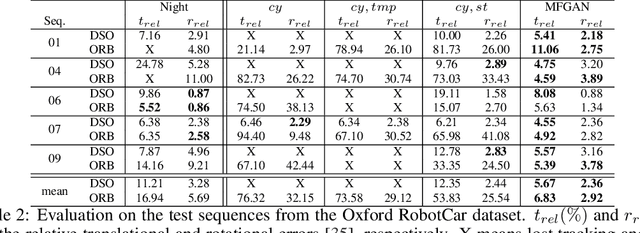
We propose the concept of a multi-frame GAN (MFGAN) and demonstrate its potential as an image sequence enhancement for stereo visual odometry in low light conditions. We base our method on an invertible adversarial network to transfer the beneficial features of brightly illuminated scenes to the sequence in poor illumination without costly paired datasets. In order to preserve the coherent geometric cues for the translated sequence, we present a novel network architecture as well as a novel loss term combining temporal and stereo consistencies based on optical flow estimation. We demonstrate that the enhanced sequences improve the performance of state-of-the-art feature-based and direct stereo visual odometry methods on both synthetic and real datasets in challenging illumination. We also show that MFGAN outperforms other state-of-the-art image enhancement and style transfer methods by a large margin in terms of visual odometry.
Ensembles of GANs for synthetic training data generation
Apr 23, 2021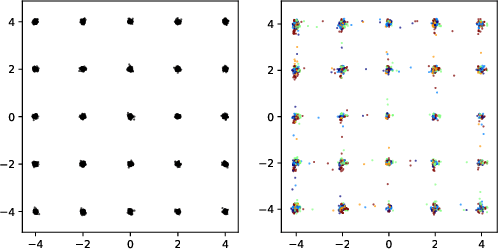
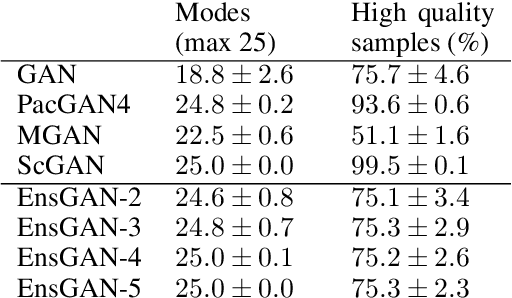
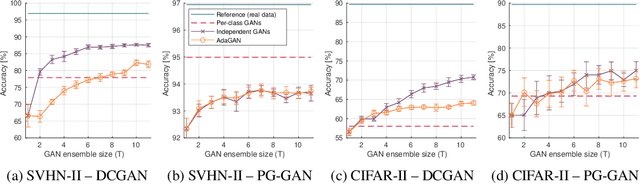
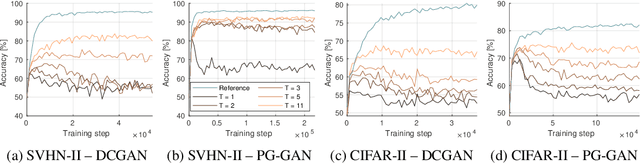
Insufficient training data is a major bottleneck for most deep learning practices, not least in medical imaging where data is difficult to collect and publicly available datasets are scarce due to ethics and privacy. This work investigates the use of synthetic images, created by generative adversarial networks (GANs), as the only source of training data. We demonstrate that for this application, it is of great importance to make use of multiple GANs to improve the diversity of the generated data, i.e. to sufficiently cover the data distribution. While a single GAN can generate seemingly diverse image content, training on this data in most cases lead to severe over-fitting. We test the impact of ensembled GANs on synthetic 2D data as well as common image datasets (SVHN and CIFAR-10), and using both DCGANs and progressively growing GANs. As a specific use case, we focus on synthesizing digital pathology patches to provide anonymized training data.