 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Texture variation adaptive image denoising with nonlocal PCA
Oct 26, 2018
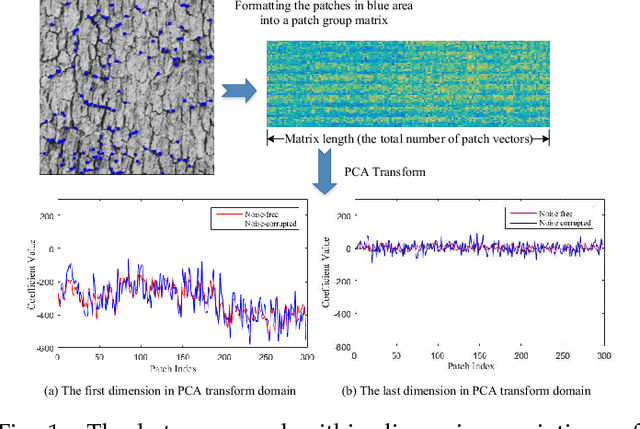
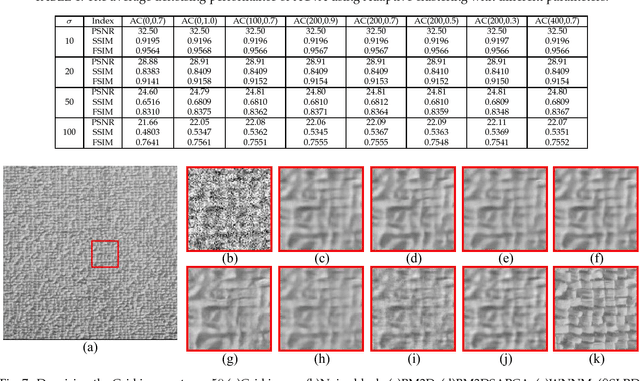
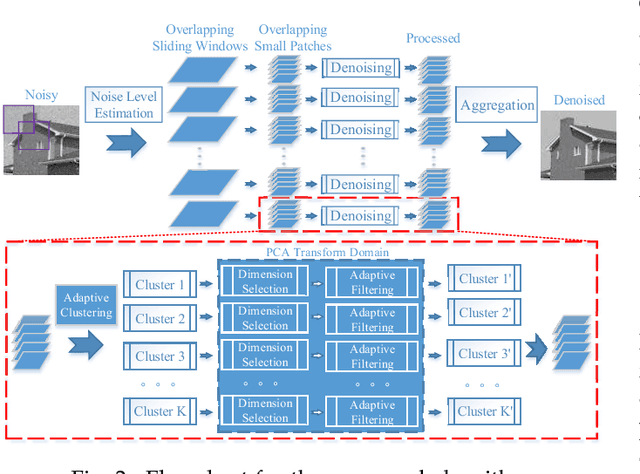
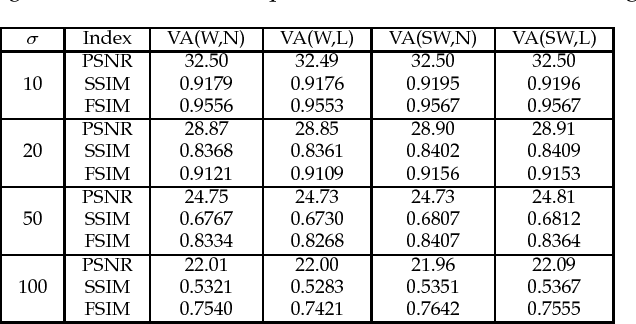
Image textures, as a kind of local variations, provide important information for human visual system. Many image textures, especially the small-scale or stochastic textures are rich in high-frequency variations, and are difficult to be preserved. Current state-of-the-art denoising algorithms typically adopt a nonlocal approach consisting of image patch grouping and group-wise denoising filtering. To achieve a better image denoising while preserving the variations in texture, we first adaptively group high correlated image patches with the same kinds of texture elements (texels) via an adaptive clustering method. This adaptive clustering method is applied in an over-clustering-and-iterative-merging approach, where its noise robustness is improved with a custom merging threshold relating to the noise level and cluster size. For texture-preserving denoising of each cluster, considering that the variations in texture are captured and wrapped in not only the between-dimension energy variations but also the within-dimension variations of PCA transform coefficients, we further propose a PCA-transform-domain variation adaptive filtering method to preserve the local variations in textures. Experiments on natural images show the superiority of the proposed transform-domain variation adaptive filtering to traditional PCA-based hard or soft threshold filtering. As a whole, the proposed denoising method achieves a favorable texture preserving performance both quantitatively and visually, especially for stochastic textures, which is further verified in camera raw image denoising.
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction
Aug 11, 2021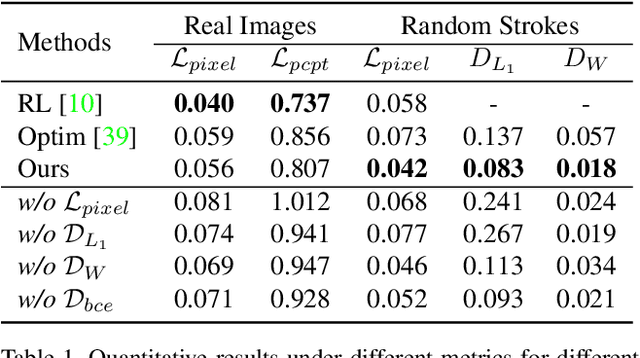
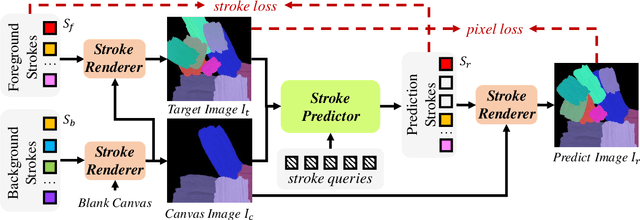
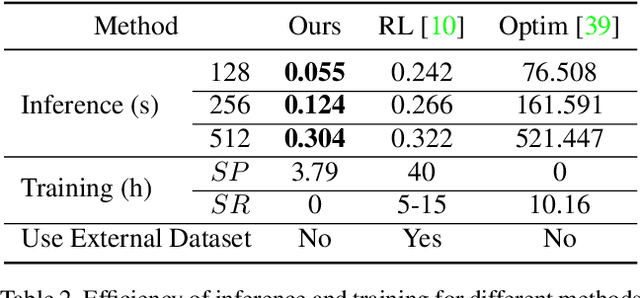
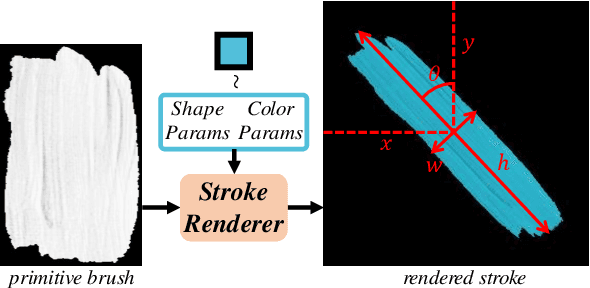
Neural painting refers to the procedure of producing a series of strokes for a given image and non-photo-realistically recreating it using neural networks. While reinforcement learning (RL) based agents can generate a stroke sequence step by step for this task, it is not easy to train a stable RL agent. On the other hand, stroke optimization methods search for a set of stroke parameters iteratively in a large search space; such low efficiency significantly limits their prevalence and practicality. Different from previous methods, in this paper, we formulate the task as a set prediction problem and propose a novel Transformer-based framework, dubbed Paint Transformer, to predict the parameters of a stroke set with a feed forward network. This way, our model can generate a set of strokes in parallel and obtain the final painting of size 512 * 512 in near real time. More importantly, since there is no dataset available for training the Paint Transformer, we devise a self-training pipeline such that it can be trained without any off-the-shelf dataset while still achieving excellent generalization capability. Experiments demonstrate that our method achieves better painting performance than previous ones with cheaper training and inference costs. Codes and models are available.
An Effective Data Augmentation for Person Re-identification
Jan 21, 2021
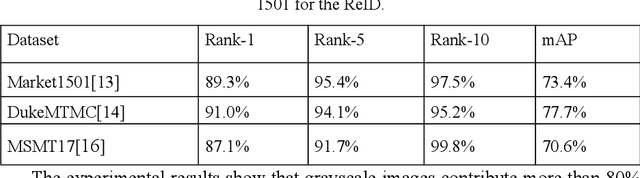

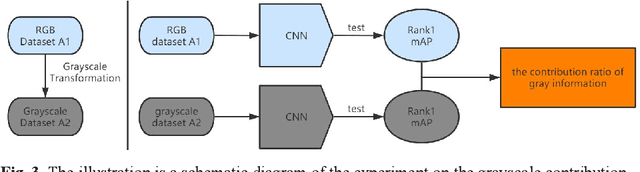
In order to make full use of structural information of grayscale images and reduce adverse impact of illumination variation for person re-identification (ReID), an effective data augmentation method is proposed in this paper, which includes Random Grayscale Transformation, Random Grayscale Patch Replacement and their combination. It is discovered that structural information has a significant effect on the ReID model performance, and it is very important complementary to RGB images ReID. During ReID model training, on the one hand, we randomly selected a rectangular area in the RGB image and replace its color with the same rectangular area grayscale in corresponding grayscale image, thus we generate a training image with different grayscale areas; On the other hand, we convert an image into a grayscale image. These two methods will reduce the risk of overfitting the model due to illumination variations and make the model more robust to cross-camera. The experimental results show that our method achieves a performance improvement of up to 3.3%, achieving the highest retrieval accuracy currently on multiple datasets.
Duplex Contextual Relation Network for Polyp Segmentation
Mar 12, 2021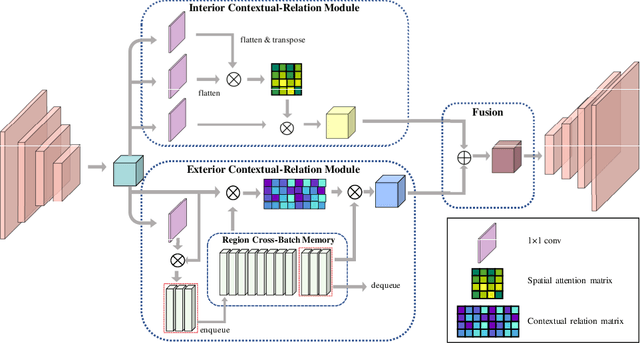
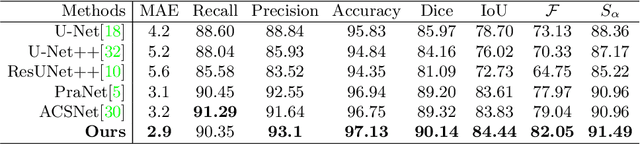
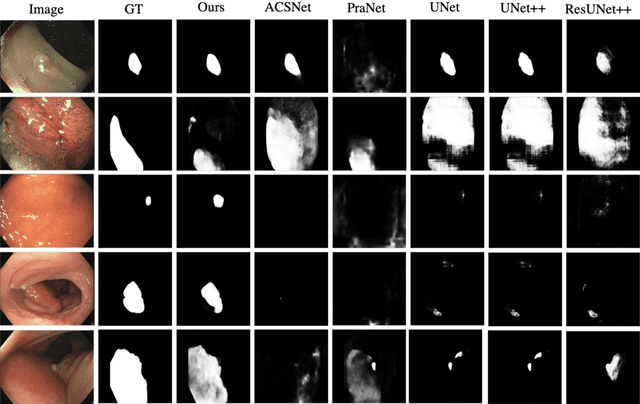
Polyp segmentation is of great importance in the early diagnosis and treatment of colorectal cancer. Since polyps vary in their shape, size, color, and texture, accurate polyp segmentation is very challenging. One promising way to mitigate the diversity of polyps is to model the contextual relation for each pixel such as using attention mechanism. However, previous methods only focus on learning the dependencies between the position within an individual image and ignore the contextual relation across different images. In this paper, we propose Duplex Contextual Relation Network (DCRNet) to capture both within-image and cross-image contextual relations. Specifically, we first design Interior Contextual-Relation Module to estimate the similarity between each position and all the positions within the same image. Then Exterior Contextual-Relation Module is incorporated to estimate the similarity between each position and the positions across different images. Based on the above two types of similarity, the feature at one position can be further enhanced by the contextual region embedding within and across images. To store the characteristic region embedding from all the images, a memory bank is designed and operates as a queue. Therefore, the proposed method can relate similar features even though they come from different images. We evaluate the proposed method on the EndoScene, Kvasir-SEG and the recently released large-scale PICCOLO dataset. Experimental results show that the proposed DCRNet outperforms the state-of-the-art methods in terms of the widely-used evaluation metrics.
Deep Graph-Convolutional Image Denoising
Jul 19, 2019



Non-local self-similarity is well-known to be an effective prior for the image denoising problem. However, little work has been done to incorporate it in convolutional neural networks, which surpass non-local model-based methods despite only exploiting local information. In this paper, we propose a novel end-to-end trainable neural network architecture employing layers based on graph convolution operations, thereby creating neurons with non-local receptive fields. The graph convolution operation generalizes the classic convolution to arbitrary graphs. In this work, the graph is dynamically computed from similarities among the hidden features of the network, so that the powerful representation learning capabilities of the network are exploited to uncover self-similar patterns. We introduce a lightweight Edge-Conditioned Convolution which addresses vanishing gradient and over-parameterization issues of this particular graph convolution. Extensive experiments show state-of-the-art performance with improved qualitative and quantitative results on both synthetic Gaussian noise and real noise.
Arithmetic addition of two integers by deep image classification networks: experiments to quantify their autonomous reasoning ability
Dec 10, 2019
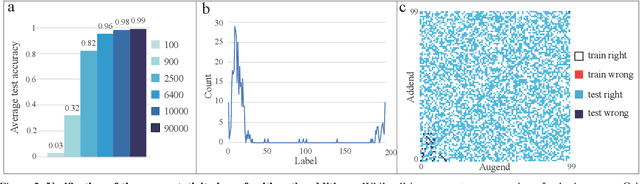
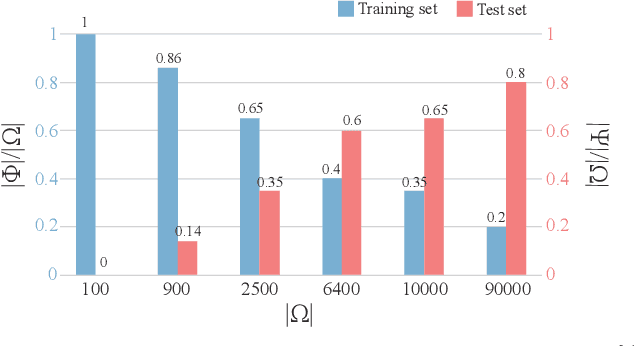
The unprecedented performance achieved by deep convolutional neural networks for image classification is linked primarily to their ability of capturing rich structural features at various layers within networks. Here we design a series of experiments, inspired by children's learning of the arithmetic addition of two integers, to showcase that such deep networks can go beyond the structural features to learn deeper knowledge. In our experiments, a set of images is constructed, each image containing an arithmetic addition $n+m$ in its central area, and several classification networks are then trained over a subset of images, using the sum as the label. Tests on the excluded images show that, as the image set gets larger, the networks have well learnt the law of arithmetic additions so as to build up their autonomous reasoning ability strongly. For instance, networks trained over a small percentage of images can classify a big majority of the remaining images correctly, and many arithmetic additions involving some integers that have never been seen during the training can also be solved correctly by the trained networks.
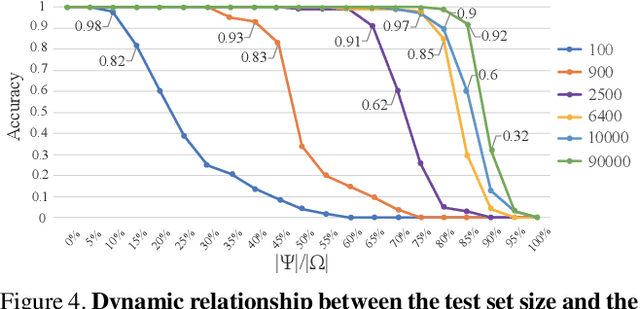
Motif Difference Field: A Simple and Effective Image Representation of Time Series for Classification
Jan 21, 2020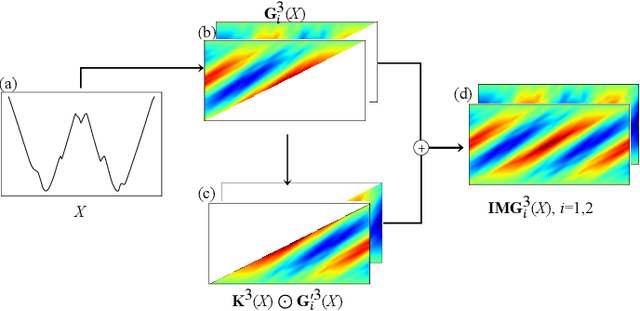
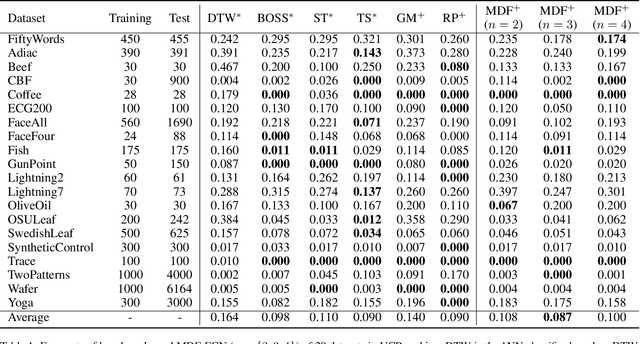
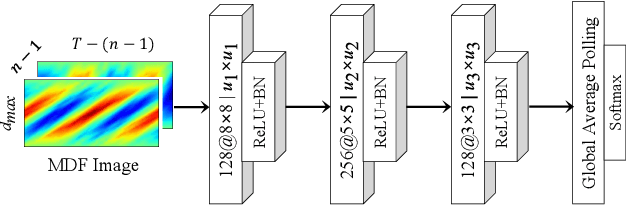
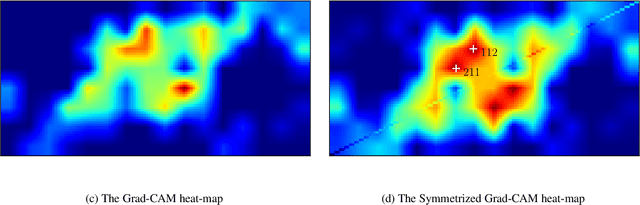
Time series motifs play an important role in the time series analysis. The motif-based time series clustering is used for the discovery of higher-order patterns or structures in time series data. Inspired by the convolutional neural network (CNN) classifier based on the image representations of time series, motif difference field (MDF) is proposed. Compared to other image representations of time series, MDF is simple and easy to construct. With the Fully Convolution Network (FCN) as the classifier, MDF demonstrates the superior performance on the UCR time series dataset in benchmark with other time series classification methods. It is interesting to find that the triadic time series motifs give the best result in the test. Due to the motif clustering reflected in MDF, the significant motifs are detected with the help of the Gradient-weighted Class Activation Mapping (Grad-CAM). The areas in MDF with high weight in Grad-CAM have a high contribution from the significant motifs with the desired ordinal patterns associated with the signature patterns in time series. However, the signature patterns cannot be identified with the neural network classifiers directly based on the time series.
OSSR-PID: One-Shot Symbol Recognition in P&ID Sheets using Path Sampling and GCN
Sep 08, 2021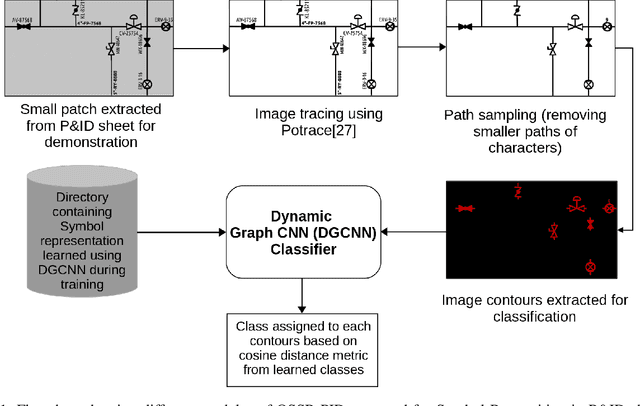
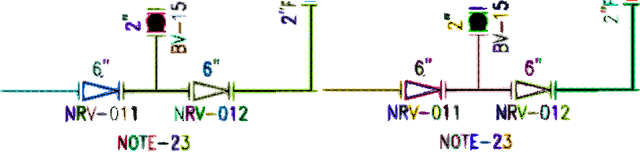

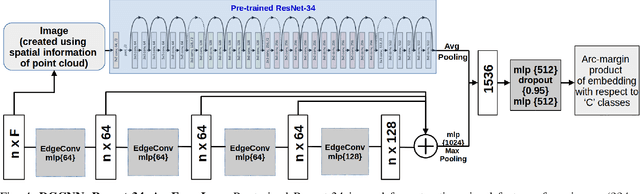
Piping and Instrumentation Diagrams (P&ID) are ubiquitous in several manufacturing, oil and gas enterprises for representing engineering schematics and equipment layout. There is an urgent need to extract and digitize information from P&IDs without the cost of annotating a varying set of symbols for each new use case. A robust one-shot learning approach for symbol recognition i.e., localization followed by classification, would therefore go a long way towards this goal. Our method works by sampling pixels sequentially along the different contour boundaries in the image. These sampled points form paths which are used in the prototypical line diagram to construct a graph that captures the structure of the contours. Subsequently, the prototypical graphs are fed into a Dynamic Graph Convolutional Neural Network (DGCNN) which is trained to classify graphs into one of the given symbol classes. Further, we append embeddings from a Resnet-34 network which is trained on symbol images containing sampled points to make the classification network more robust. Since, many symbols in P&ID are structurally very similar to each other, we utilize Arcface loss during DGCNN training which helps in maximizing symbol class separability by producing highly discriminative embeddings. The images consist of components attached on the pipeline (straight line). The sampled points segregated around the symbol regions are used for the classification task. The proposed pipeline, named OSSR-PID, is fast and gives outstanding performance for recognition of symbols on a synthetic dataset of 100 P&ID diagrams. We also compare our method against prior-work on a real-world private dataset of 12 P&ID sheets and obtain comparable/superior results. Remarkably, it is able to achieve such excellent performance using only one prototypical example per symbol.
Digitize-PID: Automatic Digitization of Piping and Instrumentation Diagrams
Sep 08, 2021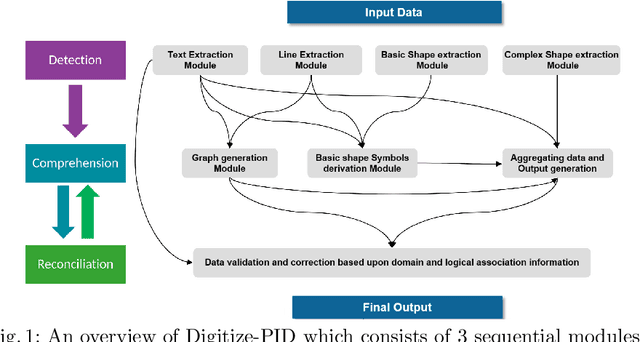
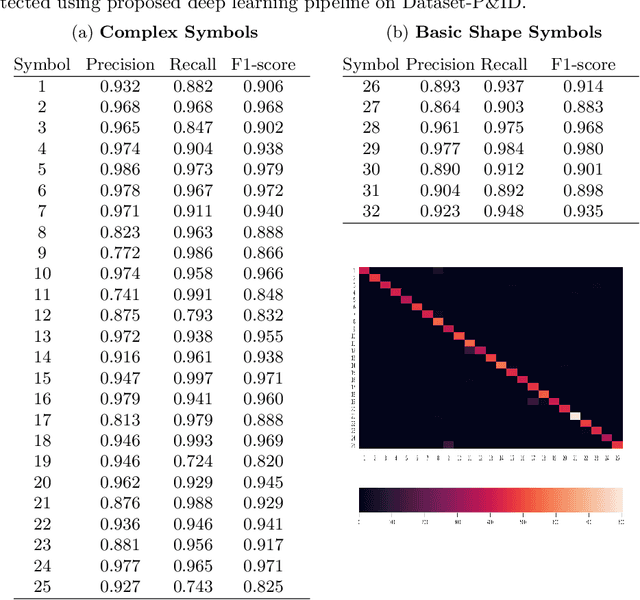
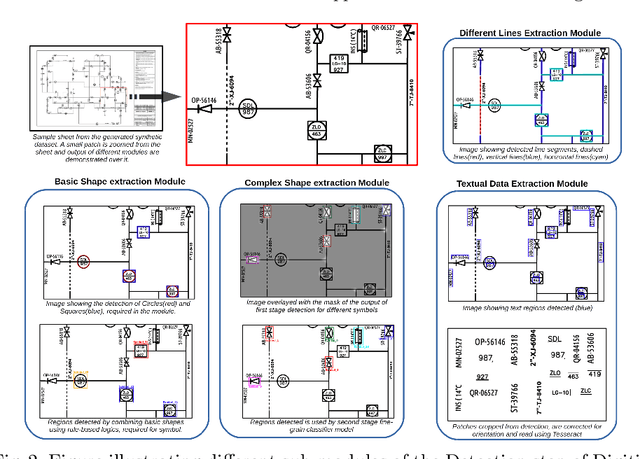
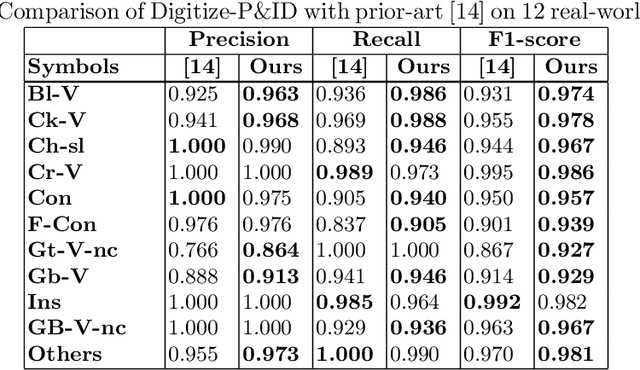
Digitization of scanned Piping and Instrumentation diagrams(P&ID), widely used in manufacturing or mechanical industries such as oil and gas over several decades, has become a critical bottleneck in dynamic inventory management and creation of smart P&IDs that are compatible with the latest CAD tools. Historically, P&ID sheets have been manually generated at the design stage, before being scanned and stored as PDFs. Current digitization initiatives involve manual processing and are consequently very time consuming, labour intensive and error-prone.Thanks to advances in image processing, machine and deep learning techniques there are emerging works on P&ID digitization. However, existing solutions face several challenges owing to the variation in the scale, size and noise in the P&IDs, sheer complexity and crowdedness within drawings, domain knowledge required to interpret the drawings. This motivates our current solution called Digitize-PID which comprises of an end-to-end pipeline for detection of core components from P&IDs like pipes, symbols and textual information, followed by their association with each other and eventually, the validation and correction of output data based on inherent domain knowledge. A novel and efficient kernel-based line detection and a two-step method for detection of complex symbols based on a fine-grained deep recognition technique is presented in the paper. In addition, we have created an annotated synthetic dataset, Dataset-P&ID, of 500 P&IDs by incorporating different types of noise and complex symbols which is made available for public use (currently there exists no public P&ID dataset). We evaluate our proposed method on this synthetic dataset and a real-world anonymized private dataset of 12 P&ID sheets. Results show that Digitize-PID outperforms the existing state-of-the-art for P&ID digitization.
* 13 pages
Ptychography Intensity Interferometry Imaging for Dynamic Distant Object
Jan 19, 2021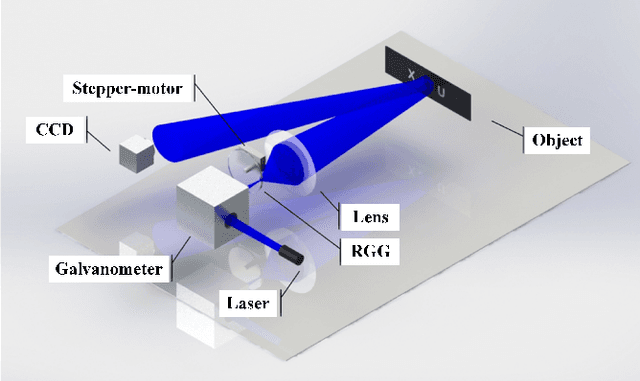



As a promising lensless imaging method for distance objects, intensity interferometry imaging (III) had been suffering from the unreliable phase retrieval process, hindering the development of III for decades. Recently, the introduction of the ptychographic detection in III overcame this challenge, and a method called ptychographic III (PIII) was proposed. We here experimentally demonstrate that PIII can image a dynamic distance object. A reasonable image for the moving object can be retrieved with only two speckle patterns for each probe, and only 10 to 20 iterations are needed. Meanwhile, PIII exhibits robust to the inaccurate information of the probe. Furthermore, PIII successfully recovers the image through a fog obfuscating the imaging light path, under which a conventional camera relying on lenses fails to provide a recognizable image.