 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
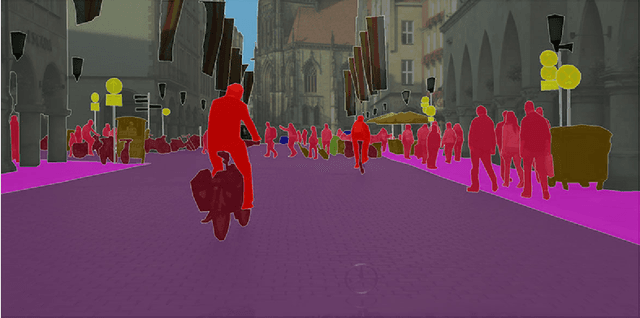
WeClick: Weakly-Supervised Video Semantic Segmentation with Click Annotations
Aug 04, 2021
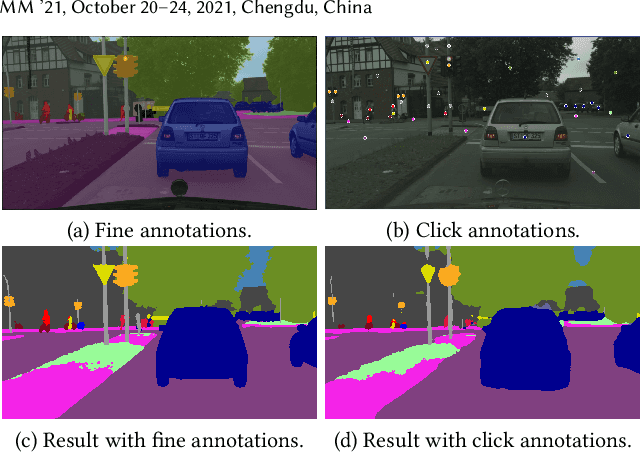
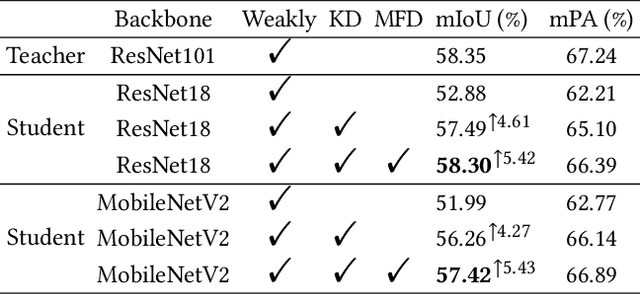
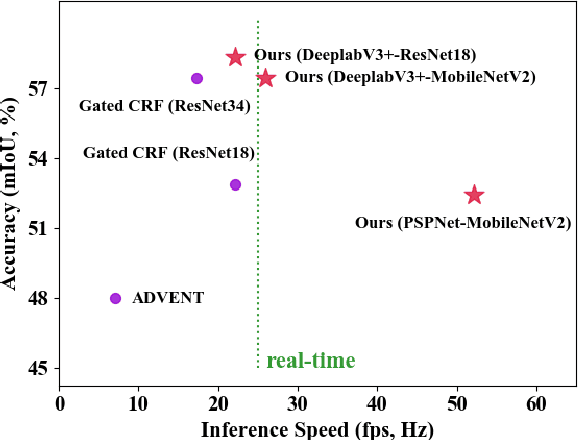
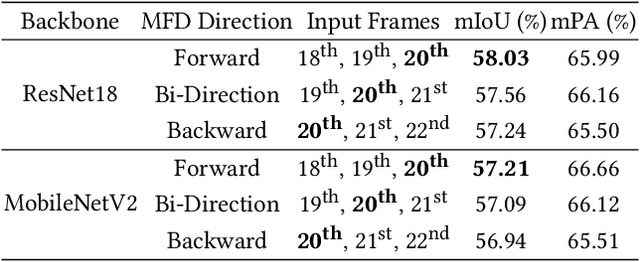
Compared with tedious per-pixel mask annotating, it is much easier to annotate data by clicks, which costs only several seconds for an image. However, applying clicks to learn video semantic segmentation model has not been explored before. In this work, we propose an effective weakly-supervised video semantic segmentation pipeline with click annotations, called WeClick, for saving laborious annotating effort by segmenting an instance of the semantic class with only a single click. Since detailed semantic information is not captured by clicks, directly training with click labels leads to poor segmentation predictions. To mitigate this problem, we design a novel memory flow knowledge distillation strategy to exploit temporal information (named memory flow) in abundant unlabeled video frames, by distilling the neighboring predictions to the target frame via estimated motion. Moreover, we adopt vanilla knowledge distillation for model compression. In this case, WeClick learns compact video semantic segmentation models with the low-cost click annotations during the training phase yet achieves real-time and accurate models during the inference period. Experimental results on Cityscapes and Camvid show that WeClick outperforms the state-of-the-art methods, increases performance by 10.24% mIoU than baseline, and achieves real-time execution.
Recent progress in semantic image segmentation
Sep 20, 2018
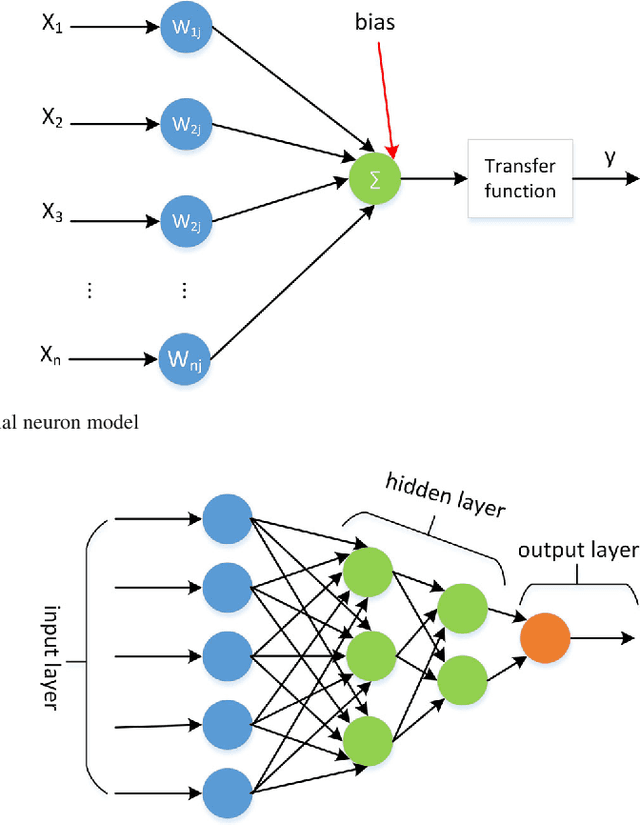
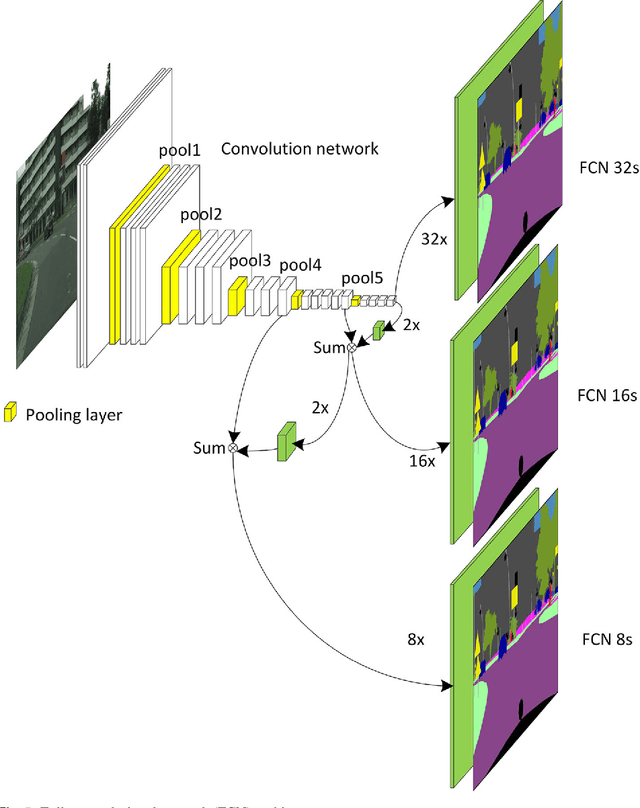
Semantic image segmentation, which becomes one of the key applications in image processing and computer vision domain, has been used in multiple domains such as medical area and intelligent transportation. Lots of benchmark datasets are released for researchers to verify their algorithms. Semantic segmentation has been studied for many years. Since the emergence of Deep Neural Network (DNN), segmentation has made a tremendous progress. In this paper, we divide semantic image segmentation methods into two categories: traditional and recent DNN method. Firstly, we briefly summarize the traditional method as well as datasets released for segmentation, then we comprehensively investigate recent methods based on DNN which are described in the eight aspects: fully convolutional network, upsample ways, FCN joint with CRF methods, dilated convolution approaches, progresses in backbone network, pyramid methods, Multi-level feature and multi-stage method, supervised, weakly-supervised and unsupervised methods. Finally, a conclusion in this area is drawn.
* Pubulished at Artificial Intelligence review
Tex2Shape: Detailed Full Human Body Geometry from a Single Image
Apr 18, 2019



We present a simple yet effective method to infer detailed full human body shape from only a single photograph. Our model can infer full-body shape including face, hair, and clothing including wrinkles at interactive frame-rates. Results feature details even on parts that are occluded in the input image. Our main idea is to turn shape regression into an aligned image-to-image translation problem. The input to our method is a partial texture map of the visible region obtained from off-the-shelf methods. From a partial texture, we estimate detailed normal and vector displacement maps, which can be applied to a low-resolution smooth body model to add detail and clothing. Despite being trained purely with synthetic data, our model generalizes well to real-world photographs. Numerous results demonstrate the versatility and robustness of our method.
sigmoidF1: A Smooth F1 Score Surrogate Loss for Multilabel Classification
Aug 24, 2021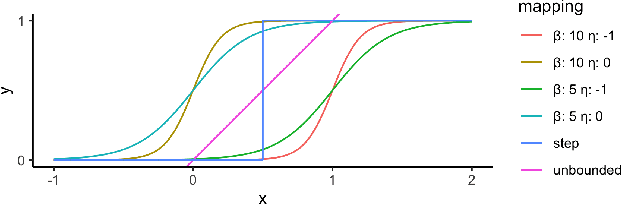

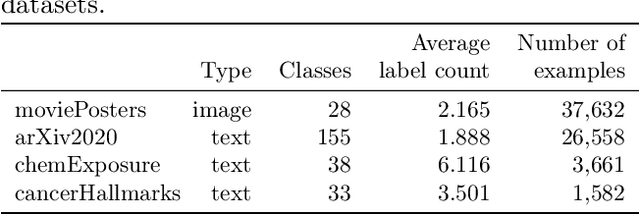
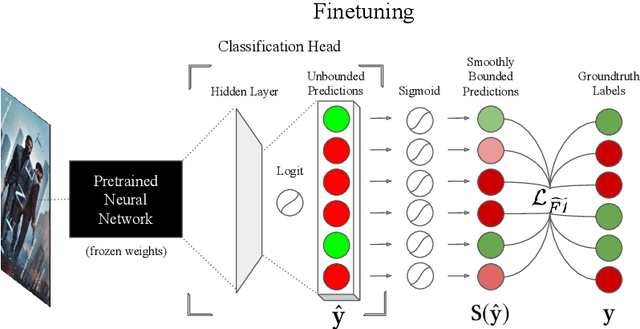
Multiclass multilabel classification refers to the task of attributing multiple labels to examples via predictions. Current models formulate a reduction of that multilabel setting into either multiple binary classifications or multiclass classification, allowing for the use of existing loss functions (sigmoid, cross-entropy, logistic, etc.). Empirically, these methods have been reported to achieve good performance on different metrics (F1 score, Recall, Precision, etc.). Theoretically though, the multilabel classification reductions does not accommodate for the prediction of varying numbers of labels per example and the underlying losses are distant estimates of the performance metrics. We propose a loss function, sigmoidF1. It is an approximation of the F1 score that (I) is smooth and tractable for stochastic gradient descent, (II) naturally approximates a multilabel metric, (III) estimates label propensities and label counts. More generally, we show that any confusion matrix metric can be formulated with a smooth surrogate. We evaluate the proposed loss function on different text and image datasets, and with a variety of metrics, to account for the complexity of multilabel classification evaluation. In our experiments, we embed the sigmoidF1 loss in a classification head that is attached to state-of-the-art efficient pretrained neural networks MobileNetV2 and DistilBERT. Our experiments show that sigmoidF1 outperforms other loss functions on four datasets and several metrics. These results show the effectiveness of using inference-time metrics as loss function at training time in general and their potential on non-trivial classification problems like multilabel classification.
Mean Embeddings with Test-Time Data Augmentation for Ensembling of Representations
Jul 14, 2021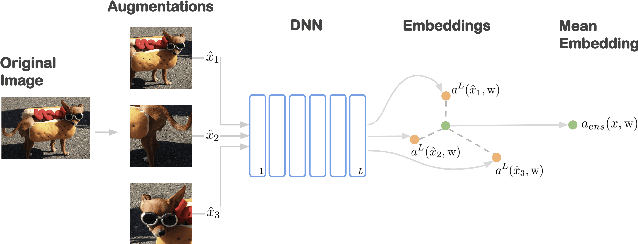
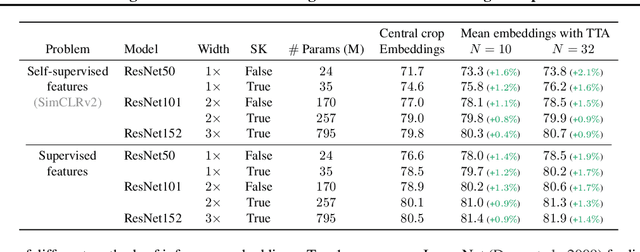
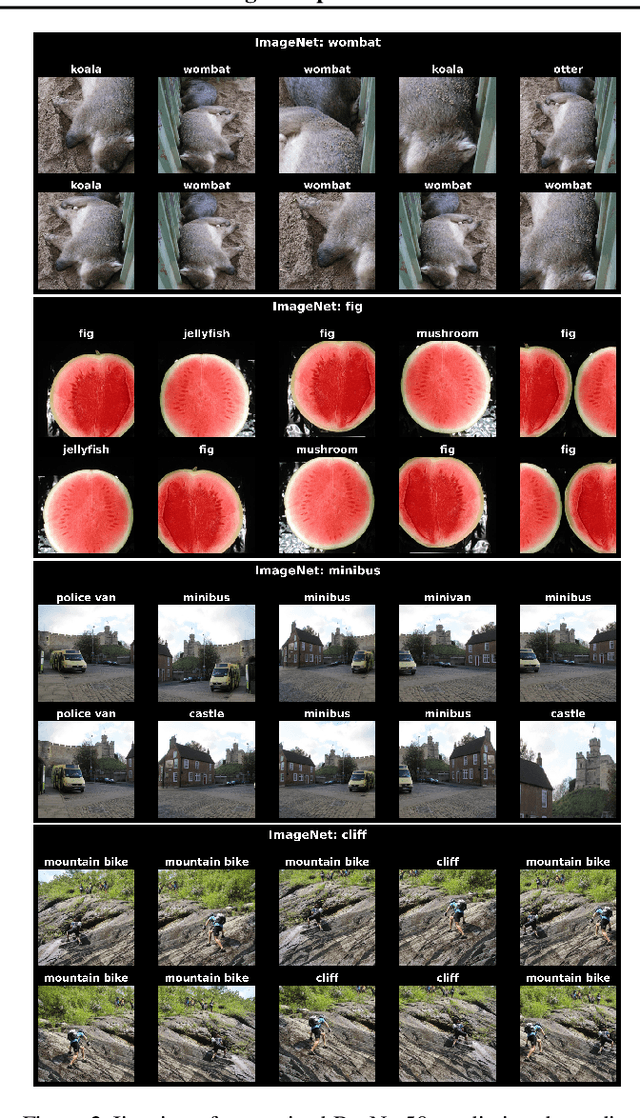
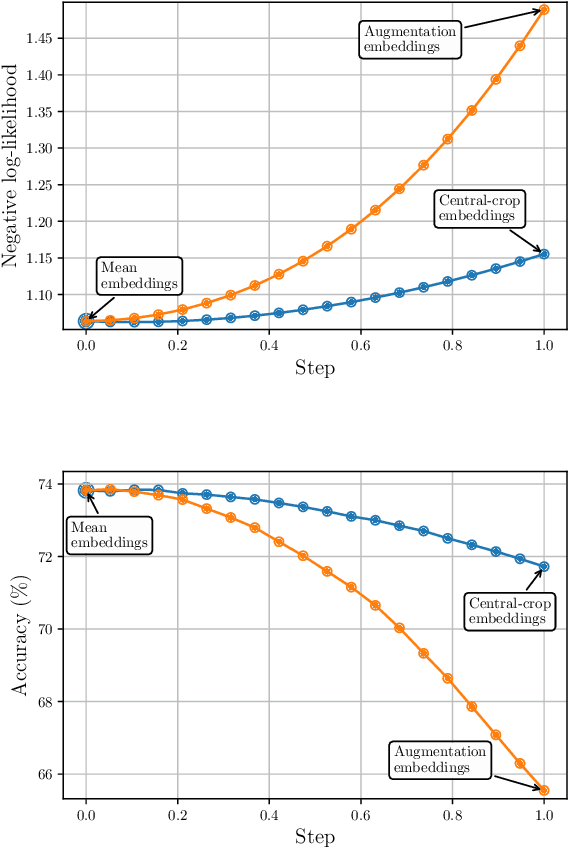
Averaging predictions over a set of models -- an ensemble -- is widely used to improve predictive performance and uncertainty estimation of deep learning models. At the same time, many machine learning systems, such as search, matching, and recommendation systems, heavily rely on embeddings. Unfortunately, due to misalignment of features of independently trained models, embeddings, cannot be improved with a naive deep ensemble like approach. In this work, we look at the ensembling of representations and propose mean embeddings with test-time augmentation (MeTTA) simple yet well-performing recipe for ensembling representations. Empirically we demonstrate that MeTTA significantly boosts the quality of linear evaluation on ImageNet for both supervised and self-supervised models. Even more exciting, we draw connections between MeTTA, image retrieval, and transformation invariant models. We believe that spreading the success of ensembles to inference higher-quality representations is the important step that will open many new applications of ensembling.
OCTID: Optical Coherence Tomography Image Database
Dec 17, 2018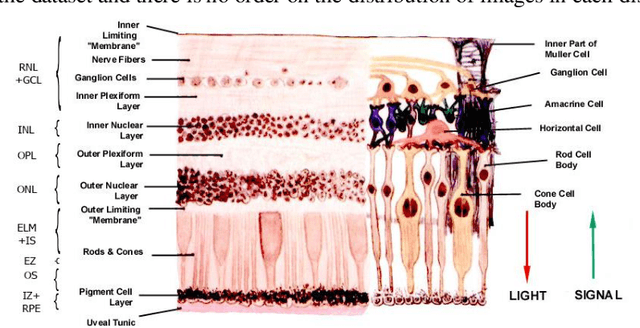
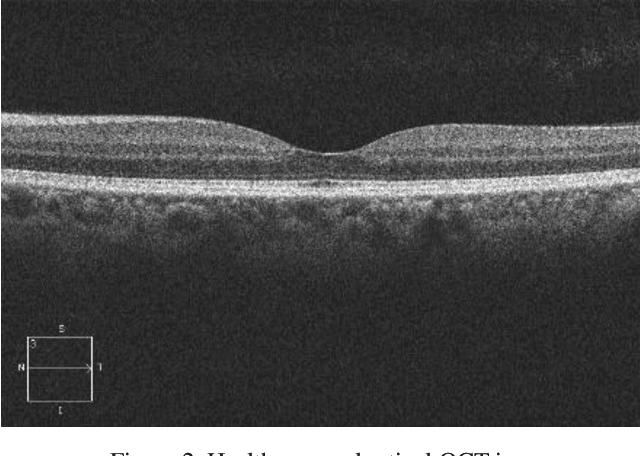
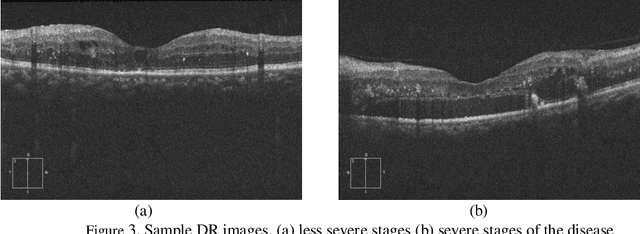
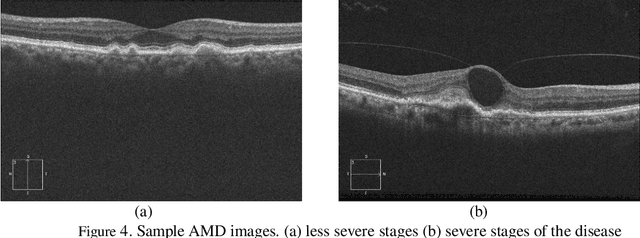
Optical coherence tomography (OCT) is a non-invasive imaging modality which is widely used in clinical ophthalmology. OCT images are capable of visualizing deep retinal layers which is crucial for the early diagnosis of retinal diseases. In this paper, we describe a comprehensive open-access database containing more than 500 high-resolution images categorized into different pathological conditions. The image classes include Normal (NO), Macular Hole (MH), Age-related Macular Degeneration (AMD), Central Serous Retinopathy, and Diabetic Retinopathy (DR). The images were obtained from a raster scan protocol with a 2mm scan length and 512x1024 pixels resolution. We have also included 25 normal OCT images with their corresponding ground truth delineations which can be used for accurate evaluation of OCT image segmentation.
Learning Hierarchical Semantic Image Manipulation through Structured Representations
Aug 28, 2018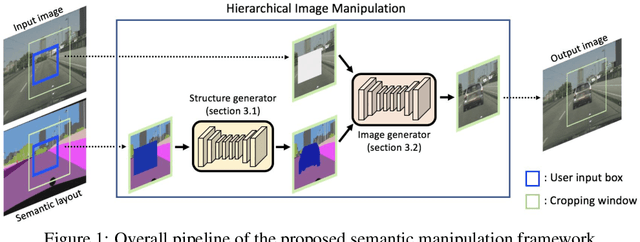


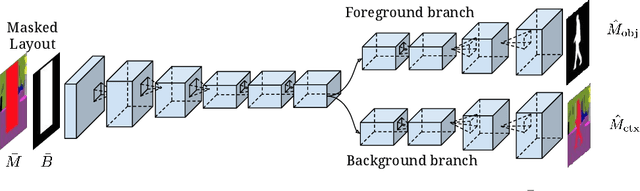
Understanding, reasoning, and manipulating semantic concepts of images have been a fundamental research problem for decades. Previous work mainly focused on direct manipulation on natural image manifold through color strokes, key-points, textures, and holes-to-fill. In this work, we present a novel hierarchical framework for semantic image manipulation. Key to our hierarchical framework is that we employ a structured semantic layout as our intermediate representation for manipulation. Initialized with coarse-level bounding boxes, our structure generator first creates pixel-wise semantic layout capturing the object shape, object-object interactions, and object-scene relations. Then our image generator fills in the pixel-level textures guided by the semantic layout. Such framework allows a user to manipulate images at object-level by adding, removing, and moving one bounding box at a time. Experimental evaluations demonstrate the advantages of the hierarchical manipulation framework over existing image generation and context hole-filing models, both qualitatively and quantitatively. Benefits of the hierarchical framework are further demonstrated in applications such as semantic object manipulation, interactive image editing, and data-driven image manipulation.
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction
Aug 11, 2021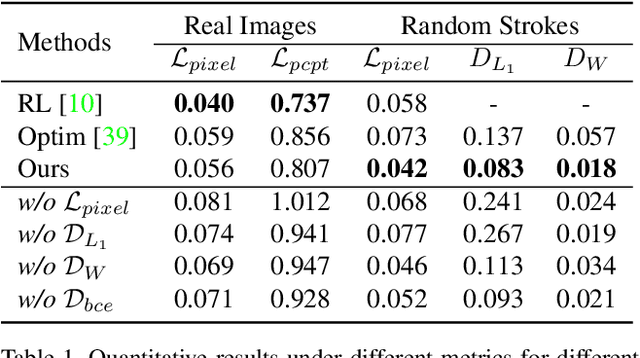
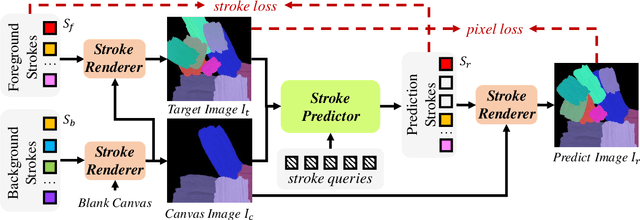
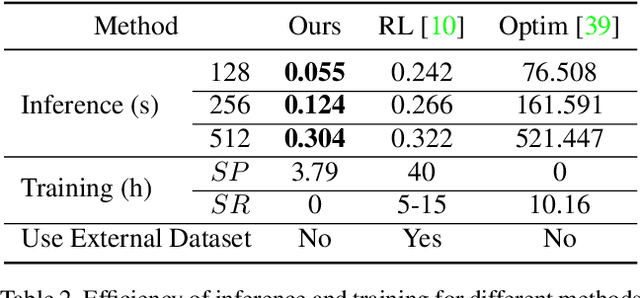
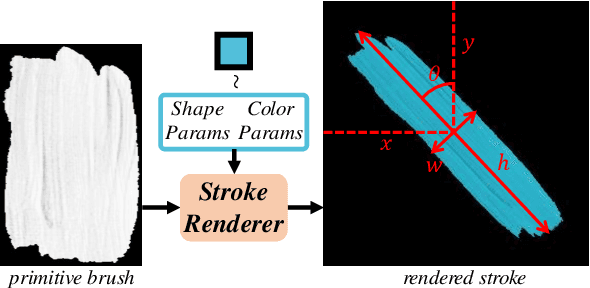
Neural painting refers to the procedure of producing a series of strokes for a given image and non-photo-realistically recreating it using neural networks. While reinforcement learning (RL) based agents can generate a stroke sequence step by step for this task, it is not easy to train a stable RL agent. On the other hand, stroke optimization methods search for a set of stroke parameters iteratively in a large search space; such low efficiency significantly limits their prevalence and practicality. Different from previous methods, in this paper, we formulate the task as a set prediction problem and propose a novel Transformer-based framework, dubbed Paint Transformer, to predict the parameters of a stroke set with a feed forward network. This way, our model can generate a set of strokes in parallel and obtain the final painting of size 512 * 512 in near real time. More importantly, since there is no dataset available for training the Paint Transformer, we devise a self-training pipeline such that it can be trained without any off-the-shelf dataset while still achieving excellent generalization capability. Experiments demonstrate that our method achieves better painting performance than previous ones with cheaper training and inference costs. Codes and models are available.
Generic Merging of Structure from Motion Maps with a Low Memory Footprint
Mar 24, 2021
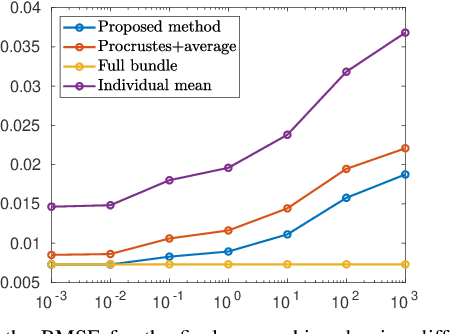
With the development of cheap image sensors, the amount of available image data have increased enormously, and the possibility of using crowdsourced collection methods has emerged. This calls for development of ways to handle all these data. In this paper, we present new tools that will enable efficient, flexible and robust map merging. Assuming that separate optimisations have been performed for the individual maps, we show how only relevant data can be stored in a low memory footprint representation. We use these representations to perform map merging so that the algorithm is invariant to the merging order and independent of the choice of coordinate system. The result is a robust algorithm that can be applied to several maps simultaneously. The result of a merge can also be represented with the same type of low-memory footprint format, which enables further merging and updating of the map in a hierarchical way. Furthermore, the method can perform loop closing and also detect changes in the scene between the capture of the different image sequences. Using both simulated and real data - from both a hand held mobile phone and from a drone - we verify the performance of the proposed method.
BioFaceNet: Deep Biophysical Face Image Interpretation
Sep 13, 2019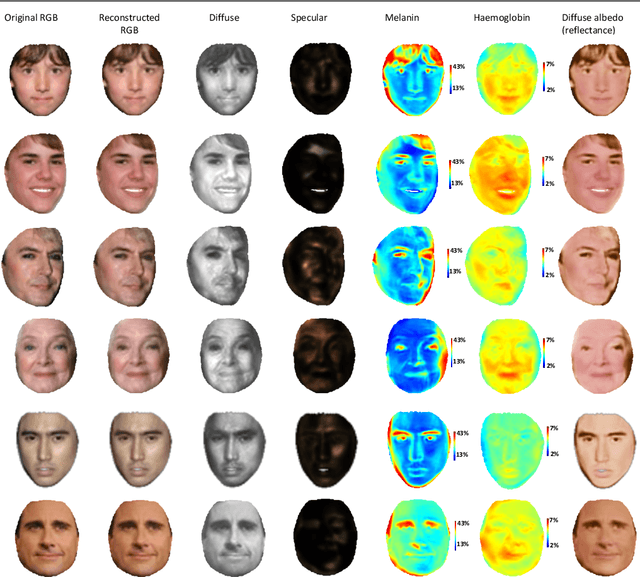

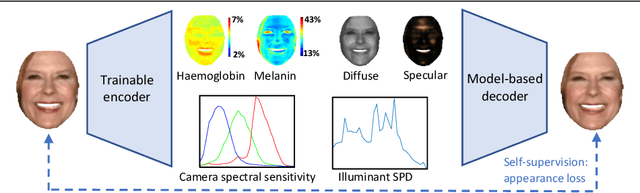
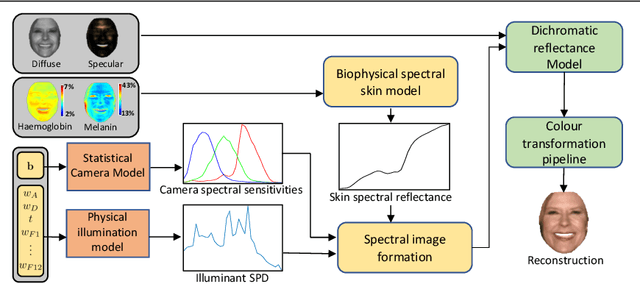
In this paper we present BioFaceNet, a deep CNN that learns to decompose a single face image into biophysical parameters maps, diffuse and specular shading maps as well as estimating the spectral power distribution of the scene illuminant and the spectral sensitivity of the camera. The network comprises a fully convolutional encoder for estimating the spatial maps with a fully connected branch for estimating the vector quantities. The network is trained using a self-supervised appearance loss computed via a model-based decoder. The task is highly underconstrained so we impose a number of model-based priors. Skin spectral reflectance is restricted to a biophysical model, we impose a statistical prior on camera spectral sensitivities, a physical constraint on illumination spectra, a sparsity prior on specular reflections and direct supervision on diffuse shading using a rough shape proxy. We show convincing qualitative results on in-the-wild data and introduce a benchmark for quantitative evaluation on this new task.