 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Joint Network for Grasp Detection Conditioned on Natural Language Commands
Apr 01, 2021
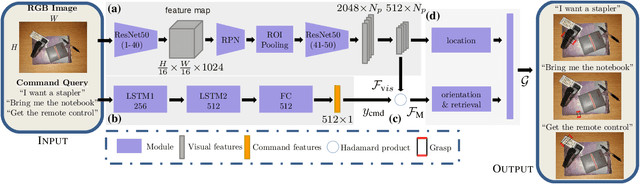

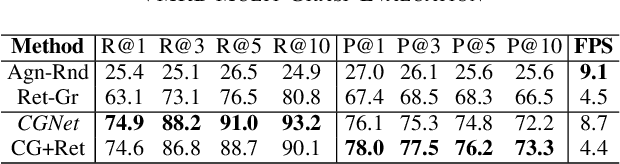
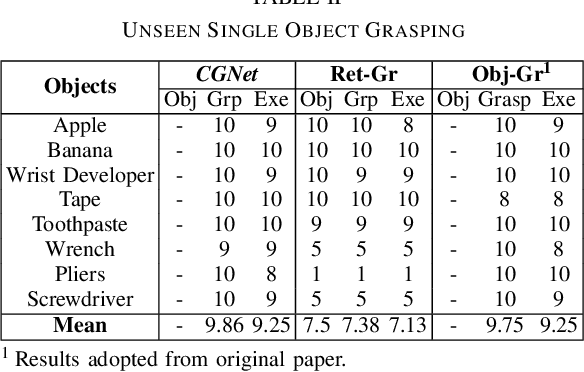
We consider the task of grasping a target object based on a natural language command query. Previous work primarily focused on localizing the object given the query, which requires a separate grasp detection module to grasp it. The cascaded application of two pipelines incurs errors in overlapping multi-object cases due to ambiguity in the individual outputs. This work proposes a model named Command Grasping Network(CGNet) to directly output command satisficing grasps from RGB image and textual command inputs. A dataset with ground truth (image, command, grasps) tuple is generated based on the VMRD dataset to train the proposed network. Experimental results on the generated test set show that CGNet outperforms a cascaded object-retrieval and grasp detection baseline by a large margin. Three physical experiments demonstrate the functionality and performance of CGNet.
LAI Estimation of Cucumber Crop Based on Improved Fully Convolutional Network
Apr 16, 2021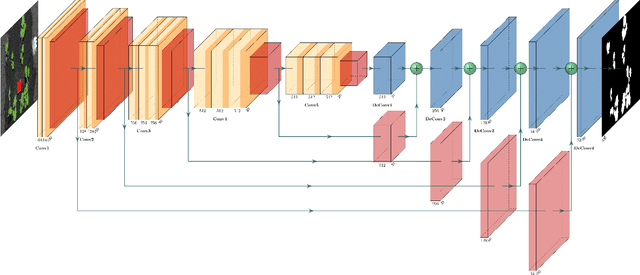
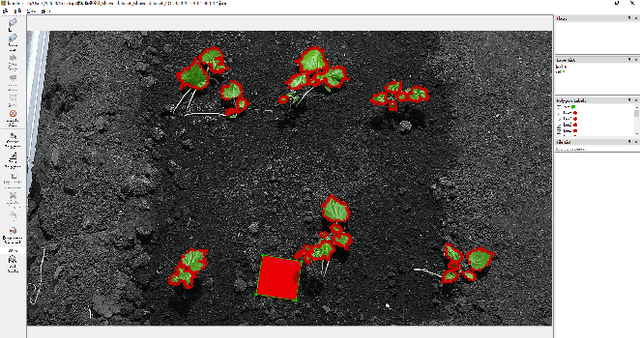


LAI (Leaf Area Index) is of great importance for crop yield estimation in agronomy. It is directly related to plant growth status, net assimilation rate, plant photosynthesis, and carbon dioxide in the environment. How to measure LAI accurately and efficiently is the key to the crop yield estimation problem. Manual measurement consumes a lot of human resources and material resources. Remote sensing technology is not suitable for near-Earth LAI measurement. Besides, methods based on traditional digital image processing are greatly affected by environmental noise and image exposure. Nowadays, deep learning is widely used in many fields. The improved FCN (Fully Convolutional Network) is proposed in our study for LAI measure task. Eighty-two cucumber images collected from our greenhouse are labeled to fine-tuning the pre-trained model. The result shows that the improved FCN model performs well on our dataset. Our method's mean IoU can reach 0.908, which is 11% better than conventional methods and 4.7% better than the basic FCN model.
Spatial Attentive Single-Image Deraining with a High Quality Real Rain Dataset
Apr 02, 2019
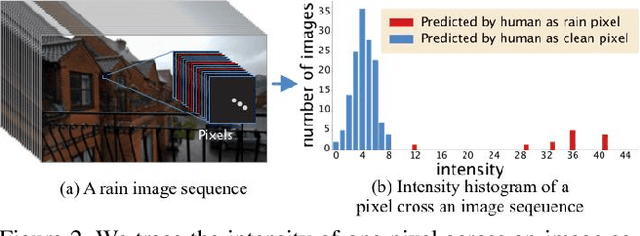

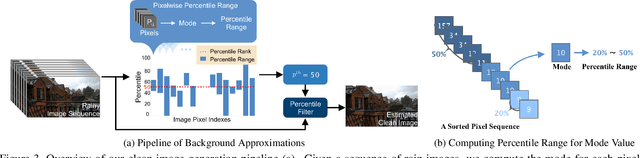
Removing rain streaks from a single image has been drawing considerable attention as rain streaks can severely degrade the image quality and affect the performance of existing outdoor vision tasks. While recent CNN-based derainers have reported promising performances, deraining remains an open problem for two reasons. First, existing synthesized rain datasets have only limited realism, in terms of modeling real rain characteristics such as rain shape, direction and intensity. Second, there are no public benchmarks for quantitative comparisons on real rain images, which makes the current evaluation less objective. The core challenge is that real world rain/clean image pairs cannot be captured at the same time. In this paper, we address the single image rain removal problem in two ways. First, we propose a semi-automatic method that incorporates temporal priors and human supervision to generate a high-quality clean image from each input sequence of real rain images. Using this method, we construct a large-scale dataset of $\sim$$29.5K$ rain/rain-free image pairs that covers a wide range of natural rain scenes. Second, to better cover the stochastic distribution of real rain streaks, we propose a novel SPatial Attentive Network (SPANet) to remove rain streaks in a local-to-global manner. Extensive experiments demonstrate that our network performs favorably against the state-of-the-art deraining methods.
Image-based Navigation using Visual Features and Map
Dec 10, 2018
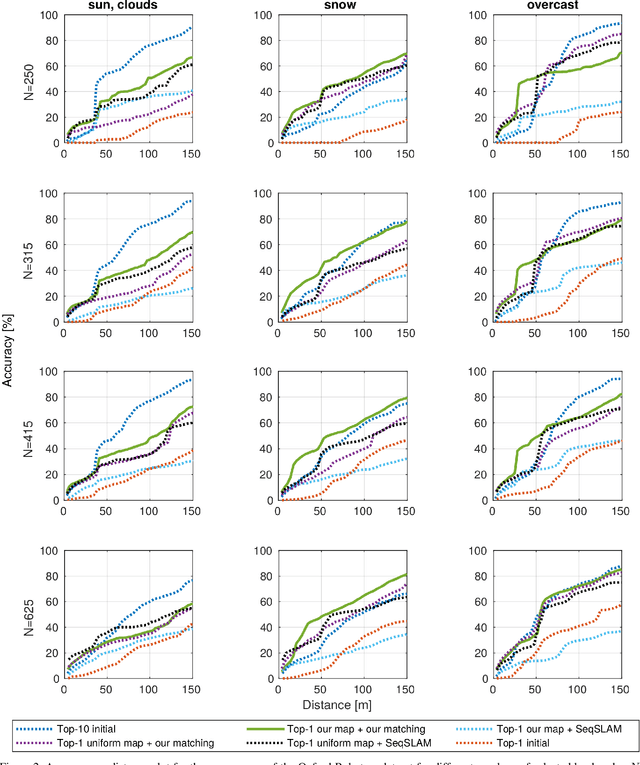
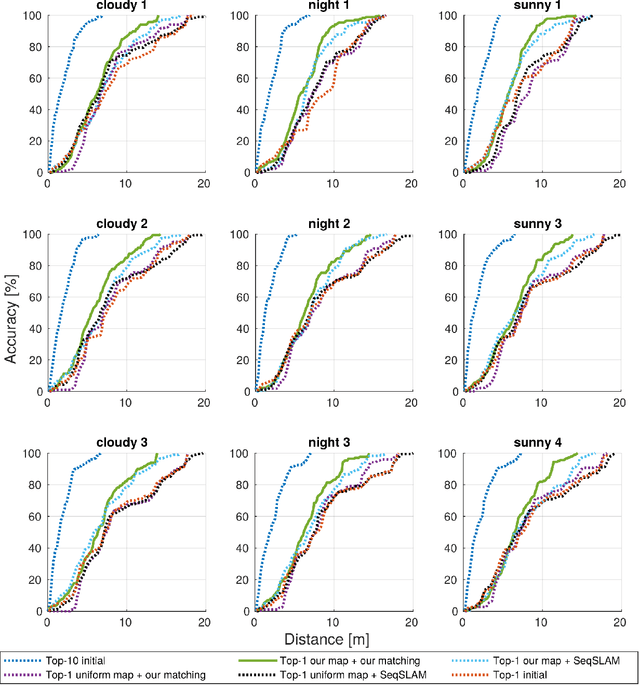
Building on progress in feature representations for image retrieval, image-based localization has seen a surge of research interest. Image-based localization has the advantage of being inexpensive and efficient, often avoiding the use of 3D metric maps altogether. This said, the need to maintain a large number of reference images as an effective support of localization in a scene, nonetheless calls for them to be organized in a map structure of some kind. The problem of localization often arises as part of a navigation process. We are, therefore, interested in summarizing the reference images as a set of landmarks, which meet the requirements for image-based navigation. A contribution of the paper is to formulate such a set of requirements for the two sub-tasks involved: map construction and self localization. These requirements are then exploited for compact map representation and accurate self-localization, using the framework of a network flow problem. During this process, we formulate the map construction and self-localization problems as convex quadratic and second-order cone programs, respectively. We evaluate our methods on publicly available indoor and outdoor datasets, where they outperform existing methods significantly.
Hierarchical View Predictor: Unsupervised 3D Global Feature Learning through Hierarchical Prediction among Unordered Views
Aug 08, 2021

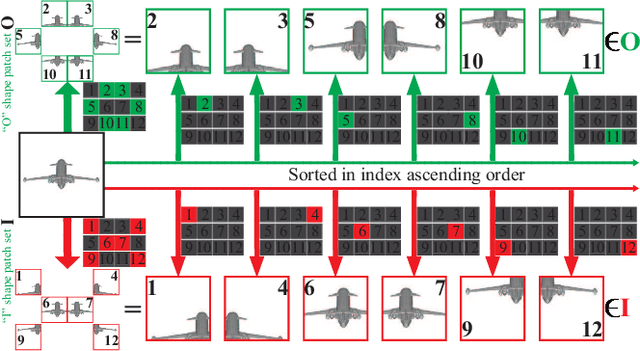

Unsupervised learning of global features for 3D shape analysis is an important research challenge because it avoids manual effort for supervised information collection. In this paper, we propose a view-based deep learning model called Hierarchical View Predictor (HVP) to learn 3D shape features from unordered views in an unsupervised manner. To mine highly discriminative information from unordered views, HVP performs a novel hierarchical view prediction over a view pair, and aggregates the knowledge learned from the predictions in all view pairs into a global feature. In a view pair, we pose hierarchical view prediction as the task of hierarchically predicting a set of image patches in a current view from its complementary set of patches, and in addition, completing the current view and its opposite from any one of the two sets of patches. Hierarchical prediction, in patches to patches, patches to view and view to view, facilitates HVP to effectively learn the structure of 3D shapes from the correlation between patches in the same view and the correlation between a pair of complementary views. In addition, the employed implicit aggregation over all view pairs enables HVP to learn global features from unordered views. Our results show that HVP can outperform state-of-the-art methods under large-scale 3D shape benchmarks in shape classification and retrieval.
The QXS-SAROPT Dataset for Deep Learning in SAR-Optical Data Fusion
Mar 15, 2021Deep learning techniques have made an increasing impact on the field of remote sensing. However, deep neural networks based fusion of multimodal data from different remote sensors with heterogenous characteristics has not been fully explored, due to the lack of availability of big amounts of perfectly aligned multi-sensor image data with diverse scenes of high resolution, especially for synthetic aperture radar (SAR) data and optical imagery. In this paper, we publish the QXS-SAROPT dataset to foster deep learning research in SAR-optical data fusion. QXS-SAROPT comprises 20,000 pairs of corresponding image patches, collected from three port cities: San Diego, Shanghai and Qingdao acquired by the SAR satellite GaoFen-3 and optical satellites of Google Earth. Besides a detailed description of the dataset, we show exemplary results for two representative applications, namely SAR-optical image matching and SAR ship detection boosted by cross-modal information from optical images. Since QXS-SAROPT is a large open dataset with multiple scenes of the highest resolution of this kind, we believe it will support further developments in the field of deep learning based SAR-optical data fusion for remote sensing.
Training Over-parameterized Models with Non-decomposable Objectives
Jul 09, 2021
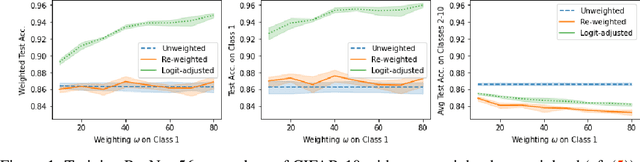

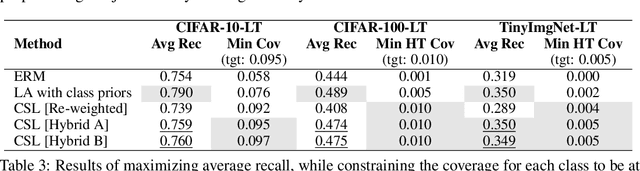
Many modern machine learning applications come with complex and nuanced design goals such as minimizing the worst-case error, satisfying a given precision or recall target, or enforcing group-fairness constraints. Popular techniques for optimizing such non-decomposable objectives reduce the problem into a sequence of cost-sensitive learning tasks, each of which is then solved by re-weighting the training loss with example-specific costs. We point out that the standard approach of re-weighting the loss to incorporate label costs can produce unsatisfactory results when used to train over-parameterized models. As a remedy, we propose new cost-sensitive losses that extend the classical idea of logit adjustment to handle more general cost matrices. Our losses are calibrated, and can be further improved with distilled labels from a teacher model. Through experiments on benchmark image datasets, we showcase the effectiveness of our approach in training ResNet models with common robust and constrained optimization objectives.
Distilling the Knowledge from Normalizing Flows
Jun 25, 2021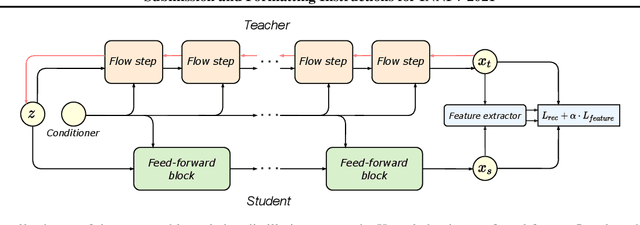
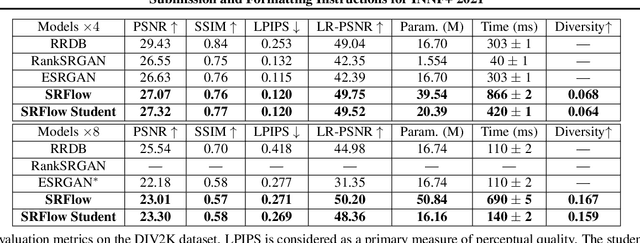
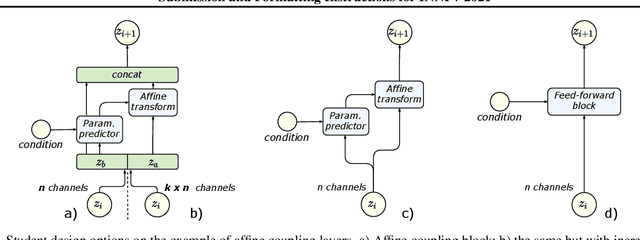
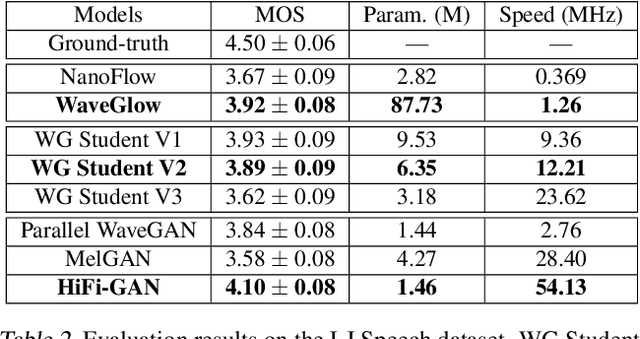
Normalizing flows are a powerful class of generative models demonstrating strong performance in several speech and vision problems. In contrast to other generative models, normalizing flows are latent variable models with tractable likelihoods and allow for stable training. However, they have to be carefully designed to represent invertible functions with efficient Jacobian determinant calculation. In practice, these requirements lead to overparameterized and sophisticated architectures that are inferior to alternative feed-forward models in terms of inference time and memory consumption. In this work, we investigate whether one can distill flow-based models into more efficient alternatives. We provide a positive answer to this question by proposing a simple distillation approach and demonstrating its effectiveness on state-of-the-art conditional flow-based models for image super-resolution and speech synthesis.
White-Box Cartoonization Using An Extended GAN Framework
Jul 09, 2021In the present study, we propose to implement a new framework for estimating generative models via an adversarial process to extend an existing GAN framework and develop a white-box controllable image cartoonization, which can generate high-quality cartooned images/videos from real-world photos and videos. The learning purposes of our system are based on three distinct representations: surface representation, structure representation, and texture representation. The surface representation refers to the smooth surface of the images. The structure representation relates to the sparse colour blocks and compresses generic content. The texture representation shows the texture, curves, and features in cartoon images. Generative Adversarial Network (GAN) framework decomposes the images into different representations and learns from them to generate cartoon images. This decomposition makes the framework more controllable and flexible which allows users to make changes based on the required output. This approach overcomes any previous system in terms of maintaining clarity, colours, textures, shapes of images yet showing the characteristics of cartoon images.
An Autoencoder-based Learned Image Compressor: Description of Challenge Proposal by NCTU
Feb 20, 2019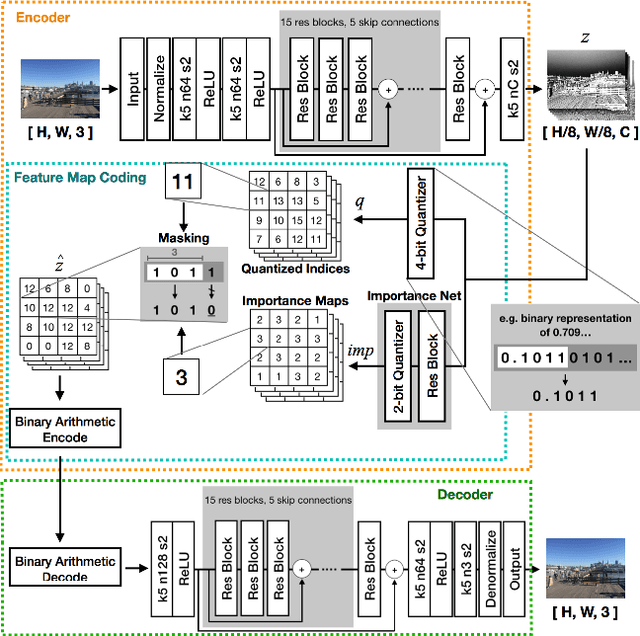
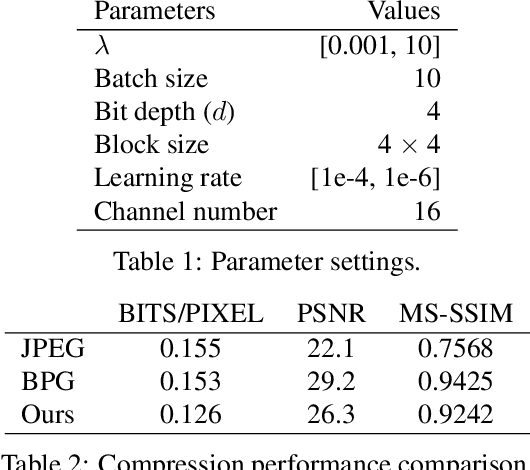

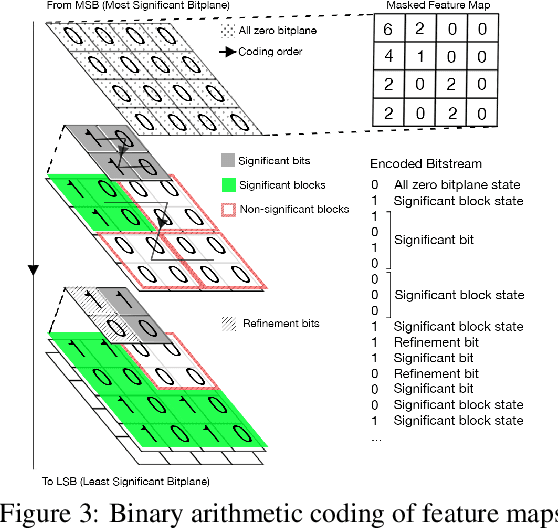
We propose a lossy image compression system using the deep-learning autoencoder structure to participate in the Challenge on Learned Image Compression (CLIC) 2018. Our autoencoder uses the residual blocks with skip connections to reduce the correlation among image pixels and condense the input image into a set of feature maps, a compact representation of the original image. The bit allocation and bitrate control are implemented by using the importance maps and quantizer. The importance maps are generated by a separate neural net in the encoder. The autoencoder and the importance net are trained jointly based on minimizing a weighted sum of mean squared error, MS-SSIM, and a rate estimate. Our aim is to produce reconstructed images with good subjective quality subject to the 0.15 bits-per-pixel constraint.