 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Super Resolution via Bilinear Pooling: Application to Confocal Endomicroscopy
Jun 18, 2019
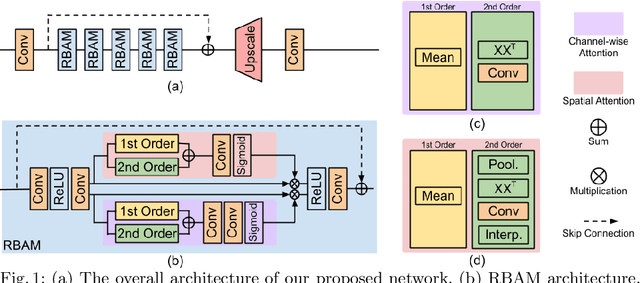

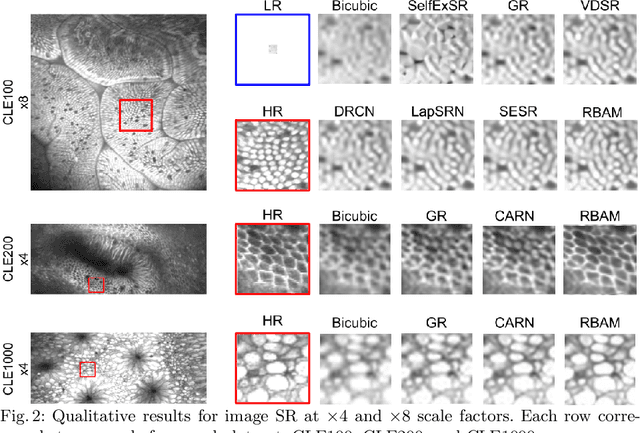

Recent developments in image acquisition literature have miniaturized the confocal laser endomicroscopes to improve usability and flexibility of the apparatus in actual clinical settings. However, miniaturized devices collect less light and have fewer optical components, resulting in pixelation artifacts and low resolution images. Owing to the strength of deep networks, many supervised methods known as super resolution have achieved considerable success in restoring low resolution images by generating the missing high frequency details. In this work, we propose a novel attention mechanism that, for the first time, combines 1st- and 2nd-order statistics for pooling operation, in the spatial and channel-wise dimensions. We compare the efficacy of our method to 11 other existing single image super resolution techniques that compensate for the reduction in image quality caused by the necessity of endomicroscope miniaturization. All evaluations are carried out on three publicly available datasets. Experimental results show that our method can produce competitive results against state-of-the-art in terms of PSNR, SSIM, and IFC metrics. Additionally, our proposed method contains small number of parameters, which makes it lightweight and fast for real-time applications.
Category-Level 6D Object Pose Estimation via Cascaded Relation and Recurrent Reconstruction Networks
Aug 19, 2021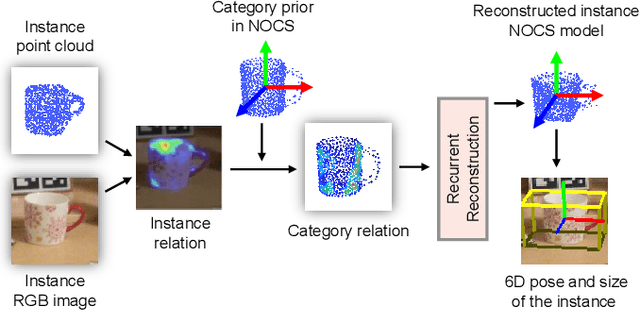
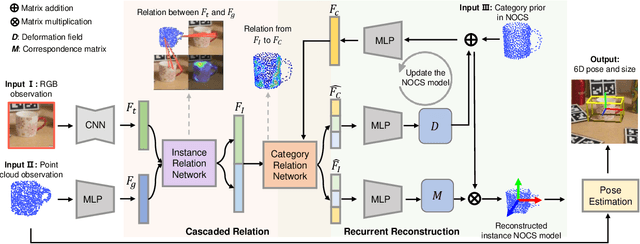
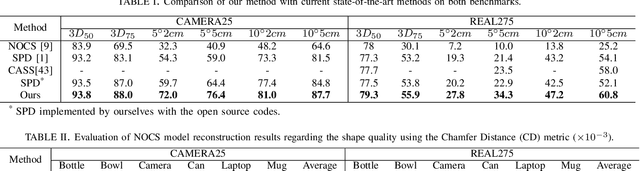
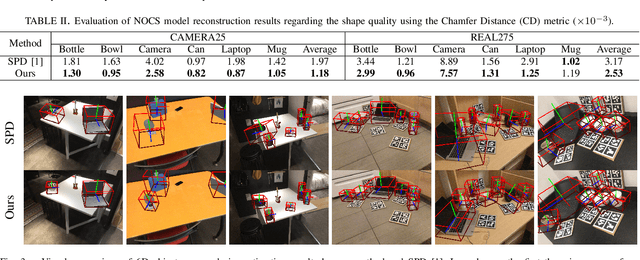
Category-level 6D pose estimation, aiming to predict the location and orientation of unseen object instances, is fundamental to many scenarios such as robotic manipulation and augmented reality, yet still remains unsolved. Precisely recovering instance 3D model in the canonical space and accurately matching it with the observation is an essential point when estimating 6D pose for unseen objects. In this paper, we achieve accurate category-level 6D pose estimation via cascaded relation and recurrent reconstruction networks. Specifically, a novel cascaded relation network is dedicated for advanced representation learning to explore the complex and informative relations among instance RGB image, instance point cloud and category shape prior. Furthermore, we design a recurrent reconstruction network for iterative residual refinement to progressively improve the reconstruction and correspondence estimations from coarse to fine. Finally, the instance 6D pose is obtained leveraging the estimated dense correspondences between the instance point cloud and the reconstructed 3D model in the canonical space. We have conducted extensive experiments on two well-acknowledged benchmarks of category-level 6D pose estimation, with significant performance improvement over existing approaches. On the representatively strict evaluation metrics of $3D_{75}$ and $5^{\circ}2 cm$, our method exceeds the latest state-of-the-art SPD by $4.9\%$ and $17.7\%$ on the CAMERA25 dataset, and by $2.7\%$ and $8.5\%$ on the REAL275 dataset. Codes are available at https://wangjiaze.cn/projects/6DPoseEstimation.html.
Track without Appearance: Learn Box and Tracklet Embedding with Local and Global Motion Patterns for Vehicle Tracking
Aug 13, 2021
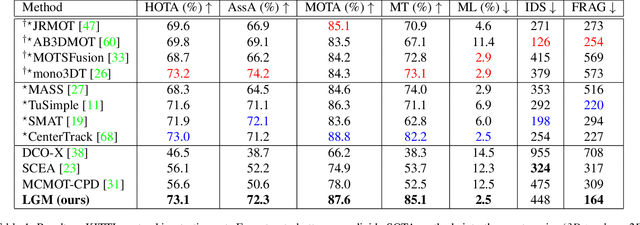

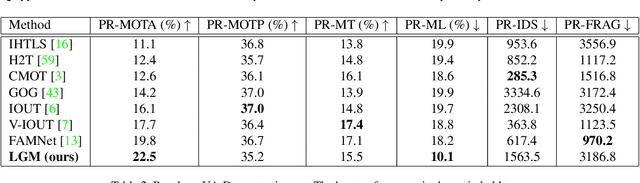
Vehicle tracking is an essential task in the multi-object tracking (MOT) field. A distinct characteristic in vehicle tracking is that the trajectories of vehicles are fairly smooth in both the world coordinate and the image coordinate. Hence, models that capture motion consistencies are of high necessity. However, tracking with the standalone motion-based trackers is quite challenging because targets could get lost easily due to limited information, detection error and occlusion. Leveraging appearance information to assist object re-identification could resolve this challenge to some extent. However, doing so requires extra computation while appearance information is sensitive to occlusion as well. In this paper, we try to explore the significance of motion patterns for vehicle tracking without appearance information. We propose a novel approach that tackles the association issue for long-term tracking with the exclusive fully-exploited motion information. We address the tracklet embedding issue with the proposed reconstruct-to-embed strategy based on deep graph convolutional neural networks (GCN). Comprehensive experiments on the KITTI-car tracking dataset and UA-Detrac dataset show that the proposed method, though without appearance information, could achieve competitive performance with the state-of-the-art (SOTA) trackers. The source code will be available at https://github.com/GaoangW/LGMTracker.
GridDehazeNet: Attention-Based Multi-Scale Network for Image Dehazing
Aug 08, 2019
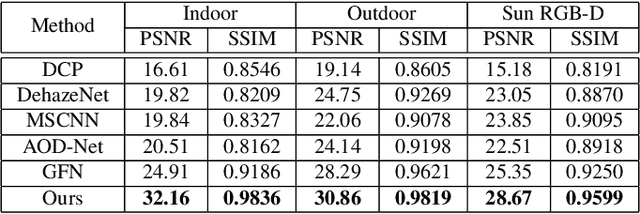
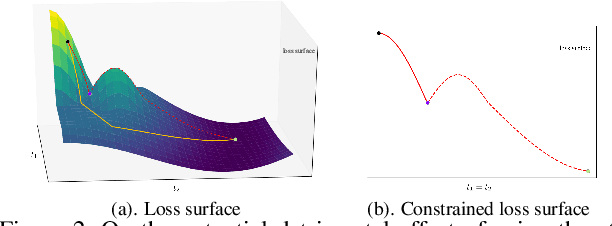
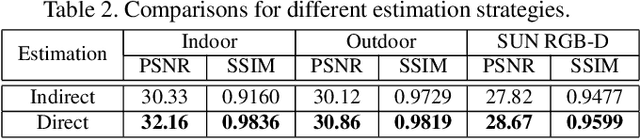
We propose an end-to-end trainable Convolutional Neural Network (CNN), named GridDehazeNet, for single image dehazing. The GridDehazeNet consists of three modules: pre-processing, backbone, and post-processing. The trainable pre-processing module can generate learned inputs with better diversity and more pertinent features as compared to those derived inputs produced by hand-selected pre-processing methods. The backbone module implements a novel attention-based multi-scale estimation on a grid network, which can effectively alleviate the bottleneck issue often encountered in the conventional multi-scale approach. The post-processing module helps to reduce the artifacts in the final output. Experimental results indicate that the GridDehazeNet outperforms the state-of-the-arts on both synthetic and real-world images. The proposed hazing method does not rely on the atmosphere scattering model, and we provide an explanation as to why it is not necessarily beneficial to take advantage of the dimension reduction offered by the atmosphere scattering model for image dehazing, even if only the dehazing results on synthetic images are concerned.
Models Genesis: Generic Autodidactic Models for 3D Medical Image Analysis
Aug 19, 2019
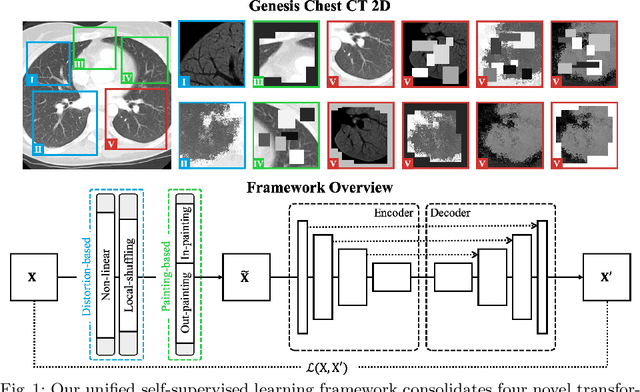
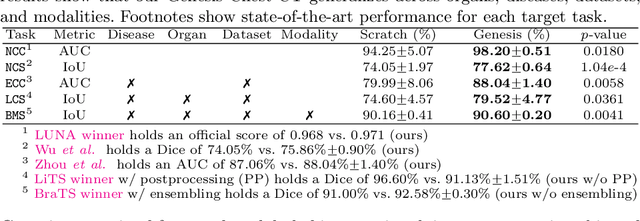
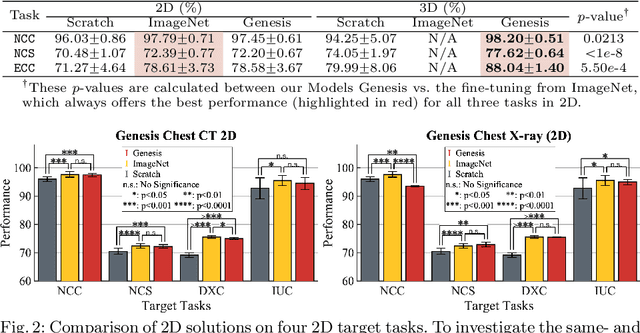
Transfer learning from natural image to medical image has established as one of the most practical paradigms in deep learning for medical image analysis. However, to fit this paradigm, 3D imaging tasks in the most prominent imaging modalities (e.g., CT and MRI) have to be reformulated and solved in 2D, losing rich 3D anatomical information and inevitably compromising the performance. To overcome this limitation, we have built a set of models, called Generic Autodidactic Models, nicknamed Models Genesis, because they are created ex nihilo (with no manual labeling), self-taught (learned by self-supervision), and generic (served as source models for generating application-specific target models). Our extensive experiments demonstrate that our Models Genesis significantly outperform learning from scratch in all five target 3D applications covering both segmentation and classification. More importantly, learning a model from scratch simply in 3D may not necessarily yield performance better than transfer learning from ImageNet in 2D, but our Models Genesis consistently top any 2D approaches including fine-tuning the models pre-trained from ImageNet as well as fine-tuning the 2D versions of our Models Genesis, confirming the importance of 3D anatomical information and significance of our Models Genesis for 3D medical imaging. This performance is attributed to our unified self-supervised learning framework, built on a simple yet powerful observation: the sophisticated yet recurrent anatomy in medical images can serve as strong supervision signals for deep models to learn common anatomical representation automatically via self-supervision. As open science, all pre-trained Models Genesis are available at https://github.com/MrGiovanni/ModelsGenesis.
Semantic Hierarchy Preserving Deep Hashing for Large-scale Image Retrieval
Apr 12, 2019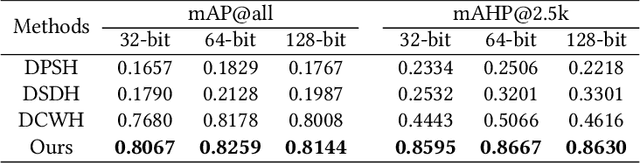

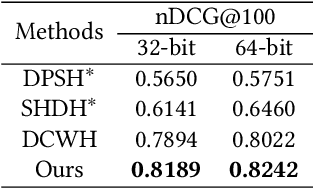
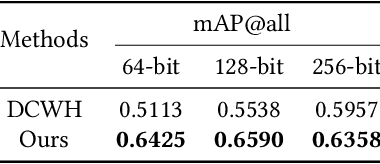
Convolutional neural networks have been widely used in content-based image retrieval. To better deal with large-scale data, the deep hashing model is proposed as an effective method, which maps an image to a binary code that can be used for hashing search. However, most existing deep hashing models only utilize fine-level semantic labels or convert them to similar/dissimilar labels for training. The natural semantic hierarchy structures are ignored in the training stage of the deep hashing model. In this paper, we present an effective algorithm to train a deep hashing model that can preserve a semantic hierarchy structure for large-scale image retrieval. Experiments on two datasets show that our method improves the fine-level retrieval performance. Meanwhile, our model achieves state-of-the-art results in terms of hierarchical retrieval.
Attention-based fusion of semantic boundary and non-boundary information to improve semantic segmentation
Aug 05, 2021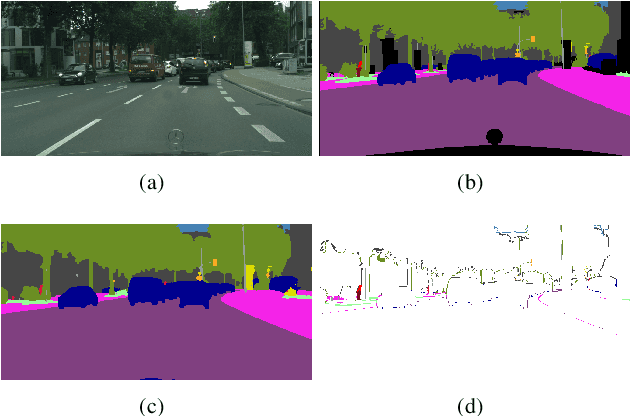
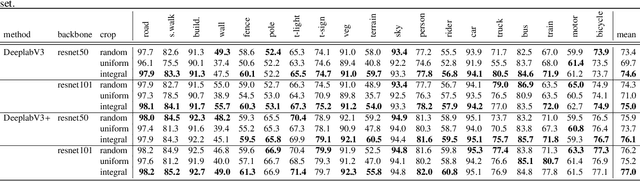
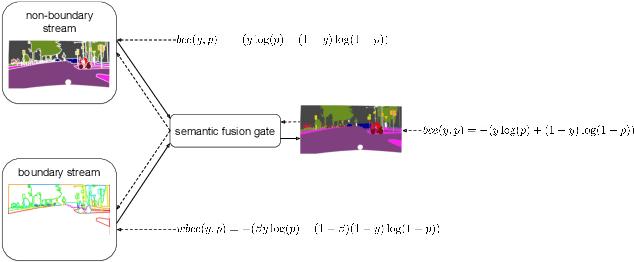

This paper introduces a method for image semantic segmentation grounded on a novel fusion scheme, which takes place inside a deep convolutional neural network. The main goal of our proposal is to explore object boundary information to improve the overall segmentation performance. Unlike previous works that combine boundary and segmentation features, or those that use boundary information to regularize semantic segmentation, we instead propose a novel approach that embodies boundary information onto segmentation. For that, our semantic segmentation method uses two streams, which are combined through an attention gate, forming an end-to-end Y-model. To the best of our knowledge, ours is the first work to show that boundary detection can improve semantic segmentation when fused through a semantic fusion gate (attention model). We performed an extensive evaluation of our method over public data sets. We found competitive results on all data sets after comparing our proposed model with other twelve state-of-the-art segmenters, considering the same training conditions. Our proposed model achieved the best mIoU on the CityScapes, CamVid, and Pascal Context data sets, and the second best on Mapillary Vistas.
Dynamic Event Camera Calibration
Jul 20, 2021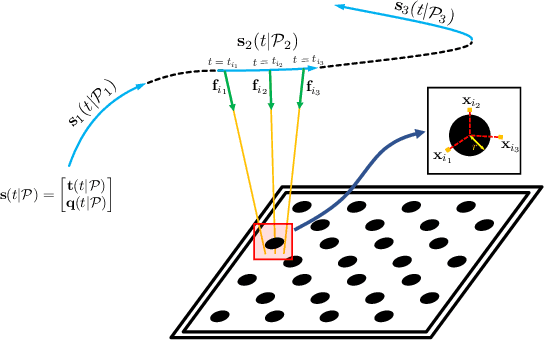
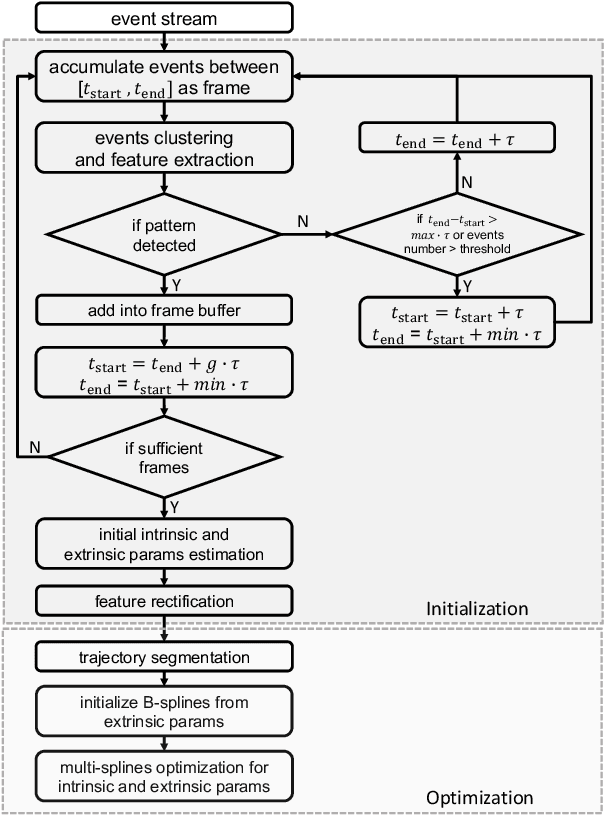


Camera calibration is an important prerequisite towards the solution of 3D computer vision problems. Traditional methods rely on static images of a calibration pattern. This raises interesting challenges towards the practical usage of event cameras, which notably require image change to produce sufficient measurements. The current standard for event camera calibration therefore consists of using flashing patterns. They have the advantage of simultaneously triggering events in all reprojected pattern feature locations, but it is difficult to construct or use such patterns in the field. We present the first dynamic event camera calibration algorithm. It calibrates directly from events captured during relative motion between camera and calibration pattern. The method is propelled by a novel feature extraction mechanism for calibration patterns, and leverages existing calibration tools before optimizing all parameters through a multi-segment continuous-time formulation. As demonstrated through our results on real data, the obtained calibration method is highly convenient and reliably calibrates from data sequences spanning less than 10 seconds.
Visual Tree Convolutional Neural Network in Image Classification
Jun 04, 2019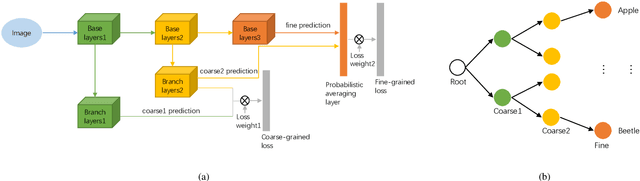
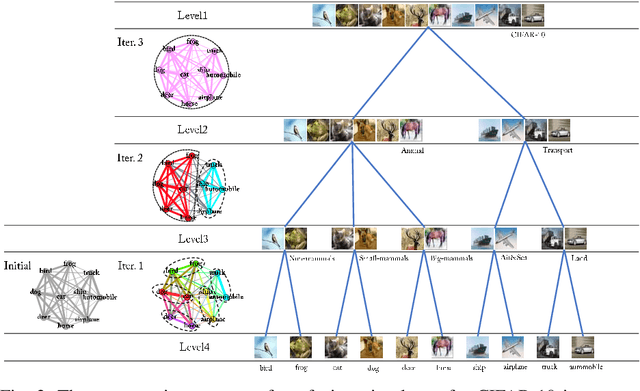
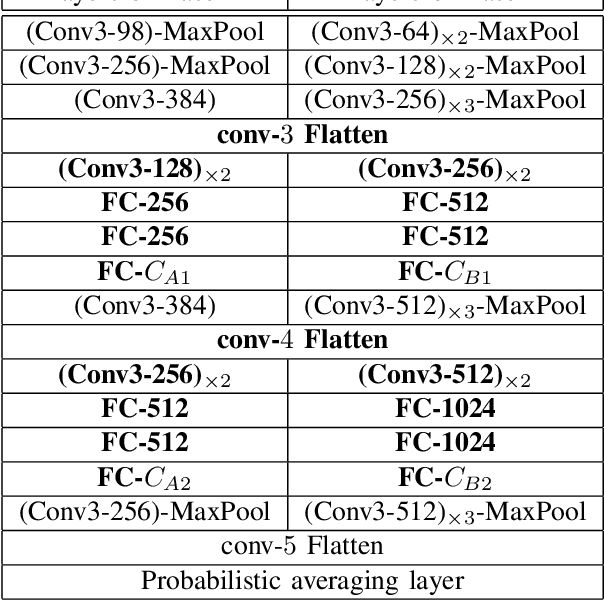
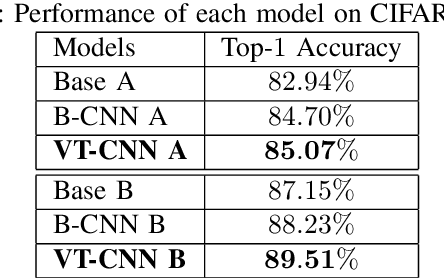
In image classification, Convolutional Neural Network(CNN) models have achieved high performance with the rapid development in deep learning. However, some categories in the image datasets are more difficult to distinguished than others. Improving the classification accuracy on these confused categories is benefit to the overall performance. In this paper, we build a Confusion Visual Tree(CVT) based on the confused semantic level information to identify the confused categories. With the information provided by the CVT, we can lead the CNN training procedure to pay more attention on these confused categories. Therefore, we propose Visual Tree Convolutional Neural Networks(VT-CNN) based on the original deep CNN embedded with our CVT. We evaluate our VT-CNN model on the benchmark datasets CIFAR-10 and CIFAR-100. In our experiments, we build up 3 different VT-CNN models and they obtain improvement over their based CNN models by 1.36%, 0.89% and 0.64%, respectively.
* 7 pages, 2 figures, conference
Evaluating CLIP: Towards Characterization of Broader Capabilities and Downstream Implications
Aug 05, 2021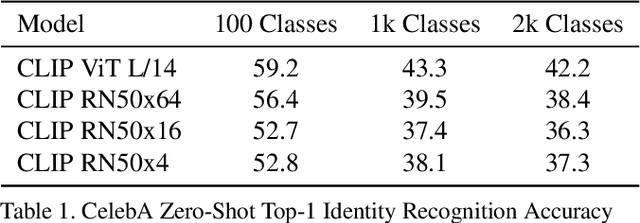
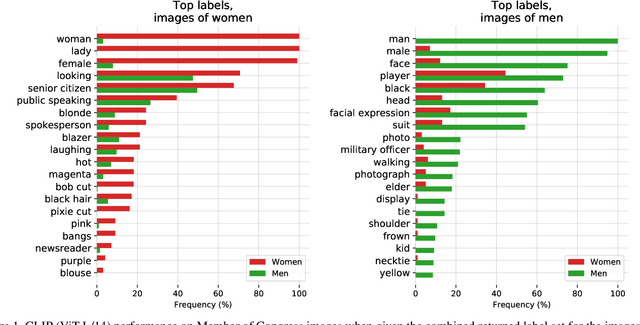


Recently, there have been breakthroughs in computer vision ("CV") models that are more generalizable with the advent of models such as CLIP and ALIGN. In this paper, we analyze CLIP and highlight some of the challenges such models pose. CLIP reduces the need for task specific training data, potentially opening up many niche tasks to automation. CLIP also allows its users to flexibly specify image classification classes in natural language, which we find can shift how biases manifest. Additionally, through some preliminary probes we find that CLIP can inherit biases found in prior computer vision systems. Given the wide and unpredictable domain of uses for such models, this raises questions regarding what sufficiently safe behaviour for such systems may look like. These results add evidence to the growing body of work calling for a change in the notion of a 'better' model--to move beyond simply looking at higher accuracy at task-oriented capability evaluations, and towards a broader 'better' that takes into account deployment-critical features such as different use contexts, and people who interact with the model when thinking about model deployment.