 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fabrication-Aware Reverse Engineering for Carpentry
Jul 21, 2021

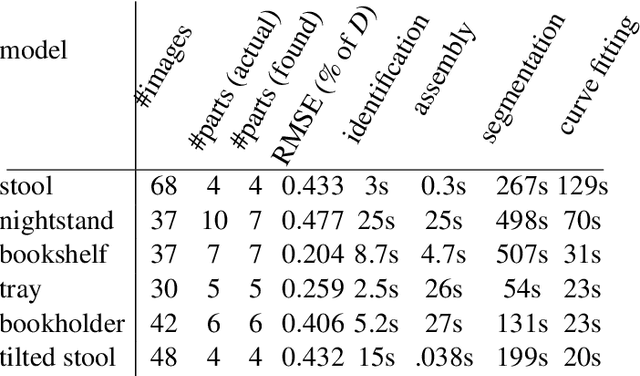
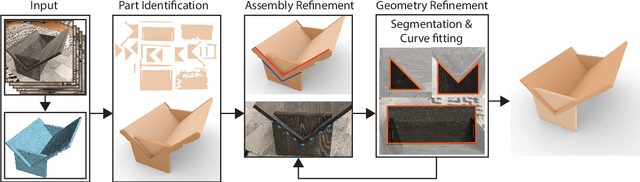
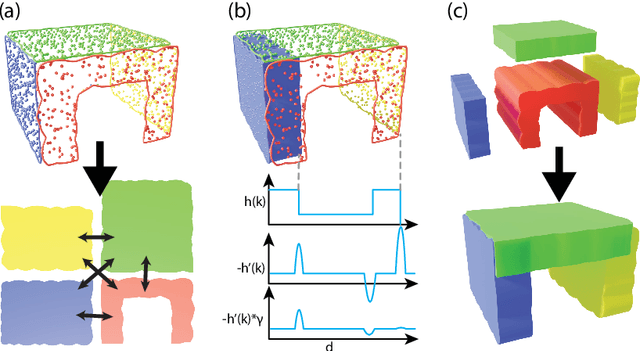
We propose a novel method to generate fabrication blueprints from images of carpentered items. While 3D reconstruction from images is a well-studied problem, typical approaches produce representations that are ill-suited for computer-aided design and fabrication applications. Our key insight is that fabrication processes define and constrain the design space for carpentered objects, and can be leveraged to develop novel reconstruction methods. Our method makes use of domain-specific constraints to recover not just valid geometry, but a semantically valid assembly of parts, using a combination of image-based and geometric optimization techniques. We demonstrate our method on a variety of wooden objects and furniture, and show that we can automatically obtain designs that are both easy to edit and accurate recreations of the ground truth. We further illustrate how our method can be used to fabricate a physical replica of the captured object as well as a customized version, which can be produced by directly editing the reconstructed model in CAD software.
Decoupling Inherent Risk and Early Cancer Signs in Image-based Breast Cancer Risk Models
Jul 11, 2020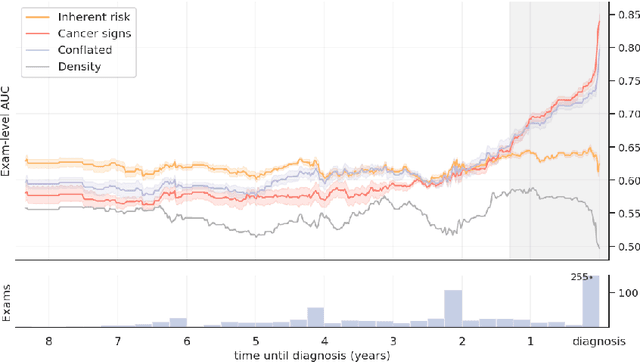

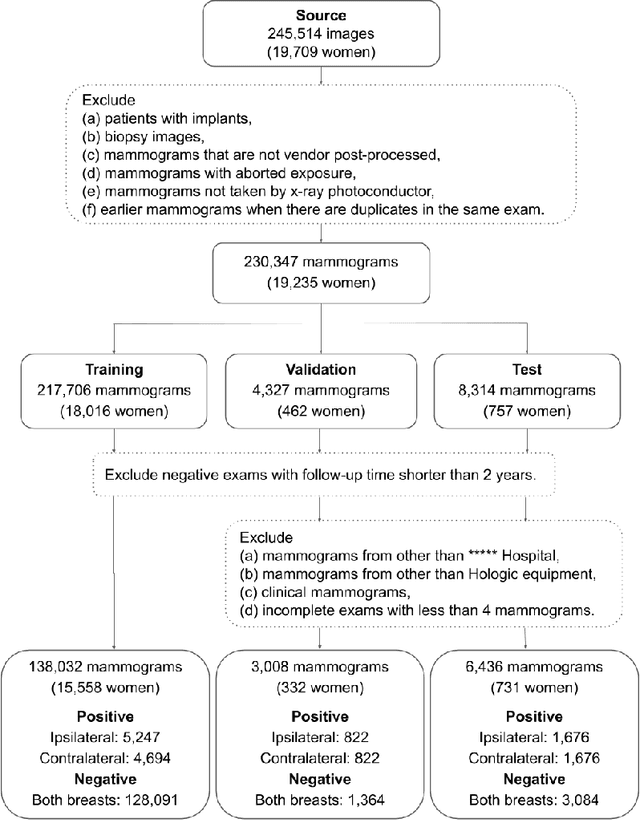
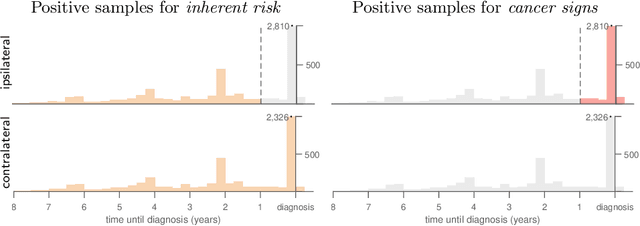
The ability to accurately estimate risk of developing breast cancer would be invaluable for clinical decision-making. One promising new approach is to integrate image-based risk models based on deep neural networks. However, one must take care when using such models, as selection of training data influences the patterns the network will learn to identify. With this in mind, we trained networks using three different criteria to select the positive training data (i.e. images from patients that will develop cancer): an inherent risk model trained on images with no visible signs of cancer, a cancer signs model trained on images containing cancer or early signs of cancer, and a conflated model trained on all images from patients with a cancer diagnosis. We find that these three models learn distinctive features that focus on different patterns, which translates to contrasts in performance. Short-term risk is best estimated by the cancer signs model, whilst long-term risk is best estimated by the inherent risk model. Carelessly training with all images conflates inherent risk with early cancer signs, and yields sub-optimal estimates in both regimes. As a consequence, conflated models may lead physicians to recommend preventative action when early cancer signs are already visible.
Few-shot Visual Relationship Co-localization
Aug 26, 2021
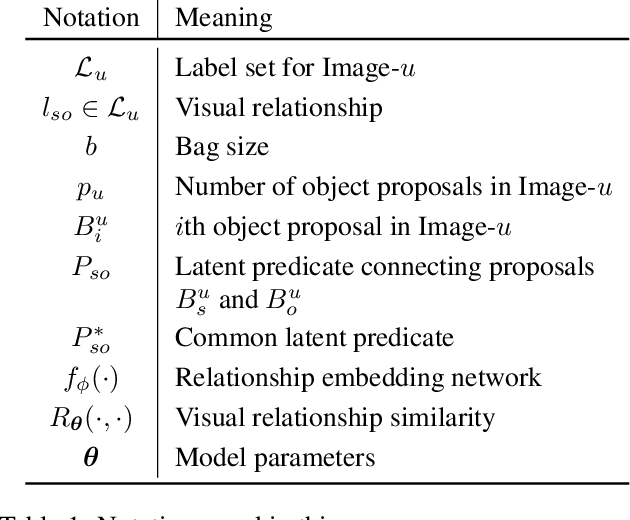
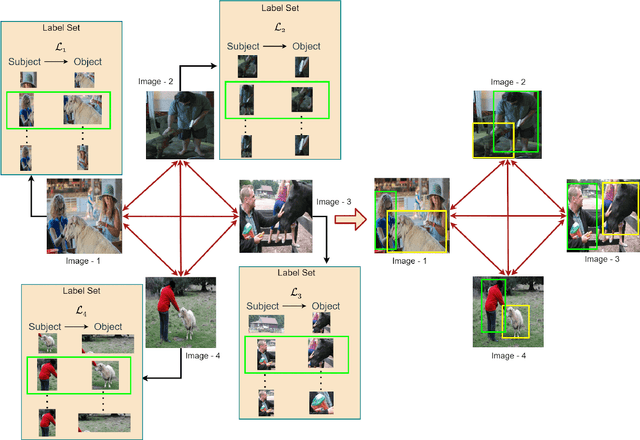
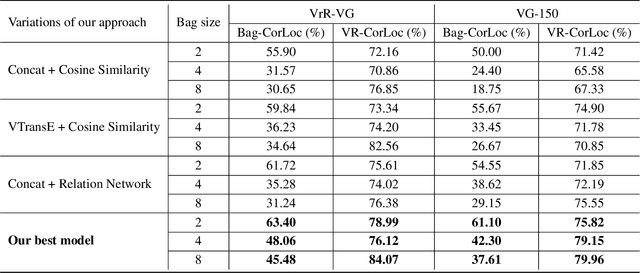
In this paper, given a small bag of images, each containing a common but latent predicate, we are interested in localizing visual subject-object pairs connected via the common predicate in each of the images. We refer to this novel problem as visual relationship co-localization or VRC as an abbreviation. VRC is a challenging task, even more so than the well-studied object co-localization task. This becomes further challenging when using just a few images, the model has to learn to co-localize visual subject-object pairs connected via unseen predicates. To solve VRC, we propose an optimization framework to select a common visual relationship in each image of the bag. The goal of the optimization framework is to find the optimal solution by learning visual relationship similarity across images in a few-shot setting. To obtain robust visual relationship representation, we utilize a simple yet effective technique that learns relationship embedding as a translation vector from visual subject to visual object in a shared space. Further, to learn visual relationship similarity, we utilize a proven meta-learning technique commonly used for few-shot classification tasks. Finally, to tackle the combinatorial complexity challenge arising from an exponential number of feasible solutions, we use a greedy approximation inference algorithm that selects approximately the best solution. We extensively evaluate our proposed framework on variations of bag sizes obtained from two challenging public datasets, namely VrR-VG and VG-150, and achieve impressive visual co-localization performance.
Continental-Scale Building Detection from High Resolution Satellite Imagery
Jul 29, 2021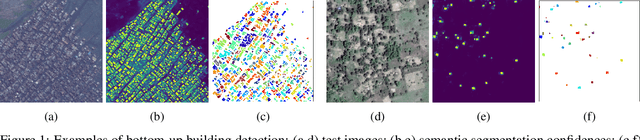
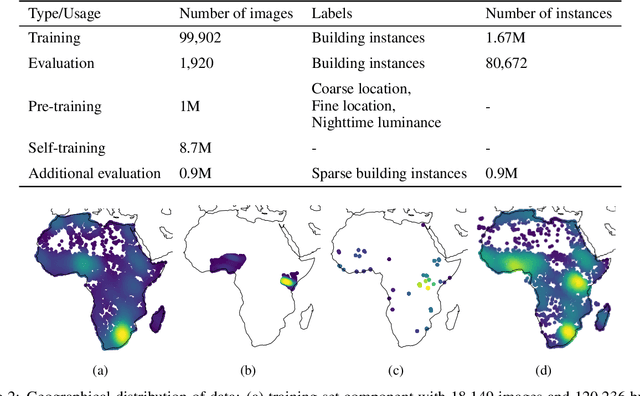

Identifying the locations and footprints of buildings is vital for many practical and scientific purposes. Such information can be particularly useful in developing regions where alternative data sources may be scarce. In this work, we describe a model training pipeline for detecting buildings across the entire continent of Africa, using 50 cm satellite imagery. Starting with the U-Net model, widely used in satellite image analysis, we study variations in architecture, loss functions, regularization, pre-training, self-training and post-processing that increase instance segmentation performance. Experiments were carried out using a dataset of 100k satellite images across Africa containing 1.75M manually labelled building instances, and further datasets for pre-training and self-training. We report novel methods for improving performance of building detection with this type of model, including the use of mixup (mAP +0.12) and self-training with soft KL loss (mAP +0.06). The resulting pipeline obtains good results even on a wide variety of challenging rural and urban contexts, and was used to create the Open Buildings dataset of 516M Africa-wide detected footprints.
Hybrid Classification and Reasoning for Image-based Constraint Solving
Mar 24, 2020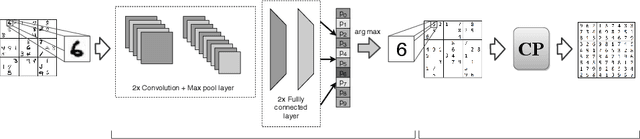

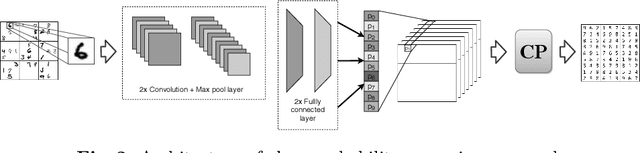
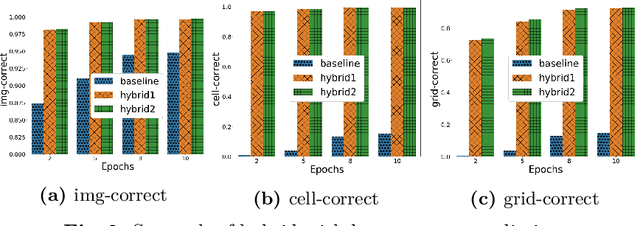
There is an increased interest in solving complex constrained problems where part of the input is not given as facts but received as raw sensor data such as images or speech. We will use "visual sudoku" as a prototype problem, where the given cell digits are handwritten and provided as an image thereof. In this case, one first has to train and use a classifier to label the images, so that the labels can be used for solving the problem. In this paper, we explore the hybridization of classifying the images with the reasoning of a constraint solver. We show that pure constraint reasoning on predictions does not give satisfactory results. Instead, we explore the possibilities of a tighter integration, by exposing the probabilistic estimates of the classifier to the constraint solver. This allows joint inference on these probabilistic estimates, where we use the solver to find the maximum likelihood solution. We explore the trade-off between the power of the classifier and the power of the constraint reasoning, as well as further integration through the additional use of structural knowledge. Furthermore, we investigate the effect of calibration of the probabilistic estimates on the reasoning. Our results show that such hybrid approaches vastly outperform a separate approach, which encourages a further integration of prediction (probabilities) and constraint solving.
A blind Robust Image Watermarking Approach exploiting the DFT Magnitude
Oct 22, 2019
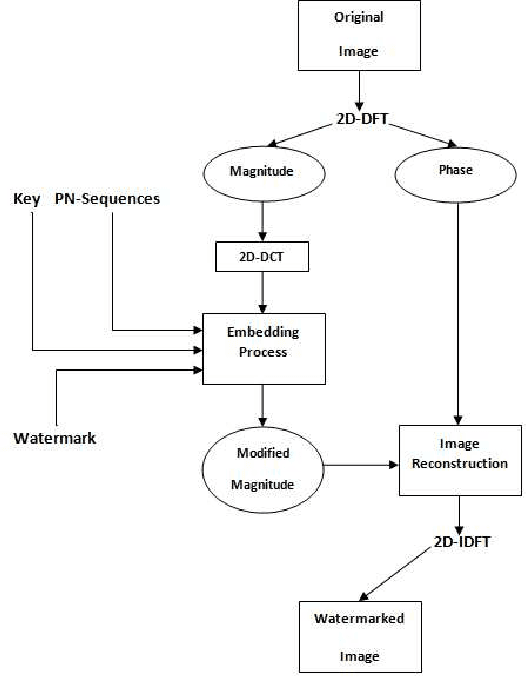
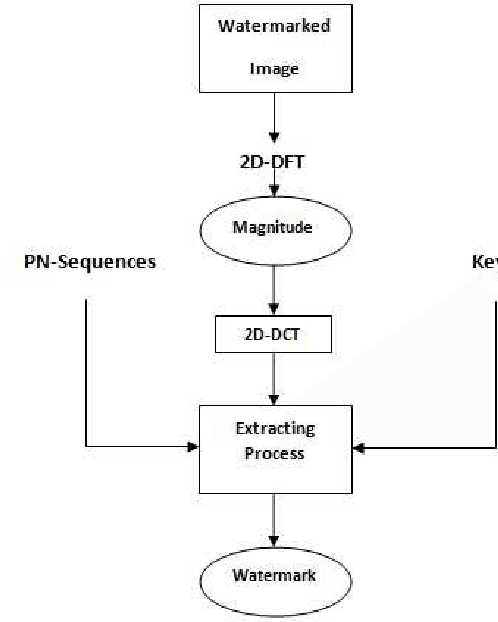

Due to the current progress in Internet, digital contents (video, audio and images) are widely used. Distribution of multimedia contents is now faster and it allows for easy unauthorized reproduction of information. Digital watermarking came up while trying to solve this problem. Its main idea is to embed a watermark into a host digital content without affecting its quality. Moreover, watermarking can be used in several applications such as authentication, copy control, indexation, Copyright protection, etc. In this paper, we propose a blind robust image watermarking approach as a solution to the problem of copyright protection of digital images. The underlying concept of our method is to apply a discrete cosine transform (DCT) to the magnitude resulting from a discrete Fourier transform (DFT) applied to the original image. Then, the watermark is embedded by modifying the coefficients of the DCT using a secret key to increase security. Experimental results show the robustness of the proposed technique to a wide range of common attacks, e.g., Low-Pass Gaussian Filtering, JPEG compression, Gaussian noise, salt & pepper noise, Gaussian Smoothing and Histogram equalization. The proposed method achieves a Peak signal-to-noise-ration (PSNR) value greater than 66 (dB) and ensures a perfect watermark extraction.
Medical Datasets Collections for Artificial Intelligence-based Medical Image Analysis
Feb 18, 2021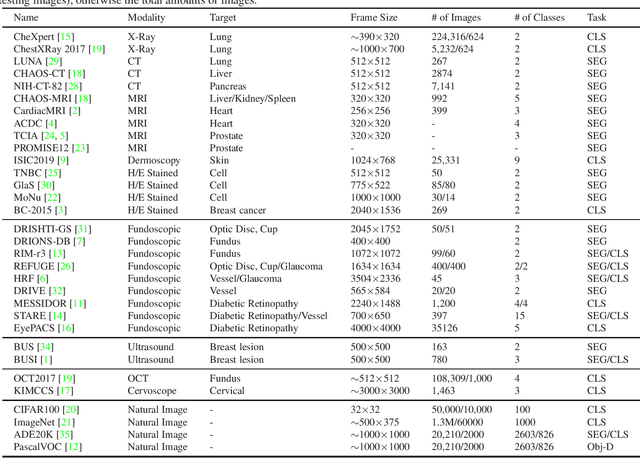
We collected 32 public datasets, of which 28 for medical imaging and 4 for natural images, to conduct study. The images of these datasets are captured by different cameras, thus vary from each other in modality, frame size and capacity. For data accessibility, we also provide the websites of most datasets and hope this will help the readers reach the datasets.
Unsupervised machine learning via transfer learning and k-means clustering to classify materials image data
Jul 16, 2020


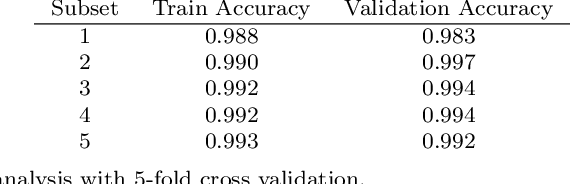
Unsupervised machine learning offers significant opportunities for extracting knowledge from unlabeled data sets and for achieving maximum machine learning performance. This paper demonstrates how to construct, use, and evaluate a high performance unsupervised machine learning system for classifying images in a popular microstructural dataset. The Northeastern University Steel Surface Defects Database includes micrographs of six different defects observed on hot-rolled steel in a format that is convenient for training and evaluating models for image classification. We use the VGG16 convolutional neural network pre-trained on the ImageNet dataset of natural images to extract feature representations for each micrograph. After applying principal component analysis to extract signal from the feature descriptors, we use k-means clustering to classify the images without needing labeled training data. The approach achieves $99.4\% \pm 0.16\%$ accuracy, and the resulting model can be used to classify new images without retraining This approach demonstrates an improvement in both performance and utility compared to a previous study. A sensitivity analysis is conducted to better understand the influence of each step on the classification performance. The results provide insight toward applying unsupervised machine learning techniques to problems of interest in materials science.
Generative Adversarial Networks for Extreme Learned Image Compression
Oct 23, 2018
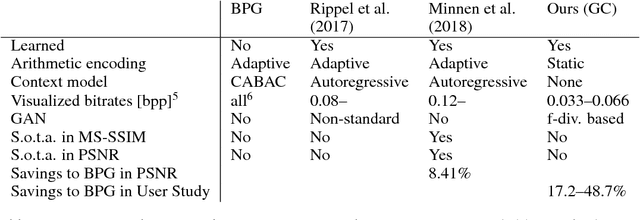


We propose a framework for extreme learned image compression based on Generative Adversarial Networks (GANs), obtaining visually pleasing images at significantly lower bitrates than previous methods. This is made possible through our GAN formulation of learned compression combined with a generator/decoder which operates on the full-resolution image and is trained in combination with a multi-scale discriminator. Additionally, if a semantic label map of the original image is available, our method can fully synthesize unimportant regions in the decoded image such as streets and trees from the label map, therefore only requiring the storage of the preserved region and the semantic label map. A user study confirms that for low bitrates, our approach is preferred to state-of-the-art methods, even when they use more than double the bits.
Unsupervised Person Re-Identification with Multi-Label Learning Guided Self-Paced Clustering
Mar 08, 2021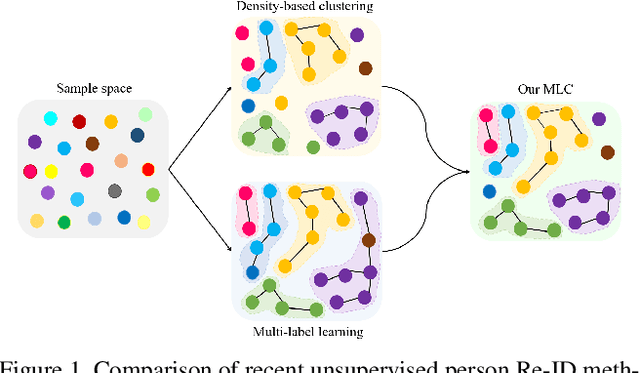

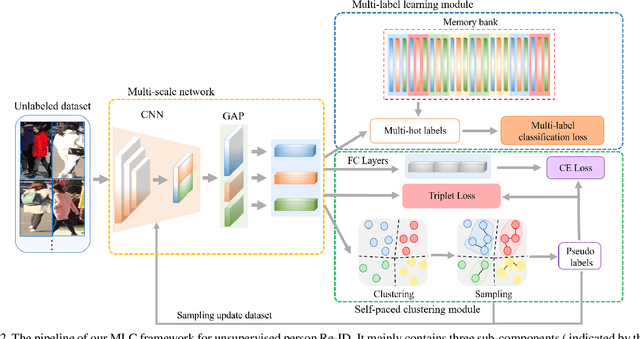
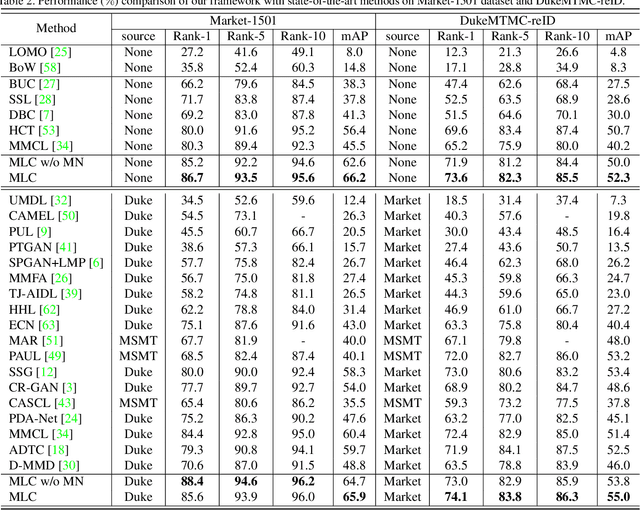
Although unsupervised person re-identification (Re-ID) has drawn increasing research attention recently, it remains challenging to learn discriminative features without annotations across disjoint camera views. In this paper, we address the unsupervised person Re-ID with a conceptually novel yet simple framework, termed as Multi-label Learning guided self-paced Clustering (MLC). MLC mainly learns discriminative features with three crucial modules, namely a multi-scale network, a multi-label learning module, and a self-paced clustering module. Specifically, the multi-scale network generates multi-granularity person features in both global and local views. The multi-label learning module leverages a memory feature bank and assigns each image with a multi-label vector based on the similarities between the image and feature bank. After multi-label training for several epochs, the self-paced clustering joins in training and assigns a pseudo label for each image. The benefits of our MLC come from three aspects: i) the multi-scale person features for better similarity measurement, ii) the multi-label assignment based on the whole dataset ensures that every image can be trained, and iii) the self-paced clustering removes some noisy samples for better feature learning. Extensive experiments on three popular large-scale Re-ID benchmarks demonstrate that our MLC outperforms previous state-of-the-art methods and significantly improves the performance of unsupervised person Re-ID.