 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Beyond ANN: Exploiting Structural Knowledge for Efficient Place Recognition
Mar 15, 2021
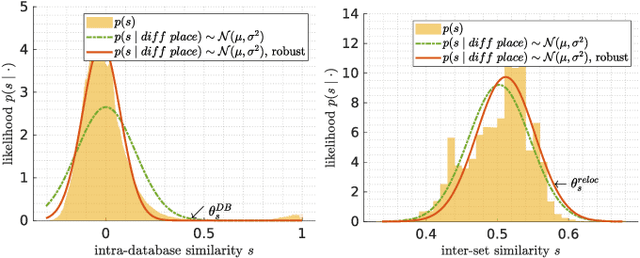
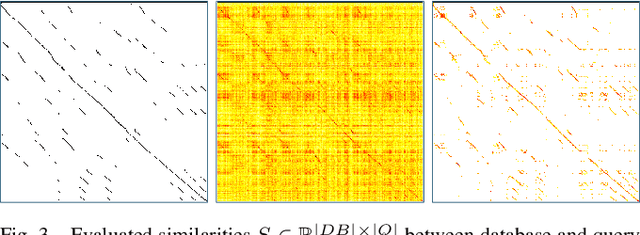
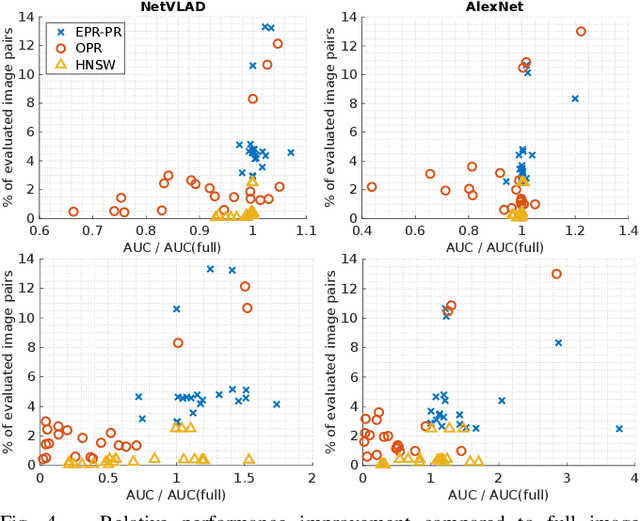
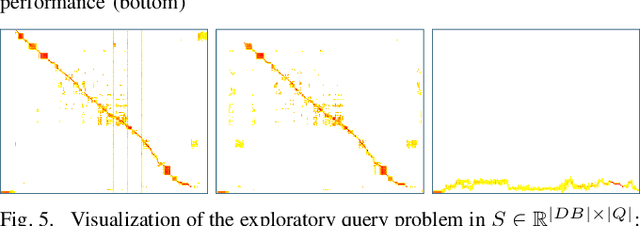
Visual place recognition is the task of recognizing same places of query images in a set of database images, despite potential condition changes due to time of day, weather or seasons. It is important for loop closure detection in SLAM and candidate selection for global localization. Many approaches in the literature perform computationally inefficient full image comparisons between queries and all database images. There is still a lack of suited methods for efficient place recognition that allow a fast, sparse comparison of only the most promising image pairs without any loss in performance. While this is partially given by ANN-based methods, they trade speed for precision and additional memory consumption, and many cannot find arbitrary numbers of matching database images in case of loops in the database. In this paper, we propose a novel fast sequence-based method for efficient place recognition that can be applied online. It uses relocalization to recover from sequence losses, and exploits usually available but often unused intra-database similarities for a potential detection of all matching database images for each query in case of loops or stops in the database. We performed extensive experimental evaluations over five datasets and 21 sequence combinations, and show that our method outperforms two state-of-the-art approaches and even full image comparisons in many cases, while providing a good tradeoff between performance and percentage of evaluated image pairs. Source code for Matlab will be provided with publication of this paper.
Scene Graph Generation with External Knowledge and Image Reconstruction
Apr 01, 2019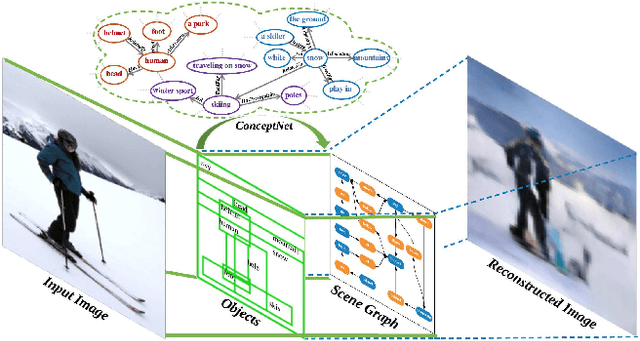
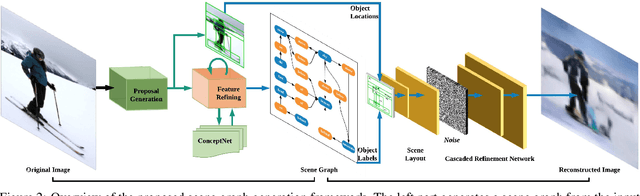
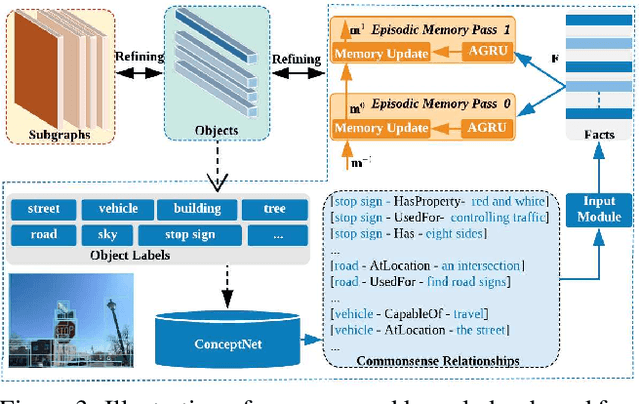
Scene graph generation has received growing attention with the advancements in image understanding tasks such as object detection, attributes and relationship prediction,~\etc. However, existing datasets are biased in terms of object and relationship labels, or often come with noisy and missing annotations, which makes the development of a reliable scene graph prediction model very challenging. In this paper, we propose a novel scene graph generation algorithm with external knowledge and image reconstruction loss to overcome these dataset issues. In particular, we extract commonsense knowledge from the external knowledge base to refine object and phrase features for improving generalizability in scene graph generation. To address the bias of noisy object annotations, we introduce an auxiliary image reconstruction path to regularize the scene graph generation network. Extensive experiments show that our framework can generate better scene graphs, achieving the state-of-the-art performance on two benchmark datasets: Visual Relationship Detection and Visual Genome datasets.
Systematic Evaluation of Backdoor Data Poisoning Attacks on Image Classifiers
Apr 24, 2020


Backdoor data poisoning attacks have recently been demonstrated in computer vision research as a potential safety risk for machine learning (ML) systems. Traditional data poisoning attacks manipulate training data to induce unreliability of an ML model, whereas backdoor data poisoning attacks maintain system performance unless the ML model is presented with an input containing an embedded "trigger" that provides a predetermined response advantageous to the adversary. Our work builds upon prior backdoor data-poisoning research for ML image classifiers and systematically assesses different experimental conditions including types of trigger patterns, persistence of trigger patterns during retraining, poisoning strategies, architectures (ResNet-50, NasNet, NasNet-Mobile), datasets (Flowers, CIFAR-10), and potential defensive regularization techniques (Contrastive Loss, Logit Squeezing, Manifold Mixup, Soft-Nearest-Neighbors Loss). Experiments yield four key findings. First, the success rate of backdoor poisoning attacks varies widely, depending on several factors, including model architecture, trigger pattern and regularization technique. Second, we find that poisoned models are hard to detect through performance inspection alone. Third, regularization typically reduces backdoor success rate, although it can have no effect or even slightly increase it, depending on the form of regularization. Finally, backdoors inserted through data poisoning can be rendered ineffective after just a few epochs of additional training on a small set of clean data without affecting the model's performance.
Image Based Camera Localization: an Overview
May 03, 2018
Recently, virtual reality, augmented reality, robotics, autonomous driving et al attract much attention of both academic and industrial community, in which image based camera localization is a key task. However, there has not been a complete review on image-based camera localization. It is urgent to map this topic to help people enter the field quickly. In this paper, an overview of image based camera localization is presented. A new and complete kind of classifications for image based camera localization is provided and the related techniques are introduced. Trends for the future development are also discussed. It will be useful to not only researchers but also engineers and other people interested.
Bridging the Gap between Spatial and Spectral Domains: A Theoretical Framework for Graph Neural Networks
Jul 21, 2021

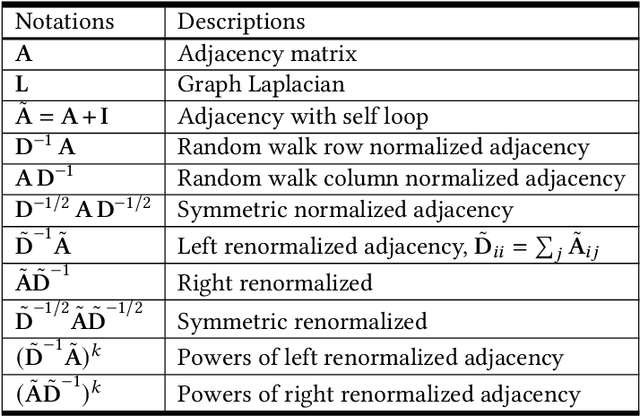
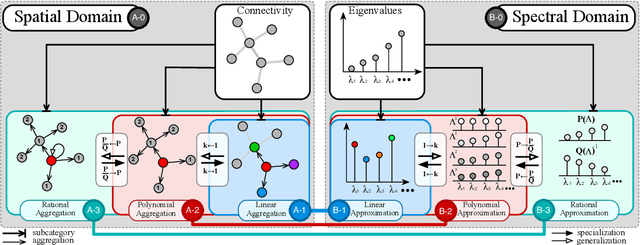
During the past decade, deep learning's performance has been widely recognized in a variety of machine learning tasks, ranging from image classification, speech recognition to natural language understanding. Graph neural networks (GNN) are a type of deep learning that is designed to handle non-Euclidean issues using graph-structured data that are difficult to solve with traditional deep learning techniques. The majority of GNNs were created using a variety of processes, including random walk, PageRank, graph convolution, and heat diffusion, making direct comparisons impossible. Previous studies have primarily focused on classifying current models into distinct categories, with little investigation of their internal relationships. This research proposes a unified theoretical framework and a novel perspective that can methodologically integrate existing GNN into our framework. We survey and categorize existing GNN models into spatial and spectral domains, as well as show linkages between subcategories within each domain. Further investigation reveals a strong relationship between the spatial, spectral, and subgroups of these domains.
Humans as Path-Finders for Safe Navigation
Jul 07, 2021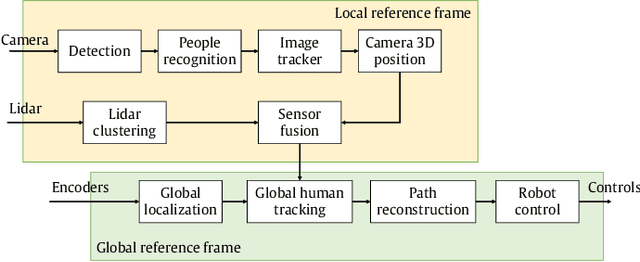
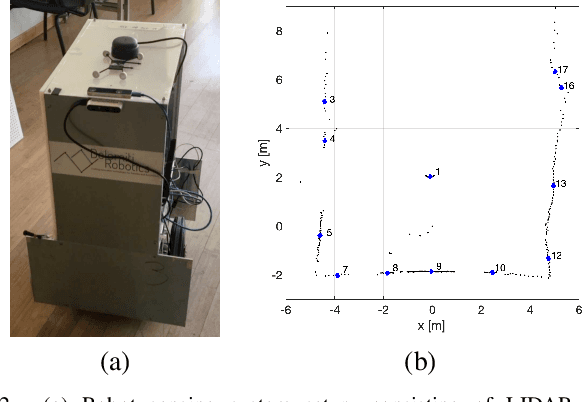


One of the most important barriers toward a widespread use of mobile robots in unstructured and human populated work environments is the ability to plan a safe path. In this paper, we propose to delegate this activity to a human operator that walks in front of the robot marking with her/his footsteps the path to be followed. The implementation of this approach requires a high degree of robustness in locating the specific person to be followed (the leader). We propose a three phase approach to fulfil this goal: 1. identification and tracking of the person in the image space, 2. sensor fusion between camera data and laser sensors, 3. point interpolation with continuous curvature curves. The approach is described in the paper and extensively validated with experimental results.
Megapixel Photon-Counting Color Imaging using Quanta Image Sensor
Mar 21, 2019
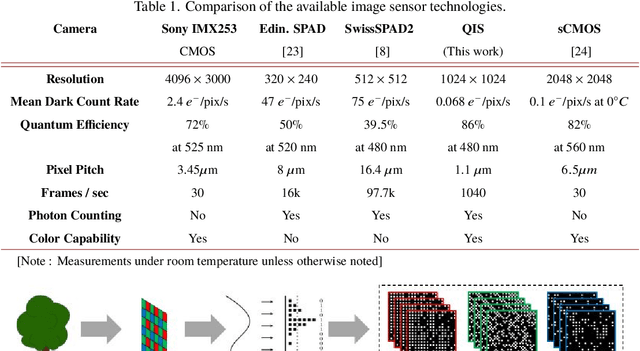


Quanta Image Sensor (QIS) is a single-photon detector designed for extremely low light imaging conditions. Majority of the existing QIS prototypes are monochrome based on single-photon avalanche diodes (SPAD). Color imaging has not been demonstrated with single-photon detectors due to the intrinsic difficulty of shrinking the pixel size and increasing the spatial resolution while maintaining acceptable intra-pixel cross-talk. In this paper, we present image reconstruction of the first color QIS with a resolution of $1024 \times 1024$ pixels, supporting both single-bit and multi-bit photon counting capability. Our color image reconstruction is enabled by a customized joint demosaicing-denoising algorithm, leveraging truncated Poisson statistics and variance stabilizing transforms. Experimental results of the new sensor and algorithm demonstrate superior color imaging performance for very low-light conditions with a mean exposure of as low as a few photons per pixel.
Generalizing Deep Models for Overhead Image Segmentation Through Getis-Ord Gi* Pooling
Dec 23, 2019
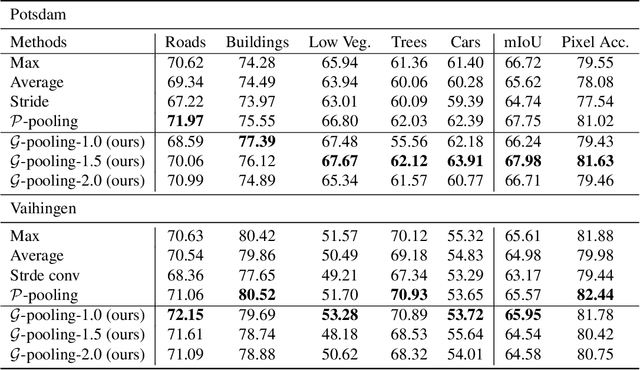
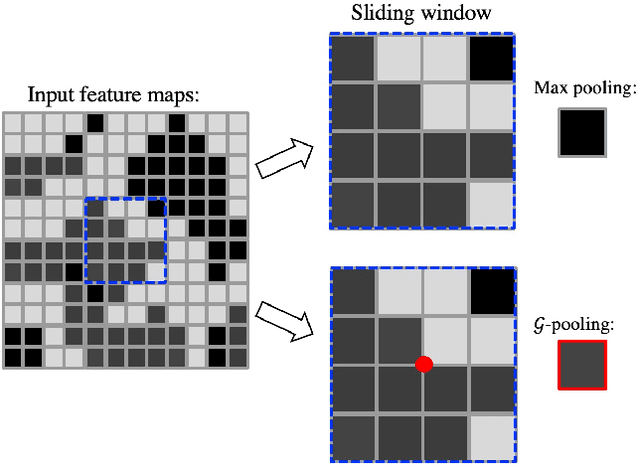
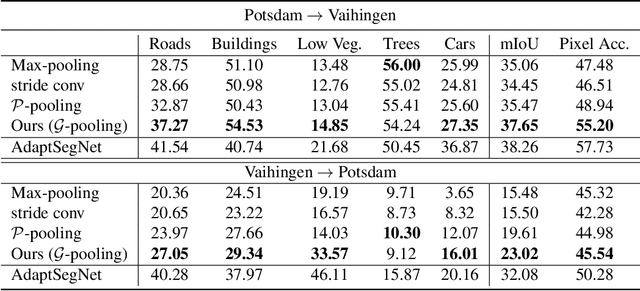
That most deep learning models are purely data driven is both a strength and a weakness. Given sufficient training data, the optimal model for a particular problem can be learned. However, this is usually not the case and so instead the model is either learned from scratch from a limited amount of training data or pre-trained on a different problem and then fine-tuned. Both of these situations are potentially suboptimal and limit the generalizability of the model. Inspired by this, we investigate methods to inform or guide deep learning models for geospatial image analysis to increase their performance when a limited amount of training data is available or when they are applied to scenarios other than which they were trained on. In particular, we exploit the fact that there are certain fundamental rules as to how things are distributed on the surface of the Earth and these rules do not vary substantially between locations. Based on this, we develop a novel feature pooling method for convolutional neural networks using Getis-Ord Gi* analysis from geostatistics. Experimental results show our proposed pooling function has significantly better generalization performance compared to a standard data-driven approach when applied to overhead image segmentation.
Knowledge Distillation from Ensemble of Offsets for Head Pose Estimation
Aug 20, 2021
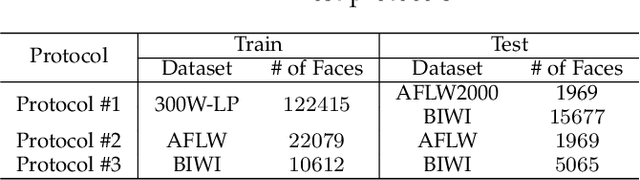
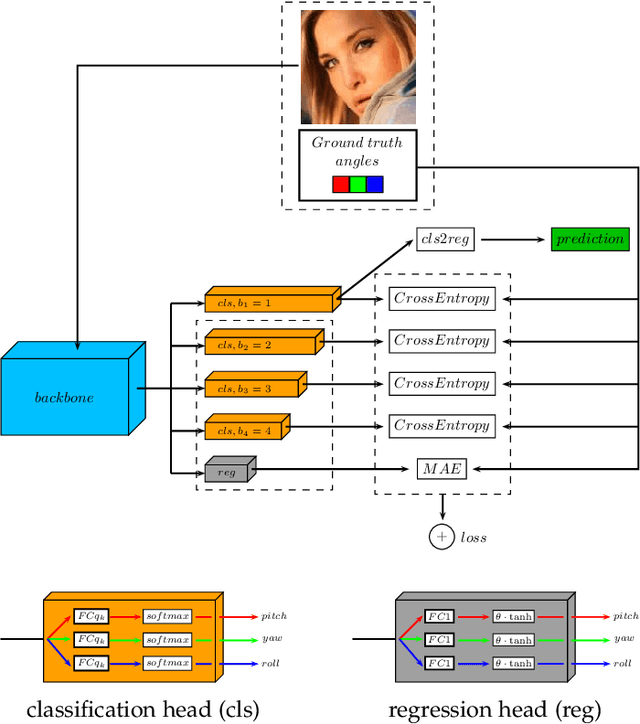
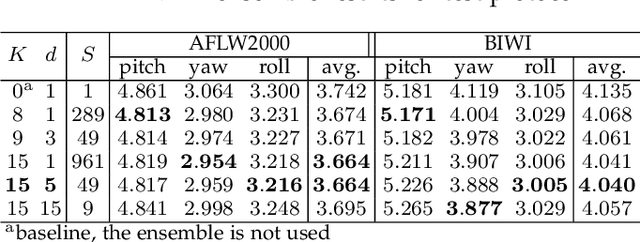
This paper proposes a method for estimating the head pose from a single image. This estimation uses a neural network (NN) obtained in two stages. In the first stage, we trained the base NN, which has one regression head and four regression via classification (RvC) heads. We build the ensemble of offsets using small offsets of face bounding boxes. In the second stage, we perform knowledge distillation (KD) from the ensemble of offsets of the base NN into the final NN with one RvC head. On the main test protocol, the use of the offset ensemble improves the results of the base NN, and the KD improves the results from the offset ensemble. The KD improves the results by an average of 7.7\% compared to the non-ensemble version. The proposed NN on the main test protocol improves the state-of-the-art result on AFLW2000 and approaches, with only a minimal gap, the state-of-the-art result on BIWI. Our NN uses only head pose data, but the previous state-of-the-art model also uses facial landmarks during training. We have made publicly available trained NNs and face bounding boxes for the 300W-LP, AFLW, AFLW2000, and BIWI datasets. KD-ResNet152 has the best results, and KD-ResNet18 has a better result on the AFLW2000 dataset than any previous method.
Evidential Deep Learning for Open Set Action Recognition
Jul 21, 2021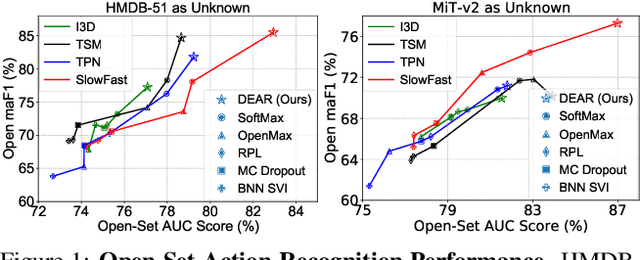
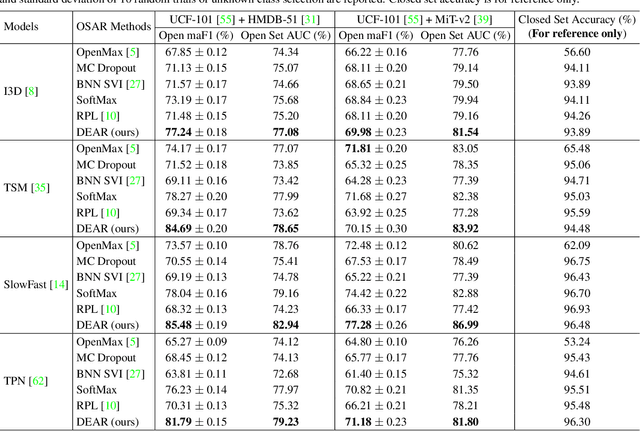

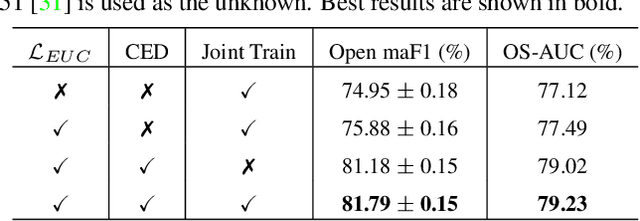
In a real-world scenario, human actions are typically out of the distribution from training data, which requires a model to both recognize the known actions and reject the unknown. Different from image data, video actions are more challenging to be recognized in an open-set setting due to the uncertain temporal dynamics and static bias of human actions. In this paper, we propose a Deep Evidential Action Recognition (DEAR) method to recognize actions in an open testing set. Specifically, we formulate the action recognition problem from the evidential deep learning (EDL) perspective and propose a novel model calibration method to regularize the EDL training. Besides, to mitigate the static bias of video representation, we propose a plug-and-play module to debias the learned representation through contrastive learning. Experimental results show that our DEAR method achieves consistent performance gain on multiple mainstream action recognition models and benchmarks. Codes and pre-trained weights will be made available upon paper acceptance.