 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Feature Importance-aware Transferable Adversarial Attacks
Aug 22, 2021

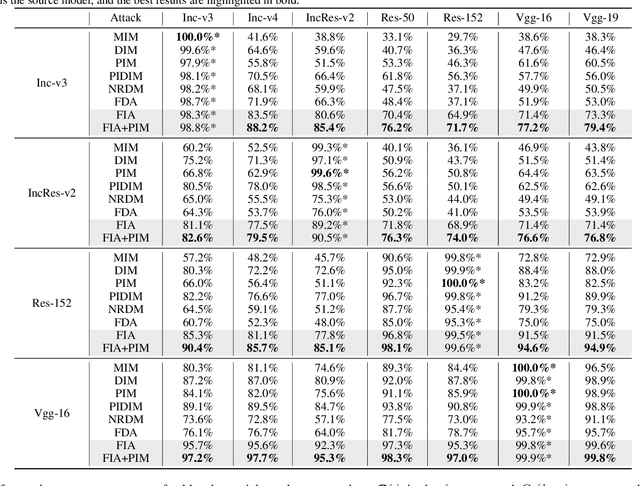
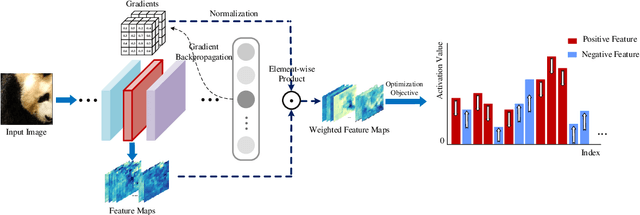
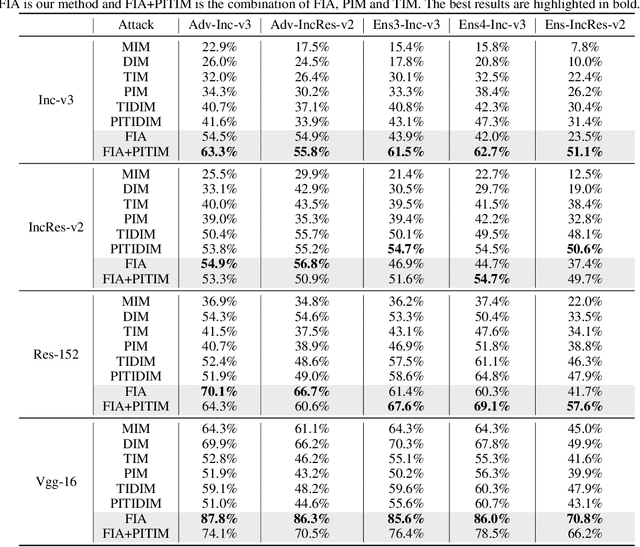
Transferability of adversarial examples is of central importance for attacking an unknown model, which facilitates adversarial attacks in more practical scenarios, e.g., black-box attacks. Existing transferable attacks tend to craft adversarial examples by indiscriminately distorting features to degrade prediction accuracy in a source model without aware of intrinsic features of objects in the images. We argue that such brute-force degradation would introduce model-specific local optimum into adversarial examples, thus limiting the transferability. By contrast, we propose the Feature Importance-aware Attack (FIA), which disrupts important object-aware features that dominate model decisions consistently. More specifically, we obtain feature importance by introducing the aggregate gradient, which averages the gradients with respect to feature maps of the source model, computed on a batch of random transforms of the original clean image. The gradients will be highly correlated to objects of interest, and such correlation presents invariance across different models. Besides, the random transforms will preserve intrinsic features of objects and suppress model-specific information. Finally, the feature importance guides to search for adversarial examples towards disrupting critical features, achieving stronger transferability. Extensive experimental evaluation demonstrates the effectiveness and superior performance of the proposed FIA, i.e., improving the success rate by 9.5% against normally trained models and 12.8% against defense models as compared to the state-of-the-art transferable attacks. Code is available at: https://github.com/hcguoO0/FIA
Deep Inception Generative Network for Cognitive Image Inpainting
Dec 01, 2018
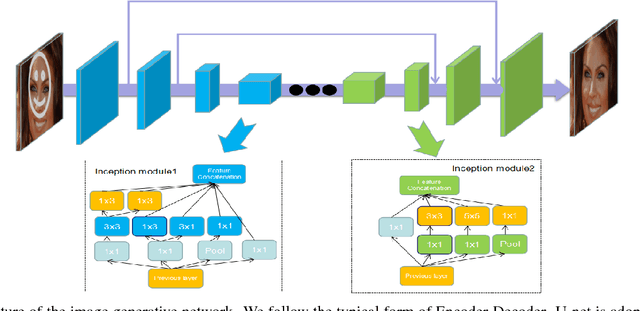

Recent advances in deep learning have shown exciting promise in filling large holes and lead to another orientation for image inpainting. However, existing learning-based methods often create artifacts and fallacious textures because of insufficient cognition understanding. Previous generative networks are limited with single receptive type and give up pooling in consideration of detail sharpness. Human cognition is constant regardless of the target attribute. As multiple receptive fields improve the ability of abstract image characterization and pooling can keep feature invariant, specifically, deep inception learning is adopted to promote high-level feature representation and enhance model learning capacity for local patches. Moreover, approaches for generating diverse mask images are introduced and a random mask dataset is created. We benchmark our methods on ImageNet, Places2 dataset, and CelebA-HQ. Experiments for regular, irregular, and custom regions completion are all performed and free-style image inpainting is also presented. Quantitative comparisons with previous state-of-the-art methods show that ours obtain much more natural image completions.
Applying VertexShuffle Toward 360-Degree Video Super-Resolution on Focused-Icosahedral-Mesh
Jun 21, 2021

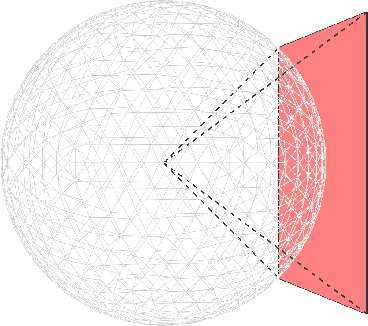
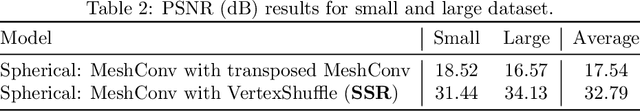
With the emerging of 360-degree image/video, augmented reality (AR) and virtual reality (VR), the demand for analysing and processing spherical signals get tremendous increase. However, plenty of effort paid on planar signals that projected from spherical signals, which leading to some problems, e.g. waste of pixels, distortion. Recent advances in spherical CNN have opened up the possibility of directly analysing spherical signals. However, they pay attention to the full mesh which makes it infeasible to deal with situations in real-world application due to the extremely large bandwidth requirement. To address the bandwidth waste problem associated with 360-degree video streaming and save computation, we exploit Focused Icosahedral Mesh to represent a small area and construct matrices to rotate spherical content to the focused mesh area. We also proposed a novel VertexShuffle operation that can significantly improve both the performance and the efficiency compared to the original MeshConv Transpose operation introduced in UGSCNN. We further apply our proposed methods on super resolution model, which is the first to propose a spherical super-resolution model that directly operates on a mesh representation of spherical pixels of 360-degree data. To evaluate our model, we also collect a set of high-resolution 360-degree videos to generate a spherical image dataset. Our experiments indicate that our proposed spherical super-resolution model achieves significant benefits in terms of both performance and inference time compared to the baseline spherical super-resolution model that uses the simple MeshConv Transpose operation. In summary, our model achieves great super-resolution performance on 360-degree inputs, achieving 32.79 dB PSNR on average when super-resoluting 16x vertices on the mesh.
Large-Scale Unsupervised Person Re-Identification with Contrastive Learning
May 17, 2021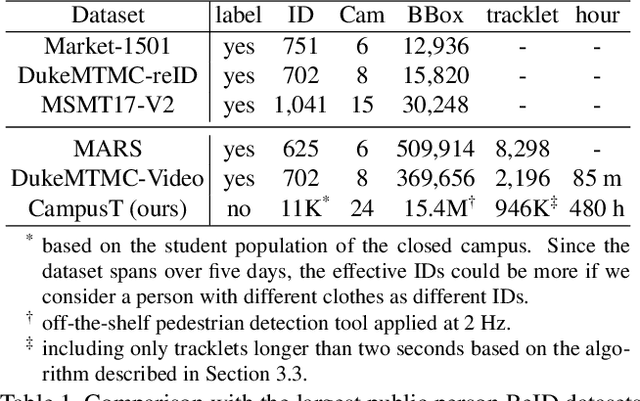
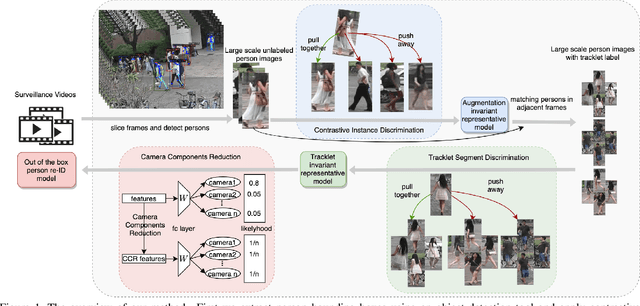

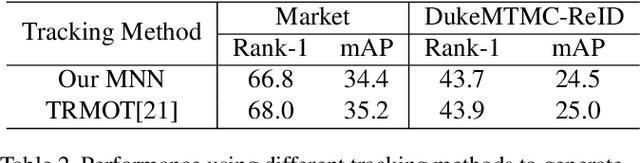
Existing public person Re-Identification~(ReID) datasets are small in modern terms because of labeling difficulty. Although unlabeled surveillance video is abundant and relatively easy to obtain, it is unclear how to leverage these footage to learn meaningful ReID representations. In particular, most existing unsupervised and domain adaptation ReID methods utilize only the public datasets in their experiments, with labels removed. In addition, due to small data sizes, these methods usually rely on fine tuning by the unlabeled training data in the testing domain to achieve good performance. Inspired by the recent progress of large-scale self-supervised image classification using contrastive learning, we propose to learn ReID representation from large-scale unlabeled surveillance video alone. Assisted by off-the-shelf pedestrian detection tools, we apply the contrastive loss at both the image and the tracklet levels. Together with a principal component analysis step using camera labels freely available, our evaluation using a large-scale unlabeled dataset shows far superior performance among unsupervised methods that do not use any training data in the testing domain. Furthermore, the accuracy improves with the data size and therefore our method has great potential with even larger and more diversified datasets.
High-Fidelity and Arbitrary Face Editing
Mar 29, 2021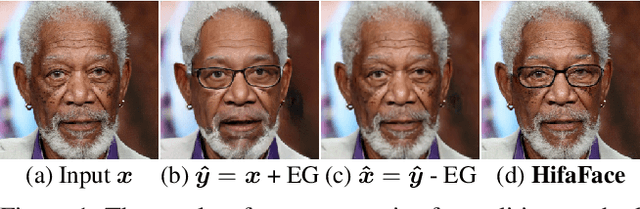
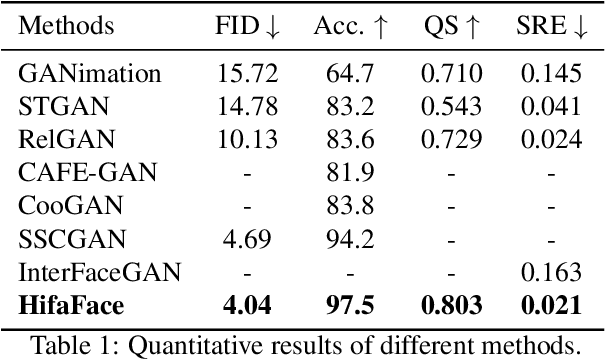


Cycle consistency is widely used for face editing. However, we observe that the generator tends to find a tricky way to hide information from the original image to satisfy the constraint of cycle consistency, making it impossible to maintain the rich details (e.g., wrinkles and moles) of non-editing areas. In this work, we propose a simple yet effective method named HifaFace to address the above-mentioned problem from two perspectives. First, we relieve the pressure of the generator to synthesize rich details by directly feeding the high-frequency information of the input image into the end of the generator. Second, we adopt an additional discriminator to encourage the generator to synthesize rich details. Specifically, we apply wavelet transformation to transform the image into multi-frequency domains, among which the high-frequency parts can be used to recover the rich details. We also notice that a fine-grained and wider-range control for the attribute is of great importance for face editing. To achieve this goal, we propose a novel attribute regression loss. Powered by the proposed framework, we achieve high-fidelity and arbitrary face editing, outperforming other state-of-the-art approaches.
Data science and Machine learning in the Clouds: A Perspective for the Future
Sep 02, 2021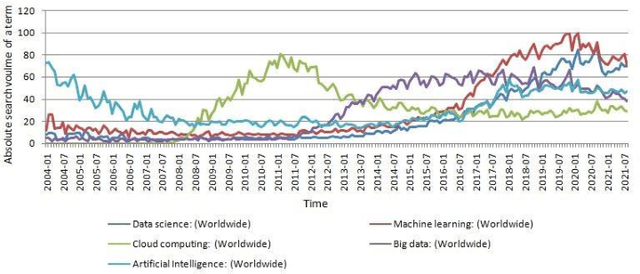
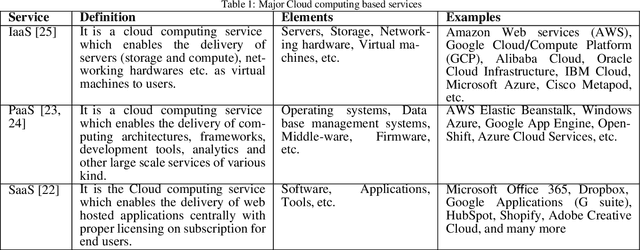
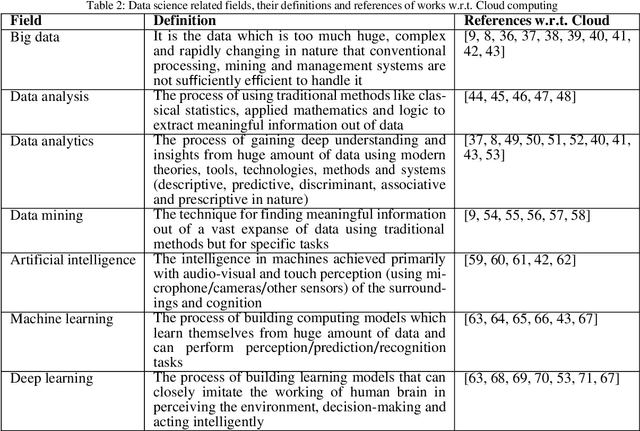
As we are fast approaching the beginning of a paradigm shift in the field of science, Data driven science (the so called fourth science paradigm) is going to be the driving force in research and innovation. From medicine to biodiversity and astronomy to geology, all these terms are somehow going to be affected by this paradigm shift. The huge amount of data to be processed under this new paradigm will be a major concern in the future and one will strongly require cloud based services in all the aspects of these computations (from storage to compute and other services). Another aspect will be energy consumption and performance of prediction jobs and tasks within such a scientific paradigm which will change the way one sees computation. Data science has heavily impacted or rather triggered the emergence of Machine Learning, Signal/Image/Video processing related algorithms, Artificial intelligence, Robotics, health informatics, geoinformatics, and many more such areas of interest. Hence, we envisage an era where Data science can deliver its promises with the help of the existing cloud based platforms and services with the addition of new services. In this article, we discuss about data driven science and Machine learning and how they are going to be linked through cloud based services in the future. It also discusses the rise of paradigms like approximate computing, quantum computing and many more in recent times and their applicability in big data processing, data science, analytics, prediction and machine learning in the cloud environments.
Simultaneous Fidelity and Regularization Learning for Image Restoration
Oct 16, 2018



Most existing non-blind restoration methods are based on the assumption that a precise degradation model is known. As the degradation process can only partially known or inaccurately modeled, images may not be well restored. Rain streak removal and image deconvolution with inaccurate blur kernels are two representative examples of such tasks. For rain streak removal, although an input image can be decomposed into a scene layer and a rain streak layer, there exists no explicit formulation for modeling rain streaks and the composition with scene layer. For blind deconvolution, as estimation error of blur kernel is usually introduced, the subsequent non-blind deconvolution process does not restore the latent image well. In this paper, we propose a principled algorithm within the maximum a posterior framework to tackle image restoration with a partially known or inaccurate degradation model. Specifically, the residual caused by a partially known or inaccurate degradation model is spatially dependent and complexly distributed. With a training set of degraded and ground-truth image pairs, we parameterize and learn the fidelity term for a degradation model in a task-driven manner. Furthermore, the regularization term can also be learned along with the fidelity term, thereby forming a simultaneous fidelity and regularization learning model. Extensive experimental results demonstrate the effectiveness of the proposed model for image deconvolution with inaccurate blur kernels and rain streak removal. Furthermore, for image restoration with precise degradation process, e.g., Gaussian denoising, the proposed model can be applied to learn the proper fidelity term for optimal performance based on visual perception metrics.
EG-Booster: Explanation-Guided Booster of ML Evasion Attacks
Sep 02, 2021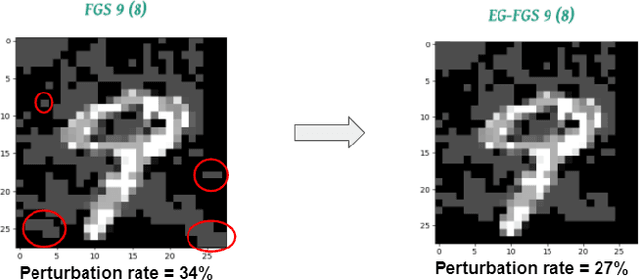
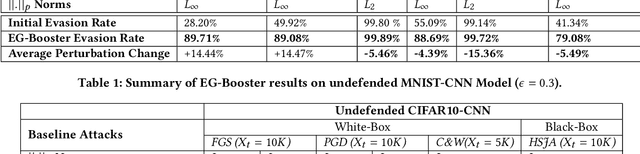
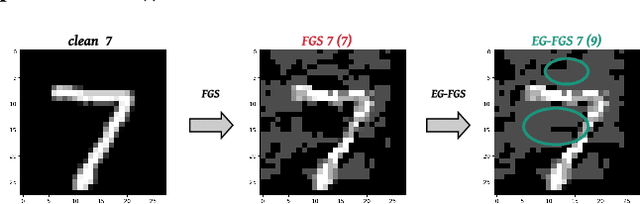

The widespread usage of machine learning (ML) in a myriad of domains has raised questions about its trustworthiness in security-critical environments. Part of the quest for trustworthy ML is robustness evaluation of ML models to test-time adversarial examples. Inline with the trustworthy ML goal, a useful input to potentially aid robustness evaluation is feature-based explanations of model predictions. In this paper, we present a novel approach called EG-Booster that leverages techniques from explainable ML to guide adversarial example crafting for improved robustness evaluation of ML models before deploying them in security-critical settings. The key insight in EG-Booster is the use of feature-based explanations of model predictions to guide adversarial example crafting by adding consequential perturbations likely to result in model evasion and avoiding non-consequential ones unlikely to contribute to evasion. EG-Booster is agnostic to model architecture, threat model, and supports diverse distance metrics used previously in the literature. We evaluate EG-Booster using image classification benchmark datasets, MNIST and CIFAR10. Our findings suggest that EG-Booster significantly improves evasion rate of state-of-the-art attacks while performing less number of perturbations. Through extensive experiments that covers four white-box and three black-box attacks, we demonstrate the effectiveness of EG-Booster against two undefended neural networks trained on MNIST and CIFAR10, and another adversarially-trained ResNet model trained on CIFAR10. Furthermore, we introduce a stability assessment metric and evaluate the reliability of our explanation-based approach by observing the similarity between the model's classification outputs across multiple runs of EG-Booster.
2-bit Model Compression of Deep Convolutional Neural Network on ASIC Engine for Image Retrieval
May 08, 2019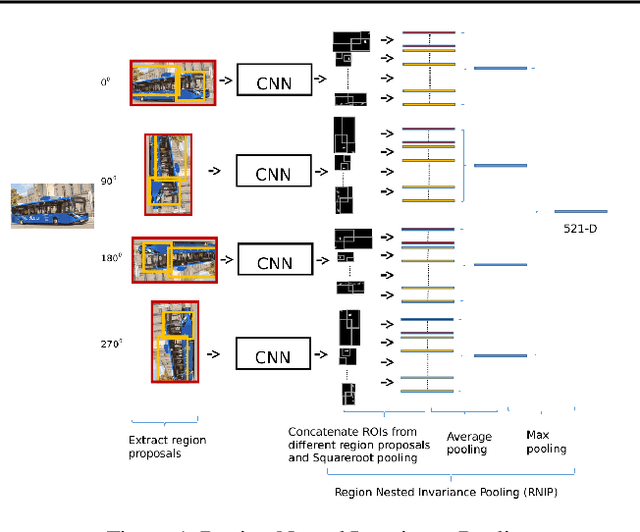
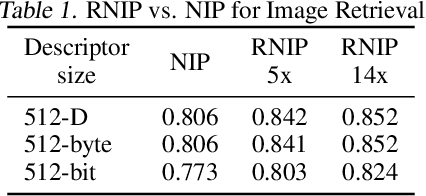
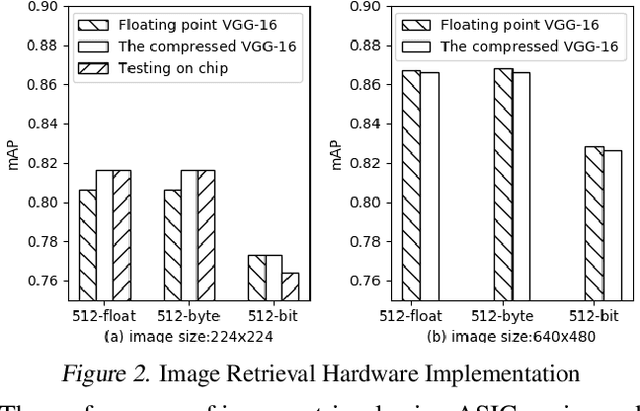

Image retrieval utilizes image descriptors to retrieve the most similar images to a given query image. Convolutional neural network (CNN) is becoming the dominant approach to extract image descriptors for image retrieval. For low-power hardware implementation of image retrieval, the drawback of CNN-based feature descriptor is that it requires hundreds of megabytes of storage. To address this problem, this paper applies deep model quantization and compression to CNN in ASIC chip for image retrieval. It is demonstrated that the CNN-based features descriptor can be extracted using as few as 2-bit weights quantization to deliver a similar performance as floating-point model for image retrieval. In addition, to implement CNN in ASIC, especially for large scale images, the limited buffer size of chips should be considered. To retrieve large scale images, we propose an improved pooling strategy, region nested invariance pooling (RNIP), which uses cropped sub-images for CNN. Testing results on chip show that integrating RNIP with the proposed 2-bit CNN model compression approach is capable of retrieving large scale images.
3D Dense Separated Convolution Module for Volumetric Image Analysis
May 14, 2019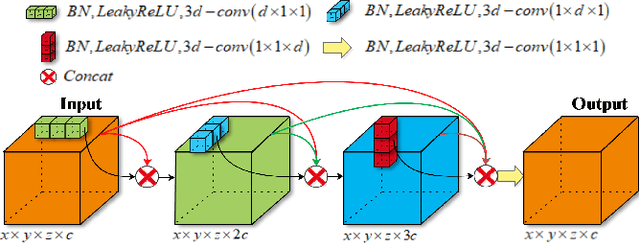
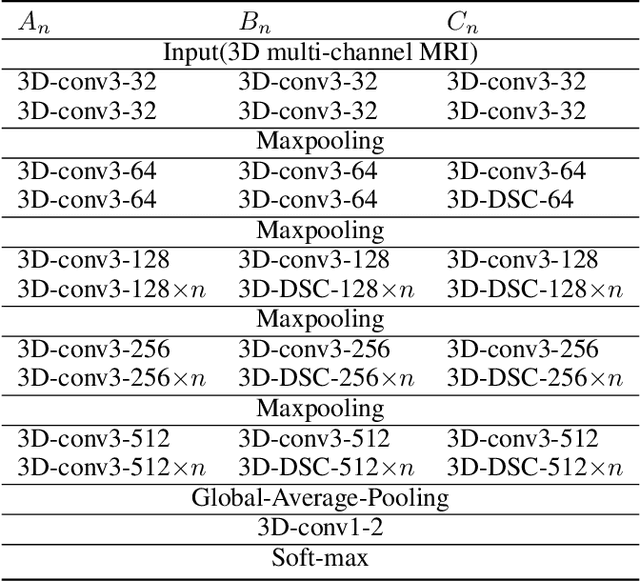
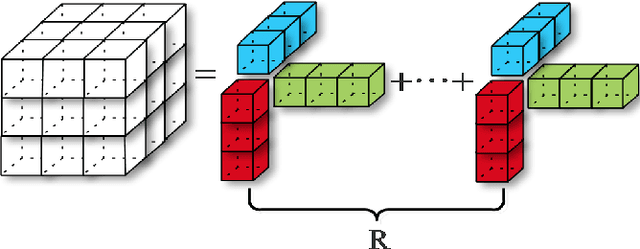
With the thriving of deep learning, 3D Convolutional Neural Networks have become a popular choice in volumetric image analysis due to their impressive 3D contexts mining ability. However, the 3D convolutional kernels will introduce a significant increase in the amount of trainable parameters. Considering the training data is often limited in biomedical tasks, a tradeoff has to be made between model size and its representational power. To address this concern, in this paper, we propose a novel 3D Dense Separated Convolution (3D-DSC) module to replace the original 3D convolutional kernels. The 3D-DSC module is constructed by a series of densely connected 1D filters. The decomposition of 3D kernel into 1D filters reduces the risk of over-fitting by removing the redundancy of 3D kernels in a topologically constrained manner, while providing the infrastructure for deepening the network. By further introducing nonlinear layers and dense connections between 1D filters, the network's representational power can be significantly improved while maintaining a compact architecture. We demonstrate the superiority of 3D-DSC on volumetric image classification and segmentation, which are two challenging tasks often encountered in biomedical image computing.