 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAR Image Change Detection via Spatial Metric Learning with an Improved Mahalanobis Distance
Jun 19, 2019


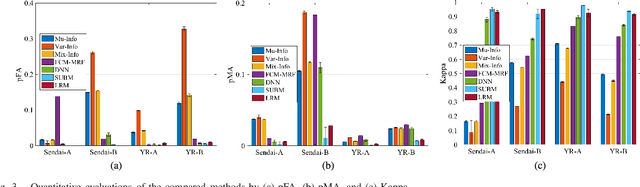

The log-ratio (LR) operator has been widely employed to generate the difference image for synthetic aperture radar (SAR) image change detection. However, the difference image generated by this pixel-wise operator can be subject to SAR images speckle and unavoidable registration errors between bitemporal SAR images. In this letter, we proposed a spatial metric learning method to obtain a difference image more robust to the speckle by learning a metric from a set of constraint pairs. In the proposed method, spatial context is considered in constructing constraint pairs, each of which consists of patches in the same location of bitemporal SAR images. Then, a semi-definite positive metric matrix $\bf M$ can be obtained by the optimization with the max-margin criterion. Finally, we verify our proposed method on four challenging datasets of bitemporal SAR images. Experimental results demonstrate that the difference map obtained by our proposed method outperforms than other state-of-art methods.
ImageGCN: Multi-Relational Image Graph Convolutional Networks for Disease Identification with Chest X-rays
Mar 31, 2019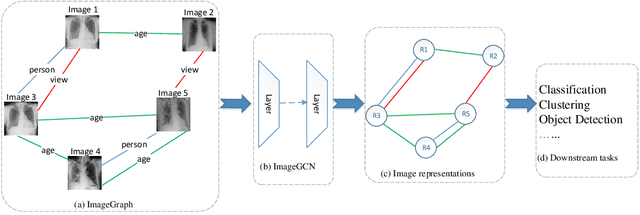
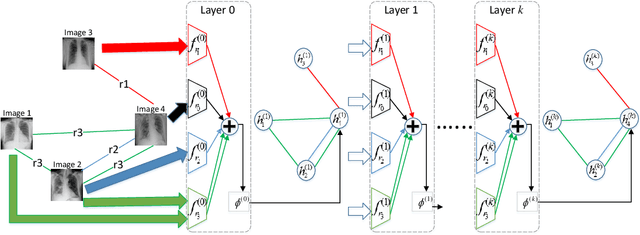
Image representation is a fundamental task in computer vision. However, most of the existing approaches for image representation ignore the relations between images and consider each input image independently. Intuitively, relations between images can help to understand the images and maintain model consistency over related images. In this paper, we consider modeling the image-level relations to generate more informative image representations, and propose ImageGCN, an end-to-end graph convolutional network framework for multi-relational image modeling. We also apply ImageGCN to chest X-ray (CXR) images where rich relational information is available for disease identification. Unlike previous image representation models, ImageGCN learns the representation of an image using both its original pixel features and the features of related images. Besides learning informative representations for images, ImageGCN can also be used for object detection in a weakly supervised manner. The Experimental results on ChestX-ray14 dataset demonstrate that ImageGCN can outperform respective baselines in both disease identification and localization tasks and can achieve comparable and often better results than the state-of-the-art methods.
Super-resolving Compressed Images via Parallel and Series Integration of Artifact Reduction and Resolution Enhancement
Mar 02, 2021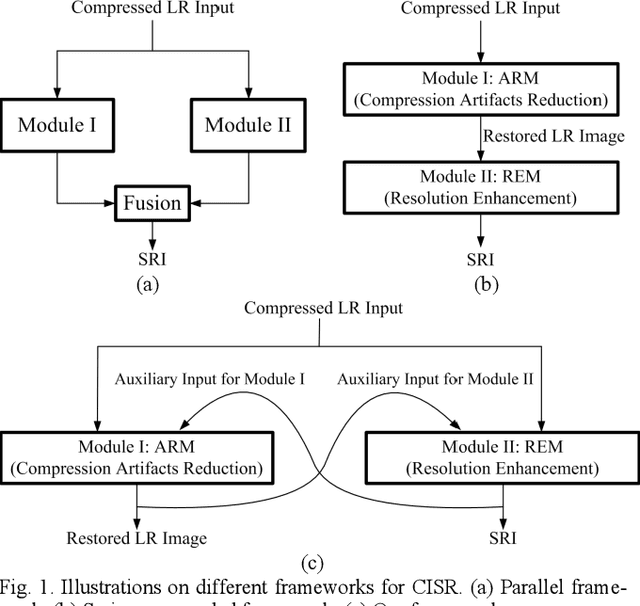
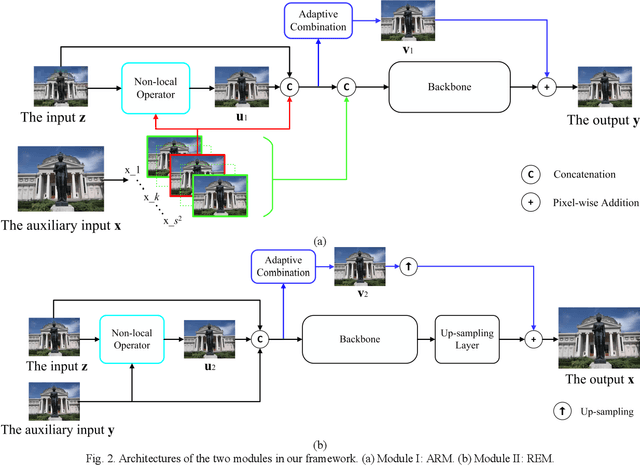
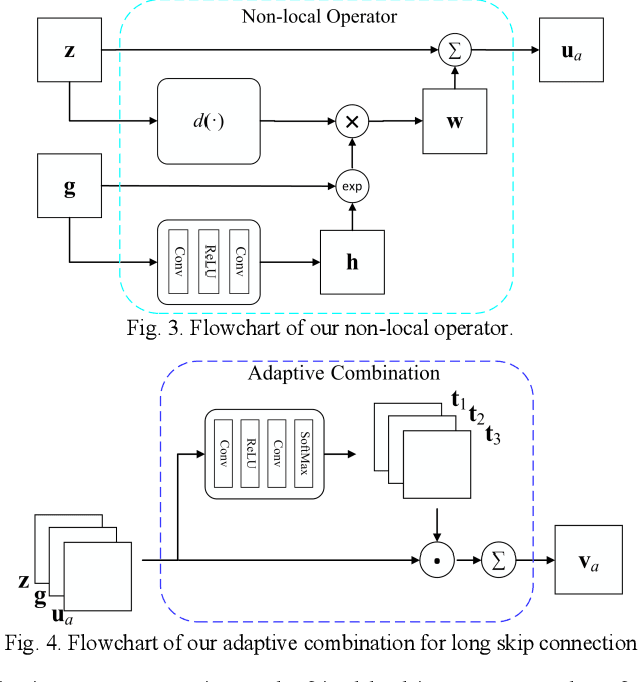
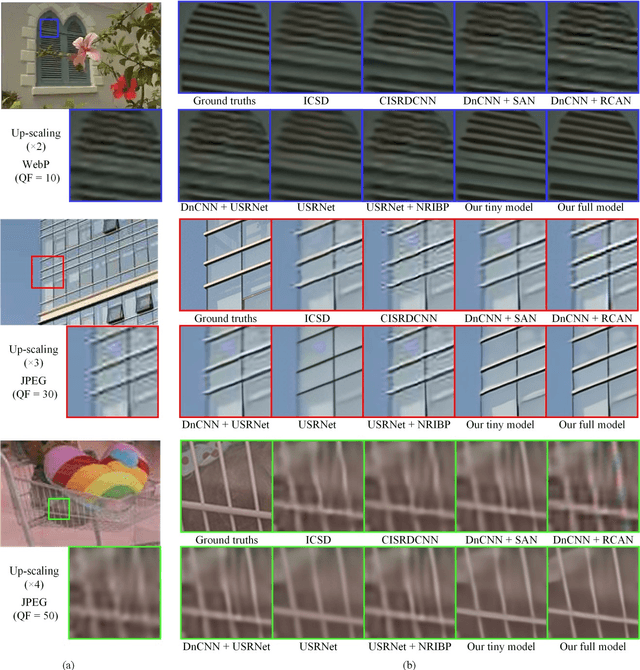
In real-world applications, images may be not only sub-sampled but also heavily compressed thus often containing various artifacts. Simple methods for enhancing the resolution of such images will exacerbate the artifacts, rendering them visually objectionable. In spite of its high practical values, super-resolving compressed images is not well studied in the literature. In this paper, we propose a novel compressed image super resolution (CISR) framework based on parallel and series integration of artifact removal and resolution enhancement. Based on maximum a posterior inference for estimating a clean low-resolution (LR) input image and a clean high resolution (HR) output image from down-sampled and compressed observations, we have designed a CISR architecture consisting of two deep neural network modules: the artifact reduction module (ARM) and resolution enhancement module (REM). ARM and REM work in parallel with both taking the compressed LR image as their inputs, while they also work in series with REM taking the output of ARM as one of its inputs and ARM taking the output of REM as its other input. A unique property of our CSIR system is that a single trained model is able to super-resolve LR images compressed by different methods to various qualities. This is achieved by exploiting deep neural net-works capacity for handling image degradations, and the parallel and series connections between ARM and REM to reduce the dependency on specific degradations. ARM and REM are trained simultaneously by the deep unfolding technique. Experiments are conducted on a mixture of JPEG and WebP compressed images without a priori knowledge of the compression type and com-pression factor. Visual and quantitative comparisons demonstrate the superiority of our method over state-of-the-art super resolu-tion methods.
Towards Ultra-Resolution Neural Style Transfer via Thumbnail Instance Normalization
Mar 22, 2021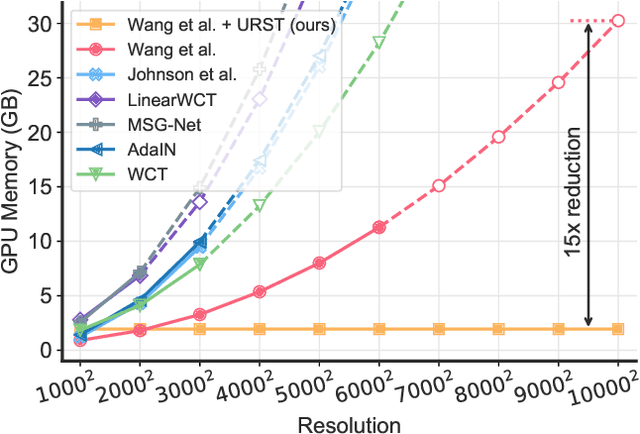
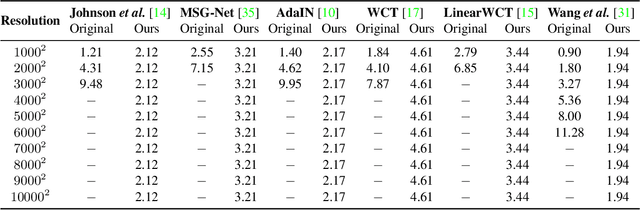

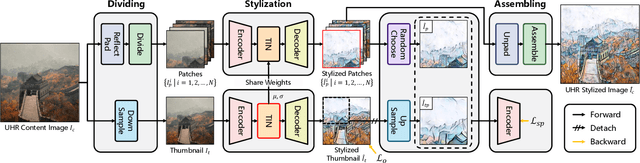
We present an extremely simple Ultra-Resolution Style Transfer framework, termed URST, to flexibly process arbitrary high-resolution images (e.g., 10000x10000 pixels) style transfer for the first time. Most of the existing state-of-the-art methods would fall short due to massive memory cost and small stroke size when processing ultra-high resolution images. URST completely avoids the memory problem caused by ultra-high resolution images by 1) dividing the image into small patches and 2) performing patch-wise style transfer with a novel Thumbnail Instance Normalization (TIN). Specifically, TIN can extract thumbnail's normalization statistics and apply them to small patches, ensuring the style consistency among different patches. Overall, the URST framework has three merits compared to prior arts. 1) We divide input image into small patches and adopt TIN, successfully transferring image style with arbitrary high-resolution. 2) Experiments show that our URST surpasses existing SOTA methods on ultra-high resolution images benefiting from the effectiveness of the proposed stroke perceptual loss in enlarging the stroke size. 3) Our URST can be easily plugged into most existing style transfer methods and directly improve their performance even without training. Code is available at https://github.com/czczup/URST.
Joint self-supervised blind denoising and noise estimation
Feb 16, 2021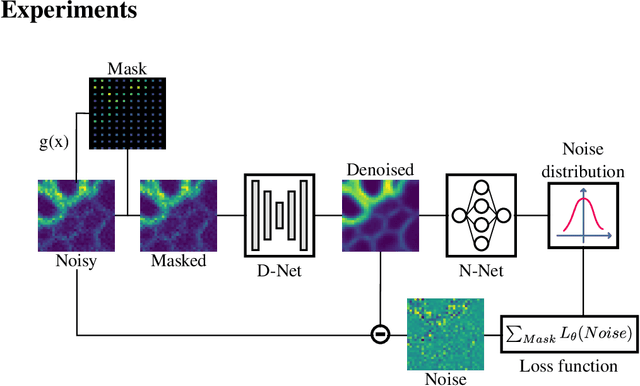
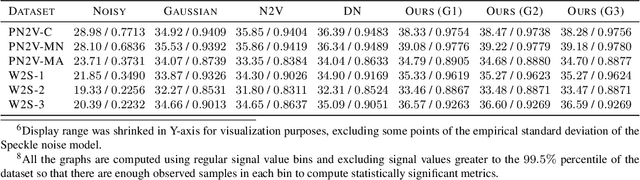
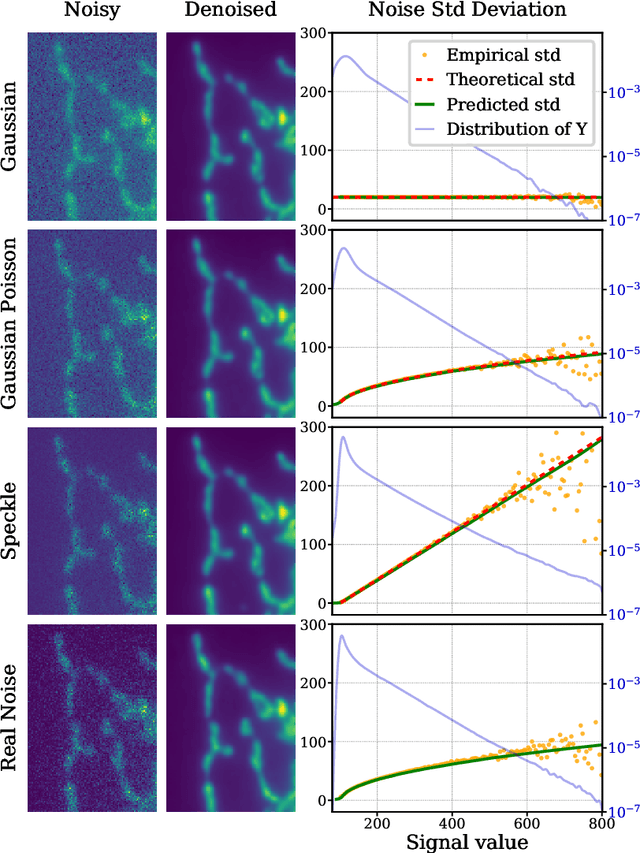
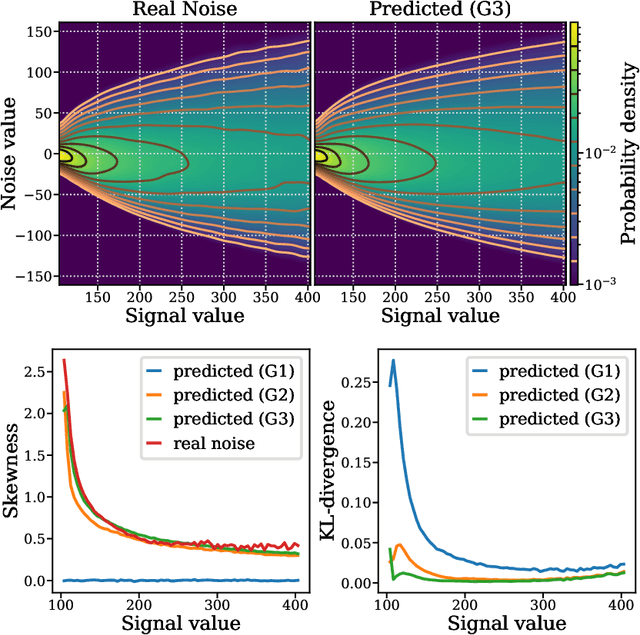
We propose a novel self-supervised image blind denoising approach in which two neural networks jointly predict the clean signal and infer the noise distribution. Assuming that the noisy observations are independent conditionally to the signal, the networks can be jointly trained without clean training data. Therefore, our approach is particularly relevant for biomedical image denoising where the noise is difficult to model precisely and clean training data are usually unavailable. Our method significantly outperforms current state-of-the-art self-supervised blind denoising algorithms, on six publicly available biomedical image datasets. We also show empirically with synthetic noisy data that our model captures the noise distribution efficiently. Finally, the described framework is simple, lightweight and computationally efficient, making it useful in practical cases.
Some open questions on morphological operators and representations in the deep learning era
May 05, 2021During recent years, the renaissance of neural networks as the major machine learning paradigm and more specifically, the confirmation that deep learning techniques provide state-of-the-art results for most of computer vision tasks has been shaking up traditional research in image processing. The same can be said for research in communities working on applied harmonic analysis, information geometry, variational methods, etc. For many researchers, this is viewed as an existential threat. On the one hand, research funding agencies privilege mainstream approaches especially when these are unquestionably suitable for solving real problems and for making progress on artificial intelligence. On the other hand, successful publishing of research in our communities is becoming almost exclusively based on a quantitative improvement of the accuracy of any benchmark task. As most of my colleagues sharing this research field, I am confronted with the dilemma of continuing to invest my time and intellectual effort on mathematical morphology as my driving force for research, or simply focussing on how to use deep learning and contributing to it. The solution is not obvious to any of us since our research is not fundamental, it is just oriented to solve challenging problems, which can be more or less theoretical. Certainly, it would be foolish for anyone to claim that deep learning is insignificant or to think that one's favourite image processing domain is productive enough to ignore the state-of-the-art. I fully understand that the labs and leading people in image processing communities have been shifting their research to almost exclusively focus on deep learning techniques. My own position is different: I do think there is room for progress on mathematically grounded image processing branches, under the condition that these are rethought in a broader sense from the deep learning paradigm. Indeed, I firmly believe that the convergence between mathematical morphology and the computation methods which gravitate around deep learning (fully connected networks, convolutional neural networks, residual neural networks, recurrent neural networks, etc.) is worthwhile. The goal of this talk is to discuss my personal vision regarding these potential interactions. Without any pretension of being exhaustive, I want to address it with a series of open questions, covering a wide range of specificities of morphological operators and representations, which could be tackled and revisited under the paradigm of deep learning. An expected benefit of such convergence between morphology and deep learning is a cross-fertilization of concepts and techniques between both fields. In addition, I think the future answer to some of these questions can provide some insight on understanding, interpreting and simplifying deep learning networks.
Manipulation of Camera Sensor Data via Fault Injection for Anomaly Detection Studies in Verification and Validation Activities For AI
Aug 31, 2021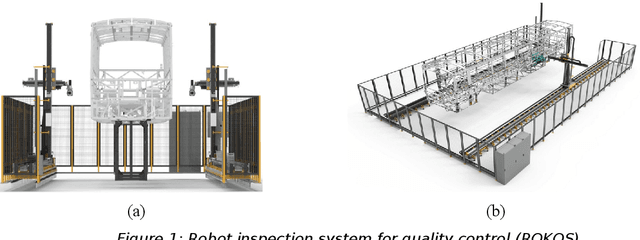



In this study, the creation of a database consisting of images obtained as a result of deformation in the images recorded by these cameras by injecting errors into the robot camera nodes and the alternative uses of this database are explained. The study is based on an existing camera fault injection software that injects faults into the cameras of the ROKOS robot arms while the system is running and collects the normal and faulty images recorded during this injection. The database obtained in the study is a source for detecting anomalies that may occur in robotic systems. The ROKOS system has been developed on the inspection of the parts in a bus body-in-white with the help of the cameras on the ROKOS robot arms, right and left. The simulation-based robot verification testing tool (SRVT) system is a system that has emerged by simulating these robots and the chassis in the Gazebo environment, performing and implementing the trajectory planning with the MoveIt planner, and integrating the ROS Smach structure and mission communication. This system is being developed within the scope of the VALU3S project to create a V&V system in the robotics field. Within the scope of this study, a database of 10000 images was created, consisting of 5000 normal and 5000 faulty images. Faulty pictures were obtained by injecting seven different image fault types, including erosion, dilusion, opening, closing, gradient, motion-blur and partial loss, at different times when the robot was in operation. This database consists of images taken by the ROKOS system from the vehicle during a bus chassis inspection mission.
An iterative Jacobi-like algorithm to compute a few sparse eigenvalue-eigenvector pairs
Jun 08, 2021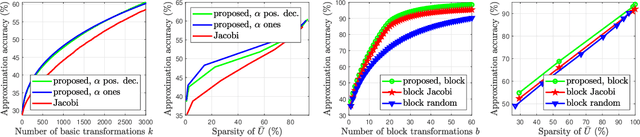
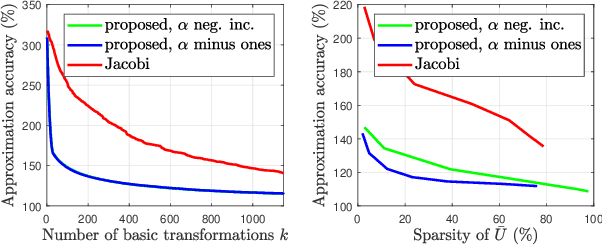
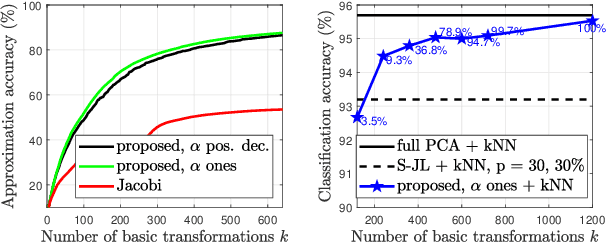
In this paper, we describe a new algorithm to compute the extreme eigenvalue/eigenvector pairs of a symmetric matrix. The proposed algorithm can be viewed as an extension of the Jacobi transformation method for symmetric matrix diagonalization to the case where we want to compute just a few eigenvalues/eigenvectors. The method is also particularly well suited for the computation of sparse eigenspaces. We show the effectiveness of the method for sparse low-rank approximations and show applications to random symmetric matrices, graph Fourier transforms, and with the sparse principal component analysis in image classification experiments.
Large-Scale Zero-Shot Image Classification from Rich and Diverse Textual Descriptions
Mar 17, 2021


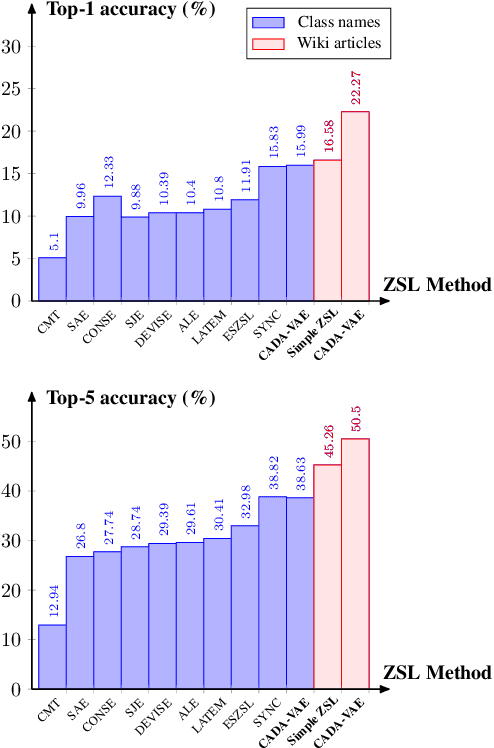
We study the impact of using rich and diverse textual descriptions of classes for zero-shot learning (ZSL) on ImageNet. We create a new dataset ImageNet-Wiki that matches each ImageNet class to its corresponding Wikipedia article. We show that merely employing these Wikipedia articles as class descriptions yields much higher ZSL performance than prior works. Even a simple model using this type of auxiliary data outperforms state-of-the-art models that rely on standard features of word embedding encodings of class names. These results highlight the usefulness and importance of textual descriptions for ZSL, as well as the relative importance of auxiliary data type compared to algorithmic progress. Our experimental results also show that standard zero-shot learning approaches generalize poorly across categories of classes.
Deep Graph-Convolutional Image Denoising
Jul 19, 2019



Non-local self-similarity is well-known to be an effective prior for the image denoising problem. However, little work has been done to incorporate it in convolutional neural networks, which surpass non-local model-based methods despite only exploiting local information. In this paper, we propose a novel end-to-end trainable neural network architecture employing layers based on graph convolution operations, thereby creating neurons with non-local receptive fields. The graph convolution operation generalizes the classic convolution to arbitrary graphs. In this work, the graph is dynamically computed from similarities among the hidden features of the network, so that the powerful representation learning capabilities of the network are exploited to uncover self-similar patterns. We introduce a lightweight Edge-Conditioned Convolution which addresses vanishing gradient and over-parameterization issues of this particular graph convolution. Extensive experiments show state-of-the-art performance with improved qualitative and quantitative results on both synthetic Gaussian noise and real noise.