 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Co$^2$L: Contrastive Continual Learning
Jun 28, 2021
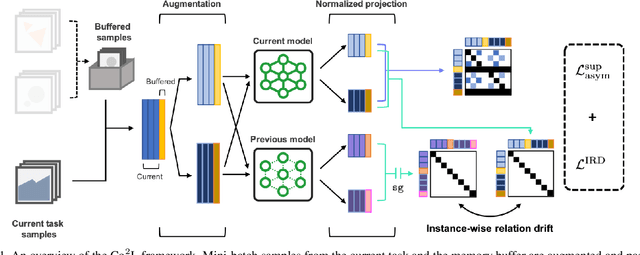
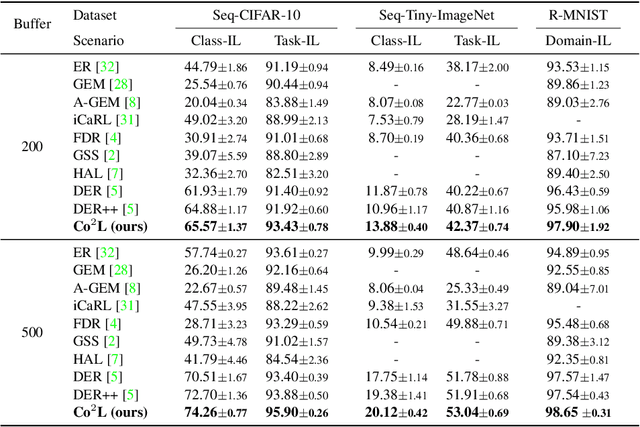
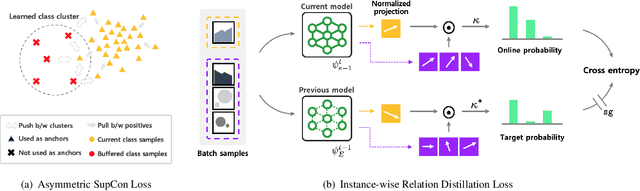
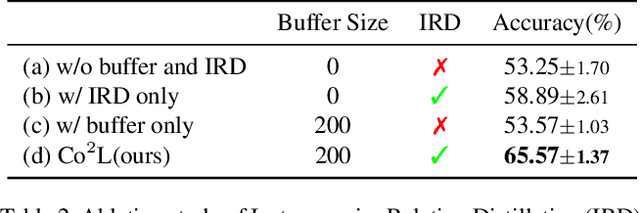
Recent breakthroughs in self-supervised learning show that such algorithms learn visual representations that can be transferred better to unseen tasks than joint-training methods relying on task-specific supervision. In this paper, we found that the similar holds in the continual learning con-text: contrastively learned representations are more robust against the catastrophic forgetting than jointly trained representations. Based on this novel observation, we propose a rehearsal-based continual learning algorithm that focuses on continually learning and maintaining transferable representations. More specifically, the proposed scheme (1) learns representations using the contrastive learning objective, and (2) preserves learned representations using a self-supervised distillation step. We conduct extensive experimental validations under popular benchmark image classification datasets, where our method sets the new state-of-the-art performance.
Megapixel Photon-Counting Color Imaging using Quanta Image Sensor
Mar 21, 2019
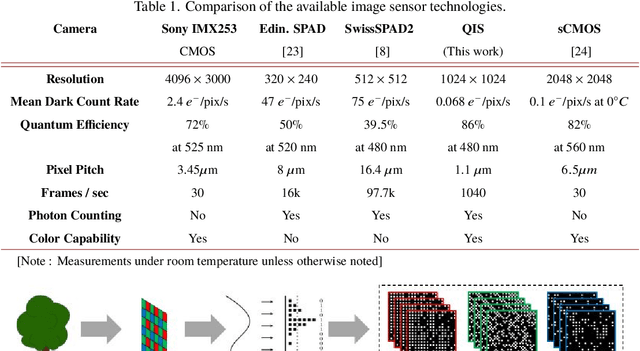


Quanta Image Sensor (QIS) is a single-photon detector designed for extremely low light imaging conditions. Majority of the existing QIS prototypes are monochrome based on single-photon avalanche diodes (SPAD). Color imaging has not been demonstrated with single-photon detectors due to the intrinsic difficulty of shrinking the pixel size and increasing the spatial resolution while maintaining acceptable intra-pixel cross-talk. In this paper, we present image reconstruction of the first color QIS with a resolution of $1024 \times 1024$ pixels, supporting both single-bit and multi-bit photon counting capability. Our color image reconstruction is enabled by a customized joint demosaicing-denoising algorithm, leveraging truncated Poisson statistics and variance stabilizing transforms. Experimental results of the new sensor and algorithm demonstrate superior color imaging performance for very low-light conditions with a mean exposure of as low as a few photons per pixel.
Discrete Cosine Transform in JPEG Compression
Feb 13, 2021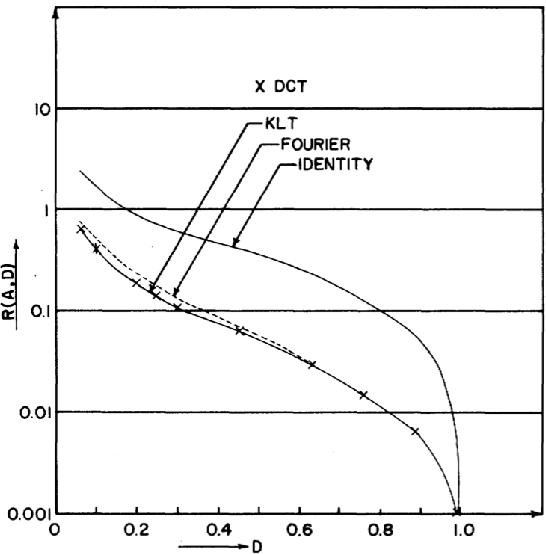
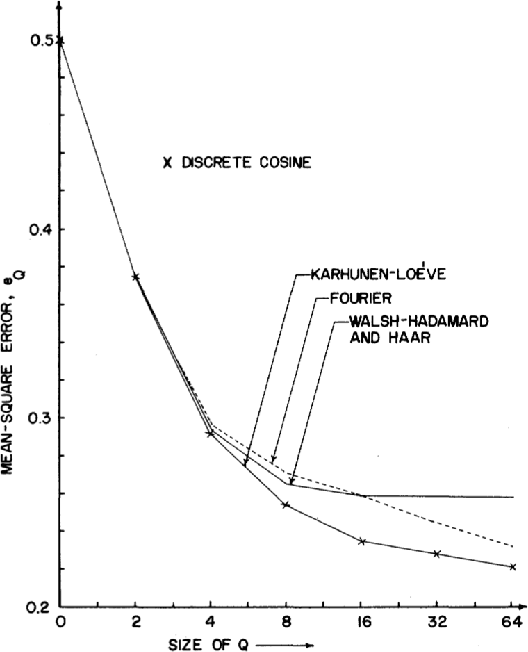

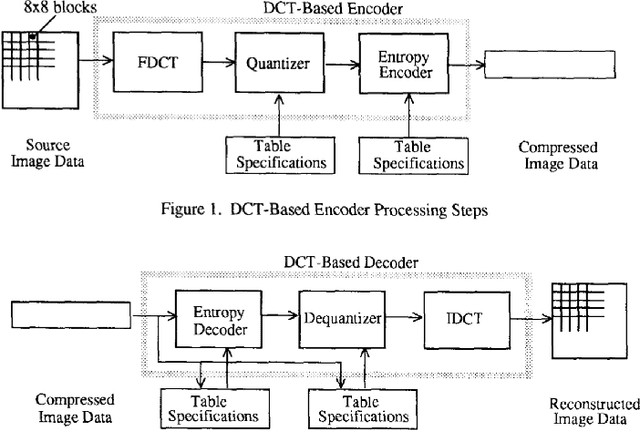
Image Compression has become an absolute necessity in today's day and age. With the advent of the Internet era, compressing files to share among other users is quintessential. Several efforts have been made to reduce file sizes while still maintain image quality in order to transmit files even on limited bandwidth connections. This paper discusses the need for Discrete Cosine Transform or DCT in the compression of images in Joint Photographic Experts Group or JPEG file format. Via an intensive literature study, this paper first introduces DCT and JPEG Compression. The section preceding it discusses how JPEG compression is implemented by DCT. The last section concludes with further real world applications of DCT in image processing.
Compensation Learning
Jul 26, 2021
Weighting strategy prevails in machine learning. For example, a common approach in robust machine learning is to exert lower weights on samples which are likely to be noisy or hard. This study reveals another undiscovered strategy, namely, compensating, that has also been widely used in machine learning. Learning with compensating is called compensation learning and a systematic taxonomy is constructed for it in this study. In our taxonomy, compensation learning is divided on the basis of the compensation targets, inference manners, and granularity levels. Many existing learning algorithms including some classical ones can be seen as a special case of compensation learning or partially leveraging compensating. Furthermore, a family of new learning algorithms can be obtained by plugging the compensation learning into existing learning algorithms. Specifically, three concrete new learning algorithms are proposed for robust machine learning. Extensive experiments on text sentiment analysis, image classification, and graph classification verify the effectiveness of the three new algorithms. Compensation learning can also be used in various learning scenarios, such as imbalance learning, clustering, regression, and so on.
Explainable AI for Natural Adversarial Images
Jun 16, 2021
Adversarial images highlight how vulnerable modern image classifiers are to perturbations outside of their training set. Human oversight might mitigate this weakness, but depends on humans understanding the AI well enough to predict when it is likely to make a mistake. In previous work we have found that humans tend to assume that the AI's decision process mirrors their own. Here we evaluate if methods from explainable AI can disrupt this assumption to help participants predict AI classifications for adversarial and standard images. We find that both saliency maps and examples facilitate catching AI errors, but their effects are not additive, and saliency maps are more effective than examples.
Unsupervised Single Image Deraining with Self-supervised Constraints
Nov 21, 2018
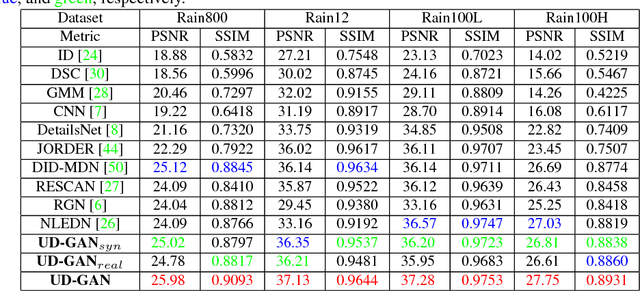

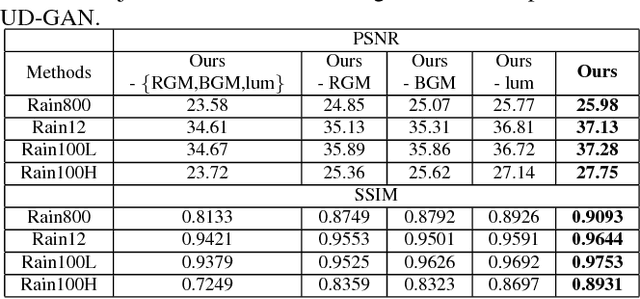
Most existing single image deraining methods require learning supervised models from a large set of paired synthetic training data, which limits their generality, scalability and practicality in real-world multimedia applications. Besides, due to lack of labeled-supervised constraints, directly applying existing unsupervised frameworks to the image deraining task will suffer from low-quality recovery. Therefore, we propose an Unsupervised Deraining Generative Adversarial Network (UD-GAN) to tackle above problems by introducing self-supervised constraints from the intrinsic statistics of unpaired rainy and clean images. Specifically, we firstly design two collaboratively optimized modules, namely Rain Guidance Module (RGM) and Background Guidance Module (BGM), to take full advantage of rainy image characteristics: The RGM is designed to discriminate real rainy images from fake rainy images which are created based on outputs of the generator with BGM. Simultaneously, the BGM exploits a hierarchical Gaussian-Blur gradient error to ensure background consistency between rainy input and de-rained output. Secondly, a novel luminance-adjusting adversarial loss is integrated into the clean image discriminator considering the built-in luminance difference between real clean images and derained images. Comprehensive experiment results on various benchmarking datasets and different training settings show that UD-GAN outperforms existing image deraining methods in both quantitative and qualitative comparisons.
Polyp-PVT: Polyp Segmentation with Pyramid Vision Transformers
Aug 16, 2021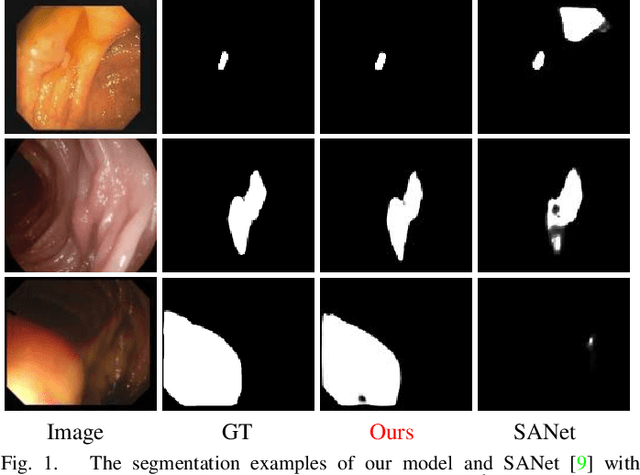
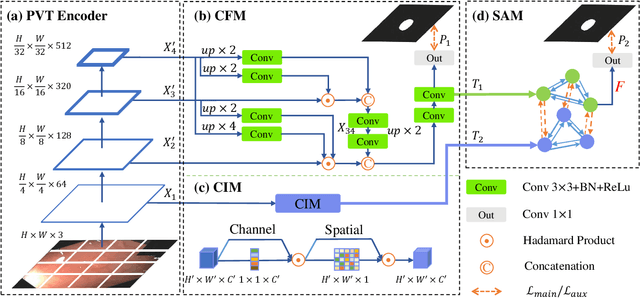
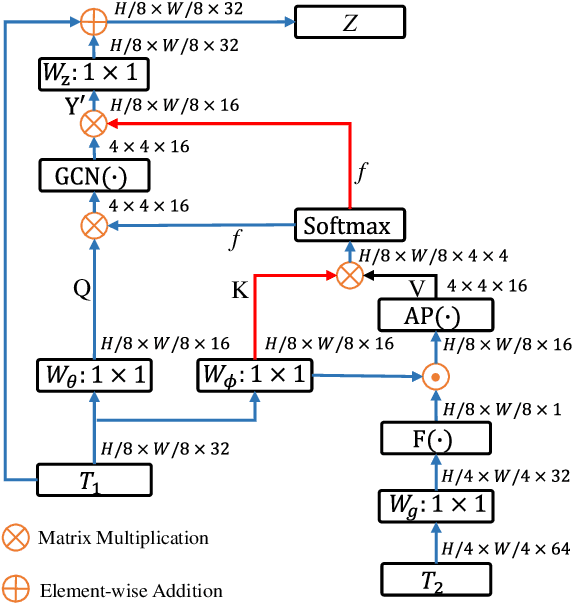
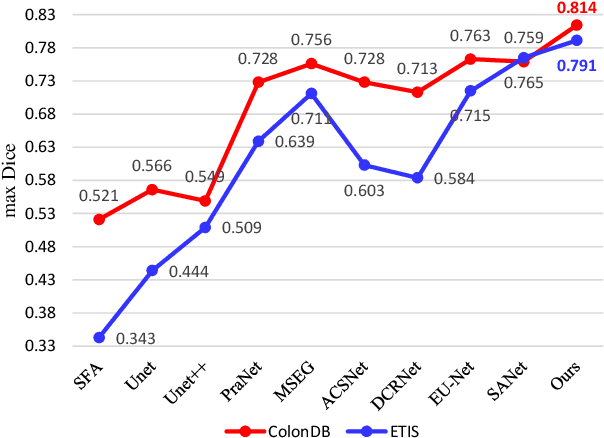
Most polyp segmentation methods use CNNs as their backbone, leading to two key issues when exchanging information between the encoder and decoder: 1) taking into account the differences in contribution between different-level features; and 2) designing effective mechanism for fusing these features. Different from existing CNN-based methods, we adopt a transformer encoder, which learns more powerful and robust representations. In addition, considering the image acquisition influence and elusive properties of polyps, we introduce three novel modules, including a cascaded fusion module (CFM), a camouflage identification module (CIM), a and similarity aggregation module (SAM). Among these, the CFM is used to collect the semantic and location information of polyps from high-level features, while the CIM is applied to capture polyp information disguised in low-level features. With the help of the SAM, we extend the pixel features of the polyp area with high-level semantic position information to the entire polyp area, thereby effectively fusing cross-level features. The proposed model, named \ourmodel, effectively suppresses noises in the features and significantly improves their expressive capabilities. Extensive experiments on five widely adopted datasets show that the proposed model is more robust to various challenging situations (e.g., appearance changes, small objects) than existing methods, and achieves the new state-of-the-art performance. The proposed model is available at https://github.com/DengPingFan/Polyp-PVT .
SPeCiaL: Self-Supervised Pretraining for Continual Learning
Jun 16, 2021
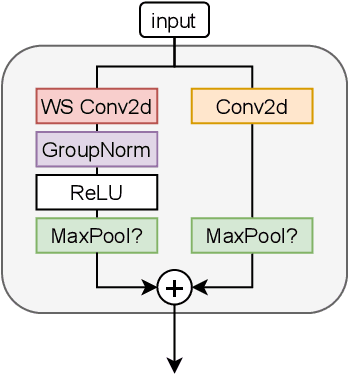
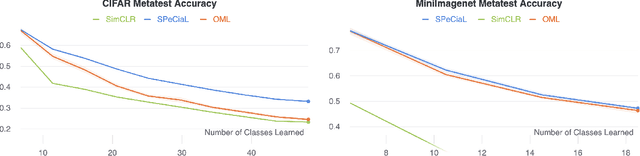
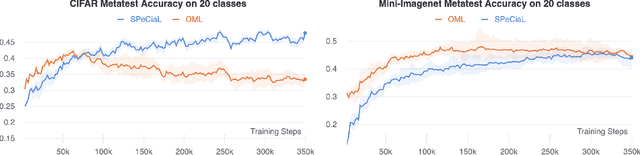
This paper presents SPeCiaL: a method for unsupervised pretraining of representations tailored for continual learning. Our approach devises a meta-learning objective that differentiates through a sequential learning process. Specifically, we train a linear model over the representations to match different augmented views of the same image together, each view presented sequentially. The linear model is then evaluated on both its ability to classify images it just saw, and also on images from previous iterations. This gives rise to representations that favor quick knowledge retention with minimal forgetting. We evaluate SPeCiaL in the Continual Few-Shot Learning setting, and show that it can match or outperform other supervised pretraining approaches.
Crash Report Data Analysis for Creating Scenario-Wise, Spatio-Temporal Attention Guidance to Support Computer Vision-based Perception of Fatal Crash Risks
Sep 06, 2021
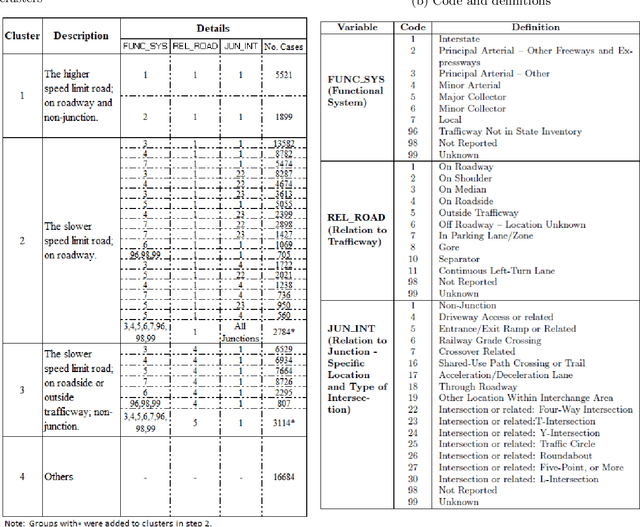
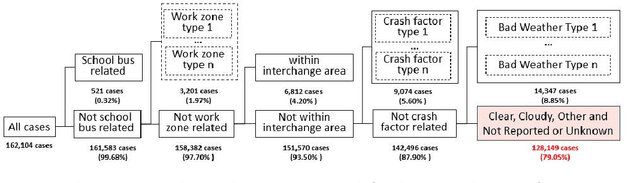
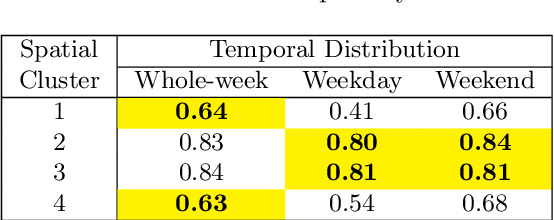
Reducing traffic fatalities and serious injuries is a top priority of the US Department of Transportation. The computer vision (CV)-based crash anticipation in the near-crash phase is receiving growing attention. The ability to perceive fatal crash risks earlier is also critical because it will improve the reliability of crash anticipation. Yet, annotated image data for training a reliable AI model for the early visual perception of crash risks are not abundant. The Fatality Analysis Reporting System contains big data of fatal crashes. It is a reliable data source for learning the relationship between driving scene characteristics and fatal crashes to compensate for the limitation of CV. Therefore, this paper develops a data analytics model, named scenario-wise, Spatio-temporal attention guidance, from fatal crash report data, which can estimate the relevance of detected objects to fatal crashes from their environment and context information. First, the paper identifies five sparse variables that allow for decomposing the 5-year fatal crash dataset to develop scenario-wise attention guidance. Then, exploratory analysis of location- and time-related variables of the crash report data suggests reducing fatal crashes to spatially defined groups. The group's temporal pattern is an indicator of the similarity of fatal crashes in the group. Hierarchical clustering and K-means clustering merge the spatially defined groups into six clusters according to the similarity of their temporal patterns. After that, association rule mining discovers the statistical relationship between the temporal information of driving scenes with crash features, for each cluster. The paper shows how the developed attention guidance supports the design and implementation of a preliminary CV model that can identify objects of a possibility to involve in fatal crashes from their environment and context information.
* 20 pages, 14 figures, submitted and accepted by Accident Analysis & Prevention
Image Super Resolution via Bilinear Pooling: Application to Confocal Endomicroscopy
Jun 18, 2019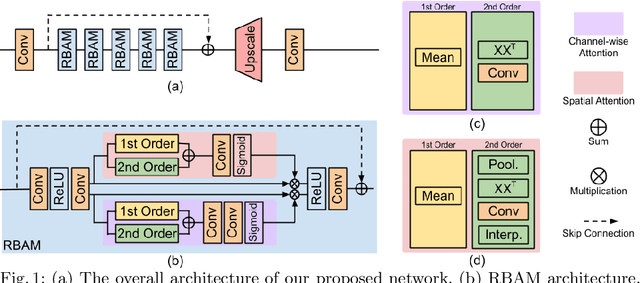

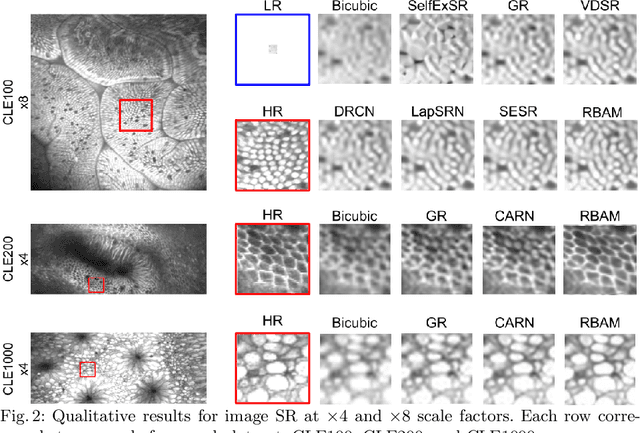

Recent developments in image acquisition literature have miniaturized the confocal laser endomicroscopes to improve usability and flexibility of the apparatus in actual clinical settings. However, miniaturized devices collect less light and have fewer optical components, resulting in pixelation artifacts and low resolution images. Owing to the strength of deep networks, many supervised methods known as super resolution have achieved considerable success in restoring low resolution images by generating the missing high frequency details. In this work, we propose a novel attention mechanism that, for the first time, combines 1st- and 2nd-order statistics for pooling operation, in the spatial and channel-wise dimensions. We compare the efficacy of our method to 11 other existing single image super resolution techniques that compensate for the reduction in image quality caused by the necessity of endomicroscope miniaturization. All evaluations are carried out on three publicly available datasets. Experimental results show that our method can produce competitive results against state-of-the-art in terms of PSNR, SSIM, and IFC metrics. Additionally, our proposed method contains small number of parameters, which makes it lightweight and fast for real-time applications.