 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Drone Detection Using Convolutional Neural Networks
Jul 03, 2021

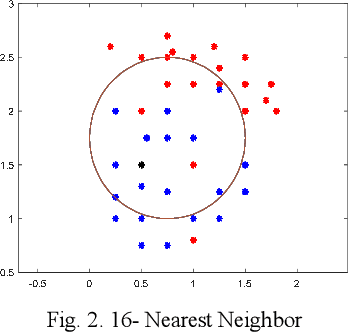

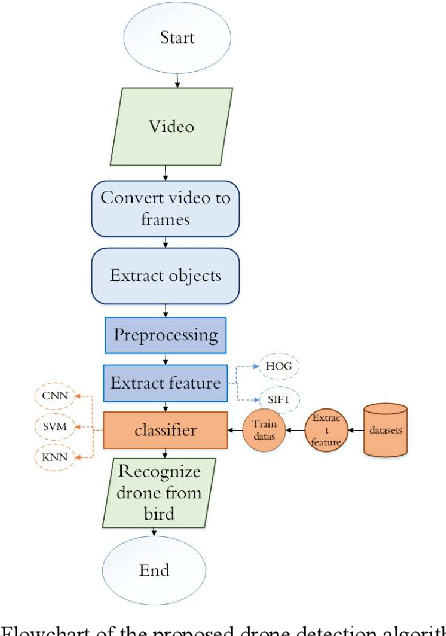
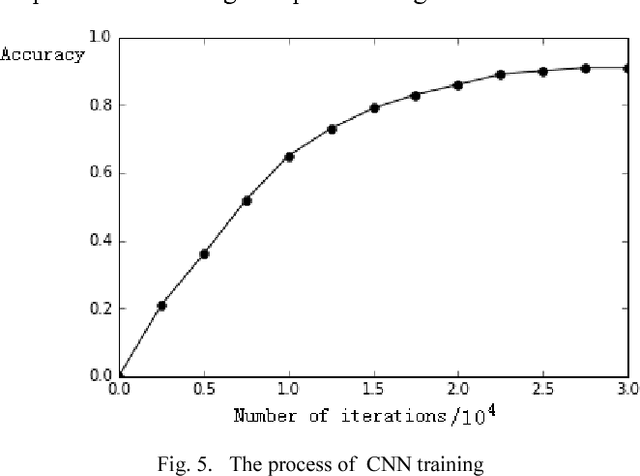
In image processing, it is essential to detect and track air targets, especially UAVs. In this paper, we detect the flying drone using a fisheye camera. In the field of diagnosis and classification of objects, there are always many problems that prevent the development of rapid and significant progress in this area. During the previous decades, a couple of advanced classification methods such as convolutional neural networks and support vector machines have been developed. In this study, the drone was detected using three methods of classification of convolutional neural network (CNN), support vector machine (SVM), and nearest neighbor. The outcomes show that CNN, SVM, and nearest neighbor have total accuracy of 95%, 88%, and 80%, respectively. Compared with other classifiers with the same experimental conditions, the accuracy of the convolutional neural network classifier is satisfactory.
Deep Direct Volume Rendering: Learning Visual Feature Mappings From Exemplary Images
Jun 09, 2021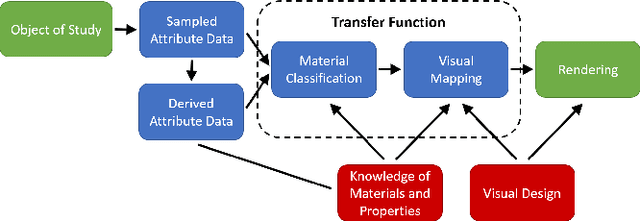
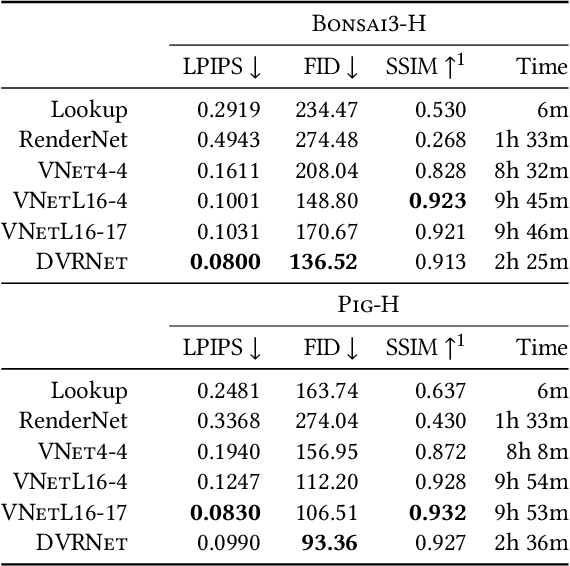
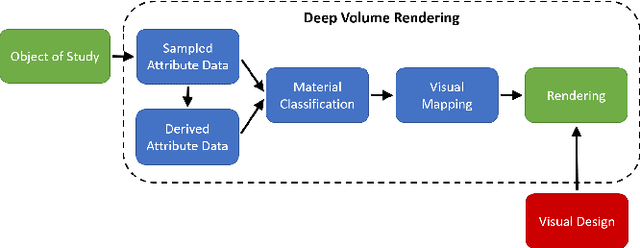
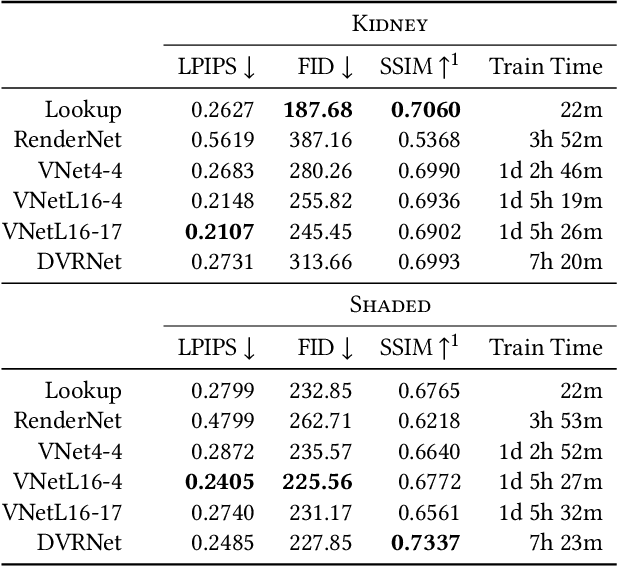
Volume Rendering is an important technique for visualizing three-dimensional scalar data grids and is commonly employed for scientific and medical image data. Direct Volume Rendering (DVR) is a well established and efficient rendering algorithm for volumetric data. Neural rendering uses deep neural networks to solve inverse rendering tasks and applies techniques similar to DVR. However, it has not been demonstrated successfully for the rendering of scientific volume data. In this work, we introduce Deep Direct Volume Rendering (DeepDVR), a generalization of DVR that allows for the integration of deep neural networks into the DVR algorithm. We conceptualize the rendering in a latent color space, thus enabling the use of deep architectures to learn implicit mappings for feature extraction and classification, replacing explicit feature design and hand-crafted transfer functions. Our generalization serves to derive novel volume rendering architectures that can be trained end-to-end directly from examples in image space, obviating the need to manually define and fine-tune multidimensional transfer functions while providing superior classification strength. We further introduce a novel stepsize annealing scheme to accelerate the training of DeepDVR models and validate its effectiveness in a set of experiments. We validate our architectures on two example use cases: (1) learning an optimized rendering from manually adjusted reference images for a single volume and (2) learning advanced visualization concepts like shading and semantic colorization that generalize to unseen volume data. We find that deep volume rendering architectures with explicit modeling of the DVR pipeline effectively enable end-to-end learning of scientific volume rendering tasks from target images.
Co$^2$L: Contrastive Continual Learning
Jun 28, 2021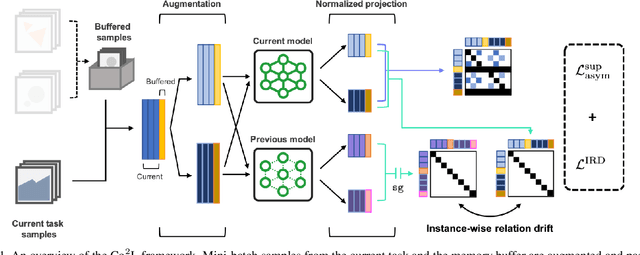
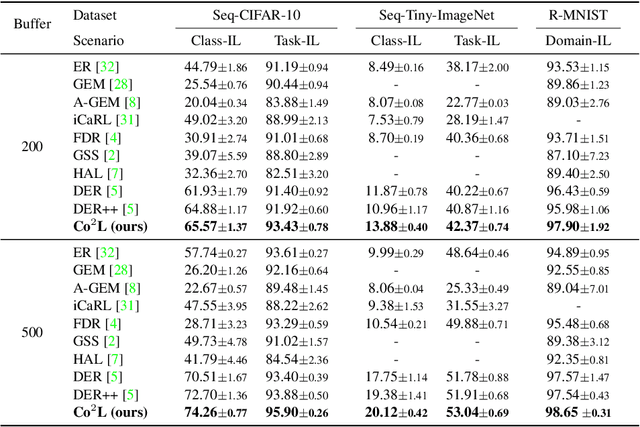
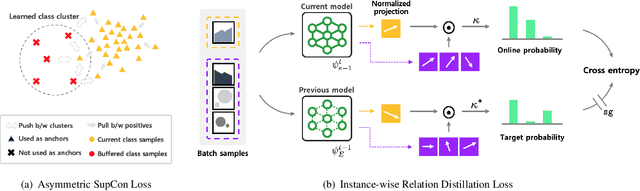
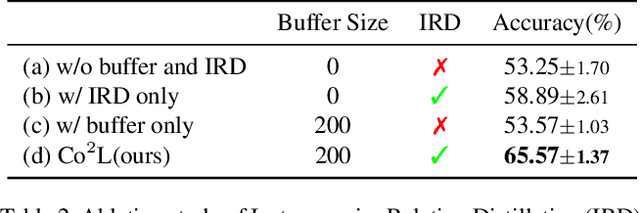
Recent breakthroughs in self-supervised learning show that such algorithms learn visual representations that can be transferred better to unseen tasks than joint-training methods relying on task-specific supervision. In this paper, we found that the similar holds in the continual learning con-text: contrastively learned representations are more robust against the catastrophic forgetting than jointly trained representations. Based on this novel observation, we propose a rehearsal-based continual learning algorithm that focuses on continually learning and maintaining transferable representations. More specifically, the proposed scheme (1) learns representations using the contrastive learning objective, and (2) preserves learned representations using a self-supervised distillation step. We conduct extensive experimental validations under popular benchmark image classification datasets, where our method sets the new state-of-the-art performance.
Image retrieval method based on CNN and dimension reduction
Jan 13, 2019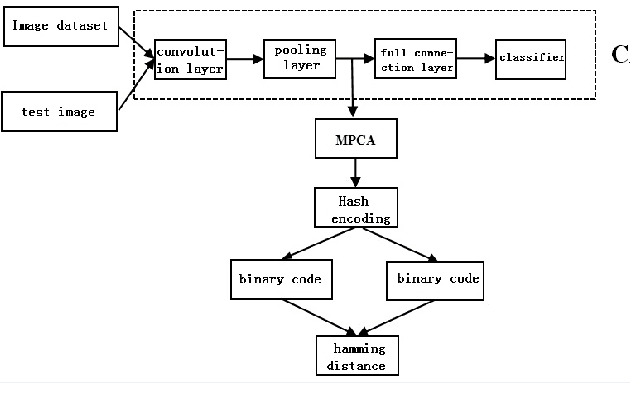
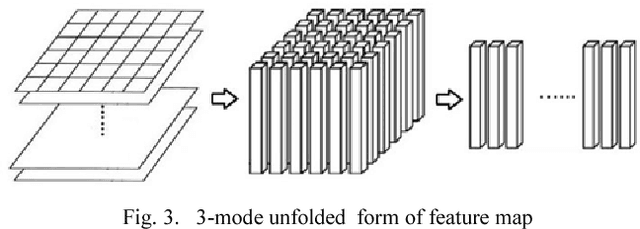

An image retrieval method based on convolution neural network and dimension reduction is proposed in this paper. Convolution neural network is used to extract high-level features of images, and to solve the problem that the extracted feature dimensions are too high and have strong correlation, multilinear principal component analysis is used to reduce the dimension of features. The features after dimension reduction are binary hash coded for fast image retrieval. Experiments show that the method proposed in this paper has better retrieval effect than the retrieval method based on principal component analysis on the e-commerce image datasets.
Generic Merging of Structure from Motion Maps with a Low Memory Footprint
Mar 24, 2021
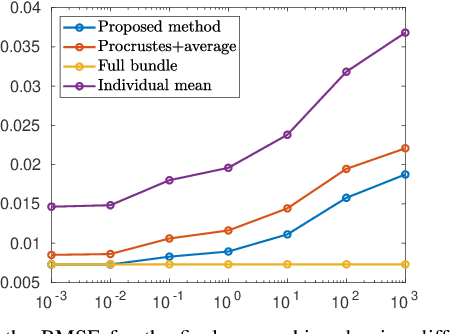
With the development of cheap image sensors, the amount of available image data have increased enormously, and the possibility of using crowdsourced collection methods has emerged. This calls for development of ways to handle all these data. In this paper, we present new tools that will enable efficient, flexible and robust map merging. Assuming that separate optimisations have been performed for the individual maps, we show how only relevant data can be stored in a low memory footprint representation. We use these representations to perform map merging so that the algorithm is invariant to the merging order and independent of the choice of coordinate system. The result is a robust algorithm that can be applied to several maps simultaneously. The result of a merge can also be represented with the same type of low-memory footprint format, which enables further merging and updating of the map in a hierarchical way. Furthermore, the method can perform loop closing and also detect changes in the scene between the capture of the different image sequences. Using both simulated and real data - from both a hand held mobile phone and from a drone - we verify the performance of the proposed method.
Compensation Learning
Jul 26, 2021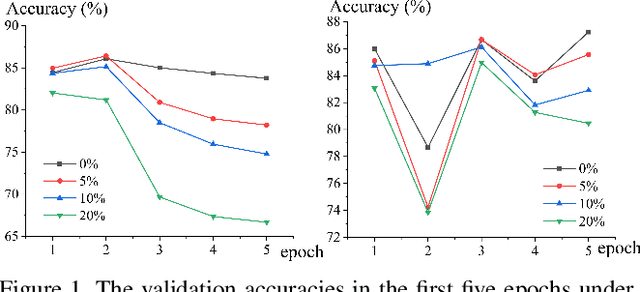
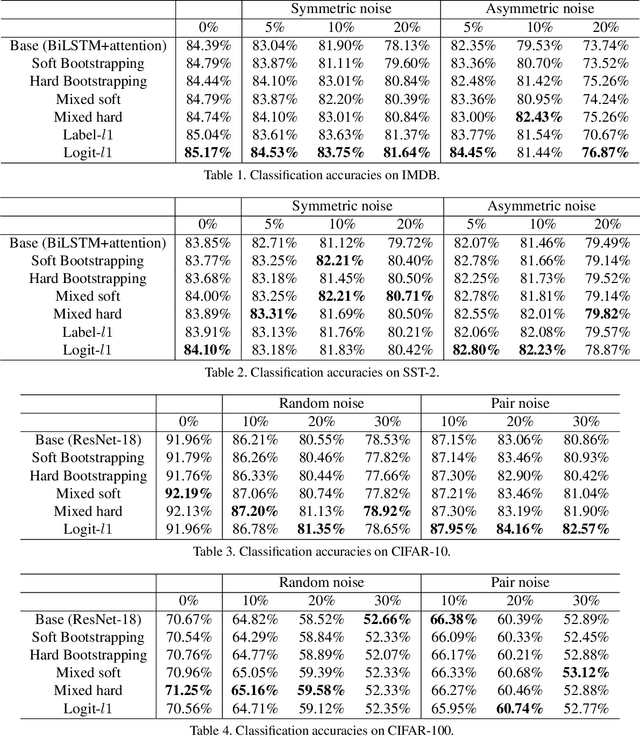
Weighting strategy prevails in machine learning. For example, a common approach in robust machine learning is to exert lower weights on samples which are likely to be noisy or hard. This study reveals another undiscovered strategy, namely, compensating, that has also been widely used in machine learning. Learning with compensating is called compensation learning and a systematic taxonomy is constructed for it in this study. In our taxonomy, compensation learning is divided on the basis of the compensation targets, inference manners, and granularity levels. Many existing learning algorithms including some classical ones can be seen as a special case of compensation learning or partially leveraging compensating. Furthermore, a family of new learning algorithms can be obtained by plugging the compensation learning into existing learning algorithms. Specifically, three concrete new learning algorithms are proposed for robust machine learning. Extensive experiments on text sentiment analysis, image classification, and graph classification verify the effectiveness of the three new algorithms. Compensation learning can also be used in various learning scenarios, such as imbalance learning, clustering, regression, and so on.
Scene Graph Generation with External Knowledge and Image Reconstruction
Apr 01, 2019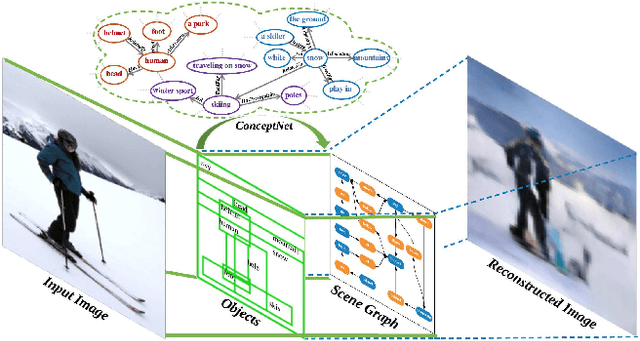
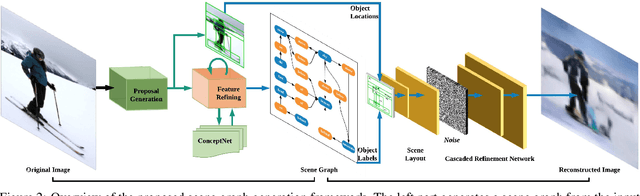
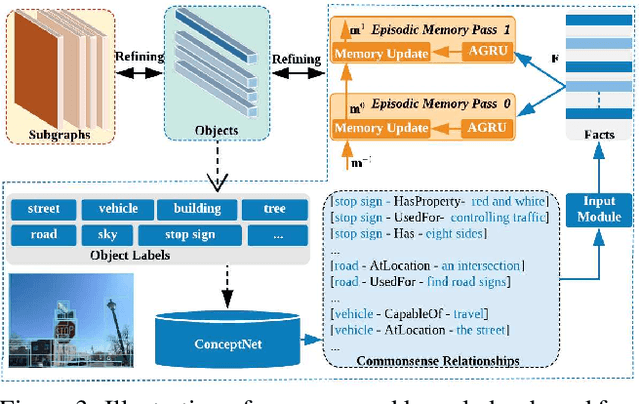
Scene graph generation has received growing attention with the advancements in image understanding tasks such as object detection, attributes and relationship prediction,~\etc. However, existing datasets are biased in terms of object and relationship labels, or often come with noisy and missing annotations, which makes the development of a reliable scene graph prediction model very challenging. In this paper, we propose a novel scene graph generation algorithm with external knowledge and image reconstruction loss to overcome these dataset issues. In particular, we extract commonsense knowledge from the external knowledge base to refine object and phrase features for improving generalizability in scene graph generation. To address the bias of noisy object annotations, we introduce an auxiliary image reconstruction path to regularize the scene graph generation network. Extensive experiments show that our framework can generate better scene graphs, achieving the state-of-the-art performance on two benchmark datasets: Visual Relationship Detection and Visual Genome datasets.
Discrete Cosine Transform in JPEG Compression
Feb 13, 2021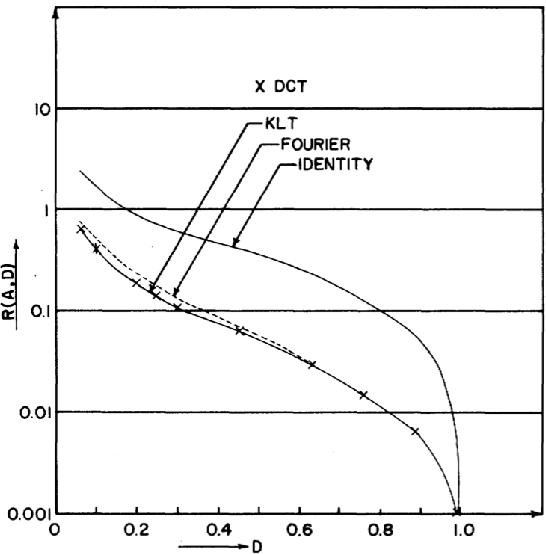
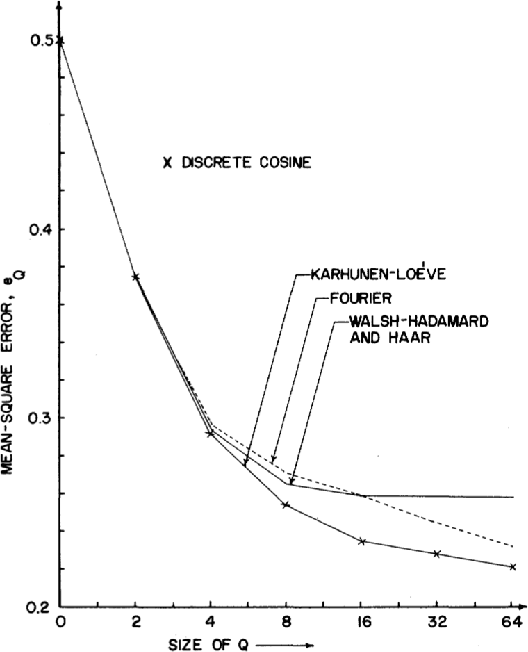

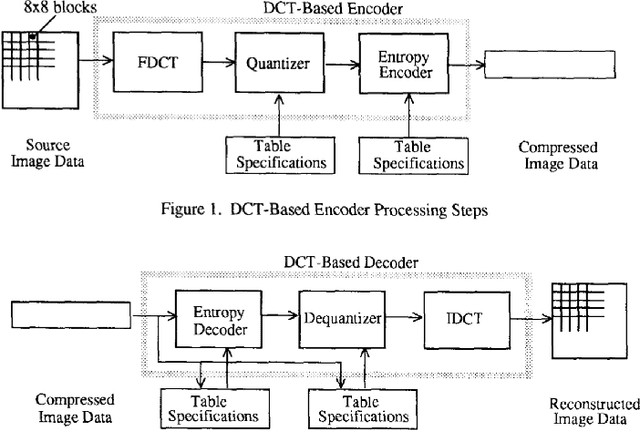
Image Compression has become an absolute necessity in today's day and age. With the advent of the Internet era, compressing files to share among other users is quintessential. Several efforts have been made to reduce file sizes while still maintain image quality in order to transmit files even on limited bandwidth connections. This paper discusses the need for Discrete Cosine Transform or DCT in the compression of images in Joint Photographic Experts Group or JPEG file format. Via an intensive literature study, this paper first introduces DCT and JPEG Compression. The section preceding it discusses how JPEG compression is implemented by DCT. The last section concludes with further real world applications of DCT in image processing.
Polyp-PVT: Polyp Segmentation with Pyramid Vision Transformers
Aug 16, 2021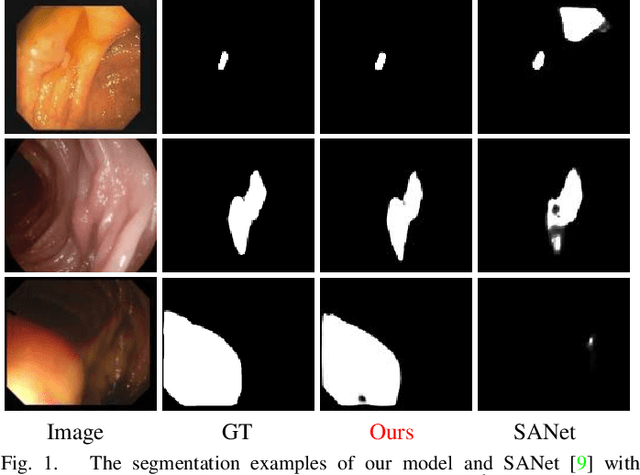
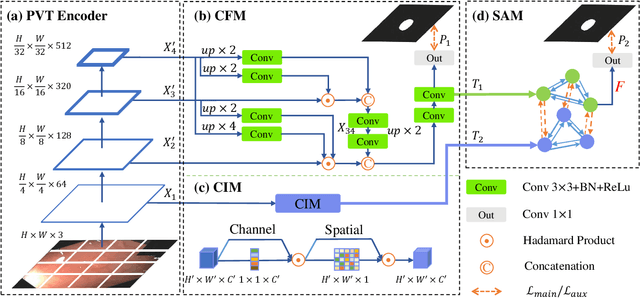
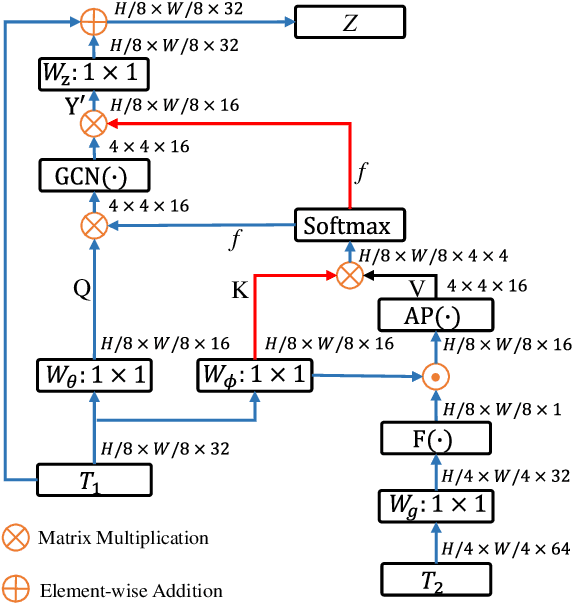
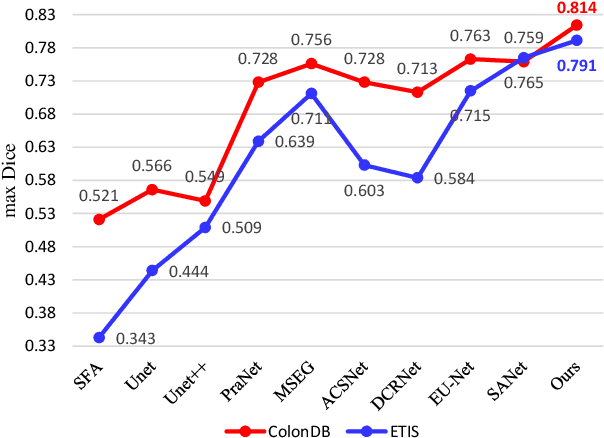
Most polyp segmentation methods use CNNs as their backbone, leading to two key issues when exchanging information between the encoder and decoder: 1) taking into account the differences in contribution between different-level features; and 2) designing effective mechanism for fusing these features. Different from existing CNN-based methods, we adopt a transformer encoder, which learns more powerful and robust representations. In addition, considering the image acquisition influence and elusive properties of polyps, we introduce three novel modules, including a cascaded fusion module (CFM), a camouflage identification module (CIM), a and similarity aggregation module (SAM). Among these, the CFM is used to collect the semantic and location information of polyps from high-level features, while the CIM is applied to capture polyp information disguised in low-level features. With the help of the SAM, we extend the pixel features of the polyp area with high-level semantic position information to the entire polyp area, thereby effectively fusing cross-level features. The proposed model, named \ourmodel, effectively suppresses noises in the features and significantly improves their expressive capabilities. Extensive experiments on five widely adopted datasets show that the proposed model is more robust to various challenging situations (e.g., appearance changes, small objects) than existing methods, and achieves the new state-of-the-art performance. The proposed model is available at https://github.com/DengPingFan/Polyp-PVT .
Explainable AI for Natural Adversarial Images
Jun 16, 2021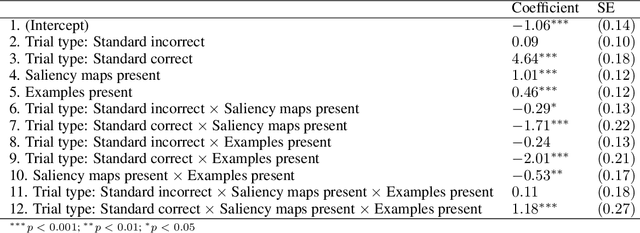
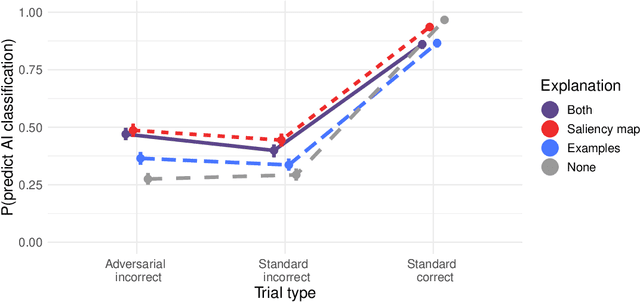
Adversarial images highlight how vulnerable modern image classifiers are to perturbations outside of their training set. Human oversight might mitigate this weakness, but depends on humans understanding the AI well enough to predict when it is likely to make a mistake. In previous work we have found that humans tend to assume that the AI's decision process mirrors their own. Here we evaluate if methods from explainable AI can disrupt this assumption to help participants predict AI classifications for adversarial and standard images. We find that both saliency maps and examples facilitate catching AI errors, but their effects are not additive, and saliency maps are more effective than examples.