 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
se(3)-TrackNet: Data-driven 6D Pose Tracking by Calibrating Image Residuals in Synthetic Domains
Jul 27, 2020
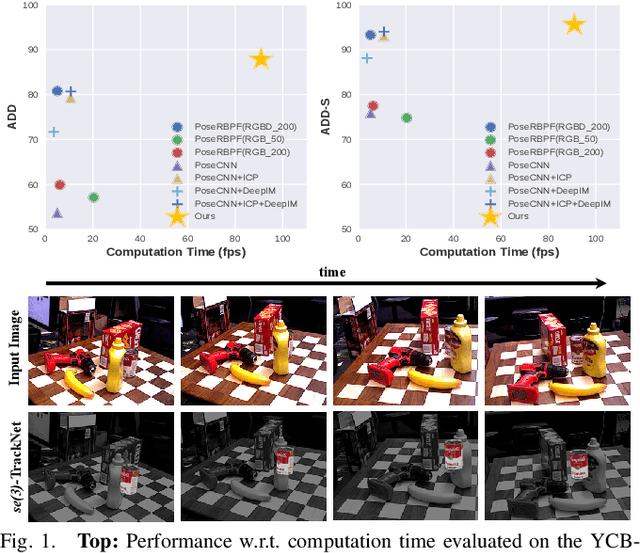
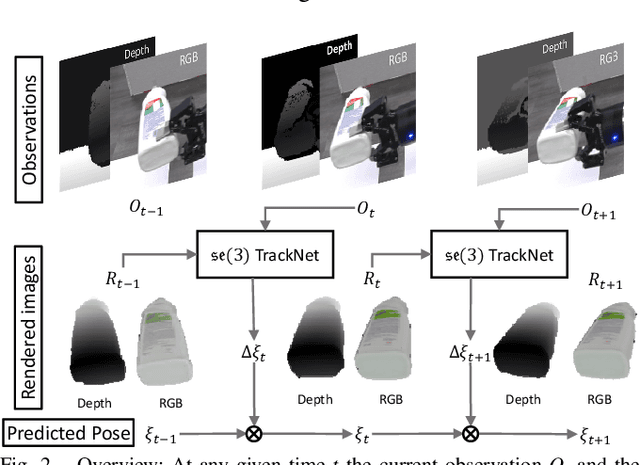
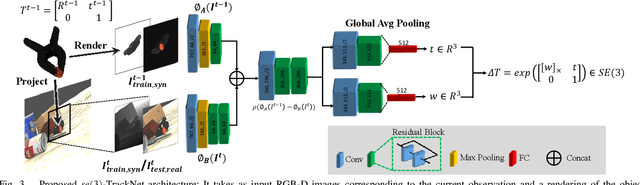

Tracking the 6D pose of objects in video sequences is important for robot manipulation. This task, however, introduces multiple challenges: (i) robot manipulation involves significant occlusions; (ii) data and annotations are troublesome and difficult to collect for 6D poses, which complicates machine learning solutions, and (iii) incremental error drift often accumulates in long term tracking to necessitate re-initialization of the object's pose. This work proposes a data-driven optimization approach for long-term, 6D pose tracking. It aims to identify the optimal relative pose given the current RGB-D observation and a synthetic image conditioned on the previous best estimate and the object's model. The key contribution in this context is a novel neural network architecture, which appropriately disentangles the feature encoding to help reduce domain shift, and an effective 3D orientation representation via Lie Algebra. Consequently, even when the network is trained only with synthetic data can work effectively over real images. Comprehensive experiments over benchmarks - existing ones as well as a new dataset with significant occlusions related to object manipulation - show that the proposed approach achieves consistently robust estimates and outperforms alternatives, even though they have been trained with real images. The approach is also the most computationally efficient among the alternatives and achieves a tracking frequency of 90.9Hz.
An Attention Module for Convolutional Neural Networks
Aug 18, 2021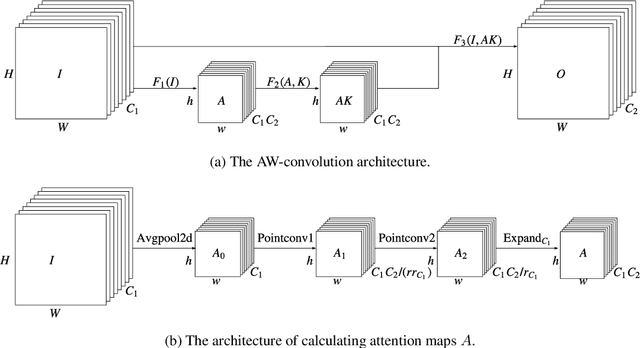
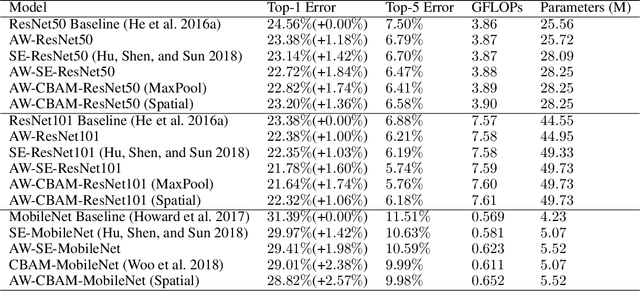
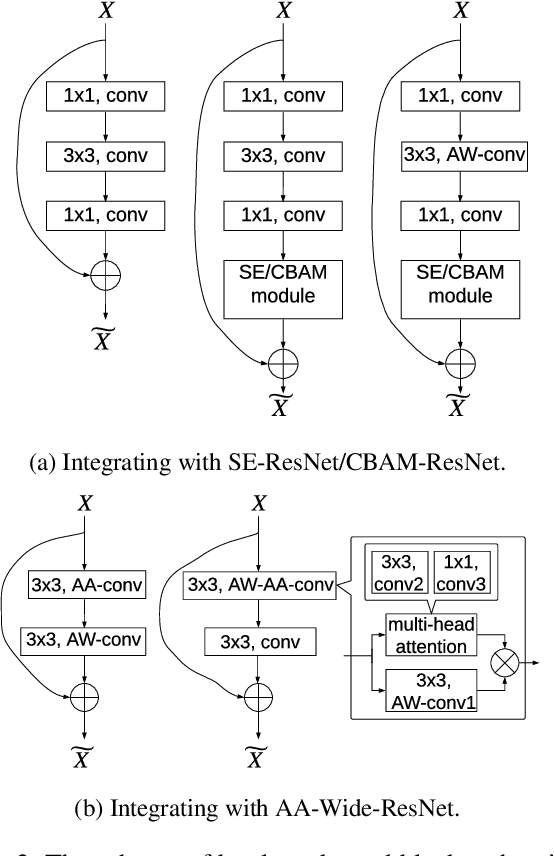
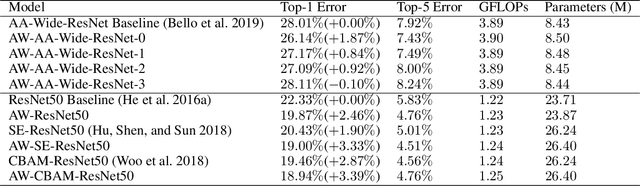
Attention mechanism has been regarded as an advanced technique to capture long-range feature interactions and to boost the representation capability for convolutional neural networks. However, we found two ignored problems in current attentional activations-based models: the approximation problem and the insufficient capacity problem of the attention maps. To solve the two problems together, we initially propose an attention module for convolutional neural networks by developing an AW-convolution, where the shape of attention maps matches that of the weights rather than the activations. Our proposed attention module is a complementary method to previous attention-based schemes, such as those that apply the attention mechanism to explore the relationship between channel-wise and spatial features. Experiments on several datasets for image classification and object detection tasks show the effectiveness of our proposed attention module. In particular, our proposed attention module achieves 1.00% Top-1 accuracy improvement on ImageNet classification over a ResNet101 baseline and 0.63 COCO-style Average Precision improvement on the COCO object detection on top of a Faster R-CNN baseline with the backbone of ResNet101-FPN. When integrating with the previous attentional activations-based models, our proposed attention module can further increase their Top-1 accuracy on ImageNet classification by up to 0.57% and COCO-style Average Precision on the COCO object detection by up to 0.45. Code and pre-trained models will be publicly available.
Universal Image Manipulation Detection using Deep Siamese Convolutional Neural Network
Aug 23, 2018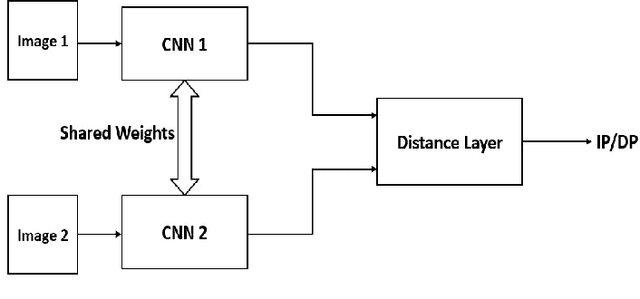
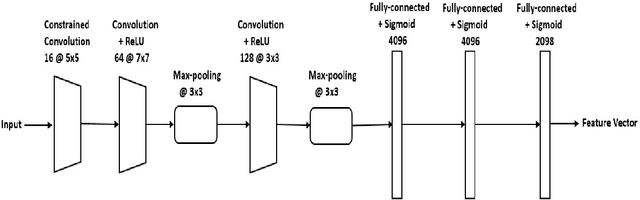

Detection of different types of image editing operations carried out on an image is an important problem in image forensics. It gives the information about the processing history of an image, and also can expose forgeries present in an image. There have been few methods proposed to detect different types of image editing operations in a single framework. However, all the operations have to be known a priori in the training phase. But, in real-forensics scenarios it may not be possible to know about the editing operations carried out on an image. To solve this problem, we propose a novel deep learning-based method which can differentiate between different types of image editing operations. The proposed method classifies image patches in a pair-wise fashion as either similarly or differently processed using a deep siamese neural network. Once the network learns feature that can discriminate between different image editing operations, it can differentiate between different image editing operations not present in the training stage. The experimental results show the efficacy of the proposed method in detecting/discriminating different image editing operations.
Learning Non-local Image Diffusion for Image Denoising
Feb 24, 2017


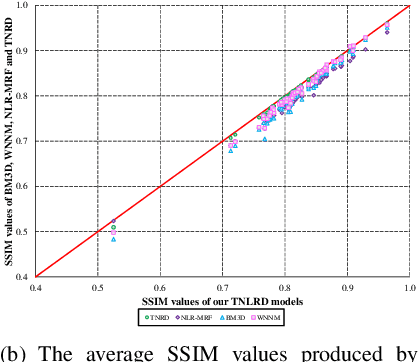
Image diffusion plays a fundamental role for the task of image denoising. Recently proposed trainable nonlinear reaction diffusion (TNRD) model defines a simple but very effective framework for image denoising. However, as the TNRD model is a local model, the diffusion behavior of which is purely controlled by information of local patches, it is prone to create artifacts in the homogenous regions and over-smooth highly textured regions, especially in the case of strong noise levels. Meanwhile, it is widely known that the non-local self-similarity (NSS) prior stands as an effective image prior for image denoising, which has been widely exploited in many non-local methods. In this work, we are highly motivated to embed the NSS prior into the TNRD model to tackle its weaknesses. In order to preserve the expected property that end-to-end training is available, we exploit the NSS prior by a set of non-local filters, and derive our proposed trainable non-local reaction diffusion (TNLRD) model for image denoising. Together with the local filters and influence functions, the non-local filters are learned by employing loss-specific training. The experimental results show that the trained TNLRD model produces visually plausible recovered images with more textures and less artifacts, compared to its local versions. Moreover, the trained TNLRD model can achieve strongly competitive performance to recent state-of-the-art image denoising methods in terms of peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM).
S2R-DepthNet: Learning a Generalizable Depth-specific Structural Representation
Apr 02, 2021
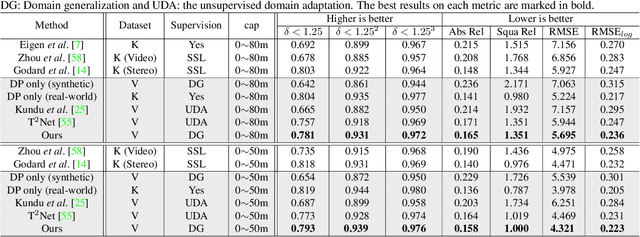
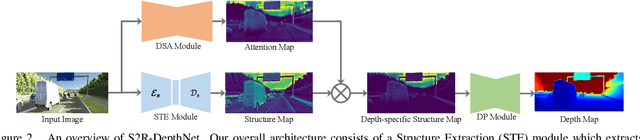
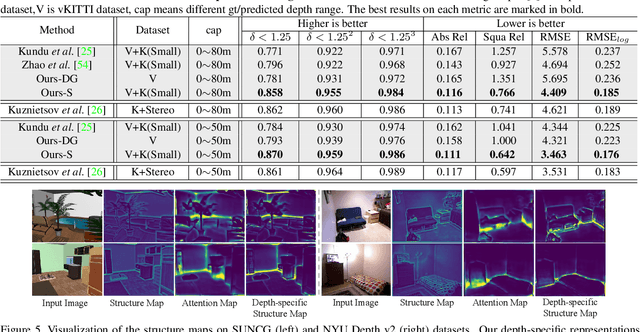
Human can infer the 3D geometry of a scene from a sketch instead of a realistic image, which indicates that the spatial structure plays a fundamental role in understanding the depth of scenes. We are the first to explore the learning of a depth-specific structural representation, which captures the essential feature for depth estimation and ignores irrelevant style information. Our S2R-DepthNet (Synthetic to Real DepthNet) can be well generalized to unseen real-world data directly even though it is only trained on synthetic data. S2R-DepthNet consists of: a) a Structure Extraction (STE) module which extracts a domaininvariant structural representation from an image by disentangling the image into domain-invariant structure and domain-specific style components, b) a Depth-specific Attention (DSA) module, which learns task-specific knowledge to suppress depth-irrelevant structures for better depth estimation and generalization, and c) a depth prediction module (DP) to predict depth from the depth-specific representation. Without access of any real-world images, our method even outperforms the state-of-the-art unsupervised domain adaptation methods which use real-world images of the target domain for training. In addition, when using a small amount of labeled real-world data, we achieve the state-ofthe-art performance under the semi-supervised setting.
2D3D-MatchNet: Learning to Match Keypoints Across 2D Image and 3D Point Cloud
Apr 22, 2019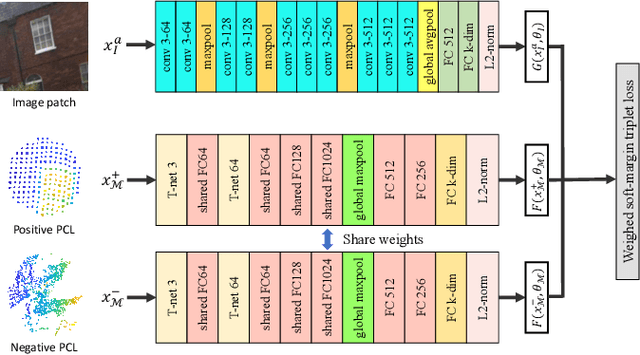
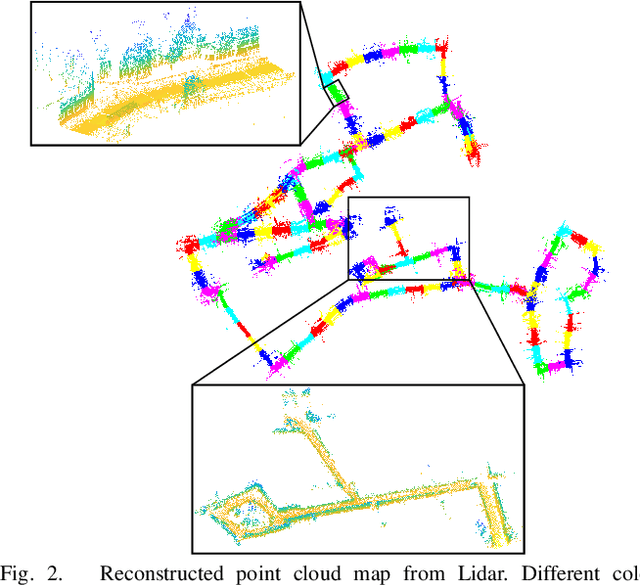

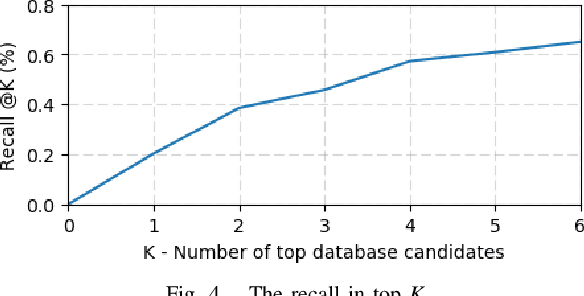
Large-scale point cloud generated from 3D sensors is more accurate than its image-based counterpart. However, it is seldom used in visual pose estimation due to the difficulty in obtaining 2D-3D image to point cloud correspondences. In this paper, we propose the 2D3D-MatchNet - an end-to-end deep network architecture to jointly learn the descriptors for 2D and 3D keypoint from image and point cloud, respectively. As a result, we are able to directly match and establish 2D-3D correspondences from the query image and 3D point cloud reference map for visual pose estimation. We create our Oxford 2D-3D Patches dataset from the Oxford Robotcar dataset with the ground truth camera poses and 2D-3D image to point cloud correspondences for training and testing the deep network. Experimental results verify the feasibility of our approach.
PasteGAN: A Semi-Parametric Method to Generate Image from Scene Graph
May 05, 2019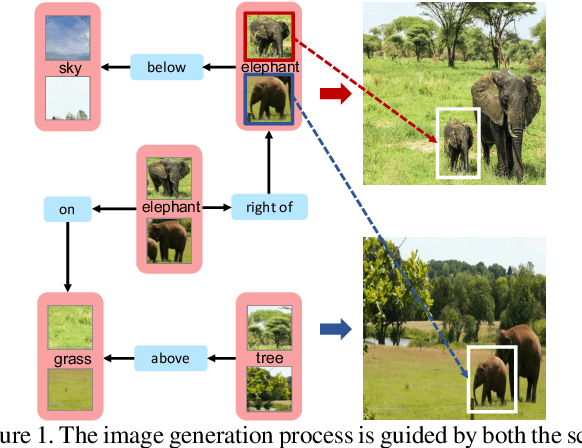
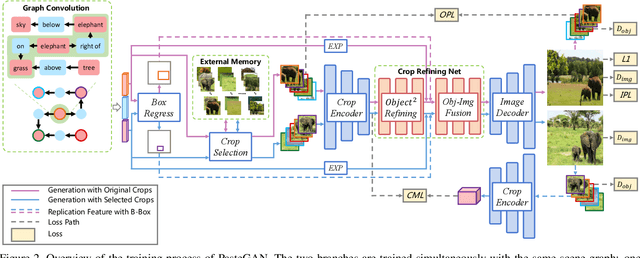
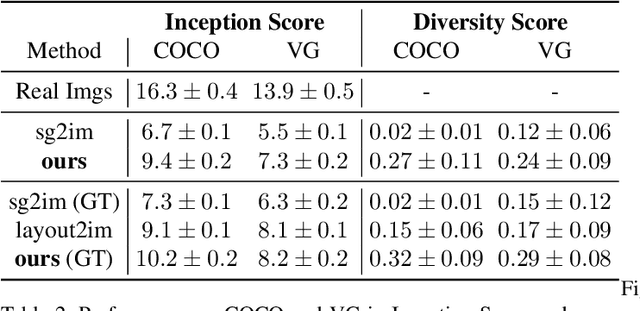
Despite some exciting progress on high-quality image generation from structured~(scene graphs) or free-form~(sentences) descriptions, most of them only guarantee the image-level semantical consistency, \ie the generated image matching the semantic meaning of the description. However, it still lacks the investigations on synthesizing the images in a more controllable way, like finely manipulating the visual appearance of every object. Therefore, to generate the images with preferred objects and rich interactions, we propose a semi-parametric method, denoted as PasteGAN, for generating the image from the scene graph, where spatial arrangements of the objects and their pair-wise relationships are defined by the scene graph and the object appearances are determined by given object crops. To enhance the interactions of the objects in the output, we design a Crop Refining Network to embed the objects as well as their relationships into one map. Multiple losses work collaboratively to guarantee the generated images highly respecting the crops and complying with the scene graphs while maintaining excellent image quality. A crop selector is also proposed to pick the most-compatible crops from our external object tank by encoding the interactions around the objects in the scene graph if the crops are not provided. Evaluated on Visual Genome and COCO-Stuff, our proposed method significantly outperforms the SOTA methods on both Inception Score and Diversity Score with a huge margin. Extensive experiments also demonstrate our method's ability to generate complex and diverse images with given objects.
JDSR-GAN: Constructing A Joint and Collaborative Learning Network for Masked Face Super-Resolution
Mar 25, 2021
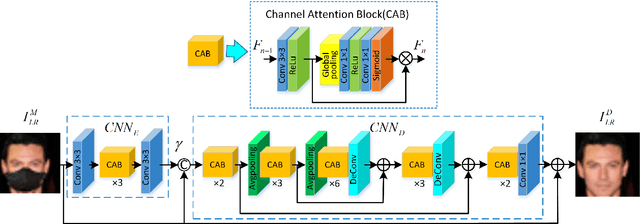

With the growing importance of preventing the COVID-19 virus, face images obtained in most video surveillance scenarios are low resolution with mask simultaneously. However, most of the previous face super-resolution solutions can not handle both tasks in one model. In this work, we treat the mask occlusion as image noise and construct a joint and collaborative learning network, called JDSR-GAN, for the masked face super-resolution task. Given a low-quality face image with the mask as input, the role of the generator composed of a denoising module and super-resolution module is to acquire a high-quality high-resolution face image. The discriminator utilizes some carefully designed loss functions to ensure the quality of the recovered face images. Moreover, we incorporate the identity information and attention mechanism into our network for feasible correlated feature expression and informative feature learning. By jointly performing denoising and face super-resolution, the two tasks can complement each other and attain promising performance. Extensive qualitative and quantitative results show the superiority of our proposed JDSR-GAN over some comparable methods which perform the previous two tasks separately.
Semantic Hierarchical Priors for Intrinsic Image Decomposition
Feb 11, 2019

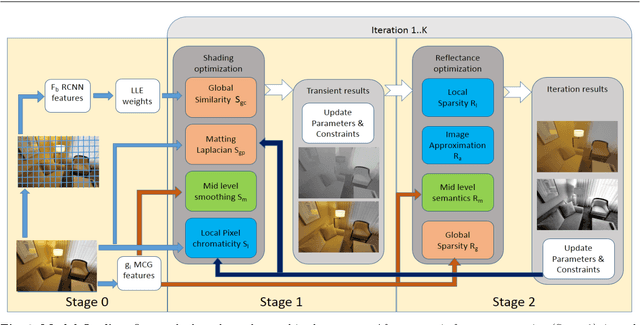

Intrinsic Image Decomposition (IID) is a challenging and interesting computer vision problem with various applications in several fields. We present novel semantic priors and an integrated approach for single image IID that involves analyzing image at three hierarchical context levels. Local context priors capture scene properties at each pixel within a small neighbourhood. Mid-level context priors encode object level semantics. Global context priors establish correspondences at the scene level. Our semantic priors are designed on both fixed and flexible regions, using selective search method and Convolutional Neural Network features. Our IID method is an iterative multistage optimization scheme and consists of two complementary formulations: $L_2$ smoothing for shading and $L_1$ sparsity for reflectance. Experiments and analysis of our method indicate the utility of our semantic priors and structured hierarchical analysis in an IID framework. We compare our method with other contemporary IID solutions and show results with lesser artifacts. Finally, we highlight that proper choice and encoding of prior knowledge can produce competitive results even when compared to end-to-end deep learning IID methods, signifying the importance of such priors. We believe that the insights and techniques presented in this paper would be useful in the future IID research.
To fit or not to fit: Model-based Face Reconstruction and Occlusion Segmentation from Weak Supervision
Jun 17, 2021


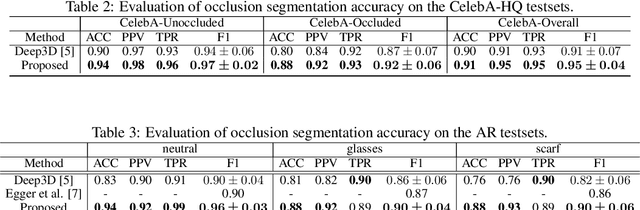
3D face reconstruction from a single image is challenging due to its ill-posed nature. Model-based face autoencoders address this issue effectively by fitting a face model to the target image in a weakly supervised manner. However, in unconstrained environments occlusions distort the face reconstruction because the model often erroneously tries to adapt to occluded face regions. Supervised occlusion segmentation is a viable solution to avoid the fitting of occluded face regions, but it requires a large amount of annotated training data. In this work, we enable model-based face autoencoders to segment occluders accurately without requiring any additional supervision during training, and this separates regions where the model will be fitted from those where it will not be fitted. To achieve this, we extend face autoencoders with a segmentation network. The segmentation network decides which regions the model should adapt to by reaching balances in a trade-off between including pixels and adapting the model to them, and excluding pixels so that the model fitting is not negatively affected and reaches higher overall reconstruction accuracy on pixels showing the face. This leads to a synergistic effect, in which the occlusion segmentation guides the training of the face autoencoder to constrain the fitting in the non-occluded regions, while the improved fitting enables the segmentation model to better predict the occluded face regions. Qualitative and quantitative experiments on the CelebA-HQ database and the AR database verify the effectiveness of our model in improving 3D face reconstruction under occlusions and in enabling accurate occlusion segmentation from weak supervision only. Code available at https://github.com/unibas-gravis/Occlusion-Robust-MoFA.