 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Drone Detection Using Convolutional Neural Networks
Jul 03, 2021

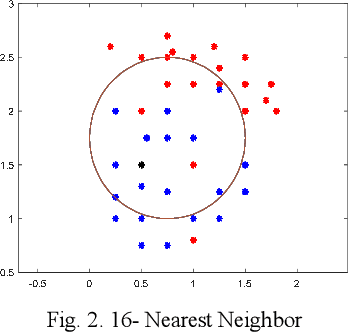

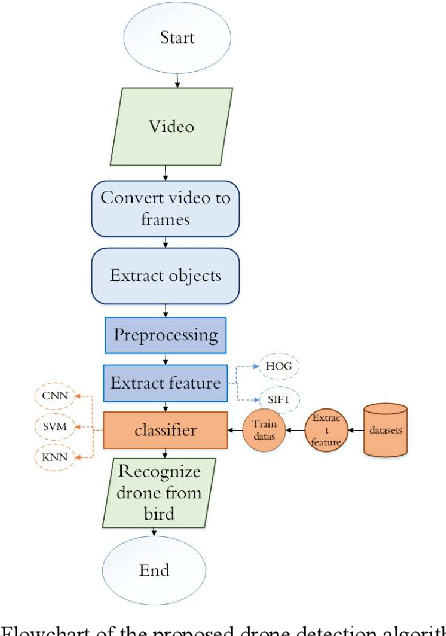
In image processing, it is essential to detect and track air targets, especially UAVs. In this paper, we detect the flying drone using a fisheye camera. In the field of diagnosis and classification of objects, there are always many problems that prevent the development of rapid and significant progress in this area. During the previous decades, a couple of advanced classification methods such as convolutional neural networks and support vector machines have been developed. In this study, the drone was detected using three methods of classification of convolutional neural network (CNN), support vector machine (SVM), and nearest neighbor. The outcomes show that CNN, SVM, and nearest neighbor have total accuracy of 95%, 88%, and 80%, respectively. Compared with other classifiers with the same experimental conditions, the accuracy of the convolutional neural network classifier is satisfactory.
Polyp-PVT: Polyp Segmentation with Pyramid Vision Transformers
Aug 16, 2021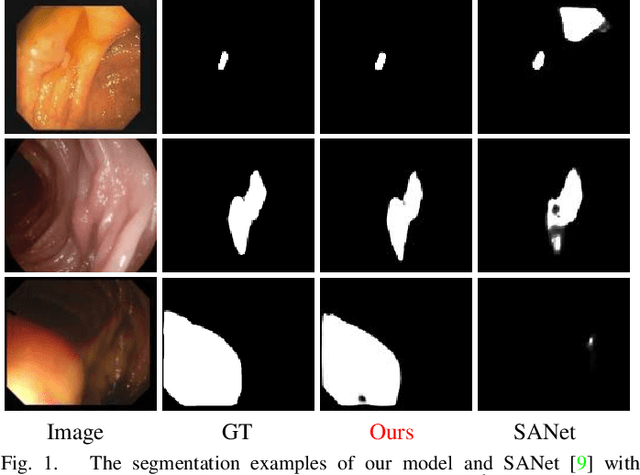
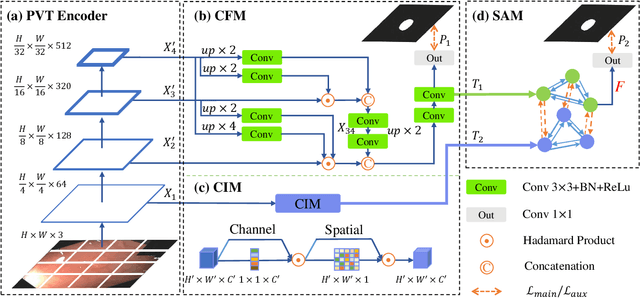
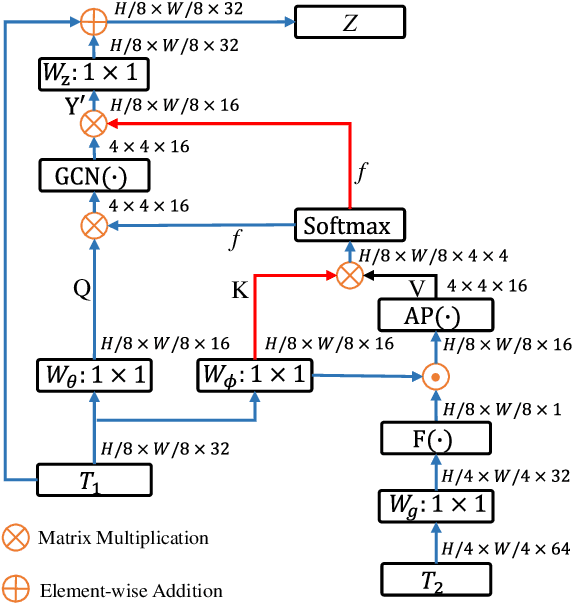
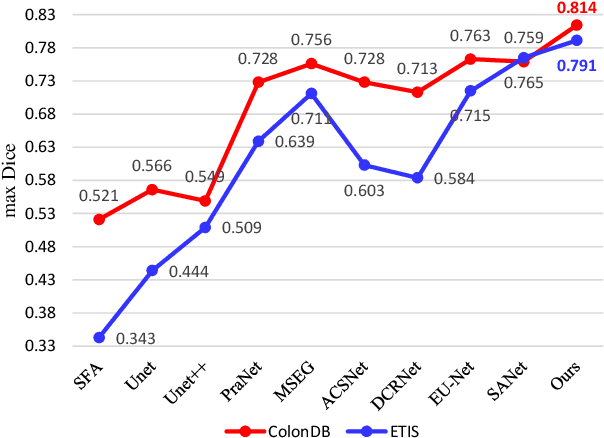
Most polyp segmentation methods use CNNs as their backbone, leading to two key issues when exchanging information between the encoder and decoder: 1) taking into account the differences in contribution between different-level features; and 2) designing effective mechanism for fusing these features. Different from existing CNN-based methods, we adopt a transformer encoder, which learns more powerful and robust representations. In addition, considering the image acquisition influence and elusive properties of polyps, we introduce three novel modules, including a cascaded fusion module (CFM), a camouflage identification module (CIM), a and similarity aggregation module (SAM). Among these, the CFM is used to collect the semantic and location information of polyps from high-level features, while the CIM is applied to capture polyp information disguised in low-level features. With the help of the SAM, we extend the pixel features of the polyp area with high-level semantic position information to the entire polyp area, thereby effectively fusing cross-level features. The proposed model, named \ourmodel, effectively suppresses noises in the features and significantly improves their expressive capabilities. Extensive experiments on five widely adopted datasets show that the proposed model is more robust to various challenging situations (e.g., appearance changes, small objects) than existing methods, and achieves the new state-of-the-art performance. The proposed model is available at https://github.com/DengPingFan/Polyp-PVT .
Compensation Learning
Jul 26, 2021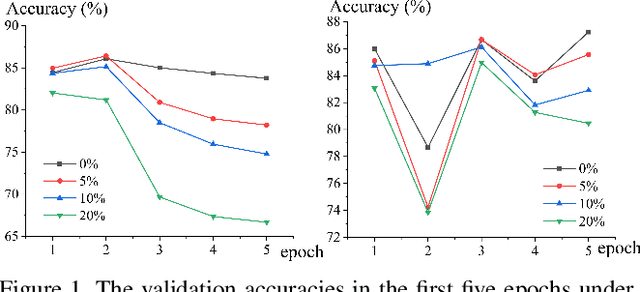
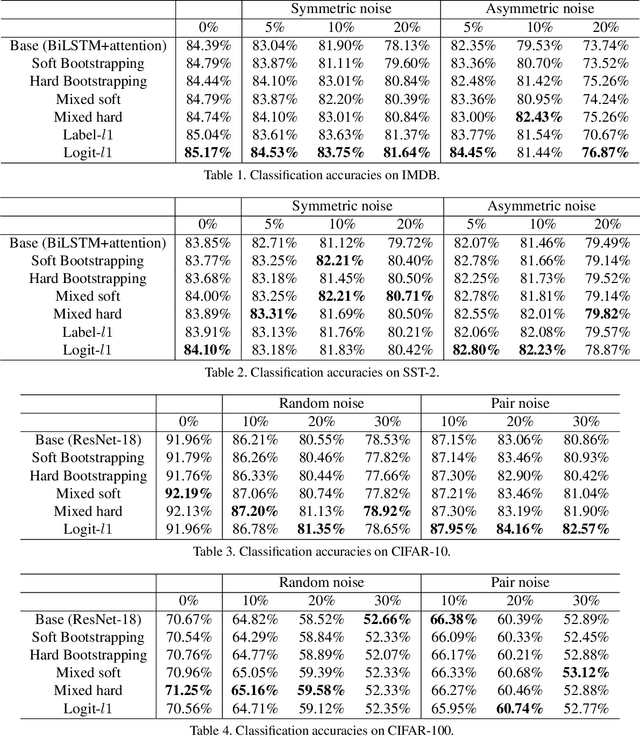
Weighting strategy prevails in machine learning. For example, a common approach in robust machine learning is to exert lower weights on samples which are likely to be noisy or hard. This study reveals another undiscovered strategy, namely, compensating, that has also been widely used in machine learning. Learning with compensating is called compensation learning and a systematic taxonomy is constructed for it in this study. In our taxonomy, compensation learning is divided on the basis of the compensation targets, inference manners, and granularity levels. Many existing learning algorithms including some classical ones can be seen as a special case of compensation learning or partially leveraging compensating. Furthermore, a family of new learning algorithms can be obtained by plugging the compensation learning into existing learning algorithms. Specifically, three concrete new learning algorithms are proposed for robust machine learning. Extensive experiments on text sentiment analysis, image classification, and graph classification verify the effectiveness of the three new algorithms. Compensation learning can also be used in various learning scenarios, such as imbalance learning, clustering, regression, and so on.
A novel statistical metric learning for hyperspectral image classification
May 13, 2019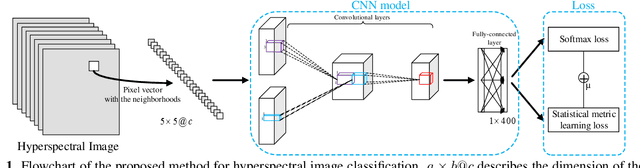
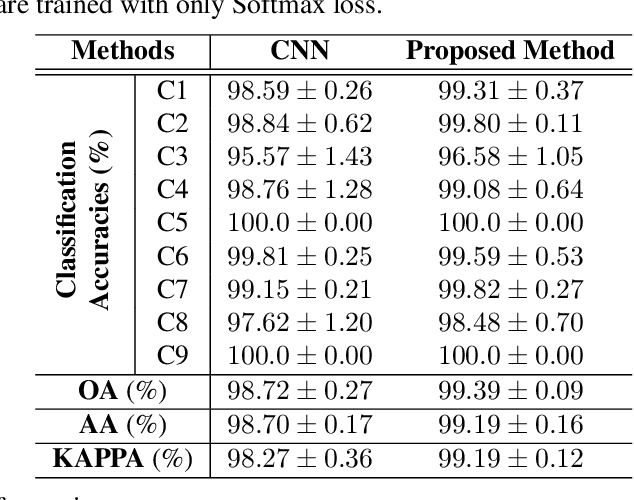

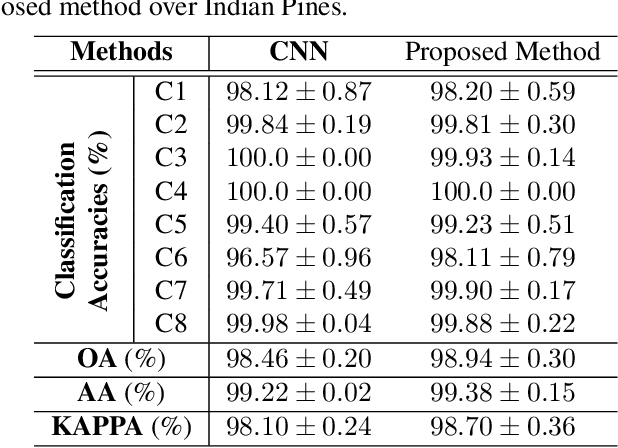
In this paper, a novel statistical metric learning is developed for spectral-spatial classification of the hyperspectral image. First, the standard variance of the samples of each class in each batch is used to decrease the intra-class variance within each class. Then, the distances between the means of different classes are used to penalize the inter-class variance of the training samples. Finally, the standard variance between the means of different classes is added as an additional diversity term to repulse different classes from each other. Experiments have conducted over two real-world hyperspectral image datasets and the experimental results have shown the effectiveness of the proposed statistical metric learning.
Co$^2$L: Contrastive Continual Learning
Jun 28, 2021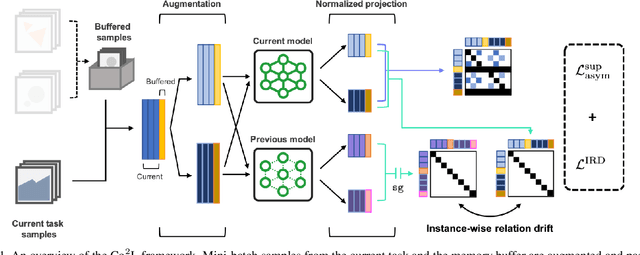
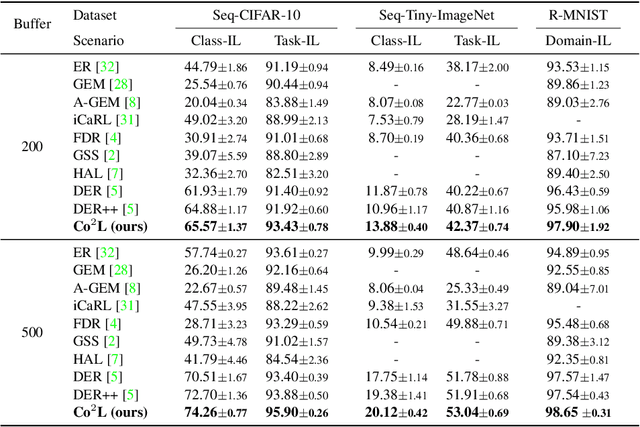
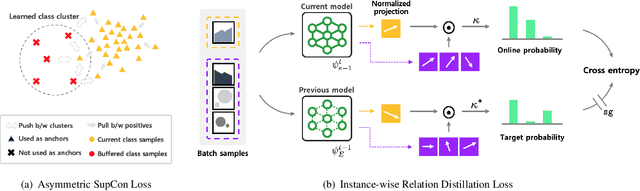
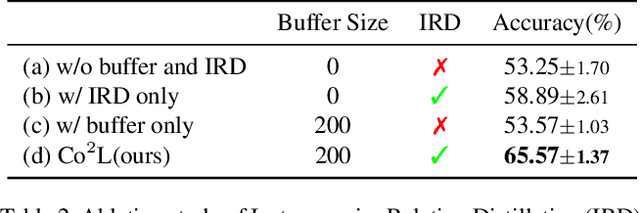
Recent breakthroughs in self-supervised learning show that such algorithms learn visual representations that can be transferred better to unseen tasks than joint-training methods relying on task-specific supervision. In this paper, we found that the similar holds in the continual learning con-text: contrastively learned representations are more robust against the catastrophic forgetting than jointly trained representations. Based on this novel observation, we propose a rehearsal-based continual learning algorithm that focuses on continually learning and maintaining transferable representations. More specifically, the proposed scheme (1) learns representations using the contrastive learning objective, and (2) preserves learned representations using a self-supervised distillation step. We conduct extensive experimental validations under popular benchmark image classification datasets, where our method sets the new state-of-the-art performance.
Generative Art Using Neural Visual Grammars and Dual Encoders
May 04, 2021


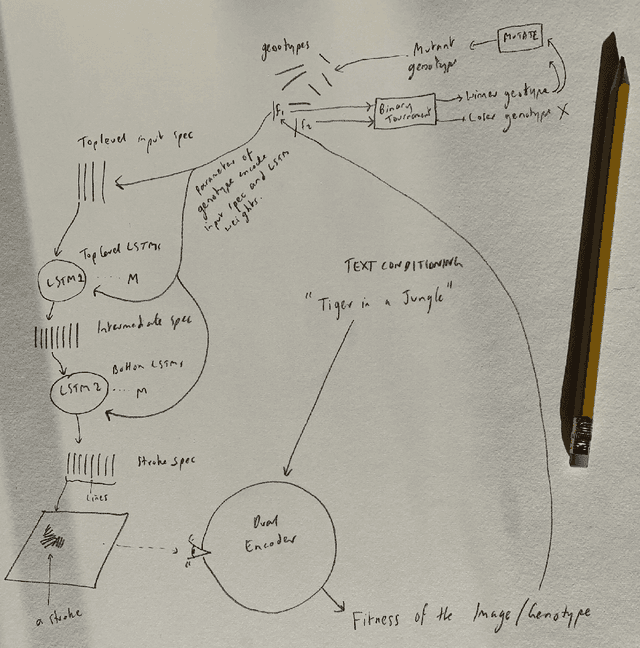
Whilst there are perhaps only a few scientific methods, there seem to be almost as many artistic methods as there are artists. Artistic processes appear to inhabit the highest order of open-endedness. To begin to understand some of the processes of art making it is helpful to try to automate them even partially. In this paper, a novel algorithm for producing generative art is described which allows a user to input a text string, and which in a creative response to this string, outputs an image which interprets that string. It does so by evolving images using a hierarchical neural Lindenmeyer system, and evaluating these images along the way using an image text dual encoder trained on billions of images and their associated text from the internet. In doing so we have access to and control over an instance of an artistic process, allowing analysis of which aspects of the artistic process become the task of the algorithm, and which elements remain the responsibility of the artist.
Deep Direct Volume Rendering: Learning Visual Feature Mappings From Exemplary Images
Jun 09, 2021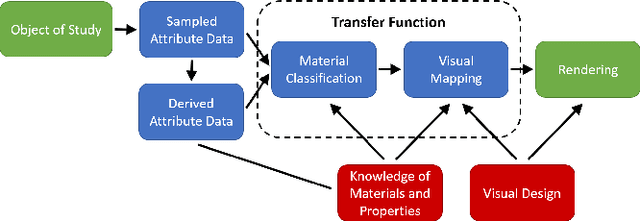
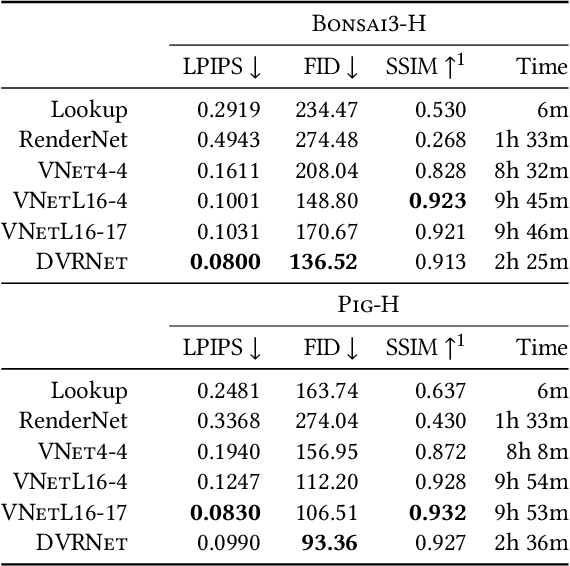
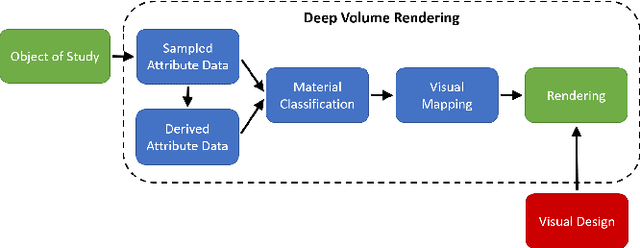
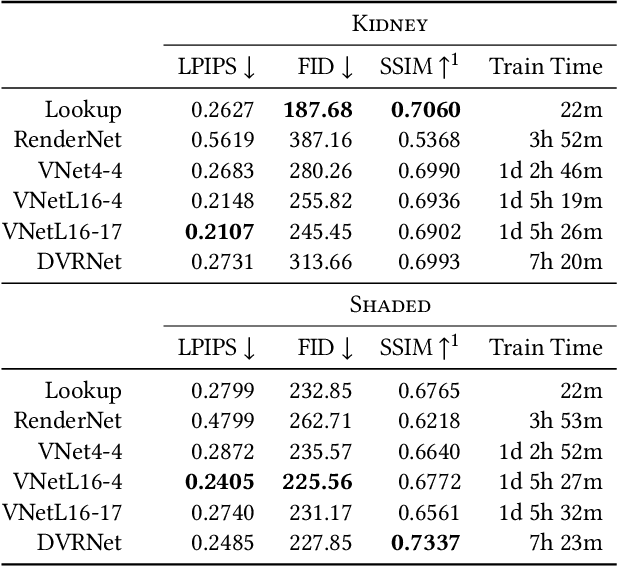
Volume Rendering is an important technique for visualizing three-dimensional scalar data grids and is commonly employed for scientific and medical image data. Direct Volume Rendering (DVR) is a well established and efficient rendering algorithm for volumetric data. Neural rendering uses deep neural networks to solve inverse rendering tasks and applies techniques similar to DVR. However, it has not been demonstrated successfully for the rendering of scientific volume data. In this work, we introduce Deep Direct Volume Rendering (DeepDVR), a generalization of DVR that allows for the integration of deep neural networks into the DVR algorithm. We conceptualize the rendering in a latent color space, thus enabling the use of deep architectures to learn implicit mappings for feature extraction and classification, replacing explicit feature design and hand-crafted transfer functions. Our generalization serves to derive novel volume rendering architectures that can be trained end-to-end directly from examples in image space, obviating the need to manually define and fine-tune multidimensional transfer functions while providing superior classification strength. We further introduce a novel stepsize annealing scheme to accelerate the training of DeepDVR models and validate its effectiveness in a set of experiments. We validate our architectures on two example use cases: (1) learning an optimized rendering from manually adjusted reference images for a single volume and (2) learning advanced visualization concepts like shading and semantic colorization that generalize to unseen volume data. We find that deep volume rendering architectures with explicit modeling of the DVR pipeline effectively enable end-to-end learning of scientific volume rendering tasks from target images.
Hybrid Loss for Learning Single-Image-based HDR Reconstruction
Dec 18, 2018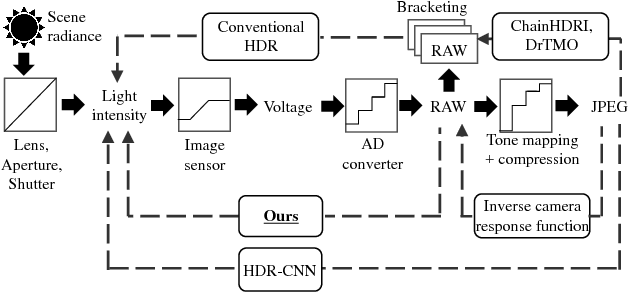
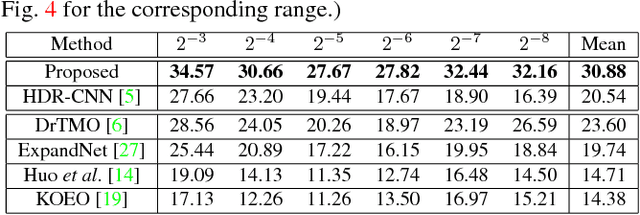
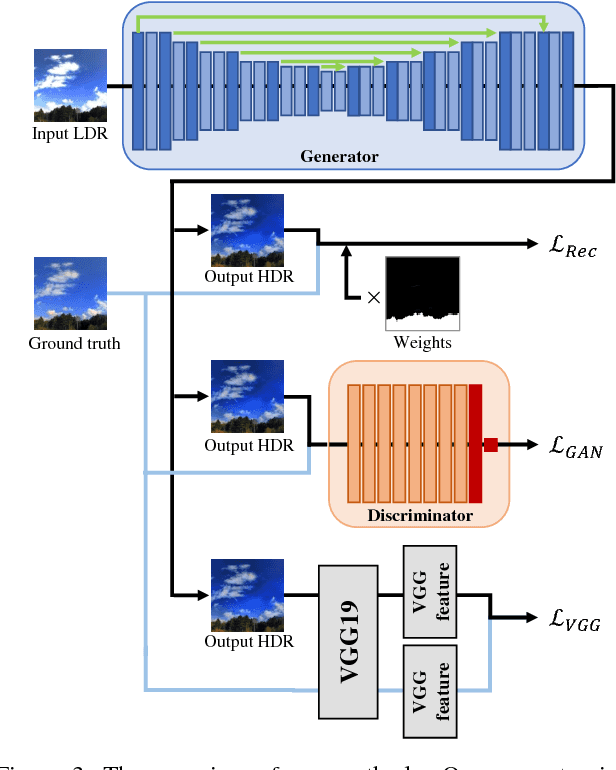
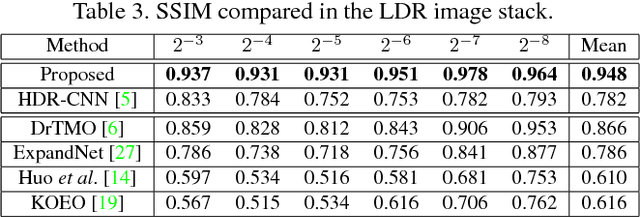
This paper tackles high-dynamic-range (HDR) image reconstruction given only a single low-dynamic-range (LDR) image as input. While the existing methods focus on minimizing the mean-squared-error (MSE) between the target and reconstructed images, we minimize a hybrid loss that consists of perceptual and adversarial losses in addition to HDR-reconstruction loss. The reconstruction loss instead of MSE is more suitable for HDR since it puts more weight on both over- and under- exposed areas. It makes the reconstruction faithful to the input. Perceptual loss enables the networks to utilize knowledge about objects and image structure for recovering the intensity gradients of saturated and grossly quantized areas. Adversarial loss helps to select the most plausible appearance from multiple solutions. The hybrid loss that combines all the three losses is calculated in logarithmic space of image intensity so that the outputs retain a large dynamic range and meanwhile the learning becomes tractable. Comparative experiments conducted with other state-of-the-art methods demonstrated that our method produces a leap in image quality.
A Vision-based Irregular Obstacle Avoidance Framework via Deep Reinforcement Learning
Aug 16, 2021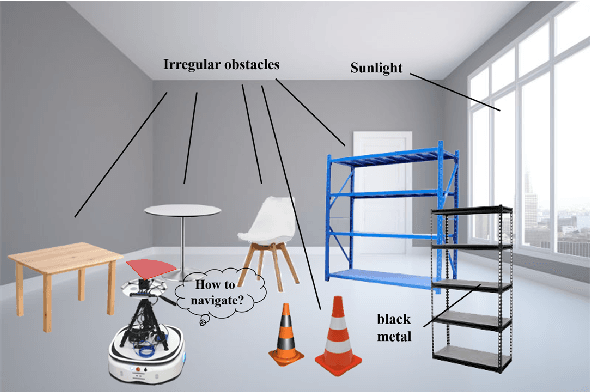
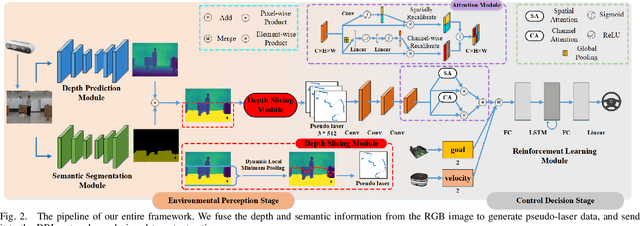

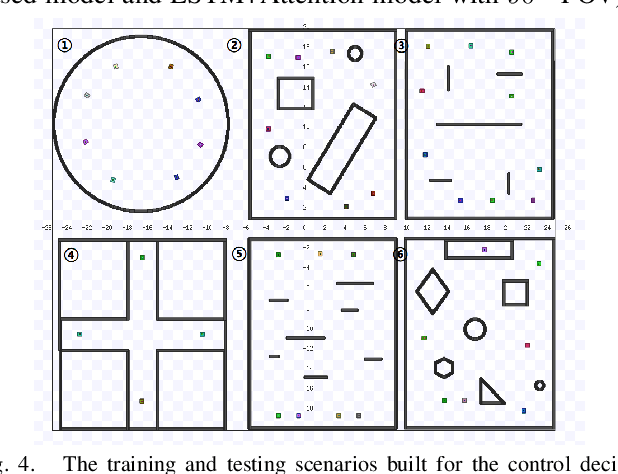
Deep reinforcement learning has achieved great success in laser-based collision avoidance work because the laser can sense accurate depth information without too much redundant data, which can maintain the robustness of the algorithm when it is migrated from the simulation environment to the real world. However, high-cost laser devices are not only difficult to apply on a large scale but also have poor robustness to irregular objects, e.g., tables, chairs, shelves, etc. In this paper, we propose a vision-based collision avoidance framework to solve the challenging problem. Our method attempts to estimate the depth and incorporate the semantic information from RGB data to obtain a new form of data, pseudo-laser data, which combines the advantages of visual information and laser information. Compared to traditional laser data that only contains the one-dimensional distance information captured at a certain height, our proposed pseudo-laser data encodes the depth information and semantic information within the image, which makes our method more effective for irregular obstacles. Besides, we adaptively add noise to the laser data during the training stage to increase the robustness of our model in the real world, due to the estimated depth information is not accurate. Experimental results show that our framework achieves state-of-the-art performance in several unseen virtual and real-world scenarios.
Collapsible Linear Blocks for Super-Efficient Super Resolution
Mar 17, 2021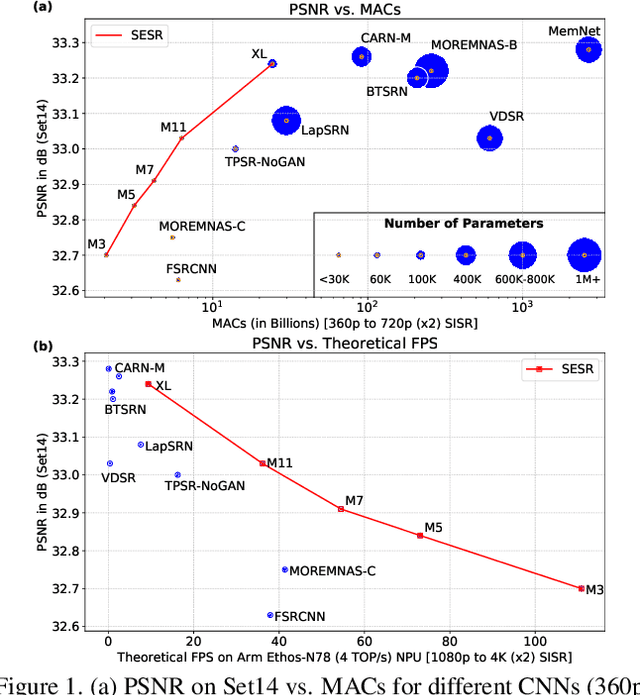
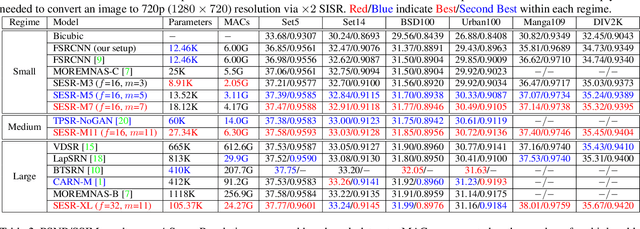
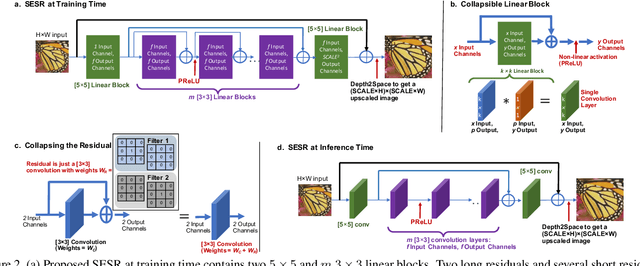
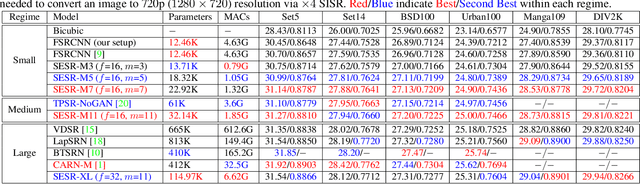
With the advent of smart devices that support 4K and 8K resolution, Single Image Super Resolution (SISR) has become an important computer vision problem. However, most super resolution deep networks are computationally very expensive. In this paper, we propose SESR, a new class of Super-Efficient Super Resolution networks that significantly improve image quality and reduce computational complexity. Detailed experiments across six benchmark datasets demonstrate that SESR achieves similar or better image quality than state-of-the-art models while requiring 2x to 330x fewer Multiply-Accumulate (MAC) operations. As a result, SESR can be used on constrained hardware to perform x2 (1080p to 4K) and x4 SISR (1080p to 8K). Towards this, we simulate hardware performance numbers for a commercial mobile Neural Processing Unit (NPU) for 1080p to 4K (x2) and 1080p to 8K (x4) SISR. Our results highlight the challenges faced by super resolution on AI accelerators and demonstrate that SESR is significantly faster than existing models. Overall, SESR establishes a new Pareto frontier on the quality (PSNR)-computation relationship for the super resolution task.