 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Intrinsic Image Transformation via Scale Space Decomposition
May 25, 2018
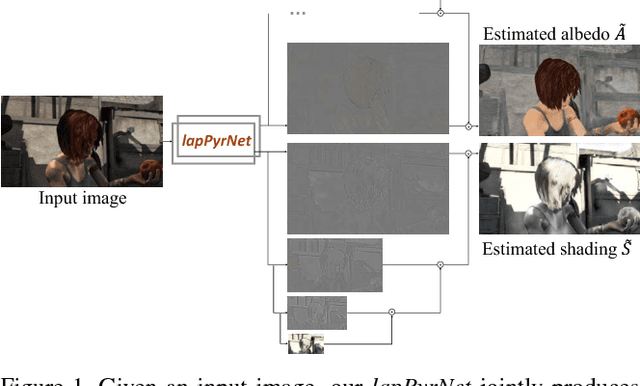
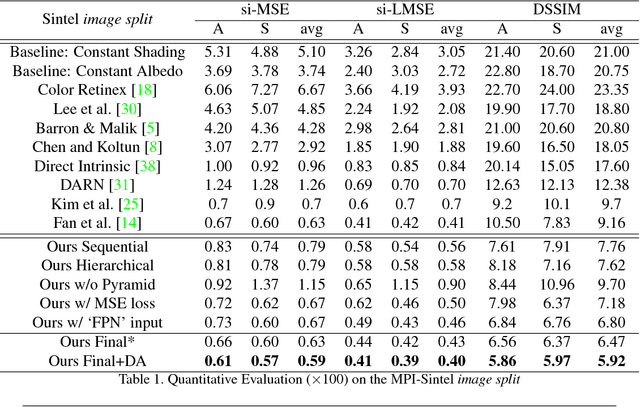
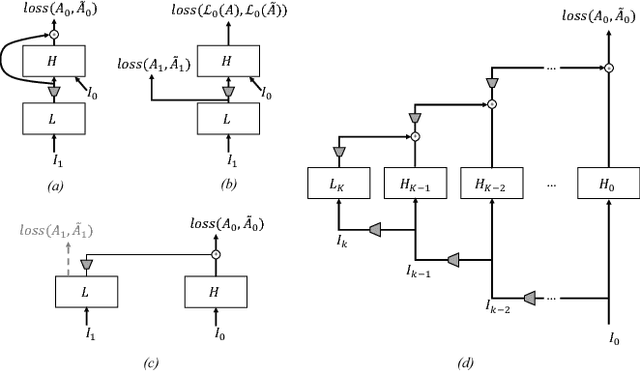
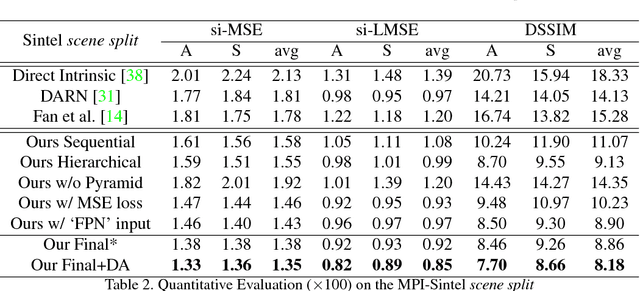
We introduce a new network structure for decomposing an image into its intrinsic albedo and shading. We treat this as an image-to-image transformation problem and explore the scale space of the input and output. By expanding the output images (albedo and shading) into their Laplacian pyramid components, we develop a multi-channel network structure that learns the image-to-image transformation function in successive frequency bands in parallel, within each channel is a fully convolutional neural network with skip connections. This network structure is general and extensible, and has demonstrated excellent performance on the intrinsic image decomposition problem. We evaluate the network on two benchmark datasets: the MPI-Sintel dataset and the MIT Intrinsic Images dataset. Both quantitative and qualitative results show our model delivers a clear progression over state-of-the-art.
RFN-Nest: An end-to-end residual fusion network for infrared and visible images
Mar 07, 2021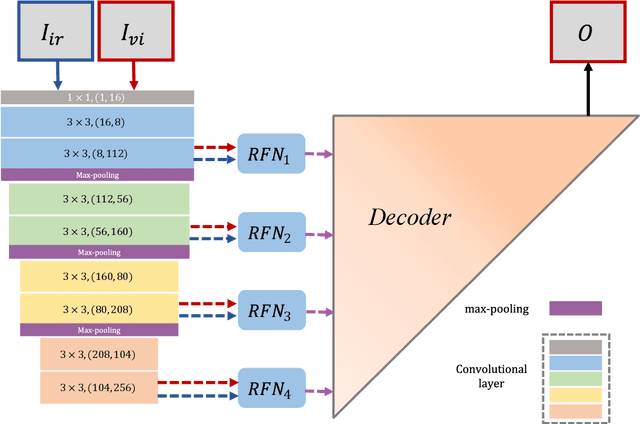
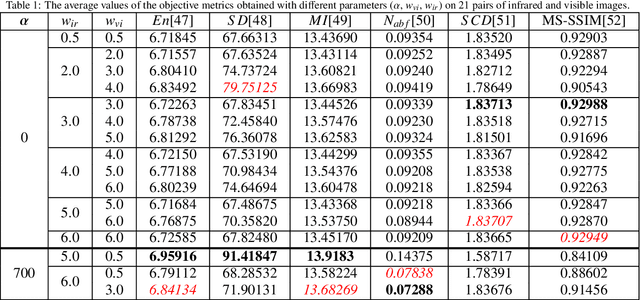
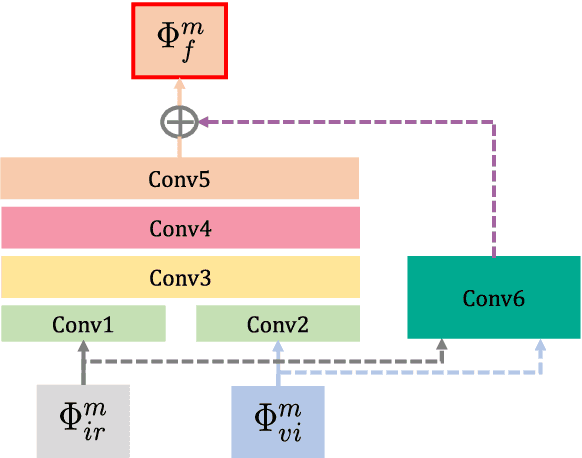

In the image fusion field, the design of deep learning-based fusion methods is far from routine. It is invariably fusion-task specific and requires a careful consideration. The most difficult part of the design is to choose an appropriate strategy to generate the fused image for a specific task in hand. Thus, devising learnable fusion strategy is a very challenging problem in the community of image fusion. To address this problem, a novel end-to-end fusion network architecture (RFN-Nest) is developed for infrared and visible image fusion. We propose a residual fusion network (RFN) which is based on a residual architecture to replace the traditional fusion approach. A novel detail-preserving loss function, and a feature enhancing loss function are proposed to train RFN. The fusion model learning is accomplished by a novel two-stage training strategy. In the first stage, we train an auto-encoder based on an innovative nest connection (Nest) concept. Next, the RFN is trained using the proposed loss functions. The experimental results on public domain data sets show that, compared with the existing methods, our end-to-end fusion network delivers a better performance than the state-of-the-art methods in both subjective and objective evaluation. The code of our fusion method is available at https://github.com/hli1221/imagefusion-rfn-nest
Convergence of Deep ReLU Networks
Jul 27, 2021We explore convergence of deep neural networks with the popular ReLU activation function, as the depth of the networks tends to infinity. To this end, we introduce the notion of activation domains and activation matrices of a ReLU network. By replacing applications of the ReLU activation function by multiplications with activation matrices on activation domains, we obtain an explicit expression of the ReLU network. We then identify the convergence of the ReLU networks as convergence of a class of infinite products of matrices. Sufficient and necessary conditions for convergence of these infinite products of matrices are studied. As a result, we establish necessary conditions for ReLU networks to converge that the sequence of weight matrices converges to the identity matrix and the sequence of the bias vectors converges to zero as the depth of ReLU networks increases to infinity. Moreover, we obtain sufficient conditions in terms of the weight matrices and bias vectors at hidden layers for pointwise convergence of deep ReLU networks. These results provide mathematical insights to the design strategy of the well-known deep residual networks in image classification.
Meta-repository of screening mammography classifiers
Aug 10, 2021
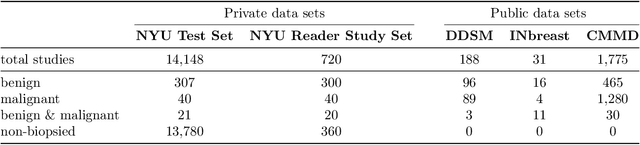
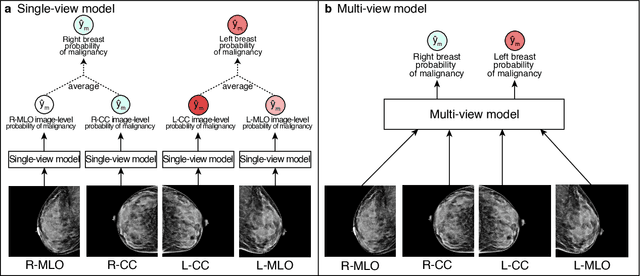
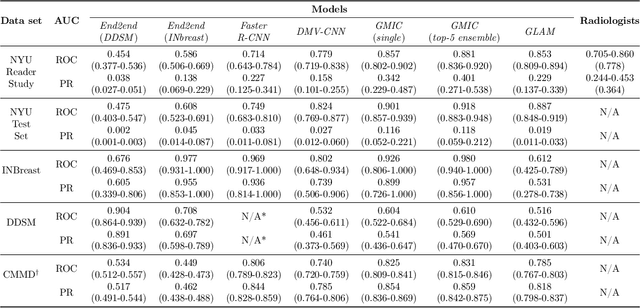
Artificial intelligence (AI) is transforming medicine and showing promise in improving clinical diagnosis. In breast cancer screening, several recent studies show that AI has the potential to improve radiologists' accuracy, subsequently helping in early cancer diagnosis and reducing unnecessary workup. As the number of proposed models and their complexity grows, it is becoming increasingly difficult to re-implement them in order to reproduce the results and to compare different approaches. To enable reproducibility of research in this application area and to enable comparison between different methods, we release a meta-repository containing deep learning models for classification of screening mammograms. This meta-repository creates a framework that enables the evaluation of machine learning models on any private or public screening mammography data set. At its inception, our meta-repository contains five state-of-the-art models with open-source implementations and cross-platform compatibility. We compare their performance on five international data sets: two private New York University breast cancer screening data sets as well as three public (DDSM, INbreast and Chinese Mammography Database) data sets. Our framework has a flexible design that can be generalized to other medical image analysis tasks. The meta-repository is available at https://www.github.com/nyukat/mammography_metarepository.
End-to-End Learning Using Cycle Consistency for Image-to-Caption Transformations
Mar 25, 2019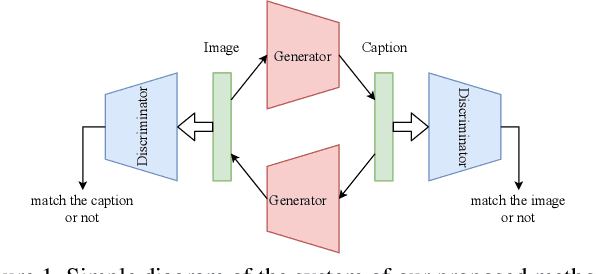
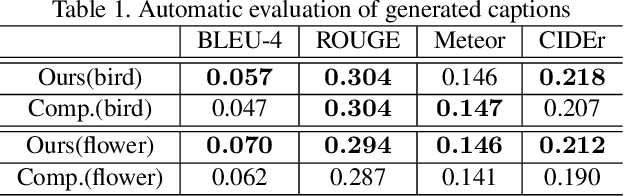
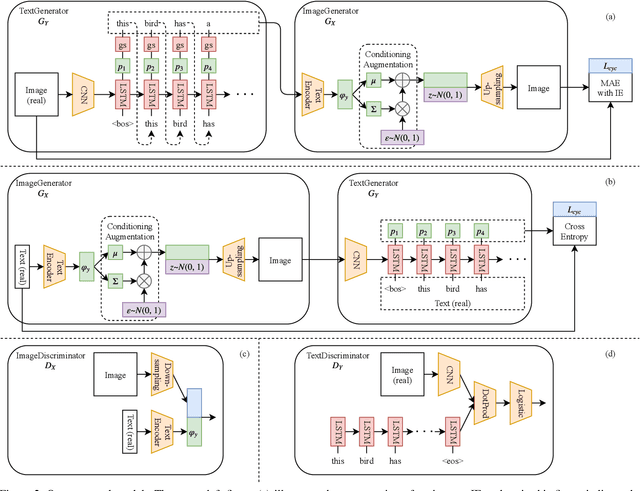
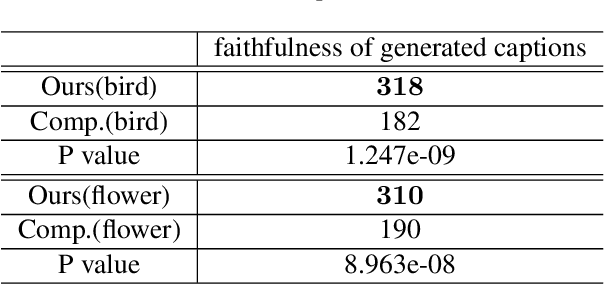
So far, research to generate captions from images has been carried out from the viewpoint that a caption holds sufficient information for an image. If it is possible to generate an image that is close to the input image from a generated caption, i.e., if it is possible to generate a natural language caption containing sufficient information to reproduce the image, then the caption is considered to be faithful to the image. To make such regeneration possible, learning using the cycle-consistency loss is effective. In this study, we propose a method of generating captions by learning end-to-end mutual transformations between images and texts. To evaluate our method, we perform comparative experiments with and without the cycle consistency. The results are evaluated by an automatic evaluation and crowdsourcing, demonstrating that our proposed method is effective.
S2R-DepthNet: Learning a Generalizable Depth-specific Structural Representation
Apr 02, 2021
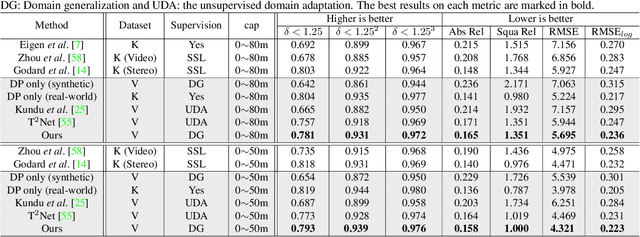
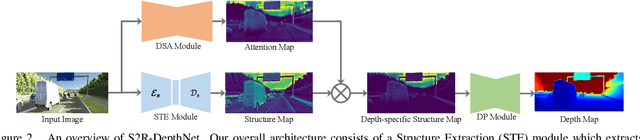
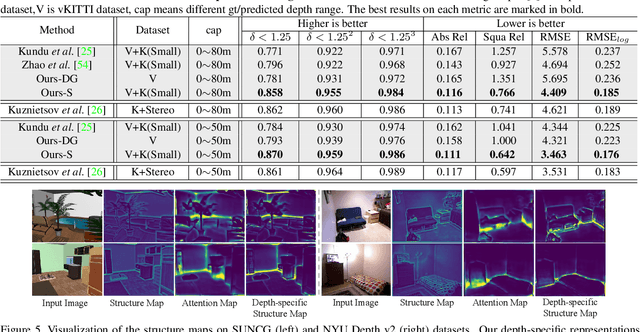
Human can infer the 3D geometry of a scene from a sketch instead of a realistic image, which indicates that the spatial structure plays a fundamental role in understanding the depth of scenes. We are the first to explore the learning of a depth-specific structural representation, which captures the essential feature for depth estimation and ignores irrelevant style information. Our S2R-DepthNet (Synthetic to Real DepthNet) can be well generalized to unseen real-world data directly even though it is only trained on synthetic data. S2R-DepthNet consists of: a) a Structure Extraction (STE) module which extracts a domaininvariant structural representation from an image by disentangling the image into domain-invariant structure and domain-specific style components, b) a Depth-specific Attention (DSA) module, which learns task-specific knowledge to suppress depth-irrelevant structures for better depth estimation and generalization, and c) a depth prediction module (DP) to predict depth from the depth-specific representation. Without access of any real-world images, our method even outperforms the state-of-the-art unsupervised domain adaptation methods which use real-world images of the target domain for training. In addition, when using a small amount of labeled real-world data, we achieve the state-ofthe-art performance under the semi-supervised setting.
Inductive Guided Filter: Real-time Deep Image Matting with Weakly Annotated Masks on Mobile Devices
May 16, 2019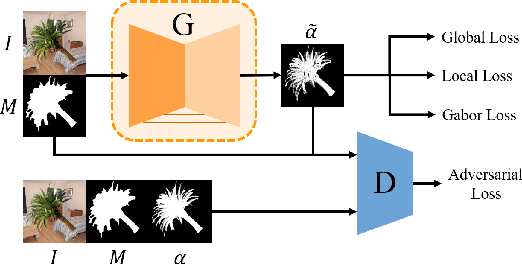
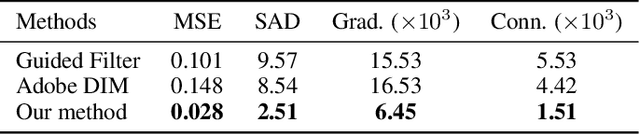
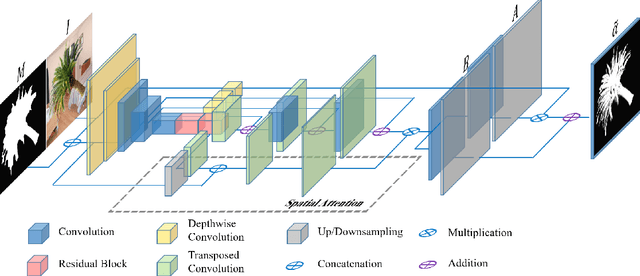
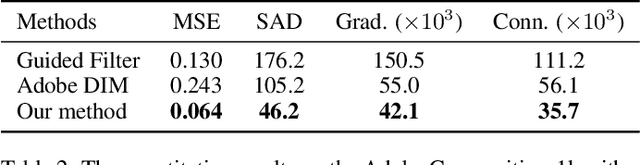
Recently, significant progress has been achieved in deep image matting. Most of the classical image matting methods are time-consuming and require an ideal trimap which is difficult to attain in practice. A high efficient image matting method based on a weakly annotated mask is in demand for mobile applications. In this paper, we propose a novel method based on Deep Learning and Guided Filter, called Inductive Guided Filter, which can tackle the real-time general image matting task on mobile devices. We design a lightweight hourglass network to parameterize the original Guided Filter method that takes an image and a weakly annotated mask as input. Further, the use of Gabor loss is proposed for training networks for complicated textures in image matting. Moreover, we create an image matting dataset MAT-2793 with a variety of foreground objects. Experimental results demonstrate that our proposed method massively reduces running time with robust accuracy.
Image Captioning at Will: A Versatile Scheme for Effectively Injecting Sentiments into Image Descriptions
Jan 30, 2018
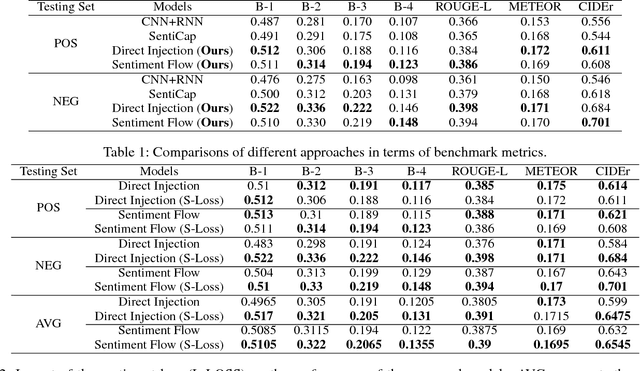
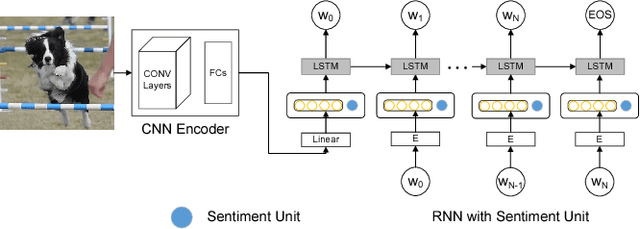
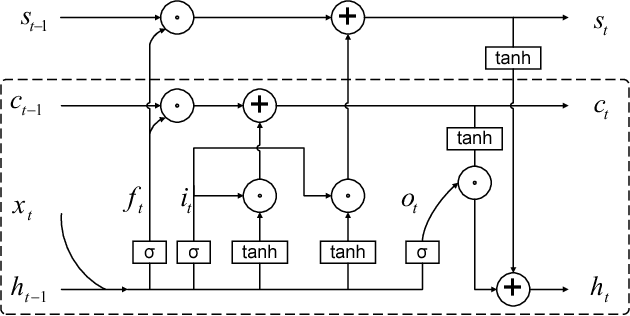
Automatic image captioning has recently approached human-level performance due to the latest advances in computer vision and natural language understanding. However, most of the current models can only generate plain factual descriptions about the content of a given image. However, for human beings, image caption writing is quite flexible and diverse, where additional language dimensions, such as emotion, humor and language styles, are often incorporated to produce diverse, emotional, or appealing captions. In particular, we are interested in generating sentiment-conveying image descriptions, which has received little attention. The main challenge is how to effectively inject sentiments into the generated captions without altering the semantic matching between the visual content and the generated descriptions. In this work, we propose two different models, which employ different schemes for injecting sentiments into image captions. Compared with the few existing approaches, the proposed models are much simpler and yet more effective. The experimental results show that our model outperform the state-of-the-art models in generating sentimental (i.e., sentiment-bearing) image captions. In addition, we can also easily manipulate the model by assigning different sentiments to the testing image to generate captions with the corresponding sentiments.
Semantic-embedded Unsupervised Spectral Reconstruction from Single RGB Images in the Wild
Aug 17, 2021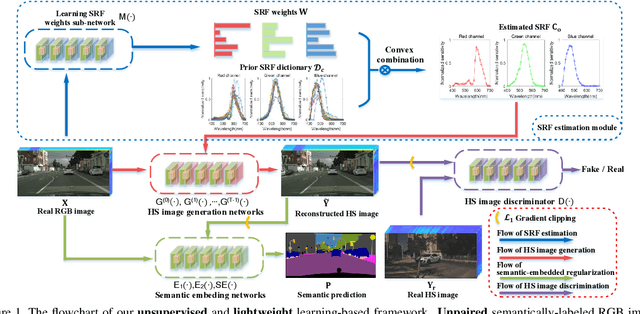
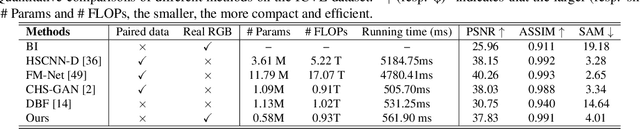

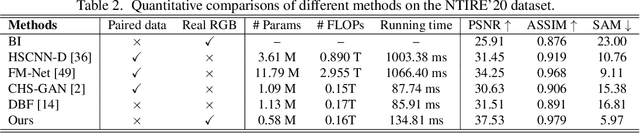
This paper investigates the problem of reconstructing hyperspectral (HS) images from single RGB images captured by commercial cameras, \textbf{without} using paired HS and RGB images during training. To tackle this challenge, we propose a new lightweight and end-to-end learning-based framework. Specifically, on the basis of the intrinsic imaging degradation model of RGB images from HS images, we progressively spread the differences between input RGB images and re-projected RGB images from recovered HS images via effective unsupervised camera spectral response function estimation. To enable the learning without paired ground-truth HS images as supervision, we adopt the adversarial learning manner and boost it with a simple yet effective $\mathcal{L}_1$ gradient clipping scheme. Besides, we embed the semantic information of input RGB images to locally regularize the unsupervised learning, which is expected to promote pixels with identical semantics to have consistent spectral signatures. In addition to conducting quantitative experiments over two widely-used datasets for HS image reconstruction from synthetic RGB images, we also evaluate our method by applying recovered HS images from real RGB images to HS-based visual tracking. Extensive results show that our method significantly outperforms state-of-the-art unsupervised methods and even exceeds the latest supervised method under some settings. The source code is public available at https://github.com/zbzhzhy/Unsupervised-Spectral-Reconstruction.
se(3)-TrackNet: Data-driven 6D Pose Tracking by Calibrating Image Residuals in Synthetic Domains
Jul 27, 2020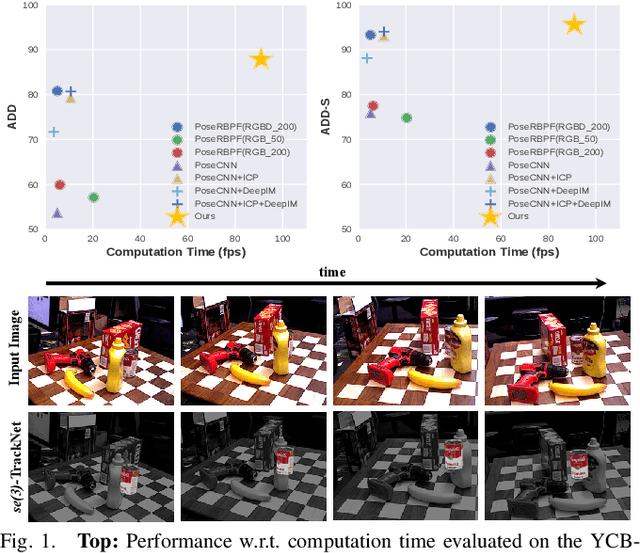
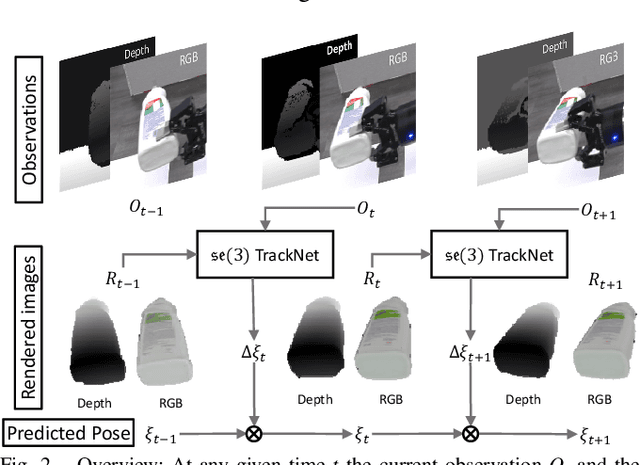
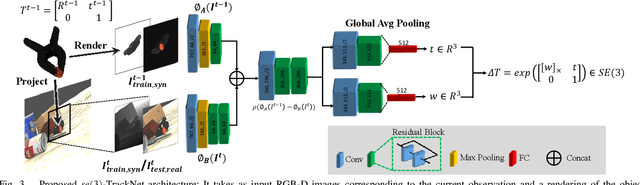

Tracking the 6D pose of objects in video sequences is important for robot manipulation. This task, however, introduces multiple challenges: (i) robot manipulation involves significant occlusions; (ii) data and annotations are troublesome and difficult to collect for 6D poses, which complicates machine learning solutions, and (iii) incremental error drift often accumulates in long term tracking to necessitate re-initialization of the object's pose. This work proposes a data-driven optimization approach for long-term, 6D pose tracking. It aims to identify the optimal relative pose given the current RGB-D observation and a synthetic image conditioned on the previous best estimate and the object's model. The key contribution in this context is a novel neural network architecture, which appropriately disentangles the feature encoding to help reduce domain shift, and an effective 3D orientation representation via Lie Algebra. Consequently, even when the network is trained only with synthetic data can work effectively over real images. Comprehensive experiments over benchmarks - existing ones as well as a new dataset with significant occlusions related to object manipulation - show that the proposed approach achieves consistently robust estimates and outperforms alternatives, even though they have been trained with real images. The approach is also the most computationally efficient among the alternatives and achieves a tracking frequency of 90.9Hz.