 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Image Segmentation Model Based on a Variational Formulation
Oct 13, 2019
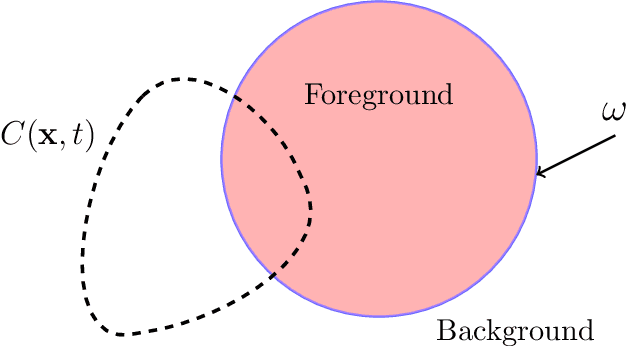

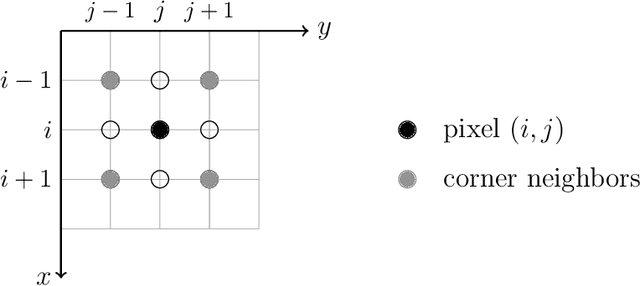

Starting from a variational formulation, we present a model for image segmentation that employs both region statistics and edge information. This combination allows for improved flexibility, making the proposed model suitable to process a wider class of images than purely region-based and edge-based models. We perform several simulations with real images that attest to the versatility of the model. We also show another set of experiments on images with certain pathologies that suggest opportunities for improvement.
Knowledge Distillation Using Hierarchical Self-Supervision Augmented Distribution
Sep 07, 2021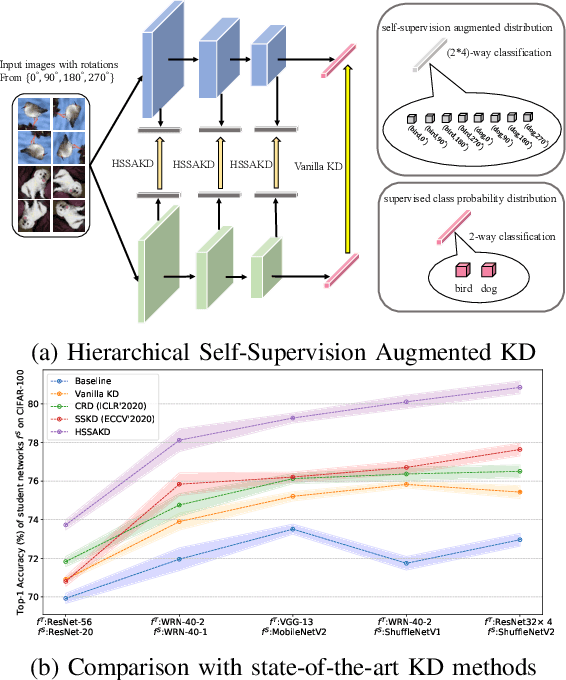
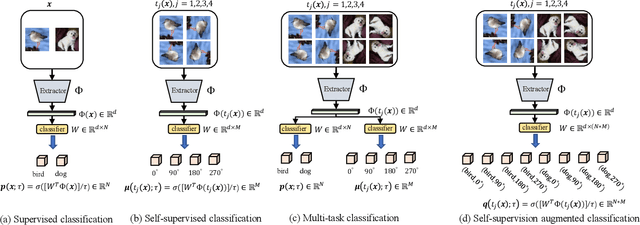
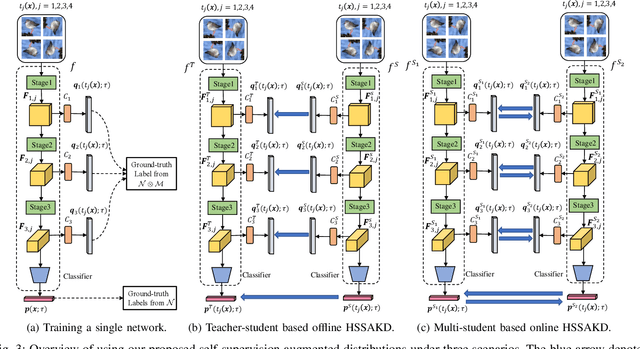

Knowledge distillation (KD) is an effective framework that aims to transfer meaningful information from a large teacher to a smaller student. Generally, KD often involves how to define and transfer knowledge. Previous KD methods often focus on mining various forms of knowledge, for example, feature maps and refined information. However, the knowledge is derived from the primary supervised task and thus is highly task-specific. Motivated by the recent success of self-supervised representation learning, we propose an auxiliary self-supervision augmented task to guide networks to learn more meaningful features. Therefore, we can derive soft self-supervision augmented distributions as richer dark knowledge from this task for KD. Unlike previous knowledge, this distribution encodes joint knowledge from supervised and self-supervised feature learning. Beyond knowledge exploration, another crucial aspect is how to learn and distill our proposed knowledge effectively. To fully take advantage of hierarchical feature maps, we propose to append several auxiliary branches at various hidden layers. Each auxiliary branch is guided to learn self-supervision augmented task and distill this distribution from teacher to student. Thus we call our KD method as Hierarchical Self-Supervision Augmented Knowledge Distillation (HSSAKD). Experiments on standard image classification show that both offline and online HSSAKD achieves state-of-the-art performance in the field of KD. Further transfer experiments on object detection further verify that HSSAKD can guide the network to learn better features, which can be attributed to learn and distill an auxiliary self-supervision augmented task effectively.
Pyramid Real Image Denoising Network
Aug 01, 2019
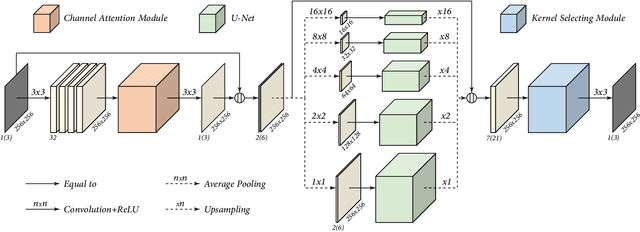
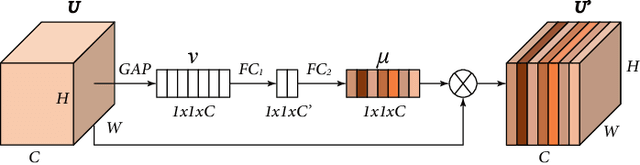
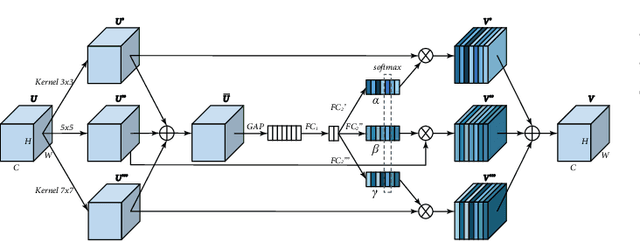
While deep Convolutional Neural Networks (CNNs) have shown extraordinary capability of modelling specific noise and denoising, they still perform poorly on real-world noisy images. The main reason is that the real-world noise is more sophisticated and diverse. To tackle the issue of blind denoising, in this paper, we propose a novel pyramid real image denoising network (PRIDNet), which contains three stages. First, the noise estimation stage uses channel attention mechanism to recalibrate the channel importance of input noise. Second, at the multi-scale denoising stage, pyramid pooling is utilized to extract multi-scale features. Third, the stage of feature fusion adopts a kernel selecting operation to adaptively fuse multi-scale features. Experiments on two datasets of real noisy photographs demonstrate that our approach can achieve competitive performance in comparison with state-of-the-art denoisers in terms of both quantitative measure and visual perception quality.
NLH: A Blind Pixel-level Non-local Method for Real-world Image Denoising
Jul 04, 2019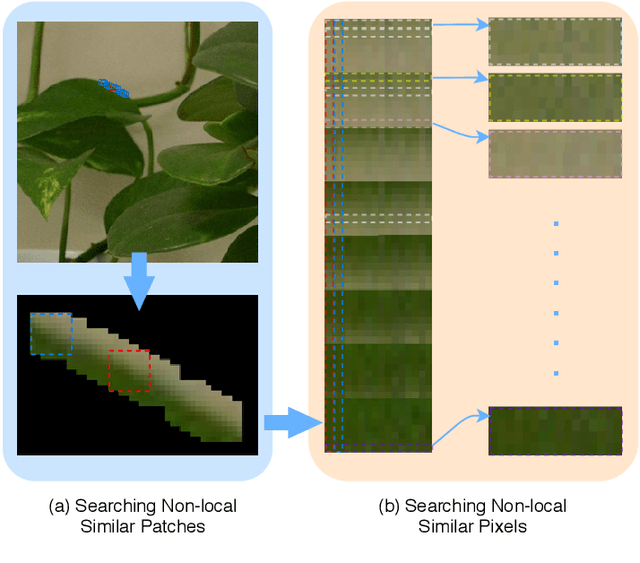
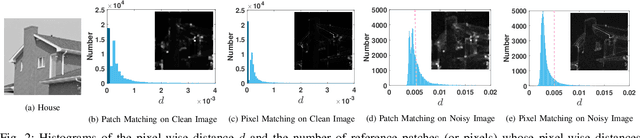
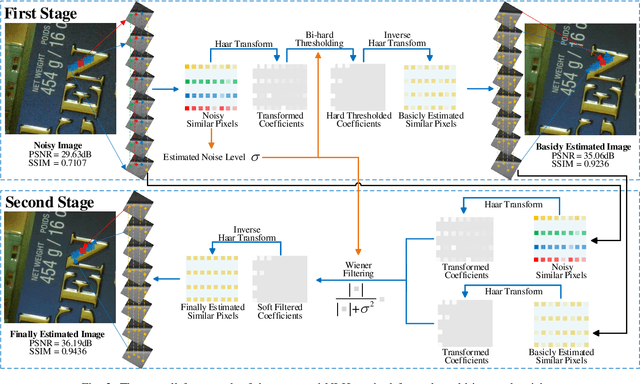

Non-local self similarity (NSS) is a powerful prior of natural images for image denoising. Most of existing denoising methods employ similar patches, which is a patch-level NSS prior. In this paper, we take one step forward by introducing a pixel-level NSS prior, i.e., searching similar pixels across a non-local region. This is motivated by the fact that finding closely similar pixels is more feasible than similar patches in natural images, which can be used to enhance image denoising performance. With the introduced pixel-level NSS prior, we propose an accurate noise level estimation method, and then develop a blind image denoising method based on the lifting Haar transform and Wiener filtering techniques. Experiments on benchmark datasets demonstrate that, the proposed method achieves much better performance than state-of-the-art methods on real-world image denoising. The code will be released.
Ultrafast Focus Detection for Automated Microscopy
Aug 26, 2021
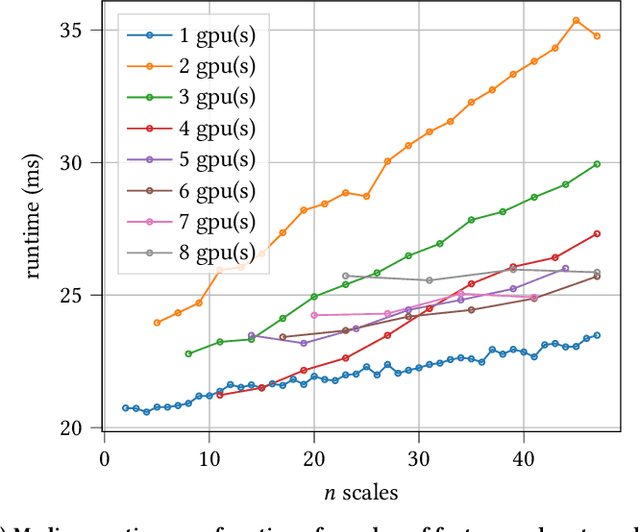
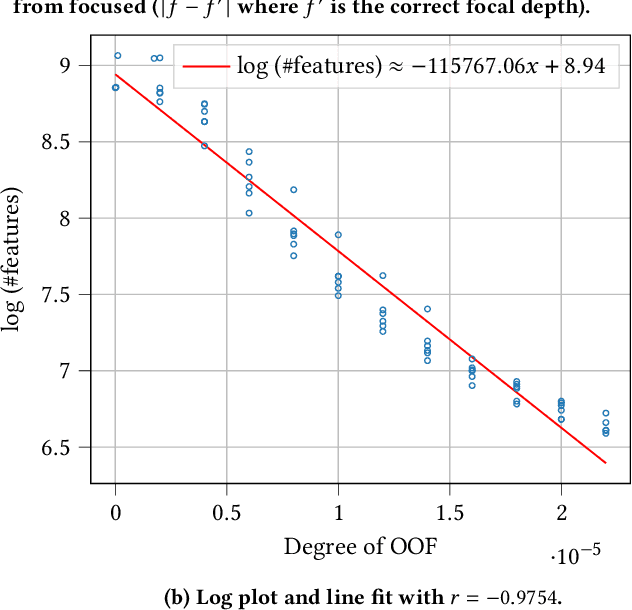
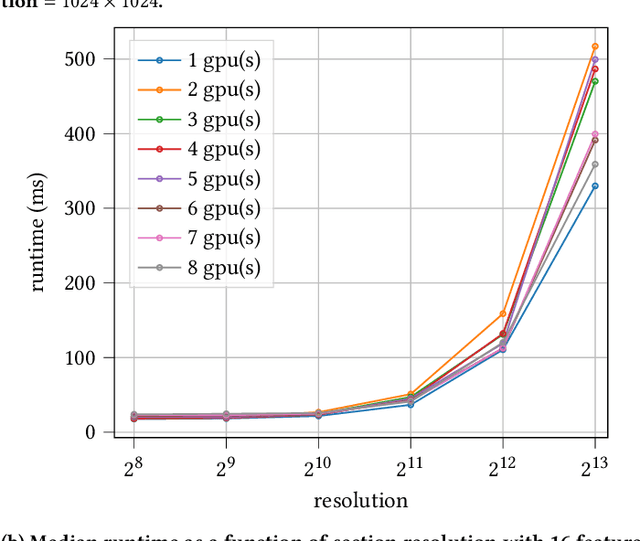
Recent advances in scientific instruments have resulted in dramatic increase in the volumes and velocities of data being generated in every-day laboratories. Scanning electron microscopy is one such example where technological advancements are now overwhelming scientists with critical data for montaging, alignment, and image segmentation -- key practices for many scientific domains, including, for example, neuroscience, where they are used to derive the anatomical relationships of the brain. These instruments now necessitate equally advanced computing resources and techniques to realize their full potential. Here we present a fast out-of-focus detection algorithm for electron microscopy images collected serially and demonstrate that it can be used to provide near-real time quality control for neurology research. Our technique, Multi-scale Histologic Feature Detection, adapts classical computer vision techniques and is based on detecting various fine-grained histologic features. We further exploit the inherent parallelism in the technique by employing GPGPU primitives in order to accelerate characterization. Tests are performed that demonstrate near-real-time detection of out-of-focus conditions. We deploy these capabilities as a funcX function and show that it can be applied as data are collected using an automated pipeline . We discuss extensions that enable scaling out to support multi-beam microscopes and integration with existing focus systems for purposes of implementing auto-focus.
Semi- and Self-Supervised Multi-View Fusion of 3D Microscopy Images using Generative Adversarial Networks
Aug 05, 2021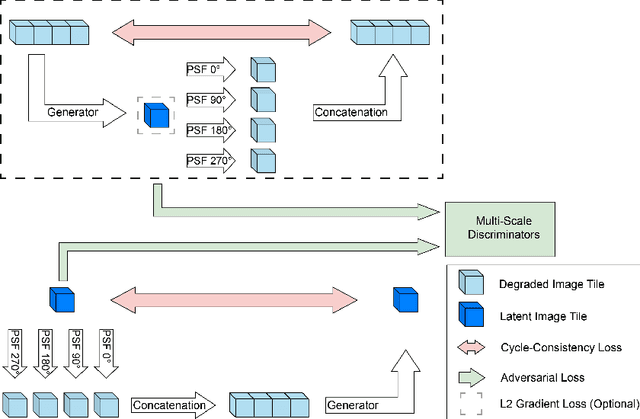
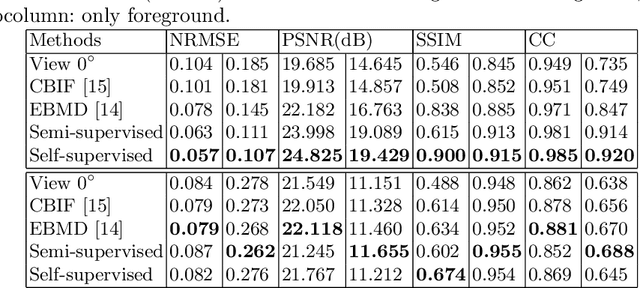
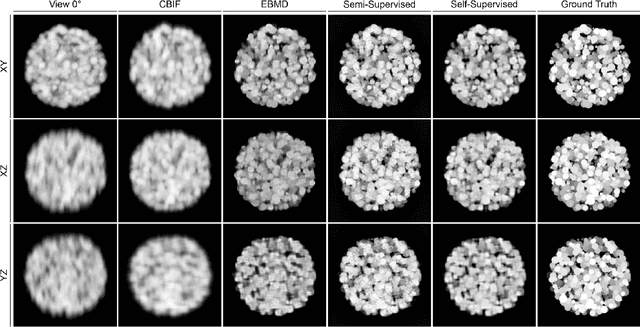
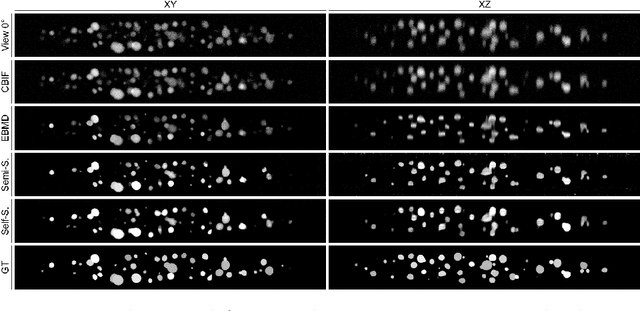
Recent developments in fluorescence microscopy allow capturing high-resolution 3D images over time for living model organisms. To be able to image even large specimens, techniques like multi-view light-sheet imaging record different orientations at each time point that can then be fused into a single high-quality volume. Based on measured point spread functions (PSF), deconvolution and content fusion are able to largely revert the inevitable degradation occurring during the imaging process. Classical multi-view deconvolution and fusion methods mainly use iterative procedures and content-based averaging. Lately, Convolutional Neural Networks (CNNs) have been deployed to approach 3D single-view deconvolution microscopy, but the multi-view case waits to be studied. We investigated the efficacy of CNN-based multi-view deconvolution and fusion with two synthetic data sets that mimic developing embryos and involve either two or four complementary 3D views. Compared with classical state-of-the-art methods, the proposed semi- and self-supervised models achieve competitive and superior deconvolution and fusion quality in the two-view and quad-view cases, respectively.
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
May 05, 2021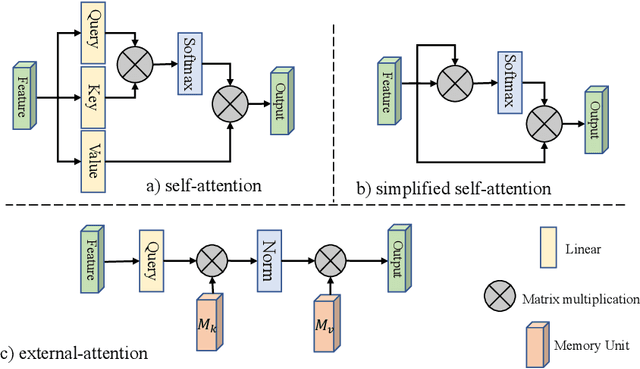
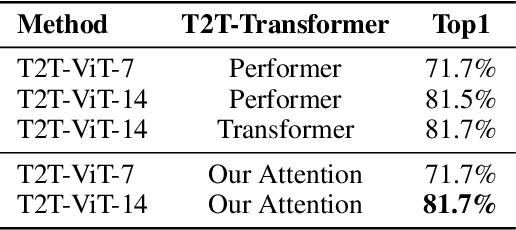

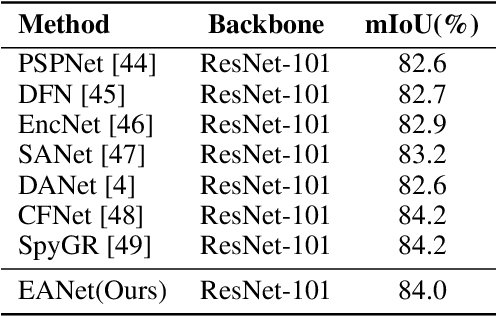
Attention mechanisms, especially self-attention, play an increasingly important role in deep feature representation in visual tasks. Self-attention updates the feature at each position by computing a weighted sum of features using pair-wise affinities across all positions to capture long-range dependency within a single sample. However, self-attention has a quadratic complexity and ignores potential correlation between different samples. This paper proposes a novel attention mechanism which we call external attention, based on two external, small, learnable, and shared memories, which can be implemented easily by simply using two cascaded linear layers and two normalization layers; it conveniently replaces self-attention in existing popular architectures. External attention has linear complexity and implicitly considers the correlations between all samples. Extensive experiments on image classification, semantic segmentation, image generation, point cloud classification and point cloud segmentation tasks reveal that our method provides comparable or superior performance to the self-attention mechanism and some of its variants, with much lower computational and memory costs.
Video Contrastive Learning with Global Context
Aug 05, 2021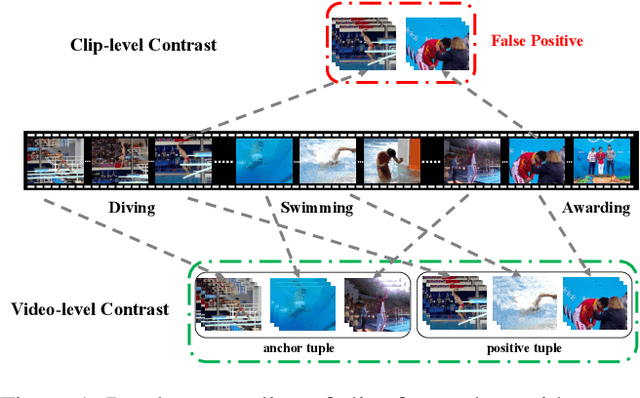

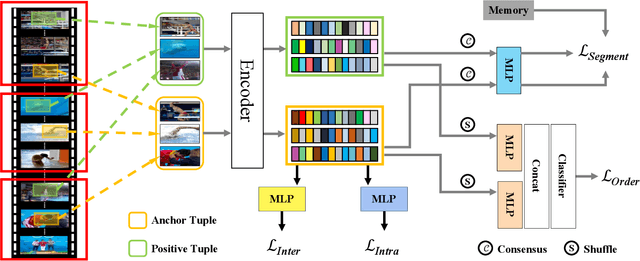
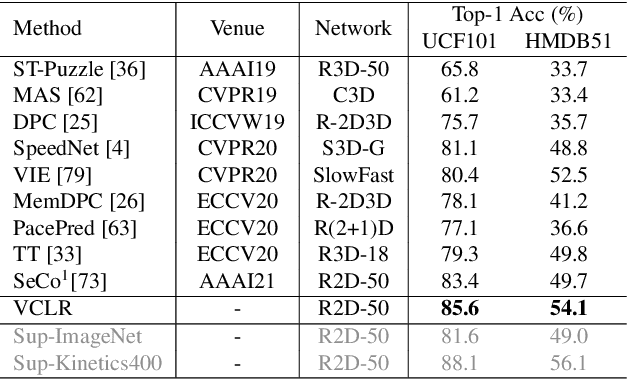
Contrastive learning has revolutionized self-supervised image representation learning field, and recently been adapted to video domain. One of the greatest advantages of contrastive learning is that it allows us to flexibly define powerful loss objectives as long as we can find a reasonable way to formulate positive and negative samples to contrast. However, existing approaches rely heavily on the short-range spatiotemporal salience to form clip-level contrastive signals, thus limit themselves from using global context. In this paper, we propose a new video-level contrastive learning method based on segments to formulate positive pairs. Our formulation is able to capture global context in a video, thus robust to temporal content change. We also incorporate a temporal order regularization term to enforce the inherent sequential structure of videos. Extensive experiments show that our video-level contrastive learning framework (VCLR) is able to outperform previous state-of-the-arts on five video datasets for downstream action classification, action localization and video retrieval. Code is available at https://github.com/amazon-research/video-contrastive-learning.
Video-based Person Re-identification with Spatial and Temporal Memory Networks
Aug 20, 2021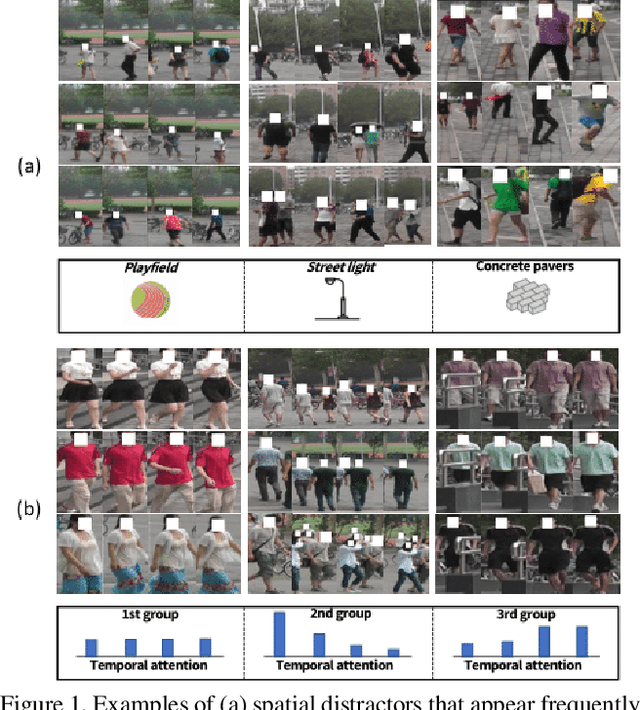
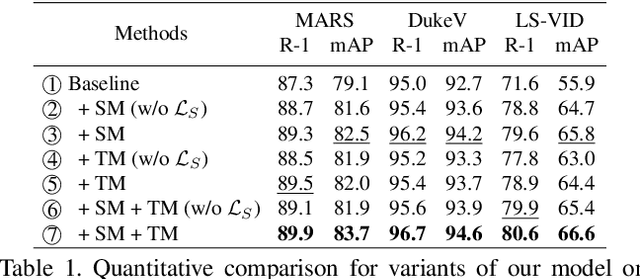
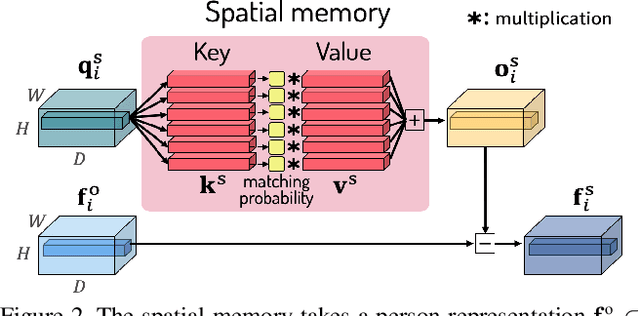
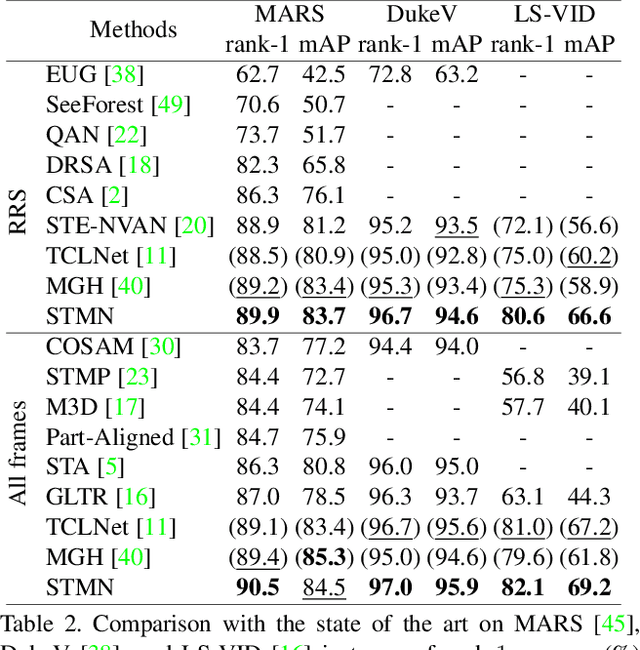
Video-based person re-identification (reID) aims to retrieve person videos with the same identity as a query person across multiple cameras. Spatial and temporal distractors in person videos, such as background clutter and partial occlusions over frames, respectively, make this task much more challenging than image-based person reID. We observe that spatial distractors appear consistently in a particular location, and temporal distractors show several patterns, e.g., partial occlusions occur in the first few frames, where such patterns provide informative cues for predicting which frames to focus on (i.e., temporal attentions). Based on this, we introduce a novel Spatial and Temporal Memory Networks (STMN). The spatial memory stores features for spatial distractors that frequently emerge across video frames, while the temporal memory saves attentions which are optimized for typical temporal patterns in person videos. We leverage the spatial and temporal memories to refine frame-level person representations and to aggregate the refined frame-level features into a sequence-level person representation, respectively, effectively handling spatial and temporal distractors in person videos. We also introduce a memory spread loss preventing our model from addressing particular items only in the memories. Experimental results on standard benchmarks, including MARS, DukeMTMC-VideoReID, and LS-VID, demonstrate the effectiveness of our method.
The Art of Food: Meal Image Synthesis from Ingredients
May 09, 2019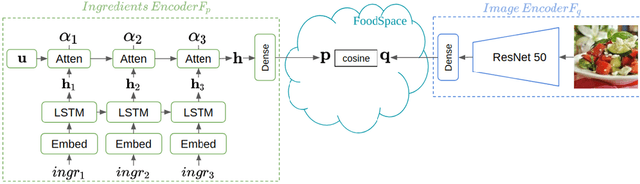
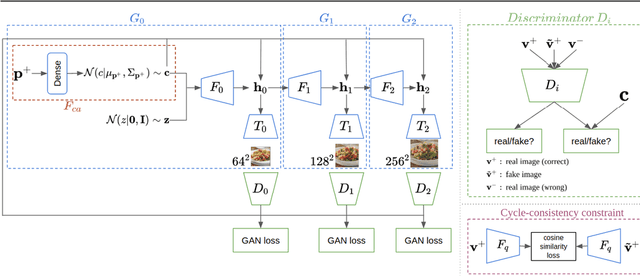


In this work we propose a new computational framework, based on generative deep models, for synthesis of photo-realistic food meal images from textual descriptions of its ingredients. Previous works on synthesis of images from text typically rely on pre-trained text models to extract text features, followed by a generative neural networks (GANs) aimed to generate realistic images conditioned on the text features. These works mainly focus on generating spatially compact and well-defined categories of objects, such as birds or flowers. In contrast, meal images are significantly more complex, consisting of multiple ingredients whose appearance and spatial qualities are further modified by cooking methods. We propose a method that first builds an attention-based ingredients-image association model, which is then used to condition a generative neural network tasked with synthesizing meal images. Furthermore, a cycle-consistent constraint is added to further improve image quality and control appearance. Extensive experiments show our model is able to generate meal image corresponding to the ingredients, which could be used to augment existing dataset for solving other computational food analysis problems.