 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OmniFusion Technical Report
Apr 09, 2024
Last year, multimodal architectures served up a revolution in AI-based approaches and solutions, extending the capabilities of large language models (LLM). We propose an \textit{OmniFusion} model based on a pretrained LLM and adapters for visual modality. We evaluated and compared several architecture design principles for better text and visual data coupling: MLP and transformer adapters, various CLIP ViT-based encoders (SigLIP, InternVIT, etc.), and their fusing approach, image encoding method (whole image or tiles encoding) and two 7B LLMs (the proprietary one and open-source Mistral). Experiments on 8 visual-language benchmarks show the top score for the best OmniFusion setup in terms of different VQA tasks in comparison with open-source LLaVA-like solutions: VizWiz, Pope, MM-Vet, ScienceQA, MMBench, TextVQA, VQAv2, MMMU. We also propose a variety of situations, where OmniFusion provides highly-detailed answers in different domains: housekeeping, sightseeing, culture, medicine, handwritten and scanned equations recognition, etc. Mistral-based OmniFusion model is an open-source solution with weights, training and inference scripts available at https://github.com/AIRI-Institute/OmniFusion.
GeneAvatar: Generic Expression-Aware Volumetric Head Avatar Editing from a Single Image
Apr 02, 2024Recently, we have witnessed the explosive growth of various volumetric representations in modeling animatable head avatars. However, due to the diversity of frameworks, there is no practical method to support high-level applications like 3D head avatar editing across different representations. In this paper, we propose a generic avatar editing approach that can be universally applied to various 3DMM driving volumetric head avatars. To achieve this goal, we design a novel expression-aware modification generative model, which enables lift 2D editing from a single image to a consistent 3D modification field. To ensure the effectiveness of the generative modification process, we develop several techniques, including an expression-dependent modification distillation scheme to draw knowledge from the large-scale head avatar model and 2D facial texture editing tools, implicit latent space guidance to enhance model convergence, and a segmentation-based loss reweight strategy for fine-grained texture inversion. Extensive experiments demonstrate that our method delivers high-quality and consistent results across multiple expression and viewpoints. Project page: https://zju3dv.github.io/geneavatar/
Locate, Assign, Refine: Taming Customized Image Inpainting with Text-Subject Guidance
Mar 28, 2024
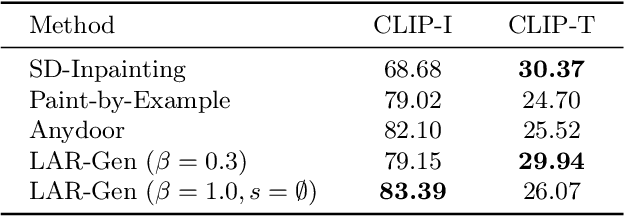
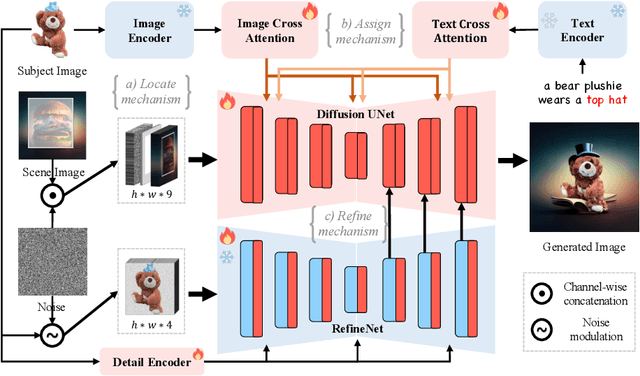

Prior studies have made significant progress in image inpainting guided by either text or subject image. However, the research on editing with their combined guidance is still in the early stages. To tackle this challenge, we present LAR-Gen, a novel approach for image inpainting that enables seamless inpainting of masked scene images, incorporating both the textual prompts and specified subjects. Our approach adopts a coarse-to-fine manner to ensure subject identity preservation and local semantic coherence. The process involves (i) Locate: concatenating the noise with masked scene image to achieve precise regional editing, (ii) Assign: employing decoupled cross-attention mechanism to accommodate multi-modal guidance, and (iii) Refine: using a novel RefineNet to supplement subject details. Additionally, to address the issue of scarce training data, we introduce a novel data construction pipeline. This pipeline extracts substantial pairs of data consisting of local text prompts and corresponding visual instances from a vast image dataset, leveraging publicly available large models. Extensive experiments and varied application scenarios demonstrate the superiority of LAR-Gen in terms of both identity preservation and text semantic consistency. Project page can be found at \url{https://ali-vilab.github.io/largen-page/}.
Improving Shift Invariance in Convolutional Neural Networks with Translation Invariant Polyphase Sampling
Apr 11, 2024Downsampling operators break the shift invariance of convolutional neural networks (CNNs) and this affects the robustness of features learned by CNNs when dealing with even small pixel-level shift. Through a large-scale correlation analysis framework, we study shift invariance of CNNs by inspecting existing downsampling operators in terms of their maximum-sampling bias (MSB), and find that MSB is negatively correlated with shift invariance. Based on this crucial insight, we propose a learnable pooling operator called Translation Invariant Polyphase Sampling (TIPS) and two regularizations on the intermediate feature maps of TIPS to reduce MSB and learn translation-invariant representations. TIPS can be integrated into any CNN and can be trained end-to-end with marginal computational overhead. Our experiments demonstrate that TIPS results in consistent performance gains in terms of accuracy, shift consistency, and shift fidelity on multiple benchmarks for image classification and semantic segmentation compared to previous methods and also leads to improvements in adversarial and distributional robustness. TIPS results in the lowest MSB compared to all previous methods, thus explaining our strong empirical results.
Two Tricks to Improve Unsupervised Segmentation Learning
Apr 08, 2024We present two practical improvement techniques for unsupervised segmentation learning. These techniques address limitations in the resolution and accuracy of predicted segmentation maps of recent state-of-the-art methods. Firstly, we leverage image post-processing techniques such as guided filtering to refine the output masks, improving accuracy while avoiding substantial computational costs. Secondly, we introduce a multi-scale consistency criterion, based on a teacher-student training scheme. This criterion matches segmentation masks predicted from regions of the input image extracted at different resolutions to each other. Experimental results on several benchmarks used in unsupervised segmentation learning demonstrate the effectiveness of our proposed techniques.
MugenNet: A Novel Combined Convolution Neural Network and Transformer Network with its Application for Colonic Polyp Image Segmentation
Mar 31, 2024Biomedical image segmentation is a very important part in disease diagnosis. The term "colonic polyps" refers to polypoid lesions that occur on the surface of the colonic mucosa within the intestinal lumen. In clinical practice, early detection of polyps is conducted through colonoscopy examinations and biomedical image processing. Therefore, the accurate polyp image segmentation is of great significance in colonoscopy examinations. Convolutional Neural Network (CNN) is a common automatic segmentation method, but its main disadvantage is the long training time. Transformer utilizes a self-attention mechanism, which essentially assigns different importance weights to each piece of information, thus achieving high computational efficiency during segmentation. However, a potential drawback is the risk of information loss. In the study reported in this paper, based on the well-known hybridization principle, we proposed a method to combine CNN and Transformer to retain the strengths of both, and we applied this method to build a system called MugenNet for colonic polyp image segmentation. We conducted a comprehensive experiment to compare MugenNet with other CNN models on five publicly available datasets. The ablation experiment on MugentNet was conducted as well. The experimental results show that MugenNet achieves significantly higher processing speed and accuracy compared with CNN alone. The generalized implication with our work is a method to optimally combine two complimentary methods of machine learning.
Tackling Ambiguity from Perspective of Uncertainty Inference and Affinity Diversification for Weakly Supervised Semantic Segmentation
Apr 12, 2024Weakly supervised semantic segmentation (WSSS) with image-level labels intends to achieve dense tasks without laborious annotations. However, due to the ambiguous contexts and fuzzy regions, the performance of WSSS, especially the stages of generating Class Activation Maps (CAMs) and refining pseudo masks, widely suffers from ambiguity while being barely noticed by previous literature. In this work, we propose UniA, a unified single-staged WSSS framework, to efficiently tackle this issue from the perspective of uncertainty inference and affinity diversification, respectively. When activating class objects, we argue that the false activation stems from the bias to the ambiguous regions during the feature extraction. Therefore, we design a more robust feature representation with a probabilistic Gaussian distribution and introduce the uncertainty estimation to avoid the bias. A distribution loss is particularly proposed to supervise the process, which effectively captures the ambiguity and models the complex dependencies among features. When refining pseudo labels, we observe that the affinity from the prevailing refinement methods intends to be similar among ambiguities. To this end, an affinity diversification module is proposed to promote diversity among semantics. A mutual complementing refinement is proposed to initially rectify the ambiguous affinity with multiple inferred pseudo labels. More importantly, a contrastive affinity loss is further designed to diversify the relations among unrelated semantics, which reliably propagates the diversity into the whole feature representations and helps generate better pseudo masks. Extensive experiments are conducted on PASCAL VOC, MS COCO, and medical ACDC datasets, which validate the efficiency of UniA tackling ambiguity and the superiority over recent single-staged or even most multi-staged competitors.
A Transfer Attack to Image Watermarks
Mar 25, 2024Watermark has been widely deployed by industry to detect AI-generated images. The robustness of such watermark-based detector against evasion attacks in the white-box and black-box settings is well understood in the literature. However, the robustness in the no-box setting is much less understood. In particular, multiple studies claimed that image watermark is robust in such setting. In this work, we propose a new transfer evasion attack to image watermark in the no-box setting. Our transfer attack adds a perturbation to a watermarked image to evade multiple surrogate watermarking models trained by the attacker itself, and the perturbed watermarked image also evades the target watermarking model. Our major contribution is to show that, both theoretically and empirically, watermark-based AI-generated image detector is not robust to evasion attacks even if the attacker does not have access to the watermarking model nor the detection API.
Aggregating Local and Global Features via Selective State Spaces Model for Efficient Image Deblurring
Mar 29, 2024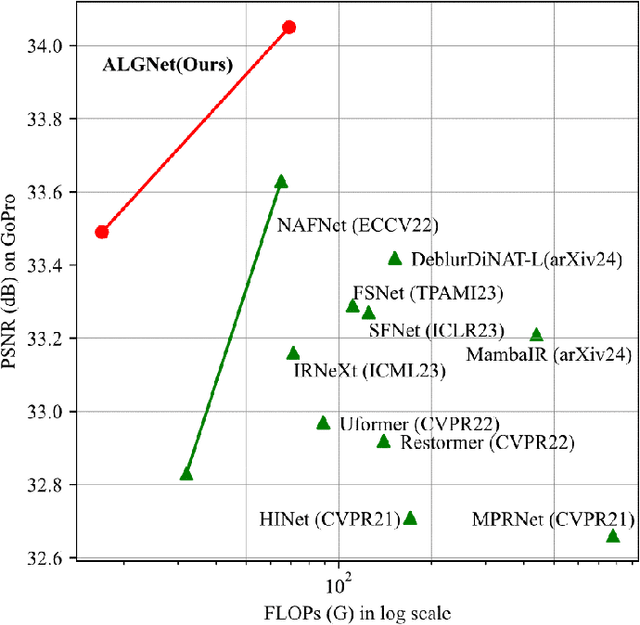
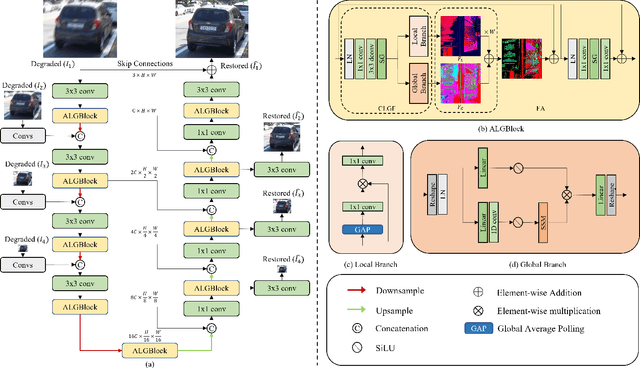

Image deblurring is a process of restoring a high quality image from the corresponding blurred image. Significant progress in this field has been made possible by the emergence of various effective deep learning models, including CNNs and Transformers. However, these methods often face the dilemma between eliminating long-range blur degradation perturbations and maintaining computational efficiency, which hinders their practical application. To address this issue, we propose an efficient image deblurring network that leverages selective structured state spaces model to aggregate enriched and accurate features. Specifically, we design an aggregate local and global block (ALGBlock) to capture and fuse both local invariant properties and non-local information. The ALGBlock consists of two blocks: (1) The local block models local connectivity using simplified channel attention. (2) The global block captures long-range dependency features with linear complexity through selective structured state spaces. Nevertheless, we note that the image details are local features of images, we accentuate the local part for restoration by recalibrating the weight when aggregating the two branches for recovery. Experimental results demonstrate that the proposed method outperforms state-of-the-art approaches on widely used benchmarks, highlighting its superior performance.
DiffStyler: Diffusion-based Localized Image Style Transfer
Mar 27, 2024Image style transfer aims to imbue digital imagery with the distinctive attributes of style targets, such as colors, brushstrokes, shapes, whilst concurrently preserving the semantic integrity of the content. Despite the advancements in arbitrary style transfer methods, a prevalent challenge remains the delicate equilibrium between content semantics and style attributes. Recent developments in large-scale text-to-image diffusion models have heralded unprecedented synthesis capabilities, albeit at the expense of relying on extensive and often imprecise textual descriptions to delineate artistic styles. Addressing these limitations, this paper introduces DiffStyler, a novel approach that facilitates efficient and precise arbitrary image style transfer. DiffStyler lies the utilization of a text-to-image Stable Diffusion model-based LoRA to encapsulate the essence of style targets. This approach, coupled with strategic cross-LoRA feature and attention injection, guides the style transfer process. The foundation of our methodology is rooted in the observation that LoRA maintains the spatial feature consistency of UNet, a discovery that further inspired the development of a mask-wise style transfer technique. This technique employs masks extracted through a pre-trained FastSAM model, utilizing mask prompts to facilitate feature fusion during the denoising process, thereby enabling localized style transfer that preserves the original image's unaffected regions. Moreover, our approach accommodates multiple style targets through the use of corresponding masks. Through extensive experimentation, we demonstrate that DiffStyler surpasses previous methods in achieving a more harmonious balance between content preservation and style integration.