 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Algorithms for Learning from Coarse Labels
Aug 22, 2021
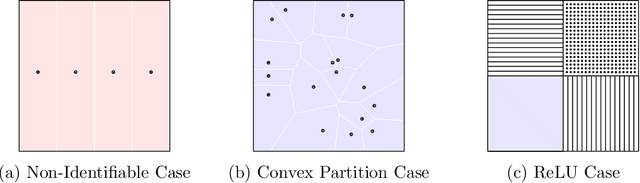
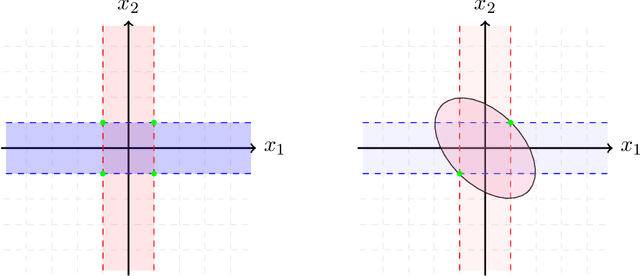
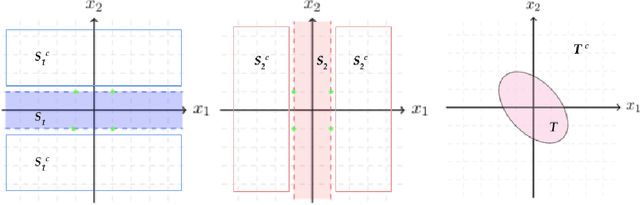
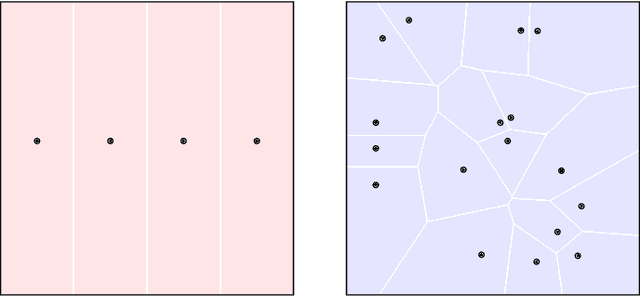
For many learning problems one may not have access to fine grained label information; e.g., an image can be labeled as husky, dog, or even animal depending on the expertise of the annotator. In this work, we formalize these settings and study the problem of learning from such coarse data. Instead of observing the actual labels from a set $\mathcal{Z}$, we observe coarse labels corresponding to a partition of $\mathcal{Z}$ (or a mixture of partitions). Our main algorithmic result is that essentially any problem learnable from fine grained labels can also be learned efficiently when the coarse data are sufficiently informative. We obtain our result through a generic reduction for answering Statistical Queries (SQ) over fine grained labels given only coarse labels. The number of coarse labels required depends polynomially on the information distortion due to coarsening and the number of fine labels $|\mathcal{Z}|$. We also investigate the case of (infinitely many) real valued labels focusing on a central problem in censored and truncated statistics: Gaussian mean estimation from coarse data. We provide an efficient algorithm when the sets in the partition are convex and establish that the problem is NP-hard even for very simple non-convex sets.
Automatic Generation of Descriptive Titles for Video Clips Using Deep Learning
Apr 07, 2021


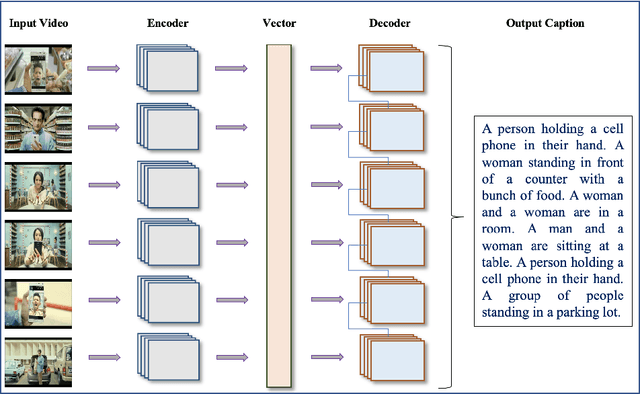
Over the last decade, the use of Deep Learning in many applications produced results that are comparable to and in some cases surpassing human expert performance. The application domains include diagnosing diseases, finance, agriculture, search engines, robot vision, and many others. In this paper, we are proposing an architecture that utilizes image/video captioning methods and Natural Language Processing systems to generate a title and a concise abstract for a video. Such a system can potentially be utilized in many application domains, including, the cinema industry, video search engines, security surveillance, video databases/warehouses, data centers, and others. The proposed system functions and operates as followed: it reads a video; representative image frames are identified and selected; the image frames are captioned; NLP is applied to all generated captions together with text summarization; and finally, a title and an abstract are generated for the video. All functions are performed automatically. Preliminary results are provided in this paper using publicly available datasets. This paper is not concerned about the efficiency of the system at the execution time. We hope to be able to address execution efficiency issues in our subsequent publications.
Segmentation of skin lesions and their attributes using Generative Adversarial Networks
Jan 30, 2021
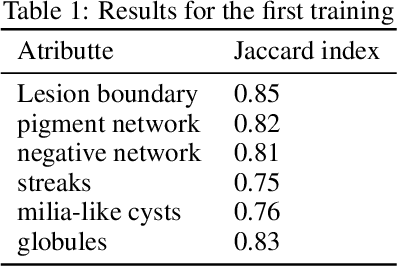
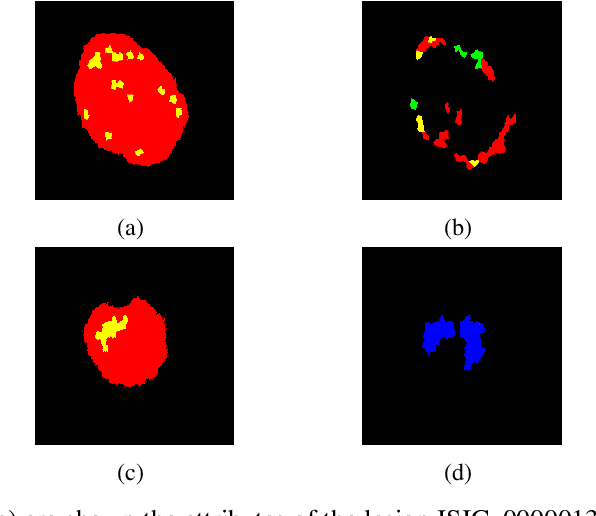
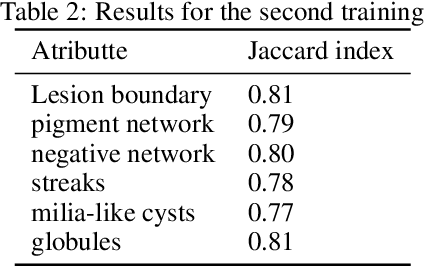
This work is about the semantic segmentation of skin lesion boundary and their attributes using Image-to-Image Translation with Conditional Adversarial Nets. Melanoma is a type of skin cancer that can be cured if detected in time. Segmentation into dermoscopic images is an essential procedure for computer-assisted diagnosis due to its existing artifacts typical of skin images. To alleviate the image annotation process, we propose to use a modified Pix2Pix network. The discriminator network learns the mapping from a dermal image as an input and a mask image of six channels as an output. Likewise, the discriminative network output called PatchGAN is varied for one channel and six output channels. The photos used come from the 2018 ISIC Challenge, where 500 photographs are used with their respective semantic map, divided into 75% for training and 35% for testing. Obtaining for 100 training epochs high Jaccard indices for all attributes of the segmentation map.
MetH: A family of high-resolution and variable-shape image challenges
Nov 29, 2019
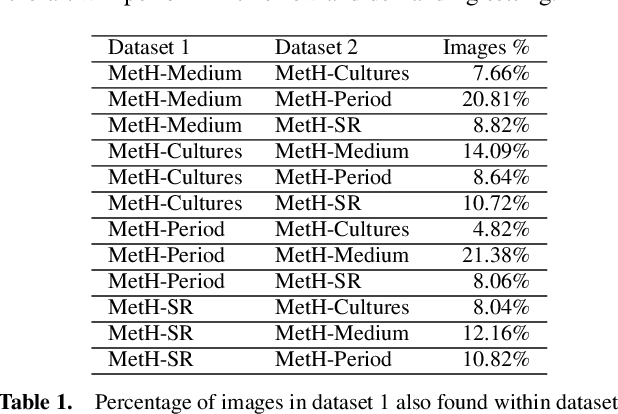
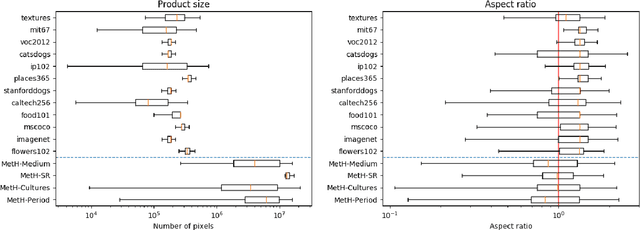
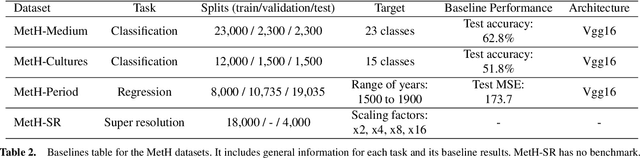
High-resolution and variable-shape images have not yet been properly addressed by the AI community. The approach of down-sampling data often used with convolutional neural networks is sub-optimal for many tasks, and has too many drawbacks to be considered a sustainable alternative. In sight of the increasing importance of problems that can benefit from exploiting high-resolution (HR) and variable-shape, and with the goal of promoting research in that direction, we introduce a new family of datasets (MetH). The four proposed problems include two image classification, one image regression and one super resolution task. Each of these datasets contains thousands of art pieces captured by HR and variable-shape images, labeled by experts at the Metropolitan Museum of Art. We perform an analysis, which shows how the proposed tasks go well beyond current public alternatives in both pixel size and aspect ratio variance. At the same time, the performance obtained by popular architectures on these tasks shows that there is ample room for improvement. To wrap up the relevance of the contribution we review the fields, both in AI and high-performance computing, that could benefit from the proposed challenges.
Using CNNs to Identify the Origin of Finger Vein Image
Mar 02, 2021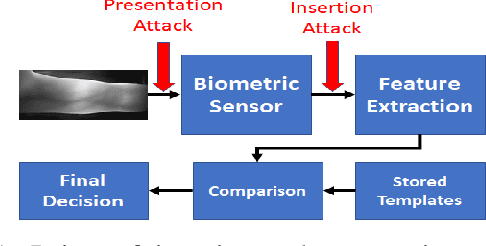
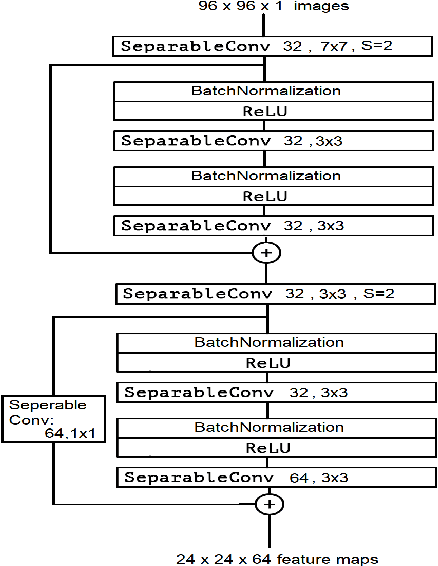
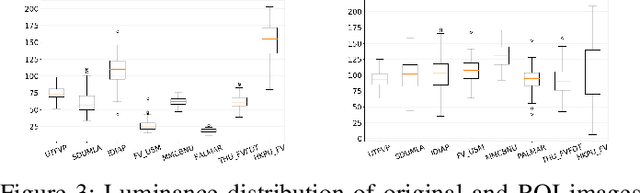
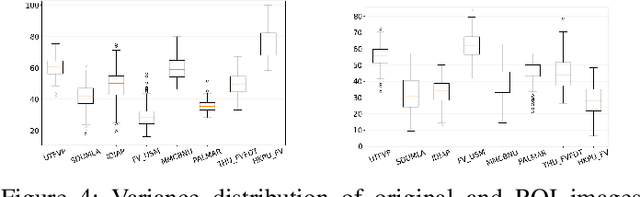
We study the finger vein (FV) sensor model identification task using a deep learning approach. So far, for this biometric modality, only correlation-based PRNU and texture descriptor-based methods have been applied. We employ five prominent CNN architectures covering a wide range of CNN family models, including VGG16, ResNet, and the Xception model. In addition, a novel architecture termed FV2021 is proposed in this work, which excels by its compactness and a low number of parameters to be trained. Original samples, as well as the region of interest data from eight publicly accessible FV datasets, are used in experimentation. An excellent sensor identification AUC-ROC score of 1.0 for patches of uncropped samples and 0.9997 for ROI samples have been achieved. The comparison with former methods shows that the CNN-based approach is superior and improved the results.
CNN-based Cardiac Motion Extraction to Generate Deformable Geometric Left Ventricle Myocardial Models from Cine MRI
Mar 30, 2021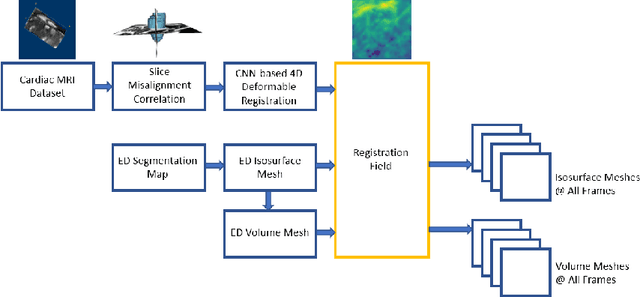
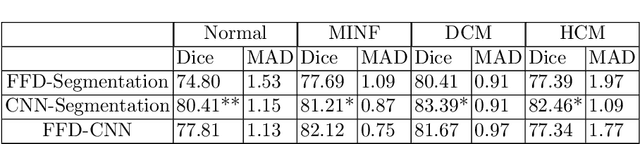

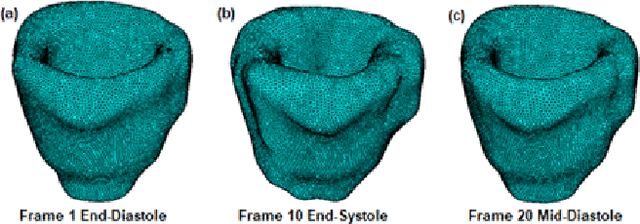
Patient-specific left ventricle (LV) myocardial models have the potential to be used in a variety of clinical scenarios for improved diagnosis and treatment plans. Cine cardiac magnetic resonance (MR) imaging provides high resolution images to reconstruct patient-specific geometric models of the LV myocardium. With the advent of deep learning, accurate segmentation of cardiac chambers from cine cardiac MR images and unsupervised learning for image registration for cardiac motion estimation on a large number of image datasets is attainable. Here, we propose a deep leaning-based framework for the development of patient-specific geometric models of LV myocardium from cine cardiac MR images, using the Automated Cardiac Diagnosis Challenge (ACDC) dataset. We use the deformation field estimated from the VoxelMorph-based convolutional neural network (CNN) to propagate the isosurface mesh and volume mesh of the end-diastole (ED) frame to the subsequent frames of the cardiac cycle. We assess the CNN-based propagated models against segmented models at each cardiac phase, as well as models propagated using another traditional nonrigid image registration technique.
Classifying Image Sequences of Astronomical Transients with Deep Neural Networks
Apr 28, 2020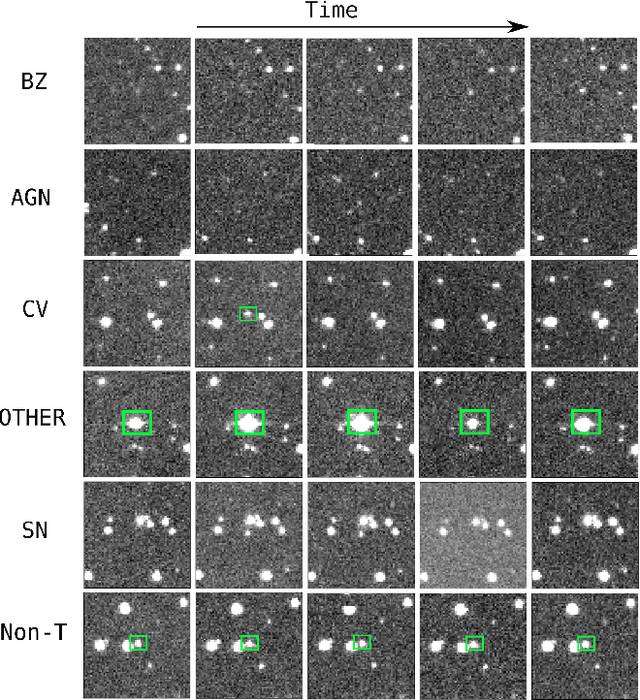


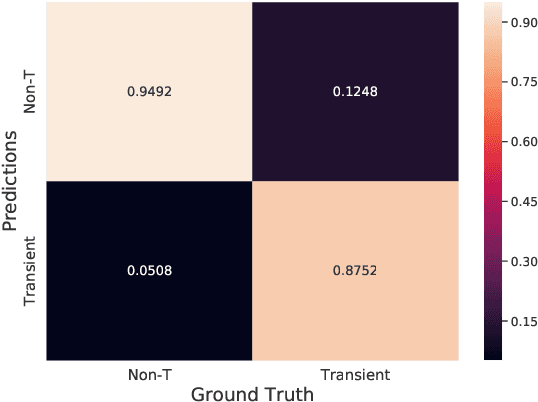
Supervised classification of temporal sequences of astronomical images into meaningful transient astrophysical phenomena has been considered a hard problem because it requires the intervention of human experts. The classifier uses the expert's knowledge to find heuristic features to process the images, for instance, by performing image subtraction or by extracting sparse information such as flux time series in the form of light curves. We present a successful deep learning approach that learns directly from imaging data. Our method models explicitly the spatio-temporal patterns with Deep Convolutional Neural Networks and Gated Recurrent Units. We train these deep neural networks using 1.3 million real astronomical images from the Catalina Real-Time Transient Survey to classify the sequences into five different types of astronomical transient classes. The TAO-Net (for Transient Astronomical Objects Network) architecture achieves on the five-type classification task an average F1-score of 54.58$\pm$13.32, almost nine points higher than the F1-score of 45.49 $\pm$ 13.75 from the random forest classification on light curves. The achievement TAO-Net opens the possibility to develop new deep-learning architectures for early transient detection. We make available the training dataset and trained models of TAO-Net to allow for future extensions of this work.
A comprehensive evaluation of full-reference image quality assessment algorithms on KADID-10k
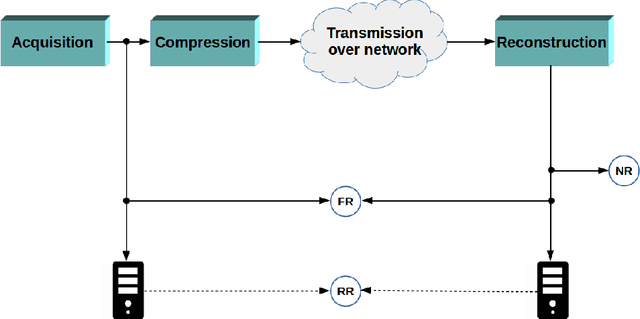
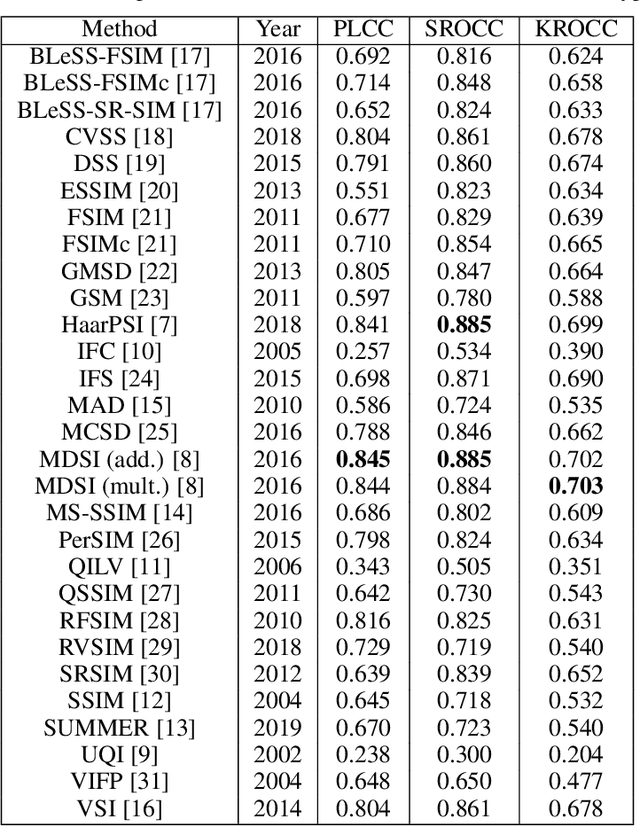
Jul 03, 2019

Significant progress has been made in the past decade for full-reference image quality assessment (FR-IQA). However, new large scale image quality databases have been released for evaluating image quality assessment algorithms. In this study, our goal is to give a comprehensive evaluation of state-of-the-art FR-IQA metrics using the recently published KADID-10k database which is largest available one at the moment. Our evaluation results and the associated discussions is very helpful to obtain a clear understanding about the status of state-of-the-art FR-IQA metrics.
Learned Smartphone ISP on Mobile NPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021
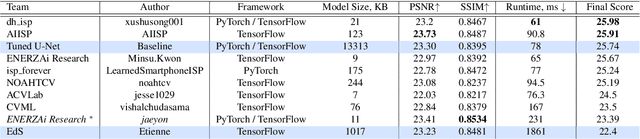
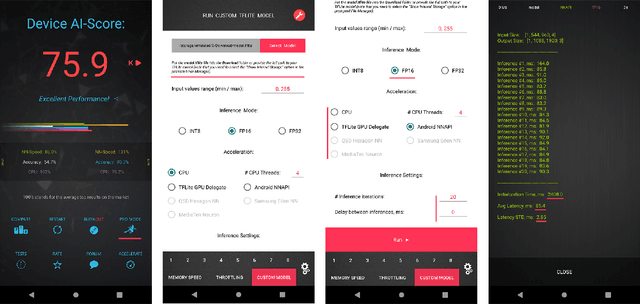
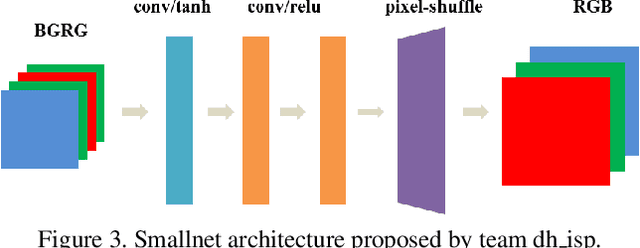
As the quality of mobile cameras starts to play a crucial role in modern smartphones, more and more attention is now being paid to ISP algorithms used to improve various perceptual aspects of mobile photos. In this Mobile AI challenge, the target was to develop an end-to-end deep learning-based image signal processing (ISP) pipeline that can replace classical hand-crafted ISPs and achieve nearly real-time performance on smartphone NPUs. For this, the participants were provided with a novel learned ISP dataset consisting of RAW-RGB image pairs captured with the Sony IMX586 Quad Bayer mobile sensor and a professional 102-megapixel medium format camera. The runtime of all models was evaluated on the MediaTek Dimensity 1000+ platform with a dedicated AI processing unit capable of accelerating both floating-point and quantized neural networks. The proposed solutions are fully compatible with the above NPU and are capable of processing Full HD photos under 60-100 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.
A novel text representation which enables image classifiers to perform text classification, applied to name disambiguation
Aug 19, 2019
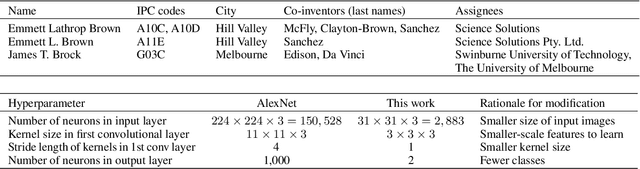


Patent data are often used to study the process of innovation and research, but patent databases lack unique identifiers for individual inventors, making it difficult to study innovation processes at the individual level. Here we introduce an algorithm that performs highly accurate disambiguation of inventors (named entities) in US patent data (F1: 99.09%, precision: 99.41%, recall: 98.76%). The algorithm involves a novel method for converting text-based record data into abstract image representations, in which text from a given pairwise comparison between two inventor name records is converted into a 2D RGB (stacked) image representation. We train an image classification neural network to discriminate between such pairwise comparison images, and then use the trained network to label each pair of records as either matched (same inventor) or non-matched (different inventors). The resulting disambiguation algorithm produces highly accurate results, out-performing other inventor name disambiguation studies on US patent data. Our new text-to-image representation method could potentially be used more broadly for other NLP comparison problems, as it allows image-based processing techniques (e.g. image classification networks) to be applied to text-based comparison problems (such as disambiguation of academic publications, or data linkage problems).