 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ReS2tAC -- UAV-Borne Real-Time SGM Stereo Optimized for Embedded ARM and CUDA Devices
Jun 15, 2021
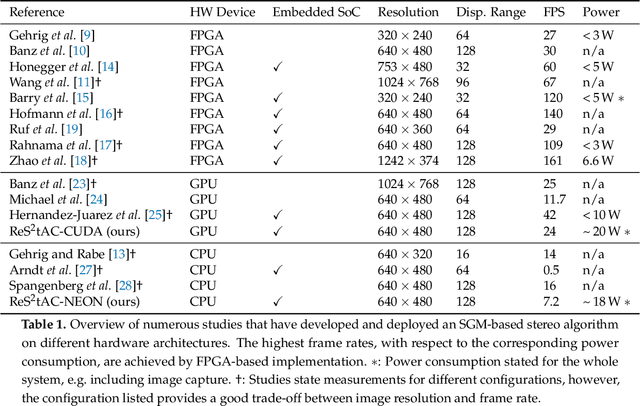

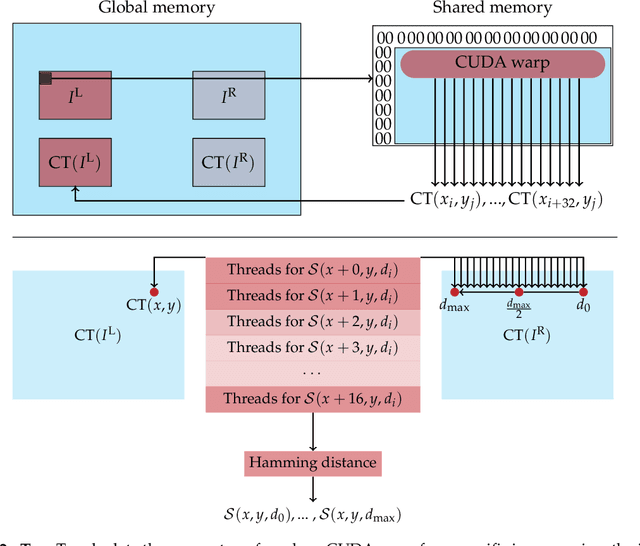
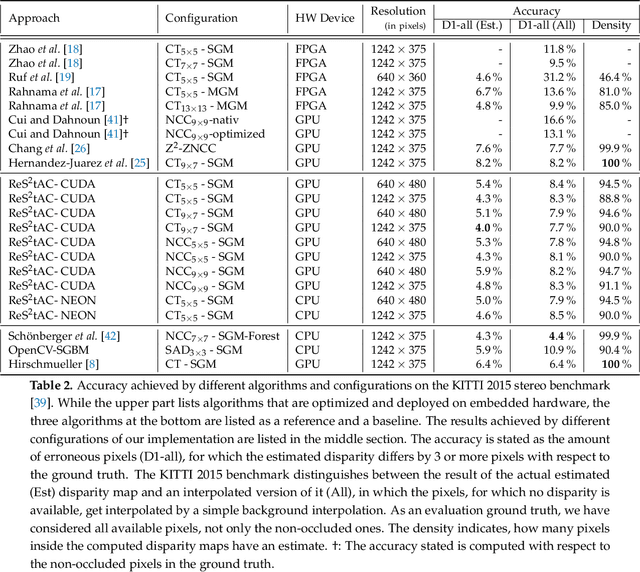
With the emergence of low-cost robotic systems, such as unmanned aerial vehicle, the importance of embedded high-performance image processing has increased. For a long time, FPGAs were the only processing hardware that were capable of high-performance computing, while at the same time preserving a low power consumption, essential for embedded systems. However, the recently increasing availability of embedded GPU-based systems, such as the NVIDIA Jetson series, comprised of an ARM CPU and a NVIDIA Tegra GPU, allows for massively parallel embedded computing on graphics hardware. With this in mind, we propose an approach for real-time embedded stereo processing on ARM and CUDA-enabled devices, which is based on the popular and widely used Semi-Global Matching algorithm. In this, we propose an optimization of the algorithm for embedded CUDA GPUs, by using massively parallel computing, as well as using the NEON intrinsics to optimize the algorithm for vectorized SIMD processing on embedded ARM CPUs. We have evaluated our approach with different configurations on two public stereo benchmark datasets to demonstrate that they can reach an error rate as low as 3.3%. Furthermore, our experiments show that the fastest configuration of our approach reaches up to 46 FPS on VGA image resolution. Finally, in a use-case specific qualitative evaluation, we have evaluated the power consumption of our approach and deployed it on the DJI Manifold 2-G attached to a DJI Matrix 210v2 RTK unmanned aerial vehicle (UAV), demonstrating its suitability for real-time stereo processing onboard a UAV.
High-Fidelity and Arbitrary Face Editing
Mar 29, 2021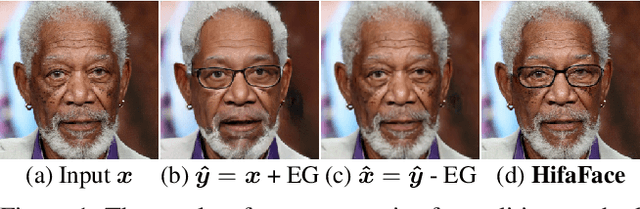
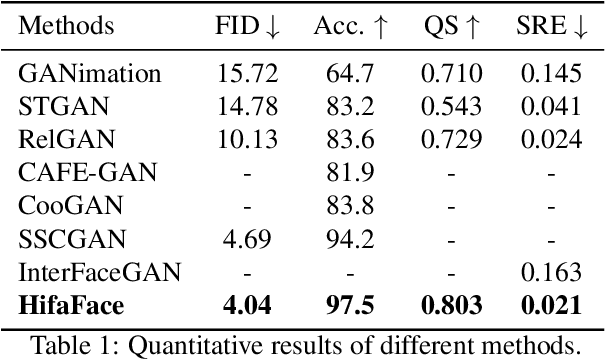


Cycle consistency is widely used for face editing. However, we observe that the generator tends to find a tricky way to hide information from the original image to satisfy the constraint of cycle consistency, making it impossible to maintain the rich details (e.g., wrinkles and moles) of non-editing areas. In this work, we propose a simple yet effective method named HifaFace to address the above-mentioned problem from two perspectives. First, we relieve the pressure of the generator to synthesize rich details by directly feeding the high-frequency information of the input image into the end of the generator. Second, we adopt an additional discriminator to encourage the generator to synthesize rich details. Specifically, we apply wavelet transformation to transform the image into multi-frequency domains, among which the high-frequency parts can be used to recover the rich details. We also notice that a fine-grained and wider-range control for the attribute is of great importance for face editing. To achieve this goal, we propose a novel attribute regression loss. Powered by the proposed framework, we achieve high-fidelity and arbitrary face editing, outperforming other state-of-the-art approaches.
Single-Read Reconstruction for DNA Data Storage Using Transformers
Sep 12, 2021

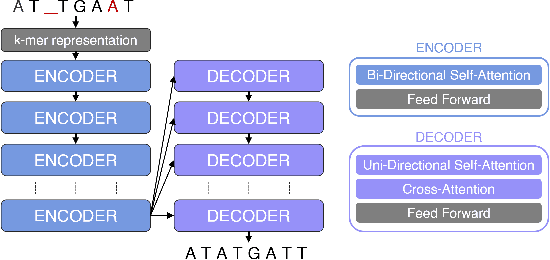
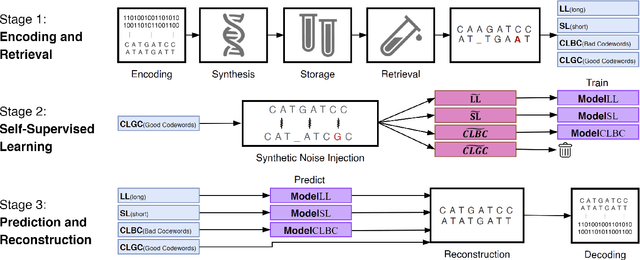
As the global need for large-scale data storage is rising exponentially, existing storage technologies are approaching their theoretical and functional limits in terms of density and energy consumption, making DNA based storage a potential solution for the future of data storage. Several studies introduced DNA based storage systems with high information density (petabytes/gram). However, DNA synthesis and sequencing technologies yield erroneous outputs. Algorithmic approaches for correcting these errors depend on reading multiple copies of each sequence and result in excessive reading costs. The unprecedented success of Transformers as a deep learning architecture for language modeling has led to its repurposing for solving a variety of tasks across various domains. In this work, we propose a novel approach for single-read reconstruction using an encoder-decoder Transformer architecture for DNA based data storage. We address the error correction process as a self-supervised sequence-to-sequence task and use synthetic noise injection to train the model using only the decoded reads. Our approach exploits the inherent redundancy of each decoded file to learn its underlying structure. To demonstrate our proposed approach, we encode text, image and code-script files to DNA, produce errors with high-fidelity error simulator, and reconstruct the original files from the noisy reads. Our model achieves lower error rates when reconstructing the original data from a single read of each DNA strand compared to state-of-the-art algorithms using 2-3 copies. This is the first demonstration of using deep learning models for single-read reconstruction in DNA based storage which allows for the reduction of the overall cost of the process. We show that this approach is applicable for various domains and can be generalized to new domains as well.
A Benchmark on Tricks for Large-scale Image Retrieval
Jul 27, 2019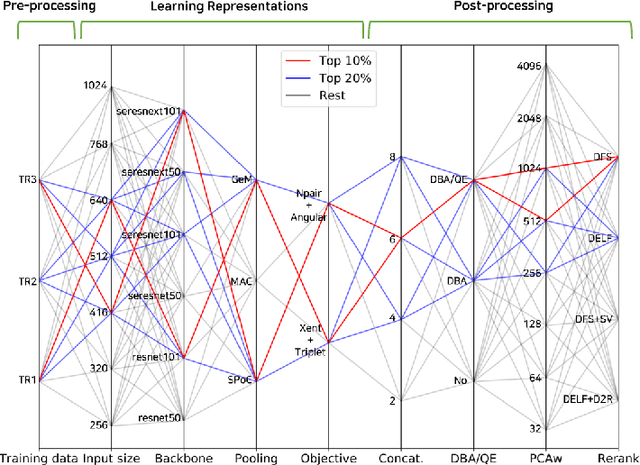
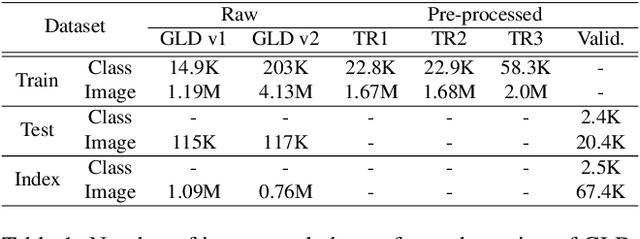

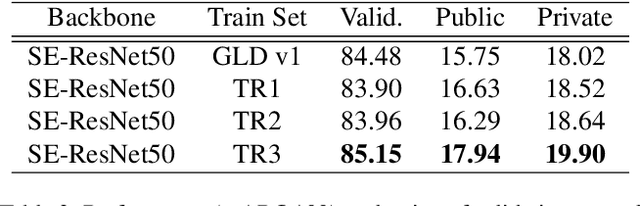
Many studies have been performed on metric learning, which has become a key ingredient in top-performing methods of instance-level image retrieval. Meanwhile, less attention has been paid to pre-processing and post-processing tricks that can significantly boost performance. Furthermore, we found that most previous studies used small scale datasets to simplify processing. Because the behavior of a feature representation in a deep learning model depends on both domain and data, it is important to understand how model behave in large-scale environments when a proper combination of retrieval tricks is used. In this paper, we extensively analyze the effect of well-known pre-processing, post-processing tricks, and their combination for large-scale image retrieval. We found that proper use of these tricks can significantly improve model performance without necessitating complex architecture or introducing loss, as confirmed by achieving a competitive result on the Google Landmark Retrieval Challenge 2019.
Correlation via synthesis: end-to-end nodule image generation and radiogenomic map learning based on generative adversarial network
Jul 08, 2019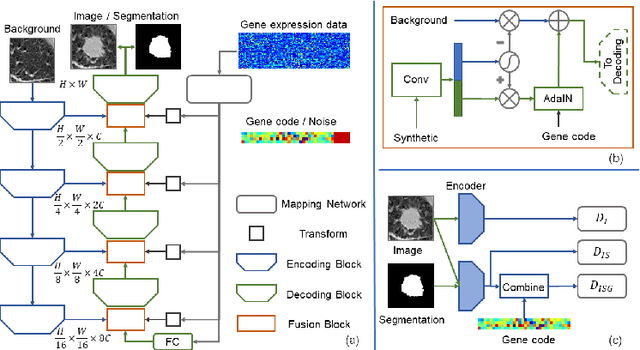

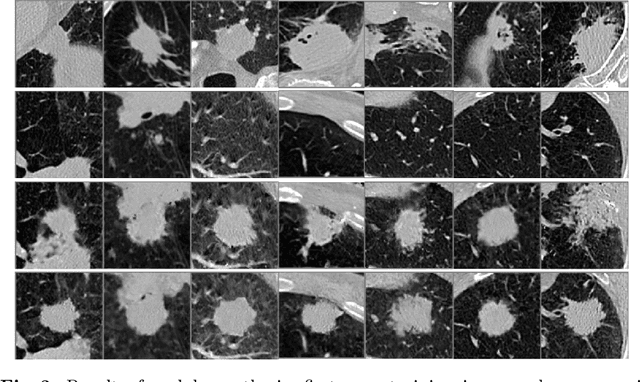
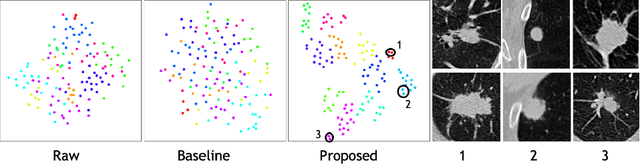
Radiogenomic map linking image features and gene expression profiles is useful for noninvasively identifying molecular properties of a particular type of disease. Conventionally, such map is produced in three separate steps: 1) gene-clustering to "metagenes", 2) image feature extraction, and 3) statistical correlation between metagenes and image features. Each step is independently performed and relies on arbitrary measurements. In this work, we investigate the potential of an end-to-end method fusing gene data with image features to generate synthetic image and learn radiogenomic map simultaneously. To achieve this goal, we develop a generative adversarial network (GAN) conditioned on both background images and gene expression profiles, synthesizing the corresponding image. Image and gene features are fused at different scales to ensure the realism and quality of the synthesized image. We tested our method on non-small cell lung cancer (NSCLC) dataset. Results demonstrate that the proposed method produces realistic synthetic images, and provides a promising way to find gene-image relationship in a holistic end-to-end manner.
Semantic Image Inpainting Through Improved Wasserstein Generative Adversarial Networks
Dec 03, 2018
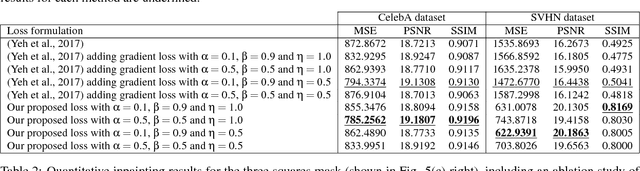

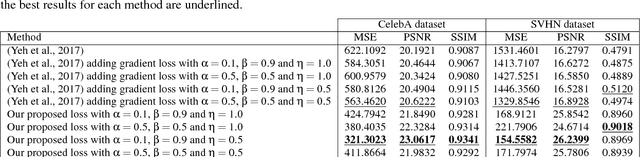
Image inpainting is the task of filling-in missing regions of a damaged or incomplete image. In this work we tackle this problem not only by using the available visual data but also by incorporating image semantics through the use of generative models. Our contribution is twofold: First, we learn a data latent space by training an improved version of the Wasserstein generative adversarial network, for which we incorporate a new generator and discriminator architecture. Second, the learned semantic information is combined with a new optimization loss for inpainting whose minimization infers the missing content conditioned by the available data. It takes into account powerful contextual and perceptual content inherent in the image itself. The benefits include the ability to recover large regions by accumulating semantic information even it is not fully present in the damaged image. Experiments show that the presented method obtains qualitative and quantitative top-tier results in different experimental situations and also achieves accurate photo-realism comparable to state-of-the-art works.
Multi-focus Noisy Image Fusion using Low-Rank Representation
Oct 09, 2018
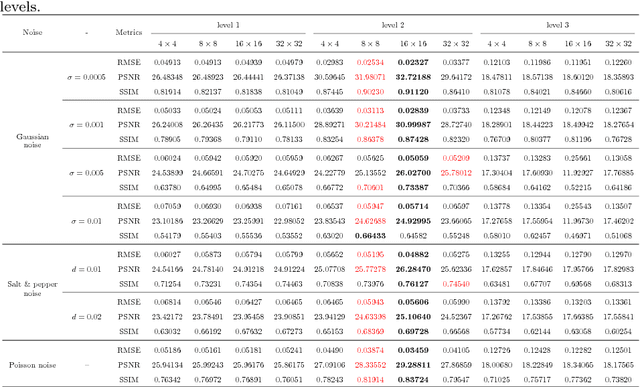
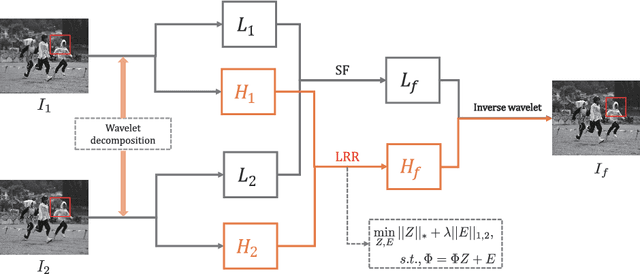
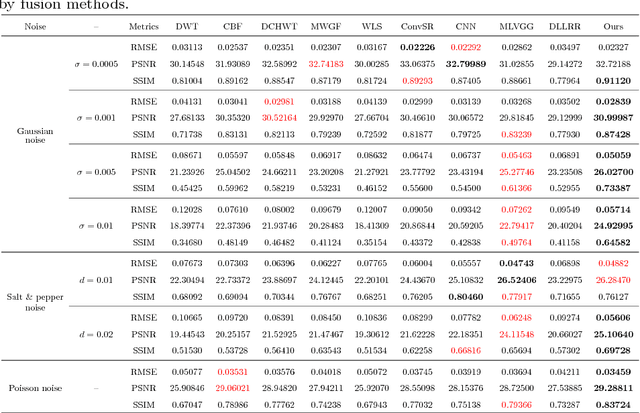
In the process of image acquisition, the noise is inevitable for source image. The multi-focus noisy image fusion is a very challenging task. However, there is no truly adaptive noisy image fusion approaches at present. As we all know, Low-Rank representation(LRR) is robust to noise and outliers. In this paper, we propose a novel fusion method based on LRR for multi-focus noisy image fusion. In the discrete wavelet transform(DWT) framework, the low frequency coefficients are fused by spatial frequency, the high frequency coefficients are fused by LRR coefficients and choose-max strategy. Finally, the fused image is obtained by inverse DWT. Experimental results demonstrate that the proposed algorithm can obtain state-of-the-art performance when the source images contain noise. The Code of our fusion method is available at https://github.com/exceptionLi/imagefusion_noisy_lrr
Teacher's pet: understanding and mitigating biases in distillation
Jul 08, 2021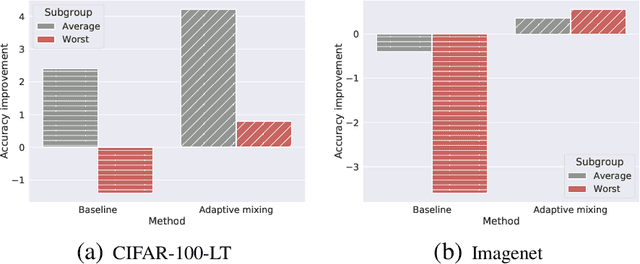

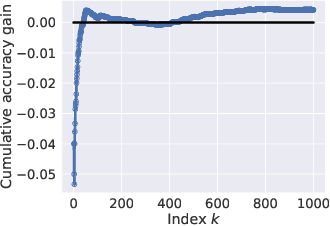
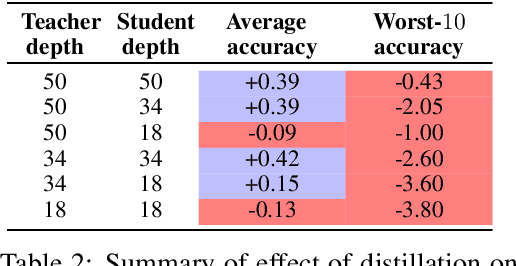
Knowledge distillation is widely used as a means of improving the performance of a relatively simple student model using the predictions from a complex teacher model. Several works have shown that distillation significantly boosts the student's overall performance; however, are these gains uniform across all data subgroups? In this paper, we show that distillation can harm performance on certain subgroups, e.g., classes with few associated samples. We trace this behaviour to errors made by the teacher distribution being transferred to and amplified by the student model. To mitigate this problem, we present techniques which soften the teacher influence for subgroups where it is less reliable. Experiments on several image classification benchmarks show that these modifications of distillation maintain boost in overall accuracy, while additionally ensuring improvement in subgroup performance.
TIPCB: A Simple but Effective Part-based Convolutional Baseline for Text-based Person Search
May 25, 2021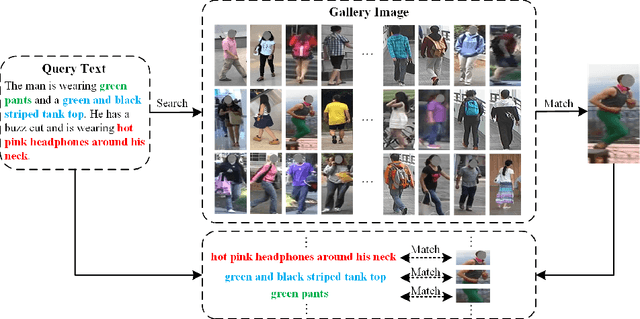
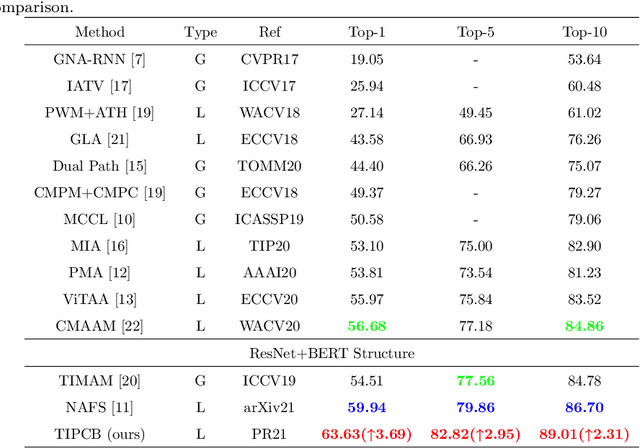
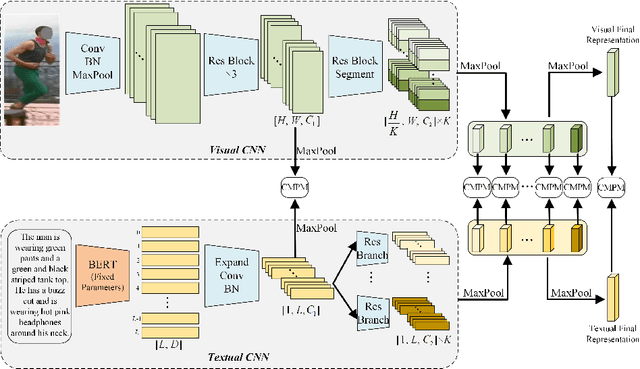
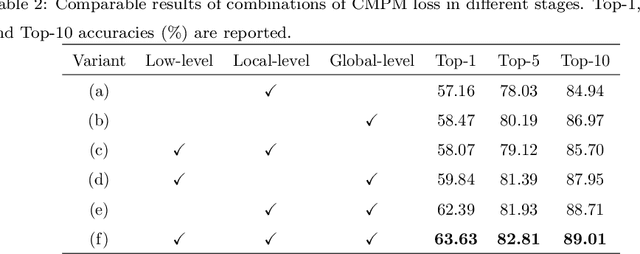
Text-based person search is a sub-task in the field of image retrieval, which aims to retrieve target person images according to a given textual description. The significant feature gap between two modalities makes this task very challenging. Many existing methods attempt to utilize local alignment to address this problem in the fine-grained level. However, most relevant methods introduce additional models or complicated training and evaluation strategies, which are hard to use in realistic scenarios. In order to facilitate the practical application, we propose a simple but effective end-to-end learning framework for text-based person search named TIPCB (i.e., Text-Image Part-based Convolutional Baseline). Firstly, a novel dual-path local alignment network structure is proposed to extract visual and textual local representations, in which images are segmented horizontally and texts are aligned adaptively. Then, we propose a multi-stage cross-modal matching strategy, which eliminates the modality gap from three feature levels, including low level, local level and global level. Extensive experiments are conducted on the widely-used benchmark dataset (CUHK-PEDES) and verify that our method outperforms the state-of-the-art methods by 3.69%, 2.95% and 2.31% in terms of Top-1, Top-5 and Top-10. Our code has been released in https://github.com/OrangeYHChen/TIPCB.
Assembly Planning by Recognizing a Graphical Instruction Manual
Jun 01, 2021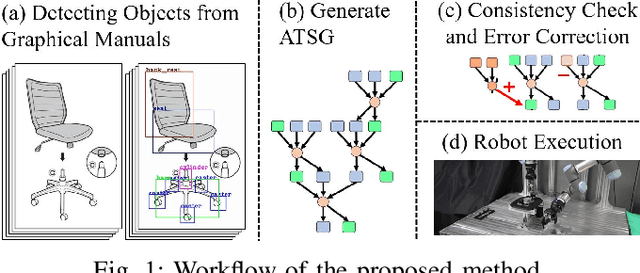
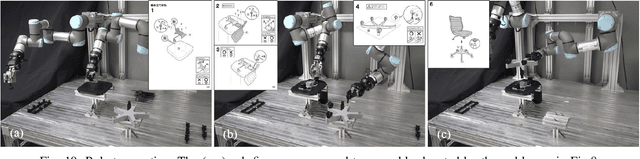
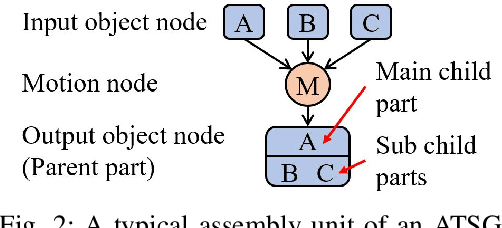
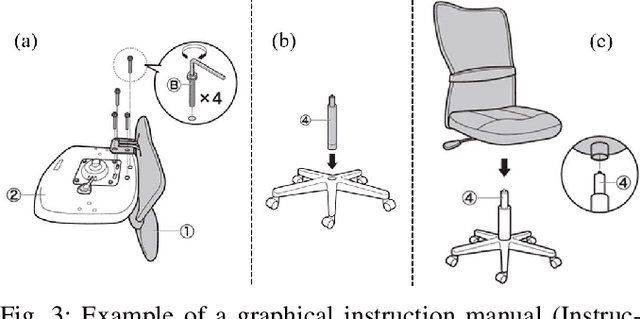
This paper proposes a robot assembly planning method by automatically reading the graphical instruction manuals design for humans. Essentially, the method generates an Assembly Task Sequence Graph (ATSG) by recognizing a graphical instruction manual. An ATSG is a graph describing the assembly task procedure by detecting types of parts included in the instruction images, completing the missing information automatically, and correcting the detection errors automatically. To build an ATSG, the proposed method first extracts the information of the parts contained in each image of the graphical instruction manual. Then, by using the extracted part information, it estimates the proper work motions and tools for the assembly task. After that, the method builds an ATSG by considering the relationship between the previous and following images, which makes it possible to estimate the undetected parts caused by occlusion using the information of the entire image series. Finally, by collating the total number of each part with the generated ATSG, the excess or deficiency of parts are investigated, and task procedures are removed or added according to those parts. In the experiment section, we build an ATSG using the proposed method to a graphical instruction manual for a chair and demonstrate the action sequences found in the ATSG can be performed by a dual-arm robot execution. The results show the proposed method is effective and simplifies robot teaching in automatic assembly.