 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SROBB: Targeted Perceptual Loss for Single Image Super-Resolution
Aug 20, 2019
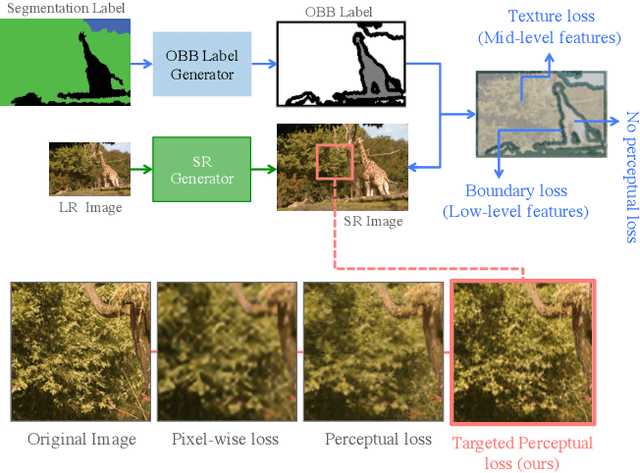
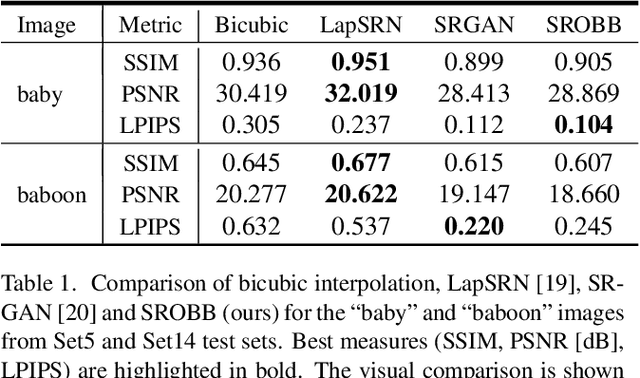

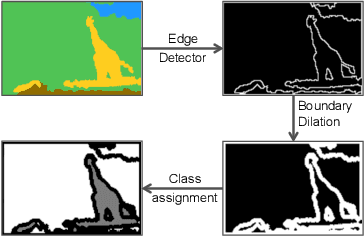
By benefiting from perceptual losses, recent studies have improved significantly the performance of the super-resolution task, where a high-resolution image is resolved from its low-resolution counterpart. Although such objective functions generate near-photorealistic results, their capability is limited, since they estimate the reconstruction error for an entire image in the same way, without considering any semantic information. In this paper, we propose a novel method to benefit from perceptual loss in a more objective way. We optimize a deep network-based decoder with a targeted objective function that penalizes images at different semantic levels using the corresponding terms. In particular, the proposed method leverages our proposed OBB (Object, Background and Boundary) labels, generated from segmentation labels, to estimate a suitable perceptual loss for boundaries, while considering texture similarity for backgrounds. We show that our proposed approach results in more realistic textures and sharper edges, and outperforms other state-of-the-art algorithms in terms of both qualitative results on standard benchmarks and results of extensive user studies.
Billion-scale semi-supervised learning for image classification
May 02, 2019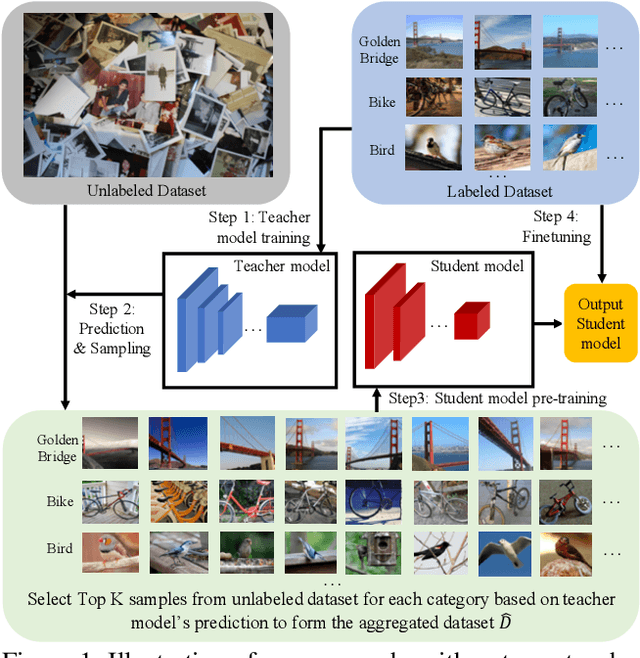

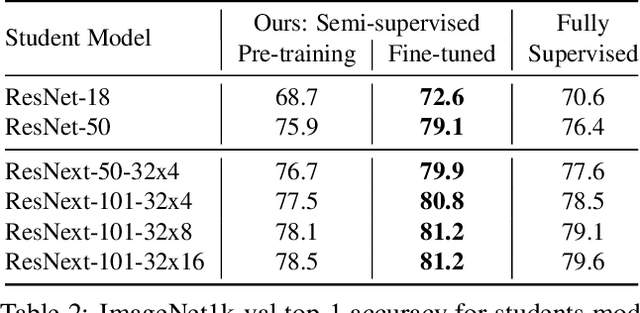
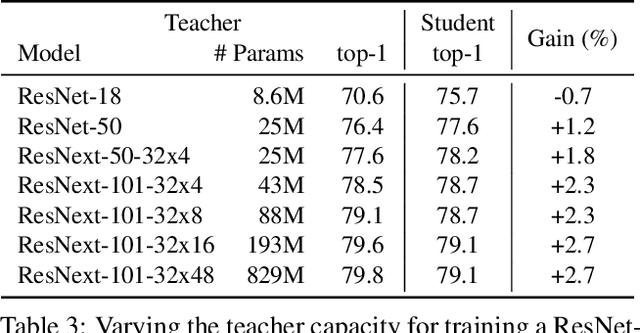
This paper presents a study of semi-supervised learning with large convolutional networks. We propose a pipeline, based on a teacher/student paradigm, that leverages a large collection of unlabelled images (up to 1 billion). Our main goal is to improve the performance for a given target architecture, like ResNet-50 or ResNext. We provide an extensive analysis of the success factors of our approach, which leads us to formulate some recommendations to produce high-accuracy models for image classification with semi-supervised learning. As a result, our approach brings important gains to standard architectures for image, video and fine-grained classification. For instance, by leveraging one billion unlabelled images, our learned vanilla ResNet-50 achieves 81.2% top-1 accuracy on the ImageNet benchmark.
Teacher-Student chain for efficient semi-supervised histology image classification
Mar 17, 2020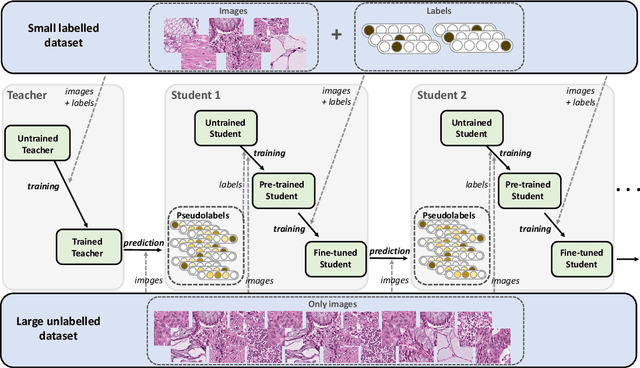

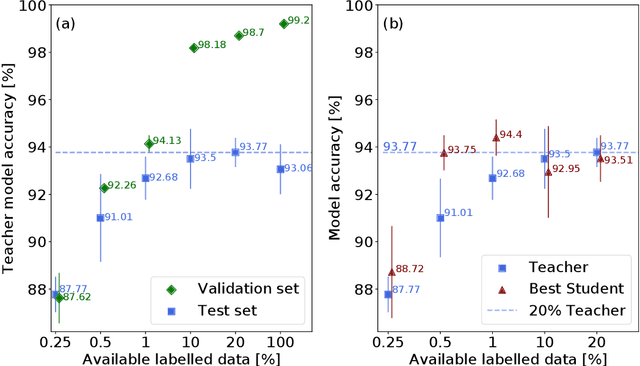
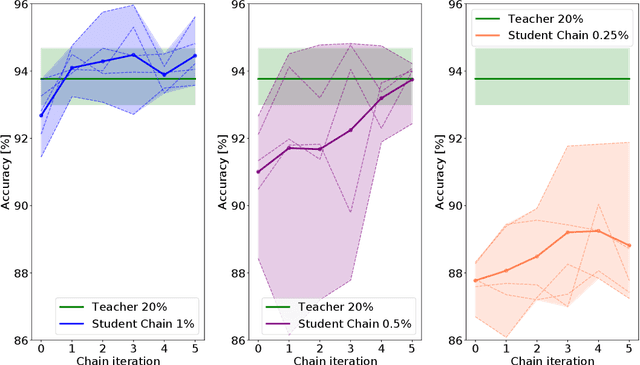
Deep learning shows great potential for the domain of digital pathology. An automated digital pathology system could serve as a second reader, perform initial triage in large screening studies, or assist in reporting. However, it is expensive to exhaustively annotate large histology image databases, since medical specialists are a scarce resource. In this paper, we apply the semi-supervised teacher-student knowledge distillation technique proposed by Yalniz et al. (2019) to the task of quantifying prognostic features in colorectal cancer. We obtain accuracy improvements through extending this approach to a chain of students, where each student's predictions are used to train the next student i.e. the student becomes the teacher. Using the chain approach, and only 0.5% labelled data (the remaining 99.5% in the unlabelled pool), we match the accuracy of training on 100% labelled data. At lower percentages of labelled data, similar gains in accuracy are seen, allowing some recovery of accuracy even from a poor initial choice of labelled training set. In conclusion, this approach shows promise for reducing the annotation burden, thus increasing the affordability of automated digital pathology systems.
A Strong and Robust Baseline for Text-Image Matching
Jun 04, 2019
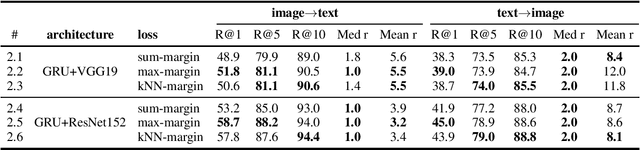
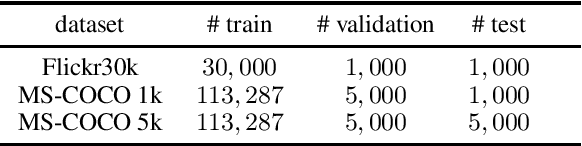
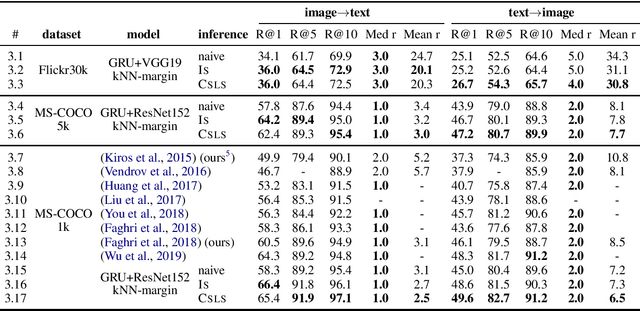
We review the current schemes of text-image matching models and propose improvements for both training and inference. First, we empirically show limitations of two popular loss (sum and max-margin loss) widely used in training text-image embeddings and propose a trade-off: a kNN-margin loss which 1) utilizes information from hard negatives and 2) is robust to noise as all $K$-most hardest samples are taken into account, tolerating \emph{pseudo} negatives and outliers. Second, we advocate the use of Inverted Softmax (\textsc{Is}) and Cross-modal Local Scaling (\textsc{Csls}) during inference to mitigate the so-called hubness problem in high-dimensional embedding space, enhancing scores of all metrics by a large margin.
SAT: 2D Semantics Assisted Training for 3D Visual Grounding
May 24, 2021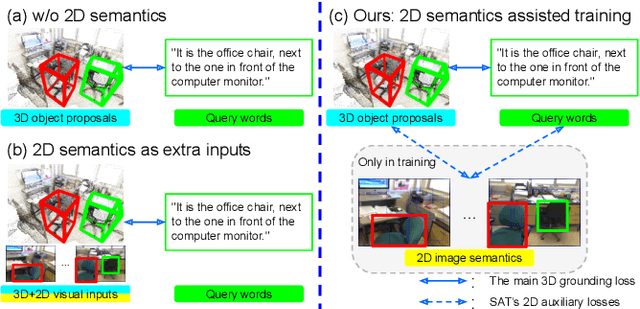
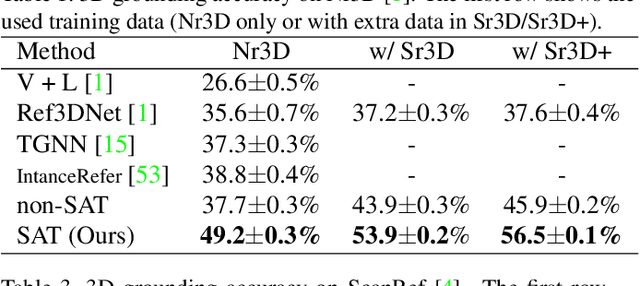
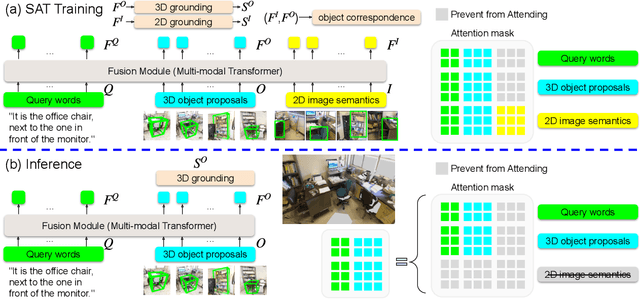
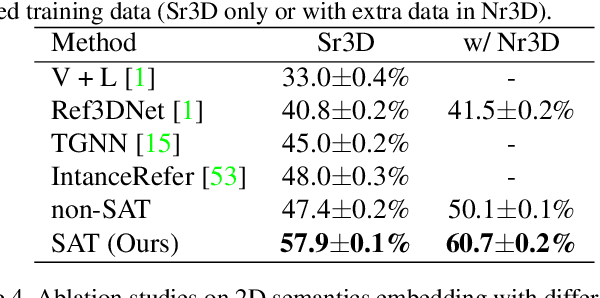
3D visual grounding aims at grounding a natural language description about a 3D scene, usually represented in the form of 3D point clouds, to the targeted object region. Point clouds are sparse, noisy, and contain limited semantic information compared with 2D images. These inherent limitations make the 3D visual grounding problem more challenging. In this study, we propose 2D Semantics Assisted Training (SAT) that utilizes 2D image semantics in the training stage to ease point-cloud-language joint representation learning and assist 3D visual grounding. The main idea is to learn auxiliary alignments between rich, clean 2D object representations and the corresponding objects or mentioned entities in 3D scenes. SAT takes 2D object semantics, i.e., object label, image feature, and 2D geometric feature, as the extra input in training but does not require such inputs during inference. By effectively utilizing 2D semantics in training, our approach boosts the accuracy on the Nr3D dataset from 37.7% to 49.2%, which significantly surpasses the non-SAT baseline with the identical network architecture and inference input. Our approach outperforms the state of the art by large margins on multiple 3D visual grounding datasets, i.e., +10.4% absolute accuracy on Nr3D, +9.9% on Sr3D, and +5.6% on ScanRef.
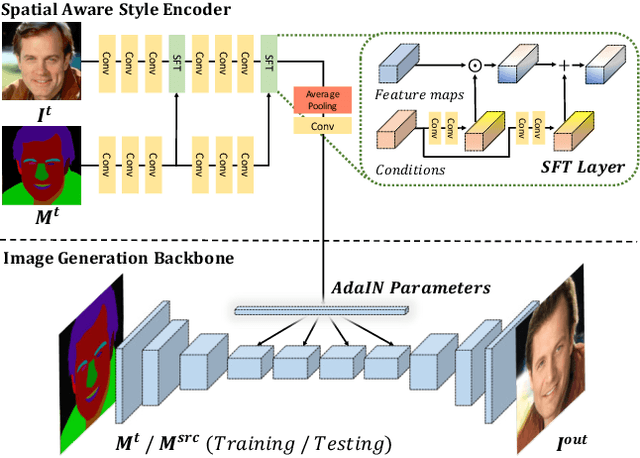
High-Fidelity and Arbitrary Face Editing
Mar 29, 2021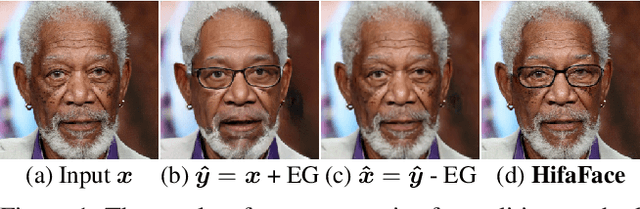
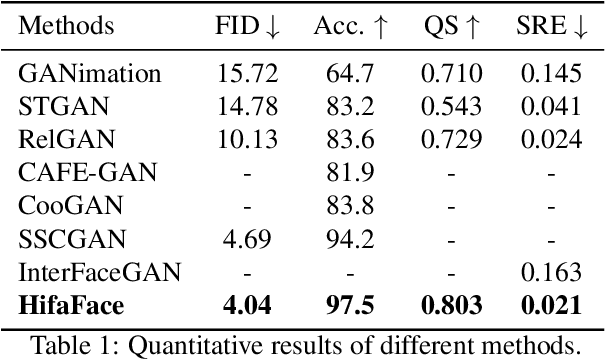


Cycle consistency is widely used for face editing. However, we observe that the generator tends to find a tricky way to hide information from the original image to satisfy the constraint of cycle consistency, making it impossible to maintain the rich details (e.g., wrinkles and moles) of non-editing areas. In this work, we propose a simple yet effective method named HifaFace to address the above-mentioned problem from two perspectives. First, we relieve the pressure of the generator to synthesize rich details by directly feeding the high-frequency information of the input image into the end of the generator. Second, we adopt an additional discriminator to encourage the generator to synthesize rich details. Specifically, we apply wavelet transformation to transform the image into multi-frequency domains, among which the high-frequency parts can be used to recover the rich details. We also notice that a fine-grained and wider-range control for the attribute is of great importance for face editing. To achieve this goal, we propose a novel attribute regression loss. Powered by the proposed framework, we achieve high-fidelity and arbitrary face editing, outperforming other state-of-the-art approaches.
Localized Adversarial Training for Increased Accuracy and Robustness in Image Classification
Sep 10, 2019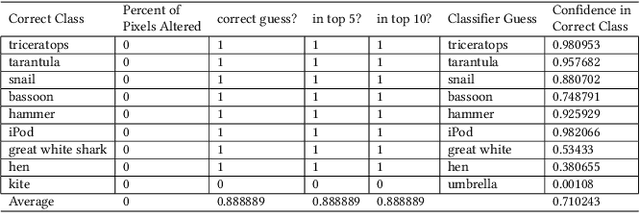

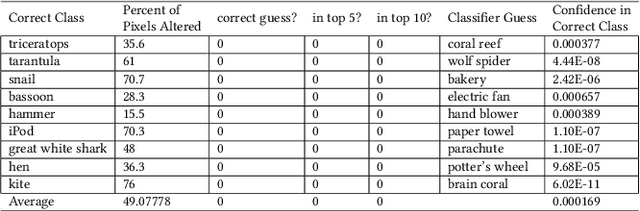
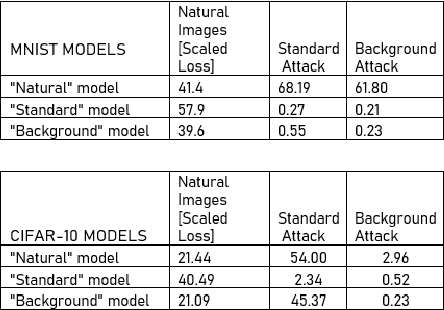
Today's state-of-the-art image classifiers fail to correctly classify carefully manipulated adversarial images. In this work, we develop a new, localized adversarial attack that generates adversarial examples by imperceptibly altering the backgrounds of normal images. We first use this attack to highlight the unnecessary sensitivity of neural networks to changes in the background of an image, then use it as part of a new training technique: localized adversarial training. By including locally adversarial images in the training set, we are able to create a classifier that suffers less loss than a non-adversarially trained counterpart model on both natural and adversarial inputs. The evaluation of our localized adversarial training algorithm on MNIST and CIFAR-10 datasets shows decreased accuracy loss on natural images, and increased robustness against adversarial inputs.
Noise Entangled GAN For Low-Dose CT Simulation
Feb 18, 2021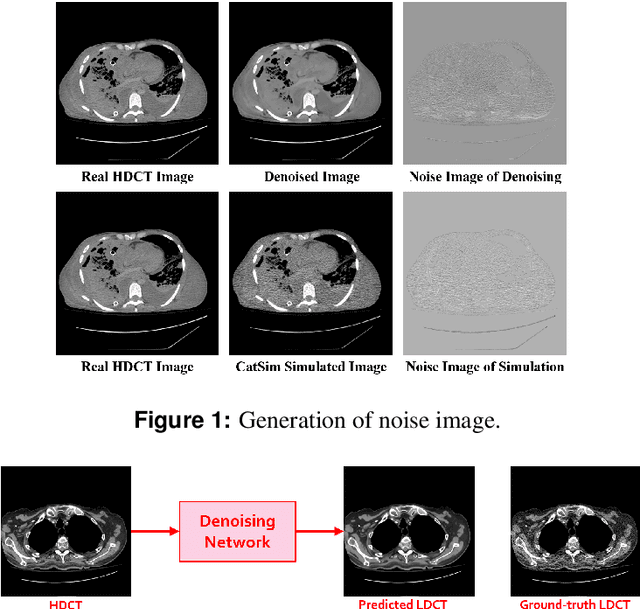
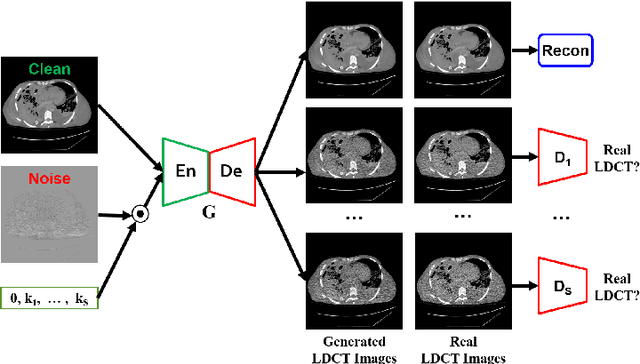
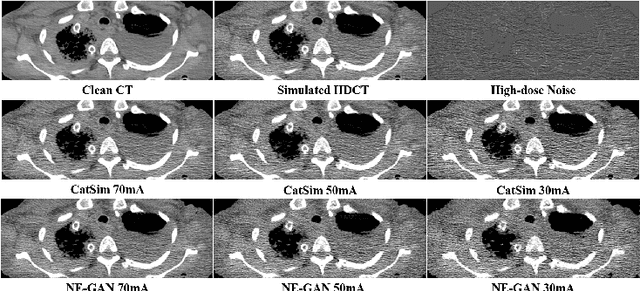
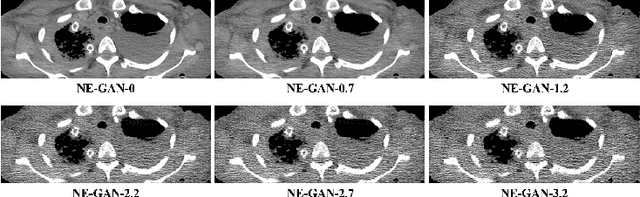
We propose a Noise Entangled GAN (NE-GAN) for simulating low-dose computed tomography (CT) images from a higher dose CT image. First, we present two schemes to generate a clean CT image and a noise image from the high-dose CT image. Then, given these generated images, an NE-GAN is proposed to simulate different levels of low-dose CT images, where the level of generated noise can be continuously controlled by a noise factor. NE-GAN consists of a generator and a set of discriminators, and the number of discriminators is determined by the number of noise levels during training. Compared with the traditional methods based on the projection data that are usually unavailable in real applications, NE-GAN can directly learn from the real and/or simulated CT images and may create low-dose CT images quickly without the need of raw data or other proprietary CT scanner information. The experimental results show that the proposed method has the potential to simulate realistic low-dose CT images.
MaskGAN: Towards Diverse and Interactive Facial Image Manipulation
Jul 27, 2019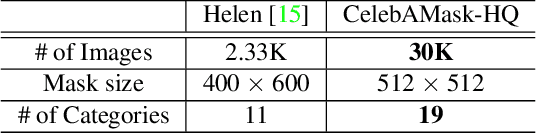
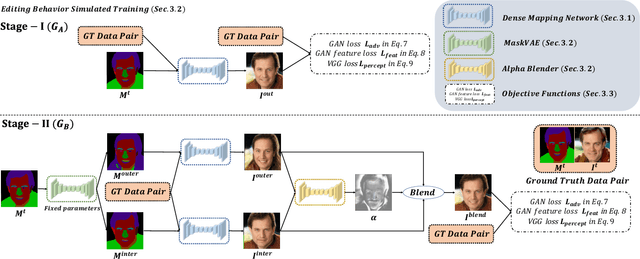
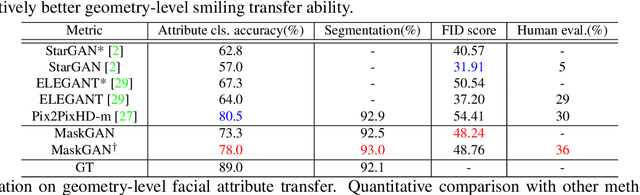
Facial image manipulation has achieved great progresses in recent years. However, previous methods either operate on a predefined set of face attributes or leave users little freedom to interactively manipulate images. To overcome these drawbacks, we propose a novel framework termed MaskGAN, enabling diverse and interactive face manipulation. Our key insight is that semantic masks serve as a suitable intermediate representation for flexible face manipulation with fidelity preservation. MaskGAN has two main components: 1) Dense Mapping Network, and 2) Editing Behavior Simulated Training. Specifically, Dense mapping network learns style mapping between a free-form user modified mask and a target image, enabling diverse generation results. Editing behavior simulated training models the user editing behavior on the source mask, making the overall framework more robust to various manipulated inputs. To facilitate extensive studies, we construct a large-scale high-resolution face dataset with fine-grained mask annotations named CelebAMask-HQ. MaskGAN is comprehensively evaluated on two challenging tasks: attribute transfer and style copy, demonstrating superior performance over other state-of-the-art methods. The code, models and dataset are available at \url{https://github.com/switchablenorms/CelebAMask-HQ}.
A Contactless Fingerprint Recognition System
Aug 20, 2021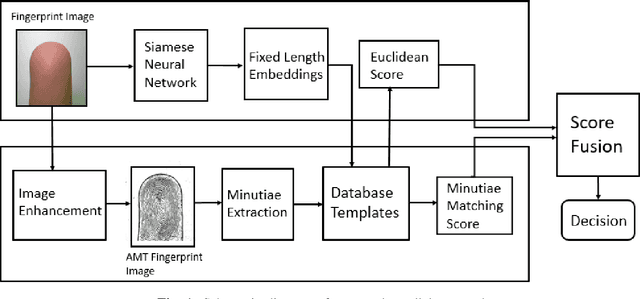
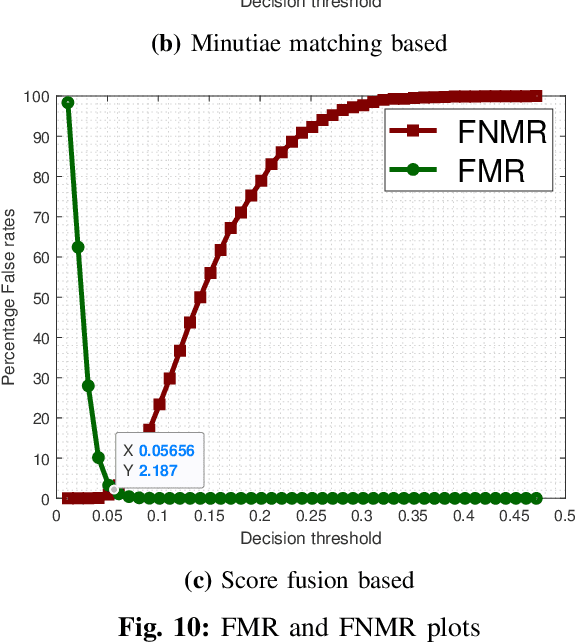
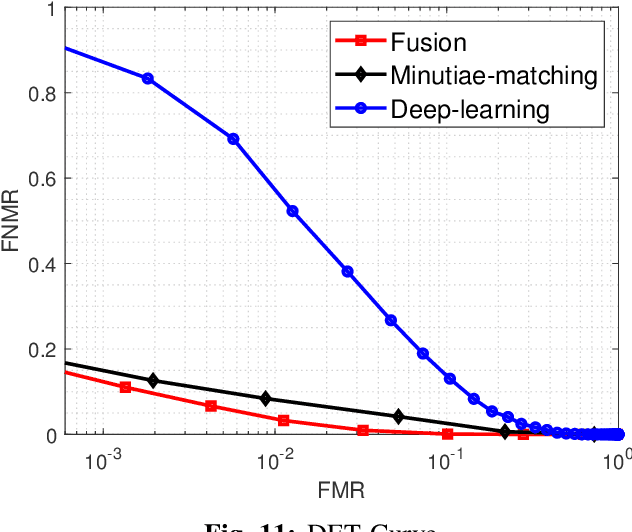
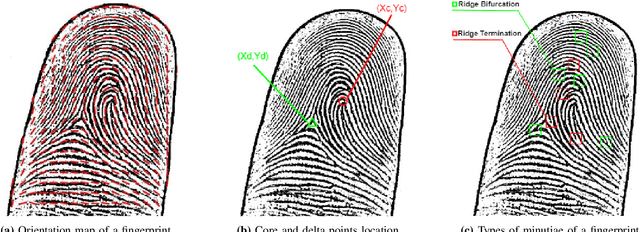
Fingerprints are one of the most widely explored biometric traits. Specifically, contact-based fingerprint recognition systems reign supreme due to their robustness, portability and the extensive research work done in the field. However, these systems suffer from issues such as hygiene, sensor degradation due to constant physical contact, and latent fingerprint threats. In this paper, we propose an approach for developing a contactless fingerprint recognition system that captures finger photo from a distance using an image sensor in a suitable environment. The captured finger photos are then processed further to obtain global and local (minutiae-based) features. Specifically, a Siamese convolutional neural network (CNN) is designed to extract global features from a given finger photo. The proposed system computes matching scores from CNN-based features and minutiae-based features. Finally, the two scores are fused to obtain the final matching score between the probe and reference fingerprint templates. Most importantly, the proposed system is developed using the Nvidia Jetson Nano development kit, which allows us to perform contactless fingerprint recognition in real-time with minimum latency and acceptable matching accuracy. The performance of the proposed system is evaluated on an in-house IITI contactless fingerprint dataset (IITI-CFD) containing 105train and 100 test subjects. The proposed system achieves an equal-error-rate of 2.19% on IITI-CFD.