 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PAS-MEF: Multi-exposure image fusion based on principal component analysis, adaptive well-exposedness and saliency map
May 25, 2021
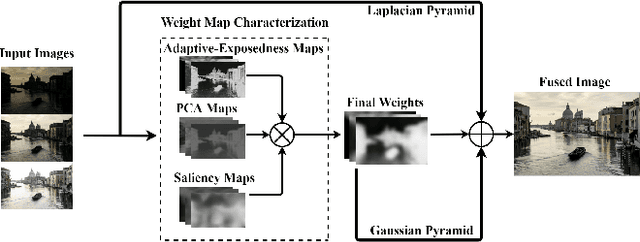
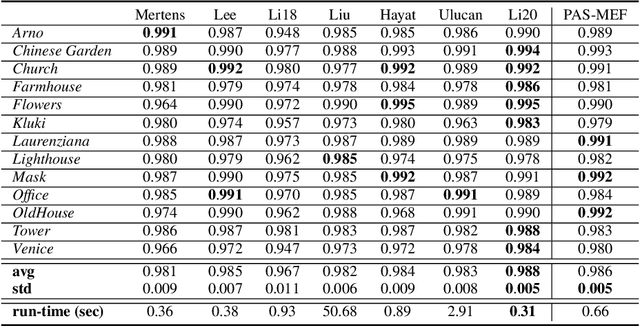


High dynamic range (HDR) imaging enables to immortalize natural scenes similar to the way that they are perceived by human observers. With regular low dynamic range (LDR) capture/display devices, significant details may not be preserved in images due to the huge dynamic range of natural scenes. To minimize the information loss and produce high quality HDR-like images for LDR screens, this study proposes an efficient multi-exposure fusion (MEF) approach with a simple yet effective weight extraction method relying on principal component analysis, adaptive well-exposedness and saliency maps. These weight maps are later refined through a guided filter and the fusion is carried out by employing a pyramidal decomposition. Experimental comparisons with existing techniques demonstrate that the proposed method produces very strong statistical and visual results.
Teacher-Student chain for efficient semi-supervised histology image classification
Mar 20, 2020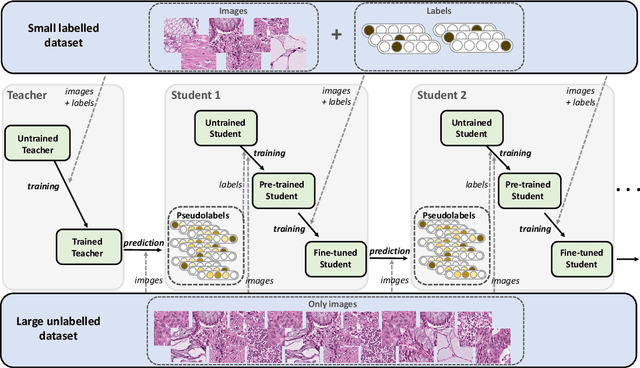

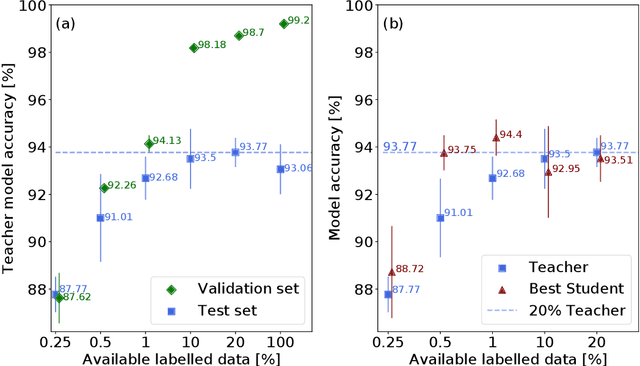
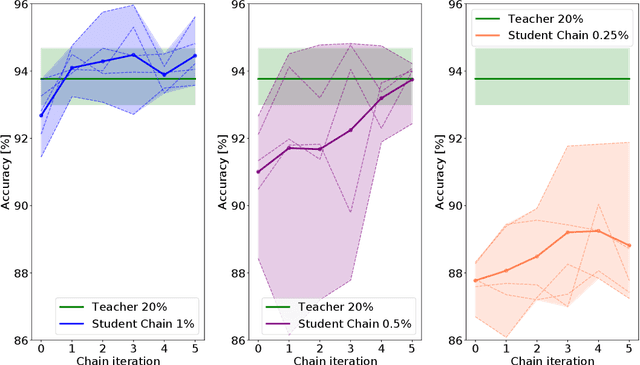
Deep learning shows great potential for the domain of digital pathology. An automated digital pathology system could serve as a second reader, perform initial triage in large screening studies, or assist in reporting. However, it is expensive to exhaustively annotate large histology image databases, since medical specialists are a scarce resource. In this paper, we apply the semi-supervised teacher-student knowledge distillation technique proposed by Yalniz et al. (2019) to the task of quantifying prognostic features in colorectal cancer. We obtain accuracy improvements through extending this approach to a chain of students, where each student's predictions are used to train the next student i.e. the student becomes the teacher. Using the chain approach, and only 0.5% labelled data (the remaining 99.5% in the unlabelled pool), we match the accuracy of training on 100% labelled data. At lower percentages of labelled data, similar gains in accuracy are seen, allowing some recovery of accuracy even from a poor initial choice of labelled training set. In conclusion, this approach shows promise for reducing the annotation burden, thus increasing the affordability of automated digital pathology systems.
UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation
Jan 28, 2020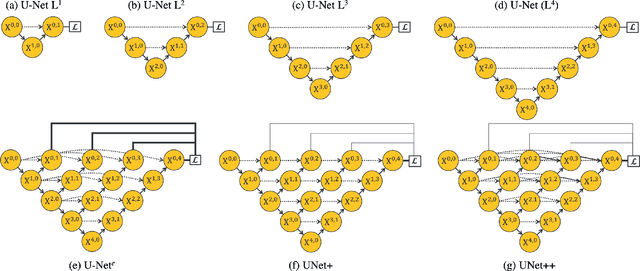

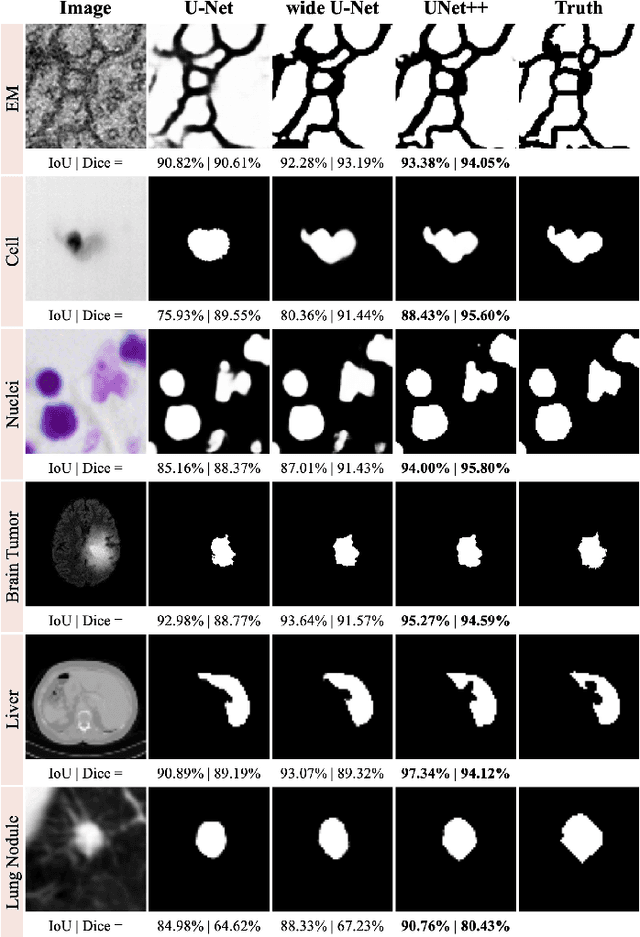
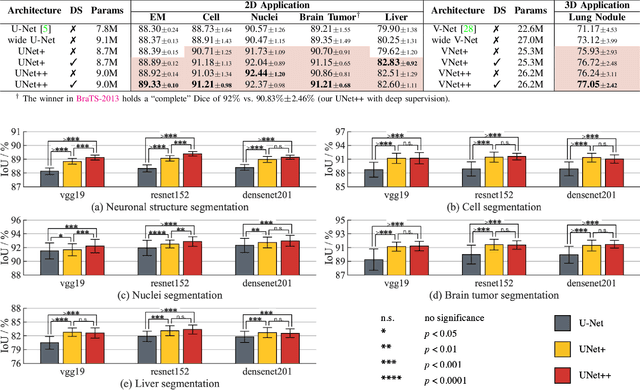
The state-of-the-art models for medical image segmentation are variants of U-Net and fully convolutional networks (FCN). Despite their success, these models have two limitations: (1) their optimal depth is apriori unknown, requiring extensive architecture search or inefficient ensemble of models of varying depths; and (2) their skip connections impose an unnecessarily restrictive fusion scheme, forcing aggregation only at the same-scale feature maps of the encoder and decoder sub-networks. To overcome these two limitations, we propose UNet++, a new neural architecture for semantic and instance segmentation, by (1) alleviating the unknown network depth with an efficient ensemble of U-Nets of varying depths, which partially share an encoder and co-learn simultaneously using deep supervision; (2) redesigning skip connections to aggregate features of varying semantic scales at the decoder sub-networks, leading to a highly flexible feature fusion scheme; and (3) devising a pruning scheme to accelerate the inference speed of UNet++. We have evaluated UNet++ using six different medical image segmentation datasets, covering multiple imaging modalities such as computed tomography (CT), magnetic resonance imaging (MRI), and electron microscopy (EM), and demonstrating that (1) UNet++ consistently outperforms the baseline models for the task of semantic segmentation across different datasets and backbone architectures; (2) UNet++ enhances segmentation quality of varying-size objects -- an improvement over the fixed-depth U-Net; (3) Mask RCNN++ (Mask R-CNN with UNet++ design) outperforms the original Mask R-CNN for the task of instance segmentation; and (4) pruned UNet++ models achieve significant speedup while showing only modest performance degradation. Our implementation and pre-trained models are available at https://github.com/MrGiovanni/UNetPlusPlus.
MLReal: Bridging the gap between training on synthetic data and real data applications in machine learning
Sep 11, 2021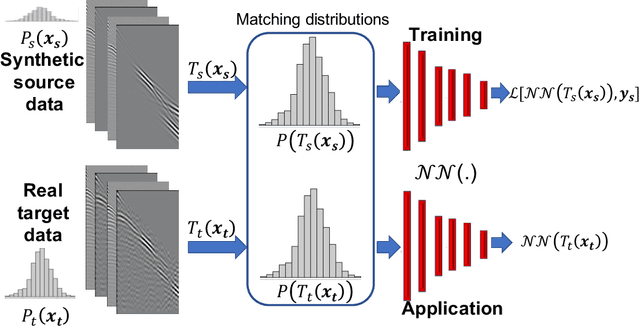
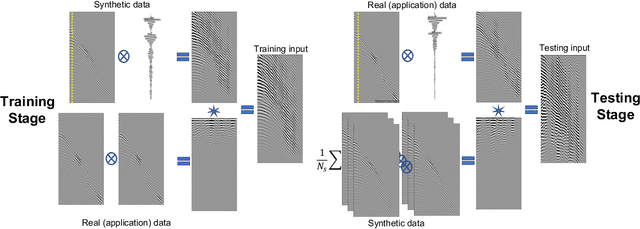
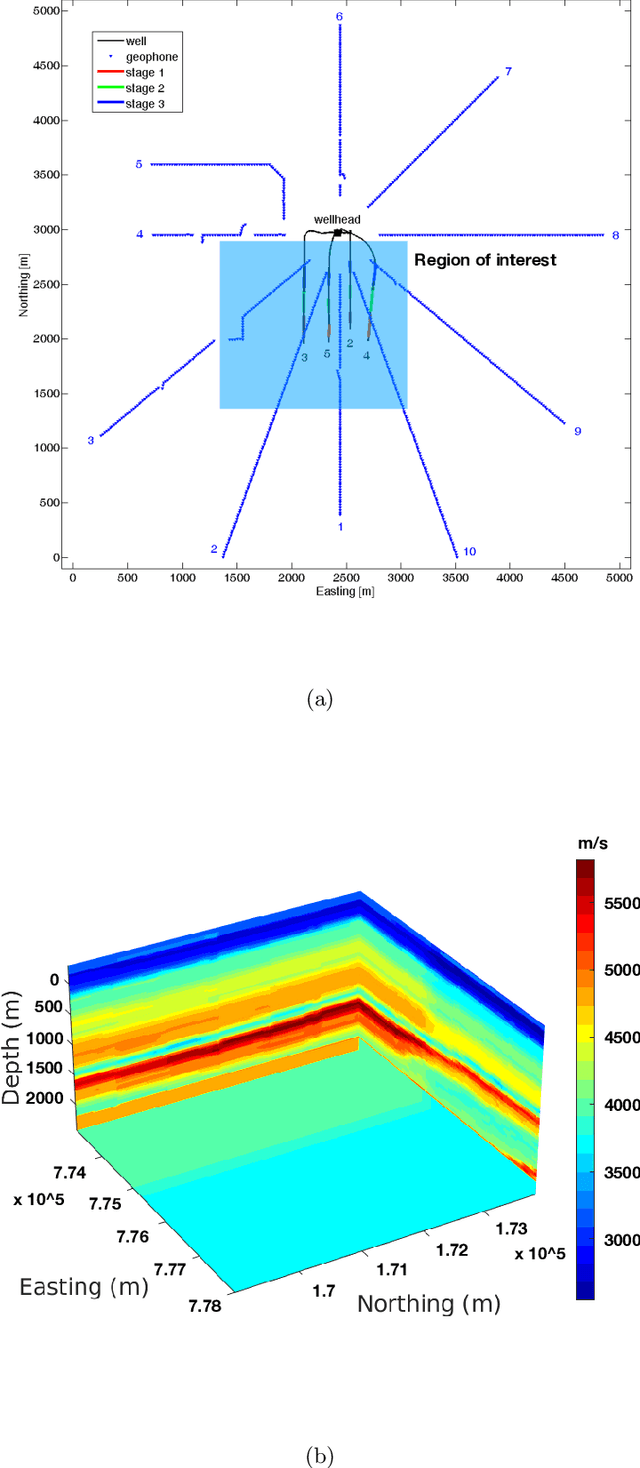
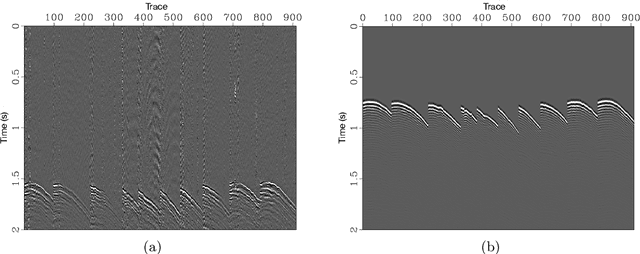
Among the biggest challenges we face in utilizing neural networks trained on waveform data (i.e., seismic, electromagnetic, or ultrasound) is its application to real data. The requirement for accurate labels forces us to develop solutions using synthetic data, where labels are readily available. However, synthetic data often do not capture the reality of the field/real experiment, and we end up with poor performance of the trained neural network (NN) at the inference stage. We describe a novel approach to enhance supervised training on synthetic data with real data features (domain adaptation). Specifically, for tasks in which the absolute values of the vertical axis (time or depth) of the input data are not crucial, like classification, or can be corrected afterward, like velocity model building using a well-log, we suggest a series of linear operations on the input so the training and application data have similar distributions. This is accomplished by applying two operations on the input data to the NN model: 1) The crosscorrelation of the input data (i.e., shot gather, seismic image, etc.) with a fixed reference trace from the same dataset. 2) The convolution of the resulting data with the mean (or a random sample) of the autocorrelated data from another domain. In the training stage, the input data are from the synthetic domain and the auto-correlated data are from the real domain, and random samples from real data are drawn at every training epoch. In the inference/application stage, the input data are from the real subset domain and the mean of the autocorrelated sections are from the synthetic data subset domain. Example applications on passive seismic data for microseismic event source location determination and active seismic data for predicting low frequencies are used to demonstrate the power of this approach in improving the applicability of trained models to real data.
An XAI Approach to Deep Learning Models in the Detection of Ductal Carcinoma in Situ
Jun 27, 2021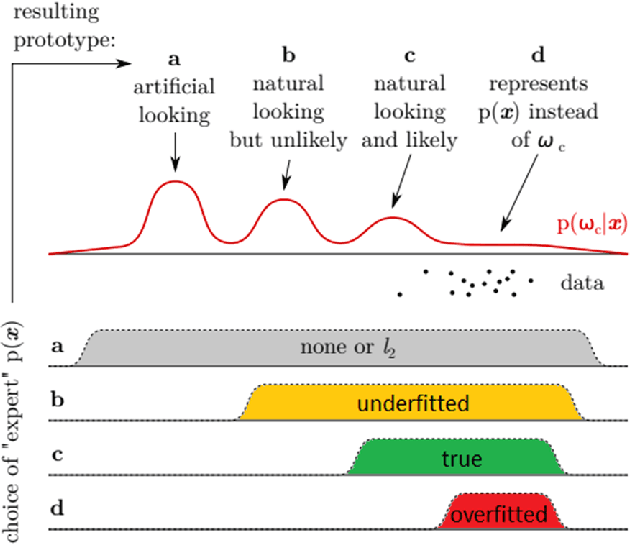
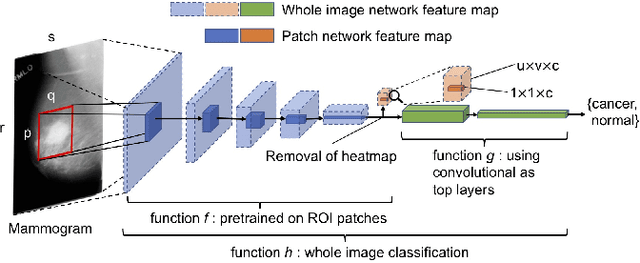
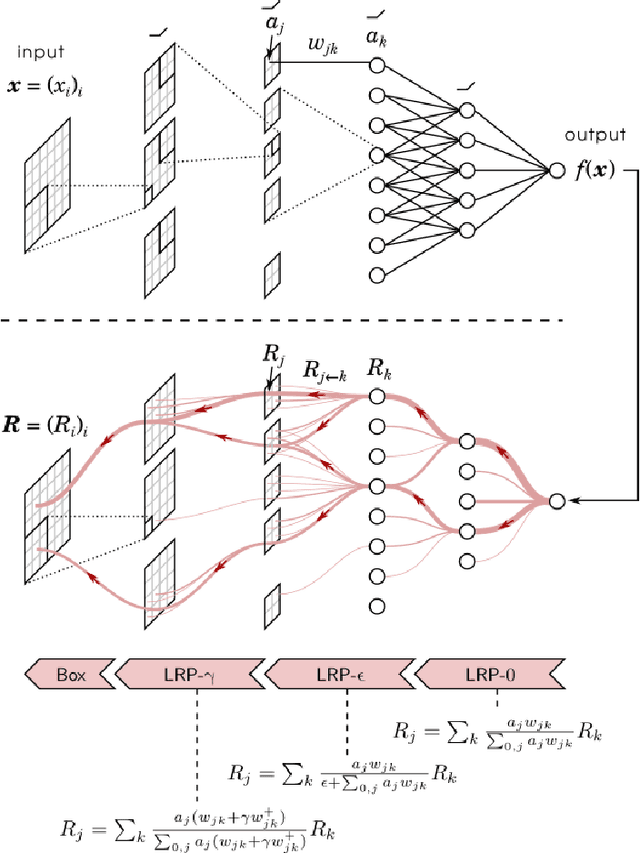
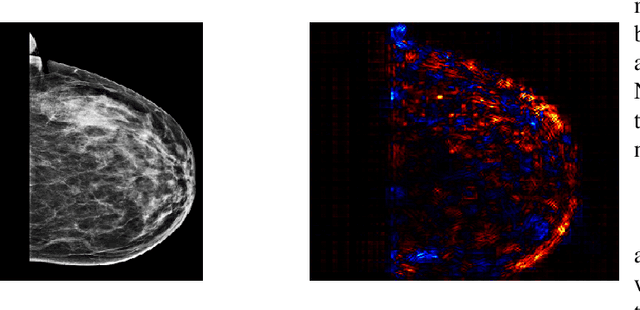
During the last decade or so, there has been an insurgence in the deep learning community to solve health-related issues, particularly breast cancer. Following the Camelyon-16 challenge in 2016, several researchers have dedicated their time to build Convolutional Neural Networks (CNNs) to help radiologists and other clinicians diagnose breast cancer. In particular, there has been an emphasis on Ductal Carcinoma in Situ (DCIS); the clinical term for early-stage breast cancer. Large companies have given their fair share of research into this subject, among these Google Deepmind who developed a model in 2020 that has proven to be better than radiologists themselves to diagnose breast cancer correctly. We found that among the issues which exist, there is a need for an explanatory system that goes through the hidden layers of a CNN to highlight those pixels that contributed to the classification of a mammogram. We then chose an open-source, reasonably successful project developed by Prof. Shen, using the CBIS-DDSM image database to run our experiments on. It was later improved using the Resnet-50 and VGG-16 patch-classifiers, analytically comparing the outcome of both. The results showed that the Resnet-50 one converged earlier in the experiments. Following the research by Montavon and Binder, we used the DeepTaylor Layer-wise Relevance Propagation (LRP) model to highlight those pixels and regions within a mammogram which contribute most to its classification. This is represented as a map of those pixels in the original image, which contribute to the diagnosis and the extent to which they contribute to the final classification. The most significant advantage of this algorithm is that it performs exceptionally well with the Resnet-50 patch classifier architecture.
Membership Inference Attacks on Lottery Ticket Networks
Aug 07, 2021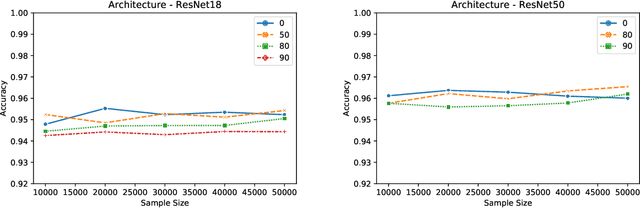
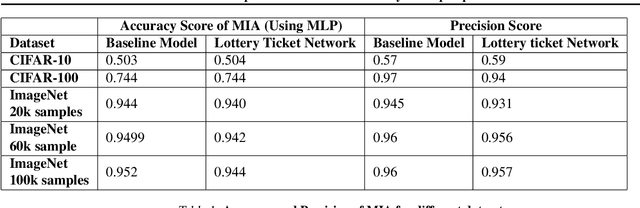
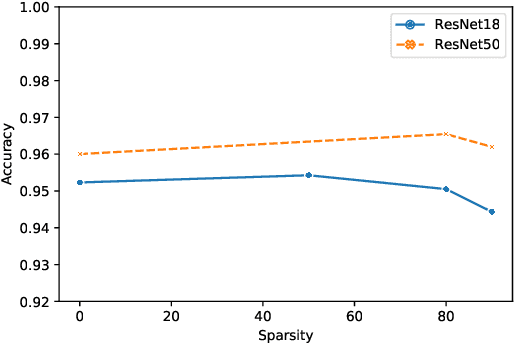
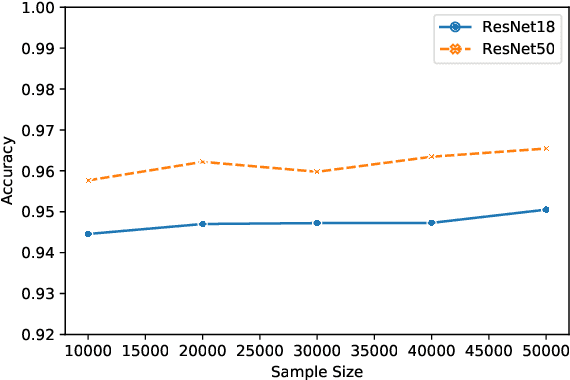
The vulnerability of the Lottery Ticket Hypothesis has not been studied from the purview of Membership Inference Attacks. Through this work, we are the first to empirically show that the lottery ticket networks are equally vulnerable to membership inference attacks. A Membership Inference Attack (MIA) is the process of determining whether a data sample belongs to a training set of a trained model or not. Membership Inference Attacks could leak critical information about the training data that can be used for targeted attacks. Recent deep learning models often have very large memory footprints and a high computational cost associated with training and drawing inferences. Lottery Ticket Hypothesis is used to prune the networks to find smaller sub-networks that at least match the performance of the original model in terms of test accuracy in a similar number of iterations. We used CIFAR-10, CIFAR-100, and ImageNet datasets to perform image classification tasks and observe that the attack accuracies are similar. We also see that the attack accuracy varies directly according to the number of classes in the dataset and the sparsity of the network. We demonstrate that these attacks are transferable across models with high accuracy.
Beyond pixel-wise supervision for segmentation: A few global shape descriptors might be surprisingly good!
May 03, 2021

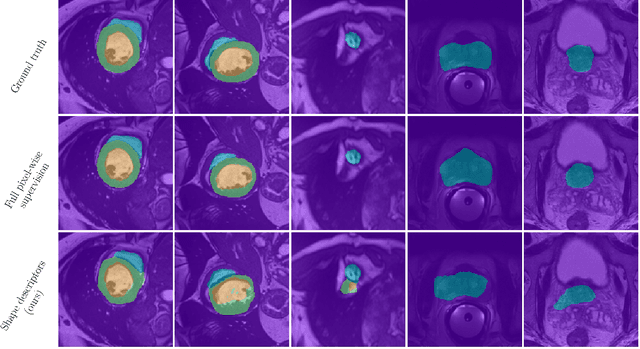
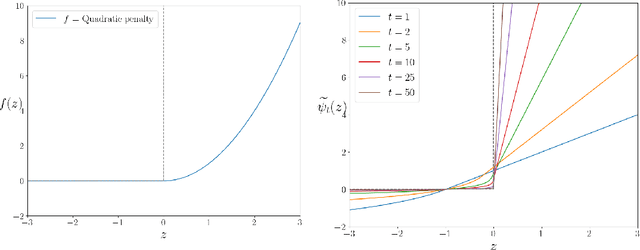
Standard losses for training deep segmentation networks could be seen as individual classifications of pixels, instead of supervising the global shape of the predicted segmentations. While effective, they require exact knowledge of the label of each pixel in an image. This study investigates how effective global geometric shape descriptors could be, when used on their own as segmentation losses for training deep networks. Not only interesting theoretically, there exist deeper motivations to posing segmentation problems as a reconstruction of shape descriptors: Annotations to obtain approximations of low-order shape moments could be much less cumbersome than their full-mask counterparts, and anatomical priors could be readily encoded into invariant shape descriptions, which might alleviate the annotation burden. Also, and most importantly, we hypothesize that, given a task, certain shape descriptions might be invariant across image acquisition protocols/modalities and subject populations, which might open interesting research avenues for generalization in medical image segmentation. We introduce and formulate a few shape descriptors in the context of deep segmentation, and evaluate their potential as standalone losses on two different challenging tasks. Inspired by recent works in constrained optimization for deep networks, we propose a way to use those descriptors to supervise segmentation, without any pixel-level label. Very surprisingly, as little as 4 descriptors values per class can approach the performance of a segmentation mask with 65k individual discrete labels. We also found that shape descriptors can be a valid way to encode anatomical priors about the task, enabling to leverage expert knowledge without additional annotations. Our implementation is publicly available and can be easily extended to other tasks and descriptors: https://github.com/hkervadec/shape_descriptors
Deep MR Image Super-Resolution Using Structural Priors
Sep 10, 2018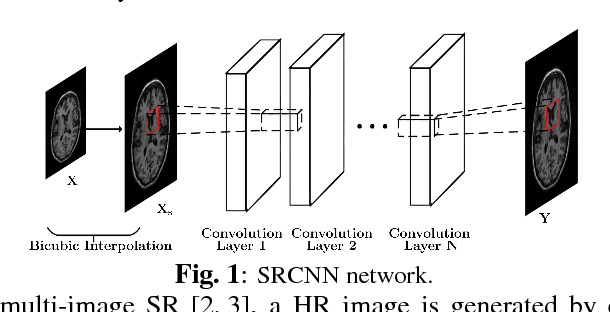
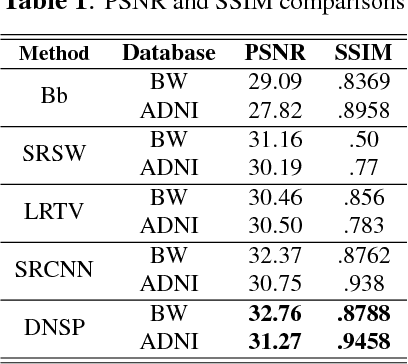
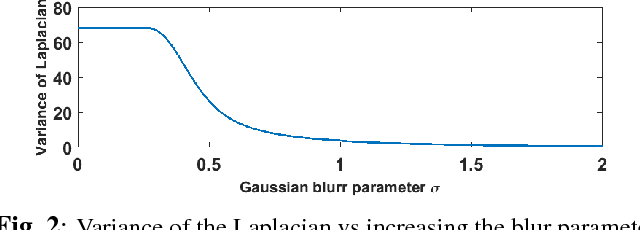
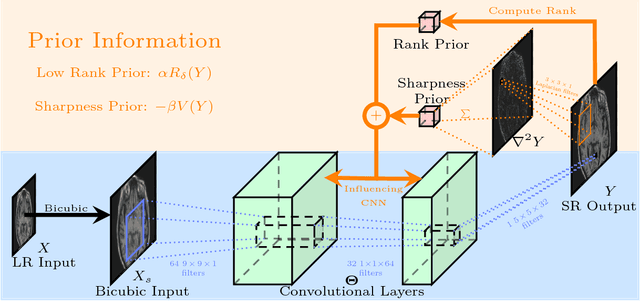
High resolution magnetic resonance (MR) images are desired for accurate diagnostics. In practice, image resolution is restricted by factors like hardware, cost and processing constraints. Recently, deep learning methods have been shown to produce compelling state of the art results for image super-resolution. Paying particular attention to desired hi-resolution MR image structure, we propose a new regularized network that exploits image priors, namely a low-rank structure and a sharpness prior to enhance deep MR image superresolution. Our contributions are then incorporating these priors in an analytically tractable fashion in the learning of a convolutional neural network (CNN) that accomplishes the super-resolution task. This is particularly challenging for the low rank prior, since the rank is not a differentiable function of the image matrix (and hence the network parameters), an issue we address by pursuing differentiable approximations of the rank. Sharpness is emphasized by the variance of the Laplacian which we show can be implemented by a fixed {\em feedback} layer at the output of the network. Experiments performed on two publicly available MR brain image databases exhibit promising results particularly when training imagery is limited.
NODE: Extreme Low Light Raw Image Denoising using a Noise Decomposition Network
Sep 11, 2019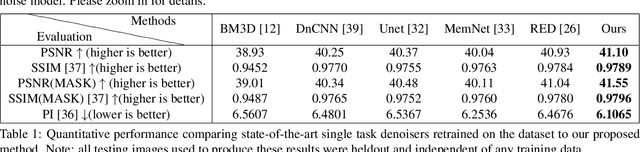
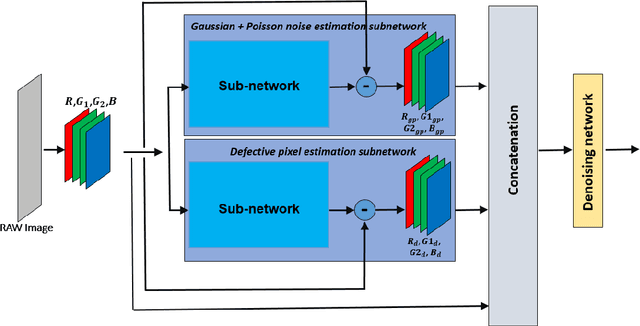

Denoising extreme low light images is a challenging task due to the high noise level. When the illumination is low, digital cameras increase the ISO (electronic gain) to amplify the brightness of captured data. However, this in turn amplifies the noise, arising from read, shot, and defective pixel sources. In the raw domain, read and shot noise are effectively modelled using Gaussian and Poisson distributions respectively, whereas defective pixels can be modeled with impulsive noise. In extreme low light imaging, noise removal becomes a critical challenge to produce a high quality, detailed image with low noise. In this paper, we propose a multi-task deep neural network called Noise Decomposition (NODE) that explicitly and separately estimates defective pixel noise, in conjunction with Gaussian and Poisson noise, to denoise an extreme low light image. Our network is purposely designed to work with raw data, for which the noise is more easily modeled before going through non-linear transformations in the image signal processing (ISP) pipeline. Quantitative and qualitative evaluation show the proposed method to be more effective at denoising real raw images than state-of-the-art techniques.
ReS2tAC -- UAV-Borne Real-Time SGM Stereo Optimized for Embedded ARM and CUDA Devices
Jun 15, 2021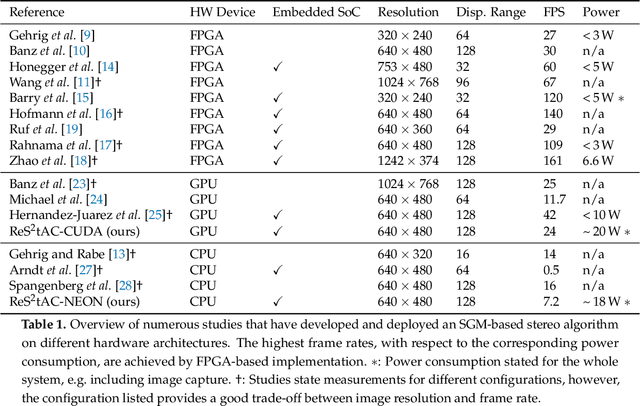

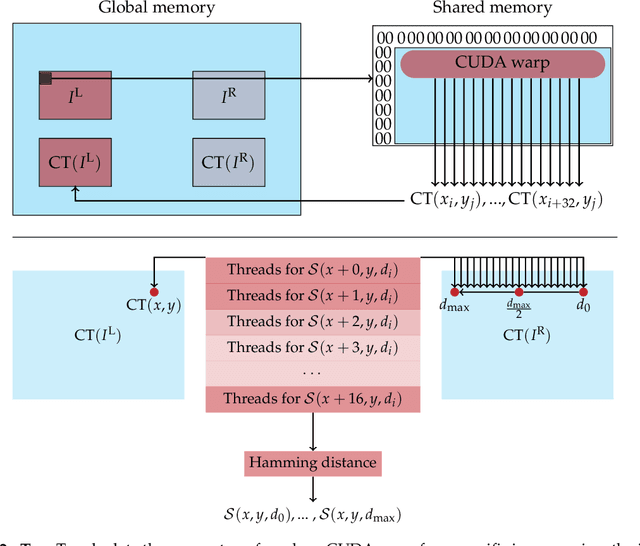
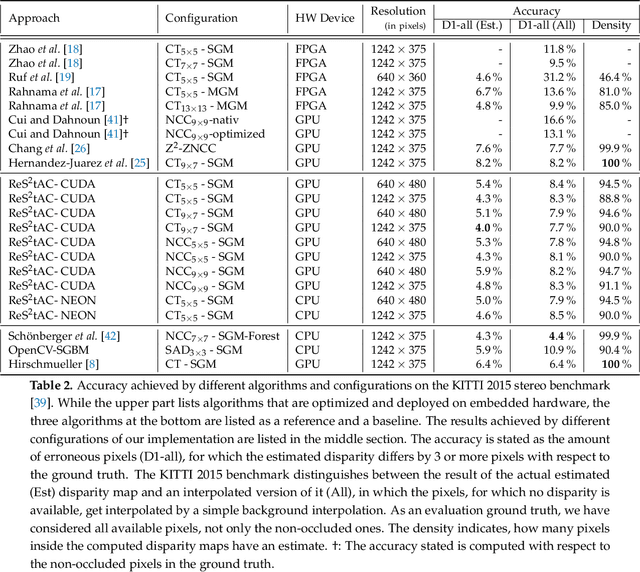
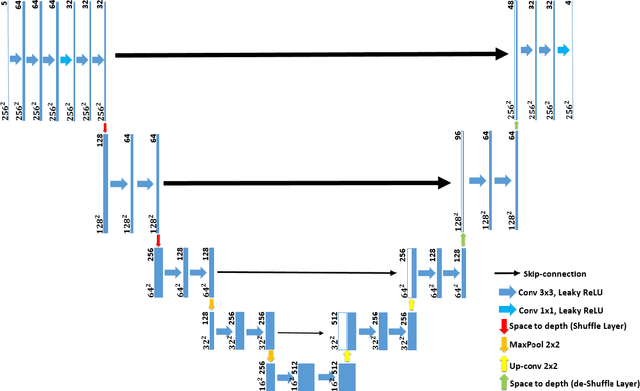
With the emergence of low-cost robotic systems, such as unmanned aerial vehicle, the importance of embedded high-performance image processing has increased. For a long time, FPGAs were the only processing hardware that were capable of high-performance computing, while at the same time preserving a low power consumption, essential for embedded systems. However, the recently increasing availability of embedded GPU-based systems, such as the NVIDIA Jetson series, comprised of an ARM CPU and a NVIDIA Tegra GPU, allows for massively parallel embedded computing on graphics hardware. With this in mind, we propose an approach for real-time embedded stereo processing on ARM and CUDA-enabled devices, which is based on the popular and widely used Semi-Global Matching algorithm. In this, we propose an optimization of the algorithm for embedded CUDA GPUs, by using massively parallel computing, as well as using the NEON intrinsics to optimize the algorithm for vectorized SIMD processing on embedded ARM CPUs. We have evaluated our approach with different configurations on two public stereo benchmark datasets to demonstrate that they can reach an error rate as low as 3.3%. Furthermore, our experiments show that the fastest configuration of our approach reaches up to 46 FPS on VGA image resolution. Finally, in a use-case specific qualitative evaluation, we have evaluated the power consumption of our approach and deployed it on the DJI Manifold 2-G attached to a DJI Matrix 210v2 RTK unmanned aerial vehicle (UAV), demonstrating its suitability for real-time stereo processing onboard a UAV.