 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploring the Limits of Out-of-Distribution Detection
Jun 06, 2021
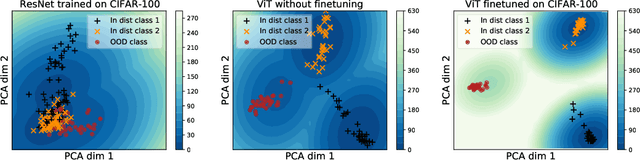
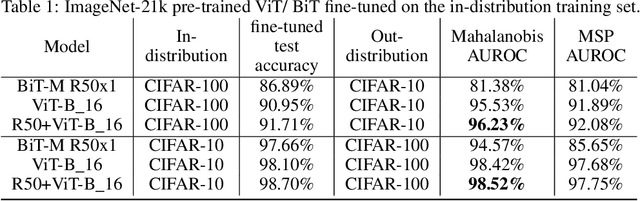
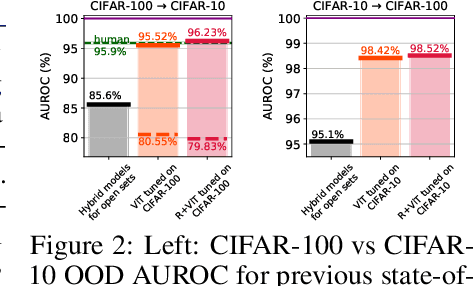

Near out-of-distribution detection (OOD) is a major challenge for deep neural networks. We demonstrate that large-scale pre-trained transformers can significantly improve the state-of-the-art (SOTA) on a range of near OOD tasks across different data modalities. For instance, on CIFAR-100 vs CIFAR-10 OOD detection, we improve the AUROC from 85% (current SOTA) to more than 96% using Vision Transformers pre-trained on ImageNet-21k. On a challenging genomics OOD detection benchmark, we improve the AUROC from 66% to 77% using transformers and unsupervised pre-training. To further improve performance, we explore the few-shot outlier exposure setting where a few examples from outlier classes may be available; we show that pre-trained transformers are particularly well-suited for outlier exposure, and that the AUROC of OOD detection on CIFAR-100 vs CIFAR-10 can be improved to 98.7% with just 1 image per OOD class, and 99.46% with 10 images per OOD class. For multi-modal image-text pre-trained transformers such as CLIP, we explore a new way of using just the names of outlier classes as a sole source of information without any accompanying images, and show that this outperforms previous SOTA on standard vision OOD benchmark tasks.
Multi-Task Self-Training for Learning General Representations
Aug 25, 2021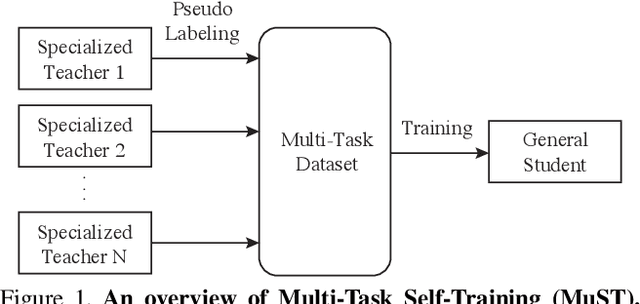
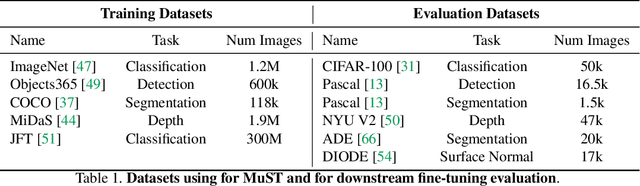

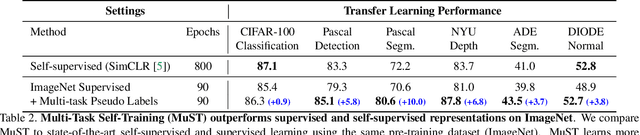
Despite the fast progress in training specialized models for various tasks, learning a single general model that works well for many tasks is still challenging for computer vision. Here we introduce multi-task self-training (MuST), which harnesses the knowledge in independent specialized teacher models (e.g., ImageNet model on classification) to train a single general student model. Our approach has three steps. First, we train specialized teachers independently on labeled datasets. We then use the specialized teachers to label an unlabeled dataset to create a multi-task pseudo labeled dataset. Finally, the dataset, which now contains pseudo labels from teacher models trained on different datasets/tasks, is then used to train a student model with multi-task learning. We evaluate the feature representations of the student model on 6 vision tasks including image recognition (classification, detection, segmentation)and 3D geometry estimation (depth and surface normal estimation). MuST is scalable with unlabeled or partially labeled datasets and outperforms both specialized supervised models and self-supervised models when training on large scale datasets. Lastly, we show MuST can improve upon already strong checkpoints trained with billions of examples. The results suggest self-training is a promising direction to aggregate labeled and unlabeled training data for learning general feature representations.
DeepObfuscator: Adversarial Training Framework for Privacy-Preserving Image Classification
Sep 09, 2019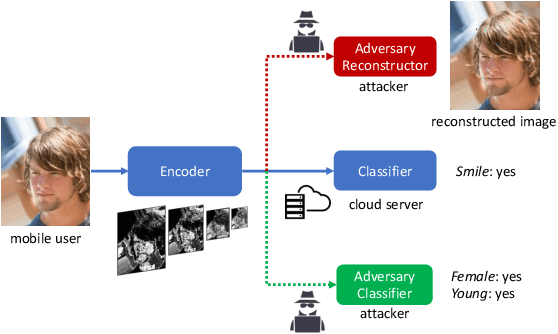
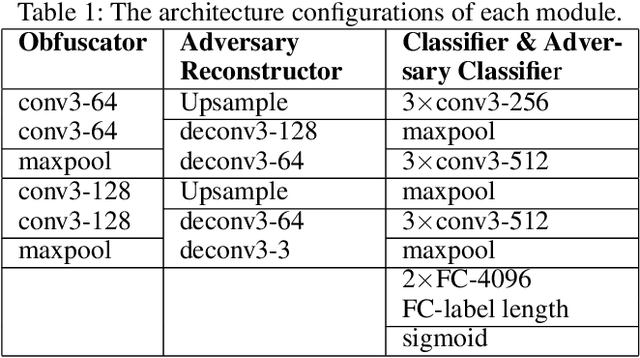


Deep learning has been widely utilized in many computer vision applications and achieved remarkable commercial success. However, running deep learning models on mobile devices is generally challenging due to limitation of the available computing resources. It is common to let the users send their service requests to cloud servers that run the large-scale deep learning models to process. Sending the data associated with the service requests to the cloud, however, impose risks on the user data privacy. Some prior arts proposed sending the features extracted from raw data (e.g., images) to the cloud. Unfortunately, these extracted features can still be exploited by attackers to recover raw images and to infer embedded private attributes (e.g., age, gender, etc.). In this paper, we propose an adversarial training framework DeepObfuscator that can prevent extracted features from being utilized to reconstruct raw images and infer private attributes, while retaining the useful information for the intended cloud service (i.e., image classification). DeepObfuscator includes a learnable encoder, namely, obfuscator that is designed to hide privacy-related sensitive information from the features by performingour proposed adversarial training algorithm. Our experiments on CelebAdataset show that the quality of the reconstructed images fromthe obfuscated features of the raw image is dramatically decreased from 0.9458 to 0.3175 in terms of multi-scale structural similarity (MS-SSIM). The person in the reconstructed image, hence, becomes hardly to be re-identified. The classification accuracy of the inferred private attributes that can be achieved by the attacker drops down to a random-guessing level, e.g., the accuracy of gender is reduced from 97.36% to 58.85%. As a comparison, the accuracy of the intended classification tasks performed via the cloud service drops by only 2%
Learning Deep Multimodal Feature Representation with Asymmetric Multi-layer Fusion
Aug 11, 2021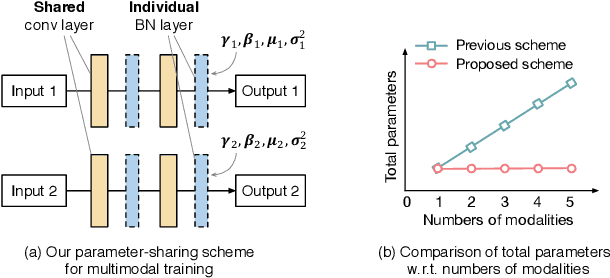
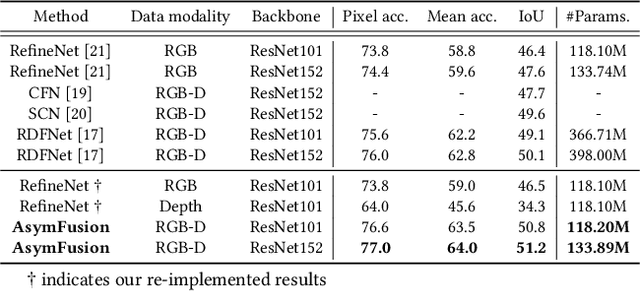
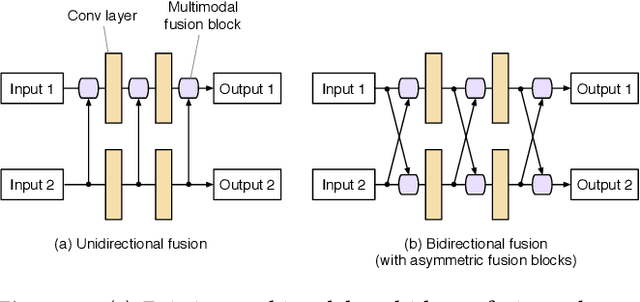
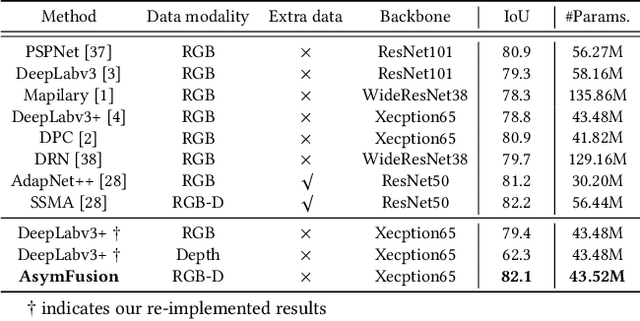
We propose a compact and effective framework to fuse multimodal features at multiple layers in a single network. The framework consists of two innovative fusion schemes. Firstly, unlike existing multimodal methods that necessitate individual encoders for different modalities, we verify that multimodal features can be learnt within a shared single network by merely maintaining modality-specific batch normalization layers in the encoder, which also enables implicit fusion via joint feature representation learning. Secondly, we propose a bidirectional multi-layer fusion scheme, where multimodal features can be exploited progressively. To take advantage of such scheme, we introduce two asymmetric fusion operations including channel shuffle and pixel shift, which learn different fused features with respect to different fusion directions. These two operations are parameter-free and strengthen the multimodal feature interactions across channels as well as enhance the spatial feature discrimination within channels. We conduct extensive experiments on semantic segmentation and image translation tasks, based on three publicly available datasets covering diverse modalities. Results indicate that our proposed framework is general, compact and is superior to state-of-the-art fusion frameworks.
Black-Box Attacks on Sequential Recommenders via Data-Free Model Extraction
Sep 01, 2021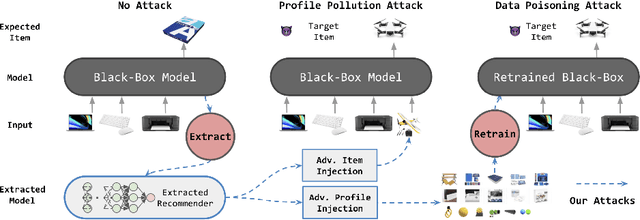

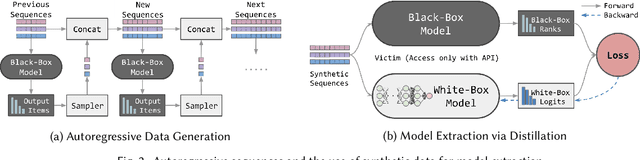
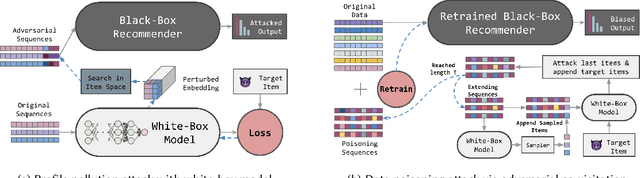
We investigate whether model extraction can be used to "steal" the weights of sequential recommender systems, and the potential threats posed to victims of such attacks. This type of risk has attracted attention in image and text classification, but to our knowledge not in recommender systems. We argue that sequential recommender systems are subject to unique vulnerabilities due to the specific autoregressive regimes used to train them. Unlike many existing recommender attackers, which assume the dataset used to train the victim model is exposed to attackers, we consider a data-free setting, where training data are not accessible. Under this setting, we propose an API-based model extraction method via limited-budget synthetic data generation and knowledge distillation. We investigate state-of-the-art models for sequential recommendation and show their vulnerability under model extraction and downstream attacks. We perform attacks in two stages. (1) Model extraction: given different types of synthetic data and their labels retrieved from a black-box recommender, we extract the black-box model to a white-box model via distillation. (2) Downstream attacks: we attack the black-box model with adversarial samples generated by the white-box recommender. Experiments show the effectiveness of our data-free model extraction and downstream attacks on sequential recommenders in both profile pollution and data poisoning settings.
Optimizing Data Processing in Space for Object Detection in Satellite Imagery
Jul 08, 2021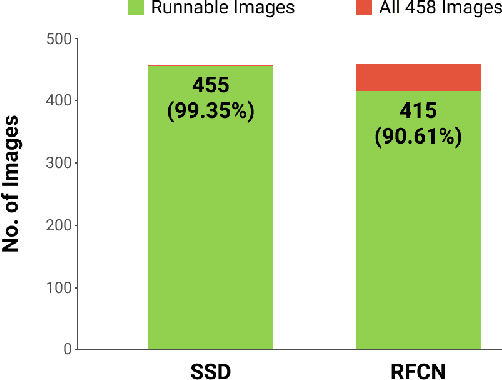

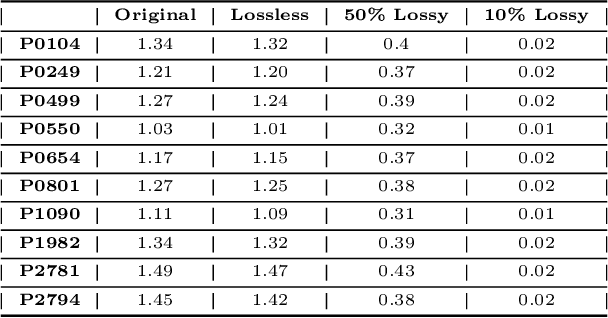

There is a proliferation in the number of satellites launched each year, resulting in downlinking of terabytes of data each day. The data received by ground stations is often unprocessed, making this an expensive process considering the large data sizes and that not all of the data is useful. This, coupled with the increasing demand for real-time data processing, has led to a growing need for on-orbit processing solutions. In this work, we investigate the performance of CNN-based object detectors on constrained devices by applying different image compression techniques to satellite data. We examine the capabilities of the NVIDIA Jetson Nano and NVIDIA Jetson AGX Xavier; low-power, high-performance computers, with integrated GPUs, small enough to fit on-board a nanosatellite. We take a closer look at object detection networks, including the Single Shot MultiBox Detector (SSD) and Region-based Fully Convolutional Network (R-FCN) models that are pre-trained on DOTA - a Large Scale Dataset for Object Detection in Aerial Images. The performance is measured in terms of execution time, memory consumption, and accuracy, and are compared against a baseline containing a server with two powerful GPUs. The results show that by applying image compression techniques, we are able to improve the execution time and memory consumption, achieving a fully runnable dataset. A lossless compression technique achieves roughly a 10% reduction in execution time and about a 3% reduction in memory consumption, with no impact on the accuracy. While a lossy compression technique improves the execution time by up to 144% and the memory consumption is reduced by as much as 97%. However, it has a significant impact on accuracy, varying depending on the compression ratio. Thus the application and ratio of these compression techniques may differ depending on the required level of accuracy for a particular task.
Attack to Fool and Explain Deep Networks
Jun 20, 2021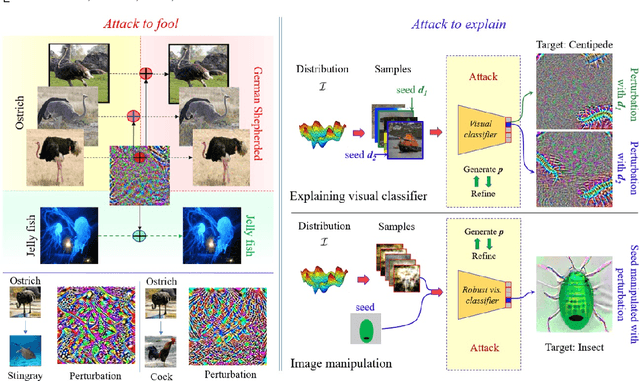
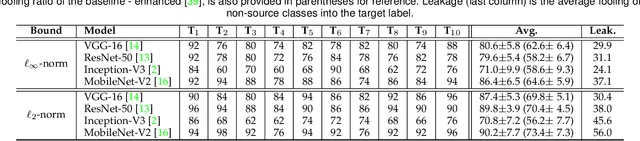
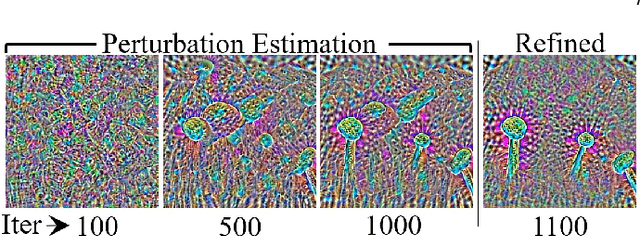
Deep visual models are susceptible to adversarial perturbations to inputs. Although these signals are carefully crafted, they still appear noise-like patterns to humans. This observation has led to the argument that deep visual representation is misaligned with human perception. We counter-argue by providing evidence of human-meaningful patterns in adversarial perturbations. We first propose an attack that fools a network to confuse a whole category of objects (source class) with a target label. Our attack also limits the unintended fooling by samples from non-sources classes, thereby circumscribing human-defined semantic notions for network fooling. We show that the proposed attack not only leads to the emergence of regular geometric patterns in the perturbations, but also reveals insightful information about the decision boundaries of deep models. Exploring this phenomenon further, we alter the `adversarial' objective of our attack to use it as a tool to `explain' deep visual representation. We show that by careful channeling and projection of the perturbations computed by our method, we can visualize a model's understanding of human-defined semantic notions. Finally, we exploit the explanability properties of our perturbations to perform image generation, inpainting and interactive image manipulation by attacking adversarialy robust `classifiers'.In all, our major contribution is a novel pragmatic adversarial attack that is subsequently transformed into a tool to interpret the visual models. The article also makes secondary contributions in terms of establishing the utility of our attack beyond the adversarial objective with multiple interesting applications.
DVMN: Dense Validity Mask Network for Depth Completion
Jul 14, 2021
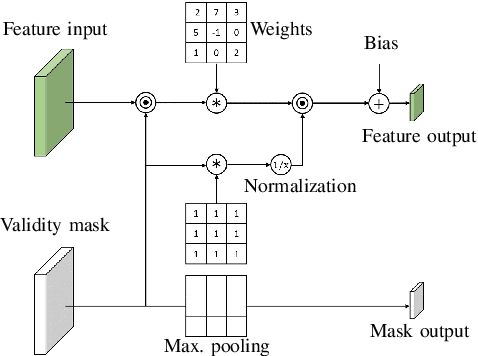
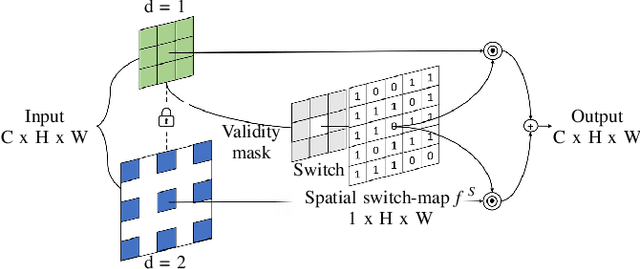
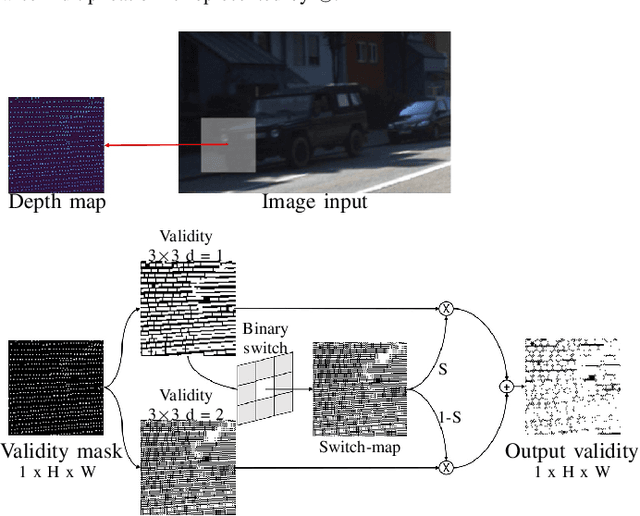
LiDAR depth maps provide environmental guidance in a variety of applications. However, such depth maps are typically sparse and insufficient for complex tasks such as autonomous navigation. State of the art methods use image guided neural networks for dense depth completion. We develop a guided convolutional neural network focusing on gathering dense and valid information from sparse depth maps. To this end, we introduce a novel layer with spatially variant and content-depended dilation to include additional data from sparse input. Furthermore, we propose a sparsity invariant residual bottleneck block. We evaluate our Dense Validity Mask Network (DVMN) on the KITTI depth completion benchmark and achieve state of the art results. At the time of submission, our network is the leading method using sparsity invariant convolution.
Multiple Combined Constraints for Image Stitching
Sep 18, 2018
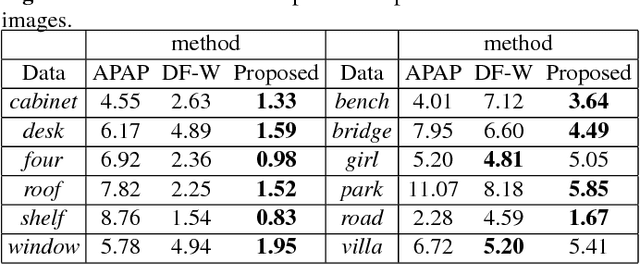

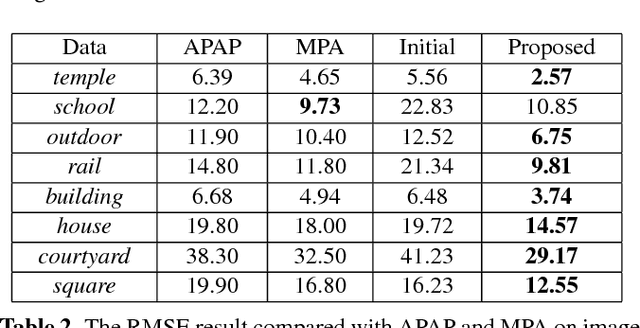
Several approaches to image stitching use different constraints to estimate the motion model between image pairs. These constraints can be roughly divided into two categories: geometric constraints and photometric constraints. In this paper, geometric and photometric constraints are combined to improve the alignment quality, which is based on the observation that these two kinds of constraints are complementary. On the one hand, geometric constraints (e.g., point and line correspondences) are usually spatially biased and are insufficient in some extreme scenes, while photometric constraints are always evenly and densely distributed. On the other hand, photometric constraints are sensitive to displacements and are not suitable for images with large parallaxes, while geometric constraints are usually imposed by feature matching and are more robust to handle parallaxes. The proposed method therefore combines them together in an efficient mesh-based image warping framework. It achieves better alignment quality than methods only with geometric constraints, and can handle larger parallax than photometric-constraint-based method. Experimental results on various images illustrate that the proposed method outperforms representative state-of-the-art image stitching methods reported in the literature.
Densely connected neural networks for nonlinear regression
Jul 29, 2021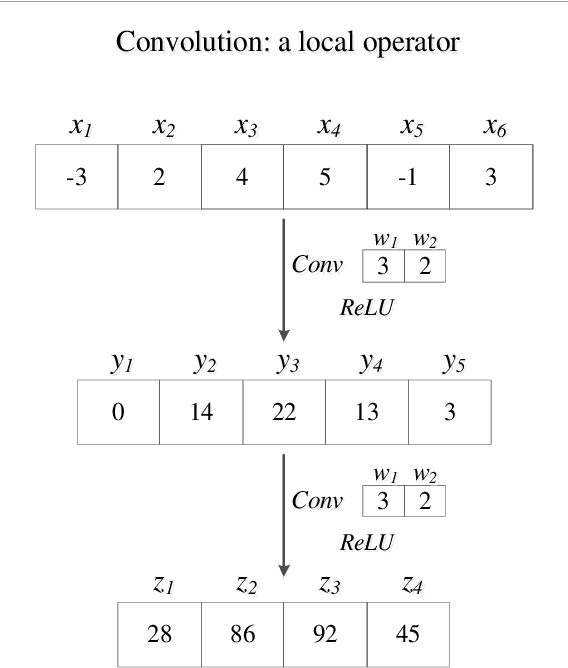
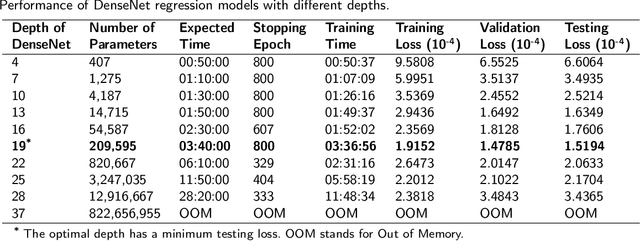
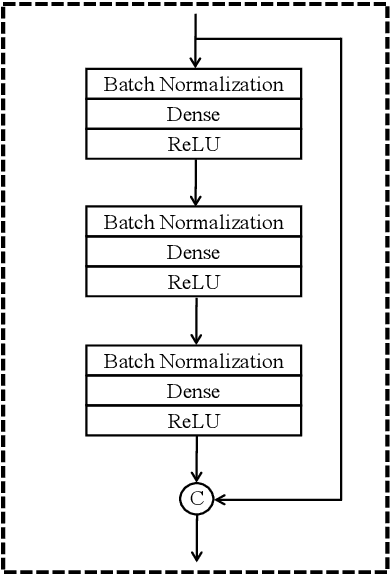
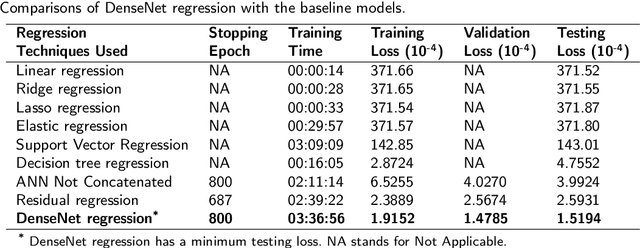
Densely connected convolutional networks (DenseNet) behave well in image processing. However, for regression tasks, convolutional DenseNet may lose essential information from independent input features. To tackle this issue, we propose a novel DenseNet regression model where convolution and pooling layers are replaced by fully connected layers and the original concatenation shortcuts are maintained to reuse the feature. To investigate the effects of depth and input dimension of proposed model, careful validations are performed by extensive numerical simulation. The results give an optimal depth (19) and recommend a limited input dimension (under 200). Furthermore, compared with the baseline models including support vector regression, decision tree regression, and residual regression, our proposed model with the optimal depth performs best. Ultimately, DenseNet regression is applied to predict relative humidity, and the outcome shows a high correlation (0.91) with observations, which indicates that our model could advance environmental data analysis.