 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Stylizing 3D Scene via Implicit Representation and HyperNetwork
May 27, 2021

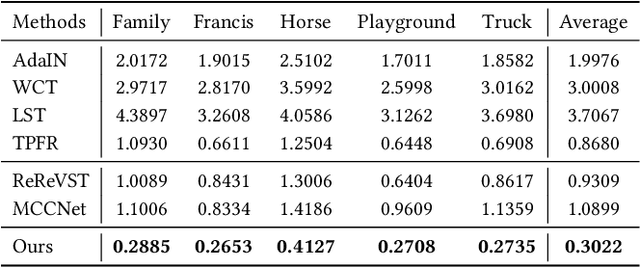
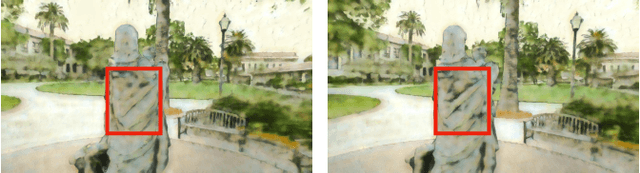
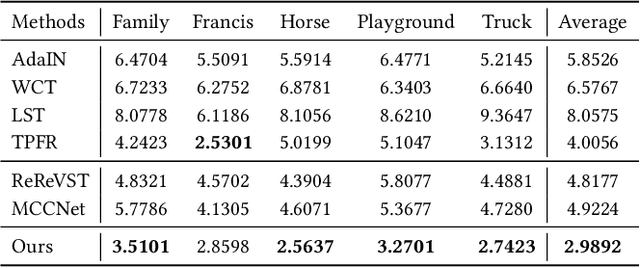
In this work, we aim to address the 3D scene stylization problem - generating stylized images of the scene at arbitrary novel view angles. A straightforward solution is to combine existing novel view synthesis and image/video style transfer approaches, which often leads to blurry results or inconsistent appearance. Inspired by the high quality results of the neural radiance fields (NeRF) method, we propose a joint framework to directly render novel views with the desired style. Our framework consists of two components: an implicit representation of the 3D scene with the neural radiance field model, and a hypernetwork to transfer the style information into the scene representation. In particular, our implicit representation model disentangles the scene into the geometry and appearance branches, and the hypernetwork learns to predict the parameters of the appearance branch from the reference style image. To alleviate the training difficulties and memory burden, we propose a two-stage training procedure and a patch sub-sampling approach to optimize the style and content losses with the neural radiance field model. After optimization, our model is able to render consistent novel views at arbitrary view angles with arbitrary style. Both quantitative evaluation and human subject study have demonstrated that the proposed method generates faithful stylization results with consistent appearance across different views.
PIT: Position-Invariant Transform for Cross-FoV Domain Adaptation
Aug 16, 2021
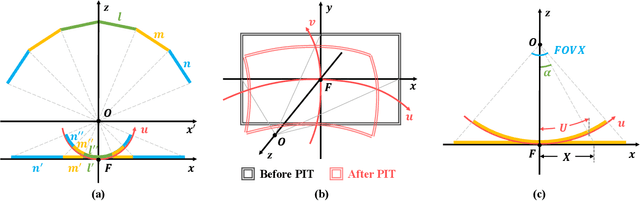
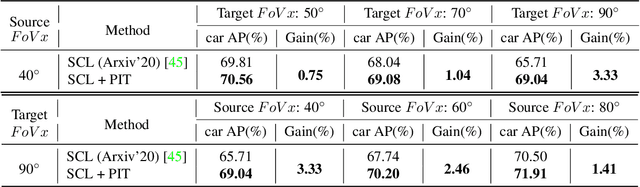
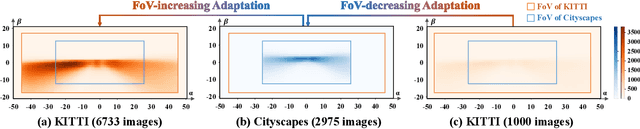
Cross-domain object detection and semantic segmentation have witnessed impressive progress recently. Existing approaches mainly consider the domain shift resulting from external environments including the changes of background, illumination or weather, while distinct camera intrinsic parameters appear commonly in different domains, and their influence for domain adaptation has been very rarely explored. In this paper, we observe that the Field of View (FoV) gap induces noticeable instance appearance differences between the source and target domains. We further discover that the FoV gap between two domains impairs domain adaptation performance under both the FoV-increasing (source FoV < target FoV) and FoV-decreasing cases. Motivated by the observations, we propose the \textbf{Position-Invariant Transform} (PIT) to better align images in different domains. We also introduce a reverse PIT for mapping the transformed/aligned images back to the original image space and design a loss re-weighting strategy to accelerate the training process. Our method can be easily plugged into existing cross-domain detection/segmentation frameworks while bringing about negligible computational overhead. Extensive experiments demonstrate that our method can soundly boost the performance on both cross-domain object detection and segmentation for state-of-the-art techniques. Our code is available at https://github.com/sheepooo/PIT-Position-Invariant-Transform.
REO-Relevance, Extraness, Omission: A Fine-grained Evaluation for Image Captioning
Sep 05, 2019
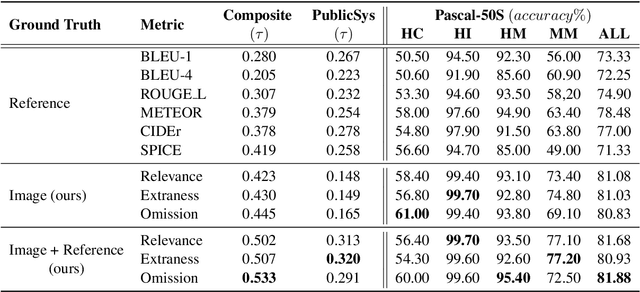
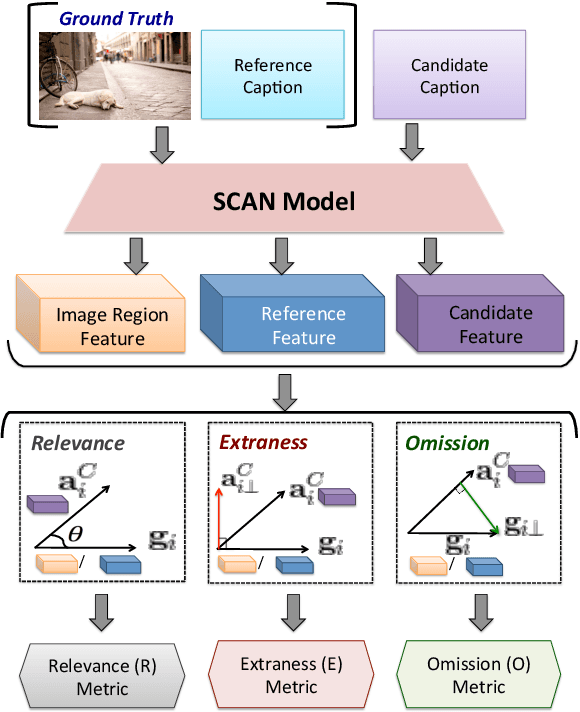

Popular metrics used for evaluating image captioning systems, such as BLEU and CIDEr, provide a single score to gauge the system's overall effectiveness. This score is often not informative enough to indicate what specific errors are made by a given system. In this study, we present a fine-grained evaluation method REO for automatically measuring the performance of image captioning systems. REO assesses the quality of captions from three perspectives: 1) Relevance to the ground truth, 2) Extraness of the content that is irrelevant to the ground truth, and 3) Omission of the elements in the images and human references. Experiments on three benchmark datasets demonstrate that our method achieves a higher consistency with human judgments and provides more intuitive evaluation results than alternative metrics.
Learning from Pixel-Level Label Noise: A New Perspective for Semi-Supervised Semantic Segmentation
Mar 26, 2021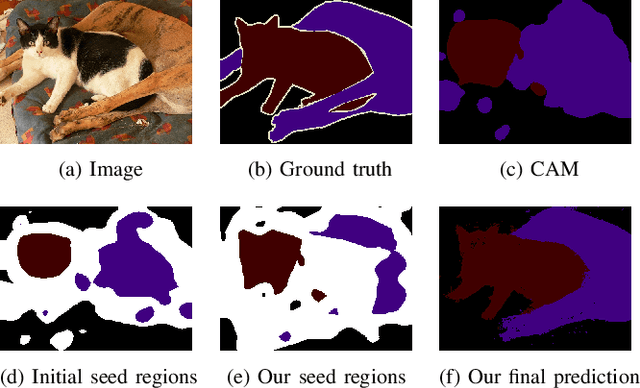
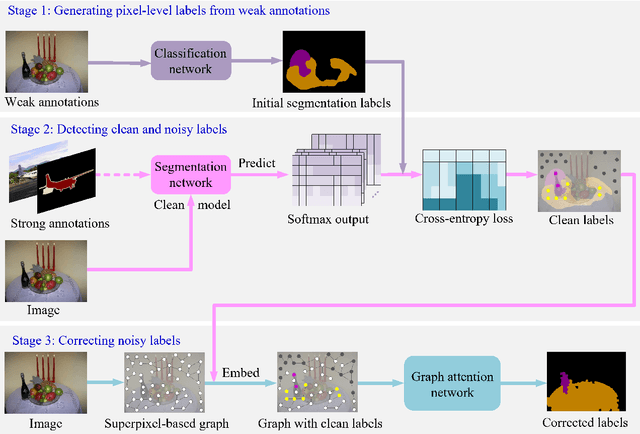


This paper addresses semi-supervised semantic segmentation by exploiting a small set of images with pixel-level annotations (strong supervisions) and a large set of images with only image-level annotations (weak supervisions). Most existing approaches aim to generate accurate pixel-level labels from weak supervisions. However, we observe that those generated labels still inevitably contain noisy labels. Motivated by this observation, we present a novel perspective and formulate this task as a problem of learning with pixel-level label noise. Existing noisy label methods, nevertheless, mainly aim at image-level tasks, which can not capture the relationship between neighboring labels in one image. Therefore, we propose a graph based label noise detection and correction framework to deal with pixel-level noisy labels. In particular, for the generated pixel-level noisy labels from weak supervisions by Class Activation Map (CAM), we train a clean segmentation model with strong supervisions to detect the clean labels from these noisy labels according to the cross-entropy loss. Then, we adopt a superpixel-based graph to represent the relations of spatial adjacency and semantic similarity between pixels in one image. Finally we correct the noisy labels using a Graph Attention Network (GAT) supervised by detected clean labels. We comprehensively conduct experiments on PASCAL VOC 2012, PASCAL-Context and MS-COCO datasets. The experimental results show that our proposed semi supervised method achieves the state-of-the-art performances and even outperforms the fully-supervised models on PASCAL VOC 2012 and MS-COCO datasets in some cases.
A Vision-based Irregular Obstacle Avoidance Framework via Deep Reinforcement Learning
Aug 23, 2021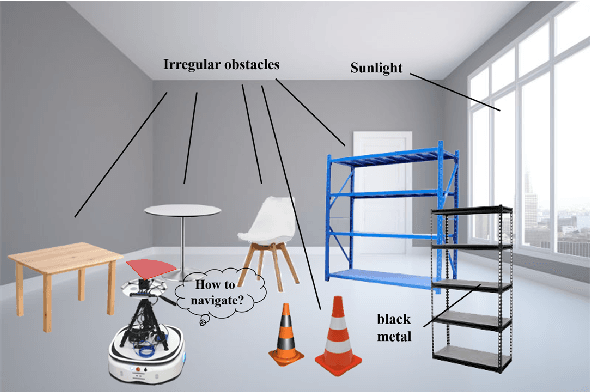
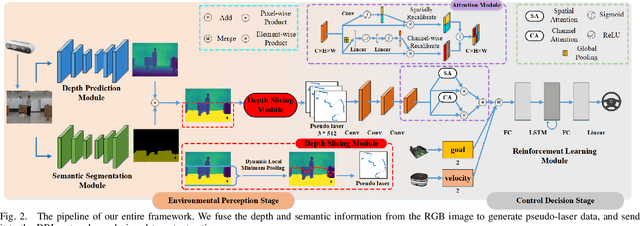

Deep reinforcement learning has achieved great success in laser-based collision avoidance work because the laser can sense accurate depth information without too much redundant data, which can maintain the robustness of the algorithm when it is migrated from the simulation environment to the real world. However, high-cost laser devices are not only difficult to apply on a large scale but also have poor robustness to irregular objects, e.g., tables, chairs, shelves, etc. In this paper, we propose a vision-based collision avoidance framework to solve the challenging problem. Our method attempts to estimate the depth and incorporate the semantic information from RGB data to obtain a new form of data, pseudo-laser data, which combines the advantages of visual information and laser information. Compared to traditional laser data that only contains the one-dimensional distance information captured at a certain height, our proposed pseudo-laser data encodes the depth information and semantic information within the image, which makes our method more effective for irregular obstacles. Besides, we adaptively add noise to the laser data during the training stage to increase the robustness of our model in the real world, due to the estimated depth information is not accurate. Experimental results show that our framework achieves state-of-the-art performance in several unseen virtual and real-world scenarios.
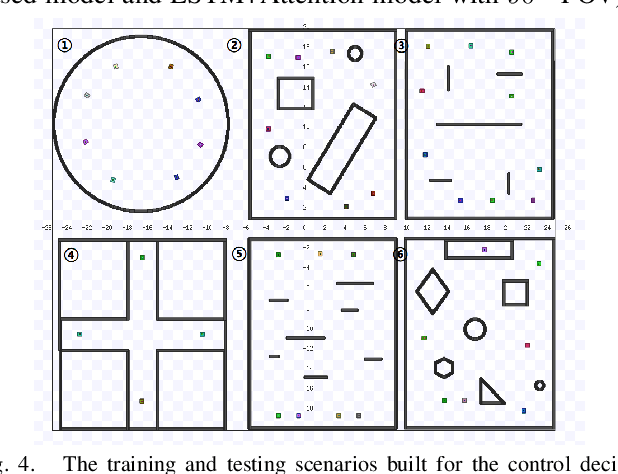
Exploiting Natural Language for Efficient Risk-Aware Multi-robot SaR Planning
Apr 08, 2021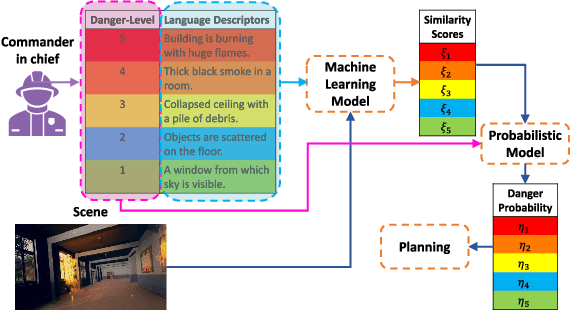
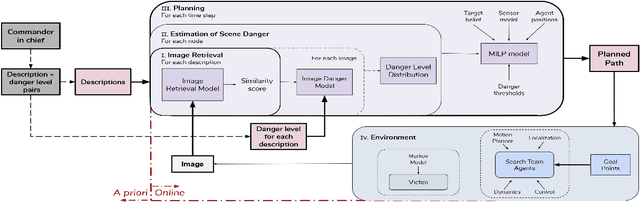

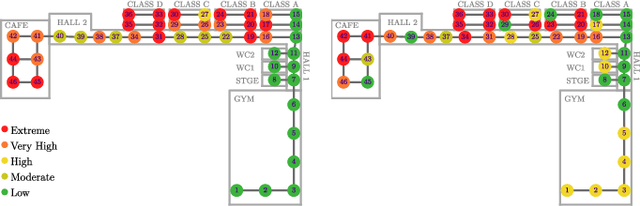
The ability to develop a high-level understanding of a scene, such as perceiving danger levels, can prove valuable in planning multi-robot search and rescue (SaR) missions. In this work, we propose to uniquely leverage natural language descriptions from the mission commander in chief and image data captured by robots to estimate scene danger. Given a description and an image, a state-of-the-art deep neural network is used to assess a corresponding similarity score, which is then converted into a probabilistic distribution of danger levels. Because commonly used visio-linguistic datasets do not represent SaR missions well, we collect a large-scale image-description dataset from synthetic images taken from realistic disaster scenes and use it to train our machine learning model. A risk-aware variant of the Multi-robot Efficient Search Path Planning (MESPP) problem is then formulated to use the danger estimates in order to account for high-risk locations in the environment when planning the searchers' paths. The problem is solved via a distributed approach based on Mixed-Integer Linear Programming. Our experiments demonstrate that our framework allows to plan safer yet highly successful search missions, abiding to the two most important aspects of SaR missions: to ensure both searchers' and victim safety.
* 8 pages, 5 figures. To be presented at the IEEE International Conference on Robotics and Automation, 2021. Dataset available at: https://github.com/vikshree/DISC-L.git
ResUNet++: An Advanced Architecture for Medical Image Segmentation
Nov 16, 2019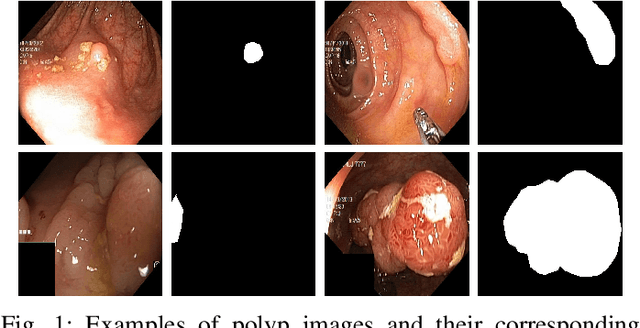
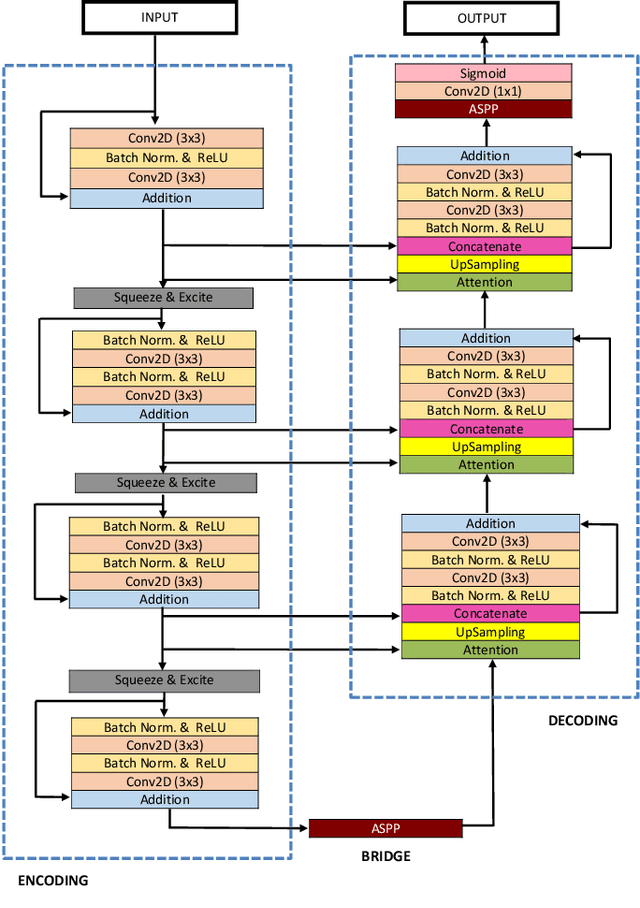
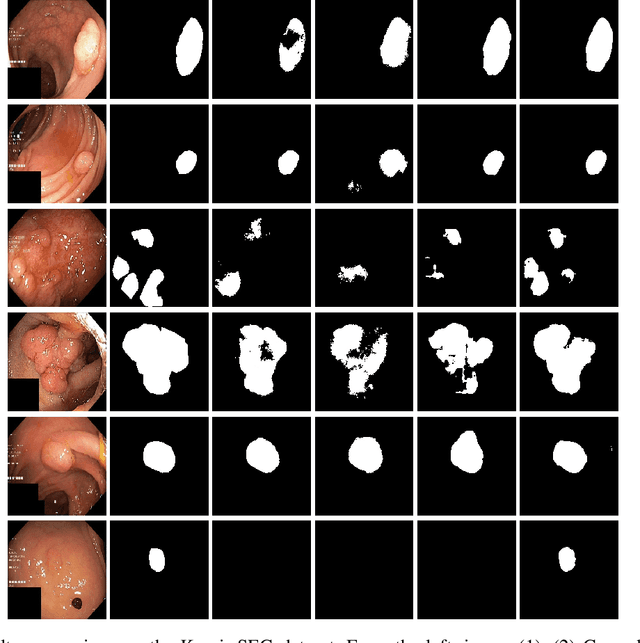
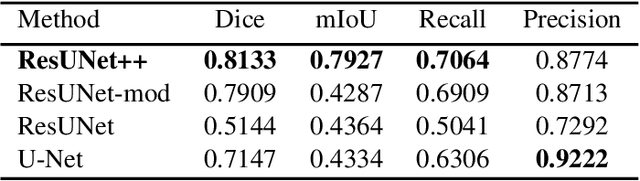
Accurate computer-aided polyp detection and segmentation during colonoscopy examinations can help endoscopists resect abnormal tissue and thereby decrease chances of polyps growing into cancer. Towards developing a fully automated model for pixel-wise polyp segmentation, we propose ResUNet++, which is an improved ResUNet architecture for colonoscopic image segmentation. Our experimental evaluations show that the suggested architecture produces good segmentation results on publicly available datasets. Furthermore, ResUNet++ significantly outperforms U-Net and ResUNet, two key state-of-the-art deep learning architectures, by achieving high evaluation scores with a dice coefficient of 81.33%, and a mean Intersection over Union (mIoU) of 79.27% for the Kvasir-SEG dataset and a dice coefficient of 79.55%, and a mIoU of 79.62% with CVC-612 dataset.
Semi-Sparsity for Smoothing Filters
Jul 24, 2021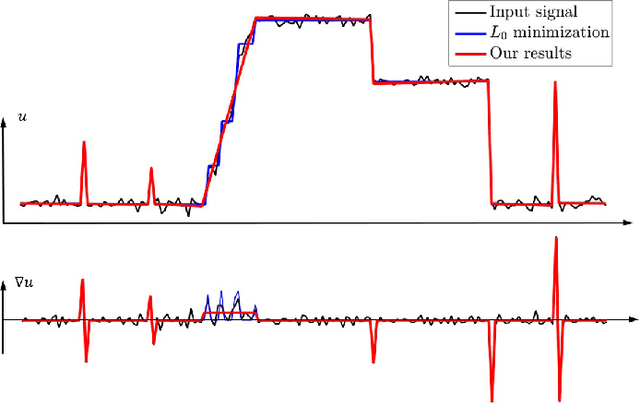
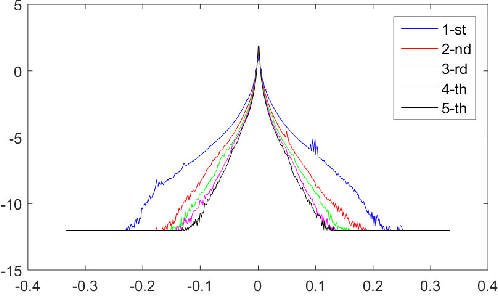

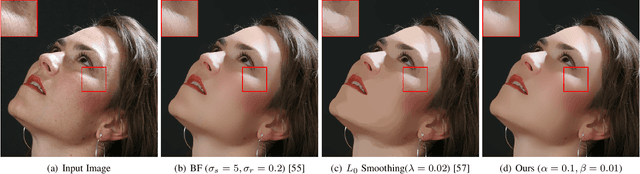
In this paper, we propose an interesting semi-sparsity smoothing algorithm based on a novel sparsity-inducing optimization framework. This method is derived from the multiple observations, that is, semi-sparsity prior knowledge is more universally applicable, especially in areas where sparsity is not fully admitted, such as polynomial-smoothing surfaces. We illustrate that this semi-sparsity can be identified into a generalized $L_0$-norm minimization in higher-order gradient domains, thereby giving rise to a new "feature-aware" filtering method with a powerful simultaneous-fitting ability in both sparse features (singularities and sharpening edges) and non-sparse regions (polynomial-smoothing surfaces). Notice that a direct solver is always unavailable due to the non-convexity and combinatorial nature of $L_0$-norm minimization. Instead, we solve the model based on an efficient half-quadratic splitting minimization with fast Fourier transforms (FFTs) for acceleration. We finally demonstrate its versatility and many benefits to a series of signal/image processing and computer vision applications.
MedGAN: Medical Image Translation using GANs
Jun 17, 2018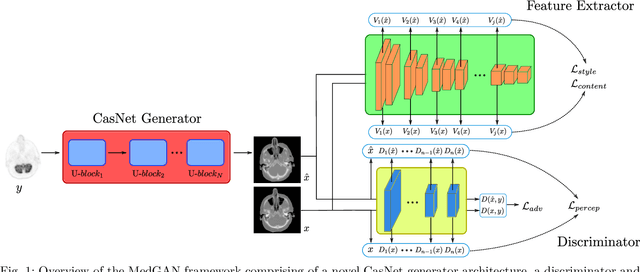
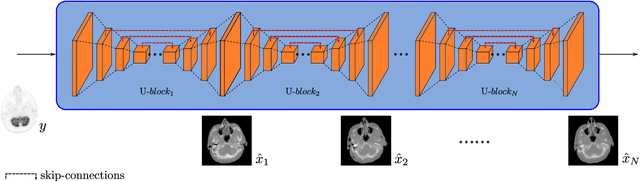
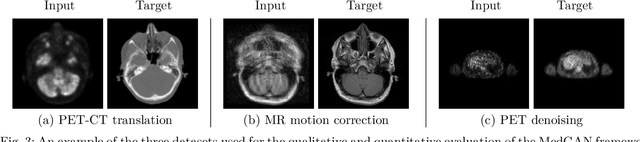
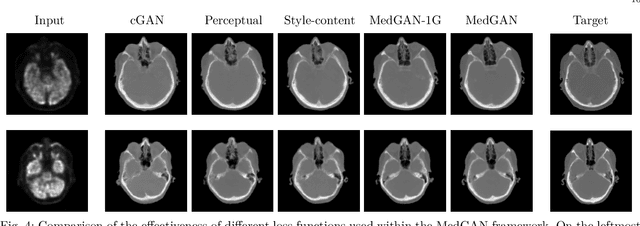
Image-to-image translation is considered a next frontier in the field of medical image analysis, with numerous potential applications. However, recent advances in this field offer individualized solutions by utilizing specialized architectures which are task specific or by suffering from limited capacities and thus requiring refinement through non end-to-end training. In this paper, we propose a novel general purpose framework for medical image-to-image translation, titled MedGAN, which operates in an end-to-end manner on the image level. MedGAN builds upon recent advances in the field of generative adversarial networks(GANs) by combining the adversarial framework with a unique combination of non-adversarial losses which captures the high and low frequency components of the desired target modality. Namely, we utilize a discriminator network as a trainable feature extractor which penalizes the discrepancy between the translated medical images and the desired modalities in the pixel and perceptual sense. Moreover, style-transfer losses are utilized to match the textures and fine-structures of the desired target images to the outputs. Additionally, we present a novel generator architecture, titled CasNet, which enhances the sharpness of the translated medical outputs through progressive refinement via encoder decoder pairs. To demonstrate the effectiveness of our approach, we apply MedGAN on three novel and challenging applications: PET-CT translation, correction of MR motion artefacts and PET image denoising. Qualitative and quantitative comparisons with state-of-the-art techniques have emphasized the superior performance of the proposed framework. MedGAN can be directly applied as a general framework for future medical translation tasks.
Measuring Robustness in Deep Learning Based Compressive Sensing
Feb 11, 2021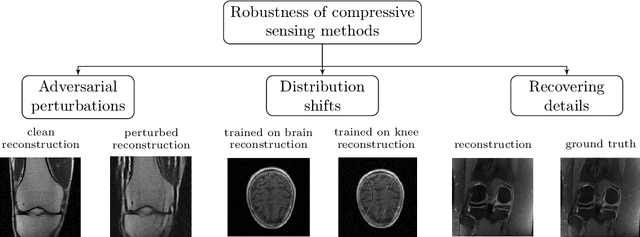
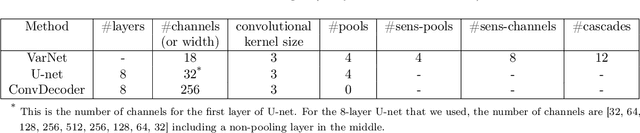
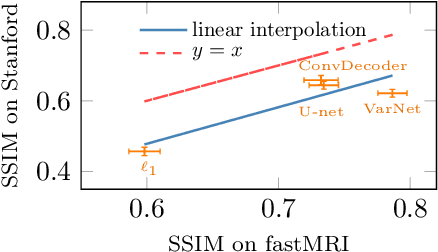
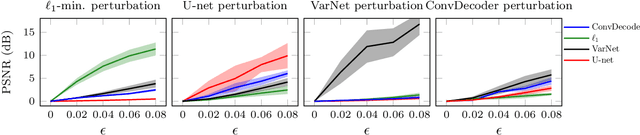
Deep neural networks give state-of-the-art performance for inverse problems such as reconstructing images from few and noisy measurements, a problem arising in accelerated magnetic resonance imaging (MRI). However, recent works have raised concerns that deep-learning-based image reconstruction methods are sensitive to perturbations and are less robust than traditional methods: Neural networks (i) may be sensitive to small, yet adversarially-selected perturbations, (ii) may perform poorly under distribution shifts, and (iii) may fail to recover small but important features in the image. In order to understand whether neural networks are sensitive to such perturbations, in this work, we measure the robustness of different approaches for image reconstruction including trained neural networks, un-trained networks, and traditional sparsity-based methods. We find, contrary to prior works, that both trained and un-trained methods are vulnerable to adversarial perturbations. Moreover, we find that both trained and un-trained methods tuned for a particular dataset suffer very similarly from distribution shifts. Finally, we demonstrate that an image reconstruction method that achieves higher reconstruction accuracy, also performs better in terms of accurately recovering fine details. Thus, the current state-of-the-art deep-learning-based image reconstruction methods enable a performance gain over traditional methods without compromising robustness.