 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pyramid Real Image Denoising Network
Aug 01, 2019

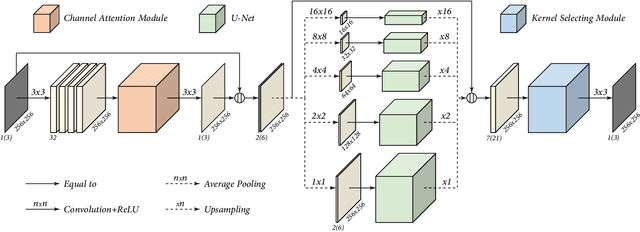
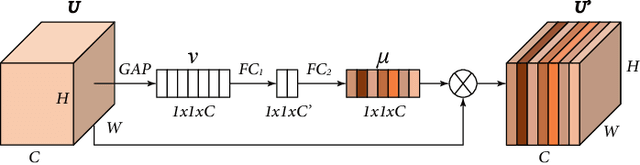
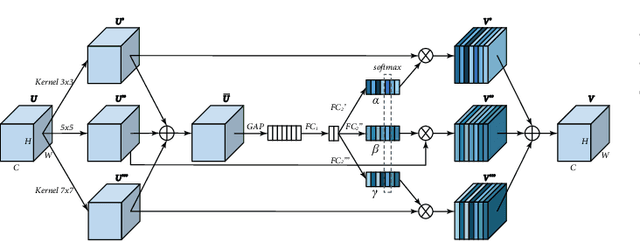
While deep Convolutional Neural Networks (CNNs) have shown extraordinary capability of modelling specific noise and denoising, they still perform poorly on real-world noisy images. The main reason is that the real-world noise is more sophisticated and diverse. To tackle the issue of blind denoising, in this paper, we propose a novel pyramid real image denoising network (PRIDNet), which contains three stages. First, the noise estimation stage uses channel attention mechanism to recalibrate the channel importance of input noise. Second, at the multi-scale denoising stage, pyramid pooling is utilized to extract multi-scale features. Third, the stage of feature fusion adopts a kernel selecting operation to adaptively fuse multi-scale features. Experiments on two datasets of real noisy photographs demonstrate that our approach can achieve competitive performance in comparison with state-of-the-art denoisers in terms of both quantitative measure and visual perception quality.
Single Image Super-Resolution via CNN Architectures and TV-TV Minimization
Jul 11, 2019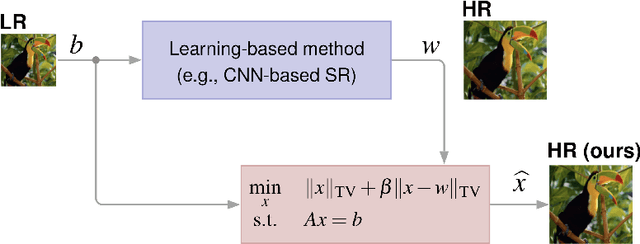
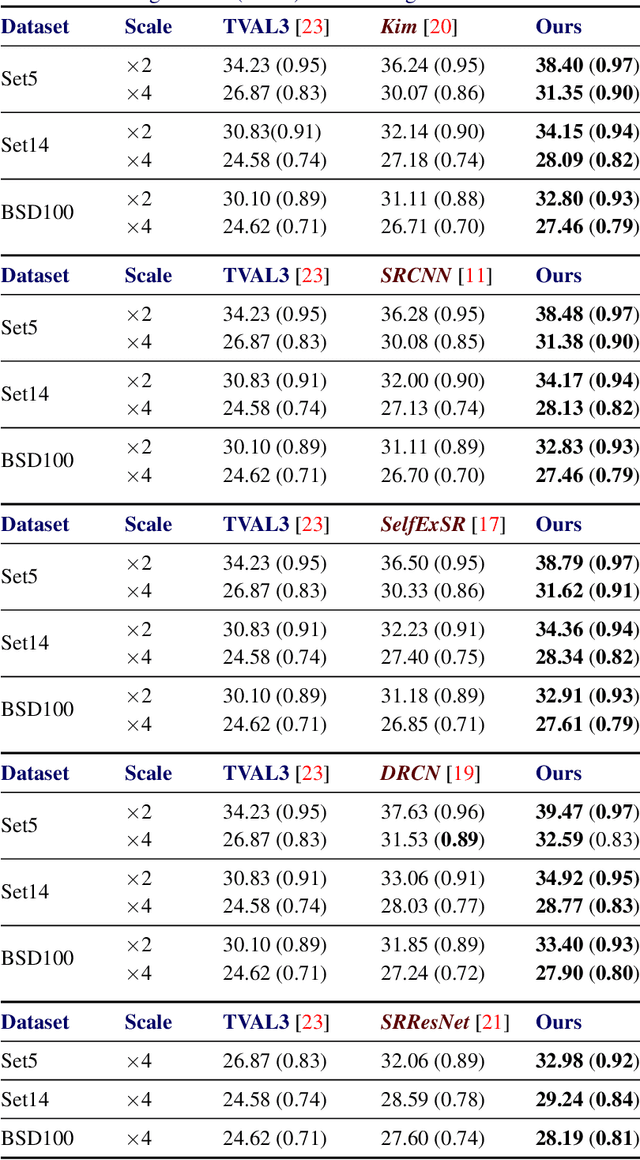

Super-resolution (SR) is a technique that allows increasing the resolution of a given image. Having applications in many areas, from medical imaging to consumer electronics, several SR methods have been proposed. Currently, the best performing methods are based on convolutional neural networks (CNNs) and require extensive datasets for training. However, at test time, they fail to impose consistency between the super-resolved image and the given low-resolution image, a property that classic reconstruction-based algorithms naturally enforce in spite of having poorer performance. Motivated by this observation, we propose a new framework that joins both approaches and produces images with superior quality than any of the prior methods. Although our framework requires additional computation, our experiments on Set5, Set14, and BSD100 show that it systematically produces images with better peak signal to noise ratio (PSNR) and structural similarity (SSIM) than the current state-of-the-art CNN architectures for SR.
External Dynamic InTerference Estimation and Removal (EDITER) for low field MRI
Apr 29, 2021
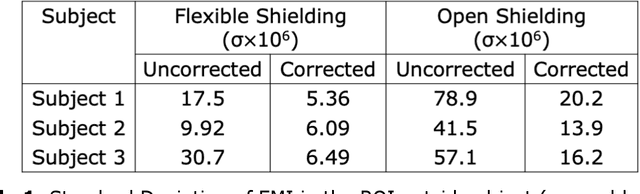
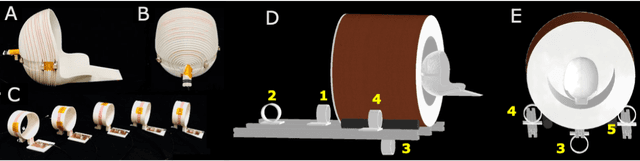
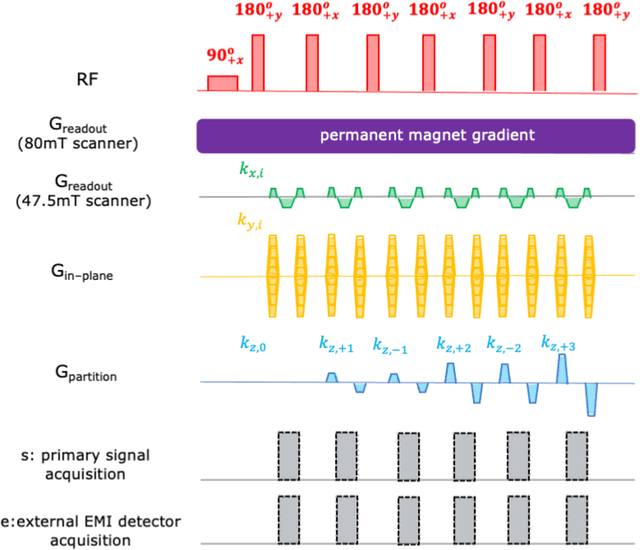
Purpose: Point-of-care MRI requires operation outside of a faraday shielded room normally used to block image-degrading electromagnetic Interference (EMI). To address this, we introduce the EDITER method, an external sensor based dynamic EMI estimation and removal method to retrospectively remove time-varying external interference sources. Theory and Methods: The method acquires data from multiple EMI detectors (tuned receive coils and electrodes placed on the body) simultaneous with the primary MR coil during image data acquisition. We dynamically calculate impulse response functions that map the data from the detectors to the artifacts in the kspace data, then remove the transformed detected EMI from the MR data. Performance of the EDITER algorithm was assessed in phantom and in vivo imaging experiments in an 80mT portable brain MRI in a controlled EMI environment and with an open 47.5mT MRI scanner in an uncontrolled EMI setting. Results: In the controlled setting, the effectiveness of the EDITER technique was demonstrated for specific types of introduced EMI sources with up to a 97% reduction of structured EMI and up to 76% reduction of broadband EMI. In the uncontrolled EMI experiments, we demonstrate EMI reductions of 37% with a single pickup coil and 89% with a single electrode and up to 99% with both. Conclusion: The EDITER technique is a flexible and robust method to improve image quality in portable MRI systems with minimal passive shielding. This could reduce the reliance of MRI on shielded rooms and allow for truly portable MRI with specialized compact POC scanners
Semi-Sparsity for Smoothing Filters
Jul 24, 2021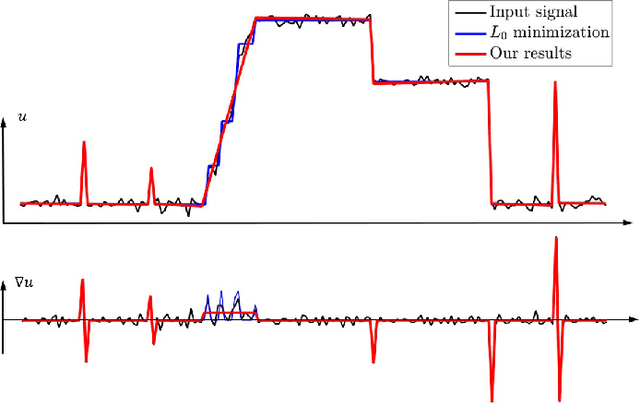
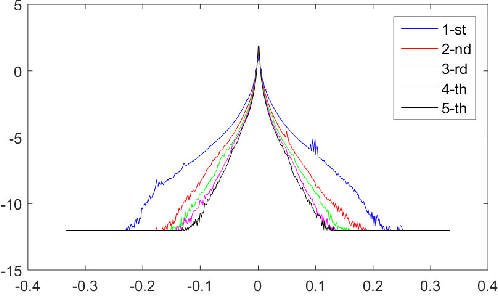

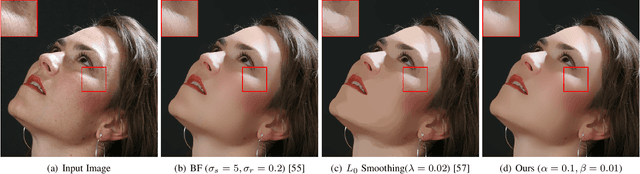
In this paper, we propose an interesting semi-sparsity smoothing algorithm based on a novel sparsity-inducing optimization framework. This method is derived from the multiple observations, that is, semi-sparsity prior knowledge is more universally applicable, especially in areas where sparsity is not fully admitted, such as polynomial-smoothing surfaces. We illustrate that this semi-sparsity can be identified into a generalized $L_0$-norm minimization in higher-order gradient domains, thereby giving rise to a new "feature-aware" filtering method with a powerful simultaneous-fitting ability in both sparse features (singularities and sharpening edges) and non-sparse regions (polynomial-smoothing surfaces). Notice that a direct solver is always unavailable due to the non-convexity and combinatorial nature of $L_0$-norm minimization. Instead, we solve the model based on an efficient half-quadratic splitting minimization with fast Fourier transforms (FFTs) for acceleration. We finally demonstrate its versatility and many benefits to a series of signal/image processing and computer vision applications.
L2C: Describing Visual Differences Needs Semantic Understanding of Individuals
Feb 03, 2021
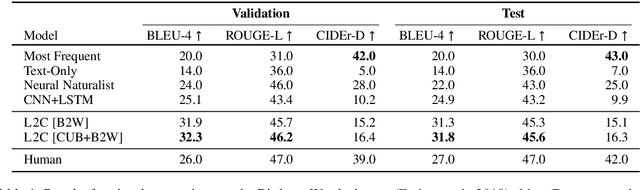
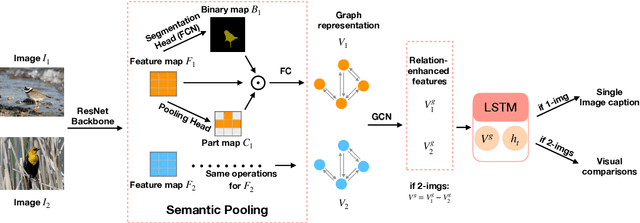

Recent advances in language and vision push forward the research of captioning a single image to describing visual differences between image pairs. Suppose there are two images, I_1 and I_2, and the task is to generate a description W_{1,2} comparing them, existing methods directly model { I_1, I_2 } -> W_{1,2} mapping without the semantic understanding of individuals. In this paper, we introduce a Learning-to-Compare (L2C) model, which learns to understand the semantic structures of these two images and compare them while learning to describe each one. We demonstrate that L2C benefits from a comparison between explicit semantic representations and single-image captions, and generalizes better on the new testing image pairs. It outperforms the baseline on both automatic evaluation and human evaluation for the Birds-to-Words dataset.
Stylizing 3D Scene via Implicit Representation and HyperNetwork
May 27, 2021
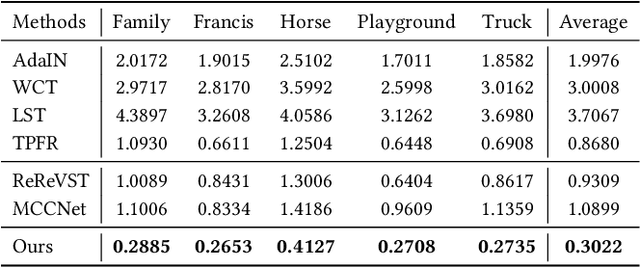
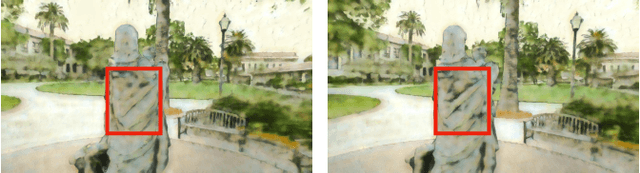
In this work, we aim to address the 3D scene stylization problem - generating stylized images of the scene at arbitrary novel view angles. A straightforward solution is to combine existing novel view synthesis and image/video style transfer approaches, which often leads to blurry results or inconsistent appearance. Inspired by the high quality results of the neural radiance fields (NeRF) method, we propose a joint framework to directly render novel views with the desired style. Our framework consists of two components: an implicit representation of the 3D scene with the neural radiance field model, and a hypernetwork to transfer the style information into the scene representation. In particular, our implicit representation model disentangles the scene into the geometry and appearance branches, and the hypernetwork learns to predict the parameters of the appearance branch from the reference style image. To alleviate the training difficulties and memory burden, we propose a two-stage training procedure and a patch sub-sampling approach to optimize the style and content losses with the neural radiance field model. After optimization, our model is able to render consistent novel views at arbitrary view angles with arbitrary style. Both quantitative evaluation and human subject study have demonstrated that the proposed method generates faithful stylization results with consistent appearance across different views.
BUZz: BUffer Zones for defending adversarial examples in image classification
Oct 03, 2019

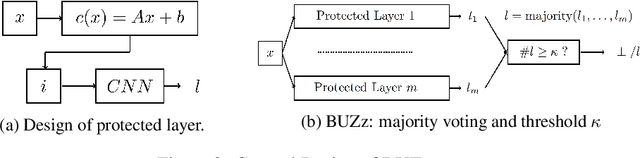
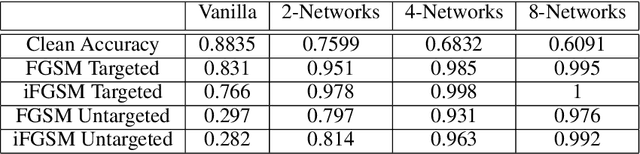
We propose a novel defense against all existing gradient based adversarial attacks on deep neural networks for image classification problems. Our defense is based on a combination of deep neural networks and simple image transformations. While straight forward in implementation, this defense yields a unique security property which we term buffer zones. In this paper, we formalize the concept of buffer zones. We argue that our defense based on buffer zones is secure against state-of-the-art black box attacks. We are able to achieve this security even when the adversary has access to the {\em entire} original training data set and unlimited query access to the defense. We verify our security claims through experimentation using FashionMNIST, CIFAR-10 and CIFAR-100. We demonstrate $<10\%$ attack success rate -- significantly lower than what other well-known defenses offer -- at only a price of a 15-20\% drop in clean accuracy. By using a new intuitive metric we explain why this trade-off offers a significant improvement over prior work.
Surprising Effectiveness of Few-Image Unsupervised Feature Learning
Apr 30, 2019

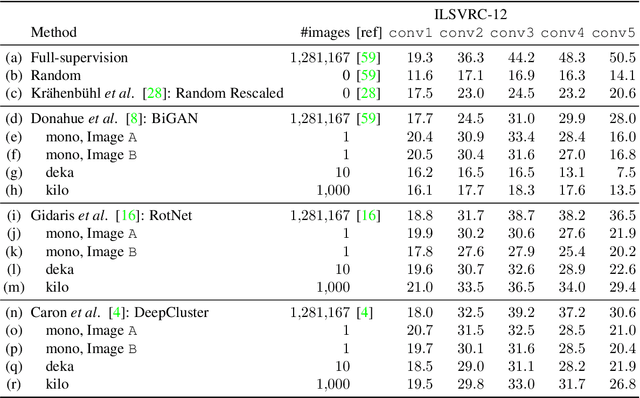
State-of-the-art methods for unsupervised representation learning can train well the first few layers of standard convolutional neural networks, but they are not as good as supervised learning for deeper layers. This is likely due to the generic and relatively simple nature of shallow layers; and yet, these approaches are applied to millions of images, scalability being advertised as their major advantage since unlabelled data is cheap to collect. In this paper we question this practice and ask whether so many images are actually needed to learn the layers for which unsupervised learning works best. Our main result is that a few or even a single image together with strong data augmentation are sufficient to nearly saturate performance. Specifically, we provide an analysis for three different self-supervised feature learning methods (BiGAN, RotNet, DeepCluster) vs number of training images (1, 10, 1000) and show that we can top the accuracy for the first two convolutional layers of common networks using just a single unlabelled training image and obtain competitive results for other layers. We further study and visualize the learned representation as a function of which (single) image is used for training. Our results are also suggestive of which type of information may be captured by shallow layers in deep networks.
Semi-Heterogeneous Three-Way Joint Embedding Network for Sketch-Based Image Retrieval
Nov 10, 2019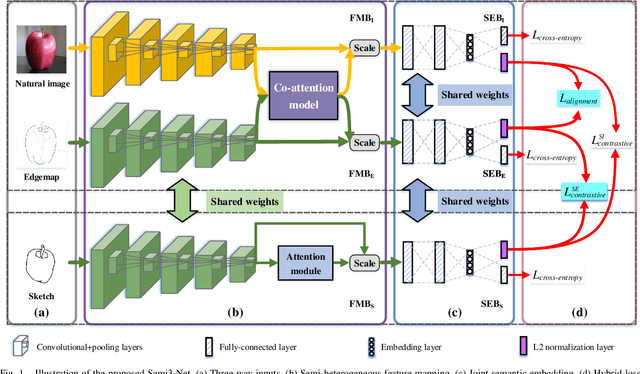
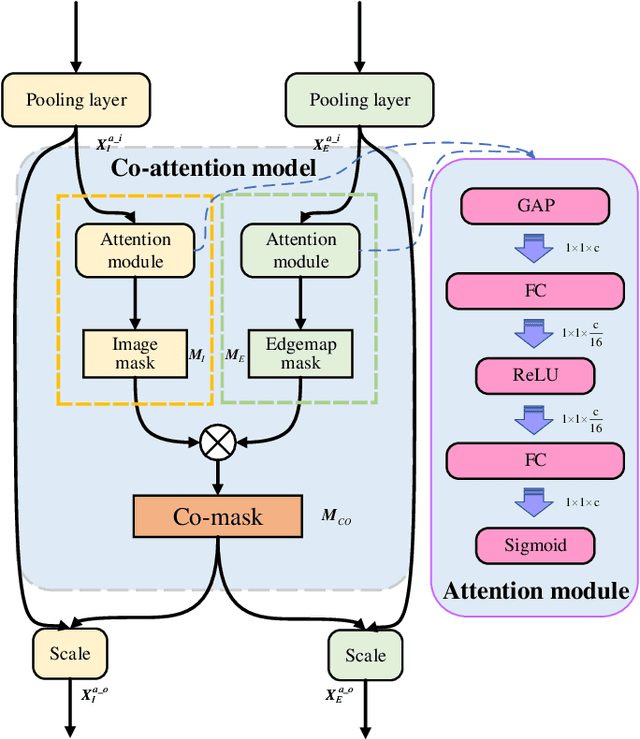

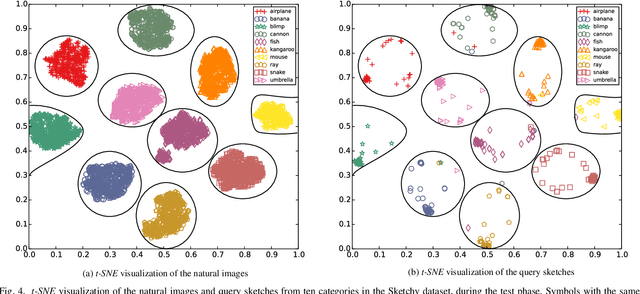
Sketch-based image retrieval (SBIR) is a challenging task due to the large cross-domain gap between sketches and natural images. How to align abstract sketches and natural images into a common high-level semantic space remains a key problem in SBIR. In this paper, we propose a novel semi-heterogeneous three-way joint embedding network (Semi3-Net), which integrates three branches (a sketch branch, a natural image branch, and an edgemap branch) to learn more discriminative cross-domain feature representations for the SBIR task. The key insight lies with how we cultivate the mutual and subtle relationships amongst the sketches, natural images, and edgemaps. A semi-heterogeneous feature mapping is designed to extract bottom features from each domain, where the sketch and edgemap branches are shared while the natural image branch is heterogeneous to the other branches. In addition, a joint semantic embedding is introduced to embed the features from different domains into a common high-level semantic space, where all of the three branches are shared. To further capture informative features common to both natural images and the corresponding edgemaps, a co-attention model is introduced to conduct common channel-wise feature recalibration between different domains. A hybrid-loss mechanism is designed to align the three branches, where an alignment loss and a sketch-edgemap contrastive loss are presented to encourage the network to learn invariant cross-domain representations. Experimental results on two widely used category-level datasets (Sketchy and TU-Berlin Extension) demonstrate that the proposed method outperforms state-of-the-art methods.
RFN-Nest: An end-to-end residual fusion network for infrared and visible images
Mar 14, 2021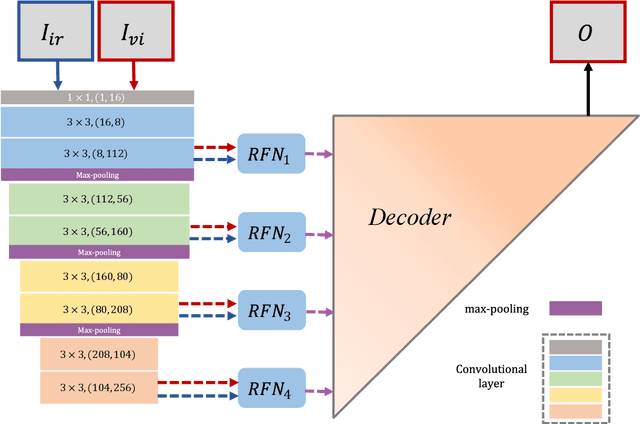
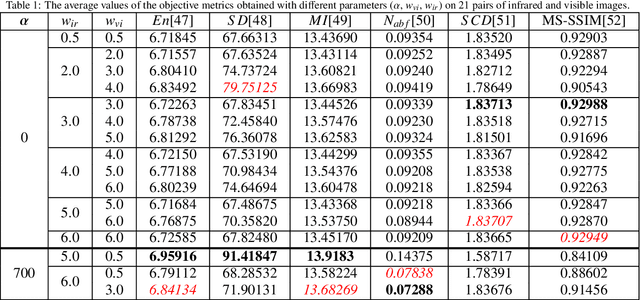
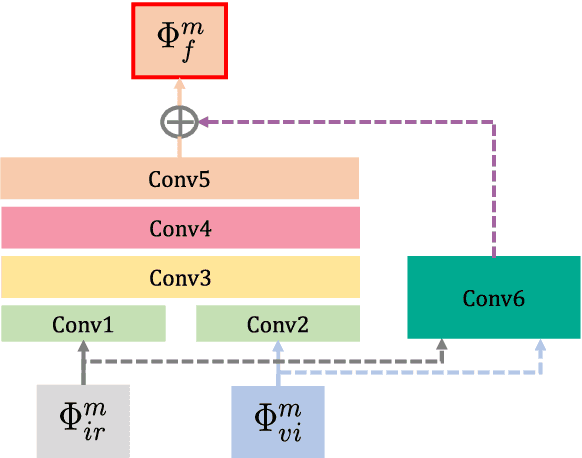

In the image fusion field, the design of deep learning-based fusion methods is far from routine. It is invariably fusion-task specific and requires a careful consideration. The most difficult part of the design is to choose an appropriate strategy to generate the fused image for a specific task in hand. Thus, devising learnable fusion strategy is a very challenging problem in the community of image fusion. To address this problem, a novel end-to-end fusion network architecture (RFN-Nest) is developed for infrared and visible image fusion. We propose a residual fusion network (RFN) which is based on a residual architecture to replace the traditional fusion approach. A novel detail-preserving loss function, and a feature enhancing loss function are proposed to train RFN. The fusion model learning is accomplished by a novel two-stage training strategy. In the first stage, we train an auto-encoder based on an innovative nest connection (Nest) concept. Next, the RFN is trained using the proposed loss functions. The experimental results on public domain data sets show that, compared with the existing methods, our end-to-end fusion network delivers a better performance than the state-of-the-art methods in both subjective and objective evaluation. The code of our fusion method is available at https://github.com/hli1221/imagefusion-rfn-nest