 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Feature-Align Network and Knowledge Distillation for Efficient Denoising
Mar 02, 2021

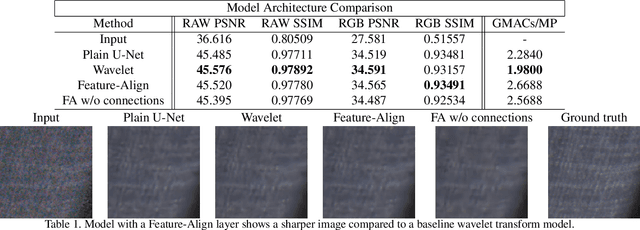
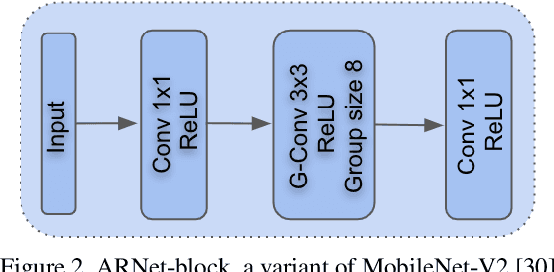
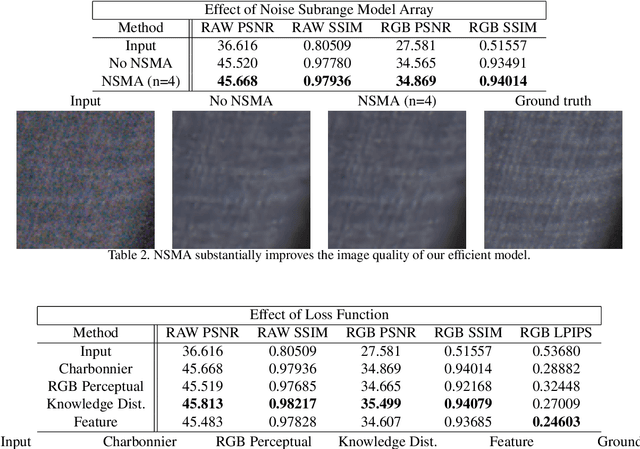
Deep learning-based RAW image denoising is a quintessential problem in image restoration. Recent works have pushed the state-of-the-art in denoising image quality. However, many of these networks are computationally too expensive for efficient use in mobile devices. Here, we propose a novel network for efficient RAW denoising on mobile devices. Our contributions are: (1) An efficient encoder-decoder network augmented with a new Feature-Align layer to attend to spatially varying noise. (2) A new perceptual Feature Loss calculated in the RAW domain to preserve high frequency image content. (3) An analysis of the use of multiple models tuned to different subranges of noise levels. (4) An open-source RAW noisy-clean paired dataset with noise modeling, to facilitate research in RAW denoising. We evaluate the effectiveness of our proposed network and training techniques and show results that compete with the state-of-the-art network, while using significantly fewer parameters and MACs. On the Darmstadt Noise Dataset benchmark, we achieve a PSNR of 48.28dB, with 263 times fewer MACs, and 17.6 times fewer parameters than the state-of-the-art network, which achieves 49.12 dB.
Learning by Aligning: Visible-Infrared Person Re-identification using Cross-Modal Correspondences
Aug 17, 2021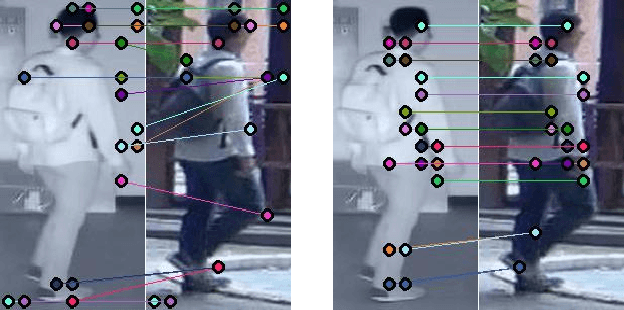
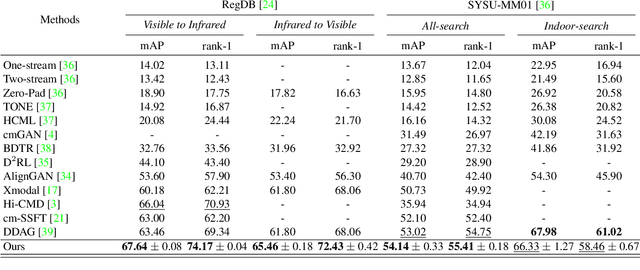
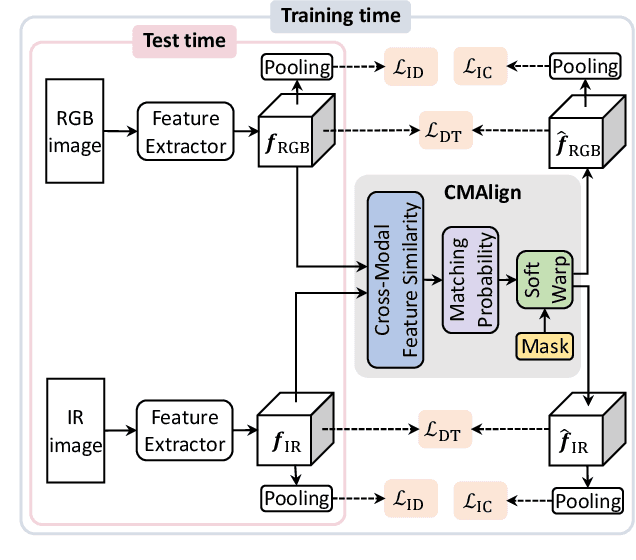
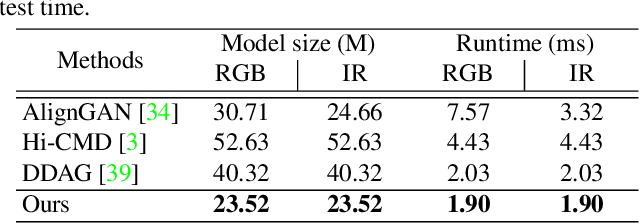
We address the problem of visible-infrared person re-identification (VI-reID), that is, retrieving a set of person images, captured by visible or infrared cameras, in a cross-modal setting. Two main challenges in VI-reID are intra-class variations across person images, and cross-modal discrepancies between visible and infrared images. Assuming that the person images are roughly aligned, previous approaches attempt to learn coarse image- or rigid part-level person representations that are discriminative and generalizable across different modalities. However, the person images, typically cropped by off-the-shelf object detectors, are not necessarily well-aligned, which distract discriminative person representation learning. In this paper, we introduce a novel feature learning framework that addresses these problems in a unified way. To this end, we propose to exploit dense correspondences between cross-modal person images. This allows to address the cross-modal discrepancies in a pixel-level, suppressing modality-related features from person representations more effectively. This also encourages pixel-wise associations between cross-modal local features, further facilitating discriminative feature learning for VI-reID. Extensive experiments and analyses on standard VI-reID benchmarks demonstrate the effectiveness of our approach, which significantly outperforms the state of the art.
Domain-Aware Universal Style Transfer
Aug 17, 2021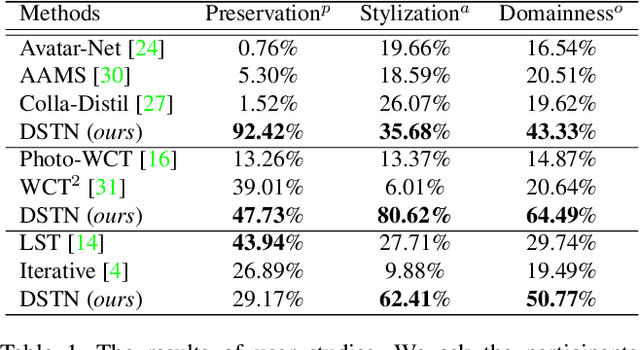
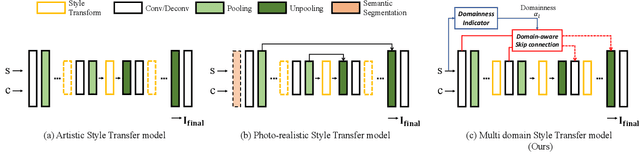
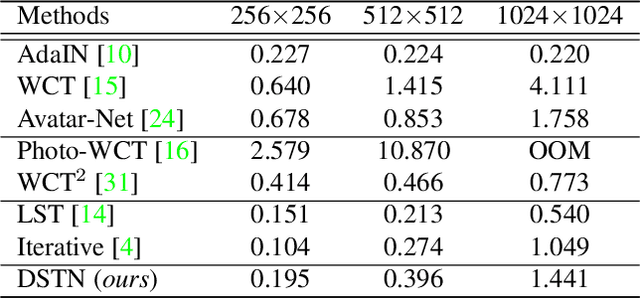
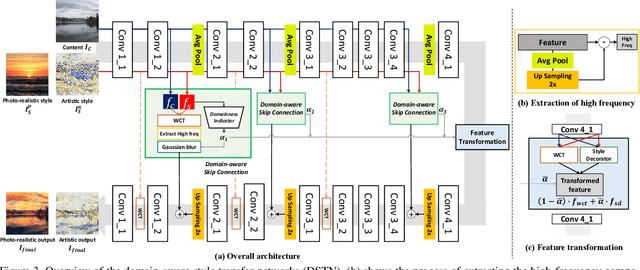
Style transfer aims to reproduce content images with the styles from reference images. Existing universal style transfer methods successfully deliver arbitrary styles to original images either in an artistic or a photo-realistic way. However, the range of 'arbitrary style' defined by existing works is bounded in the particular domain due to their structural limitation. Specifically, the degrees of content preservation and stylization are established according to a predefined target domain. As a result, both photo-realistic and artistic models have difficulty in performing the desired style transfer for the other domain. To overcome this limitation, we propose a unified architecture, Domain-aware Style Transfer Networks (DSTN) that transfer not only the style but also the property of domain (i.e., domainness) from a given reference image. To this end, we design a novel domainness indicator that captures the domainness value from the texture and structural features of reference images. Moreover, we introduce a unified framework with domain-aware skip connection to adaptively transfer the stroke and palette to the input contents guided by the domainness indicator. Our extensive experiments validate that our model produces better qualitative results and outperforms previous methods in terms of proxy metrics on both artistic and photo-realistic stylizations.
Decomposing 3D Scenes into Objects via Unsupervised Volume Segmentation
Apr 02, 2021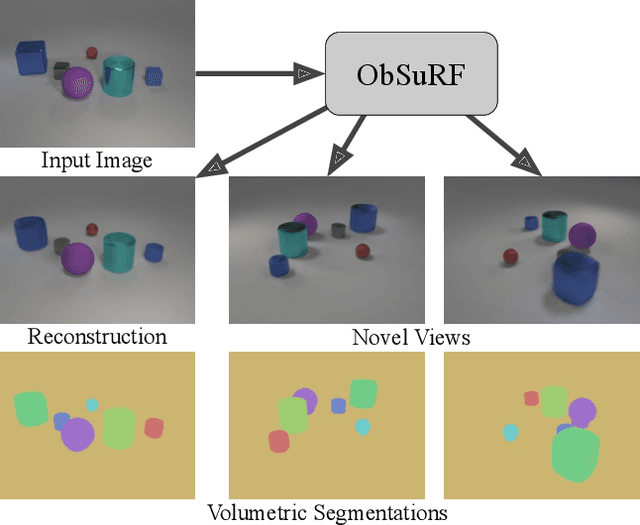
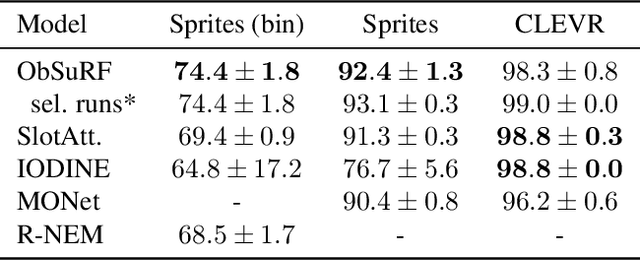
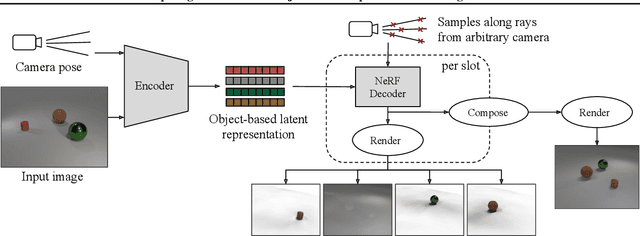

We present ObSuRF, a method which turns a single image of a scene into a 3D model represented as a set of Neural Radiance Fields (NeRFs), with each NeRF corresponding to a different object. A single forward pass of an encoder network outputs a set of latent vectors describing the objects in the scene. These vectors are used independently to condition a NeRF decoder, defining the geometry and appearance of each object. We make learning more computationally efficient by deriving a novel loss, which allows training NeRFs on RGB-D inputs without explicit ray marching. After confirming that the model performs equal or better than state of the art on three 2D image segmentation benchmarks, we apply it to two multi-object 3D datasets: A multiview version of CLEVR, and a novel dataset in which scenes are populated by ShapeNet models. We find that after training ObSuRF on RGB-D views of training scenes, it is capable of not only recovering the 3D geometry of a scene depicted in a single input image, but also to segment it into objects, despite receiving no supervision in that regard.
Invariance-based Multi-Clustering of Latent Space Embeddings for Equivariant Learning
Jul 25, 2021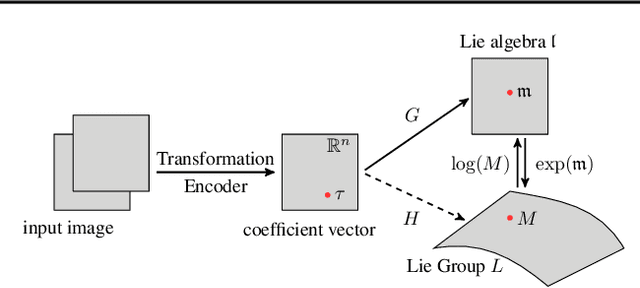
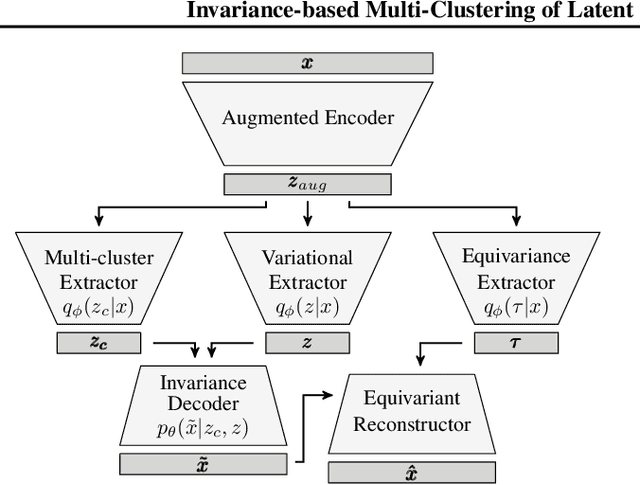

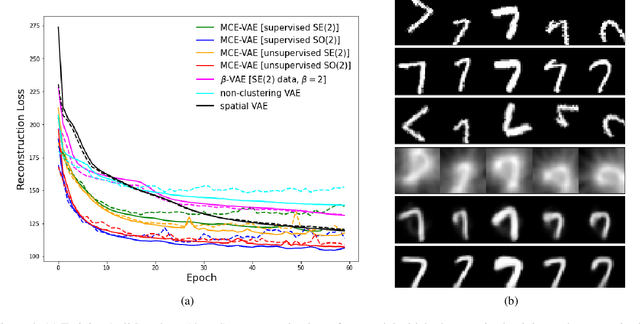
Variational Autoencoders (VAEs) have been shown to be remarkably effective in recovering model latent spaces for several computer vision tasks. However, currently trained VAEs, for a number of reasons, seem to fall short in learning invariant and equivariant clusters in latent space. Our work focuses on providing solutions to this problem and presents an approach to disentangle equivariance feature maps in a Lie group manifold by enforcing deep, group-invariant learning. Simultaneously implementing a novel separation of semantic and equivariant variables of the latent space representation, we formulate a modified Evidence Lower BOund (ELBO) by using a mixture model pdf like Gaussian mixtures for invariant cluster embeddings that allows superior unsupervised variational clustering. Our experiments show that this model effectively learns to disentangle the invariant and equivariant representations with significant improvements in the learning rate and an observably superior image recognition and canonical state reconstruction compared to the currently best deep learning models.
An Image Segmentation Model Based on a Variational Formulation
Oct 13, 2019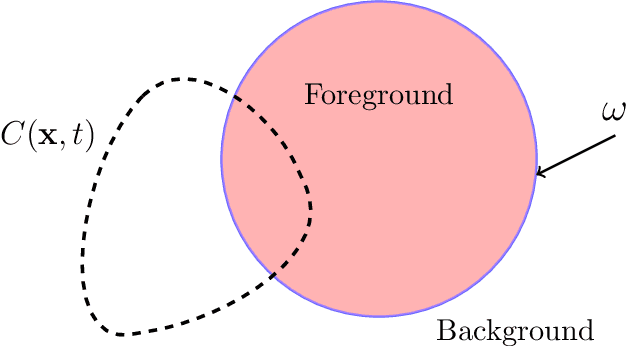


Starting from a variational formulation, we present a model for image segmentation that employs both region statistics and edge information. This combination allows for improved flexibility, making the proposed model suitable to process a wider class of images than purely region-based and edge-based models. We perform several simulations with real images that attest to the versatility of the model. We also show another set of experiments on images with certain pathologies that suggest opportunities for improvement.
Shelf-Supervised Mesh Prediction in the Wild
Feb 11, 2021
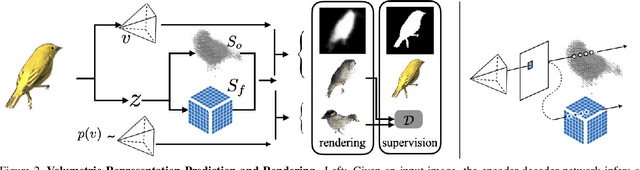
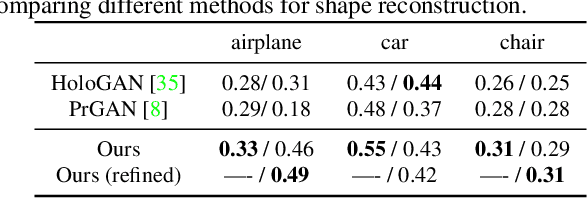
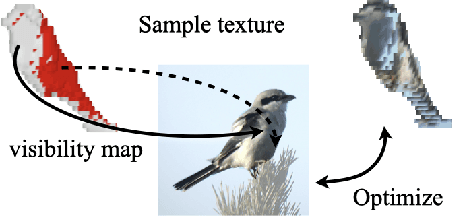
We aim to infer 3D shape and pose of object from a single image and propose a learning-based approach that can train from unstructured image collections, supervised by only segmentation outputs from off-the-shelf recognition systems (i.e. 'shelf-supervised'). We first infer a volumetric representation in a canonical frame, along with the camera pose. We enforce the representation geometrically consistent with both appearance and masks, and also that the synthesized novel views are indistinguishable from image collections. The coarse volumetric prediction is then converted to a mesh-based representation, which is further refined in the predicted camera frame. These two steps allow both shape-pose factorization from image collections and per-instance reconstruction in finer details. We examine the method on both synthetic and real-world datasets and demonstrate its scalability on 50 categories in the wild, an order of magnitude more classes than existing works.
Boosting Video Captioning with Dynamic Loss Network
Jul 25, 2021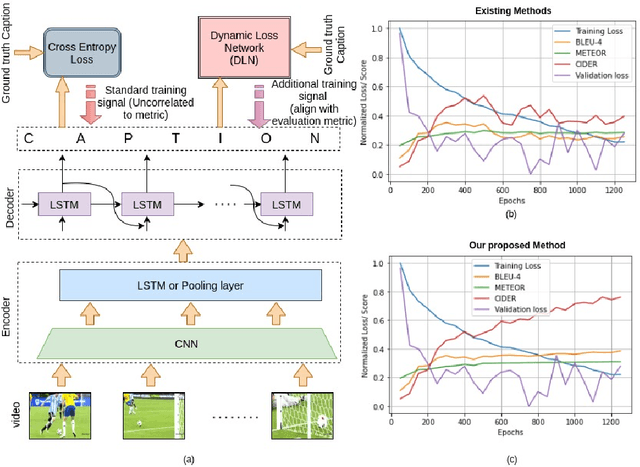
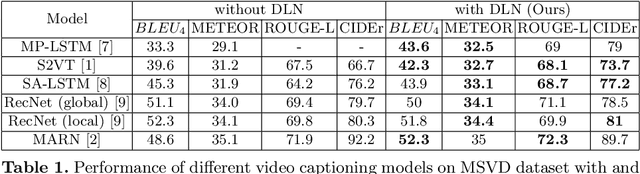
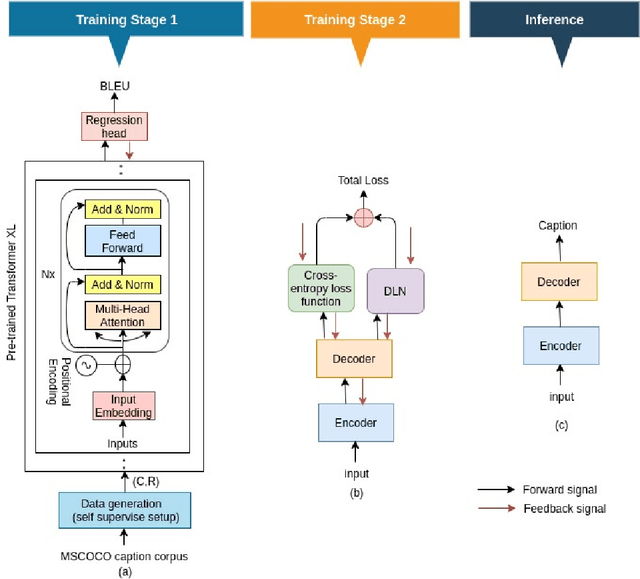
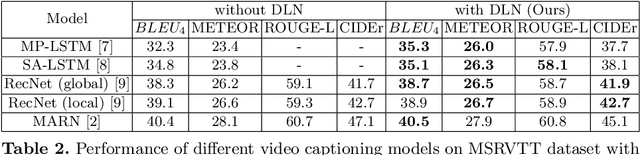
Video captioning is one of the challenging problems at the intersection of vision and language, having many real-life applications in video retrieval, video surveillance, assisting visually challenged people, Human-machine interface, and many more. Recent deep learning-based methods have shown promising results but are still on the lower side than other vision tasks (such as image classification, object detection). A significant drawback with existing video captioning methods is that they are optimized over cross-entropy loss function, which is uncorrelated to the de facto evaluation metrics (BLEU, METEOR, CIDER, ROUGE).In other words, cross-entropy is not a proper surrogate of the true loss function for video captioning. This paper addresses the drawback by introducing a dynamic loss network (DLN), which provides an additional feedback signal that directly reflects the evaluation metrics. Our results on Microsoft Research Video Description Corpus (MSVD) and MSR-Video to Text (MSRVTT) datasets outperform previous methods.
Pyramid Real Image Denoising Network
Aug 01, 2019
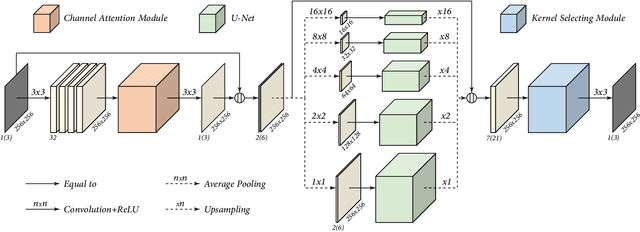
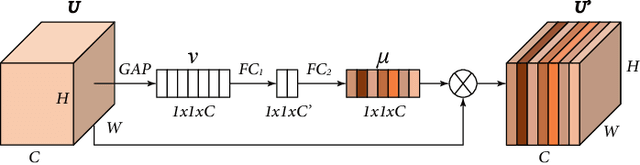
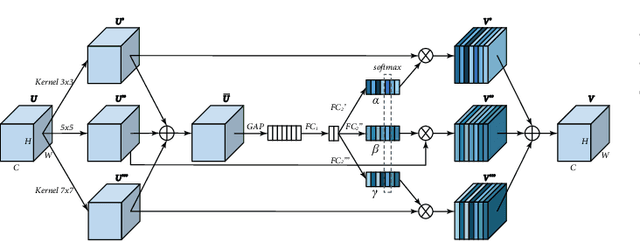
While deep Convolutional Neural Networks (CNNs) have shown extraordinary capability of modelling specific noise and denoising, they still perform poorly on real-world noisy images. The main reason is that the real-world noise is more sophisticated and diverse. To tackle the issue of blind denoising, in this paper, we propose a novel pyramid real image denoising network (PRIDNet), which contains three stages. First, the noise estimation stage uses channel attention mechanism to recalibrate the channel importance of input noise. Second, at the multi-scale denoising stage, pyramid pooling is utilized to extract multi-scale features. Third, the stage of feature fusion adopts a kernel selecting operation to adaptively fuse multi-scale features. Experiments on two datasets of real noisy photographs demonstrate that our approach can achieve competitive performance in comparison with state-of-the-art denoisers in terms of both quantitative measure and visual perception quality.
Single Image Super-Resolution via CNN Architectures and TV-TV Minimization
Jul 11, 2019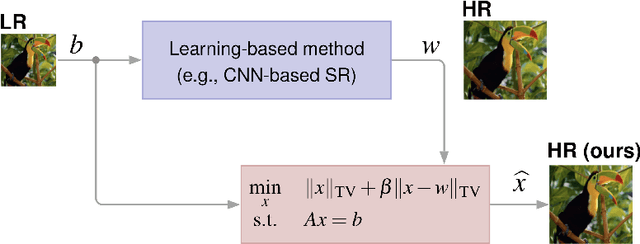
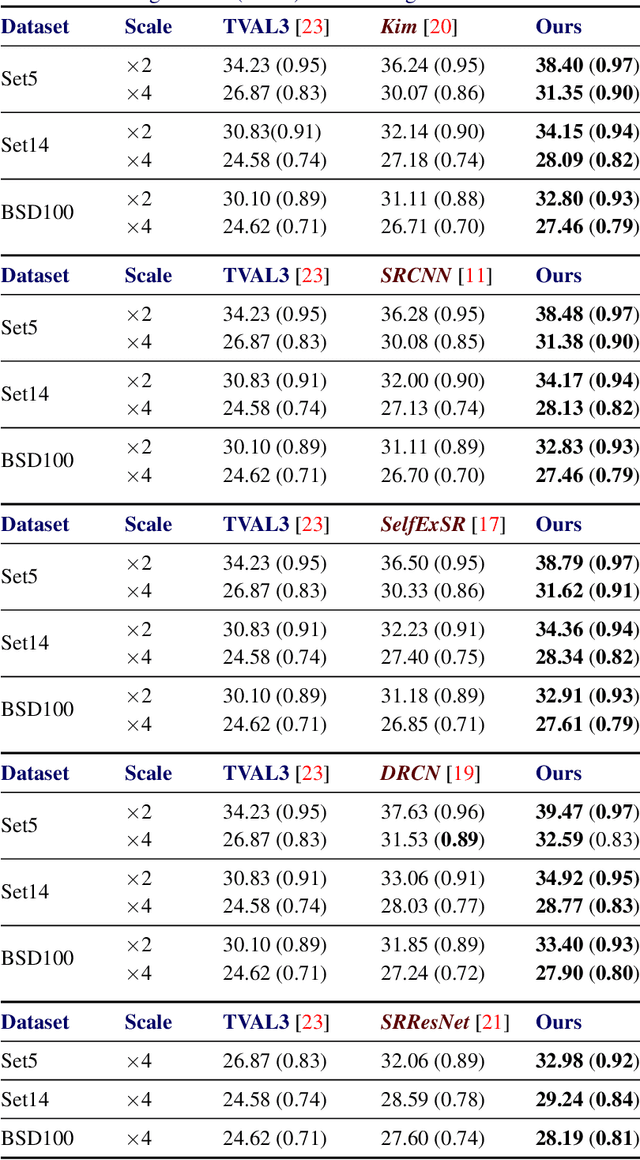

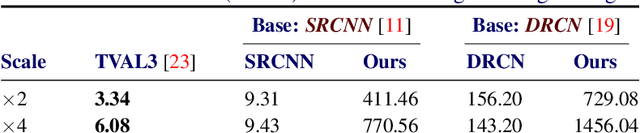
Super-resolution (SR) is a technique that allows increasing the resolution of a given image. Having applications in many areas, from medical imaging to consumer electronics, several SR methods have been proposed. Currently, the best performing methods are based on convolutional neural networks (CNNs) and require extensive datasets for training. However, at test time, they fail to impose consistency between the super-resolved image and the given low-resolution image, a property that classic reconstruction-based algorithms naturally enforce in spite of having poorer performance. Motivated by this observation, we propose a new framework that joins both approaches and produces images with superior quality than any of the prior methods. Although our framework requires additional computation, our experiments on Set5, Set14, and BSD100 show that it systematically produces images with better peak signal to noise ratio (PSNR) and structural similarity (SSIM) than the current state-of-the-art CNN architectures for SR.