 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Image is Worth 16x16 Words, What is a Video Worth?
Mar 25, 2021
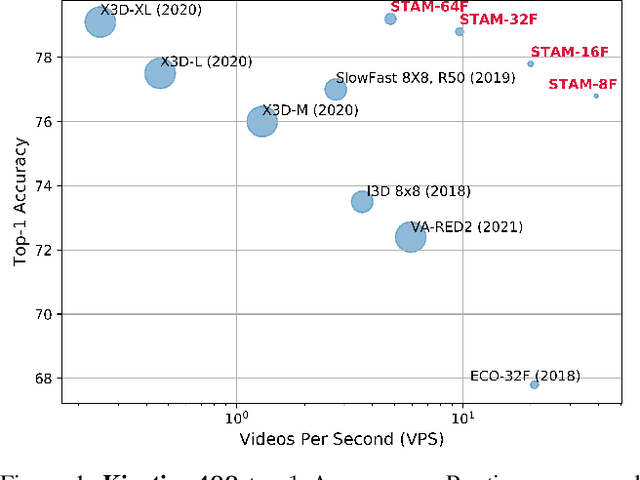
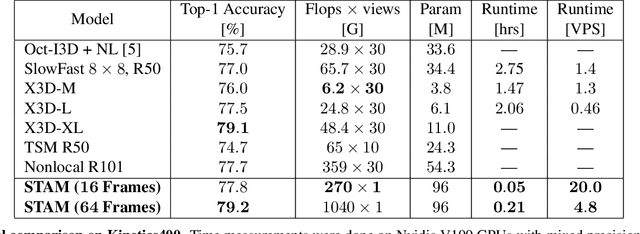

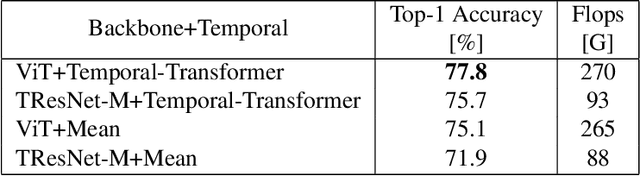
Leading methods in the domain of action recognition try to distill information from both the spatial and temporal dimensions of an input video. Methods that reach State of the Art (SotA) accuracy, usually make use of 3D convolution layers as a way to abstract the temporal information from video frames. The use of such convolutions requires sampling short clips from the input video, where each clip is a collection of closely sampled frames. Since each short clip covers a small fraction of an input video, multiple clips are sampled at inference in order to cover the whole temporal length of the video. This leads to increased computational load and is impractical for real-world applications. We address the computational bottleneck by significantly reducing the number of frames required for inference. Our approach relies on a temporal transformer that applies global attention over video frames, and thus better exploits the salient information in each frame. Therefore our approach is very input efficient, and can achieve SotA results (on Kinetics dataset) with a fraction of the data (frames per video), computation and latency. Specifically on Kinetics-400, we reach 78.8 top-1 accuracy with $\times 30$ less frames per video, and $\times 40$ faster inference than the current leading method. Code is available at: https://github.com/Alibaba-MIIL/STAM
Unrolled Wirtinger Flow with Deep Priors for Phaseless Imaging
Aug 12, 2021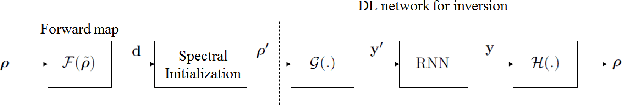
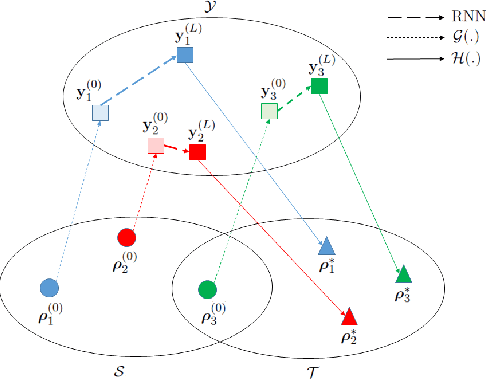

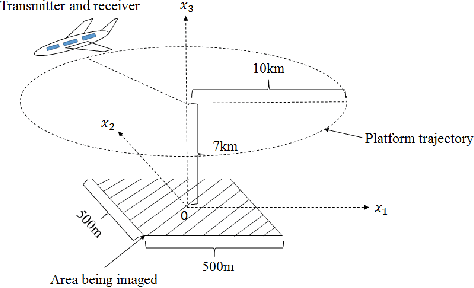
We introduce a deep learning (DL) based network for imaging from measurement intensities. The network architecture uses a recurrent structure that unrolls the Wirtinger Flow (WF) algorithm with a deep prior which enables performing the algorithm updates in a lower dimensional encoded image space. We use a separate deep network (DN), referred to as the encoding network, for transforming the spectral initialization used in the WF algorithm to an appropriate initial value for the encoded domain. The unrolling scheme that models a fixed number of iterations of the underlying algorithm into a recurrent neural network (RNN) enable us to simultaneously learn the parameters of the prior network, the encoding network and the RNN during training. We establish sufficient conditions on the network to guarantee exact recovery under deterministic forward models and demonstrate the relation between the Lipschitz constants of the trained prior and encoding networks to the convergence rate. We show the practical applicability of our method on synthetic aperture imaging using high fidelity simulation data from the PCSWAT software. Our numerical study shows that the deep prior facilitates improvements in sample complexity.
Mitigating Information Leakage in Image Representations: A Maximum Entropy Approach
Apr 11, 2019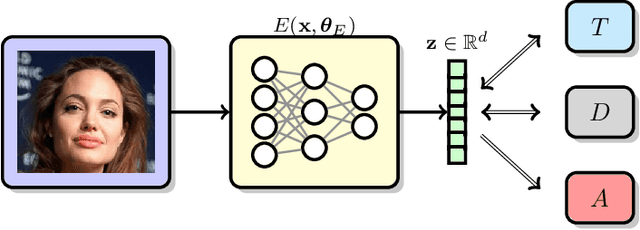
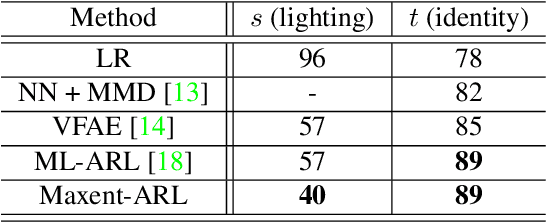
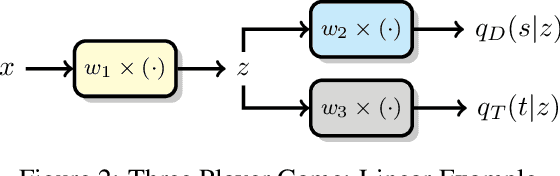
Image recognition systems have demonstrated tremendous progress over the past few decades thanks, in part, to our ability of learning compact and robust representations of images. As we witness the wide spread adoption of these systems, it is imperative to consider the problem of unintended leakage of information from an image representation, which might compromise the privacy of the data owner. This paper investigates the problem of learning an image representation that minimizes such leakage of user information. We formulate the problem as an adversarial non-zero sum game of finding a good embedding function with two competing goals: to retain as much task dependent discriminative image information as possible, while simultaneously minimizing the amount of information, as measured by entropy, about other sensitive attributes of the user. We analyze the stability and convergence dynamics of the proposed formulation using tools from non-linear systems theory and compare to that of the corresponding adversarial zero-sum game formulation that optimizes likelihood as a measure of information content. Numerical experiments on UCI, Extended Yale B, CIFAR-10 and CIFAR-100 datasets indicate that our proposed approach is able to learn image representations that exhibit high task performance while mitigating leakage of predefined sensitive information.
A registration error estimation framework for correlative imaging
Mar 10, 2021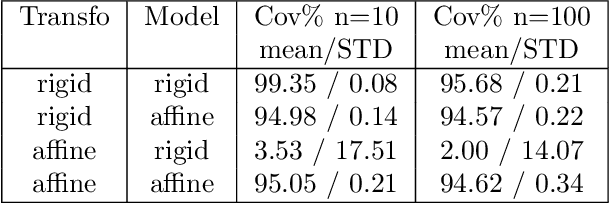
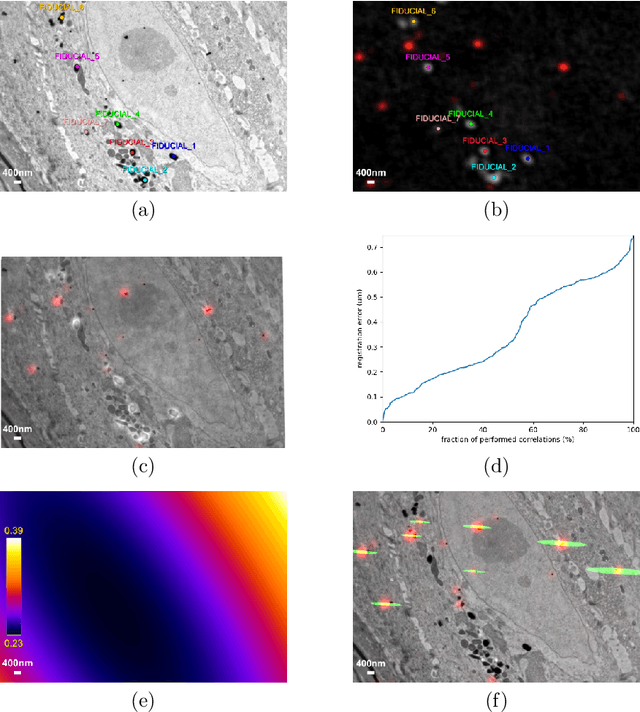
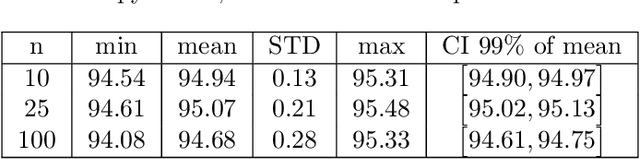
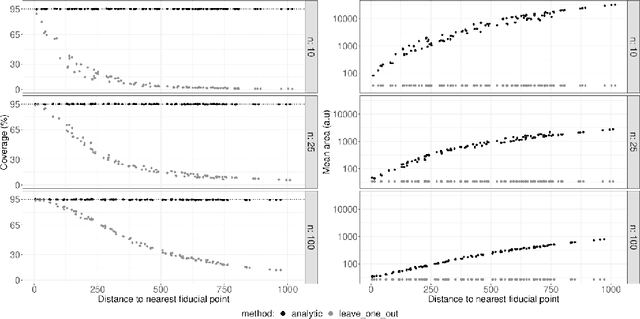
Correlative imaging workflows are now widely used in bioimaging and aims to image the same sample using at least two different and complementary imaging modalities. Part of the workflow relies on finding the transformation linking a source image to a target image. We are specifically interested in the estimation of registration error in point-based registration. We propose an application of multivariate linear regression to solve the registration problem allowing us to propose a framework for the estimation of the associated error in the case of rigid and affine transformations and with anisotropic noise. These developments can be used as a decision-support tool for the biologist to analyze multimodal correlative images and are available under Ec-CLEM, an open-source plugin under ICY.
Multi-Label Gold Asymmetric Loss Correction with Single-Label Regulators
Aug 04, 2021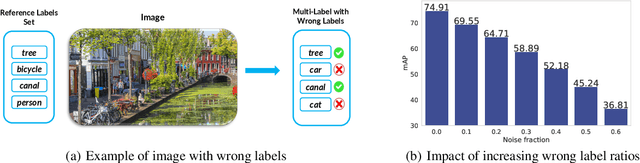
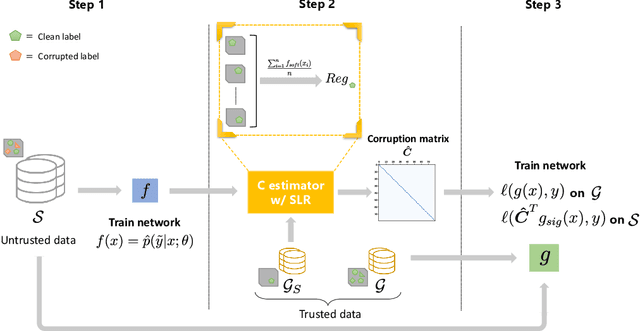
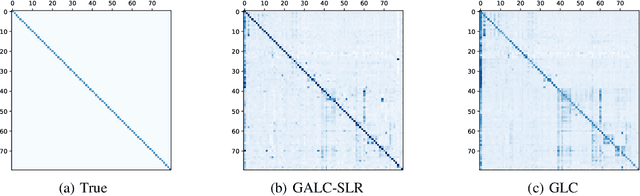
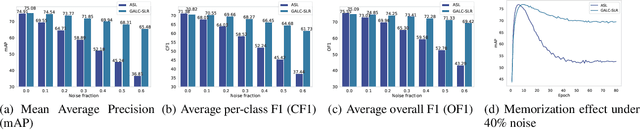
Multi-label learning is an emerging extension of the multi-class classification where an image contains multiple labels. Not only acquiring a clean and fully labeled dataset in multi-label learning is extremely expensive, but also many of the actual labels are corrupted or missing due to the automated or non-expert annotation techniques. Noisy label data decrease the prediction performance drastically. In this paper, we propose a novel Gold Asymmetric Loss Correction with Single-Label Regulators (GALC-SLR) that operates robust against noisy labels. GALC-SLR estimates the noise confusion matrix using single-label samples, then constructs an asymmetric loss correction via estimated confusion matrix to avoid overfitting to the noisy labels. Empirical results show that our method outperforms the state-of-the-art original asymmetric loss multi-label classifier under all corruption levels, showing mean average precision improvement up to 28.67% on a real world dataset of MS-COCO, yielding a better generalization of the unseen data and increased prediction performance.
Operational Learning-based Boundary Estimation in Electromagnetic Medical Imaging
Aug 04, 2021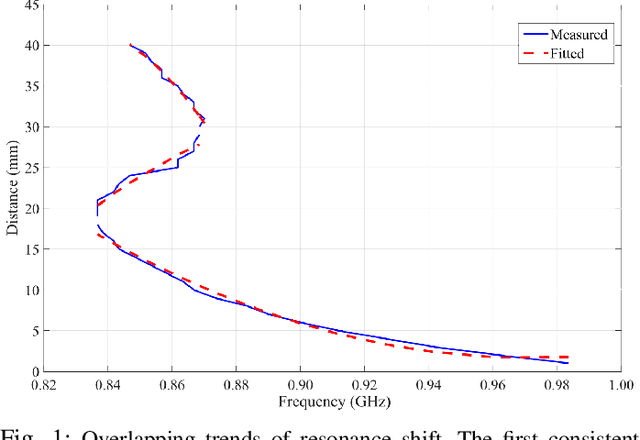
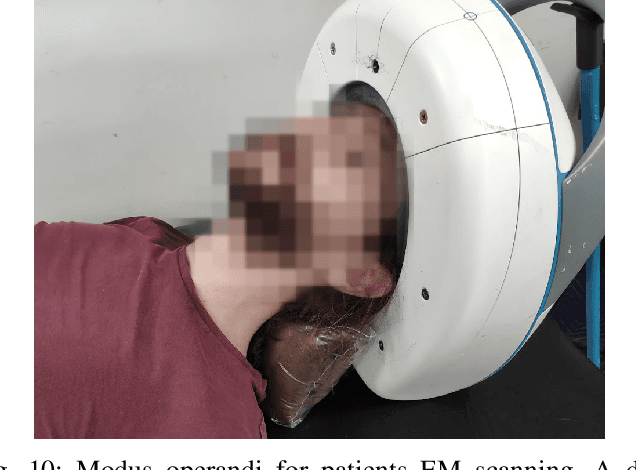
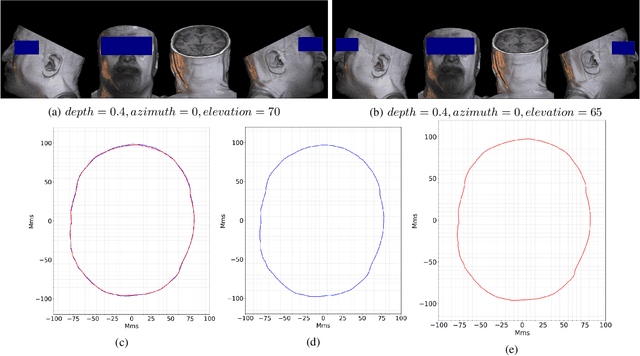
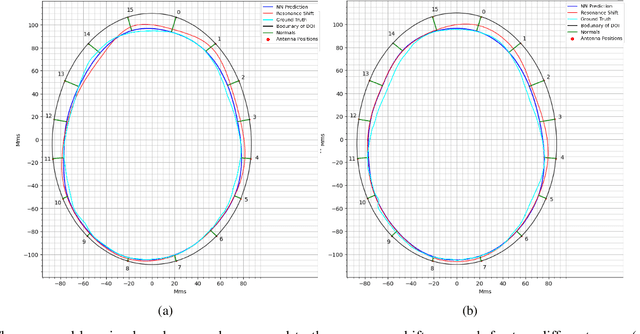
Incorporating boundaries of the imaging object as a priori information to imaging algorithms can significantly improve the performance of electromagnetic medical imaging systems. To avoid overly complicating the system by using different sensors and the adverse effect of the subject's movement, a learning-based method is proposed to estimate the boundary (external contour) of the imaged object using the same electromagnetic imaging data. While imaging techniques may discard the reflection coefficients for being dominant and uninformative for imaging, these parameters are made use of for boundary detection. The learned model is verified through independent clinical human trials by using a head imaging system with a 16-element antenna array that works across the band 0.7-1.6 GHz. The evaluation demonstrated that the model achieves average dissimilarity of 0.012 in Hu-moment while detecting head boundary. The model enables fast scan and image creation while eliminating the need for additional devices for accurate boundary estimation.
* Under Review
Non-Homogeneous Haze Removal via Artificial Scene Prior and Bidimensional Graph Reasoning
Apr 05, 2021
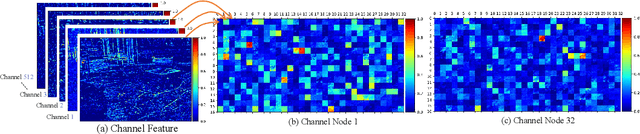
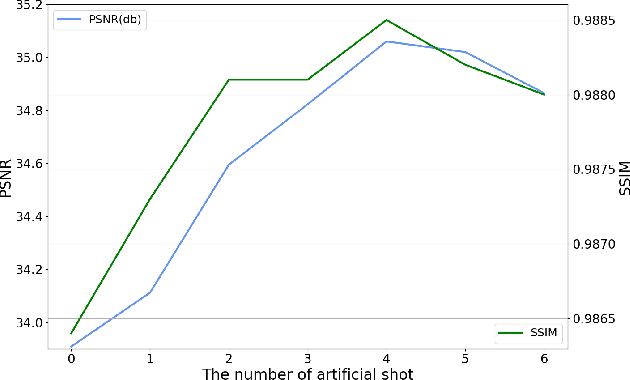
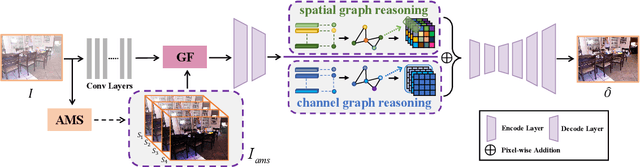
Due to the lack of natural scene and haze prior information, it is greatly challenging to completely remove the haze from single image without distorting its visual content. Fortunately, the real-world haze usually presents non-homogeneous distribution, which provides us with many valuable clues in partial well-preserved regions. In this paper, we propose a Non-Homogeneous Haze Removal Network (NHRN) via artificial scene prior and bidimensional graph reasoning. Firstly, we employ the gamma correction iteratively to simulate artificial multiple shots under different exposure conditions, whose haze degrees are different and enrich the underlying scene prior. Secondly, beyond utilizing the local neighboring relationship, we build a bidimensional graph reasoning module to conduct non-local filtering in the spatial and channel dimensions of feature maps, which models their long-range dependency and propagates the natural scene prior between the well-preserved nodes and the nodes contaminated by haze. We evaluate our method on different benchmark datasets. The results demonstrate that our method achieves superior performance over many state-of-the-art algorithms for both the single image dehazing and hazy image understanding tasks.
Multiscale Laplacian Learning
Sep 08, 2021
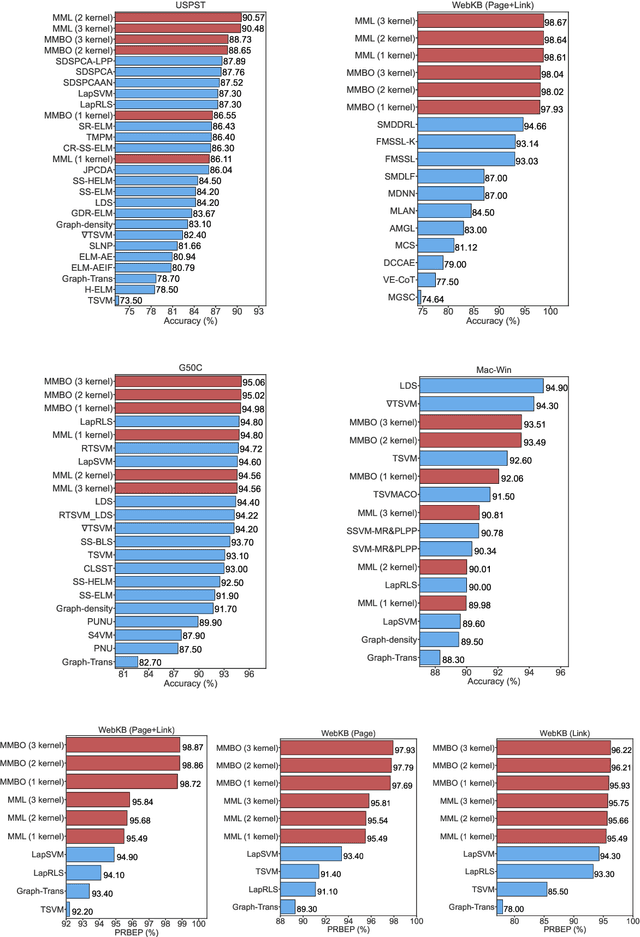
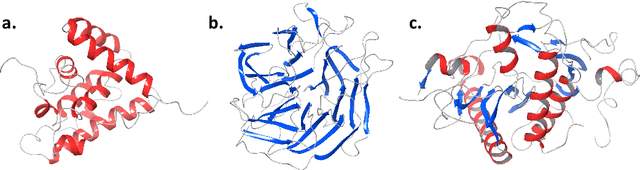
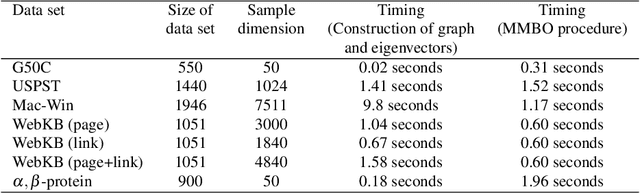
Machine learning methods have greatly changed science, engineering, finance, business, and other fields. Despite the tremendous accomplishments of machine learning and deep learning methods, many challenges still remain. In particular, the performance of machine learning methods is often severely affected in case of diverse data, usually associated with smaller data sets or data related to areas of study where the size of the data sets is constrained by the complexity and/or high cost of experiments. Moreover, data with limited labeled samples is a challenge to most learning approaches. In this paper, the aforementioned challenges are addressed by integrating graph-based frameworks, multiscale structure, modified and adapted optimization procedures and semi-supervised techniques. This results in two innovative multiscale Laplacian learning (MLL) approaches for machine learning tasks, such as data classification, and for tackling diverse data, data with limited samples and smaller data sets. The first approach, called multikernel manifold learning (MML), integrates manifold learning with multikernel information and solves a regularization problem consisting of a loss function and a warped kernel regularizer using multiscale graph Laplacians. The second approach, called the multiscale MBO (MMBO) method, introduces multiscale Laplacians to a modification of the famous classical Merriman-Bence-Osher (MBO) scheme, and makes use of fast solvers for finding the approximations to the extremal eigenvectors of the graph Laplacian. We demonstrate the performance of our methods experimentally on a variety of data sets, such as biological, text and image data, and compare them favorably to existing approaches.
MLP-Mixer: An all-MLP Architecture for Vision
May 04, 2021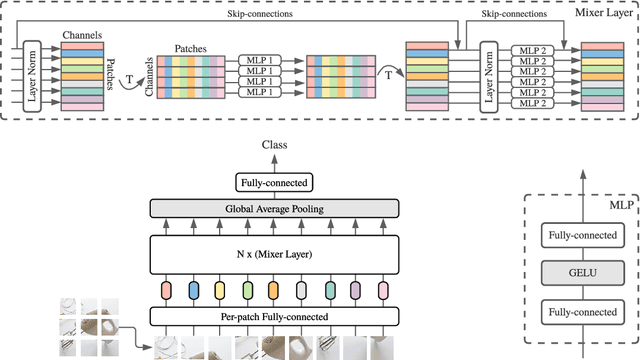
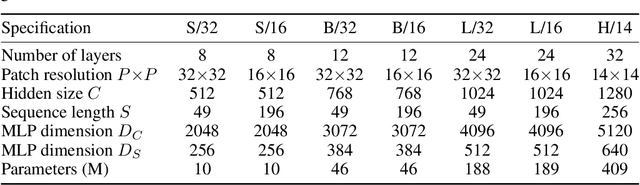
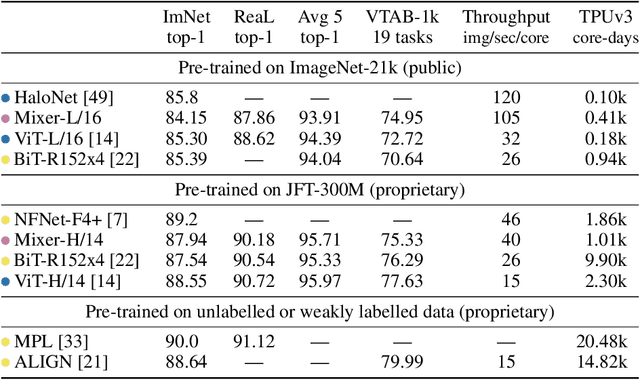
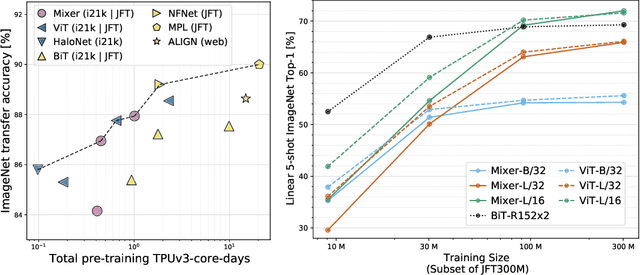
Convolutional Neural Networks (CNNs) are the go-to model for computer vision. Recently, attention-based networks, such as the Vision Transformer, have also become popular. In this paper we show that while convolutions and attention are both sufficient for good performance, neither of them are necessary. We present MLP-Mixer, an architecture based exclusively on multi-layer perceptrons (MLPs). MLP-Mixer contains two types of layers: one with MLPs applied independently to image patches (i.e. "mixing" the per-location features), and one with MLPs applied across patches (i.e. "mixing" spatial information). When trained on large datasets, or with modern regularization schemes, MLP-Mixer attains competitive scores on image classification benchmarks, with pre-training and inference cost comparable to state-of-the-art models. We hope that these results spark further research beyond the realms of well established CNNs and Transformers.
GAN Inversion: A Survey
Jan 14, 2021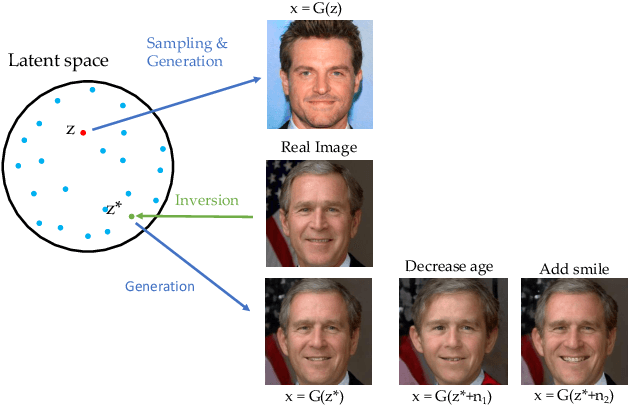
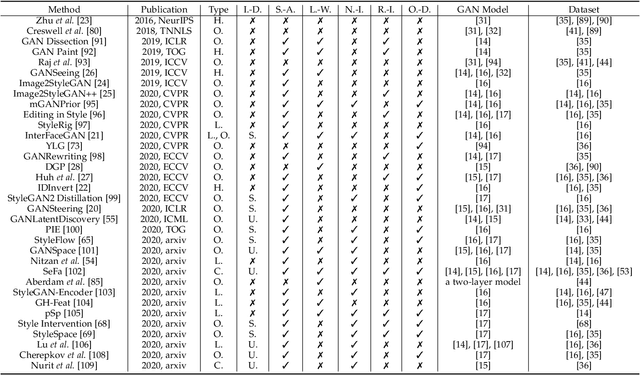
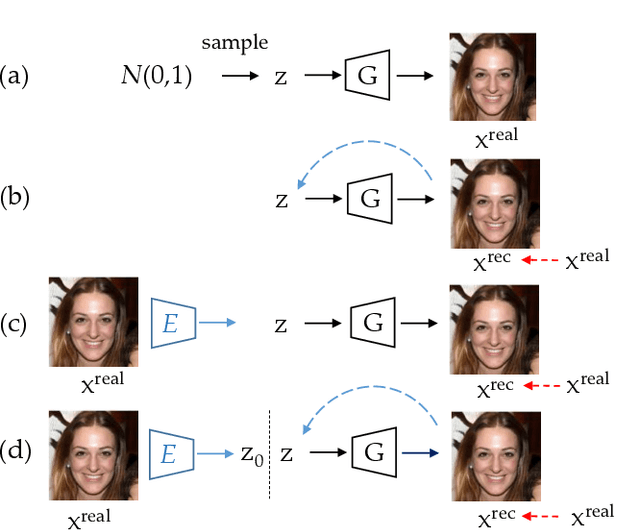
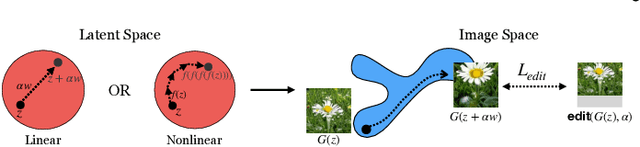
GAN inversion aims to invert a given image back into the latent space of a pretrained GAN model, for the image to be faithfully reconstructed from the inverted code by the generator. As an emerging technique to bridge the real and fake image domains, GAN inversion plays an essential role in enabling the pretrained GAN models such as StyleGAN and BigGAN to be used for real image editing applications. Meanwhile, GAN inversion also provides insights on the interpretation of GAN's latent space and how the realistic images can be generated. In this paper, we provide an overview of GAN inversion with a focus on its recent algorithms and applications. We cover important techniques of GAN inversion and their applications to image restoration and image manipulation. We further elaborate on some trends and challenges for future directions.