 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Asynchronous Federated Learning for Sensor Data with Concept Drift
Sep 01, 2021
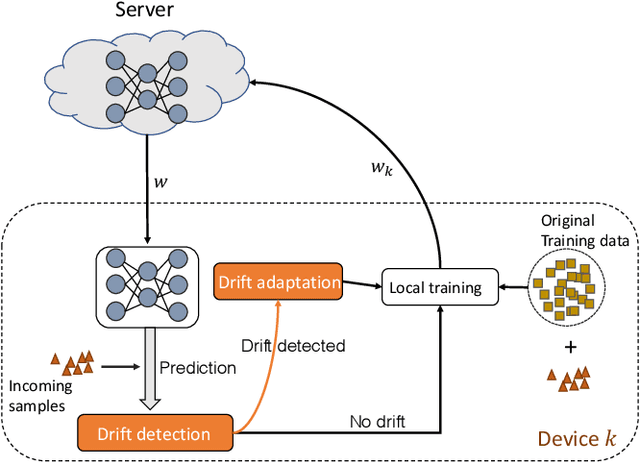
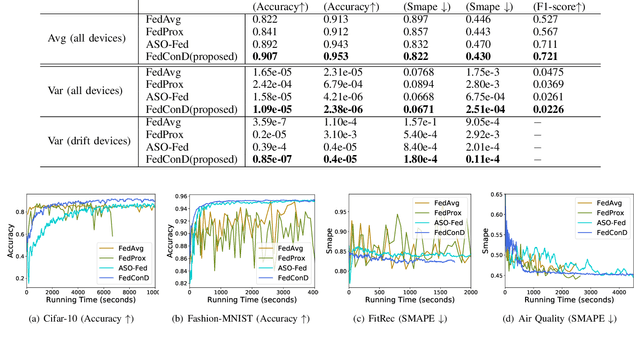
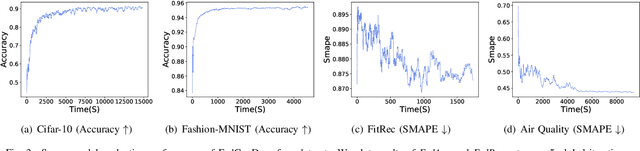
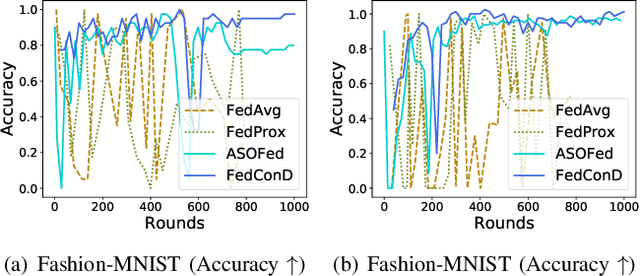
Federated learning (FL) involves multiple distributed devices jointly training a shared model without any of the participants having to reveal their local data to a centralized server. Most of previous FL approaches assume that data on devices are fixed and stationary during the training process. However, this assumption is unrealistic because these devices usually have varying sampling rates and different system configurations. In addition, the underlying distribution of the device data can change dynamically over time, which is known as concept drift. Concept drift makes the learning process complicated because of the inconsistency between existing and upcoming data. Traditional concept drift handling techniques such as chunk based and ensemble learning-based methods are not suitable in the federated learning frameworks due to the heterogeneity of local devices. We propose a novel approach, FedConD, to detect and deal with the concept drift on local devices and minimize the effect on the performance of models in asynchronous FL. The drift detection strategy is based on an adaptive mechanism which uses the historical performance of the local models. The drift adaptation is realized by adjusting the regularization parameter of objective function on each local device. Additionally, we design a communication strategy on the server side to select local updates in a prudent fashion and speed up model convergence. Experimental evaluations on three evolving data streams and two image datasets show that \model~detects and handles concept drift, and also reduces the overall communication cost compared to other baseline methods.
MOC-GAN: Mixing Objects and Captions to Generate Realistic Images
Jun 06, 2021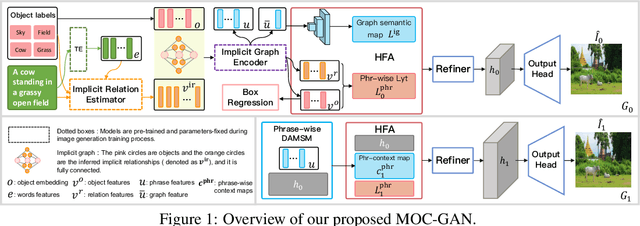
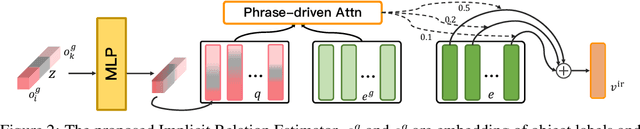
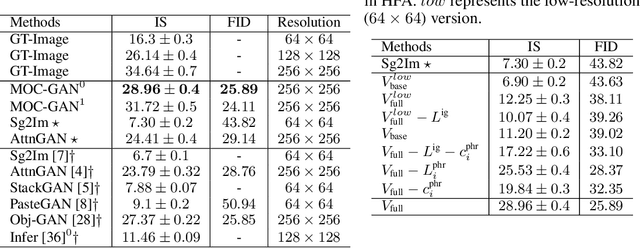

Generating images with conditional descriptions gains increasing interests in recent years. However, existing conditional inputs are suffering from either unstructured forms (captions) or limited information and expensive labeling (scene graphs). For a targeted scene, the core items, objects, are usually definite while their interactions are flexible and hard to clearly define. Thus, we introduce a more rational setting, generating a realistic image from the objects and captions. Under this setting, objects explicitly define the critical roles in the targeted images and captions implicitly describe their rich attributes and connections. Correspondingly, a MOC-GAN is proposed to mix the inputs of two modalities to generate realistic images. It firstly infers the implicit relations between object pairs from the captions to build a hidden-state scene graph. So a multi-layer representation containing objects, relations and captions is constructed, where the scene graph provides the structures of the scene and the caption provides the image-level guidance. Then a cascaded attentive generative network is designed to coarse-to-fine generate phrase patch by paying attention to the most relevant words in the caption. In addition, a phrase-wise DAMSM is proposed to better supervise the fine-grained phrase-patch consistency. On COCO dataset, our method outperforms the state-of-the-art methods on both Inception Score and FID while maintaining high visual quality. Extensive experiments demonstrate the unique features of our proposed method.
The Art of Food: Meal Image Synthesis from Ingredients
May 09, 2019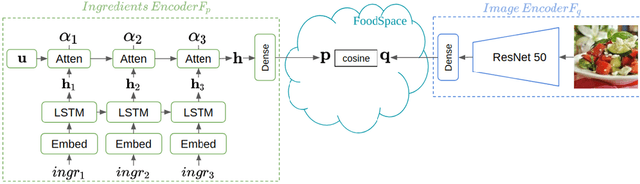
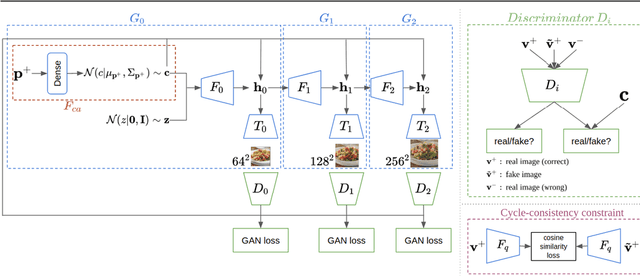


In this work we propose a new computational framework, based on generative deep models, for synthesis of photo-realistic food meal images from textual descriptions of its ingredients. Previous works on synthesis of images from text typically rely on pre-trained text models to extract text features, followed by a generative neural networks (GANs) aimed to generate realistic images conditioned on the text features. These works mainly focus on generating spatially compact and well-defined categories of objects, such as birds or flowers. In contrast, meal images are significantly more complex, consisting of multiple ingredients whose appearance and spatial qualities are further modified by cooking methods. We propose a method that first builds an attention-based ingredients-image association model, which is then used to condition a generative neural network tasked with synthesizing meal images. Furthermore, a cycle-consistent constraint is added to further improve image quality and control appearance. Extensive experiments show our model is able to generate meal image corresponding to the ingredients, which could be used to augment existing dataset for solving other computational food analysis problems.
Mask2Lesion: Mask-Constrained Adversarial Skin Lesion Image Synthesis
Jun 13, 2019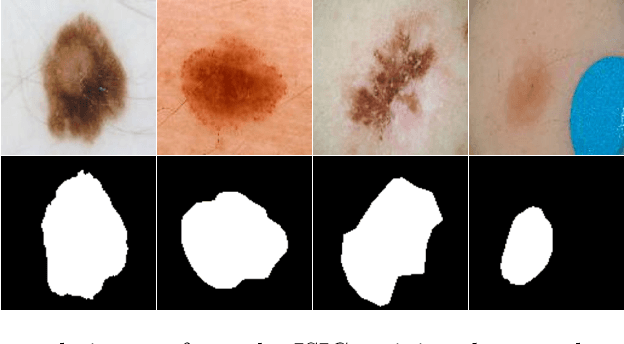
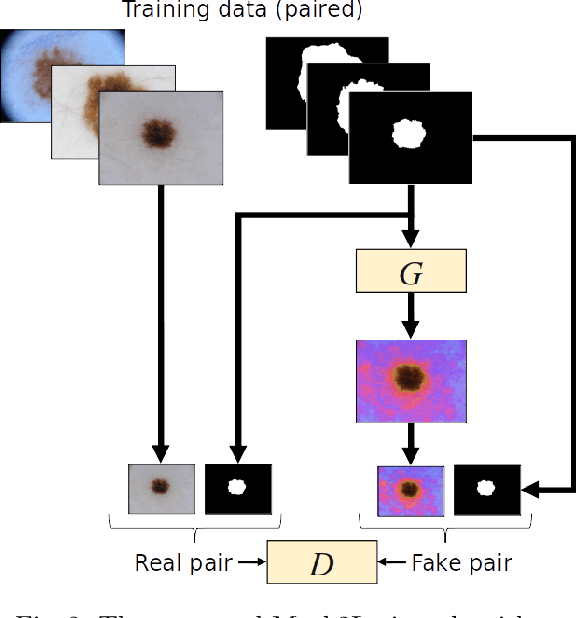

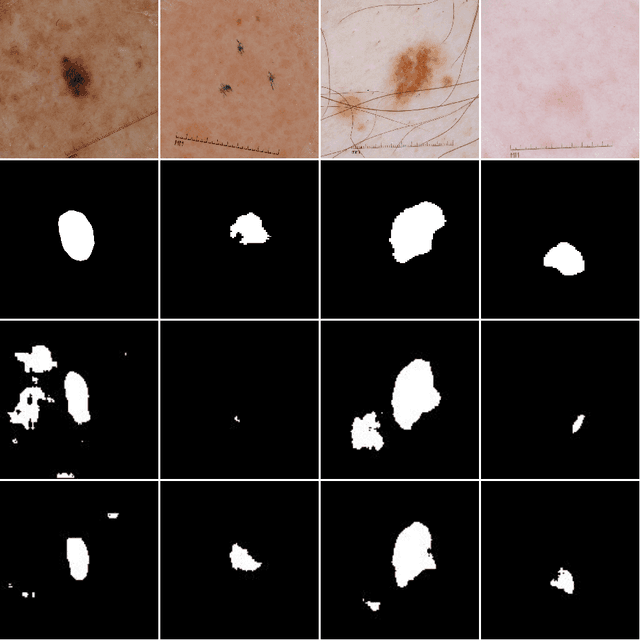
Skin lesion segmentation is a vital task in skin cancer diagnosis and further treatment. Although deep learning based approaches have significantly improved the segmentation accuracy, these algorithms are still reliant on having a large enough dataset in order to achieve adequate results. Inspired by the immense success of generative adversarial networks (GANs), we propose a GAN-based augmentation of the original dataset in order to improve the segmentation performance. In particular, we use the segmentation masks available in the training dataset to generate new synthetic skin lesion images using a conditional GAN, modeling this as a paired image-to-image translation task, which are then used to augment the original training dataset. We test Mask2Lesion augmentation on the ISBI ISIC 2017 Skin Lesion Segmentation Challenge dataset and observe that it improves the segmentation accuracy, compared to a model trained with only classical data augmentation techniques by 1.12%.
BUZz: BUffer Zones for defending adversarial examples in image classification
Oct 03, 2019

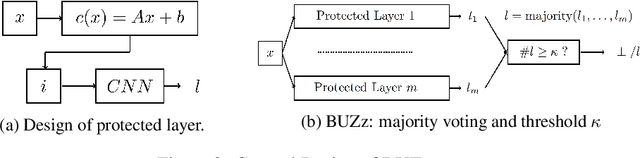
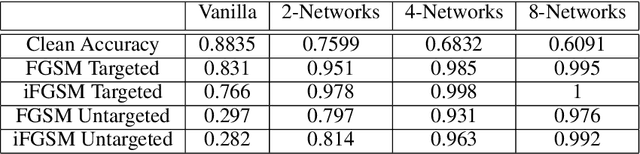
We propose a novel defense against all existing gradient based adversarial attacks on deep neural networks for image classification problems. Our defense is based on a combination of deep neural networks and simple image transformations. While straight forward in implementation, this defense yields a unique security property which we term buffer zones. In this paper, we formalize the concept of buffer zones. We argue that our defense based on buffer zones is secure against state-of-the-art black box attacks. We are able to achieve this security even when the adversary has access to the {\em entire} original training data set and unlimited query access to the defense. We verify our security claims through experimentation using FashionMNIST, CIFAR-10 and CIFAR-100. We demonstrate $<10\%$ attack success rate -- significantly lower than what other well-known defenses offer -- at only a price of a 15-20\% drop in clean accuracy. By using a new intuitive metric we explain why this trade-off offers a significant improvement over prior work.
A Machine-Learning-Ready Dataset Prepared from the Solar and Heliospheric Observatory Mission
Aug 04, 2021

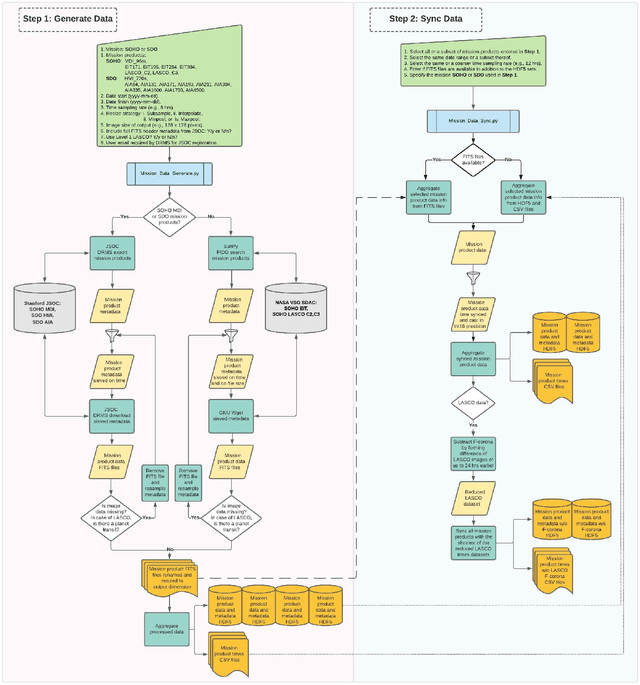

We present a Python tool to generate a standard dataset from solar images that allows for user-defined selection criteria and a range of pre-processing steps. Our Python tool works with all image products from both the Solar and Heliospheric Observatory (SoHO) and Solar Dynamics Observatory (SDO) missions. We discuss a dataset produced from the SoHO mission's multi-spectral images which is free of missing or corrupt data as well as planetary transits in coronagraph images, and is temporally synced making it ready for input to a machine learning system. Machine-learning-ready images are a valuable resource for the community because they can be used, for example, for forecasting space weather parameters. We illustrate the use of this data with a 3-5 day-ahead forecast of the north-south component of the interplanetary magnetic field (IMF) observed at Lagrange point one (L1). For this use case, we apply a deep convolutional neural network (CNN) to a subset of the full SoHO dataset and compare with baseline results from a Gaussian Naive Bayes classifier.
Oriented R-CNN for Object Detection
Aug 12, 2021
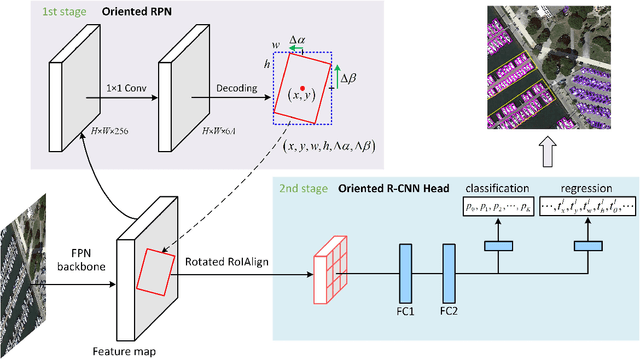
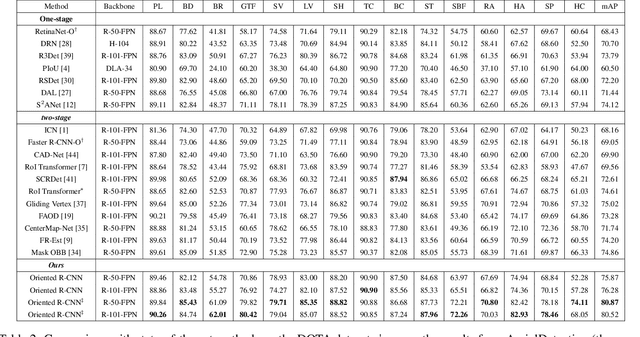
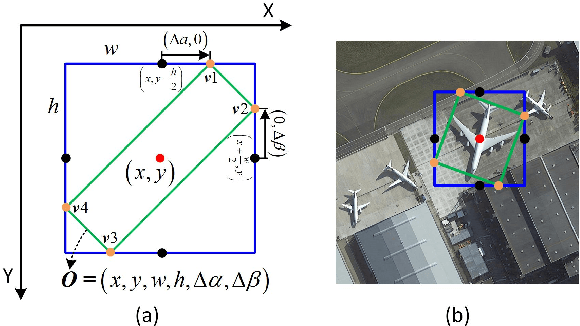
Current state-of-the-art two-stage detectors generate oriented proposals through time-consuming schemes. This diminishes the detectors' speed, thereby becoming the computational bottleneck in advanced oriented object detection systems. This work proposes an effective and simple oriented object detection framework, termed Oriented R-CNN, which is a general two-stage oriented detector with promising accuracy and efficiency. To be specific, in the first stage, we propose an oriented Region Proposal Network (oriented RPN) that directly generates high-quality oriented proposals in a nearly cost-free manner. The second stage is oriented R-CNN head for refining oriented Regions of Interest (oriented RoIs) and recognizing them. Without tricks, oriented R-CNN with ResNet50 achieves state-of-the-art detection accuracy on two commonly-used datasets for oriented object detection including DOTA (75.87% mAP) and HRSC2016 (96.50% mAP), while having a speed of 15.1 FPS with the image size of 1024$\times$1024 on a single RTX 2080Ti. We hope our work could inspire rethinking the design of oriented detectors and serve as a baseline for oriented object detection. Code is available at https://github.com/jbwang1997/OBBDetection.
ENHANCE (ENriching Health data by ANnotations of Crowd and Experts): A case study for skin lesion classification
Jul 27, 2021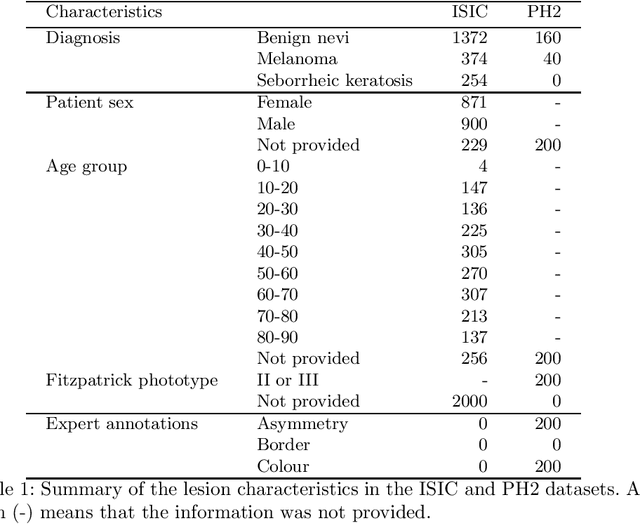
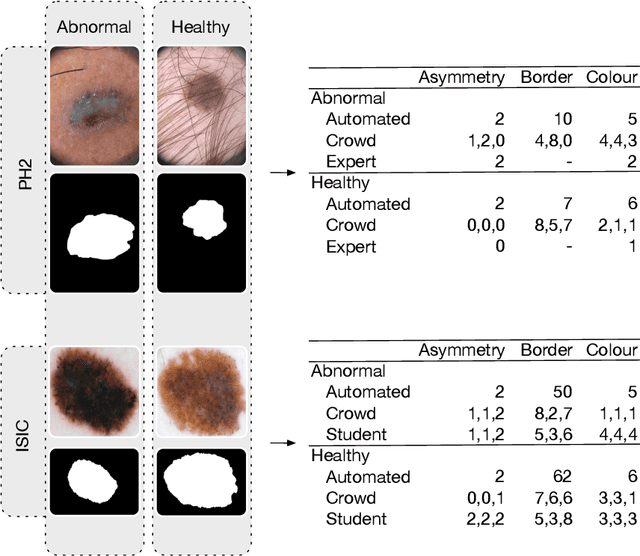
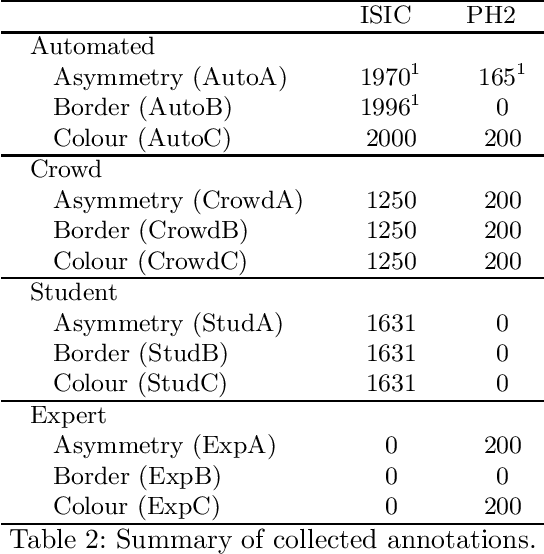
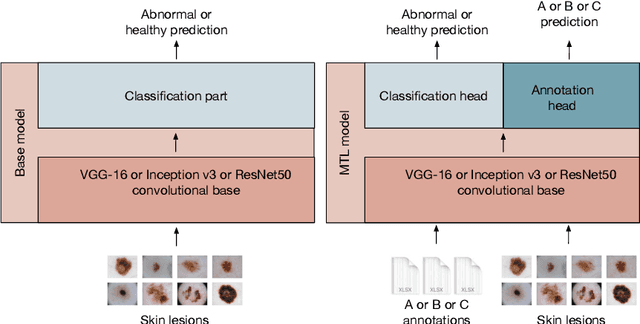
We present ENHANCE, an open dataset with multiple annotations to complement the existing ISIC and PH2 skin lesion classification datasets. This dataset contains annotations of visual ABC (asymmetry, border, colour) features from non-expert annotation sources: undergraduate students, crowd workers from Amazon MTurk and classic image processing algorithms. In this paper we first analyse the correlations between the annotations and the diagnostic label of the lesion, as well as study the agreement between different annotation sources. Overall we find weak correlations of non-expert annotations with the diagnostic label, and low agreement between different annotation sources. We then study multi-task learning (MTL) with the annotations as additional labels, and show that non-expert annotations can improve (ensembles of) state-of-the-art convolutional neural networks via MTL. We hope that our dataset can be used in further research into multiple annotations and/or MTL. All data and models are available on Github: https://github.com/raumannsr/ENHANCE.
Image Enhancement Network Trained by Using HDR images
Jan 17, 2019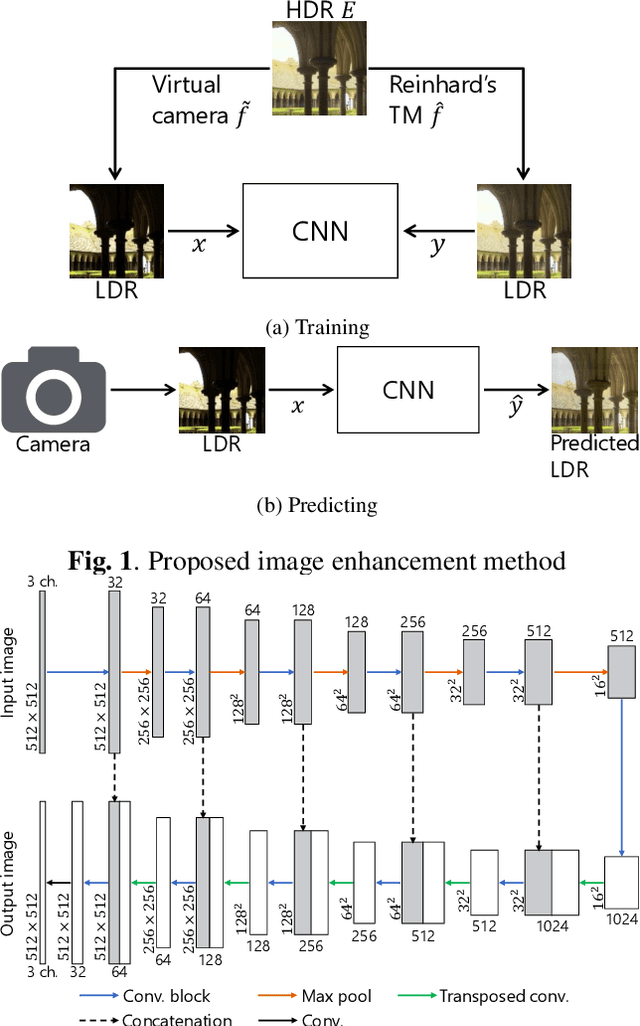

In this paper, a novel image enhancement network is proposed, where HDR images are used for generating training data for our network. Most of conventional image enhancement methods, including Retinex based methods, do not take into account restoring lost pixel values caused by clipping and quantizing. In addition, recently proposed CNN based methods still have a limited scope of application or a limited performance, due to network architectures. In contrast, the proposed method have a higher performance and a simpler network architecture than existing CNN based methods. Moreover, the proposed method enables us to restore lost pixel values. Experimental results show that the proposed method can provides higher-quality images than conventional image enhancement methods including a CNN based method, in terms of TMQI and NIQE.
Enhanced CNN for image denoising
Nov 05, 2018
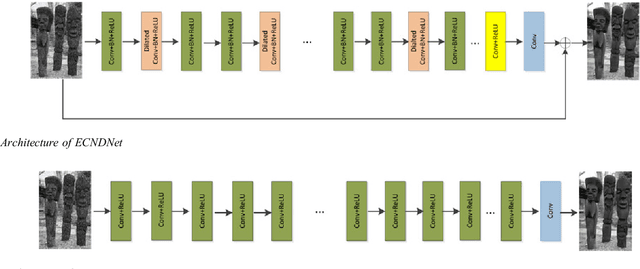
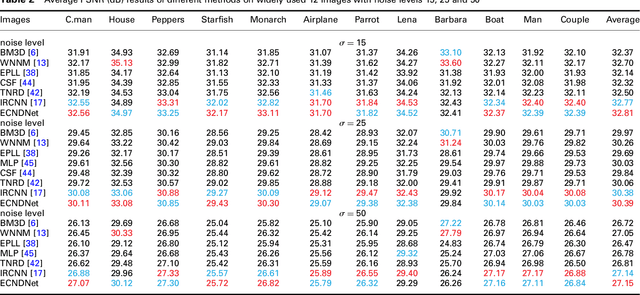
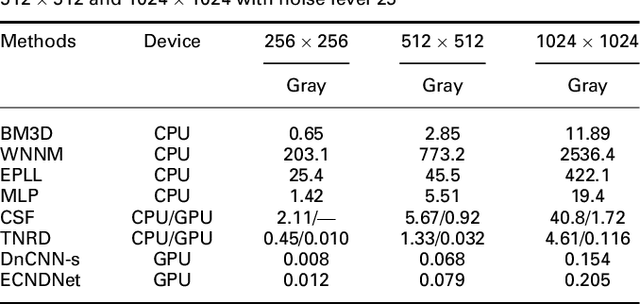
Due to the flexible architectures of deep convolutional neural networks (CNNs), which are successfully used for image denoising. However, they suffer from the following drawbacks: (1) deep network architecture is very difficult to be train. (2) Very deep networks face the challenge of performance saturation. In this paper, we propose a novel method called enhanced convolutional neural denoising network (ECNDNet). Specifically, we use residual learning and batch normalization (BN) techniques to address the problem of training difficulties and accelerate the convergence of the network. In addition, dilated convolutions are used in our network to enlarge the context information and reduce the computational cost. Extensive experiments demonstrate that our ECNDNet outperforms the state-of-the-art methods such as IRCNN for image denoising.