 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Gastric Cancer Detection from X-ray Images Using Effective Data Augmentation and Hard Boundary Box Training
Aug 18, 2021
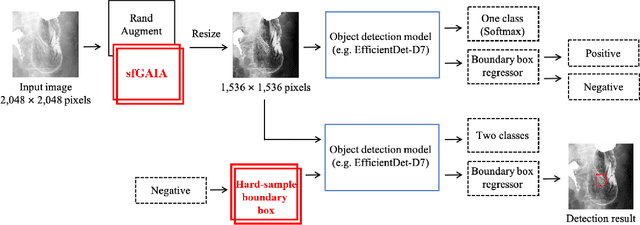
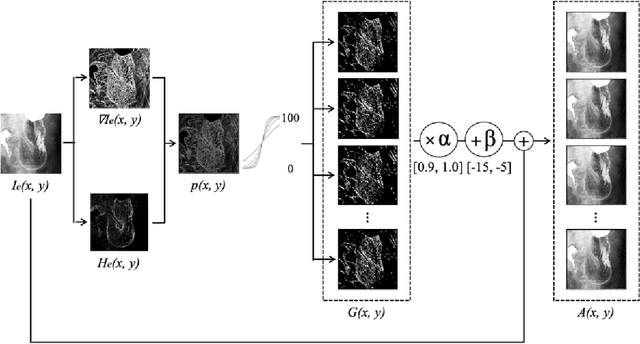
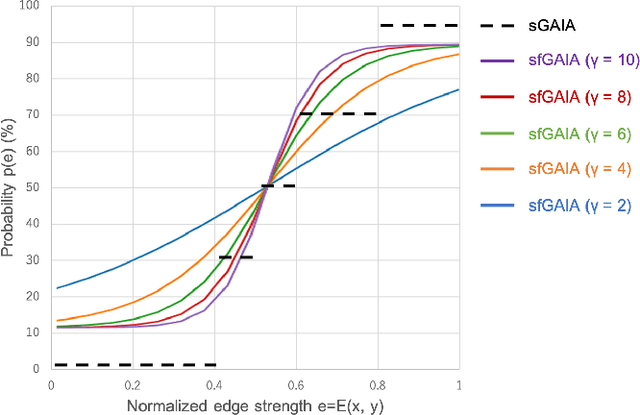
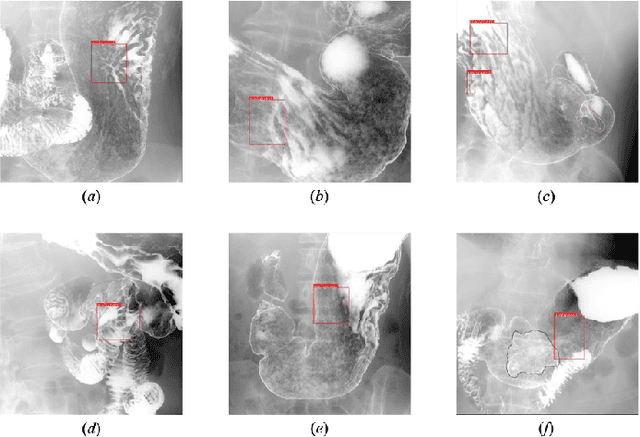
X-ray examination is suitable for screening of gastric cancer. Compared to endoscopy, which can only be performed by doctors, X-ray imaging can also be performed by radiographers, and thus, can treat more patients. However, the diagnostic accuracy of gastric radiographs is as low as 85%. To address this problem, highly accurate and quantitative automated diagnosis using machine learning needs to be performed. This paper proposes a diagnostic support method for detecting gastric cancer sites from X-ray images with high accuracy. The two new technical proposal of the method are (1) stochastic functional gastric image augmentation (sfGAIA), and (2) hard boundary box training (HBBT). The former is a probabilistic enhancement of gastric folds in X-ray images based on medical knowledge, whereas the latter is a recursive retraining technique to reduce false positives. We use 4,724 gastric radiographs of 145 patients in clinical practice and evaluate the cancer detection performance of the method in a patient-based five-group cross-validation. The proposed sfGAIA and HBBT significantly enhance the performance of the EfficientDet-D7 network by 5.9% in terms of the F1-score, and our screening method reaches a practical screening capability for gastric cancer (F1: 57.8%, recall: 90.2%, precision: 42.5%).
Generalized Rank Minimization based Group Sparse Coding for Low-level Image Restoration via Dictionary Learning
Jul 13, 2019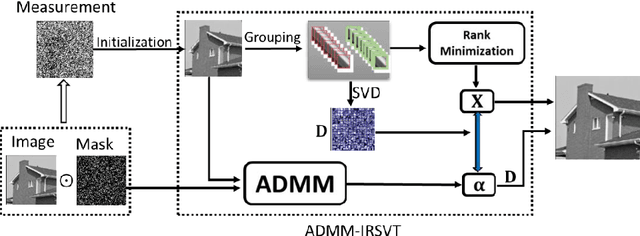
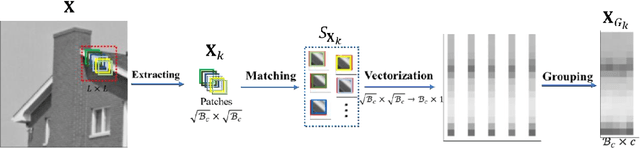


Recently, low-rank matrix recovery theory has been emerging as a significant progress for various image processing problems. Meanwhile, the group sparse coding (GSC) theory has led to great successes in image restoration with group contains low-rank property. In this paper, we introduce a novel GSC framework using generalized rank minimization for image restoration tasks via an effective adaptive dictionary learning scheme. For a more accurate approximation of the rank of group matrix, we proposed a generalized rank minimization model with a generalized and flexible weighted scheme and the generalized nonconvex nonsmooth relaxation function. Then an efficient generalized iteratively reweighted singular-value function thresholding (GIR-SFT) algorithm is proposed to handle the resulting minimization problem of GSC. Our proposed model is connected to image restoration (IR) problems via an alternating direction method of multipliers (ADMM) strategy. Extensive experiments on typical IR problems of image compressive sensing (CS) reconstruction, inpainting, deblurring and impulsive noise removal demonstrate that our proposed GSC framework can enhance the image restoration quality compared with many state-of-the-art methods.
Abstract Reasoning via Logic-guided Generation
Jul 22, 2021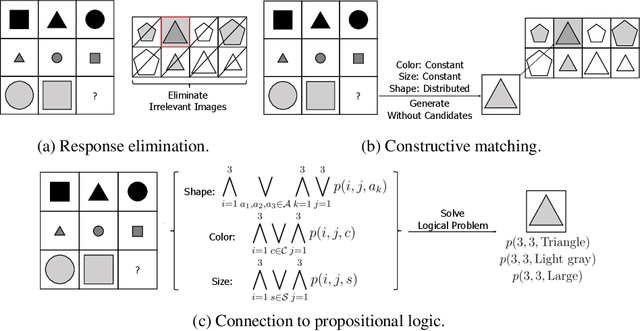
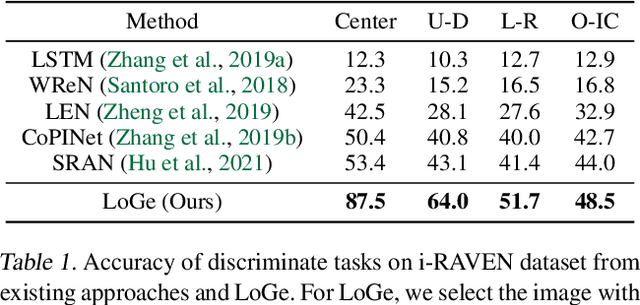
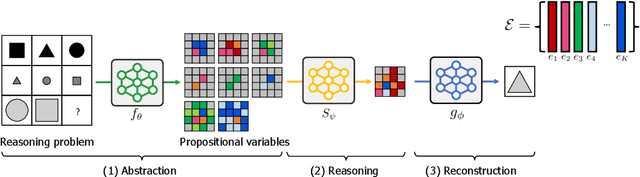
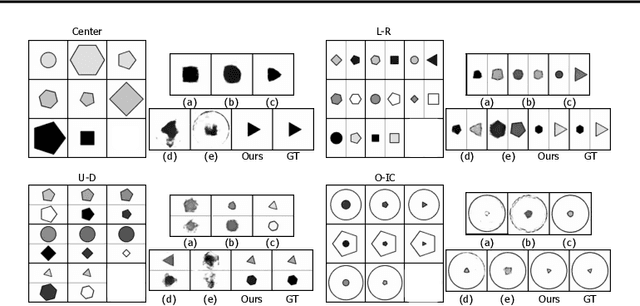
Abstract reasoning, i.e., inferring complicated patterns from given observations, is a central building block of artificial general intelligence. While humans find the answer by either eliminating wrong candidates or first constructing the answer, prior deep neural network (DNN)-based methods focus on the former discriminative approach. This paper aims to design a framework for the latter approach and bridge the gap between artificial and human intelligence. To this end, we propose logic-guided generation (LoGe), a novel generative DNN framework that reduces abstract reasoning as an optimization problem in propositional logic. LoGe is composed of three steps: extract propositional variables from images, reason the answer variables with a logic layer, and reconstruct the answer image from the variables. We demonstrate that LoGe outperforms the black box DNN frameworks for generative abstract reasoning under the RAVEN benchmark, i.e., reconstructing answers based on capturing correct rules of various attributes from observations.
Domain Adaptation for Real-World Single View 3D Reconstruction
Aug 24, 2021
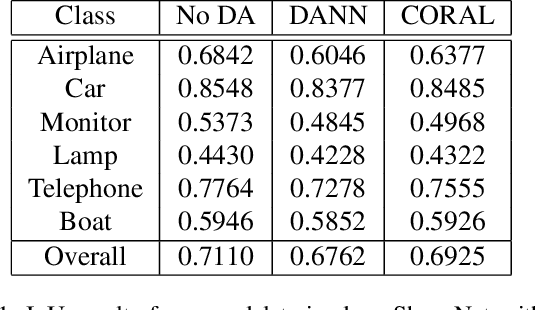
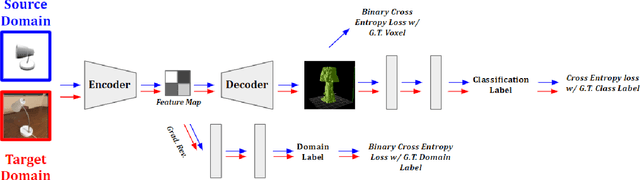
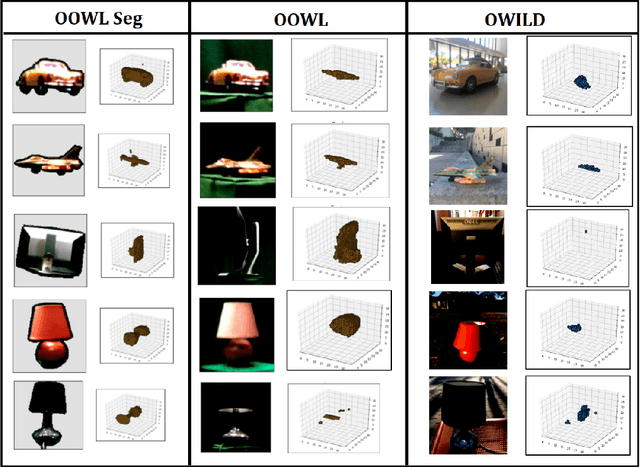
Deep learning-based object reconstruction algorithms have shown remarkable improvements over classical methods. However, supervised learning based methods perform poorly when the training data and the test data have different distributions. Indeed, most current works perform satisfactorily on the synthetic ShapeNet dataset, but dramatically fail in when presented with real world images. To address this issue, unsupervised domain adaptation can be used transfer knowledge from the labeled synthetic source domain and learn a classifier for the unlabeled real target domain. To tackle this challenge of single view 3D reconstruction in the real domain, we experiment with a variety of domain adaptation techniques inspired by the maximum mean discrepancy (MMD) loss, Deep CORAL, and the domain adversarial neural network (DANN). From these findings, we additionally propose a novel architecture which takes advantage of the fact that in this setting, target domain data is unsupervised with regards to the 3D model but supervised for class labels. We base our framework off a recent network called pix2vox. Results are performed with ShapeNet as the source domain and domains within the Object Dataset Domain Suite (ODDS) dataset as the target, which is a real world multiview, multidomain image dataset. The domains in ODDS vary in difficulty, allowing us to assess notions of domain gap size. Our results are the first in the multiview reconstruction literature using this dataset.
Real-time Indian Sign Language (ISL) Recognition
Aug 24, 2021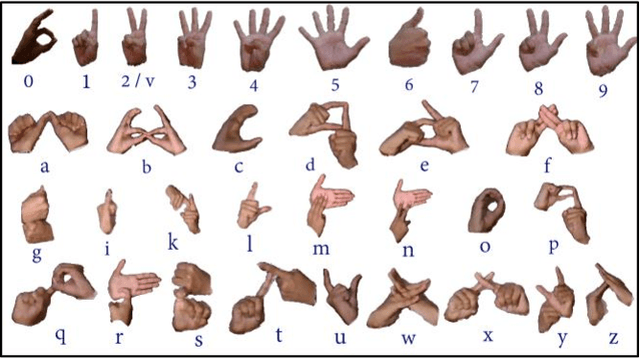
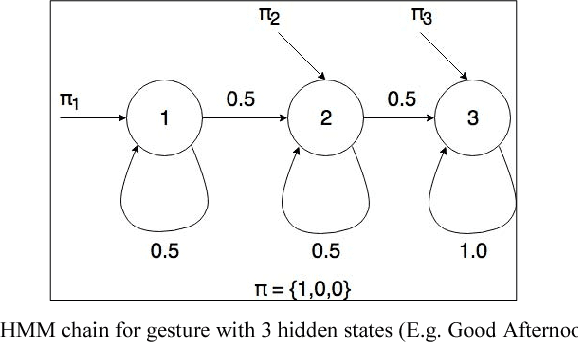

This paper presents a system which can recognise hand poses & gestures from the Indian Sign Language (ISL) in real-time using grid-based features. This system attempts to bridge the communication gap between the hearing and speech impaired and the rest of the society. The existing solutions either provide relatively low accuracy or do not work in real-time. This system provides good results on both the parameters. It can identify 33 hand poses and some gestures from the ISL. Sign Language is captured from a smartphone camera and its frames are transmitted to a remote server for processing. The use of any external hardware (such as gloves or the Microsoft Kinect sensor) is avoided, making it user-friendly. Techniques such as Face detection, Object stabilisation and Skin Colour Segmentation are used for hand detection and tracking. The image is further subjected to a Grid-based Feature Extraction technique which represents the hand's pose in the form of a Feature Vector. Hand poses are then classified using the k-Nearest Neighbours algorithm. On the other hand, for gesture classification, the motion and intermediate hand poses observation sequences are fed to Hidden Markov Model chains corresponding to the 12 pre-selected gestures defined in ISL. Using this methodology, the system is able to achieve an accuracy of 99.7% for static hand poses, and an accuracy of 97.23% for gesture recognition.
* 9 pages
CogSense: A Cognitively Inspired Framework for Perception Adaptation
Jul 22, 2021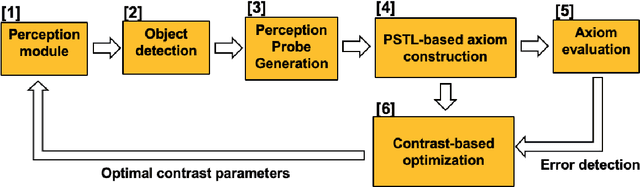
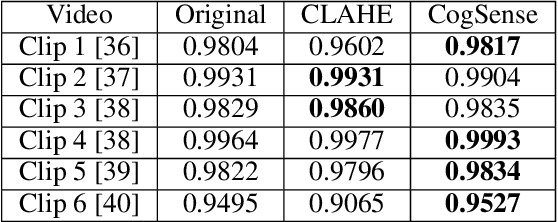

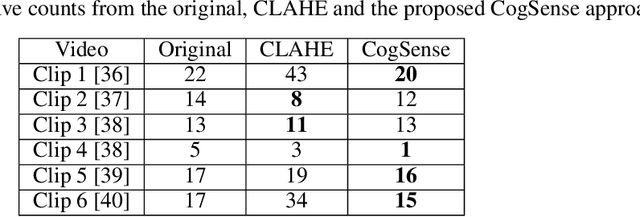
This paper proposes the CogSense system, which is inspired by sense-making cognition and perception in the mammalian brain to perform perception error detection and perception parameter adaptation using probabilistic signal temporal logic. As a specific application, a contrast-based perception adaption method is presented and validated. The proposed method evaluates perception errors using heterogeneous probe functions computed from the detected objects and subsequently solves a contrast optimization problem to correct perception errors. The CogSense probe functions utilize the characteristics of geometry, dynamics, and detected blob image quality of the objects to develop axioms in a probabilistic signal temporal logic framework. By evaluating these axioms, we can formally verify whether the detections are valid or erroneous. Further, using the CogSense axioms, we generate the probabilistic signal temporal logic-based constraints to finally solve the contrast-based optimization problem to reduce false positives and false negatives.
Roughness Index and Roughness Distance for Benchmarking Medical Segmentation
Mar 23, 2021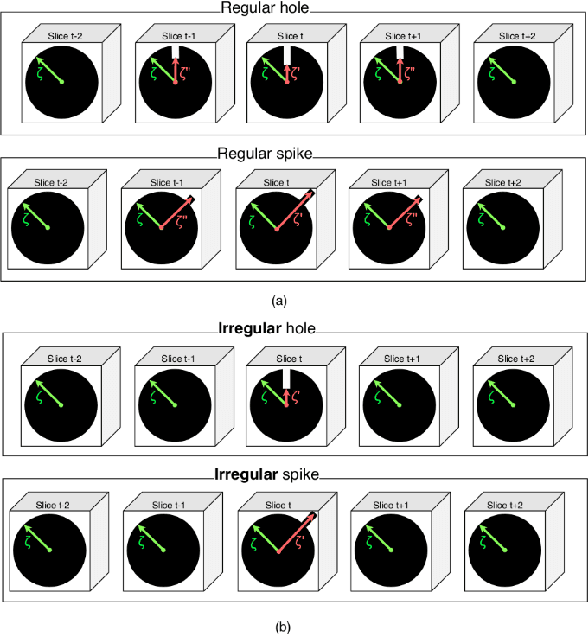
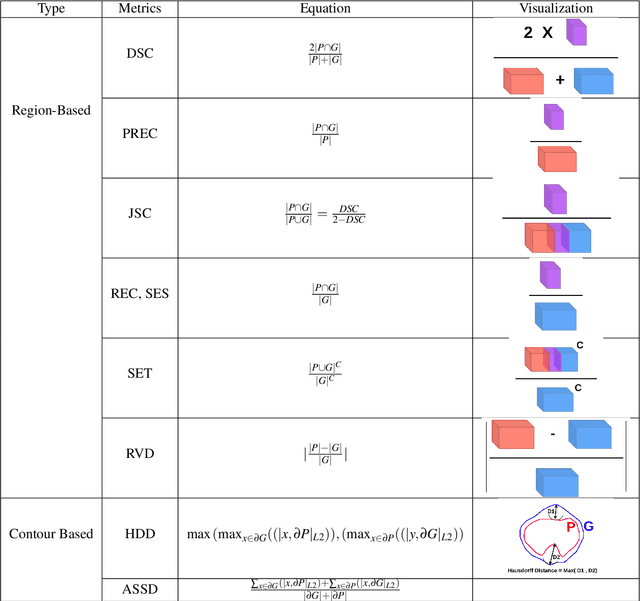
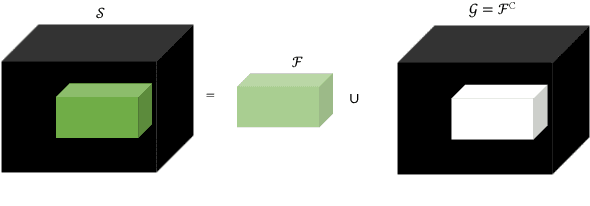

Medical image segmentation is one of the most challenging tasks in medical image analysis and has been widely developed for many clinical applications. Most of the existing metrics have been first designed for natural images and then extended to medical images. While object surface plays an important role in medical segmentation and quantitative analysis i.e. analyze brain tumor surface, measure gray matter volume, most of the existing metrics are limited when it comes to analyzing the object surface, especially to tell about surface smoothness or roughness of a given volumetric object or to analyze the topological errors. In this paper, we first analysis both pros and cons of all existing medical image segmentation metrics, specially on volumetric data. We then propose an appropriate roughness index and roughness distance for medical image segmentation analysis and evaluation. Our proposed method addresses two kinds of segmentation errors, i.e. (i)topological errors on boundary/surface and (ii)irregularities on the boundary/surface. The contribution of this work is four-fold: (i) detect irregular spikes/holes on a surface, (ii) propose roughness index to measure surface roughness of a given object, (iii) propose a roughness distance to measure the distance of two boundaries/surfaces by utilizing the proposed roughness index and (iv) suggest an algorithm which helps to remove the irregular spikes/holes to smooth the surface. Our proposed roughness index and roughness distance are built upon the solid surface roughness parameter which has been successfully developed in the civil engineering.
Unrolled Wirtinger Flow with Deep Priors for Phaseless Imaging
Aug 03, 2021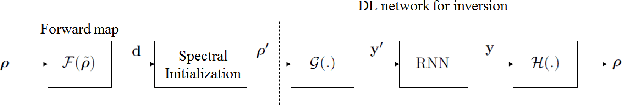
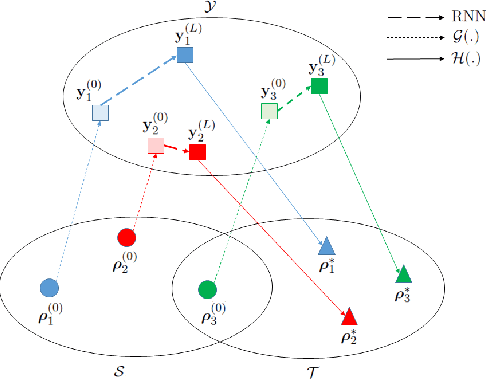

We introduce a deep learning (DL) based network for imaging from measurement intensities. The network architecture uses a recurrent structure that unrolls the Wirtinger Flow (WF) algorithm with a deep prior which enables performing the algorithm updates in a lower dimensional encoded image space. We use a separate deep network (DN), referred to as the encoding network, for transforming the spectral initialization used in the WF algorithm to an appropriate initial value for the encoded domain. The unrolling scheme that models a fixed number of iterations of the underlying algorithm into a recurrent neural network (RNN) enable us to simultaneously learn the parameters of the prior network, the encoding network and the RNN during training. We establish sufficient conditions on the network to guarantee exact recovery under deterministic forward models and demonstrate the relation between the Lipschitz constants of the trained prior and encoding networks to the convergence rate. We show the practical applicability of our method on synthetic aperture imaging using high fidelity simulation data from the PCSWAT software. Our numerical study shows that the deep prior facilitates improvements in sample complexity.
Abstractive Sentence Summarization with Guidance of Selective Multimodal Reference
Aug 11, 2021

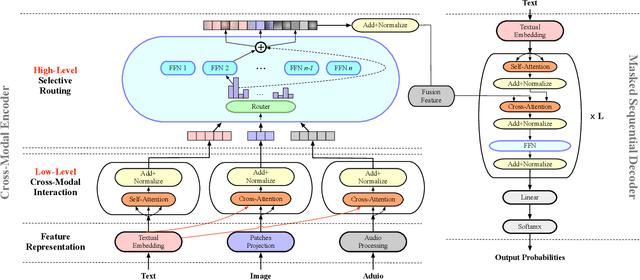
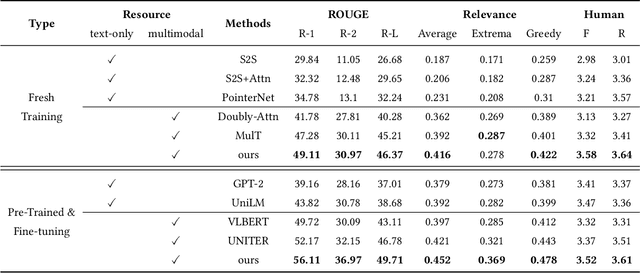
Multimodal abstractive summarization with sentence output is to generate a textual summary given a multimodal triad -- sentence, image and audio, which has been proven to improve users satisfaction and convenient our life. Existing approaches mainly focus on the enhancement of multimodal fusion, while ignoring the unalignment among multiple inputs and the emphasis of different segments in feature, which has resulted in the superfluity of multimodal interaction. To alleviate these problems, we propose a Multimodal Hierarchical Selective Transformer (mhsf) model that considers reciprocal relationships among modalities (by low-level cross-modal interaction module) and respective characteristics within single fusion feature (by high-level selective routing module). In details, it firstly aligns the inputs from different sources and then adopts a divide and conquer strategy to highlight or de-emphasize multimodal fusion representation, which can be seen as a sparsely feed-forward model - different groups of parameters will be activated facing different segments in feature. We evaluate the generalism of proposed mhsf model with the pre-trained+fine-tuning and fresh training strategies. And Further experimental results on MSMO demonstrate that our model outperforms SOTA baselines in terms of ROUGE, relevance scores and human evaluation.
Image Enhancement Network Trained by Using HDR images
Jan 25, 2019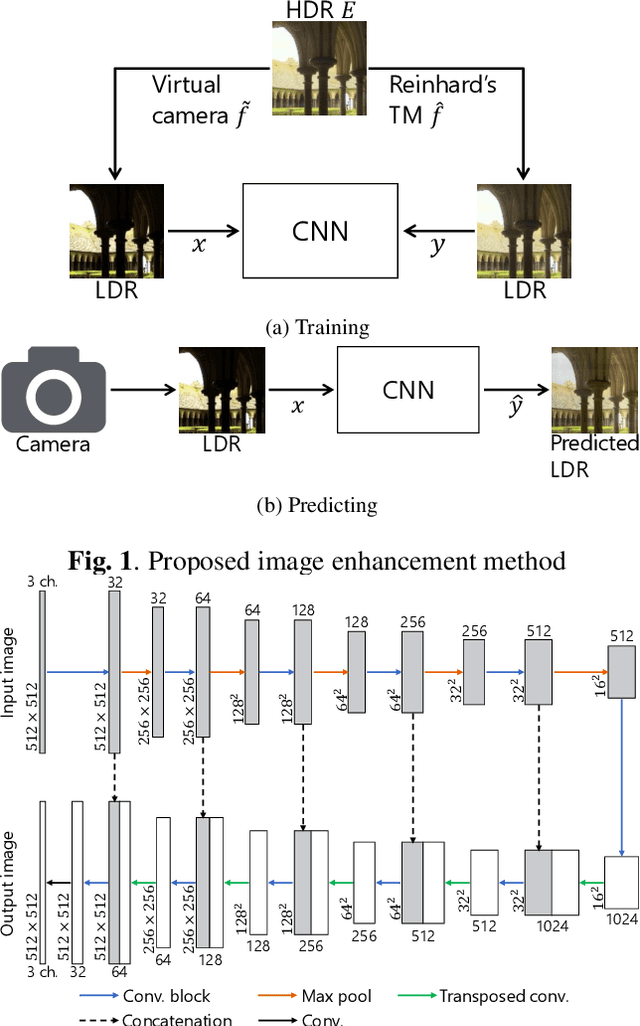

In this paper, a novel image enhancement network is proposed, where HDR images are used for generating training data for our network. Most of conventional image enhancement methods, including Retinex based methods, do not take into account restoring lost pixel values caused by clipping and quantizing. In addition, recently proposed CNN based methods still have a limited scope of application or a limited performance, due to network architectures. In contrast, the proposed method have a higher performance and a simpler network architecture than existing CNN based methods. Moreover, the proposed method enables us to restore lost pixel values. Experimental results show that the proposed method can provides higher-quality images than conventional image enhancement methods including a CNN based method, in terms of TMQI and NIQE.